Getting data from HTML¶
HTML stands for "hypertext markup language." Most of the documents you see when you're browsing the web are written in this format. Our goal today is to discuss and put into practice basic methods for extracting data from documents written in HTML.
In most browsers, there's a "View Source" option that allows you to see the HTML source code for any page you're looking at. For example, in Chrome, you can CTRL-click anywhere on the page, or go to View > Developer > View Source:
You'll see something that looks like this, a mish-mash of angle brackets and quotes and slashes and text. This is HTML.

What HTML looks like¶
HTML consists of a series of tags. Tags have a name, a series of key/value pairs called attributes, and some textual content. Attributes are optional. Here's a simple example, using the HTML <p> tag (p means "paragraph"):
<p>Mother said there'd be days like these.</p>
This example has just one tag in it: a <p> tag. The source code for a tag has two parts, its opening tag (<p>) and its closing tag (</p>). In between the opening and closing tag, you see the tag's contents (in this case, the text Mother said there'd be days like these.).
Here's another example, using the HTML <div> tag:
<div class="header" style="background: blue;">Mammoth Falls</div>
In this example, the tag's name is div. The tag has two attributes: class, with value header, and style, with value background: blue;. The contents of this tag is Mammoth Falls.
Tags can contain other tags, in a hierarchical relationship. For example, here's some HTML to make a bulletted list:
<ul>
<li>Item one</li>
<li>Item two</li>
<li>Item three</li>
</ul>
The <ul> tag (ul stands for "unordered list") in this example has three other <li> tags inside of it (li stands for "list item"). The <ul> tag is said to be the "parent" of the <li> tags, and the <li> tags are the "children" of the <ul> tag. All tags grouped under a particular parent tag are called "siblings."
HTML's shortcomings¶
HTML documents are intended to add "markup" to text to add information that allows browsers to display the text in different ways---e.g., HTML markup might tell the browser to make the font of the text a particular size, or to position it in a particular place on the screen.
Because the primary purpose of HTML is to change the appearance of text, HTML markup usually does not tell us anything useful about what the text means, or what kind of data it contains. When you look at a web page in the browser, it might appear to contain a list of newspaper articles, or a table with birth rates, or a series of names with associated biographies, or whatever. But that's information that we get, as humans, from reading the page. There's (usually) no easy way to extract this information with a computer program.
HTML is also notoriously messy---web browsers are very forgiving of syntax errors and other irregularities in HTML (like mismatched or unclosed tags). (This is in contrast to data formats like JSON, where even small errors will fail to be parsed.) For this reason, we need special libraries to parse HTML into data structures that our Python programs can use, libraries that can make a "good guess" about what the structure of an HTML document is, even when that structure is written incorrectly or inconsistently.
Beautiful Soup is a Python library that parses HTML (even if it's poorly formatted) and allows us to extract and manipulate its contents. We'll be using this library in the examples that follow.
Keep in mind that there are only sketchy rules for what HTML elements "mean"---semantic information you figure out for one web page might not apply to the next. Values for class attributes especially are meaningful only in the context of a single page.
Note: There's an effort to add semantic information to HTML markup called HTML Microformats. If sites added microformats to their markup, you'd be able to write code that could more reliably extract information from web pages, because there would be a common language for what tags with particular classes and attributes mean. Alas, microformats remain unpopular, and until the anarcho-collectivists win a greater mindshare, we can count only on our own individual readings of individual HTML documents.
Inspecting HTML's anatomy with Developer Tools¶
I've crafted a very simple example of HTML for us to work with. It concerns kittens. Here's the rendered version, and here's the HTML source code.
Now we're going to use Developer Tools in Chrome to take a look at how kittens.html is organized. Click on the "rendered version" link above. In Chrome, ctrl-click (or right click) anywhere on the page and select "Inspect Element." This will open Chrome's Developer Tools. Your screen should look (something) like this:
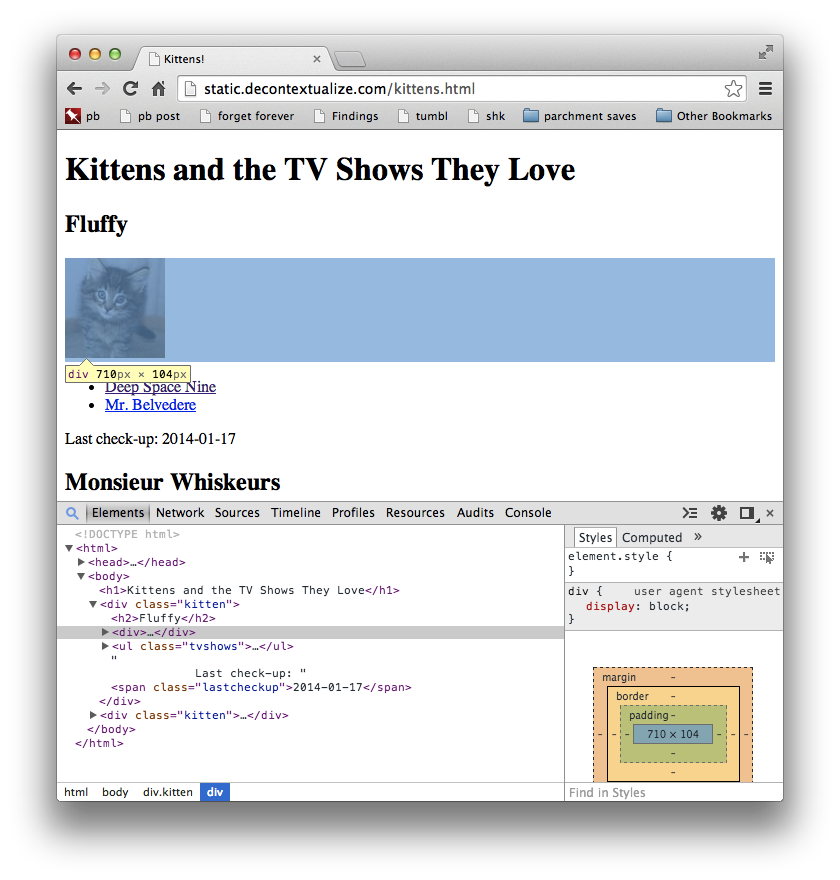
In the upper panel, you see the web page you're inspecting. In the lower panel, you see a version of the HTML source code, with little arrows next to some of the lines. (The little arrows allow you to collapse parts of the HTML source that are hierarchically related.) As you move your mouse over the elements in the top panel, different parts of the source code will be highlighted. Chrome is showing you which parts of the source code are causing which parts of the page to show up. Pretty spiffy!
This relationship also works in reverse: you can move your mouse over some part of the source code in the lower panel, which will highlight in the top panel what that source code corresponds to on the page. We'll be using this later to visually identify the parts of the page that are interesting to us, so we can write code that extracts the contents of those parts automatically.
Characterizing the structure of kittens¶
Here's what the source code of kittens.html looks like:
<!doctype html>
<html>
<head>
<title>Kittens!</title>
</head>
<body>
<h1>Kittens and the TV Shows They Love</h1>
<div class="kitten">
<h2>Fluffy</h2>
<div><img src="http://placekitten.com/100/100"></div>
<ul class="tvshows">
<li><a href="http://www.imdb.com/title/tt0106145/">Deep Space Nine</a></li>
<li><a href="http://www.imdb.com/title/tt0088576/">Mr. Belvedere</a></li>
</ul>
Last check-up: <span class="lastcheckup">2014-01-17</span>
</div>
<div class="kitten">
<h2>Monsieur Whiskeurs</h2>
<div><img src="http://placekitten.com/150/100"></div>
<ul class="tvshows">
<li><a href="http://www.imdb.com/title/tt0106179/">The X-Files</a></li>
<li><a href="http://www.imdb.com/title/tt0098800/">Fresh Prince</a></li>
</ul>
Last check-up: <span class="lastcheckup">2013-11-02</span>
</div>
</body>
</html>
This is pretty well organized HTML, but if you don't know how to read HTML, it will still look like a big jumble. Here's how I would characterize the structure of this HTML, reading in my own idea of what the meaning of the elements are.
- We have two "kittens," both of which are contained in
<div>tags with classkitten. - Each "kitten"
<div>has an<h2>tag with that kitten's name. - There's an image for each kitten, specified with an
<img>tag. - Each kitten has a list (a
<ul>with classtvshows) of television shows, contained within<li>tags. - Those list items themselves have links (
<a>tags) with anhrefattribute that contains a link to an IMDB entry for that show.
BONUS QUIZ: What's the parent tag of
<a href="http://www.imdb.com/title/tt0088576/">Mr. Belvedere</a>? Both<div class="kitten">tags share a parent tag---what is it? What attributes are present on both<img>tags?
Scraping kittens with Beautiful Soup¶
We've examined kittens.html a bit now. What we'd like to do is write some code that is going to extract information from the HTML, like "what is the last checkup date for each of these kittens?" or "what are Monsieur Whiskeur's favorite TV shows?" To do so, we need to parse the HTML, and create a representation of it in our program that we can manipulate with Python.
As mentioned above, HTML is hard to parse by hand. (Don't even try it. In particular, don't parse HTML with regular expressions.)
Beautiful Soup is a Python library that will parse the HTML for us, and give us some Python objects that we can call methods on to poke at the data contained therein. So instead of working with strings and bytes, we can work with Python objects, methods and data structures.
If you're using Anaconda, Beautiful Soup comes pre-installed, so there's no extra installation step! If you're not using Anaconda, you may need to install the library with pip:
pip3 install beautifulsoup4
Beautiful Soup only parses HTML. It's left to us to actually get the HTML from somewhere. Because we're doing web scraping, most likely we'll want to download the HTML directly from the web site that hosts it. For that, we'll use the urlopen function in the built-in Python library urllib.request:
import requests
resp = requests.get("http://static.decontextualize.com/kittens.html")
html_str = resp.text
Now html_str is a string that contains the HTML source code of the page in question:
html_str
'<!doctype html>\n<html>\n\t<head>\n\t\t<title>Kittens!</title>\n\t\t<style type="text/css">\n\t\t\tspan.lastcheckup { font-family: "Courier", fixed; font-size: 11px; }\n\t\t</style>\n\t</head>\n\t<body>\n\t\t<h1>Kittens and the TV Shows They Love</h1>\n\t\t<div class="kitten">\n\t\t\t<h2>Fluffy</h2>\n\t\t\t<div><img src="http://placekitten.com/120/120"></div>\n\t\t\t<ul class="tvshows">\n\t\t\t\t<li>\n\t\t\t\t\t<a href="http://www.imdb.com/title/tt0106145/">Deep Space Nine</a>\n\t\t\t\t</li>\n\t\t\t\t<li>\n\t\t\t\t\t<a href="http://www.imdb.com/title/tt0088576/">Mr. Belvedere</a>\n\t\t\t\t</li>\n\t\t\t</ul>\n\t\t\tLast check-up: <span class="lastcheckup">2014-01-17</span>\n\t\t</div>\n\t\t<div class="kitten">\n\t\t\t<h2>Monsieur Whiskeurs</h2>\n\t\t\t<div><img src="http://placekitten.com/110/110"></div>\n\t\t\t<ul class="tvshows">\n\t\t\t\t<li>\n\t\t\t\t\t<a href="http://www.imdb.com/title/tt0106179/">The X-Files</a>\n\t\t\t\t</li>\n\t\t\t\t<li>\n\t\t\t\t\t<a href="http://www.imdb.com/title/tt0098800/">Fresh Prince</a>\n\t\t\t\t</li>\n\t\t\t</ul>\n\t\t\tLast check-up: <span class="lastcheckup">2013-11-02</span>\n\t\t</div>\n\t</body>\n</html>\n\n'
That looks like a mess but it's apparent that we've obtained the data as desired.
Now we need to create a Beautiful Soup object from that data. Here's how to go about doing that:
from bs4 import BeautifulSoup
document = BeautifulSoup(html_str, "html.parser")
type(document)
bs4.BeautifulSoup
The BeautifulSoup function creates a new Beautiful Soup object. It takes two parameters: the string containing the HTML data, and a string that designates which underlying parser to use to build the parsed version of the document. (Leave this as "html.parser".) I've assigned this object to the variable document. This object supports a number of interesting methods that allow us to dig into the contents of the HTML. Primarily what we'll be working with are Tag objects and ResultSet objects, which are essentially just lists of Tag objects.
Finding a tag¶
HTML documents are composed of tags. To represent this, Beautiful Soup has a type of value that represents tags. We can use the .find() method of the BeautifulSoup object to find a tag that matches a particular tag name. For example:
h1_tag = document.find('h1')
type(h1_tag)
bs4.element.Tag
A Tag object has several interesting attributes and methods. The string attribute of a Tag object, for example, returns a string representing that tag's contents:
h1_tag.string
'Kittens and the TV Shows They Love'
You can access the attributes of a tag by treating the tag object as though it were a dictionary, using the square-bracket index syntax, with the name of the attribute whose value you want as a string inside the brackets. For example, to print out the src attribute of the first <img> tag in the document:
img_tag = document.find('img')
img_tag['src']
'http://placekitten.com/120/120'
Note: You might have noticed that there is more than one
<img>tag inkittens.html! If more than one tag matches the name you pass to.find(), it returns only the first matching tag. (A better name for.find()might befind_first.)
Finding multiple tags¶
It's often the case that we want to find not just one tag that matches particular criteria, but ALL tags matching those criteria. For that, we use the .find_all() method of the BeautifulSoup object. For example, to find all h2 tags in the document:
h2_tags = document.find_all('h2')
type(h2_tags)
bs4.element.ResultSet
[tag.string for tag in h2_tags]
['Fluffy', 'Monsieur Whiskeurs']
Both the .find() and .find_all() methods can search not just for tags with particular names, but also for tags that have particular attributes. For that, we use the attrs keyword argument, giving it a dictionary that associates attribute names as keys and the desired attribute value as values. For example, to find all span tags with a class attribute of lastcheckup:
checkup_tags = document.find_all('span', attrs={'class': 'lastcheckup'})
[tag.string for tag in checkup_tags]
['2014-01-17', '2013-11-02']
Note: Beautiful Soup's
.find()and.find_all()methods are actually more powerful than we're letting on here. Check out the details in the official Beautiful Soup documentation.
Finding tags within tags¶
Let's say that we wanted to print out a list of the name of each kitten, along with a list of the names of that kitten's favorite TV shows. In other words, we want to print out something that looks like this:
Fluffy: Deep Space Nine, Mr. Belvedere
Monsieur Whiskeurs: The X-Files, Fresh Prince
In order to do this, we need to find not just tags with particular names, but tags with particular hierarchical relationships with other tags. I.e., we need to identify all of the kittens, and then find the shows that belong to that kitten. This kind of search is made easy by the fact that you can use .find() and .find_all() methods not just on the entire document, but on individual tags. When you use these methods on tags, they search for matching tags that are specifically children of the tag that you call them on.
In our kittens example, we can see that information about individual kittens is grouped together under <div> tags with a class attribute of kitten. So, to find a list of all <div> tags with class set to kitten, we might do this:
kitten_tags = document.find_all("div", attrs={"class": "kitten"})
Now, we'll loop over that list of tags and find, inside each of them, the <h2> tag that is its child:
for kitten_tag in kitten_tags:
h2_tag = kitten_tag.find('h2')
print(h2_tag.string)
Fluffy Monsieur Whiskeurs
Now, we'll go one extra step. Looping over all of the kitten tags, we'll find not just the <h2> tag with the kitten's name, but all <a> tags (which contain the names of the TV shows that we were looking for):
for kitten_tag in kitten_tags:
h2_tag = kitten_tag.find('h2')
a_tags = kitten_tag.find_all('a')
a_tag_strings = [tag.string for tag in a_tags]
a_tag_strings_joined = ", ".join(a_tag_strings)
print(h2_tag.string + ": " + a_tag_strings_joined)
Fluffy: Deep Space Nine, Mr. Belvedere Monsieur Whiskeurs: The X-Files, Fresh Prince
EXERCISE: Modify the code above to print out a list of kitten names along with the last check-up date for that kitten.
EXTRA FUN EXERCISE: Rewrite the code above to create a dictionary that maps kitten names to a list of links to that kitten's favorite shows. I.e., you should end up with a dictionary that looks like this:
{u'Fluffy': [u'http://www.imdb.com/title/tt0106145/',
u'http://www.imdb.com/title/tt0088576/'],
u'Monsieur Whiskeurs': [u'http://www.imdb.com/title/tt0106179/',
u'http://www.imdb.com/title/tt0098800/']}
Finding sibling tags¶
Often, the tags we're looking for don't have a distinguishing characteristic, like a class attribute, that allows us to find them using .find() and .find_all(), and the tags also aren't in a parent-child relationship. This can be tricky! Take the following HTML snippet, for example:
cheese_html = """
<h2>Camembert</h2>
<p>A soft cheese made in the Camembert region of France.</p>
<h2>Cheddar</h2>
<p>A yellow cheese made in the Cheddar region of... France, probably, idk whatevs.</p>
"""
If our task was to create a dictionary that maps the name of the cheese to the description that follows in the <p> tag directly afterward, we'd be out of luck. Fortunately, Beautiful Soup has a .find_next_sibling() method, which allows us to search for the next tag that is a sibling of the tag you're calling it on (i.e., the two tags share a parent), that also matches particular criteria. So, for example, to accomplish the task outlined above:
document = BeautifulSoup(cheese_html, "html.parser")
cheese_dict = {}
for h2_tag in document.find_all('h2'):
cheese_name = h2_tag.string
cheese_desc_tag = h2_tag.find_next_sibling('p')
cheese_dict[cheese_name] = cheese_desc_tag.string
cheese_dict
{'Camembert': 'A soft cheese made in the Camembert region of France.',
'Cheddar': 'A yellow cheese made in the Cheddar region of... France, probably, idk whatevs.'}
You now know most of what you need to know to scrape web pages effectively. Good job!
When things go wrong with Beautiful Soup¶
A number of things might go wrong with Beautiful Soup. You might, for example, search for a tag that doesn't exist in the document:
footer_tag = document.find("footer")
Beautiful Soup doesn't return an error if it can't find the tag you want. Instead, it returns None:
type(footer_tag)
NoneType
If you try to call a method on the object that Beautiful Soup returned anyway, you might end up with an error like this:
footer_tag.find("p")
--------------------------------------------------------------------------- AttributeError Traceback (most recent call last) <ipython-input-25-68ae6cd15b29> in <module>() ----> 1 footer_tag.find("p") AttributeError: 'NoneType' object has no attribute 'find'
You might also inadvertently try to get an attribute of a tag that wasn't actually found. You'll get a similar error in that case:
footer_tag['title']
--------------------------------------------------------------------------- TypeError Traceback (most recent call last) <ipython-input-26-914072fc1329> in <module>() ----> 1 footer_tag['title'] TypeError: 'NoneType' object is not subscriptable
Whenever you see something like TypeError: 'NoneType' object is not subscriptable, it's a good idea to check to see whether your method calls are indeed finding the thing you were looking for.
However, the .find_all() method will return an empty list if it doesn't find any of the tags you wanted:
footer_tags = document.find_all("footer")
print(footer_tags)
[]
If you attempt to access one of the elements of this regardless...
print(footer_tags[0].string)
--------------------------------------------------------------------------- IndexError Traceback (most recent call last) <ipython-input-29-35baeffa5004> in <module>() ----> 1 print(footer_tags[0].string) IndexError: list index out of range
...you'll get an IndexError.
Further reading¶
- Chapter 11 from Al Sweigart's Automate the Boring Stuff with Python is another good take on this material (and discusses a wider range of techniques).
- The official Beautiful Soup documentation provides a systematic walkthrough of the library's functionality. If you find yourself thinking, "it really should be easy to do the thing that I want to do, why isn't it easier?" then check the documentation! Leonard's probably already thought of a way to make it easier and implemented a feature in the code to help you out.
- Beautiful Soup is the best scraping library out there for quick jobs, but if you have a larger site that you need to scrape, you might look into Scrapy, which bundles a good parser with a framework for writing web "spiders" (i.e., programs that parse web pages and follow the links found there, in order to make a catalog of an entire web site, not just a single web page).