수업 보충 자료¶
12. E-learning 22, 23 보충 자료¶
- 보충 내용 없음
11. E-learning 21 보충 자료¶
- Python 에서 Java에서 문법적으로 제공되는 것과 비슷하게 abstract class를 생성할 수 있나?
- Python 문법 자체적으로 abstract class 지원하지 않음
- abc 모듈을 활용하여 abstract class 생성할 수 있음 (참고적으로만 알아둘 것)
- Python 에서 Java에서 문법적으로 제공되는 것과 비슷하게 interface를 생성할 수 있나?
- Python 문법 자체적으로 interface 지원하지 않음
- interface를 지우너하는 모듈도 존재하지 않음
10. E-learning 19, 20 보충 자료¶
- 보충 내용 없음
9. E-learning 17, 18 보충 자료¶
1) 전역공간과 지역공간 내 이름 알아내기-globals(), locals(), dir()¶
- globals(): 전역 이름(심볼 테이블) 및 해당 이름에 할당된 객체의 repr (또는 str) 형태를 사전으로 반환
- locals(): 지역 이름(심볼 테이블) 및 해당 이름에 할당된 객체의 repr (또는 str) 형태를 사전으로 반환
- 최상위 모듈 수준에서 위 두 함수는 동일한 결과를 반환
- dit(): 현재 이름 공간에 존재하는 이름 리스트 반환
In [1]:
print globals()
{'_dh': [u'/Users/yhhan/git/python-e-learning'], '_sh': <module 'IPython.core.shadowns' from '/Users/yhhan/Library/Enthought/Canopy_64bit/User/lib/python2.7/site-packages/IPython/core/shadowns.pyc'>, '_i1': u'print globals()', '_ii': u'', 'quit': <IPython.core.autocall.ZMQExitAutocall object at 0x105b23690>, '__builtins__': <module '__builtin__' (built-in)>, 'In': ['', u'print globals()'], '__builtin__': <module '__builtin__' (built-in)>, '_oh': {}, '_iii': u'', 'exit': <IPython.core.autocall.ZMQExitAutocall object at 0x105b23690>, 'get_ipython': <bound method ZMQInteractiveShell.get_ipython of <IPython.kernel.zmq.zmqshell.ZMQInteractiveShell object at 0x105b1a6d0>>, '__': '', '_ih': ['', u'print globals()'], '_i': u'', '__name__': '__main__', '___': '', '__doc__': 'Automatically created module for IPython interactive environment', '_': '', 'Out': {}}
In [2]:
print locals()
{'_dh': [u'/Users/yhhan/git/python-e-learning'], '__': '', '_i': u'print globals()', 'quit': <IPython.core.autocall.ZMQExitAutocall object at 0x105b23690>, '__builtins__': <module '__builtin__' (built-in)>, '_ih': ['', u'print globals()', u'print locals()'], '__builtin__': <module '__builtin__' (built-in)>, '__name__': '__main__', '___': '', '_': '', '_sh': <module 'IPython.core.shadowns' from '/Users/yhhan/Library/Enthought/Canopy_64bit/User/lib/python2.7/site-packages/IPython/core/shadowns.pyc'>, '_i2': u'print locals()', '_i1': u'print globals()', '__doc__': 'Automatically created module for IPython interactive environment', '_iii': u'', 'exit': <IPython.core.autocall.ZMQExitAutocall object at 0x105b23690>, 'get_ipython': <bound method ZMQInteractiveShell.get_ipython of <IPython.kernel.zmq.zmqshell.ZMQInteractiveShell object at 0x105b1a6d0>>, '_ii': u'', 'In': ['', u'print globals()', u'print locals()'], '_oh': {}, 'Out': {}}
In [3]:
x = 10
print globals().keys()
print dir()
['_dh', '__', '_i', 'quit', '__builtins__', '_ih', '__builtin__', '__name__', '___', '_', '_sh', '_i3', '_i2', '_i1', '__doc__', '_iii', 'exit', 'get_ipython', '_ii', 'In', 'x', '_oh', 'Out'] ['In', 'Out', '_', '__', '___', '__builtin__', '__builtins__', '__doc__', '__name__', '_dh', '_i', '_i1', '_i2', '_i3', '_ih', '_ii', '_iii', '_oh', '_sh', 'exit', 'get_ipython', 'quit', 'x']
In [4]:
print locals().keys()
['_dh', '__', '_i', 'quit', '__builtins__', '_ih', '__builtin__', '__name__', '___', '_', '_sh', '_i4', '_i3', '_i2', '_i1', '__doc__', '_iii', 'exit', 'get_ipython', '_ii', 'In', 'x', '_oh', 'Out']
In [7]:
a = 1
b = 2
def f():
localx = 10
localy = 20
print '함수 내에서 전역 이름:', globals().keys()
print
print '함수 내에서 지역 이름:', locals().keys()
f()
print
print '모듈 수준에서의 전역 이름:', globals().keys()
print
print '모듈 수준에서의 지역 이름:', locals().keys()
함수 내에서 전역 이름: ['_dh', '__', '_i', 'quit', '__builtins__', '_ih', '__builtin__', '__name__', '___', '_', 'a', '_sh', 'b', 'f', '_i7', '_i6', '_i5', '_i4', '_i3', '_i2', '_i1', '__doc__', '_iii', 'exit', 'get_ipython', '_ii', 'In', 'x', '_oh', 'Out'] 함수 내에서 지역 이름: ['localy', 'localx'] 모듈 수준에서의 전역 이름: ['_dh', '__', '_i', 'quit', '__builtins__', '_ih', '__builtin__', '__name__', '___', '_', 'a', '_sh', 'b', 'f', '_i7', '_i6', '_i5', '_i4', '_i3', '_i2', '_i1', '__doc__', '_iii', 'exit', 'get_ipython', '_ii', 'In', 'x', '_oh', 'Out'] 모듈 수준에서의 지역 이름: ['_dh', '__', '_i', 'quit', '__builtins__', '_ih', '__builtin__', '__name__', '___', '_', 'a', '_sh', 'b', 'f', '_i7', '_i6', '_i5', '_i4', '_i3', '_i2', '_i1', '__doc__', '_iii', 'exit', 'get_ipython', '_ii', 'In', 'x', '_oh', 'Out']
2) 특정 객체 내부에 지니고 있는 이름 알아보기¶
- dir(객체) : 이름 리스트 리스트 반환
- 객체.__dict__ : 이름 및 해당 이름에 할당된 객체의 repr (또는 str) 형태를 사전으로 지님
In [11]:
import string
print dir(string)
print string.__dict__.keys()
['Formatter', 'Template', '_TemplateMetaclass', '__builtins__', '__doc__', '__file__', '__name__', '__package__', '_float', '_idmap', '_idmapL', '_int', '_long', '_multimap', '_re', 'ascii_letters', 'ascii_lowercase', 'ascii_uppercase', 'atof', 'atof_error', 'atoi', 'atoi_error', 'atol', 'atol_error', 'capitalize', 'capwords', 'center', 'count', 'digits', 'expandtabs', 'find', 'hexdigits', 'index', 'index_error', 'join', 'joinfields', 'letters', 'ljust', 'lower', 'lowercase', 'lstrip', 'maketrans', 'octdigits', 'printable', 'punctuation', 'replace', 'rfind', 'rindex', 'rjust', 'rsplit', 'rstrip', 'split', 'splitfields', 'strip', 'swapcase', 'translate', 'upper', 'uppercase', 'whitespace', 'zfill'] ['ascii_lowercase', 'upper', '_re', 'letters', 'atol_error', 'lstrip', 'uppercase', 'ascii_letters', 'find', 'atof', 'replace', 'capwords', 'index_error', 'expandtabs', 'Template', 'strip', 'ascii_uppercase', 'octdigits', 'index', 'ljust', 'whitespace', '_int', 'rindex', '_float', 'punctuation', '__package__', 'printable', 'splitfields', 'split', 'rstrip', 'translate', '__doc__', '_multimap', 'count', 'joinfields', 'rjust', '__builtins__', '__file__', 'lower', 'swapcase', 'atof_error', 'atoi', 'hexdigits', 'Formatter', 'atol', '__name__', 'rsplit', '_idmapL', 'digits', 'lowercase', 'join', 'center', '_long', 'rfind', 'atoi_error', 'maketrans', 'capitalize', '_TemplateMetaclass', 'zfill', '_idmap']
In [17]:
for name, val in string.__dict__.items():
print 'name = %-20s, type = %s' % (name, type(val))
name = ascii_lowercase , type = <type 'str'> name = upper , type = <type 'function'> name = _re , type = <type 'module'> name = letters , type = <type 'str'> name = atol_error , type = <type 'type'> name = lstrip , type = <type 'function'> name = uppercase , type = <type 'str'> name = ascii_letters , type = <type 'str'> name = find , type = <type 'function'> name = atof , type = <type 'function'> name = replace , type = <type 'function'> name = capwords , type = <type 'function'> name = index_error , type = <type 'type'> name = expandtabs , type = <type 'function'> name = Template , type = <class 'string._TemplateMetaclass'> name = strip , type = <type 'function'> name = ascii_uppercase , type = <type 'str'> name = octdigits , type = <type 'str'> name = index , type = <type 'function'> name = ljust , type = <type 'function'> name = whitespace , type = <type 'str'> name = _int , type = <type 'type'> name = rindex , type = <type 'function'> name = _float , type = <type 'type'> name = punctuation , type = <type 'str'> name = __package__ , type = <type 'NoneType'> name = printable , type = <type 'str'> name = splitfields , type = <type 'function'> name = split , type = <type 'function'> name = rstrip , type = <type 'function'> name = translate , type = <type 'function'> name = __doc__ , type = <type 'str'> name = _multimap , type = <type 'classobj'> name = count , type = <type 'function'> name = joinfields , type = <type 'function'> name = rjust , type = <type 'function'> name = __builtins__ , type = <type 'dict'> name = __file__ , type = <type 'str'> name = lower , type = <type 'function'> name = swapcase , type = <type 'function'> name = atof_error , type = <type 'type'> name = atoi , type = <type 'function'> name = hexdigits , type = <type 'str'> name = Formatter , type = <type 'type'> name = atol , type = <type 'function'> name = __name__ , type = <type 'str'> name = rsplit , type = <type 'function'> name = _idmapL , type = <type 'NoneType'> name = digits , type = <type 'str'> name = lowercase , type = <type 'str'> name = join , type = <type 'function'> name = center , type = <type 'function'> name = _long , type = <type 'type'> name = rfind , type = <type 'function'> name = atoi_error , type = <type 'type'> name = maketrans , type = <type 'builtin_function_or_method'> name = capitalize , type = <type 'function'> name = _TemplateMetaclass , type = <type 'type'> name = zfill , type = <type 'function'> name = _idmap , type = <type 'str'>
3) 모듈의 재적재¶
- 이미 메모리에 적재되어 있는 모듈은 다시 import 하더라도 기존에 적재되어 있는 모듈이 그대로 다시 이용된다.
In [12]:
import mymath
mymath.mypi = 6.2 # 값 수정(원래 모듈 파일에 정의된 값은 3.14)
import mymath # 다시 import
print mymath.mypi # 3.14가 아니라 6.2 -> 즉 이미 적재되어 있는 모듈 그냥 이용
50.24 6.2
- reload(모듈)
- 메모리에 등록된 것과 관계없이 해당 모듈의 파일에서 새롭게 다시 메모리에 재적재 시키는 내장 함수
In [13]:
print mymath.mypi
reload(mymath)
print mymath.mypi
6.2 50.24 3.14
4) 윈도우즈/MAC/리눅스에서 편하게 PYTHONPATH 설정하기¶
- CMD 창 (터미널 창)에서 다음과 같이 수행
- set PYTHONPATH=C:\Python\Mymodules
8. E-learning 15, 16 보충 자료¶
1) 함수 정의시에 예상할 수 없는 키워드 인수 처리하기¶
- 함수를 정의할 때 예측할 수 없는 인수를 선언하여 사전 타입으로 그러한 인수를 받을 수 있다.
- 함수 정의시에 **var 형태의 인수 정의
In [10]:
def f(width, height, **kw):
print width, height
print kw
value = 0
for key in kw:
value += kw[key]
return value
print f(width=10, height=5, depth=10, diamension=3)
10 5
{'depth': 10, 'diamension': 3}
13
In [13]:
print f(10, 5, depth=10, diamension=3)
10 5
{'depth': 10, 'diamension': 3}
13
- 첫 두 개의 인수 다음에는 반드시 키워드 인수로만 함수 호출 가능
In [11]:
print f(width=10, height=5, 10, 3)
File "<ipython-input-11-840223010262>", line 1 print f(width=10, height=5, 10, 3) SyntaxError: non-keyword arg after keyword arg
In [12]:
print f(10, 5, 10, 3)
--------------------------------------------------------------------------- TypeError Traceback (most recent call last) <ipython-input-12-8900a8c061b7> in <module>() ----> 1 print f(10, 5, 10, 3) TypeError: f() takes exactly 2 arguments (4 given)
- 함수 선언시에 예상할 수 없는 키워드 인수는 맨 마지막에 선언해야 한다.
- 함수 선언시 인수 선언 나열 방법
- 일반 인수 -> 키워드 인수 -> 가변 인수 -> 예상치 못하는 키워드 인수
- 함수 선언시 인수 선언 나열 방법
In [18]:
def g(a, b, k = 1, *args, **kw):
print a, b
print args
print kw
g(1, 2, 3, 4, 5, c=6, d=7)
1 2
(4, 5)
{'c': 6, 'd': 7}
2) 함수 호출시에 사용 가능한 튜플 인수 및 사전 인수¶
- 함수 호출에 사용될 인수값들이 튜플에 있다면 "*튜플변수"를 이용하여 함수 호출이 가능
In [19]:
def h(a, b, c):
print a, b, c
args = (1, 2, 3)
h(*args)
1 2 3
- 함수 호출에 사용될 인수값들이 사전에 있다면 "**사전변수"를 이용하여 함수 호출이 가능
In [20]:
dargs = {'a':1, 'b':2, 'c':3}
h(**dargs)
1 2 3
- 튜플 인수와 사전 인수를 동시에 사용
In [21]:
args = (1,2)
dargs = {'c':3}
h(*args, **dargs)
1 2 3
3) Trivial 람다 함수 및 키워드 인수/가변 인수/예상치 못하는 키워드 인수를 지닌 람다 함수¶
In [23]:
lambda: 1
Out[23]:
<function __main__.<lambda>>
In [24]:
f = lambda: 1
f()
Out[24]:
1
In [25]:
vargs = lambda x, *args: args
print vargs(1, 2, 3, 4, 5)
(2, 3, 4, 5)
In [27]:
kwords = lambda x, y=1, *args, **kw: kw
kwords(1, 2, 3, 4, a=5, b=6)
Out[27]:
{'a': 5, 'b': 6}
4) 람다 함수 보충¶
- 다음 4가지 프로그램은 동일함
In [1]:
def f1(x):
return x*x + 3*x - 10
def f2(x):
return x*x*x
def g(func):
return [func(x) for x in range(-10, 10)]
print g(f1)
print g(f2)
[60, 44, 30, 18, 8, 0, -6, -10, -12, -12, -10, -6, 0, 8, 18, 30, 44, 60, 78, 98] [-1000, -729, -512, -343, -216, -125, -64, -27, -8, -1, 0, 1, 8, 27, 64, 125, 216, 343, 512, 729]
In [4]:
def g(func):
return [func(x) for x in range(-10, 10)]
print g(lambda x: x*x + 3*x - 10)
print g(lambda x: x*x*x)
[60, 44, 30, 18, 8, 0, -6, -10, -12, -12, -10, -6, 0, 8, 18, 30, 44, 60, 78, 98] [-1000, -729, -512, -343, -216, -125, -64, -27, -8, -1, 0, 1, 8, 27, 64, 125, 216, 343, 512, 729]
In [5]:
print [(lambda x: x*x + 3*x - 10)(x) for x in range(-10, 10)]
print [(lambda x: x*x*x)(x) for x in range(-10, 10)]
[60, 44, 30, 18, 8, 0, -6, -10, -12, -12, -10, -6, 0, 8, 18, 30, 44, 60, 78, 98] [-1000, -729, -512, -343, -216, -125, -64, -27, -8, -1, 0, 1, 8, 27, 64, 125, 216, 343, 512, 729]
In [7]:
print map(lambda x: x*x + 3*x - 10, range(-10, 10))
print map(lambda x: x*x*x, range(-10, 10))
[60, 44, 30, 18, 8, 0, -6, -10, -12, -12, -10, -6, 0, 8, 18, 30, 44, 60, 78, 98] [-1000, -729, -512, -343, -216, -125, -64, -27, -8, -1, 0, 1, 8, 27, 64, 125, 216, 343, 512, 729]
5) map 및 filter 함수 보충¶
- map함수에 시퀀스 자료형을 두 개 이상 할당할 수 있다.
- 시퀀스 자료형이 n개 이면 function의 인자도 n개 이어야 함
In [28]:
Y1 = map(lambda x, y: x + y, [1, 2, 3, 4, 5], [6, 7, 8, 9, 10])
Y2 = map(lambda x, y, z: x + y + z, [1, 2, 3], [4, 5, 6], [7, 8, 9])
print Y1
print Y2
[7, 9, 11, 13, 15] [12, 15, 18]
- 두 개 이상의 시퀀스 자료형들에 대해 map 함수를 사용하여 순서쌍 만들기
- function 인자를 None으로 할당
In [29]:
a = ['a', 'b', 'c', 'd']
b = [1, 2, 3, 4]
print map(None, a, b)
[('a', 1), ('b', 2), ('c', 3), ('d', 4)]
In [30]:
a = ['a', 'b', 'c', 'd']
b = [1, 2, 3, 4]
c = [5, 6, 7, 8]
print map(None, a, b, c)
[('a', 1, 5), ('b', 2, 6), ('c', 3, 7), ('d', 4, 8)]
- 두 개의 시퀀스 자료형의 원소의 개수가 다르면 부족한 원소에는 None을 할당
In [31]:
a = ['a', 'b']
b = [1, 2, 3, 4]
print map(None, a, b)
[('a', 1), ('b', 2), (None, 3), (None, 4)]
- 순서쌍을 만드는 전용 내장 함수 zip은 None을 추가하지 않고 짧은 인자를 기준으로 나머지는 버린다.
In [32]:
a = ['a', 'b']
b = [1, 2, 3, 4]
print zip(a, b)
[('a', 1), ('b', 2)]
In [33]:
print zip([1, 2, 3], [4, 5, 6, 7, 8])
[(1, 4), (2, 5), (3, 6)]
- filter의 첫 인자의 함수로서 None을 할당하면 seq 자료형에 있는 각 원소값 자체들을 평가하여 참인 것들만 필터링한다.
In [34]:
L = ['high', False, 'level', '', 'built-in', '', 'function', 0, 10]
L = filter(None, L)
print L
['high', 'level', 'built-in', 'function', 10]
6) 함수 객체의 속성¶
- 함수도 객체이며 속성을 지닌다.
- __doc__, func_doc: 문서 문자열
- __name__, func_name: 함수 이름
- func_defaults: 기본 인수 값들
In [35]:
def f(a, b, c=1):
'func attribute testing'
localx = 1
localy = 2
return 1
In [42]:
print f.__doc__ # 문서 문자열
print f.func_doc
print
print f.__name__ # 함수의 이름
print f.func_name
print
print f.func_defaults # 기본 인수값들
func attribute testing func attribute testing f f (1,)
7. E-learning 13, 14 보충 자료¶
- 해법 1
In [22]:
f = open('supplement.ipynb')
print len(f.read())
f.close()
70112
- 해법 2
In [23]:
import os
os.path.getsize('supplement.ipynb')
Out[23]:
70112
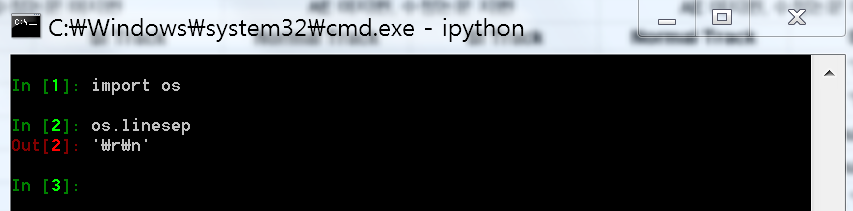
- 윈도우즈에서 만든 파일에 위 예제들을 수행하면 os.path.getsize('t.txt')가 라인수만큼 더 큼
- 이유
- 리눅스와 Mac에서는 라인 구분 제어 문자로 '\012' 한 문자를 사용
- 윈도우즈에서는 라인을 구분하는 제어 문자로 '\015\012' 두 개의 문자를 사용함
- 이유
In [24]:
import os
os.linesep
Out[24]:
'\n'
- 해법 1
In [4]:
f = open('supplement.ipynb')
s = f.read()
n = len(s.split())
print n
f.close()
7748
- 해법 2
In [5]:
n = len(open('supplement.ipynb').read().split())
print n
7748
- 해법 1
In [15]:
f = open('supplement.ipynb')
s = f.read()
print s.count('\n')
f.close()
2685
- 해법 2
In [16]:
f = open('supplement.ipynb')
print len(f.readlines())
f.close()
2685
- 해법 3
In [17]:
print open('supplement.ipynb').read().count('\n')
2685
- 해법 4
In [18]:
print len(open('supplement.ipynb').readlines())
2685
4) 다양한 파일 처리 모드¶
- open 내장 함수의 두번째 인자 mode 설명
- 두번째 인자 mode 생략시에는 읽기 전용(r) 모드로 설정
| Mode | 간단 설명 | 자세한 설명 |
|---|---|---|
| 'r' | 읽기 전용(기본 모드) | 파일 객체를 읽기 모드로 생성하고, 파일 포인터를 파일 처음 위치에 놓는다. |
| 'w' | 쓰기 전용(기존 파일 내용 삭제) | 파일이 존재하지 않으면 새로운 파일을 쓰기 모드로 생성하고, 해당 파일이 이미 존재하면 내용을 모두 없에면서 쓰기 모드로 생성하고, 파일 포인터를 파일 처음 위치에 놓는다. |
| 'a' | 파일 끝에 추가(쓰기 전용) | 파일이 존재하지 않으면 새롭게 파일을 생성하면서 쓰기 모드로 생성하고, 해당 파일이 이미 존재하면 파일 객체을 쓰기 모드로 생성하면서 파일 포인터를 파일의 마지막 위치에 놓는다 (그래서, 이후 작성되는 내용은 파일의 뒷 부분에 추가). |
| 'r+' | 읽고 쓰기 | 파일 객체를 읽고 쓸 수 있도록 생성한다. 파일 포인터를 파일 처음 위치에 놓는다. |
| 'w+' | 읽고 쓰기(기존 파일 내용 삭제) | 파일 객체를 읽고 쓸 수 있도록 생성한다. 파일이 존재하지 않으면 새로운 파일을 생성하고, 해당 파일이 이미 존재하면 내용을 모두 없에면서 생성하고, 파일 포인터를 파일 처음 위치에 놓는다. |
| 'a+' | 읽고 쓰기(파일 끝에 추가) | 파일 객체를 읽고 쓸 수 있도록 생성한다. 파일이 존재하지 않으면 새롭게 파일을 생성하고, 해당 파일이 이미 존재하면 파일 객체을 생성하면서 파일 포인터를 파일의 마지막 위치에 놓는다 (그래서, 이후 작성되는 내용은 파일의 뒷 부분에 추가). |
- 이진 파일로 저장을 위해서는 아래 모드 사용
| Mode | 간단 설명 |
|---|---|
| 'rb' | 이진 파일 읽기 전용 |
| 'wb' | 이진 파일 쓰기 전용(기존 파일 내용 삭제) |
| 'ab' | 이진 파일 끝에 추가(쓰기 전용) |
| 'rb+' | 이진 파일 읽고 쓰기 |
| 'wb+' | 이진 파일 읽고 쓰기(기존 파일 내용 삭제) |
| 'ab+' | 이진 파일 끝에 추가(읽기도 가능) |
6. E-learning 11, 12 보충 자료¶
1) 프로그램 예제¶
- 100개의 소문자를 랜덤하게 생성하여 출력한다.
- 생성된 각 소문자의 개수를 카운트하여 출력한다.
In [7]:
import random
def getRandomLowerCaseLetter():
return chr(random.randint(ord('a'), ord('z')))
def createList():
'''
소문자를 랜덤하게 생성하여 담은 리스트를 반환한다.
'''
chars = []
for i in range(100):
chars.append(getRandomLowerCaseLetter())
#위 코드는 아래 코드와 동일
#chars = [getRandomLowerCaseLetter() for i in range(100)]
return chars
def displayList(chars):
'''
리스트에 포함된 문자를 한 행에 20개씩 출력한다.
'''
for i in range(len(chars)):
if (i + 1) % 20 == 0:
print chars[i]
else:
print chars[i],
def countLetters(chars):
'''
0으로 초기화된 26개의 정수리스트를 생성한 후 인자로 주어진 chars에 있는 각 문자들의 개수를 저장한다.
'''
counts = [0] * 26
for i in range(len(chars)):
counts[ord(chars[i]) - ord('a')] += 1
return counts
def displayCounts(counts):
'''
각 문자별로 카운트를 한 행에 10개씩 출력한다.
'''
for i in range(len(counts)):
if (i + 1) % 10 == 0:
print chr(i + ord('a')), counts[i]
else:
print chr(i + ord('a')), counts[i],
if __name__ == '__main__':
chars = createList()
displayList(chars)
print
counts = countLetters(chars)
displayCounts(counts)
b j h i w a r g l w d g d q c y x n f d s j i w z q y c r z v w u t v p g j r x f o w q r x f i y g q z q a u i u u d q m e i v g l k h u g h g t a f i d k b f t g x z o n y r z m z t w f y d r h e g a 3 b 2 c 2 d 6 e 2 f 6 g 9 h 4 i 6 j 3 k 2 l 2 m 2 n 2 o 2 p 1 q 6 r 6 s 1 t 4 u 5 v 3 w 6 x 4 y 5 z 6
2) 집합의 성능¶
In [20]:
import random
import time
NUMBER_OF_ELEMENTS = 10000
lst = list(range(NUMBER_OF_ELEMENTS))
random.shuffle(lst)
s = set(lst)
# 해당 원소가 집합/리스트에 포함되어 있는지 검사
startTime = time.time()
for i in range(NUMBER_OF_ELEMENTS):
i in s
endTime = time.time()
runTime = int((endTime - startTime) * 1000)
print runTime, "ms"
startTime = time.time()
for i in range(NUMBER_OF_ELEMENTS):
i in lst
endTime = time.time()
runTime = int((endTime - startTime) * 1000)
print runTime, "ms"
# 해당 원소를 집합/리스트로 부터 제거
startTime = time.time()
for i in range(NUMBER_OF_ELEMENTS):
s.remove(i)
endTime = time.time()
runTime = int((endTime - startTime) * 1000)
print runTime, "ms"
startTime = time.time()
for i in range(NUMBER_OF_ELEMENTS):
lst.remove(i)
endTime = time.time()
runTime = int((endTime - startTime) * 1000)
print runTime, "ms"
2 ms 933 ms 1 ms 410 ms
3) 단어 세기¶
- 다음 주어진 문자열 s에서 ,와 .을 제거하고
- 모든 문자를 소문자로 변경하고
- 각각의 단어의 출현 빈도를 출력하시오.
In [3]:
# -*-coding:utf-8 -*-
s = "We propose to start by making it possible to teach progra\
mming in python, an existing scripting language, and to focus \
on creating a new development enviroment and teaching \
materials for it."
# 대치 과정
s=s.replace(',','')
s=s.replace('.','')
s=s.lower()
#공백 단위로 단어 쪼개고 단어 넣을 딕셔너리 선언
listSplited = s.split()
words = {}
#단어 쪼개놓은 리스트에서 각각 단어의 개수 세기
for i in listSplited:
if not i in dicWords.keys():
words[i]=1
else:
words[i]=dicWords[i]+1
#포맷을 이용한 출력
format = "%s : %d"
for i in dicWords:
print format % (i, words[i])
and : 3 it : 3 existing : 2 in : 2 for : 2 start : 2 enviroment : 2 to : 4 new : 2 development : 2 we : 2 creating : 2 python : 2 propose : 2 possible : 2 focus : 2 teaching : 2 teach : 2 an : 2 by : 2 a : 2 on : 2 language : 2 programming : 2 materials : 2 making : 2 scripting : 2
5. E-learning 9, 10 보충 자료¶
1) 리스트를 배열처럼 활용하기¶
- 1차원 배열처럼 활용하기
In [8]:
a = [1, 2, 3, 4, 5]
b = range(10)
print a
print a[0]
print b
print b[1]
[1, 2, 3, 4, 5] 1 [0, 1, 2, 3, 4, 5, 6, 7, 8, 9] 1
- 0으로 초기화된 사이즈 10인 1차원 배열 생성
In [9]:
a = [0] * 10
a
Out[9]:
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
- 2차원 배열처럼 활용하기
In [10]:
mat = [ [1, 2, 3],
[4, 5, 6],
[7, 8, 9] ]
print mat
print mat[1][2]
[[1, 2, 3], [4, 5, 6], [7, 8, 9]] 6
2) 리스트 내포¶
다음은 고등학교 수학에서 배운 집합의 표기 방법이다.
- A = {x^2 | x in {0, ..., 9}}
- B = {1, 2, 4, 8, 16, ..., 2^16}
- C = {x | x in S and x is odd}
파이썬의 리스트 내포(list comprehension)는 바로 위 집합 표기법과 유사한 방식의 리터럴이다.
위 집합들을 리스트 내포 방식으로 표현하면 다음과 같다.
- A = [x**2 for x in range(10)]
- B = [2**i for i in range(17)]
- C = [x for x in S if x % 2 == 1]
- 예 1. 피타고라스 삼각형의 각 3변의 길이 리스트 (각 변의 길이는 30 보다 작아야 함)
In [1]:
[(x,y,z) for x in range(1,30) for y in range(x,30) for z in range(y,30) if x**2 + y**2 == z**2]
Out[1]:
[(3, 4, 5), (5, 12, 13), (6, 8, 10), (7, 24, 25), (8, 15, 17), (9, 12, 15), (10, 24, 26), (12, 16, 20), (15, 20, 25), (20, 21, 29)]
- 예 2. 중첩 리스트 내포
In [2]:
list_a = ['A', 'B']
list_b = ['C', 'D']
print [x+y for x in list_a for y in list_b]
print
print [[x+y for x in list_a] for y in list_b]
['AC', 'AD', 'BC', 'BD'] [['AC', 'BC'], ['AD', 'BD']]
- 위 예제의 마지막 코드는 아래와 동일하다.
In [3]:
l = []
for y in list_b:
l2 = []
for x in list_a:
l2.append(x+y)
l.append(l2)
print l
[['AC', 'BC'], ['AD', 'BD']]
- 예 3. 리스트 내포를 활용한 2차원 배열 생성
In [11]:
mat = [ [0]*4 for x in range(3)]
print mat
mat[0][0] = 100
print mat
[[0, 0, 0, 0], [0, 0, 0, 0], [0, 0, 0, 0]] [[100, 0, 0, 0], [0, 0, 0, 0], [0, 0, 0, 0]]
3) 특별 속성¶
- 특별 속성: 파이썬 내에 존재하는 모든 객체 마다 부여되는 특별한 Read-only 속성
In [4]:
print __name__ # 로컬 이름
print
print __doc__ # 로컬에 지정된 문서문자열
print
__main__ Automatically created module for IPython interactive environment
In [5]:
import math
print "math.__name__: ", math.__name__
print
print dir(math) # dir() 내장 함수에 모듈을 인자로 전달하면 해당 모듈이 지원하는 멤버 변수 및 함수 목록을 얻는다.
print
print "math.__doc__:", math.__doc__
print
print "math.log10.__doc__: ", math.log10.__doc__
math.__name__: math ['__doc__', '__file__', '__name__', '__package__', 'acos', 'acosh', 'asin', 'asinh', 'atan', 'atan2', 'atanh', 'ceil', 'copysign', 'cos', 'cosh', 'degrees', 'e', 'erf', 'erfc', 'exp', 'expm1', 'fabs', 'factorial', 'floor', 'fmod', 'frexp', 'fsum', 'gamma', 'hypot', 'isinf', 'isnan', 'ldexp', 'lgamma', 'log', 'log10', 'log1p', 'modf', 'pi', 'pow', 'radians', 'sin', 'sinh', 'sqrt', 'tan', 'tanh', 'trunc'] math.__doc__: This module is always available. It provides access to the mathematical functions defined by the C standard. math.log10.__doc__: log10(x) Return the base 10 logarithm of x.
4) 명령행 인수¶
In [ ]:
# file: arg.py
import sys
print sys.argv
In [ ]:
# python arg.py -l -a -v a b c
5) [참고] numpy 모듈을 활용한 배열 생성¶
- 여러가지 종류의 배열 생성 가능
- 배열 자체에 많은 산술 연산을 효과적으로 처리 가능
- 선형대수에 관한 각종 수학적 연산을 효과적으로 지원
In [14]:
from numpy import *
a = array(((1,2,3), (4,5,6), (7, 8, 9))) # 3*3 행렬 생성
print a
print
b = zeros((3,3))
print b
print
c = ones((3,3))
print c
print
[[1 2 3] [4 5 6] [7 8 9]] [[ 0. 0. 0.] [ 0. 0. 0.] [ 0. 0. 0.]] [[ 1. 1. 1.] [ 1. 1. 1.] [ 1. 1. 1.]]
- 배열 자체에 산술 연산을 효과적으로 처리 가능
In [18]:
f = a + c # 각 원소들끼리의 덧셈
print f
print
d = a * a # 각 원소들끼리의 곱셈
print d
print
e = dot(a, c) # 일반적인 행렬 곱셈
print e
print
[[ 2. 3. 4.] [ 5. 6. 7.] [ 8. 9. 10.]] [[ 1 4 9] [16 25 36] [49 64 81]] [[ 6. 6. 6.] [ 15. 15. 15.] [ 24. 24. 24.]]
- 선형대수에 관한 각종 수학적 연산을 효과적으로 지원
In [16]:
from numpy.linalg import *
g = inv(a)
print g
print
h = eig(a)
print h
print
[[ -4.50359963e+15 9.00719925e+15 -4.50359963e+15]
[ 9.00719925e+15 -1.80143985e+16 9.00719925e+15]
[ -4.50359963e+15 9.00719925e+15 -4.50359963e+15]]
(array([ 1.61168440e+01, -1.11684397e+00, -1.30367773e-15]), array([[-0.23197069, -0.78583024, 0.40824829],
[-0.52532209, -0.08675134, -0.81649658],
[-0.8186735 , 0.61232756, 0.40824829]]))
4. E-learning 7, 8 보충 자료¶
1) unicode 추가 설명¶
In [7]:
a = unicode("한글과 세종대왕", 'utf-8')
b = u"한글과 세종대왕"
In [9]:
print a == b
print a is b
True False
In [23]:
print ord('A') # ord(): 문자의 ASCII 코드값 반환
print chr(65) # char(): ASCII 코드 65를 지니는 문자를 반환
65 A
In [27]:
print unichr(0xac00) # unichr(): UNICODE 코드 0xac00를 지니는 문자를 반환
print unichr(44032)
가 가
In [29]:
i = 0
while i < 1000:
print unichr(0xac00 + i),
i = i + 1
가 각 갂 갃 간 갅 갆 갇 갈 갉 갊 갋 갌 갍 갎 갏 감 갑 값 갓 갔 강 갖 갗 갘 같 갚 갛 개 객 갞 갟 갠 갡 갢 갣 갤 갥 갦 갧 갨 갩 갪 갫 갬 갭 갮 갯 갰 갱 갲 갳 갴 갵 갶 갷 갸 갹 갺 갻 갼 갽 갾 갿 걀 걁 걂 걃 걄 걅 걆 걇 걈 걉 걊 걋 걌 걍 걎 걏 걐 걑 걒 걓 걔 걕 걖 걗 걘 걙 걚 걛 걜 걝 걞 걟 걠 걡 걢 걣 걤 걥 걦 걧 걨 걩 걪 걫 걬 걭 걮 걯 거 걱 걲 걳 건 걵 걶 걷 걸 걹 걺 걻 걼 걽 걾 걿 검 겁 겂 것 겄 겅 겆 겇 겈 겉 겊 겋 게 겍 겎 겏 겐 겑 겒 겓 겔 겕 겖 겗 겘 겙 겚 겛 겜 겝 겞 겟 겠 겡 겢 겣 겤 겥 겦 겧 겨 격 겪 겫 견 겭 겮 겯 결 겱 겲 겳 겴 겵 겶 겷 겸 겹 겺 겻 겼 경 겾 겿 곀 곁 곂 곃 계 곅 곆 곇 곈 곉 곊 곋 곌 곍 곎 곏 곐 곑 곒 곓 곔 곕 곖 곗 곘 곙 곚 곛 곜 곝 곞 곟 고 곡 곢 곣 곤 곥 곦 곧 골 곩 곪 곫 곬 곭 곮 곯 곰 곱 곲 곳 곴 공 곶 곷 곸 곹 곺 곻 과 곽 곾 곿 관 괁 괂 괃 괄 괅 괆 괇 괈 괉 괊 괋 괌 괍 괎 괏 괐 광 괒 괓 괔 괕 괖 괗 괘 괙 괚 괛 괜 괝 괞 괟 괠 괡 괢 괣 괤 괥 괦 괧 괨 괩 괪 괫 괬 괭 괮 괯 괰 괱 괲 괳 괴 괵 괶 괷 괸 괹 괺 괻 괼 괽 괾 괿 굀 굁 굂 굃 굄 굅 굆 굇 굈 굉 굊 굋 굌 굍 굎 굏 교 굑 굒 굓 굔 굕 굖 굗 굘 굙 굚 굛 굜 굝 굞 굟 굠 굡 굢 굣 굤 굥 굦 굧 굨 굩 굪 굫 구 국 굮 굯 군 굱 굲 굳 굴 굵 굶 굷 굸 굹 굺 굻 굼 굽 굾 굿 궀 궁 궂 궃 궄 궅 궆 궇 궈 궉 궊 궋 권 궍 궎 궏 궐 궑 궒 궓 궔 궕 궖 궗 궘 궙 궚 궛 궜 궝 궞 궟 궠 궡 궢 궣 궤 궥 궦 궧 궨 궩 궪 궫 궬 궭 궮 궯 궰 궱 궲 궳 궴 궵 궶 궷 궸 궹 궺 궻 궼 궽 궾 궿 귀 귁 귂 귃 귄 귅 귆 귇 귈 귉 귊 귋 귌 귍 귎 귏 귐 귑 귒 귓 귔 귕 귖 귗 귘 귙 귚 귛 규 귝 귞 귟 균 귡 귢 귣 귤 귥 귦 귧 귨 귩 귪 귫 귬 귭 귮 귯 귰 귱 귲 귳 귴 귵 귶 귷 그 극 귺 귻 근 귽 귾 귿 글 긁 긂 긃 긄 긅 긆 긇 금 급 긊 긋 긌 긍 긎 긏 긐 긑 긒 긓 긔 긕 긖 긗 긘 긙 긚 긛 긜 긝 긞 긟 긠 긡 긢 긣 긤 긥 긦 긧 긨 긩 긪 긫 긬 긭 긮 긯 기 긱 긲 긳 긴 긵 긶 긷 길 긹 긺 긻 긼 긽 긾 긿 김 깁 깂 깃 깄 깅 깆 깇 깈 깉 깊 깋 까 깍 깎 깏 깐 깑 깒 깓 깔 깕 깖 깗 깘 깙 깚 깛 깜 깝 깞 깟 깠 깡 깢 깣 깤 깥 깦 깧 깨 깩 깪 깫 깬 깭 깮 깯 깰 깱 깲 깳 깴 깵 깶 깷 깸 깹 깺 깻 깼 깽 깾 깿 꺀 꺁 꺂 꺃 꺄 꺅 꺆 꺇 꺈 꺉 꺊 꺋 꺌 꺍 꺎 꺏 꺐 꺑 꺒 꺓 꺔 꺕 꺖 꺗 꺘 꺙 꺚 꺛 꺜 꺝 꺞 꺟 꺠 꺡 꺢 꺣 꺤 꺥 꺦 꺧 꺨 꺩 꺪 꺫 꺬 꺭 꺮 꺯 꺰 꺱 꺲 꺳 꺴 꺵 꺶 꺷 꺸 꺹 꺺 꺻 꺼 꺽 꺾 꺿 껀 껁 껂 껃 껄 껅 껆 껇 껈 껉 껊 껋 껌 껍 껎 껏 껐 껑 껒 껓 껔 껕 껖 껗 께 껙 껚 껛 껜 껝 껞 껟 껠 껡 껢 껣 껤 껥 껦 껧 껨 껩 껪 껫 껬 껭 껮 껯 껰 껱 껲 껳 껴 껵 껶 껷 껸 껹 껺 껻 껼 껽 껾 껿 꼀 꼁 꼂 꼃 꼄 꼅 꼆 꼇 꼈 꼉 꼊 꼋 꼌 꼍 꼎 꼏 꼐 꼑 꼒 꼓 꼔 꼕 꼖 꼗 꼘 꼙 꼚 꼛 꼜 꼝 꼞 꼟 꼠 꼡 꼢 꼣 꼤 꼥 꼦 꼧 꼨 꼩 꼪 꼫 꼬 꼭 꼮 꼯 꼰 꼱 꼲 꼳 꼴 꼵 꼶 꼷 꼸 꼹 꼺 꼻 꼼 꼽 꼾 꼿 꽀 꽁 꽂 꽃 꽄 꽅 꽆 꽇 꽈 꽉 꽊 꽋 꽌 꽍 꽎 꽏 꽐 꽑 꽒 꽓 꽔 꽕 꽖 꽗 꽘 꽙 꽚 꽛 꽜 꽝 꽞 꽟 꽠 꽡 꽢 꽣 꽤 꽥 꽦 꽧 꽨 꽩 꽪 꽫 꽬 꽭 꽮 꽯 꽰 꽱 꽲 꽳 꽴 꽵 꽶 꽷 꽸 꽹 꽺 꽻 꽼 꽽 꽾 꽿 꾀 꾁 꾂 꾃 꾄 꾅 꾆 꾇 꾈 꾉 꾊 꾋 꾌 꾍 꾎 꾏 꾐 꾑 꾒 꾓 꾔 꾕 꾖 꾗 꾘 꾙 꾚 꾛 꾜 꾝 꾞 꾟 꾠 꾡 꾢 꾣 꾤 꾥 꾦 꾧 꾨 꾩 꾪 꾫 꾬 꾭 꾮 꾯 꾰 꾱 꾲 꾳 꾴 꾵 꾶 꾷 꾸 꾹 꾺 꾻 꾼 꾽 꾾 꾿 꿀 꿁 꿂 꿃 꿄 꿅 꿆 꿇 꿈 꿉 꿊 꿋 꿌 꿍 꿎 꿏 꿐 꿑 꿒 꿓 꿔 꿕 꿖 꿗 꿘 꿙 꿚 꿛 꿜 꿝 꿞 꿟 꿠 꿡 꿢 꿣 꿤 꿥 꿦 꿧
2) str()과 repr()의 차이¶
- str(): 객체의 비공식적인 (informal) 문자열 표현 - 가능하면 읽기 편하게...
- repr(): 객체의 공식적인 (official) 문자열 표현 - 가능하면 실제 객체를 완벽하게 표현할 수 있도록...
- [참고] http://pinocc.tistory.com/168
In [10]:
f = 1.23456789123456789
print f
print str(f)
print repr(f) # repr()은 유효 숫자를 길게 출력
1.23456789123 1.23456789123 1.234567891234568
In [16]:
print "%s, %r" % (f, f) # str()과 repr() 호출
1.23456789123, 1.234567891234568
In [17]:
print "%s -- %s" % ((1, 2), [3, 4, 5]) # str() 호출
(1, 2) -- [3, 4, 5]
In [13]:
print "%r -- %r" % ((1, 2), [3, 4, 5]) # str() 대신에 repr() 내장 함수 사용
(1, 2) -- [3, 4, 5]
In [18]:
g = 0.3
print str(g)
print repr(g)
0.3 0.3
In [19]:
h = 'Hello'
print str(h)
print repr(h)
Hello 'Hello'
In [20]:
x = eval(str(h))
--------------------------------------------------------------------------- NameError Traceback (most recent call last) <ipython-input-20-282822699c67> in <module>() ----> 1 x = eval(str(h)) <string> in <module>() NameError: name 'Hello' is not defined
- repr() 내장함수에 의하여 반환된 문자열은 eval() 내장함수에 의하여 interpret 가 가능함
In [22]:
x = eval(repr(h))
3) 문서 문자열 (Documentation String, docstring)¶
In [30]:
def add(a, b):
"add(a, b) returns a+b"
return a + b
In [31]:
print add.__doc__
add(a, b) returns a+b
In [32]:
help(add)
Help on function add in module __main__:
add(a, b)
add(a, b) returns a+b
In [34]:
add?
4) string 모듈 상수¶
In [35]:
import string
print string.digits
print string.octdigits
print string.hexdigits
print string.letters
print string.lowercase
print string.uppercase
print string.punctuation # 각종 기호들
print
print string.printable # 인쇄 가능한 모든 문자들
print string.whitespace # 공백 문자들 '\011\012\013\014\015'
0123456789
01234567
0123456789abcdefABCDEF
ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz
abcdefghijklmnopqrstuvwxyz
ABCDEFGHIJKLMNOPQRSTUVWXYZ
!"#$%&'()*+,-./:;<=>?@[\]^_`{|}~
0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ!"#$%&'()*+,-./:;<=>?@[\]^_`{|}~
In [36]:
x = 'a'
print x in string.uppercase
print x in string.lowercase
False True
In [37]:
d = string.letters + string.digits
print d
ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789
In [38]:
userid = raw_input('your id:')
your id:ab#
In [39]:
d = string.letters + string.digits
for ch in userid:
if ch not in d:
print 'invalid user id'
break
invalid user id
5) 문자열 붙이기 코딩 방법 비교 (중요)¶
In [42]:
import time
start_time = time.time()
s = ''
for k in range(1000000):
s += 'python'
end_time = time.time()
print end_time - start_time
0.243875980377
In [43]:
start_time = time.time()
t = []
for k in range(1000000):
t.append('python')
s = ''.join(t)
end_time = time.time()
print end_time - start_time
0.161774158478
In [44]:
start_time = time.time()
s = 'python' * 1000000
end_time = time.time()
print end_time - start_time
0.000773191452026
3. E-learning 5, 6 보충 자료¶
1) 비트연산자¶
- ~ : 비트 반전 (보수)
- <<: 왼쪽으로 비트 이동
- a << b: a * 2 ** b 와 동일
- >>: 오른쪽으로 비트 이동
- a >> b: a / 2 ** b 와 동일
- & : 비트 단위 AND
- | : 비트 단위 OR
- ^ : 비트 단위 XOR
In [19]:
import math
def bitcounter(n):
return math.floor(math.log(n,2)) + 1
In [20]:
a = 3 # "0000 0011"
print a.bit_length() # 해당 수치를 표현하기 위한 비트의 개수를 반환
print bin(a) # 해당 수치를 2진수로 변환
2 0b11
In [21]:
b = a << 2 # "0000 1100", 오른쪽에는 0으로 채워짐 (a * 2 ** 2 와 동일)
print b
print b.bit_length()
print bin(b)
12 4 0b1100
In [22]:
print 1 << 128 # 1 * 2 ** 128 과 동일 (롱형으로 자동변환)
340282366920938463463374607431768211456
In [23]:
c = 4 # "0000 0100"
print c >> 1 # "0000 0010", 왼쪽에도 0으로 채워짐, 4 / 2 ** 1과 동일
d = 16
print d >> 3 # 16 / 2 ** 3과 동일
2 2
- [참고] 2의 보수법으로 음수를 메모리에 표현하는 방법
In [24]:
e = -4 # "1111 1100"
print e >> 1 # "1111 1110", 음수의 경우 왼쪽에는 1로 채워짐
-2
- Exclusive OR (XOR)
- 서로 같은 비트이면 False
- 서로 다른 비트이면 True
In [25]:
f = 3
print f & 2 #0000 0011 bit_and 0000 0010 = 0000 0010
print f | 8 #0000 0011 bit_or 0000 1000 = 0000 1011
print 0x0f ^ 0x06 #0000 1111 exclusive_or 0000 0110 = 0000 1001
2 11 9
2) 코드 학습: 시각 다루기¶
- Unix Epoch: 1970년 1월 1일 0시
In [26]:
import time
currentTime = time.time() # Unix Epoch 부터 현재까지 경과된 시각을 GMT/UST 기준 및 ms 단위로 얻어온다.
print currentTime
totalSeconds = int(currentTime) # 1970년 1월 1일 0시 이후부터 현재시각까지의 전체 초 값을 얻어온다.
print "totalSeconds -", totalSeconds
currentSecond = totalSeconds % 60 # 현재 시각의 초 값을 얻어온다.
totalMinutes = totalSeconds // 60 # 전체 분 값을 계산한다.
print "totalMinutes -", totalMinutes
currentMinute = totalMinutes % 60 # 현재 시각의 분 값을 얻어온다.
totalHours = totalMinutes // 60 # 전체 시 값을 계산한다.
print "totalHours -", totalHours
currentHours = totalHours % 24 # 현재 시각의 시 값을 얻어온다.
print "현재 시각은", currentHours, ":", currentMinute, ":", currentSecond, "GMT 입니다."
1442926438.95 totalSeconds - 1442926438 totalMinutes - 24048773 totalHours - 400812 현재 시각은 12 : 53 : 58 GMT 입니다.
- 대한민국의 Time Zone 및 로컬타임 얻기
In [27]:
print time.tzname
print
localtime = time.localtime()
print localtime
('KST', 'KST')
time.struct_time(tm_year=2015, tm_mon=9, tm_mday=22, tm_hour=21, tm_min=53, tm_sec=59, tm_wday=1, tm_yday=265, tm_isdst=0)
- 대한민국의 Time Zone 및 GMT/UST Time Zone 사이의 Offset 얻어오기
In [28]:
print localtime.tm_hour - currentHours
9
3) 코드 학습: 숫자 맞추기 게임 소스¶
In [29]:
# This is a guess the number game.
import random
guessesTaken = 0
print('Hello! What is your name?')
myName = raw_input()
number = random.randint(1, 20) # return random integer in range [a, b], including both end points.
print('Well, ' + myName + ', I am thinking of a number between 1 and 20.')
while guessesTaken < 6:
print('Take a guess.')
guess = int(input())
guessesTaken = guessesTaken + 1
if guess < number:
print('Your guess is too low.')
if guess > number:
print('Your guess is too high.')
if guess == number:
break
if guess == number:
guessesTaken = str(guessesTaken)
print('Good job, ' + myName + '! You guessed my number in ' + guessesTaken + ' guesses!')
if guess != number:
number = str(number)
print('Nope. The number I was thinking of was ' + number)
Hello! What is your name? Youn-Hee Han Well, Youn-Hee Han, I am thinking of a number between 1 and 20. Take a guess. 7 Your guess is too low. Take a guess. 10 Your guess is too low. Take a guess. 15 Your guess is too low. Take a guess. 17 Your guess is too low. Take a guess. 19 Your guess is too low. Take a guess. 20 Good job, Youn-Hee Han! You guessed my number in 6 guesses!
4) [참고] turtle 모듈 활용하기¶
In [1]:
import turtle
t = turtle.Turtle()
t.pensize(3) # 펜 사이즈를 3으로 설정한다.
t.penup() # 펜을 종이로 부터 들어올린다.
t.goto(-200, -50) # 해당 좌표로 이동한다.
t.pendown() # 펜을 종이에 놓는다.
t.circle(40, steps=3) # 반지름이 40인 원을 3 step으로만 그린다. ==> 삼각형이 그려짐
t.penup()
t.goto(-100, -50)
t.pendown()
t.circle(40, steps=4)
t.penup()
t.goto(0, -50)
t.pendown()
t.circle(40, steps=5)
t.penup()
t.goto(100, -50)
t.pendown()
t.circle(40, steps=6)
t.penup()
t.goto(200, -50)
t.pendown()
t.circle(40, steps=40)
Turtle의 펜 그리기 상태 메소드
| 메소드 명 | 설명 |
|---|---|
| turtle.pendown() | 펜을 내려놓는다 - 움직일 때 그려진다. |
| turtle.penup() | 펜을 들어올린다 - 움직일 때 그려지지 않는다. |
| turtle.pensize() | 선의 두께를 특정 폭으로 설정한다. |
Turtle의 이동 메소드
메소드 명 |
설명 |
|---|---|
| turtle.forward(d) | turtle이 향하고 있는 방향으로 특정 거리 d만큼 앞으로 이동시킨다. |
| turtle.backward(d) | turtle이 향하고 있는 반대 방향으로 특정 거리 d만큼 뒤로 이동시킨다. turtle의 방향은 바뀌지 않는다. |
| turtle.right(angle) | turtle을 특정 각만큼 오른쪽으로 회전시킨다. |
| turtle.left(angle) | turtle을 특정 각만큼 왼쪽으로 회전시킨다. |
| turtle.goto(x,y) | turtle을 절대 위치 (x,y)로 옮긴다. |
| turtle.setx(x) | turtle의 x 좌표를 특정 위치로 옮긴다. |
| turtle.setx(y) | turtle의 y 좌표를 특정 위치로 옮긴다. |
| turtle.setheading(angle) | 특정 각도로 turtle의 방향을 설정한다. 0-동쪽, 90-북쪽, 180-서쪽, 270-남쪽. |
| turtle.home() | turtle을 원점 (0,0)으로 옮기고 동쪽 방향으로 설정한다. |
| turtle.circle(r, ext, steps) | 특정 반지름 r, 경계 ext와 단계 step인 원을 그린다. |
| turtle.dot(diameter, color) | 특정 지름 diameter와 색상 color인 원을 그린다. |
| turtle.undo() | turtle의 마지막 명령을 (반복적으로)되돌린다. |
| turtle.speed(s) | 1부터 10사이의 정수(10이 최대) s로 turtle의 속도를 설정한다. |
Turtle 펜 색상, 채우기와 그리기 메소드
메소드 명 |
설명 |
|---|---|
| turtle.color(c) | 펜 색상을 c로 설정한다. |
| turtle.fillcolor(c) | 펜 채우기 색상을 c로 설정한다. |
| turtle.begin_fill() | 도형을 채우기 전에 이 메소드를 호출한다. |
| turtle.end_fill() | begin_fill에 대한 마지막 호출전까지 그려진 도형을 채운다. |
| turtle.filling() | 채우기 상태를 반환한다. 채우기 상태이면 True, 그렇지 않으면 False |
| turtle.clear() | 창을 깨끗하게 지운다. turtle의 상태와 위치는 영향을 받지 않는다. |
| turtle.reset() | 창을 깨끗하게 지우고 turtle의 상태와 위치를 원래 기본값으로 재설정한다. |
| turtle.screensize(w,h) | 캔버스의 폭과 높이를 w와 h로 설정한다. |
| turtle.hideturtle() | turtle을 보이지 않게 만든다. |
| turtle.showturtle() | turtle을 보이게 만든다. |
| turtle.isvisible() | turtle이 보이면 True를 반환한다. |
| turtle.write(s,font=("Arial",8,"normal")) | 현재 turtle의 위치에 문자열 s를 쓴다. 폰트는 폰트명, 폰트크기, 폰트유형의 세 값으로 구성된다. |
2. E-learning 3, 4 보충 자료¶
1) 파이썬에서 지원하는 각종 타입들 알아보기¶
In [10]:
import types
dir(types)
Out[10]:
['BooleanType', 'BufferType', 'BuiltinFunctionType', 'BuiltinMethodType', 'ClassType', 'CodeType', 'ComplexType', 'DictProxyType', 'DictType', 'DictionaryType', 'EllipsisType', 'FileType', 'FloatType', 'FrameType', 'FunctionType', 'GeneratorType', 'GetSetDescriptorType', 'InstanceType', 'IntType', 'LambdaType', 'ListType', 'LongType', 'MemberDescriptorType', 'MethodType', 'ModuleType', 'NoneType', 'NotImplementedType', 'ObjectType', 'SliceType', 'StringType', 'StringTypes', 'TracebackType', 'TupleType', 'TypeType', 'UnboundMethodType', 'UnicodeType', 'XRangeType', '__builtins__', '__doc__', '__file__', '__name__', '__package__']
In [11]:
print type(123) is types.IntType
print type(123.0) is types.FloatType
print type('abc') is types.StringType
print type([]) is types.ListType
print type(()) is types.TupleType
print type({}) is types.DictionaryType
True True True True True True
2) 레퍼런스 카운트 (Reference Count)와 쓰레기 수집 (Garbage Collection)¶
In [12]:
x = y = z = 100

In [13]:
del x

In [14]:
y = 200
z = 300
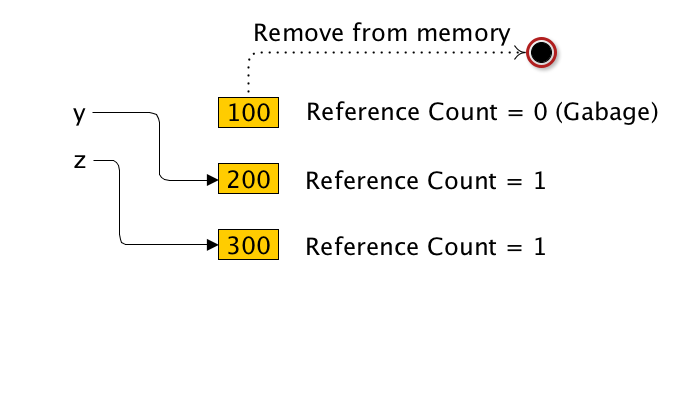
- 레퍼런스 카운트를 얻는 법
- sys 모듈의 getrefcount() 함수: 본 함수가 작업 처리를 하기 위해 원래 레퍼런스 값보다 1 큰 값을 반환함
In [15]:
import sys
a1 = 191919
print sys.getrefcount(a1) # 새로운 191919 객체를 만들고 이 객체에 대한 reference count 반환
a2 = 191919
print sys.getrefcount(a2) # 역시 새로운 191919 객체를 만들고 이 객체에 대한 reference count 반환
print
a3 = a1
print sys.getrefcount(a3) # a1이 참조하는 객체를 a3가 동시에 참조함
print sys.getrefcount(a1) # a1과 a3가 참조하는 객체는 동일하며, reference count는 기존보다 1이 증가되어 있음
print sys.getrefcount(a2) # a2는 여전히 reference count가 이전 값과 동일함
print
aa1 = aa2 = aa3 = 202020
print sys.getrefcount(aa1)
print sys.getrefcount(aa2)
print sys.getrefcount(aa3)
print
b1 = object()
print sys.getrefcount(b1)
b2 = object()
print sys.getrefcount(b2)
print
print sys.getrefcount('foobar')
3 3 4 4 3 5 5 5 2 2 3
3) 연습문제¶
- int 형 객체 1에 대해 다음 예제를 살펴보고 위 예제와 결과가 왜 다른지 생각해 보시오.
In [16]:
a1 = 1
print sys.getrefcount(a1)
a2 = 1
print sys.getrefcount(a2)
print
a3 = a1
print sys.getrefcount(a3)
print sys.getrefcount(a1)
print sys.getrefcount(a2)
print
1805 1804 1805 1805 1805
다음 사항을 읽고 요구하는 프로그램을 작성하시오.
정다각형은 모든 변의 길이와 내각의 크기가 같은 $n$개의 변으로 이루어진 다각형이다 (즉, 다각형이 등변이고 등각이다).
한변의 길이가 $s$일 때 정다각형의 넓이를 계산하는 공식은 다음과 같다.
- $정다각형의 넓이 = (n \times s^2) / (4 \times tan(\pi / n))$
사용자로 부터 정다각형의 변의 개수와 변의 길이를 입력받고 정다각형의 넓이를 출력하는 프로그램을 작성하시오.
출력예는 다음과 같다.
[출력예]
변의 개수를 입력하세요: 5 변의 길이를 입력하세요: 6.5 다각형의 넓이는 73.69017017488385 입니다.
In [17]:
n = input("변의 개수를 입력하세요: ")
s = input("변의 길이를 입력하세요: ")
area = (n*s*s)/(4*math.tan(math.pi/n))
print "다각형의 넓이는 "+str(area)+" 입니다."
변의 개수를 입력하세요: 4 변의 길이를 입력하세요: 4 다각형의 넓이는 16.0 입니다.
다음 사항을 읽고 요구하는 프로그램을 작성하시오.
사용자로 부터 ASCII 코드 (0부터 127 사이의 정수)를 입력받는다.
입력받은 코드에 대한 문자를 출력하는 프로그램을 작성하시오.
출력예는 다음과 같다.
[출력예]
ASCII코드를 입력하세요: 69 문자는 E 입니다.
In [18]:
code = input("ASCII코드를 입력하세요: ")
print "문자는 "+chr(code) +" 입니다."
ASCII코드를 입력하세요: 69 문자는 E 입니다.
1. E-learning 1, 2 보충 자료¶
1) 현재 이름 공간에 있는 이름 리스트 출력¶
dir() 내장 함수 사용
- 리턴형: 리스트
아래 리스트 중 python 기본 이름
- __builtin__
- __doc__
- __name__
- __package__
나머지는 ipython이 자체적으로 생성한 이름들
- 단순 이름만 출력: dir()
- 리턴형: 리스트
In [1]:
dir()
Out[1]:
['In', 'Out', '_', '__', '___', '__builtin__', '__builtins__', '__doc__', '__name__', '_dh', '_i', '_i1', '_ih', '_ii', '_iii', '_oh', '_sh', 'exit', 'get_ipython', 'quit']
2) 특정 객체가 지니고 있는 이름 리스트 출력¶
In [2]:
a = 10
print dir(a)
['__abs__', '__add__', '__and__', '__class__', '__cmp__', '__coerce__', '__delattr__', '__div__', '__divmod__', '__doc__', '__float__', '__floordiv__', '__format__', '__getattribute__', '__getnewargs__', '__hash__', '__hex__', '__index__', '__init__', '__int__', '__invert__', '__long__', '__lshift__', '__mod__', '__mul__', '__neg__', '__new__', '__nonzero__', '__oct__', '__or__', '__pos__', '__pow__', '__radd__', '__rand__', '__rdiv__', '__rdivmod__', '__reduce__', '__reduce_ex__', '__repr__', '__rfloordiv__', '__rlshift__', '__rmod__', '__rmul__', '__ror__', '__rpow__', '__rrshift__', '__rshift__', '__rsub__', '__rtruediv__', '__rxor__', '__setattr__', '__sizeof__', '__str__', '__sub__', '__subclasshook__', '__truediv__', '__trunc__', '__xor__', 'bit_length', 'conjugate', 'denominator', 'imag', 'numerator', 'real']
In [3]:
print dir(__builtin__)
['ArithmeticError', 'AssertionError', 'AttributeError', 'BaseException', 'BufferError', 'BytesWarning', 'DeprecationWarning', 'EOFError', 'Ellipsis', 'EnvironmentError', 'Exception', 'False', 'FloatingPointError', 'FutureWarning', 'GeneratorExit', 'IOError', 'ImportError', 'ImportWarning', 'IndentationError', 'IndexError', 'KeyError', 'KeyboardInterrupt', 'LookupError', 'MemoryError', 'NameError', 'None', 'NotImplemented', 'NotImplementedError', 'OSError', 'OverflowError', 'PendingDeprecationWarning', 'ReferenceError', 'RuntimeError', 'RuntimeWarning', 'StandardError', 'StopIteration', 'SyntaxError', 'SyntaxWarning', 'SystemError', 'SystemExit', 'TabError', 'True', 'TypeError', 'UnboundLocalError', 'UnicodeDecodeError', 'UnicodeEncodeError', 'UnicodeError', 'UnicodeTranslateError', 'UnicodeWarning', 'UserWarning', 'ValueError', 'Warning', 'ZeroDivisionError', '__IPYTHON__', '__IPYTHON__active', '__debug__', '__doc__', '__import__', '__name__', '__package__', 'abs', 'all', 'any', 'apply', 'basestring', 'bin', 'bool', 'buffer', 'bytearray', 'bytes', 'callable', 'chr', 'classmethod', 'cmp', 'coerce', 'compile', 'complex', 'copyright', 'credits', 'delattr', 'dict', 'dir', 'divmod', 'dreload', 'enumerate', 'eval', 'execfile', 'file', 'filter', 'float', 'format', 'frozenset', 'get_ipython', 'getattr', 'globals', 'hasattr', 'hash', 'help', 'hex', 'id', 'input', 'int', 'intern', 'isinstance', 'issubclass', 'iter', 'len', 'license', 'list', 'locals', 'long', 'map', 'max', 'memoryview', 'min', 'next', 'object', 'oct', 'open', 'ord', 'pow', 'print', 'property', 'range', 'raw_input', 'reduce', 'reload', 'repr', 'reversed', 'round', 'set', 'setattr', 'slice', 'sorted', 'staticmethod', 'str', 'sum', 'super', 'tuple', 'type', 'unichr', 'unicode', 'vars', 'xrange', 'zip']
3) 파이썬 버전 및 모듈들이 존재할 수 있는 패스 알아보기¶
In [4]:
import sys
print sys.version
print
print sys.path
2.7.9 | 64-bit | (default, Jun 30 2015, 22:40:22) [GCC 4.1.2 20080704 (Red Hat 4.1.2-55)] ['', '/home/goslim/Canopy/appdata/canopy-1.5.5.3123.rh5-x86_64/lib/python27.zip', '/home/goslim/Canopy/appdata/canopy-1.5.5.3123.rh5-x86_64/lib/python2.7', '/home/goslim/Canopy/appdata/canopy-1.5.5.3123.rh5-x86_64/lib/python2.7/plat-linux2', '/home/goslim/Canopy/appdata/canopy-1.5.5.3123.rh5-x86_64/lib/python2.7/lib-tk', '/home/goslim/Canopy/appdata/canopy-1.5.5.3123.rh5-x86_64/lib/python2.7/lib-old', '/home/goslim/Canopy/appdata/canopy-1.5.5.3123.rh5-x86_64/lib/python2.7/lib-dynload', '/home/goslim/Enthought/Canopy_64bit/User/lib/python2.7/site-packages', '/home/goslim/Canopy/appdata/canopy-1.5.5.3123.rh5-x86_64/lib/python2.7/site-packages', '/home/goslim/Enthought/Canopy_64bit/User/lib/python2.7/site-packages/IPython/extensions']
In [5]:
print dir(sys)
['__displayhook__', '__doc__', '__excepthook__', '__name__', '__package__', '__stderr__', '__stdin__', '__stdout__', '_clear_type_cache', '_current_frames', '_getframe', '_home', '_mercurial', 'api_version', 'argv', 'base_exec_prefix', 'base_prefix', 'builtin_module_names', 'byteorder', 'call_tracing', 'callstats', 'copyright', 'displayhook', 'dont_write_bytecode', 'exc_clear', 'exc_info', 'exc_type', 'excepthook', 'exec_prefix', 'executable', 'exit', 'exitfunc', 'flags', 'float_info', 'float_repr_style', 'getcheckinterval', 'getdefaultencoding', 'getdlopenflags', 'getfilesystemencoding', 'getprofile', 'getrecursionlimit', 'getrefcount', 'getsizeof', 'gettrace', 'hexversion', 'long_info', 'maxint', 'maxsize', 'maxunicode', 'meta_path', 'modules', 'path', 'path_hooks', 'path_importer_cache', 'platform', 'prefix', 'ps1', 'ps2', 'ps3', 'py3kwarning', 'setcheckinterval', 'setdlopenflags', 'setprofile', 'setrecursionlimit', 'settrace', 'stderr', 'stdin', 'stdout', 'subversion', 'version', 'version_info', 'warnoptions']
4) 연습문제¶
- 다음은 math 모듈을 가져오는 코딩이다. math 모듈을 가져온 후 math 모듈에 정의된 함수를 이용하여 -4.3 값을 반올림한 후 절대값을 취하는 코딩을 한 줄로 완성하라.
In [6]:
import math
In [7]:
math.fabs(round(-4.3))
Out[7]:
4.0
- 다음은 두 점의 좌표 (x1, y1), (x3, y2)를 나타내는 변수 값들이다. math 모듈에 정의된 함수를 이용하여 이 두 점 사이의 거리를 구하는 식을 한 줄로 완성하라.
In [8]:
x1 = 10
y1 = 20
x2 = 30
y2 = 40
In [9]:
math.sqrt(math.pow(x1-x2,2)+math.pow(y1-y2,2))
Out[9]:
28.284271247461902