
Arrays¶
 Dask array provides a parallel, larger-than-memory, n-dimensional array using blocked algorithms. Simply put: distributed Numpy.
Dask array provides a parallel, larger-than-memory, n-dimensional array using blocked algorithms. Simply put: distributed Numpy.
- Parallel: Uses all of the cores on your computer
- Larger-than-memory: Lets you work on datasets that are larger than your available memory by breaking up your array into many small pieces, operating on those pieces in an order that minimizes the memory footprint of your computation, and effectively streaming data from disk.
- Blocked Algorithms: Perform large computations by performing many smaller computations
In this notebook, we'll build some understanding by implementing some blocked algorithms from scratch. We'll then use Dask Array to analyze large datasets, in parallel, using a familiar NumPy-like API.
Related Documentation
Create data¶
%run prep.py -d random
Setup¶
from dask.distributed import Client
client = Client(n_workers=4, processes=False)
Blocked Algorithms¶
A blocked algorithm executes on a large dataset by breaking it up into many small blocks.
For example, consider taking the sum of a billion numbers. We might instead break up the array into 1,000 chunks, each of size 1,000,000, take the sum of each chunk, and then take the sum of the intermediate sums.
We achieve the intended result (one sum on one billion numbers) by performing many smaller results (one thousand sums on one million numbers each, followed by another sum of a thousand numbers.)
We do exactly this with Python and NumPy in the following example:
# Load data with h5py
# this creates a pointer to the data, but does not actually load
import h5py
import os
f = h5py.File(os.path.join('data', 'random.hdf5'), mode='r')
dset = f['/x']
Compute sum using blocked algorithm
Before using dask, lets consider the concept of blocked algorithms. We can compute the sum of a large number of elements by loading them chunk-by-chunk, and keeping a running total.
Here we compute the sum of this large array on disk by
- Computing the sum of each 1,000,000 sized chunk of the array
- Computing the sum of the 1,000 intermediate sums
Note that this is a sequential process in the notebook kernel, both the loading and summing.
# Compute sum of large array, one million numbers at a time
sums = []
for i in range(0, 1000000000, 1000000):
chunk = dset[i: i + 1000000] # pull out numpy array
sums.append(chunk.sum())
total = sum(sums)
print(total)
Exercise: Compute the mean using a blocked algorithm¶
Now that we've seen the simple example above try doing a slightly more complicated problem, compute the mean of the array, assuming for a moment that we don't happen to already know how many elements are in the data. You can do this by changing the code above with the following alterations:
- Compute the sum of each block
- Compute the length of each block
- Compute the sum of the 1,000 intermediate sums and the sum of the 1,000 intermediate lengths and divide one by the other
This approach is overkill for our case but does nicely generalize if we don't know the size of the array or individual blocks beforehand.
# Compute the mean of the array
sums = []
lengths = []
for i in range(0, 1000000000, 1000000):
chunk = dset[i: i + 1000000] # pull out numpy array
sums.append(chunk.sum())
lengths.append(len(chunk))
total = sum(sums)
length = sum(lengths)
print(total / length)
dask.array contains these algorithms¶
Dask.array is a NumPy-like library that does these kinds of tricks to operate on large datasets that don't fit into memory. It extends beyond the linear problems discussed above to full N-Dimensional algorithms and a decent subset of the NumPy interface.
Create dask.array object
You can create a dask.array Array object with the da.from_array function. This function accepts
data: Any object that supports NumPy slicing, likedsetchunks: A chunk size to tell us how to block up our array, like(1000000,)
import dask.array as da
x = da.from_array(dset, chunks=(1000000,))
x
** Manipulate dask.array object as you would a numpy array**
Now that we have an Array we perform standard numpy-style computations like arithmetic, mathematics, slicing, reductions, etc..
The interface is familiar, but the actual work is different. dask_array.sum() does not do the same thing as numpy_array.sum().
What's the difference?
dask_array.sum() builds an expression of the computation. It does not do the computation yet. numpy_array.sum() computes the sum immediately.
Why the difference?
Dask arrays are split into chunks. Each chunk must have computations run on that chunk explicitly. If the desired answer comes from a small slice of the entire dataset, running the computation over all data would be wasteful of CPU and memory.
result = x.sum()
result
Compute result
Dask.array objects are lazily evaluated. Operations like .sum build up a graph of blocked tasks to execute.
We ask for the final result with a call to .compute(). This triggers the actual computation.
result.compute()
Exercise: Compute the mean¶
And the variance, std, etc.. This should be a small change to the example above.
Look at what other operations you can do with the Jupyter notebook's tab-completion.
Does this match your result from before?
Performance and Parallelism¶
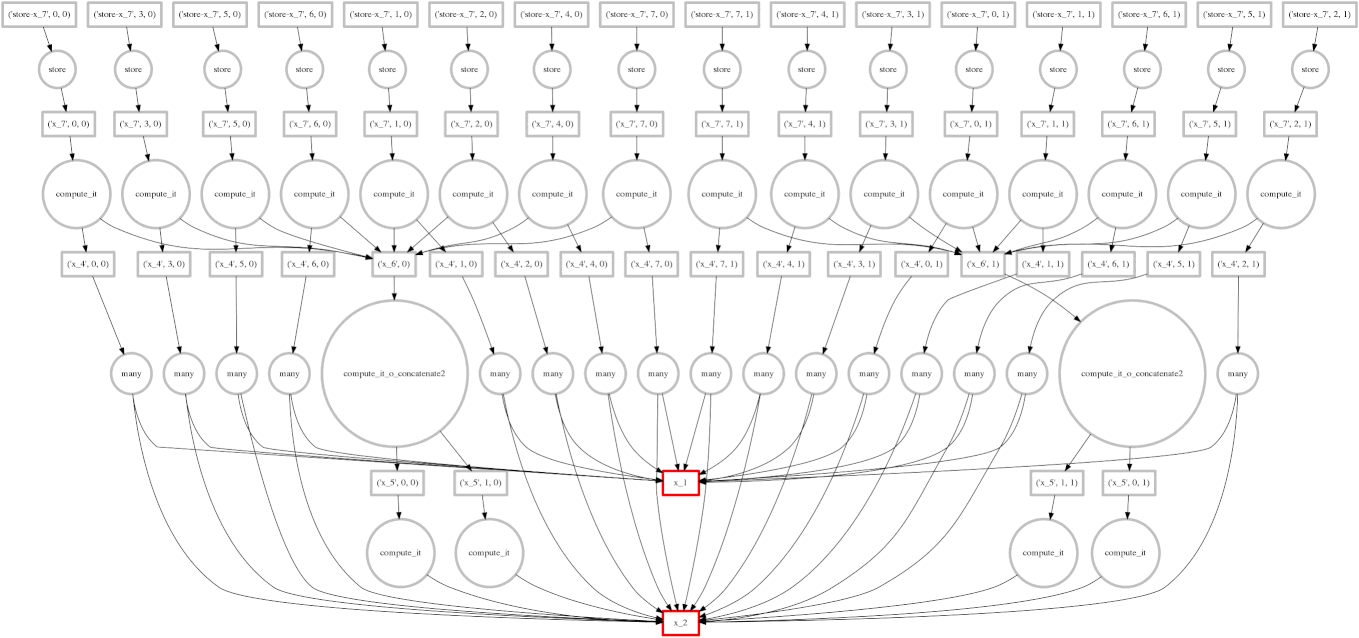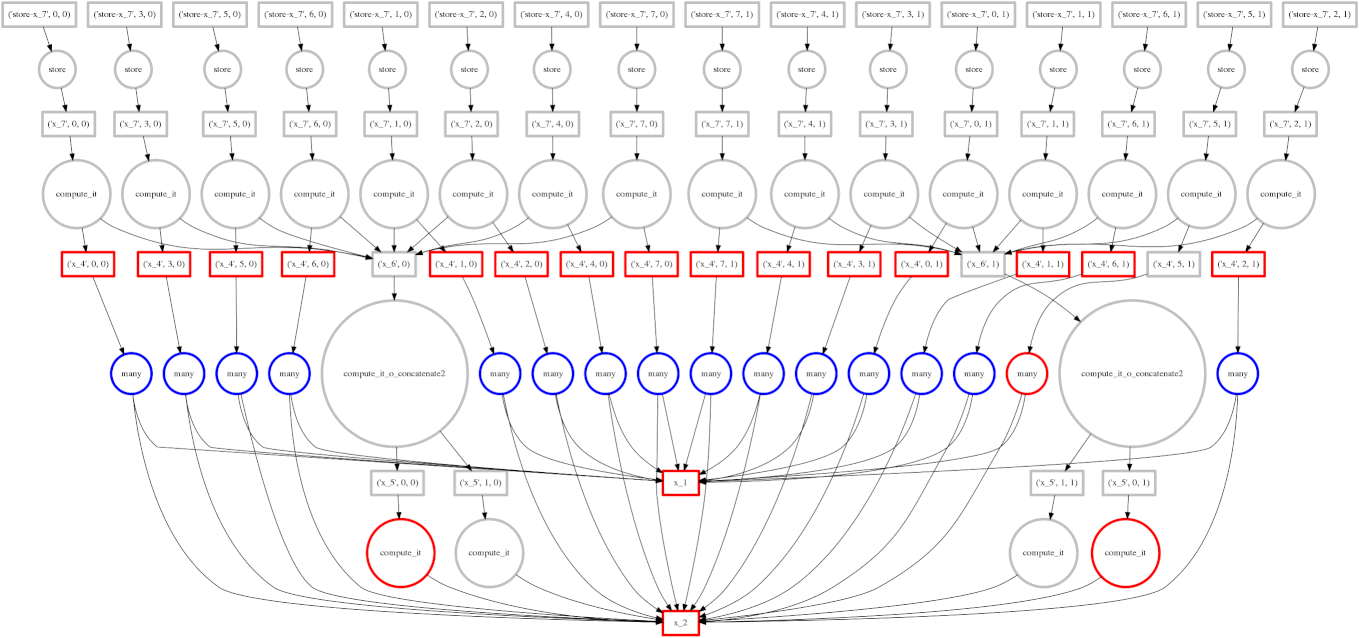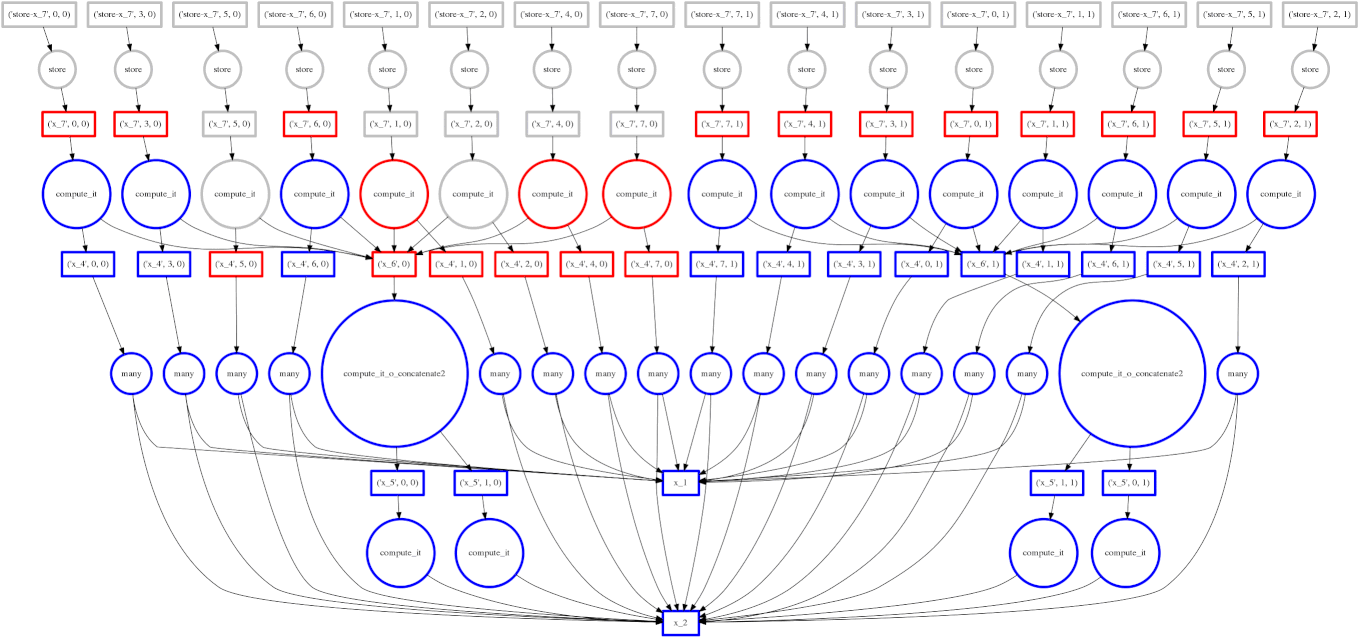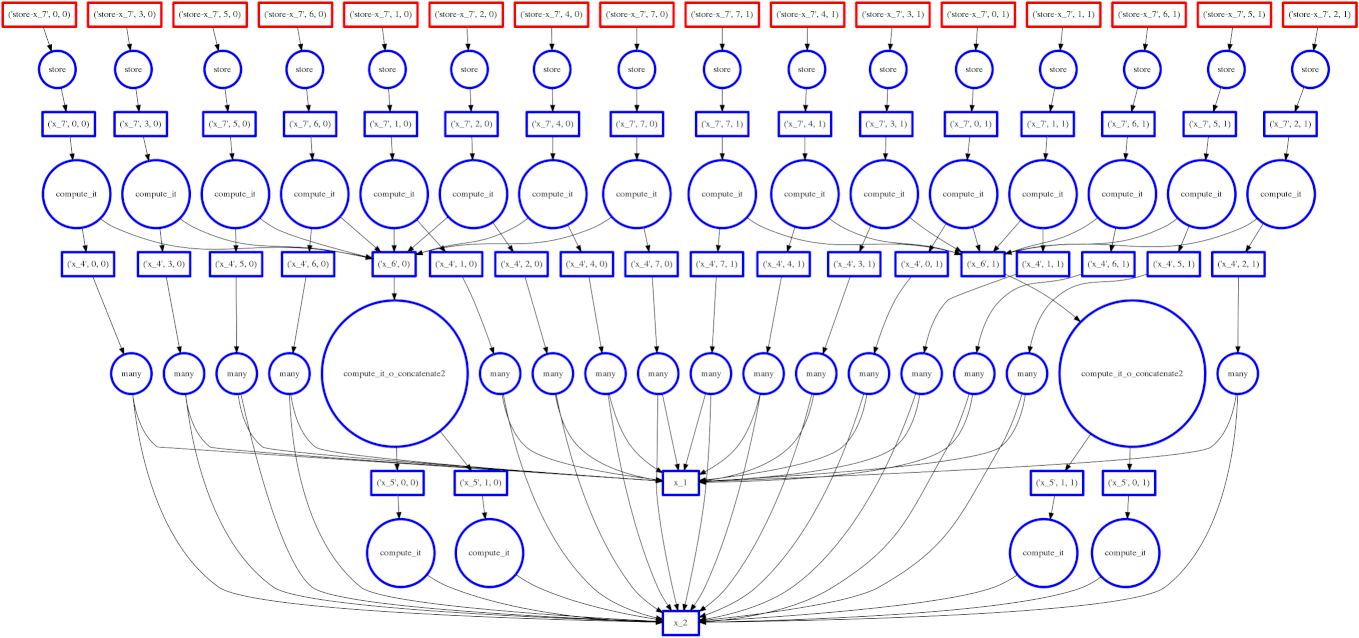
In our first examples we used for loops to walk through the array one block at a time. For simple operations like sum this is optimal. However for complex operations we may want to traverse through the array differently. In particular we may want the following:
- Use multiple cores in parallel
- Chain operations on a single blocks before moving on to the next one
Dask.array translates your array operations into a graph of inter-related tasks with data dependencies between them. Dask then executes this graph in parallel with multiple threads. We'll discuss more about this in the next section.
Example¶
- Construct a 20000x20000 array of normally distributed random values broken up into 1000x1000 sized chunks
- Take the mean along one axis
- Take every 100th element
import numpy as np
import dask.array as da
x = da.random.normal(10, 0.1, size=(20000, 20000), # 400 million element array
chunks=(1000, 1000)) # Cut into 1000x1000 sized chunks
y = x.mean(axis=0)[::100] # Perform NumPy-style operations
x.nbytes / 1e9 # Gigabytes of the input processed lazily
%%time
y.compute() # Time to compute the result
Performance comparision¶
The following experiment was performed on a heavy personal laptop. Your performance may vary. If you attempt the NumPy version then please ensure that you have more than 4GB of main memory.
NumPy: 19s, Needs gigabytes of memory
import numpy as np
%%time
x = np.random.normal(10, 0.1, size=(20000, 20000))
y = x.mean(axis=0)[::100]
y
CPU times: user 19.6 s, sys: 160 ms, total: 19.8 s
Wall time: 19.7 s
Dask Array: 4s, Needs megabytes of memory
import dask.array as da
%%time
x = da.random.normal(10, 0.1, size=(20000, 20000), chunks=(1000, 1000))
y = x.mean(axis=0)[::100]
y.compute()
CPU times: user 29.4 s, sys: 1.07 s, total: 30.5 s
Wall time: 4.01 s
Discussion
Notice that the Dask array computation ran in 4 seconds, but used 29.4 seconds of user CPU time. The numpy computation ran in 19.7 seconds and used 19.6 seconds of user CPU time.
Dask finished faster, but used more total CPU time because Dask was able to transparently parallelize the computation because of the chunk size.
Questions
- What happens if the dask chunks=(20000,20000)?
- Will the computation run in 4 seconds?
- How much memory will be used?
- What happens if the dask chunks=(25,25)?
- What happens to CPU and memory?
Exercise: Meteorological data¶
There is 2GB of somewhat artifical weather data in HDF5 files in data/weather-big/*.hdf5. We'll use the h5py library to interact with this data and dask.array to compute on it.
Our goal is to visualize the average temperature on the surface of the Earth for this month. This will require a mean over all of this data. We'll do this in the following steps
- Create
h5py.Datasetobjects for each of the days of data on disk (dsets) - Wrap these with
da.from_arraycalls - Stack these datasets along time with a call to
da.stack - Compute the mean along the newly stacked time axis with the
.mean()method - Visualize the result with
matplotlib.pyplot.imshow
%run prep.py -d weather
import h5py
from glob import glob
import os
filenames = sorted(glob(os.path.join('data', 'weather-big', '*.hdf5')))
dsets = [h5py.File(filename, mode='r')['/t2m'] for filename in filenames]
dsets[0]
dsets[0][:5, :5] # Slicing into h5py.Dataset object gives a numpy array
%matplotlib inline
import matplotlib.pyplot as plt
fig = plt.figure(figsize=(16, 8))
plt.imshow(dsets[0][::4, ::4], cmap='RdBu_r');
Integrate with dask.array
Make a list of dask.array objects out of your list of h5py.Dataset objects using the da.from_array function with a chunk size of (500, 500).
arrays = [da.from_array(dset, chunks=(500, 500)) for dset in dsets]
arrays
Stack this list of dask.array objects into a single dask.array object with da.stack
Stack these along the first axis so that the shape of the resulting array is (31, 5760, 11520).
x = da.stack(arrays, axis=0)
x
Plot the mean of this array along the time (0th) axis
# complete the following:
fig = plt.figure(figsize=(16, 8))
plt.imshow(..., cmap='RdBu_r')
result = x.mean(axis=0)
fig = plt.figure(figsize=(16, 8))
plt.imshow(result, cmap='RdBu_r');
Plot the difference of the first day from the mean
result = x[0] - x.mean(axis=0)
fig = plt.figure(figsize=(16, 8))
plt.imshow(result, cmap='RdBu_r');
Exercise: Subsample and store¶
In the above exercise the result of our computation is small, so we can call compute safely. Sometimes our result is still too large to fit into memory and we want to save it to disk. In these cases you can use one of the following two functions
da.store: Store dask.array into any object that supports numpy setitem syntax, e.g.f = h5py.File('myfile.hdf5') output = f.create_dataset(shape=..., dtype=...) da.store(my_dask_array, output)da.to_hdf5: A specialized function that creates and stores adask.arrayobject into anHDF5file.da.to_hdf5('data/myfile.hdf5', '/output', my_dask_array)
The task in this exercise is to use numpy step slicing to subsample the full dataset by a factor of two in both the latitude and longitude direction and then store this result to disk using one of the functions listed above.
As a reminder, Python slicing takes three elements
start:stop:step
>>> L = [1, 2, 3, 4, 5, 6, 7]
>>> L[::3]
[1, 4, 7]
# ...
import h5py
from glob import glob
import os
import dask.array as da
filenames = sorted(glob(os.path.join('data', 'weather-big', '*.hdf5')))
dsets = [h5py.File(filename, mode='r')['/t2m'] for filename in filenames]
arrays = [da.from_array(dset, chunks=(500, 500)) for dset in dsets]
x = da.stack(arrays, axis=0)
result = x[:, ::2, ::2]
da.to_zarr(result, os.path.join('data', 'myfile.zarr'), overwrite=True)
Example: Lennard-Jones potential¶
The Lennard-Jones is used in partical simuluations in physics, chemistry and engineering. It is highly parallelizable.
First, we'll run and profile the Numpy version on 7,000 particles.
import numpy as np
# make a random collection of particles
def make_cluster(natoms, radius=40, seed=1981):
np.random.seed(seed)
cluster = np.random.normal(0, radius, (natoms,3))-0.5
return cluster
def lj(r2):
sr6 = (1./r2)**3
pot = 4.*(sr6*sr6 - sr6)
return pot
# build the matrix of distances
def distances(cluster):
diff = cluster[:, np.newaxis, :] - cluster[np.newaxis, :, :]
mat = (diff*diff).sum(-1)
return mat
# the lj function is evaluated over the upper traingle
# after removing distances near zero
def potential(cluster):
d2 = distances(cluster)
dtri = np.triu(d2)
energy = lj(dtri[dtri > 1e-6]).sum()
return energy
cluster = make_cluster(int(7e3), radius=500)
%time potential(cluster)
Notice that the most time consuming function is distances:
# this would open in another browser tab
# %load_ext snakeviz
# %snakeviz potential(cluster)
# alternative simple version given text results in this tab
%prun -s tottime potential(cluster)
Dask version¶
Here's the Dask version. Only the potential function needs to be rewritten to best utilize Dask.
Note that da.nansum has been used over the full $NxN$ distance matrix to improve parallel efficiency.
import dask.array as da
# compute the potential on the entire
# matrix of distances and ignore division by zero
def potential_dask(cluster):
d2 = distances(cluster)
energy = da.nansum(lj(d2))/2.
return energy
Let's convert the NumPy array to a Dask array. Since the entire NumPy array fits in memory it is more computationally efficient to chunk the array by number of CPU cores.
from os import cpu_count
dcluster = da.from_array(cluster, chunks=cluster.shape[0]//cpu_count())
This step should scale quite well with number of cores. The warnings are complaining about dividing by zero, which is why we used da.nansum in potential_dask.
e = potential_dask(dcluster)
%time e.compute()
Limitations¶
Dask Array does not implement the entire numpy interface. Users expecting this will be disappointed. Notably Dask Array has the following failings:
- Dask does not implement all of
np.linalg. This has been done by a number of excellent BLAS/LAPACK implementations and is the focus of numerous ongoing academic research projects. - Dask Array does not support some operations where the resulting shape depends on the values of the array. For those that it does support (for example, masking one Dask Array with another boolean mask), the chunk sizes will be unknown, which may cause issues with other operations that need to know the chunk sizes.
- Dask Array does not attempt operations like
sortwhich are notoriously difficult to do in parallel and are of somewhat diminished value on very large data (you rarely actually need a full sort). Often we include parallel-friendly alternatives liketopk. - Dask development is driven by immediate need, and so many lesser used
functions, like
np.sometruehave not been implemented purely out of laziness. These would make excellent community contributions.
client.shutdown()