%%html
<script>
function code_toggle() {
if (code_shown){
$('div.input').hide('500');
$('#toggleButton').val('Show Code')
} else {
$('div.input').show('500');
$('#toggleButton').val('Hide Code')
}
code_shown = !code_shown
}
$( document ).ready(function(){
code_shown=false;
$('div.input').hide()
});
</script>
<form action="javascript:code_toggle()"><input type="submit" id="toggleButton" value="Show Code"></form>
<style>
.rendered_html td {
font-size: xx-large;
text-align: left; !important
}
.rendered_html th {
font-size: xx-large;
text-align: left; !important
}
</style>
%%capture
import sys
sys.path.append("..")
import statnlpbook.util as util
import matplotlib
matplotlib.rcParams['figure.figsize'] = (10.0, 6.0)
%load_ext tikzmagic
from IPython.display import Image
import random
Transformer Language Models¶
- Self-attention
- Masked langauge models
Attention is all you need¶
Transformers replace the whole LSTM with self-attention (Vaswani et al., 2017)
The full transformer model¶
Deep multi-head self-attention encoder-decoder with sinusodial positional encodings:
Transformer unit¶
Add residual connections, layer normalization and feed-forward layers (MLPs):
Multi-head self-attention¶
Repeat this multiple times with multiple sets of parameter matrices, then concatenate:

Scaled Dot-Product Attention¶
Use hidden representation $\mathbf{h}_i$ to create three vectors: query vector $\color{purple}{\mathbf{q}_i}=W^q\mathbf{h}_i$, key vector $\color{orange}{\mathbf{k}_i}=W^k\mathbf{h}_i$, value vector $\color{blue}{\mathbf{v}_i}=W^v\mathbf{h}_i$.
$$ \mathbf{\alpha}_{i,j} = \text{softmax}\left( \frac{\color{purple}{\mathbf{q}_i}^\intercal \color{orange}{\mathbf{k}_j}} {\sqrt{d_{\mathbf{h}}}} \right) \\ \mathbf{h}_i^\prime = \sum_{j=1}^n \mathbf{\alpha}_{i,j} \color{blue}{\mathbf{v}_j} $$$W^q$, $W^k$ and $W^v$ are all trained.
In matrix form:
$$ \text{Attention}(Q,K,V)= \text{softmax}\left( \frac{\color{purple}{Q} \color{orange}{K}^\intercal} {\sqrt{d_{\mathbf{h}}}} \right) \color{blue}{V} $$where $$ \text{head}_i=\text{Attention}(QW_i^q,KW_i^k,VW_i^v) $$
Transformer¶
Repeat this for multiple layers, each using the previous as input:
$$ \text{MultiHead}^\ell(Q^\ell,K^\ell,V^\ell)=\text{Concat}(\text{head}_1^\ell,\ldots,\text{head}_h^\ell)W_\ell^O $$where $$ \text{head}_i^\ell=\text{Attention}(Q^\ell W_{i,\ell}^q,K^\ell W_{i,\ell}^k,V^\ell W_{i,\ell}^v) $$

Back to bag-of-words?¶
RNNs process tokens sequentially, but Transformers process all tokens at once.
In fact, we did not even provide any information about the order of tokens...
Positional Encoding¶
Represent positions with fixed-length vectors, with the same dimensionality as word embeddings:
(1st position, 2nd position, 3rd position, ...) $\to$ Must decide on maximum sequence length
Add to word embeddings at the input layer:

Positional Encoding¶
Alternatives:
- Learned position embeddings (like word embeddings)
- Static position encoding:

SNLI results with Self-Attention (Shen et al., 2018)¶
| Model | Accuracy |
|---|---|
| LSTM | 77.6 |
| LSTMs with conditional encoding | 80.9 |
| LSTMs with conditional encoding + attention | 82.3 |
| LSTMs with word-by-word attention | 83.5 |
| Self-attention | 85.6 |
Transformers for decoding¶
Attends to encoded input and to partial output.
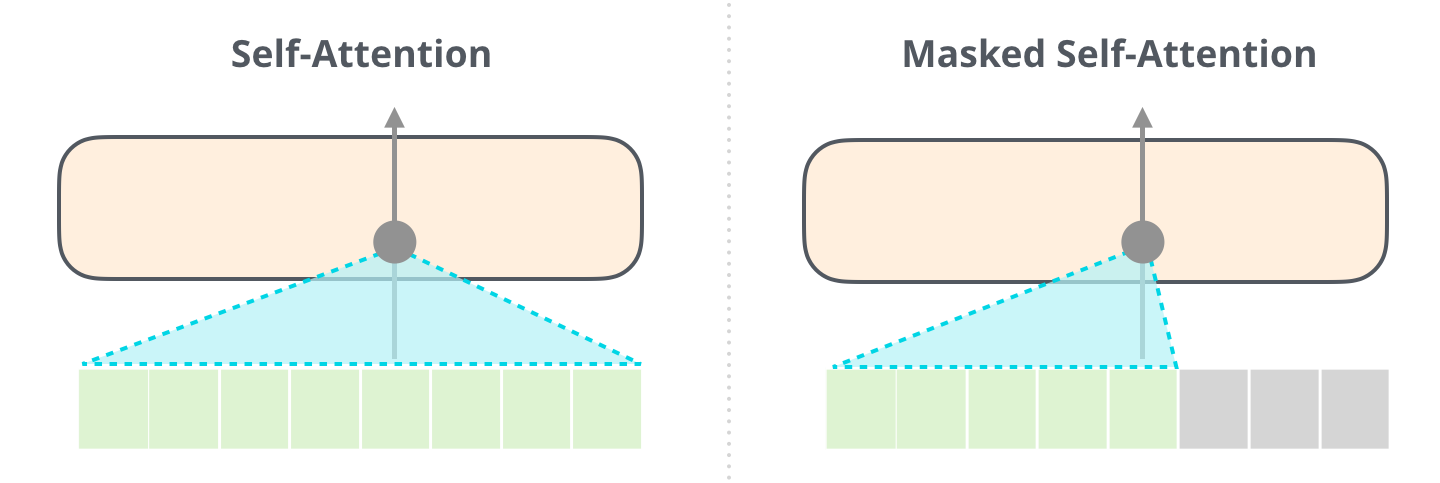
The encoder transformer is sometimes called "bidirectional transformer".

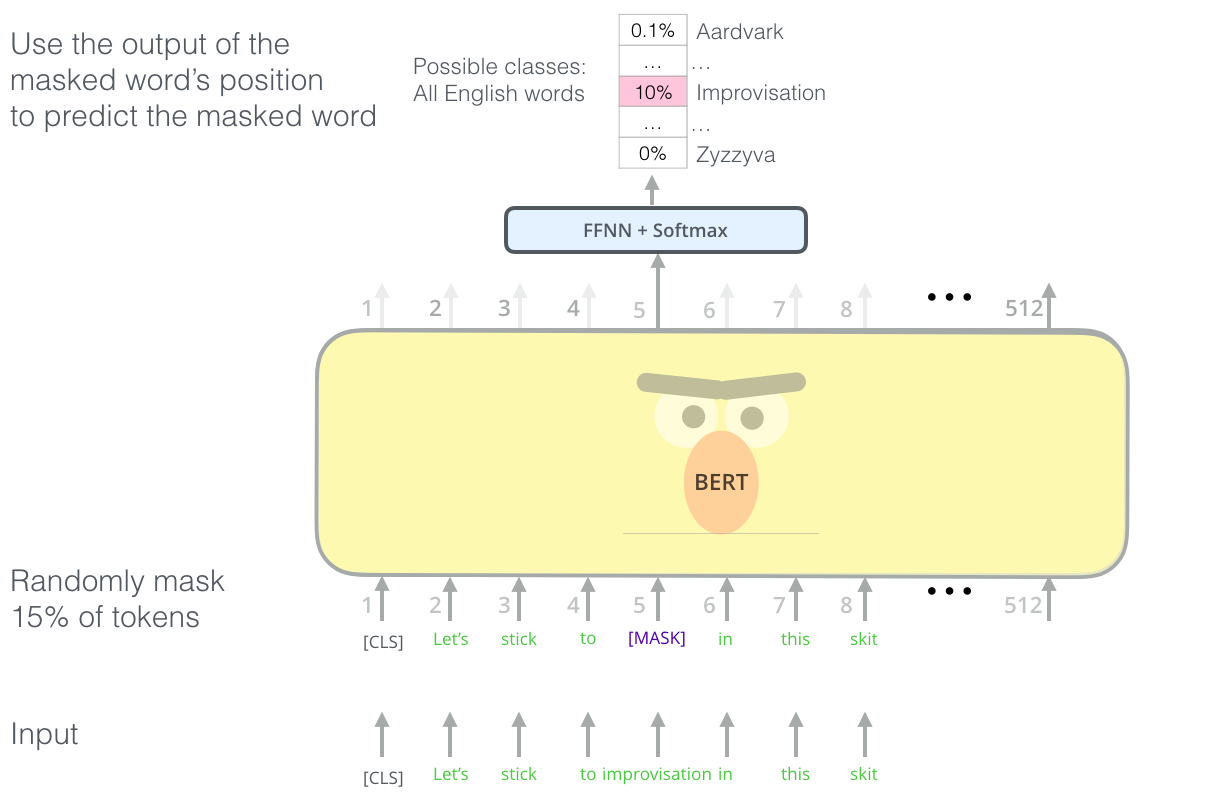
Reminder: BERT training objective (1): masked language model¶
Predict masked words given context on both sides:
Reminder: BERT Training objective (2): next sentence prediction¶
Conditional encoding of both sentences:

BERT architecture¶
Transformer with $L$ layers of dimension $H$, and $A$ self-attention heads.
- BERT$_\mathrm{BASE}$: $L=12, H=768, A=12$
- BERT$_\mathrm{LARGE}$: $L=24, H=1024, A=16$
(Many other variations available through HuggingFace Transformers)
Trained on 16GB of text from Wikipedia + BookCorpus.
- BERT$_\mathrm{BASE}$: 4 TPUs for 4 days
- BERT$_\mathrm{LARGE}$: 16 TPUs for 4 days
SNLI results¶
| Model | Accuracy |
|---|---|
| LSTM | 77.6 |
| LSTMs with conditional encoding | 80.9 |
| LSTMs with conditional encoding + attention | 82.3 |
| LSTMs with word-by-word attention | 83.5 |
| Self-attention | 85.6 |
| BERT$_\mathrm{BASE}$ | 89.2 |
| BERT$_\mathrm{LARGE}$ | 90.4 |
RoBERTa¶
Same architecture as BERT but better hyperparameter tuning and more training data (Liu et al., 2019):
- CC-News (76GB)
- OpenWebText (38GB)
- Stories (31GB)
and no next-sentence-prediction task (only masked LM).
Training: 1024 GPUs for one day.
SNLI results¶
| Model | Accuracy |
|---|---|
| LSTM | 77.6 |
| LSTMs with conditional encoding | 80.9 |
| LSTMs with conditional encoding + attention | 82.3 |
| LSTMs with word-by-word attention | 83.5 |
| Self-attention | 85.6 |
| BERT$_\mathrm{BASE}$ | 89.2 |
| BERT$_\mathrm{LARGE}$ | 90.4 |
| RoBERTa$_\mathrm{BASE}$ | 90.7 |
| RoBERTa$_\mathrm{LARGE}$ | 91.4 |
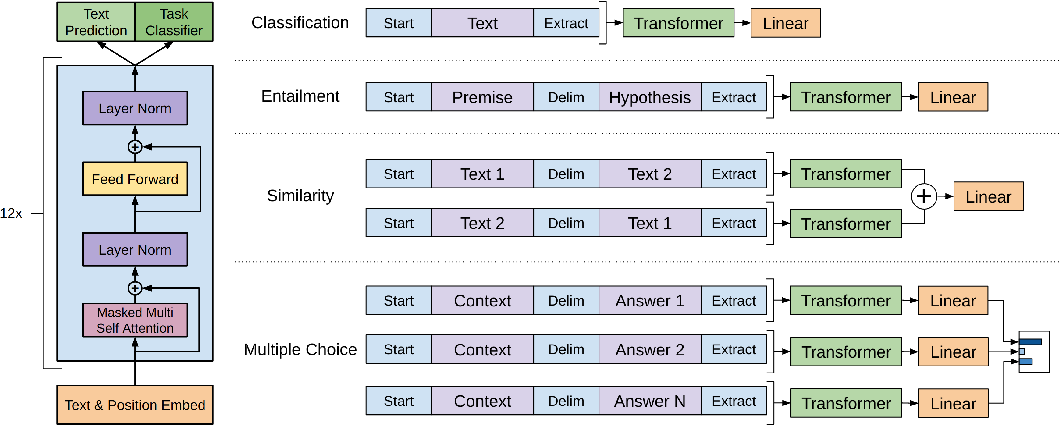


Using BERT (and friends) for NLI¶

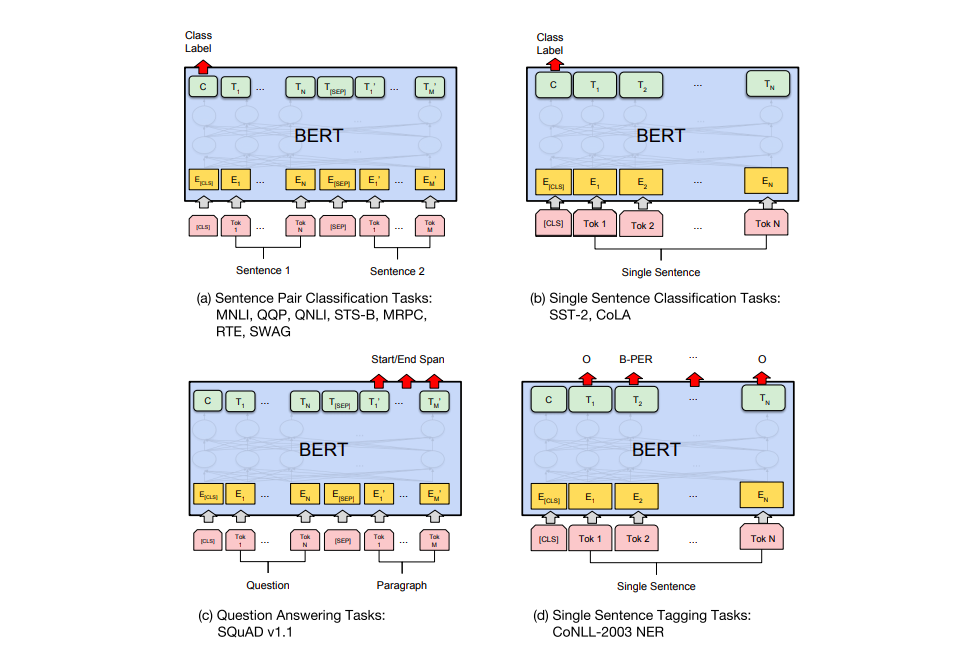
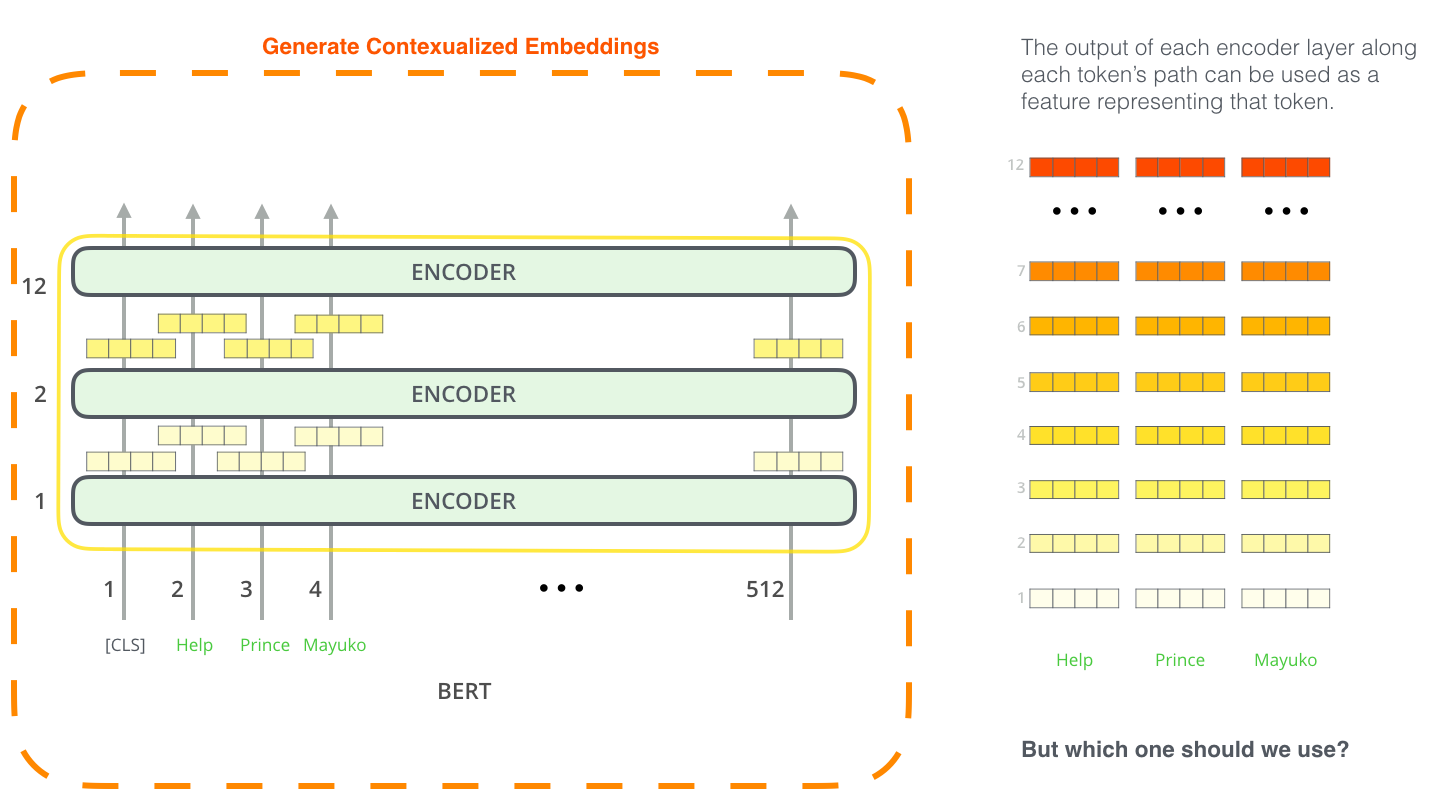
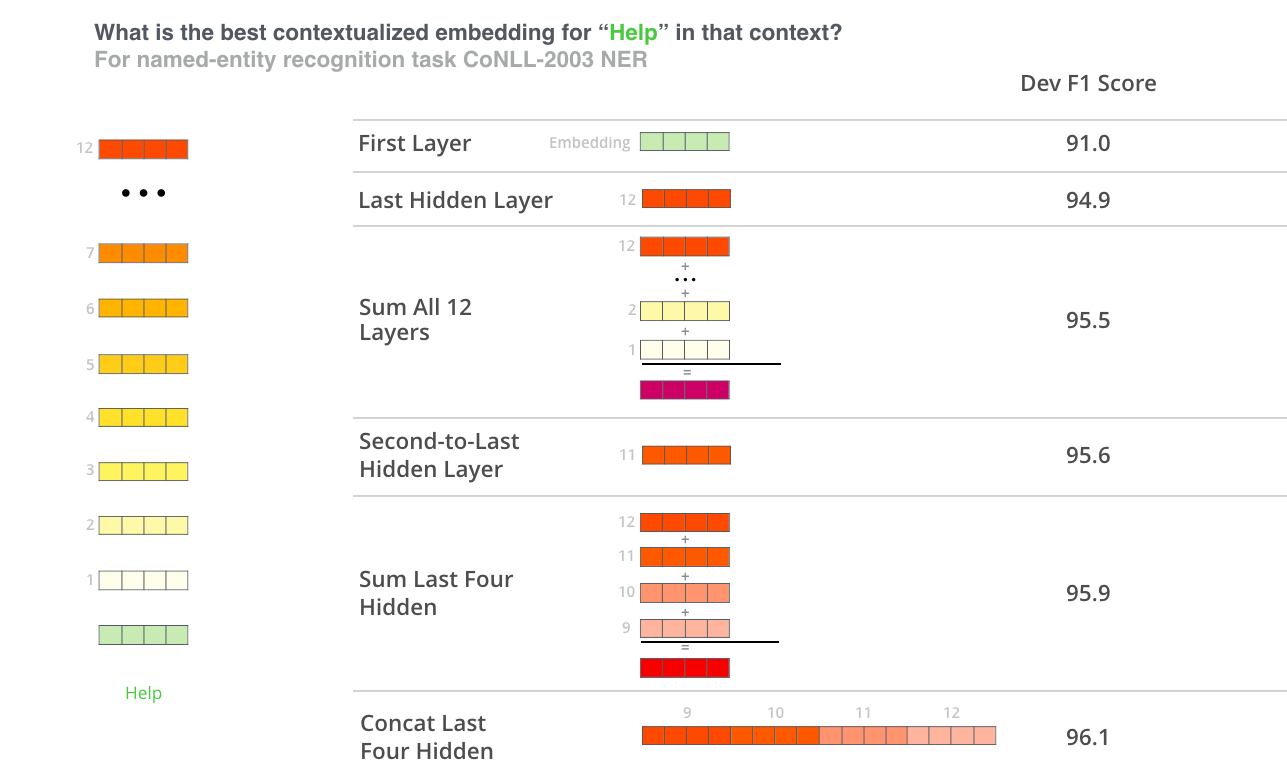
Multilingual BERT¶
- One model pre-trained on 104 languages with the largest Wikipedias
- 110k shared WordPiece vocabulary
- Same architecture as BERT$_\mathrm{BASE}$: $L=12, H=768, A=12$
- Same training objectives, no cross-lingual signal
https://github.com/google-research/bert/blob/master/multilingual.md
Other multilingual transformers¶
- XLM and XLM-R (Lample and Conneau, 2019)
- DistilmBERT (Sanh et al., 2020) is a lighter version of mBERT
- Many monolingual BERTs for languages other than English
(CamemBERT, BERTje, Nordic BERT...)
Outlook¶
- Transformer models keep coming out: larger, trained on more data, languages and domains, etc.
- Increasing energy usage and climate impact: see https://github.com/danielhers/climate-awareness-nlp
- In the machine translation lecture, you will learn how to use them for cross-lingual tasks
Additional Reading¶
- Jurafsky & Martin Chapter 11
- Jay Alammar's blog posts: