Python для сбора данных¶
Алла Тамбовцева, НИУ ВШЭ
Автоматизация работы в браузере: библиотека selenium¶
Библиотека selenium — набор инструментов для интерактивной работы в браузере средствами Python. Вообще Selenium — это целый проект, в котором есть разные инструменты. Мы рассмотрим один из самых распространённых — Selenium WebDriver, модуль, который позволяется Python встраиваться в браузер и работать в нем как пользователь: кликать на ссылки и кнопки, заполнять формы, выбирать опции в меню и прочее.
Мы будем использовать WebDriver для решения такой задачи. Необходимо выгрузить все адреса участковых избирательных комиссий Ивановской области. Для этого нужно написать код, который будет открывать в окне браузера раздел По номеру избирательного участка, вводить в поле с номером номер участка и выбирать регион из предлагаемого списка. Итак, начнём. Попробуем импортировать библиотеку:
import selenium
Если Python пишет No module called selenium, убедитесь, что у вас установлена эта библиотека. Самый надёжный способ установить её ‒ найти Anaconda Command Prompt, вписать строку pip install selenium и нажать Enter. А можно просто в Jupyter Notebook запустить следующую ячейку (! отвечает за режим исполнения ячейки, как будто запускаем в консоли).
!pip install selenium
Загрузим веб-драйвер из библиотеки selenium.
from selenium import webdriver as wb
Затем нужно выбрать браузер и открыть новое окно через Python. Для этого нужно вызвать функцию, которая отвечает за открытие браузера. Мы будем вызывать Chrome.
br = wb.Chrome()
Если код выше не исполняется, скачайте файл с веб-драйвером отсюда, распакуйте архив и пропишите путь к файлу в круглых скобках (на Windows будет файл с расширением .exe).
br = wb.Chrome('/Users/allat/Downloads/chromedriver')
Плюсы такого подхода: его несложно реализовать, высоки шансы, что все заработает. Минусы такого подхода: мы не фиксируем путь к файлу глобально, всегда при работе с selenium придется прописывать строчку с путем. Для того, чтобы Python глобально знал, где ему искать драйвер, нужно добавить путь к нему в переменные среды (environment variables).
Если всё сработает нормально, то откроется новое окно Chrome (пока пустое). Затем мы добавим ссылку на страницу, которую мы должны открыть в браузере.
br.get("http://www.cikrf.ru/services/lk_address/?do=find_by_uik")
Ура, страница открылась. Что на этой странице есть интересного? Два поля: ввод номера участка и регион. Сохраним номер участка в переменную n_uik, а регион – в reg.
n_uik = 244
reg = "Ивановская область"
Вопрос: как эти два поля заполнить? Нужно найти их на странице, открытой в браузере, и вписать туда нужные строки. Только сделать это нужно через Python. Воспользуемся инструментом CSS Selector (установить расширение для Chrome можно здесь). Для этого нужно открыть страницу в обычном браузере и кликнуть на расширение в правом углу.

Теперь, когда мы будем наводить курсор мыши на объект на странице в таком режиме и кликать, внизу будет отображаться его название в css.

Теперь осталось зафиксировать поле с таким названием и ввести туда номер УИКа.
# находим поле с #uik и сохраняем
uik_field = br.find_element_by_css_selector("#uik")
# вводим номер УИКа в поле - метод send_keys
uik_field.send_keys(n_uik)
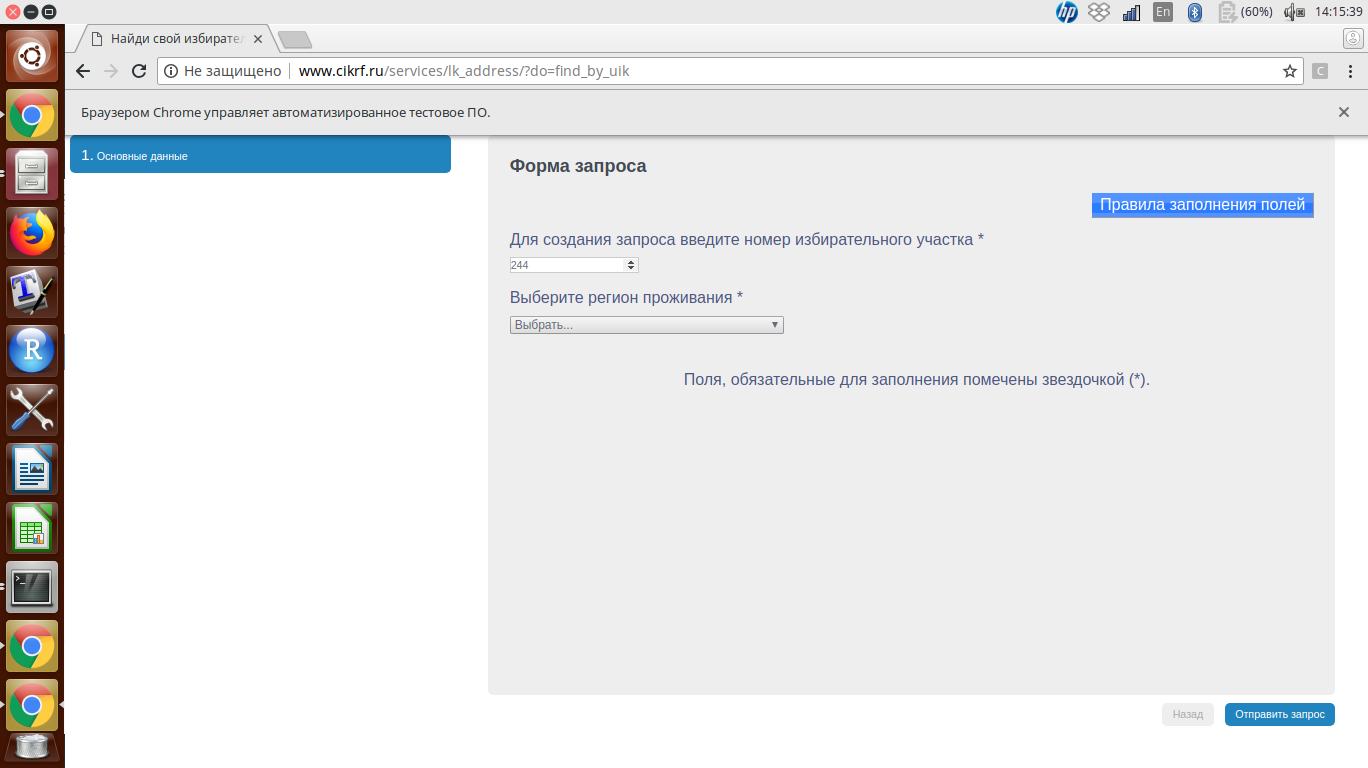
Ура, получилось. А как быть с регионом? Там же не поле ввода, а целое выпадающее меню с опциями... На самом деле, можно точно так же воспользоваться методом send_keys():
# region_field - поле для выбора региона, нашли по названию атрибута name в исходном коде страницы
region_field = br.find_element_by_name("subject")
region_field.send_keys(reg)

Осталось только кликнуть на кнопку Отправить запрос. Сначала найдем ее с помощью CSS Selector, а потом кликнем по ней ‒ воспользуемся методом .click():
button = br.find_element_by_link_text("Отправить запрос")
button.click()
В браузере открылась страница с адресом избирательного участка.

Теперь считаем эту страницу с помощью BeautifulSoup:
from bs4 import BeautifulSoup
# br.page source - строка с исходным кодом страницы
soup = BeautifulSoup(br.page_source, 'lxml')
Найдём все кусочки текста, они заключены в тэги <p></p>, и извлечём из них сам текст:
texts = [a.text for a in soup.find_all('p')]
texts
['Уважаемый пользователь!', 'Данные о номере и адресе избирательного участка:', 'Участковая избирательная комиссия №244Номер Территориальной избирательной комиссии: 011', 'Адрес помещения УИК: 155800, Ивановская область, городской округ Кинешма, город Кинешма, улица Григория Королева, дом 10, здание "Кинешемский политехнический колледж"', 'Телефон УИК: 8-(49331)-21885', 'Адрес помещения для голосования: 155800, Ивановская область, городской округ Кинешма, город Кинешма, улица Григория Королева, дом 10, здание "Кинешемский политехнический колледж"', 'Телефон помещения для голосования: 8-(49331)-21885', 'В случае необходимости получения дополнительной информации, вы можете обратиться в избирательную комиссию субъекта Российской Федерации по месту жительства (адреса избирательных комиссий субъектов Российской Федерации - www.cikrf.ru/sites).']
Напишем небольшую lambda-функцию и заключим её в filter(), чтобы отобрать из списка выше только тот элемент, в котором встречается текст "Адрес помещения для голосования:" (если забыли про lambda-функции и filter(), см. здесь).
address = list(filter(lambda x: "Адрес помещения для голосования:" in x,
texts))[0] # извлекаем единственный элемент из списка - элемент с индексом 0
address
'Адрес помещения для голосования: 155800, Ивановская область, городской округ Кинешма, город Кинешма, улица Григория Королева, дом 10, здание "Кинешемский политехнический колледж"'
Теперь у нас есть универсальный код, который позволяет найти адрес избирательного участка по номеру. В следующий раз мы оформим этот код в функцию, чтобы можно было подставлять в неё любой номер и регион, и применять её в цикле, итерируя по номерам участков.