4. Classification – Conceptual¶
Excercises from Chapter 4 of An Introduction to Statistical Learning by Gareth James, Daniela Witten, Trevor Hastie and Robert Tibshirani.
I've elected to use Python instead of R.
import numpy as np
1. Using a little bit of algebra, prove that (4.2) is equivalent to (4.3). In other words, the logistic function representation and logit representation for the logistic regression model are equivalent.¶
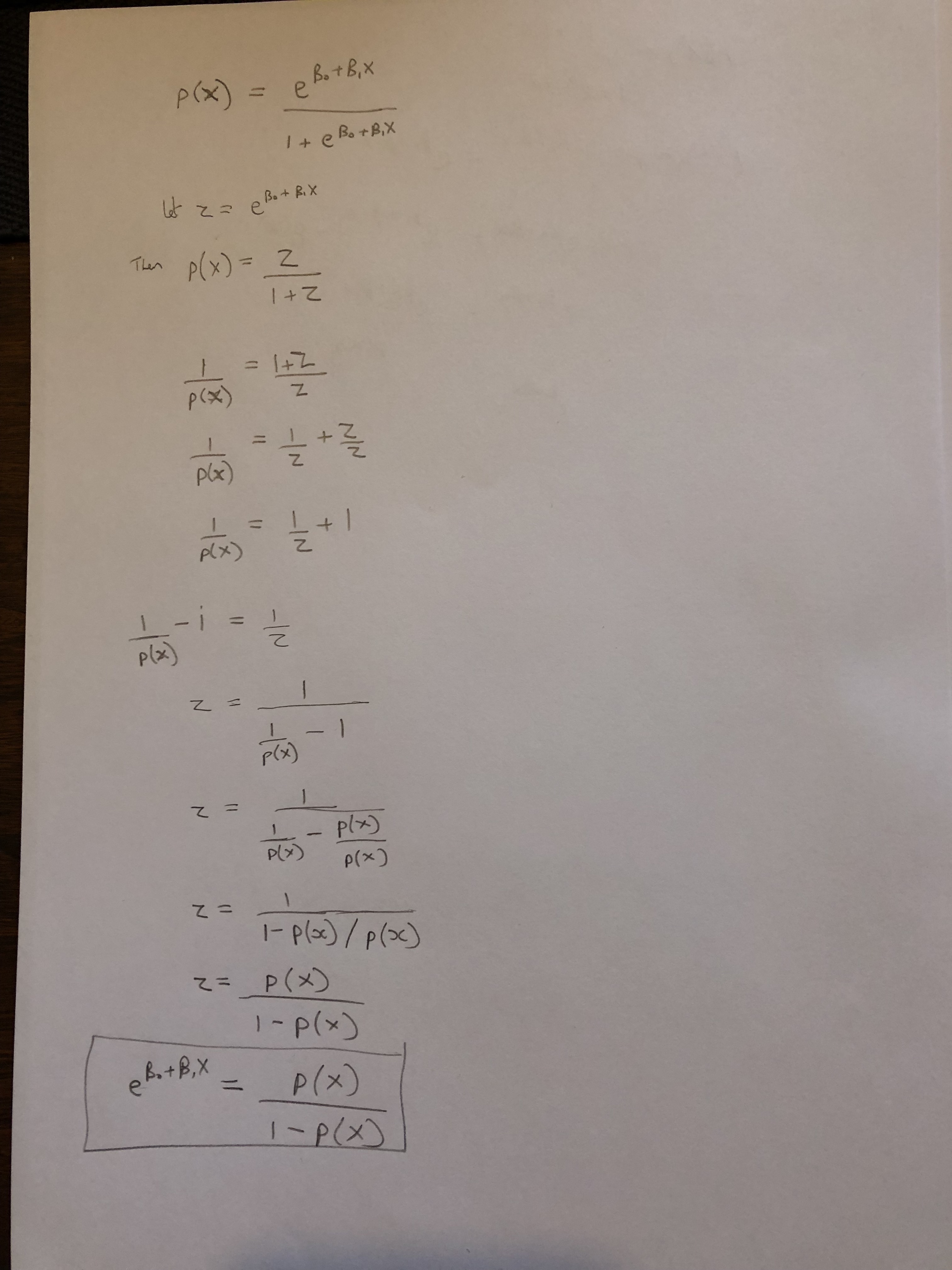
2. It was stated in the text that classifying an observation to the class for which (4.12) is largest is equivalent to classifying an observation to the class for which (4.13) is largest. Prove that this is the case. In other words, under the assumption that the observations in the kth class are drawn from a N(μk,σ2) distribution, the Bayes’ classifier assigns an observation to the class for which the discriminant function is maximized.¶

3. This problem relates to the QDA model, in which the observations within each class are drawn from a normal distribution with a class- specific mean vector and a class specific covariance matrix. We con- sider the simple case where p = 1; i.e. there is only one feature.¶
Suppose that we have K classes, and that if an observation belongs to the kth class then X comes from a one-dimensional normal dis- tribution, X ∼ N(μk,σk2). Recall that the density function for the one-dimensional normal distribution is given in (4.11). Prove that in this case, the Bayes’ classifier is not linear. Argue that it is in fact quadratic.¶
Hint: For this problem, you should follow the arguments laid out in Section 4.4.2, but without making the assumption that σ12 = . . . = σK2 .

4. When the number of features p is large, there tends to be a deteri- oration in the performance of KNN and other local approaches that perform prediction using only observations that are near the test ob- servation for which a prediction must be made. This phenomenon is known as the curse of dimensionality, and it ties into the fact that non-parametric approaches often perform poorly when p is large. We will now investigate this curse.¶
(a) Suppose that we have a set of observations, each with measure- ments on p = 1 feature, X. We assume that X is uniformly (evenly) distributed on [0,1]. Associated with each observation is a response value. Suppose that we wish to predict a test obser- vation’s response using only observations that are within 10 % of the range of X closest to that test observation. For instance, in order to predict the response for a test observation with X = 0.6, we will use observations in the range [0.55,0.65]. On average, what fraction of the available observations will we use to make the prediction?¶
(b) Now suppose that we have a set of observations, each with measurements on p = 2 features, X1 and X2. We assume that (X1,X2) are uniformly distributed on [0,1]×[0,1]. We wish to predict a test observation’s response using only observations that are within 10 % of the range of X1 and within 10 % of the range of X2 closest to that test observation. For instance, in order to predict the response for a test observation with X1 = 0.6 and X2 = 0.35, we will use observations in the range [0.55, 0.65] for X1 and in the range [0.3, 0.4] for X2. On average, what fraction of the available observations will we use to make the prediction?¶
(c) Now suppose that we have a set of observations on p = 100 fea- tures. Again the observations are uniformly distributed on each feature, and again each feature ranges in value from 0 to 1. We wish to predict a test observation’s response using observations within the 10 % of each feature’s range that is closest to that test observation. What fraction of the available observations will we use to make the prediction?¶
(d) Using your answers to parts (a)–(c), argue that a drawback of KNN when p is large is that there are very few training obser- vations “near” any given test observation.¶

(e) Now suppose that we wish to make a prediction for a test obser- vation by creating a p-dimensional hypercube centered around the test observation that contains, on average, 10 % of the train- ing observations. For p = 1,2, and 100, what is the length of each side of the hypercube? Comment on your answer.¶
Note: A hypercube is a generalization of a cube to an arbitrary number of dimensions. When p = 1, a hypercube is simply a line segment, when p = 2 it is a square, and when p = 100 it is a 100-dimensional cube.

5. We now examine the differences between LDA and QDA.¶
(a) If the Bayes decision boundary is linear, do we expect LDA or QDA to perform better on the training set? On the test set?¶
- Training: QDA should perform best as higher variance model has increased flexibility to fit noise in the data
- Test: LDA should perform best as increased bias is without cost if Bayes decision boundary is linear.
(b) If the Bayes decision boundary is non-linear, do we expect LDA or QDA to perform better on the training set? On the test set?¶
- Training: QDA should perform best as higher variance model has increased flexibility to fit non-linear relationship in data and noise
- Test: QDA should perform best as higher variance model has increased flexibility to fit non-linear relationship in data
(c) In general, as the sample size n increases, do we expect the test prediction accuracy of QDA relative to LDA to improve, decline, or be unchanged? Why?¶
Improve, as increased sample size reduces a more flexible models tendency to overfit the training data.
(d) True or False: Even if the Bayes decision boundary for a given problem is linear, we will probably achieve a superior test error rate using QDA rather than LDA because QDA is flexible enough to model a linear decision boundary. Justify your answer.¶
False. If the bayes decision boundary is linear, then a more flexible model is prone to overfit and take account of noise in the training data that will reduce its accuracy in making predictions during test.
6. Suppose we collect data for a group of students in a statistics class with variables X1 = hours studied, X2 = undergrad GPA, and Y = receive an A. We fit a logistic regression and produce estimated coefficient, βˆ0 = −6, βˆ1 = 0.05, βˆ2 = 1.¶
(a) Estimate the probability that a student who studies for 40 h and has an undergrad GPA of 3.5 gets an A in the class.¶
For multiple logistic regression a prediction p(X) is given by
$$p(X) = \frac{\exp{(β_0+β_1 X_1 + β_2 X_2)}}{1 + \exp{(β_0+β_1 X_1 + β_2 X_2)}}$$beta = np.array([-6, 0.05, 1])
X = np.array([1, 40, 3.5])
pX = np.exp(beta.T@X) / (1 + np.exp(beta.T@X))
print('p(X) = ' + str(np.around(pX, 4)))
p(X) = 0.3775
(b) How many hours would the student in part (a) need to study to have a 50 % chance of getting an A in the class?¶

50 hrs
7. Suppose that we wish to predict whether a given stock will issue a dividend this year (“Yes” or “No”) based on X, last year’s percent profit. We examine a large number of companies and discover that the mean value of X for companies that issued a dividend was X ̄ = 10, while the mean for those that didn’t was X ̄ = 0. In addition, the variance of X for these two sets of companies was σˆ2 = 36. Finally, 80 % of companies issued dividends. Assuming that X follows a nor- mal distribution, predict the probability that a company will issue a dividend this year given that its percentage profit was X = 4 last year.¶
Hint: Recall that the density function for a normal random variable is f(x) = √ 1 e−(x−μ)2/2σ2 . You will need to use Bayes’ theorem.¶
$p_1(4) = 0.752$
8. Suppose that we take a data set, divide it into equally-sized training and test sets, and then try out two different classification procedures. First we use logistic regression and get an error rate of 20 % on the training data and 30 % on the test data. Next we use 1-nearest neighbors (i.e. K = 1) and get an average error rate (averaged over both test and training data sets) of 18%. Based on these results, which method should we prefer to use for classification of new observations? Why?¶
KNN with k=1 is a highly flexible non-parametric model, it is prone to overfitting in which case we would observe a low training error and high test error.
The test error will be most indicative of the models performance on new observations.
We know that the average error rate for KNN is 18%. We expect the error in test to be higher than training therefore the best possible test error is 18% (assuming 18% error in training).
The worst possible test error is 36% (assuming 0% error in training).
Therefore the knn test error is somewhere in the range 18 - 36%.
The logistic regression achieves a test error of 30%. This inflexible model is failing to account for some variance in the data, but we do no know if this variance is noise (an irreducible error), or variance in the true relationship which could be accounted for by a more flexible model.
Without any further information we can calculate the probability that KNN produces lower than 30% error in test as:
$p = \frac{30-18}{36-18} = \frac{2}{3}$
Therefore we should prefere the KNN method.
INCORRECT: We know k=1 so training error will be 0%
9. This problem has to do with odds.¶
(a) On average, what fraction of people with an odds of 0.37 of defaulting on their credit card payment will in fact default?¶
$odds = \frac{p(X)}{1 - p(X)} = 0.37$
Rearranging for p(X)
$p(X) = 0.37 - 0.37p(X)$
$p(X) + 0.37p(X) = 0.37$
$p(X) = \frac{0.37}{1 + 0.37}$
$p(X) = 0.27$
(b) Suppose that an individual has a 16% chance of defaulting on her credit card payment. What are the odds that she will default?¶
$odds = \frac{p(X)}{1 - p(X)} = \frac{0.16}{1 - 0.16} = 0.19$