Homework II: Logistic Regression, SVM and some computational drug design¶
Given date: Saturday March 7
Due date: Friday March 20
Total : 30 pts + Bonus (One of the bonus question is on 3pts. For the other, it depends on what you can do)

Exercise I.1. Logistic regression (10pts)¶
Use the lines below to load the variables HW2_ExI_X and HW2_ExI_Y. In this first exercise, you will learn a logistic regression classifier on this dataset. Recall that the logistig regression model takes the form
$$p(t=1|\mathbf{x}) = \sigma(\mathbf{\beta}^T\tilde{\mathbf{x}})$$where $\tilde{\mathbf{x}} = [1, \mathbf{x}] = [1, x_1, x_2, \ldots, x_D]$. Consequently, we thus have
$$p(t = 0|\mathbf{x}) = 1 - \sigma(\mathbf{\beta}^T\tilde{\mathbf{x}})$$we can then write the total probability that a point $\mathbf{x}$ will be from class $c = \left\{0,1\right\}$ as
$$p(t = c|\mathbf{x}) = p(t = 1|\mathbf{x})^{c} p(t = 0|\mathbf{x})^{1-c} $$or equivalently
$$p(t = c|\mathbf{x}) = (\sigma(\mathbf{\beta}^T\tilde{\mathbf{x}}))^{c} (1-\sigma(\mathbf{\beta}^T\tilde{\mathbf{x}}))^{1-c} = p^c (1-p)^{1-c}$$which is a binomial distribution with probability of success $\sigma(\mathbf{\beta}^T\tilde{\mathbf{x}})$. If we assume that all the samples are independent, the probability of observing the dataset can read as the product
$$p(\left\{\mathbf{x}_i, t_i\right\}) = \prod_{i=1}^N p(t = t(\mathbf{x}_i)|\mathbf{x}_i)\quad (*)$$We can then try to learn the parameters $\mathbf{\beta}$ that maximize this probability (i.e such that the probability $p(t = t_i |\mathbf{x}_i)$ is high for every sample pair in the dataset. To do this, we take the negative logarithm of $(*)$ which gives
$$-\log \prod_{i=1}^N p(t = t(\mathbf{x}_i)|\mathbf{x}_i) = -\sum_{i=1}^N c_i \log(\sigma(\mathbf{\beta}^T\tilde{\mathbf{x}}_i)) - \sum_{i=1}^N (1-c_i)\log(1-\sigma(\mathbf{\beta}^T\tilde{\mathbf{x}_i}))\quad (**)$$and find the $\mathbf{\beta}$ that minimizes this expression.
from sklearn.datasets import make_blobs
import matplotlib.pyplot as plt
import numpy as np
np.load('Ex1_HW2_X.npy')
np.load('Ex1_HW2_t.npy')
X_class1 = X1[Y1==0,:]
X_class2 = X1[Y1==1,:]
plt.scatter(X_class1[:, 0], X_class1[:, 1], marker='o', c='r',
s=35)
plt.scatter(X_class2[:, 0], X_class2[:, 1], marker='o', c='b',
s=35)
plt.show()

Question I.1.1 Logistic from scratch (7pts) Write a function that takes as inputs a set of training pairs $\left\{\mathbf{x}_i, t_i\right\}$ such as those stored in the variables $\texttt{HW2_ExI_X}$ and $\texttt{HW2_ExI_Y}$, and return the logistic regression classifier by learning it through gradient descent from the minimization of the negative log likelihood function $(**)$. Apply your function to the dataset given above and plot the discriminant function on top of this dataset.
# start by coding the sigmoid function.
def sigmoid(x):
'''The function should return sigma(x) = 1/(1+e^-x) at the point x'''
return sigma
def LogisticRegression(X, y):
'''The function should learn a logistic classifier '''
return beta
Question I.1.2 Logistic vs OLS (3pts) Consider the dataset given below. On this dataset, using the corresponding modules from scikit, learn a linear regression classifier. Then learn a logistic classifier. How do the two approaches compare with each other? Display each each of the classifiers using 'meshgrid + contourf'
import matplotlib.pyplot as plt
import numpy as np
import scipy.io as sio
from sklearn.datasets import make_classification
data_class1 = sio.loadmat('XHW2_EX2_Class1.mat')['XHW2_EX2_Class1']
data_class2 = sio.loadmat('XHW2_EX2_Class2.mat')['XHW2_EX2_Class2']
plt.scatter(data_class1[:, 0], data_class1[:, 1], marker='o', c='r',
s=35)
plt.scatter(data_class2[:, 0], data_class2[:, 1], marker='o', c='b',
s=35)
plt.show()

Exercise II: Maximal Margin classifier and non linearly separable data (10pts)¶
So far we have studided Maximal Margin classifier when the data was linearly separable. In this case, the plane will naturally position itself in between the two classes. The formulation in the linearly separable case is of the form
$$\max_{\mathbf{w}, b_0}\min_{i} \frac{y(\mathbf{x}^{(i)})t^{(i)}}{\|\mathbf{w}\|} = \max_{\mathbf{w}, b_0}\min_i \frac{(\mathbf{w}^T\mathbf{x}^{(i)} + b_0)t^{(i)}}{\|\mathbf{w}\|}$$This formulation is not very nice because the optimization variable appears at the denominator. Note that the formulation $(*)$ can be written as
\begin{align} \max_{\gamma, \mathbf{w}, b_0} & \quad \frac{\gamma}{\|\mathbf{w}\|} \\ \text{subject to} &\quad t^{(i)}(\mathbf{w}^T\mathbf{x}^{(i)} + b_0) \geq \gamma \end{align}Here we simply introduce the parameter $\gamma$ to represent the margin (smallest distance between any point from the dataset and the plane). An important thing to notice when looking at $(**)$ is that any solution for $\mathbf{w}, b_0, \gamma$ can generate an other solution with the same objective by simply scaling it with a positive weight $\alpha$. Indeed if $\mathbf{w},b_0, \gamma$ is an optimal solution to $(**)$, it is easy to check that $\alpha \mathbf{w}, \alpha \gamma, \alpha b_0$ will be a valid solution as well. Since we only need one solution, we can choose to optimize over the set of solution such that $\gamma = 1$. Concretely this means that for each 'line' of solution $(\alpha \gamma, \alpha b_0, \alpha \mathbf{w})$, we only retain the $\alpha$ corresponding to $\alpha\gamma = 1$. The problem then becomes
\begin{align} \max_{\mathbf{w}, b_0} & \quad \frac{1}{\|\mathbf{w}\|} \\ \text{subject to} &\quad t^{(i)}(\mathbf{w}^T\mathbf{x}^{(i)} + b_0) \geq 1. \end{align}To get the final formulation, note that the maximum value for $1/\|\mathbf{w}\|$ is achieved when $\|\mathbf{w}\|$ is the smallest. We an thus solve the problem
\begin{align} \min_{\mathbf{w}, b_0} &\quad \|\mathbf{w}\| \\ \text{subject to} &\quad t^{(i)}(\mathbf{w}^T\mathbf{x}^{(i)} + b_0) \geq 1., \quad\quad (***) \end{align}So far we have assumed that the dataset was linearly separable. In this case, all the points will satisfy $t^{(i)}(\mathbf{w}^T\mathbf{x}^{(i)} + b_0)\geq 1$. Sometimes, however, we could be in a situation where the dataset is not linearly separable and there are points which will be misclassified so that $t^{(i)}(\mathbf{w}^T\mathbf{x}^{(i)} + b_0)$ might be negative. To account for such situation, we will consider slack variables $\xi_i$ and use a more general formulation of the form
\begin{align} \min_{\mathbf{w}, b_0} &\quad \|\mathbf{w}\| + C\sum_{i} \xi_i \\ \text{subject to} &\quad t^{(i)}(\mathbf{w}^T\mathbf{x}^{(i)} + b_0) \geq 1 - \xi_i., \quad\quad (***) \end{align}It is in fact possible to write formulation $(***)$ as an unconstrained optimization problem. Recall that we decided to set the minimum margin to $1$. This in particular means that all the points that are correctly classified should satisfy $t^{(i)}(\mathbf{w}^T\mathbf{x}^{(i)} + b_0)\geq 1$. The approach encoded in $(***)$ corresponds to penalazing those points for which $t^{(i)}(\mathbf{w}^T\mathbf{x}^{(i)} + b_0)<1$. As soon as we have a positive value for one of the variables
Question II.1 Hinge Loss (3pts)¶
We consider the hinge loss $\ell(x, y) = \max(0, 1-x\cdot y)$ for $x = t^{(i)}$ and $y = (\mathbf{w}^T\mathbf{x}^{(i)} + b_0)$. Note that if $t^{(i)}(\mathbf{w}^T\mathbf{x}^{(i)} + b_0)\geq 0$ (meaning the pair $\left\{\mathbf{x}^{(i)}\right\}$ is correctly classified), the output of the hinge function is $0$. On the other hand, if $t^{(i)}(\mathbf{w}^T\mathbf{x}^{(i)} + b_0)<0$ (which corresponds to a pair that is incorrectly classified, as can occur when the data is not linearly separable), then the cost is $1 - t^{(i)}(\mathbf{w}^T\mathbf{x}^{(i)} + b_0)$ (i.e. we can think of this cost as by how much we violate the constraint $t^{(i)}(\mathbf{w}^T\mathbf{x}^{(i)} + b_0)\geq 1$). From this, we can now write the objective as
\begin{align} \min_{\mathbf{w}, b_0} &\quad \|\mathbf{w}\|^2 + C\sum_{i} \max(0, 1 - t^{(i)}(\mathbf{w}^T\mathbf{x}^{(i)} + b_0)) \end{align}Instead of weighting the constraints, we can weight the first term. This gives a similar formulation of the form
\begin{align} \min_{\mathbf{w}, b_0} &\quad \frac{1}{N}\sum_{i=1}^{N} \left\{\frac{\lambda}{2} \|\mathbf{w}\|^2 + \max(0, 1 - t^{(i)}(\mathbf{w}^T\mathbf{x}^{(i)} + b_0))\right\}\quad (****) \end{align}The PEGASOS algorithm finds the corresponding Soft Margin classifier by applying batch gradient descent to this last objective.
What is the gradient of the Hinge loss?
def hingLoss(X, t):
'''Answer the question above by '''
return
Question II.2 Maximum Margin Classifier from scratch (7pts)¶
Using your answer to question II.2.1 above, implement the PEGASOS algorithm. Use a simple batch gradient descent approach with a sufficiently small learning rate (let us say $\eta = 1e-4$). Update the lambda as $1/t$ where $t$ is the step counter.
def approximatePEGASOS(X, t, lambda0, eta):
'''The function takes as input a set of sample pairs {x^{(i)}, t_^{(i)}} as well as an initial value for b0
and a value for the learning rate eta. It should return the weight vector w and the bias b0
for the Max Margin Classifier'''
return w, b0
Apply the algorithm to the dataset below
from sklearn.datasets import make_blobs
import matplotlib.pyplot as plt
import numpy as np
X = np.load('Ex2_HW2_X.npy')
Y = np.load('Ex2_HW2_t.npy')
XEx2_Class1 = X[Y==0,:]
XEx2_Class2 = X[Y==1,:]
plt.scatter(XEx2_Class1[:, 0], XEx2_Class1[:, 1], marker='o', c='r',
s=35)
plt.scatter(XEx2_Class2[:, 0], XEx2_Class2[:, 1], marker='o', c='b',
s=35)
plt.show()

Bonus II.3. dynamic learning rate. (3pts)¶
The exact PEGASOS algorithm updates the learning rate dynamically as $\eta_t = \lambda \cdot t$ for some particular choice of $\lambda$ and where $t$ denotes the step counter. Modify the approximate version of the PEGASOS algorithm that you derived in question II.2.2 to make it work with such a dynamical learning rate.
def PEGASOS(X, t, lambdaPG, eta):
'''The function takes as input a set of sample pairs {x^{(i)}, t_^{(i)}} as well as an initial value for b0
and a value for the learning rate eta. It should return the weight vector w and the bias b0
for the Max Margin Classifier'''
return w, b0
Exercise III: Computational drug design: Part I, Training on Thrombin (10pts)¶
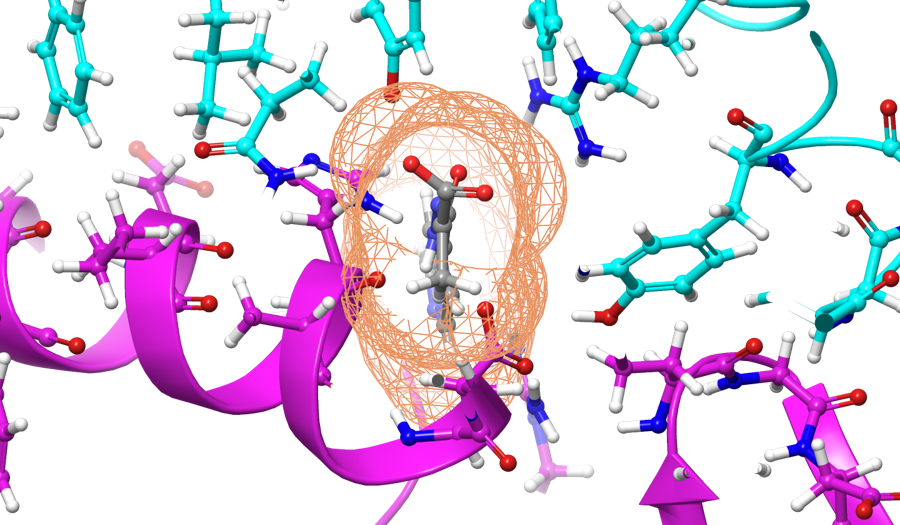
With the recent spreading of the COVID-19 "Corona" Virus. Many initiatives relying on Machine Learning, have been taken to find new drugs that would be able to prevent the virus from infecting host cells. The Human Angiotensin-Converting Enzyme 2 (ACE2) has been proved by many studies to be the specific receptor for the Spike RBD of SARS-CoV. A common approach (followed for example for researchers at Oak Ridge National Laboratory) is to design compounds (such as the one shown in gray in the figure above) that would be able to bind to the SARS-CoV-2 spike protein (shown in cyan), thus making the virus unable to dock to the human ACE2 receptors (shown in purple in the figure below).
Source: Physics.org
We do not have enough data on the COVID-19 yet so we are going to train on an older computational drug design dataset from NIPS 2003. The general idea is the same. A Drug is a small organic molecule that can achieve its desired activity by binding to a target site on a receptor. The first step in the discovery of a new drug is usually to identify and isolate the receptor to which it should bind, followed by testing many small molecules for their ability to bind to the target site (see the UCI ML Repo for more details). For this particular dataset, we are interested in checking which compounds can or cannot bind to thrombin.
Question III.1 (4pts)¶
Start by downloading the DOROTHEA dataset on the UCI ML website . Once you have downloaded the data, as we did for face recognition, use the PCA module from scikit-learn to reduce the dimension of your feature vectors from their initial size (100000) to about 100. Split the data into a training and test part using the train_test_split module from scikit learn
import numpy as np
from sklearn.model_selection import train_test_split
# Start by splitting the dataset into a training part and a validation part (take about 80 to 90% training data)
from sklearn.decomposition import PCA
# Use the PCA module to reduce compress the feature vectors
Question III.2 (6pts)¶
Once you have learned the compressed representation for your samples, learn the following two classifiers
- SVC with RBF kernel (Combine the SVC with GridSearchCVto determine the optimal values for $C$ (how much you penalize misclassification) and $\gamma$ (width of kernel)). To start you can take your grid to be defined as below
param_grid = {'C': [1e2, 5e2, 1e3, 1e4, 5e4], 'gamma': [0.0005, 0.001, 0.005, 0.01, 0.1], }
Keep in mind that larger $\gamma$ means smaller kernel. I.e. $K(x, y) = exp(-gamma ||x-y||^2)$. $C$ is defined as in exercise II.
- Logistic regression classifier
from sklearn.model_selection import GridSearchCV
from sklearn.decomposition import PCA
from sklearn.svm import SVC
# put your code here
Bonus : Computational drug design. Part II: Tackling COVID-19¶
Now that you understand the basic idea behind computational drug design, we are ready to try to tackle the real challenge. A couple of days ago, Sage Health started a competition which was aimed at developing new drugs to fight corona virus. The competition, which was advertised through youtube, is now closed. However it would be interesting to see whether anybody could make additional discoveries from the data. Check the competition video and try to implement some of the step, using the data from the github pages of the winners (see here for the main SageHealth webpage and [https://www.sage-health.org/coronavirus/](here for the links to each of the winners github pages))
Points for this question depends on how far you can go.