Introduction¶
This tutorial demonstrates how to preprocess text to clean it up for the modeling stage. Modeling can include classification models, NER (Named Entity Recognition) models, spell checking models, text summarization and generation, as well as prediction models. Usually, this analysis is performed manually and is very time-consuming. The TextCL package helps to identify and filter out (1) sentences in languages other than the target language, (2) linguistically unconnected and/or corrupted sentences, and (3) duplicate sentences.
Another feature of the package is to identify and filter out outliers from the text scope. As outliers, we consider texts that don't contextually belong to the main topic of the text. It's important to be able to identify these anomalies without having labeled data, so we can have a general algorithm for unstructured texts and find out the scope blocks.
In this tutorial, we will work with the BBC data set and additional manually generated sentences to demonstrate the package's functionality. Overall, the package can be used with any text data set loaded as a Pandas data frame.
The package contains the following functions for text cleaning:
- Filtering on language
- Filtering on Jaccard similarity
- Filtering on perplexity score
- Outliers filtering
The first three functions work at the sentence level for each text in the scope. In turn, the outlier filtering function works at the level of the full text. The latter implements 3 different outlier detection algorithms: TONMF, RPCA, and SVD, with l2 normalisation by default (can be changed to the l1, l2, or max via the norm parameter).
Preparation¶
Load package and dependencies:
import textcl
import pandas as pd
import numpy as np
import random
#set up seed for reproducibility
seed = 1
np.random.seed(seed)
random.seed(seed)
Let's prepare the input data from the modified BBC dataset bundled with TextCL. First, load the text data. The sample file is located in the examples folder, next to this tutorial.
SOURCE_FILE_PATH = 'prepared_bbc_dataset.csv'
input_texts_df = pd.read_csv(SOURCE_FILE_PATH).reset_index()
print("Num texts in the data set: {}".format(len(input_texts_df)))
Num texts in the data set: 21
In this example we'll use a subset of the BBC News data set containing 5 topics (business, entertainment, politics, sport, tech) with manually inserted texts to demonstrate the capabilities of the package. Here's how the dataset looks like:
input_texts_df
| index | topic_name | text | |
|---|---|---|---|
| 0 | 0 | business | WorldCom bosses' $54m payout Ten former direc... |
| 1 | 1 | business | Profits slide at India's Dr Reddy Profits at ... |
| 2 | 2 | business | Liberian economy starts to grow The Liberian ... |
| 3 | 3 | business | Uluslararası Para Fonu (IMF), Liberya ekonomis... |
| 4 | 4 | entertainment | Singer Ian Brown 'in gig arrest' Former Stone... |
| 5 | 5 | entertainment | Blue beat U2 to top France honour Irish band ... |
| 6 | 6 | entertainment | Housewives lift Channel 4 ratings The debut o... |
| 7 | 7 | entertainment | Домохозяйки подняли рейтинги канала 4 Дебют ам... |
| 8 | 8 | entertainment | Housewives Channel 4 reytinglerini yükseltti A... |
| 9 | 9 | politics | Observers to monitor UK election Ministers wi... |
| 10 | 10 | politics | Lib Dems highlight problem debt People vulner... |
| 11 | 11 | politics | Minister defends hunting ban law The law bann... |
| 12 | 12 | sport | Legendary Dutch boss Michels dies Legendary D... |
| 13 | 13 | sport | Connors boost for British tennis Former world... |
| 14 | 14 | sport | Sociedad set to rescue Mladenovic Rangers are... |
| 15 | 15 | tech | Mobile games come of age The BBC News website... |
| 16 | 16 | tech | PlayStation 3 processor unveiled The Cell pro... |
| 17 | 17 | tech | PC photo printers challenge printed pictures c... |
| 18 | 18 | tech | PC photo printers challenge pros Home printed... |
| 19 | 19 | tech | processor come pros 43 t6 43 Table data 342 5 ... |
| 20 | 20 | tech | Janice Dean currently serves as senior meteoro... |
Split texts into sentences¶
To be able to process/filter sentences from the data set separately, we first need to split our texts into sentences as rows in a Pandas data frame. The split_into_sentences() function is used for this purpose.
Notice the data loaded in the previous section has a column named text. By default, the split_into_sentences() function expects to find texts in this column. However, an alternative name for this column can be specified in the function's text_col parameter.
Splitting the data set texts into sentences is done as follows, using the split_into_sentences() function:
split_input_texts_df = textcl.split_into_sentences(input_texts_df)
print("Num sentences before filtering: {}".format(len(split_input_texts_df)))
Num sentences before filtering: 319
After splitting text data set into sentences, the number of rows increased from 21 to 319. Let's review them:
split_input_texts_df.head()
| index | topic_name | text | sentence | |
|---|---|---|---|---|
| 0 | 0 | business | WorldCom bosses' $54m payout Ten former direc... | WorldCom bosses' $54m payout Ten former direc... |
| 1 | 0 | business | WorldCom bosses' $54m payout Ten former direc... | James Wareham, a lawyer representing one of t... |
| 2 | 0 | business | WorldCom bosses' $54m payout Ten former direc... | The remaining $36m will be paid by the directo... |
| 3 | 0 | business | WorldCom bosses' $54m payout Ten former direc... | But, a spokesman for the prosecutor, New York ... |
| 4 | 0 | business | WorldCom bosses' $54m payout Ten former direc... | Corporate governance experts said that if the... |
As shown in this example, the split_into_sentences() function places sentences in the sentence column by default. This can be changed using the function's sentence_col parameter.
Filtering on language¶
Let's check how the language filtering function works with manually inserted texts in Russian and Turkish languages to the initial set.
To do this we'll use the language_filtering() function, which filters sentences by language. The input to this function should be a Pandas data frame (with sentence column), a threshold value, and a target language. Language score is the threshold used for filtering, with the default value of 0.99. The function makes use of the detect_language function from the langdetect package, which returns probabilities of a text belonging to a certain language. All sentences below this threshold will be filtered out.
split_input_texts_df = textcl.language_filtering(split_input_texts_df, threshold=0.99, language='en')
print("Num sentences after language filtering: {}".format(len(split_input_texts_df)))
Num sentences after language filtering: 281
The number of rows with sentences was reduced from 319 to 281. Join sentences to the initial texts to review the results:
textcl.join_sentences_by_label(split_input_texts_df, label_col = 'index')
| index | sentence | |
|---|---|---|
| 0 | 0 | WorldCom bosses' $54m payout Ten former direc... |
| 1 | 1 | Profits slide at India's Dr Reddy Profits at ... |
| 2 | 2 | Liberian economy starts to grow The Liberian ... |
| 3 | 4 | Singer Ian Brown 'in gig arrest' Former Stone... |
| 4 | 5 | Blue beat U2 to top France honour Irish band ... |
| 5 | 6 | Housewives lift Channel 4 ratings The debut o... |
| 6 | 9 | Observers to monitor UK election Ministers wi... |
| 7 | 10 | Lib Dems highlight problem debt People vulner... |
| 8 | 11 | Minister defends hunting ban law The law bann... |
| 9 | 12 | Legendary Dutch boss Michels dies Legendary D... |
| 10 | 13 | Connors boost for British tennis Former world... |
| 11 | 14 | Sociedad set to rescue Mladenovic Rangers are... |
| 12 | 15 | Mobile games come of age The BBC News website... |
| 13 | 16 | PlayStation 3 processor unveiled The Cell pro... |
| 14 | 17 | PC photo printers challenge printed pictures c... |
| 15 | 18 | PC photo printers challenge pros Home printed... |
| 16 | 19 | data clear additional 78.0 long-term 43 those) |
| 17 | 20 | Janice Dean currently serves as senior meteoro... |
As we can see, texts with index 3 (Turkish), 7 (Russian) and 8 (Turkish) were removed.
Filtering on Jaccard similarity¶
Function jaccard_sim_filtering() is used to filter sentences by Jaccard similarity. It represents each sentence as an array of tokens and finds the intersection between each pair of arrays / sentences. Using the intersection, the similarity score is calculated; if it's above the specified threshold, a sentence will be filtered out.
split_input_texts_df = textcl.jaccard_sim_filtering(split_input_texts_df, threshold=0.8)
print("Num sentences after Jaccard sim filtering: {}".format(len(split_input_texts_df)))
Num sentences after Jaccard sim filtering: 258
The number of rows with sentences was reduced from 281 to 258. Join sentences to the initial texts to review the results:
textcl.join_sentences_by_label(split_input_texts_df, label_col = 'index')
| index | sentence | |
|---|---|---|
| 0 | 0 | WorldCom bosses' $54m payout Ten former direc... |
| 1 | 1 | Profits slide at India's Dr Reddy Profits at ... |
| 2 | 2 | Liberian economy starts to grow The Liberian ... |
| 3 | 4 | Singer Ian Brown 'in gig arrest' Former Stone... |
| 4 | 5 | Blue beat U2 to top France honour Irish band ... |
| 5 | 6 | Housewives lift Channel 4 ratings The debut o... |
| 6 | 9 | Observers to monitor UK election Ministers wi... |
| 7 | 10 | Lib Dems highlight problem debt People vulner... |
| 8 | 11 | Minister defends hunting ban law The law bann... |
| 9 | 12 | Legendary Dutch boss Michels dies Legendary D... |
| 10 | 13 | Connors boost for British tennis Former world... |
| 11 | 14 | Sociedad set to rescue Mladenovic Rangers are... |
| 12 | 15 | Mobile games come of age The BBC News website... |
| 13 | 16 | PlayStation 3 processor unveiled The Cell pro... |
| 14 | 18 | PC photo printers challenge pros Home printed... |
| 15 | 19 | data clear additional 78.0 long-term 43 those) |
| 16 | 20 | Janice Dean currently serves as senior meteoro... |
Text with was removed as it was a partial duplicate of text with .




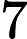

Filtering on perplexity score¶
Function perplexity_filtering() is used to filter sentences by perplexity, i.e., when sentences are linguistically incorrect and/or unconnected with the remaining text.
In general, perplexity is a measurement of how well a probability distribution or probability model predicts a sample. In the case of the text data, we will be checking the probability of the next word to be in the given sentence. A low perplexity indicates the probability distribution is good at predicting the word.
The first step creates contextual tokens to capture latent syntactic-semantic information provided by the pytorch_pretrained_bert package with pretrained openai-gpt tokenizer and using GPT as a language model with OpenAIGPTLMHeadModel. Perplexity is calculated as exp(loss) (where loss is the language modeling loss of a particular token).
split_input_texts_df = textcl.perplexity_filtering(split_input_texts_df, threshold=1000)
print("Num sentences after perplexity filtering: {}".format(len(split_input_texts_df)))
ftfy or spacy is not installed using BERT BasicTokenizer instead of SpaCy & ftfy.
Num sentences after perplexity filtering: 246
The number of rows with sentences was reduced from 258 to the 246. Join sentences to the initial texts to review the results:
textcl.join_sentences_by_label(split_input_texts_df, label_col = 'index')
| index | sentence | |
|---|---|---|
| 0 | 0 | WorldCom bosses' $54m payout Ten former direc... |
| 1 | 1 | Profits slide at India's Dr Reddy Profits at ... |
| 2 | 2 | Liberian economy starts to grow The Liberian ... |
| 3 | 4 | Singer Ian Brown 'in gig arrest' Former Stone... |
| 4 | 5 | Blue beat U2 to top France honour Irish band ... |
| 5 | 6 | Housewives lift Channel 4 ratings The debut o... |
| 6 | 9 | Observers to monitor UK election Ministers wi... |
| 7 | 10 | Lib Dems highlight problem debt People vulner... |
| 8 | 11 | Minister defends hunting ban law The law bann... |
| 9 | 12 | Legendary Dutch boss Michels dies Legendary D... |
| 10 | 13 | Connors boost for British tennis Former world... |
| 11 | 14 | Sociedad set to rescue Mladenovic Rangers are... |
| 12 | 15 | Mobile games come of age The BBC News website... |
| 13 | 16 | PlayStation 3 processor unveiled The Cell pro... |
| 14 | 18 | PC photo printers challenge pros Home printed... |
| 15 | 20 | Janice Dean currently serves as senior meteoro... |
Text with was removed because sentence "data clear additional 78.0 long-term 43 those)" is not linguistically correct.

Outliers filtering¶
Text data is uniquely challenging to outlier detection because of its sparsity and high-dimensional nature. In this package we will use Non-Negative Matrix Factorization (NMF) to detect the text topics in an unsupervised fashion, so the model can be trained and be able to detect outliers without labeling of topics.
The way it works is that NMF decomposes high-dimensional vectors into a lower-dimensional representation. These lower-dimensional vectors are non-negative, which also means their coefficients are non-negative. With this approach, we can see the fact that NMF is similar to probabilistic latent semantic indexing (pLSI) and latent Dirichlet allocation (LDA) generative models. From the original matrix, , NMF yields two matrices, and . The former represents the topics detected in the text data set, while the latter contains the weights for those topics. In other words, is the documents by words matrix, is the articles by topics matrix and is the topics by words matrix.


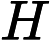
The outlier_detection() function is used to detect outliers in a list of sentences based on the contextual information using unsupervised methods. Text embeddings are created as a bag of words as an input for the implemented algorithms. The main input parameters for this function are the Pandas data frame containing the texts, the method to use for outlier detection (TONMF by default), and the type of norm (l2 by default) to normalize the obtained matrix and detecting the unrelated texts.
To test this, we'll first join sentences to the text after filtering and selecting the "tech" category. This category has a manually inserted outlier () with a person profile instead of text on the subject of "tech".


joined_texts = split_input_texts_df[["index", "text", "topic_name"]].drop_duplicates()
joined_texts = joined_texts[joined_texts.topic_name == 'tech']
joined_texts
| index | text | topic_name | |
|---|---|---|---|
| 168 | 15 | Mobile games come of age The BBC News website... | tech |
| 212 | 16 | PlayStation 3 processor unveiled The Cell pro... | tech |
| 233 | 18 | PC photo printers challenge pros Home printed... | tech |
| 253 | 20 | Janice Dean currently serves as senior meteoro... | tech |
Let's run the outlier_detection() function with the RPCA algorithm:
joined_texts, _ = textcl.outlier_detection(joined_texts, method='rpca', Z_threshold=1.0)
[nltk_data] Downloading package stopwords to /home/alina/nltk_data... [nltk_data] Package stopwords is already up-to-date!
The contents of joined_texts are now as follows:
joined_texts
| index | text | topic_name | words | Z_score | |
|---|---|---|---|---|---|
| 168 | 15 | Mobile games come of age The BBC News website... | tech | Mobile games come age BBC News website takes l... | 0.954468 |
| 212 | 16 | PlayStation 3 processor unveiled The Cell pro... | tech | PlayStation 3 processor unveiled Cell processo... | 0.431154 |
| 233 | 18 | PC photo printers challenge pros Home printed... | tech | PC photo printers challenge pros Home printed ... | 0.292867 |
Text with was removed because it describes a person profile instead of tech news.
Plots for outlier detection¶
In this section we'll visualize the outliers for the BBC data set obtained with the different algorithms. First load additional libraries required for results visualization:
import os
from sklearn.feature_extraction.text import CountVectorizer
from nltk.corpus import stopwords
from sklearn import preprocessing
import matplotlib.pyplot as plt
from sklearn import metrics
We'll use the NLTK library to filter stop words from the initial dataset. Let's import this library and download the stop words list:
import nltk
nltk.download('stopwords')
[nltk_data] Downloading package stopwords to /home/alina/nltk_data... [nltk_data] Package stopwords is already up-to-date!
True
Prepare input data from the BBC dataset¶
To demonstrate how the package handles outlier detection tasks, we present a simplified example from a real world data set to show how skewed the typical values of the corresponding column may be in real scenarios. To build plots for the outlier detection functions we'll need to load the full BBC dataset and apply initial basic text cleaning:




# Download from http://mlg.ucd.ie/files/datasets/bbc-fulltext.zip and unpack to this folder:
dataset_path = "./datasets/bbc"
bbc_dataset = pd.DataFrame([], columns = ['class_name', 'text'])
# Create a list of topics from the folder names based on the data set initial structure
list_topic_folders = os.listdir("{}/".format(dataset_path))
# Get documents per each topic from the corresponding folder
for topic_folder in list_topic_folders:
# Skip ReadMe.txt file
if "txt" not in topic_folder.lower():
list_of_files = os.listdir("{}/{}".format(dataset_path, topic_folder))
# add to the Pandas data frame each text document in the folder
for file in list_of_files:
if file.find(".txt") != -1 and file.find("ipynb") == -1:
with open("{}/{}/{}".format(dataset_path, topic_folder, file), 'rb') as f:
text = f.read()
text = text.decode('windows-1252').replace('\n', ' ')
bbc_dataset = bbc_dataset.append(pd.DataFrame([[topic_folder, text]], columns = ['class_name', 'text']))
# reset index in the final data frame to get identifier column for each document
bbc_dataset = bbc_dataset.reset_index(drop=True)
bbc_dataset.info(verbose=False)
<class 'pandas.core.frame.DataFrame'> RangeIndex: 1872 entries, 0 to 1871 Columns: 2 entries, class_name to text dtypes: object(2) memory usage: 29.4+ KB
Data set contains 2225 texts from the following categories:
for cat in bbc_dataset['class_name'].unique():
print(cat)
entertainment politics business sport tech
Get data for "business" and "politics" classes to form the core of the data set:
bus_and_pol = bbc_dataset[(bbc_dataset['class_name'] == "business") | (bbc_dataset['class_name'] == "politics")]
df_bus_and_pol_texts = pd.DataFrame(list(bus_and_pol.text.values), columns=['text'])
df_bus_and_pol_texts['y_true'] = 0
Get 50 random outliers documents from "tech" class:
text_for_outliers = bbc_dataset[bbc_dataset['class_name'] == "tech"]
text_for_outliers = text_for_outliers.iloc[random.sample(range(0, len(text_for_outliers)), 50)]
df_outliers = pd.DataFrame(list(text_for_outliers.text.values), columns=['text'])
df_outliers['y_true'] = 1
Add outliers documents to the core data set and shuffle:
df_test = pd.concat([df_bus_and_pol_texts, df_outliers])
df_test = df_test.sample(frac=1, random_state=seed).reset_index(drop=True)
stop = stopwords.words('english')
df_test['text'] = df_test['text'].apply(lambda x: ' '.join([word for word in x.split() if word not in (stop)]))
df_test
| text | y_true | |
|---|---|---|
| 0 | Security scares spark browser fix Microsoft wo... | 1 |
| 1 | Nigeria boost cocoa production The government ... | 0 |
| 2 | Businesses fail plan HIV Companies fail draw p... | 0 |
| 3 | Profile: David Blunkett Before resigned positi... | 0 |
| 4 | Tories unveil quango blitz plans Plans abolish... | 0 |
| ... | ... | ... |
| 972 | Winter freeze keeps oil $50 Oil prices carried... | 0 |
| 973 | Commons hunt protest charges Eight protesters ... | 0 |
| 974 | S Korea spending boost economy South Korea boo... | 0 |
| 975 | 'Super union' merger plan touted Two Britain's... | 0 |
| 976 | More reforms ahead says Milburn Labour continu... | 0 |
977 rows × 2 columns
Convert texts to a bag of words using sklearn's CountVectorizer class:
vectorizer = CountVectorizer()
bag_of_words = vectorizer.fit_transform(df_test['text']).todense()
TONMF¶
The tonmf() function uses the TONMF algorithm to obtain the outlier matrix. The solution is based on the non-negative matrix factorization with the extension of the block coordinate descent framework.
outlier_matrix,_,_,_ = textcl.tonmf(bag_of_words, k=10, alpha=10, beta=0.05)
Normalize with l2-normalization:
_, y_pred = preprocessing.normalize(outlier_matrix, axis = 1, norm = 'l2', return_norm = True)
Use ROC curve to plot the results of the algorithm:
f = plt.figure(figsize=(10, 8))
fpr, tpr, thresholds = metrics.roc_curve(list(df_test['y_true'].values), y_pred, pos_label=1)
plt.plot(fpr, tpr, label='ROC curve')
plt.plot([0, 1], [0, 1])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
# f.savefig("BBC dataset TONMF ROC-curve. K=3, alpha = 1, beta = 0.5.pdf", bbox_inches='tight')
plt.title('BBC dataset TONMF ROC-curve. K=3, alpha = 1, beta = 0.5')
Text(0.5, 1.0, 'BBC dataset TONMF ROC-curve. K=3, alpha = 1, beta = 0.5')

Display ℓ2 norm of columns of outlier matrix:
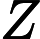
colors_array = np.array(list(df_test['y_true'].values)).astype('str')
colors_array[colors_array == '1'] = 'r'
colors_array[colors_array != 'r'] = 'b'
f = plt.figure(figsize=(20, 6))
index = range(0, len(y_pred))
plt.bar(index, y_pred, color = colors_array)
# f.savefig("Results of TONMF+L2 (outliers - red, non-outliers - blue).pdf", bbox_inches='tight')
plt.title("Results of TONMF+L2 (outliers - red, non-outliers - blue)", size = 20)
Text(0.5, 1.0, 'Results of TONMF+L2 (outliers - red, non-outliers - blue)')

RPCA¶
The function rpca_implementation() uses Robust Principal Component Analysis (RPCA) to obtain the outlier matrix. RPCA uses low-rank approximation and yields two matrices: low-rank matrix and a sparse matrix . After normalization, the matrix represents the outlier score for the document.


outlier_matrix = textcl.rpca_implementation(bag_of_words)
Normalize with l2-normalization:
_, y_pred = preprocessing.normalize(outlier_matrix, axis = 1, norm = 'l2', return_norm = True)
f = plt.figure(figsize=(10, 8))
fpr, tpr, thresholds = metrics.roc_curve(list(df_test['y_true'].values), y_pred, pos_label=1)
plt.plot(fpr, tpr, label='ROC curve')
plt.plot([0, 1], [0, 1])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
# f.savefig("BBC dataset RPCA ROC-curve.pdf", bbox_inches='tight')
plt.title('BBC dataset RPCA ROC-curve')
Text(0.5, 1.0, 'BBC dataset RPCA ROC-curve')

Display ℓ2 norm of columns of Z outlier matrix:
colors_array = np.array(list(df_test['y_true'].values)).astype('str')
colors_array[colors_array == '1'] = 'r'
colors_array[colors_array != 'r'] = 'b'
f = plt.figure(figsize=(20, 6))
plt.ylim(0.001, 0.00175)
index = range(0, len(y_pred))
plt.bar(index, y_pred, color = colors_array)
# f.savefig("Results of RPCA+L2 (outliers - red, non-outliers - blue).pdf", bbox_inches='tight')
plt.title("Results of RPCA+L2 (outliers - red, non-outliers - blue)", size = 20)
Text(0.5, 1.0, 'Results of RPCA+L2 (outliers - red, non-outliers - blue)')

SVD¶
The function svd() uses singular value decomposition (SVD) to obtain the outlier matrix. SVD is performed with the np.linalg function from the numpy package. The outlier matrix is presented as the multiplication of square root of diagonal elements of the rectangular diagonal matrix and complex unitary matrix.
outlier_matrix = textcl.svd(bag_of_words)
Normalize with l2-normalization:
_, y_pred = preprocessing.normalize(outlier_matrix, axis = 1, norm = 'l2', return_norm = True)
f = plt.figure(figsize=(10, 8))
fpr, tpr, thresholds = metrics.roc_curve(list(df_test['y_true'].values), y_pred, pos_label=1)
plt.plot(fpr, tpr, label='ROC curve')
plt.plot([0, 1], [0, 1])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('BBC dataset SVD ROC-curve')
# f.savefig("BBC dataset SVD ROC-curve.pdf", bbox_inches='tight')
/home/alina/.local/lib/python3.8/site-packages/sklearn/utils/validation.py:585: FutureWarning: np.matrix usage is deprecated in 1.0 and will raise a TypeError in 1.2. Please convert to a numpy array with np.asarray. For more information see: https://numpy.org/doc/stable/reference/generated/numpy.matrix.html warnings.warn(
Text(0.5, 1.0, 'BBC dataset SVD ROC-curve')

Display ℓ2 norm of columns of Z outlier matrix:
colors_array = np.array(list(df_test['y_true'].values)).astype('str')
colors_array[colors_array == '1'] = 'r'
colors_array[colors_array != 'r'] = 'b'
f = plt.figure(figsize=(20, 6))
# plt.ylim(0.001, 0.00175)
index = range(0, len(y_pred))
plt.bar(index, y_pred, color = colors_array)
# f.savefig("Results of SVD+L2 (outliers - red, non-outliers - blue).pdf", bbox_inches='tight')
plt.title("Results of SVD+L2 (outliers - red, non-outliers - blue)", size = 20)
Text(0.5, 1.0, 'Results of SVD+L2 (outliers - red, non-outliers - blue)')

The ROC-curve plot was used for the evaluation of the algorithm results. By analyzing obtained plots in these 3 examples we can see that with the current parameters for the BBC data set the RPCA method is offering the best results. In the plot "Results of RPCA+L2 (outliers - red, non-outliers - blue)" we can see the abnormal texts have higher values of the ℓ2 norm and can be segmented from the main distribution. AUC here represents the degree of separability between the main text group and outlied texts, the higher the AUC, the better the model is at distinguishing between different types of texts in the dataset.