Lecture 1: Tools for Scientific Computing 1 (1.5 Hours)¶
ABSTRACT¶
In Lecture 0, we covered the use of the command line, and we installed a variety of packages including SSH and Git (without telling you exactly what they were for). Here comes the punchline: SSH is a cryptographic protocol for communicating over an unsecured network, and Git is software for version control and collaboration. In this Lecture, we will cover (unsurprisingly):
- how to use SSH for secure, remote computing
- how to use Git for version control and collaboration
SSH (Secure Shell) for Remote Computing (40 Minutes)¶
We can use the SSH protocol to run command lines on a remote machine. This is useful for a range of different tasks but is perhaps most common in scientific computing to run computations on high-performance computing (HPC) resources such as clusters.
Let's start by running a new command-line session, as described in Lecture 0. We've created temporary user accounts on an example remote server, epqis.cgranade.com, so that we have something to SSH into (i.e. connect to using the SSH protocol). In the new command-line session (either PowerShell or bash), run the ssh command below, replacing <user> by the username provided on your slip of paper:
$ ssh <user>@berith.cgranade.com
Since this is probably your first time connecting to berith.cgranade.com, SSH will prompt you to confirm the server's key fingerprint. This is a security mechanism to make sure that someone hasn't performed a man-in-the-middle (MITM) attack against you. At this point, you can either research whether this is the correct fingerprint, or rely on the trust on first use (TOFU) model and accept by typing yes and pressing enter. If you use TOFU, then SSH will guarantee that future connections are to the same server as you are currently connecting to.
You will then be prompted for the password associated with this username. Type it in and press Enter to begin your SSH session on the remote machine berith.cgranade.com. The new SSH session will be heavily encrypted, as is critical for security.
NB: the ssh command will not echo your password to you (make it visible), so the password prompt will look blank. On macOS/OS X, the Terminal application may or may not place a 🔑 emoji in the command line to indicate that echoing is turned off, depending on your version of macOS/OS X.
Were this a useful server, and not (as is actually the case) a Raspberry Pi running in a sweet apartment somewhere, you could then run HPC applications from the comfort of your laptop. Sadly, reality is a little more boring at the moment, so instead feel free to pretend by running a few commands of your choice. Just don't set anything on fire, cause problems with law enforcement, or otherwise act in a very rude fashion with this example server.
Once you're satisfied, run exit or press Ctrl-D to exit the SSH session and return to your own computer's command line. Though this was a useful exercise, it's somewhat limited by one critical problem: we needed to type in our password. This will become very annoying if we have to use SSH as part of an automated process, as will be the case when we learn Git later in this lecture. To solve this, we rely on the public key infrastructure (PKI) built into SSH.
Very roughly, in PKI, one can create keypairs of a matching private and public key. Anyone with the public key can encrypt a message that can only be decrypted with the matching private key. In SSH, this concept is used to provide a much better alternative to passwords. If you have provided an SSH server with your public key, then the server can ask you to decrypt something in order to prove you have the matching private key. Using PKI in this way means that your password does not have to be sent over the network, greatly reducing your attack surface. The security of SSH's PKI can be further enhanced by using a passphrase with your private key. Effectively, a private key with a passphrase cannot be used except by someone who knows that passphrase. Critically, this passphrase is never sent across the network, but is only used by your local machine to reconstruct the full private key.
NB: You may be familiar with or have heard of other public key infrastructures, such as HTTPS certificates or PGP/GnuPG. Though much of the theory is the same, the actual implementation is different and incompatabile enough between different PKIs that it's easiest to think of them as being entirely and fundamentally different. [tl;dr]* SSH is not GnuPG is not HTTPS.*
Generating SSH Keys¶
With this bit of hand-wavy theory out of the way, let's jump in by generating an SSH key.
NB: Please skip these steps if you already have an SSH key.
The SSH client we installed in Lecture 0 comes with a handy command ssh-keygen for doing generating keys.
$ ssh-keygen
You will be prompted where to store the new private key. Press Enter to accept the default of ~/.ssh/id_rsa. You will then be asked to choose a passphrase. Pick something approximately as long as an English sentence, and press Enter to confirm it. You'll be asked to type it again to help prevent errors. Since this passphrase provides part of the entropy for your private key, it must be quite long compared to traditional passwords. Note that this passphrase cannot be recovered if you forget it— this is by design.
NB: you should never* enter your passphrase over a network, as it should only be used locally to unlock your private key.*
- Ubuntu:
To tell an SSH server about your public key, named ~/.ssh/id_rsa.pub by default, use the ssh-copy-id command. This will copy the public key to your ~/.ssh/authorized_keys file on the server, which the server then use the next time you try to log in. You should be prompted for your password on the server for the last time in this process.
$ ssh-copy-id <user>@berith.cgranade.com
$ ssh <user>@berith.cgranade.com
- Windows or macOS / OS X:
Unfortunately, ssh-copy-id is (to first approximation) only available on Ubuntu, so we'll have to copy the new ID manually. First, open ~/.ssh/id_rsa.pub in your favorite text editor and copy the entire thing to the clipboard. Next, run ssh<user>@berith.cgranade.com, and log in with your password. Next, we'll need to make the ~/.ssh directory if it doesn't already exist.
<user>@berith$ mkdir ~/.ssh
<user>@berith$ chmod 0700 ~/.ssh
Here, chmod is a Linux command (berith.cgranade.com is a Linux server, so you need to use Linux commands despite which OS you are running) that changes the permissions so that only you can read and write the new folder. If this is not set, SSH will refuse to look at that folder, and will instead assume its contents are insecure.
Next, we need to make the authorized_keys file that tells SSH what public keys you trust to log in to this account. We'll need to set its permissions, too.
<user>@berith$ touch ~/.ssh/authorized_keys
<user>@berith$ chmod 0644 ~/.ssh/authorized_keys
Finally, open up the authorized_keys file in nano, a simple command-line text editor, and paste in your public key.
<user>@berith$ nano ~/.ssh/authorized_keys
Press Ctrl+O to save and Ctrl+X to exit nano. Log out and try to log back in.
<user>@berith$ exit
$ ssh <user>@berith.cgranade.com
In either case, if all went well, you will instead by prompted by your local machine for the passphrase that you used when generating your key.
A particularly astute and snarky observer may object at this point that we seem to have done something far less convenient than passwords, while justifying our pursuit with convenience as a goal. Indeed, now we need to manage keys and type in a far longer string of characters each time we wish to use SSH to do, well, anything. Thankfully, we're not done yet, as we have yet to use an SSH agent. An agent is a piece of software running on our local machine that manages SSH keys on our behalf, such that once a key is unlocked by our passphrase, we need not use that passphrase again until the agent decides to lock the key based on its security policy. On macOS/OS X, Keychain acts as an SSH agent and is built into the operating system, such that we should not need to do any further work. Similarly, on Ubuntu, an SSH agent called ssh-agent is provided by default when we install ssh using apt-get, as in Lecture 0.
- Windows Only:
On Windows, the story is a little more complicated, but thankfully we installed everything we need back in Lecture 0. In particular, the problem we run into is that the port of OpenSSH to Windows is in progress, such that even though it supports ssh-agent, this support is not in a form that most Windows programs can make use of. Thus, we will instead use a command-line program plink.exe that comes with the PuTTY SSH client. This program uses Pageant, the Windows-style SSH agent provided with PuTTY, rather than ssh-agent.
Steps to setup a windows machine with an OpenSSH key:
- Set Pageant to launch on startup: First we will setup Pageant (our key manager here) to be run at the startup of the machine, so we’ll begin by adding it to the startup folder now. In Windows Explorer (Windows 8.1 and earlier) or in File Explorer (Windows 10 and later), go to the folder
C:\Users\<username>\AppData\Roaming\Microsoft\Windows\Start Menu\Programs\Startup. Right-click inside this folder and selectNew → Shortcut. From there, browse toC:\ProgramData\Chocolatey\bin\ and select pageant.exe. Let it use the default name for this shortcut (pageant.exe).

- Convert OpenSSH key to PuTTY key: Next we want to translate a copy of the OpenSSH key to a PuTTY format key. In In Windows Explorer (Windows 8.1 and earlier) or in File Explorer (Windows 10 and later), go to the folder
C:\ProgramData\Chocolatey\bin\plink.exeand runPuTTYgen.exe. From the Start Menu and select File → Load Key....

From there, navigate to C:\Users\<username>\.ssh\ and select id_rsa (the private key). You may have to drop down the file types selector in the dialog box to see this, as PuTTYgen defaults to filtering out everything but files ending in *.ppk. Once selected, you’ll be prompted by PuTTY to unlock your key by typing in your passphrase. Do so, and PuTTYgen will show the corresponding public key. Select File → Save private key to export your private key in PuTTY, rather than OpenSSH, format. We suggest saving it as id_rsa.ppk in the same folder as id_rsa, but this is up to you. Just be sure that to save it in a folder that only you can read, and that is not synchronized using Dropbox, OneDrive, Google Drive or similar.
- Loading PuTTY key in Pageant: Run Pageant.exe from the folder
C:\ProgramData\Chocolatey\bin\plink.exe(in the future, this will be handled automatically by the shortcut we created above). This will add a new icon to your system tray. It may be hidden by the arrow; if so, click the arrow to make all of the system tray icons visible.

Right-click on Pageant and select Add Key. Browse to where you saved id_rsa.ppk and select it. You’ll be prompted to unlock your key. Upon doing so, your unlocked key will then be made available in Pageant until you log out or quit Pageant.
- Get SSH server fingerprints: Whenever you log into an SSH server, PuTTY will check that the server’s fingerprint is correct. This is a short cryptographic string identifying that server, such that checking the fingerprint helps against man-in-the-middle attacks. If you haven’t logged into a server with PuTTY before, however, it has no idea how to check the fingerprint, and will fail to login. To do so, we’ll use PowerShell one last time. Run one of the following commands below, depending on which hosting provider you use.
PS > & 'C:\ProgramData\Chocolatey\bin\plink.exe' git@github.com
PS > & 'C:\ProgramData\Chocolatey\bin\plink.exe' git@bitbucket.org
NB: The & operator here is PowerShell's "call" operator, and evaluates the contents of a string as a PowerShell command. For instance, & "foo" is equivalent to foo in PowerShell. This is especially useful if the path to a command contains spaces or other special characters, since these are easy to escape inside of strings.
In either case, you’ll be prompted to add the server’s fingerprint to the registry. If you are confident that your traffic is not being intercepted, select y at this prompt. Neither GitHub nor Bitbucket actually allows logins via SSH, so you’ll get an error, but this is OK: you’ve gotten far enough to see the server’s fingerprint, and that’s all we needed. To check, you can run the commands above again, and note that you are no longer prompted to add the fingerprint, but instead fail immediately.
- Add GIT_SSH environment variable: All that’s left is to point Git for Windows at PuTTY and Pageant, rather than its own built-in SSH client. Open the start menu and start typing "environment variables" and you should see an option come up called Edit the System Environment Variables, as shown below.

On the open Advanced tab, press the Environment Variables... button at the bottom. Finally, click New... on the user variables pane (top), and add a new variable named GIT_SSH with value C:\ProgramData\Chocolatey\bin\plink.exe.

You may want to use Browse File... in this dialog box to make sure you get the path correct.
NB: If you are running an older than 10 version of Windows this Browse File...* button may not be there, so to find the path to your plink.exe open a PowerShell session and run:*
PS > Get-Command plink.exe | Select-Object -ExpandProperty definition
C:\ProgramData\chocolatey\bin\PLINK.EXE
This should print out the path you should enter for the value of GIT_SSH.
Once done, press OK to add the variable, OK again to close the Environment Variables dialog, then OK a third time to close System Properties. Finally, close the System window.
Yay! You now should have a working SSH key setup on your Windows machine. Wasn't that fun?!
Other SSH Features¶
Though we won't go into detail here, we'll briefly mention a few other SSH features that you may find yourself needing from time to time.
- Secure Copy (SCP) — SSH provides an FTP-like mechanism for securely copying files from one computer to another, called SCP. This protocol is fairly slow in practice, such that we don't recommend it for large files (~100s of MiB), but it works great for smaller files. At the command line, use the
scpandsftpcommands. - Jump nodes / Proxy hosts — If you're trying to SSH to a machine behind a firewall, your network admin may have set up a demilitarized zone (DMZ) between the public Internet and the firewalled network. SSH can use DMZ servers to automatically proxy other SSH connections, allowing you to "hop" from one server to another without the use of VPNs.
- SSH Forwarding — SSH can also forward network services on a remote machine. Of particular interest to us, if you're running Jupyter Notebook on a Linux or macOS / OS X server, SSH can forward the web interface for Jupyter to your local machine. This is a very powerful way to interactively use high-performance computing resources.
Version Control with Git (50 Minutes)¶
NB: We also highly recommend the tutorial provided by GitHub.
Version-control systems, roughly speaking, provide a structured way of managing changes to a project over time, and across a set of collaborators. This allows a user to determine who changed what and when, to undo changes, and to share changes with collaborators. Many version-control systems, such as Subversion or CVS, are centralized in that all changes are uploaded to, downloaded from, and tracked by a single server. This imposes a lot of restrictions however (try using Subversion when you're offline, working on a plane!), so here we'll learn a bit about decentralized version control - specifically, we will focus on and learn about the features of Git.
To start off, let's look a bit at how Git stores and manages changes. Effectively, Git is a tool for managing directed acyclic graphs (DAGs), where each node is a set of files that comprises a project (these could be Python scripts, LaTeX files, PNG images, etc). Each edge is then the difference between two sets of files and describes how to reconstruct each node, given the state of a project at some other node. A graph of this form is called a repository, and each node is called a commit.
Probably the easiest way to get a handle on the concepts is to jump right in.
$ cd ~
$ mkdir epqis16-tmp-repo
$ cd epqis16-tmp-repo
$ git init
Initialized empty Git repository in C:/Users/cgranade/epqis16-tmp-repo/.git/
This makes a new, empty repository at ~/epqis16-tmp-repo. Before anything else, there's one critical command we need to know about: git status. This command gives a brief summary the current status of a repository along with other useful information that we'll explore in more detail later.
$ git status
On branch master
Initial commit
nothing to commit (create/copy files and use "git add" to track)
Importantly, git status has told us that there's nothing to commit, so let's go on and change that by adding some files. On bash, we can use echo and file redirection (>) to make the small test files we need.
$ echo "foobar" > a.txt
On PowerShell, use the Set-Content command instead.
PS > Set-Content a.txt -Value "foobar"
From here on out, we'll use bash-style notation for making small test files. If you're using PowerShell, please modify accordingly (perhaps amusingly, bash-style notation somewhat works on PowerShell, but might cause odd encoding issues due to PowerShell defaulting to UTF-16). In any case, once we've made a change, we can use git status to see what Git knows about it.
$ git status
On branch master
Initial commit
Untracked files:
(use "git add <file>..." to include in what will be committed)
a.txt
nothing added to commit but untracked files present (use "git add" to track)
That is, git status tells us that there's a file that's untracked. This means that it isn't part of any commit, and thus isn't a part of the repository yet. Let's go on and make a new commit to hold a.txt:
$ git add a.txt
$ git commit -m "Added an important new file."
[master (root-commit) 3fd06ad] Added an important new file.
1 file changed, 0 insertions(+), 0 deletions(-)
create mode 100644 a.txt
$ git status
On branch master
nothing to commit, working tree clean
$ git log
commit 3fd06ad19d9ace8ffd5334bf277d8ee523e60b1a
Author: Chris Granade <cgranade@cgranade.com>
Date: Thu Oct 27 12:03:45 2016 +1100
Added an important new file.
NB: You may get an error when you run git commit saying that you need to set your name and your e-mail address. Git uses this information to identify who made what changes; if you see this error, run the commands that Git suggests to provide your information. Make sure that your e-mail address matches what you gave GitHub, as this will allow GitHub to associate your commits with your account. After you're done, just run git commit again and it should work.
In the above example, we used the -m flag (short for "message") to give a short description of the changes in our new commit. Doing so helps out your collaborators (such as future you) figure out what your commit did, so please be polite to yourself and others by writing short but descriptive commit messages. If you forget to include a message, Git will launch a text editor for you to make a message.
A Brief Aside About vim: Depending on your operating system's defaults, Git may launch an inscrutably complex text editor known as Vim. To quit Vim, press Esc followed by :wq!. No, that's not a joke. Vim is very nice once you used to it, I'm told, but its learning curve can be effectively simulated by driving a car off of a cliff. I have no idea why some operating systems make this the default text editor, but Git will dutifully obey that default and launch Vim for you. Thankfully, it's easy to change that default. Change the EDITOR environment variable to whatever you like. Some suggestions:
EDITOR=nano: Nano is a small lightweight text editor for use at the command line (you may need to install withchoco install nanoorsudo apt-get install nano). Unlike Vim, Nano lists its keyboard commands on the screen at all times.EDITOR=code --wait: Launches a new Visual Studio Code tab as the Git editor. More details about this are available in the VS Code documentation.EDITOR=atom --wait: Does similar, but for GitHub's Atom text editor.EDITOR=subl -n -w: Does similar, but for Sublime Text 3. Note that this requires thatsublis set up as a shortcut for invoking Sublime Text. That's the default on Linux, and is easy to set up on macOS / OS X.
At any rate, since a.txt is now in the repository, git status tells us that there's nothing left to commit at the moment. Suppose, though, that we decide that a.txt is actually entirely wrong, and need to change it to something else.
$ echo "baz" > a.txt
$ cat a.txt
baz
$ git status
On branch master
Changes not staged for commit:
(use "git add <file>..." to update what will be committed)
(use "git checkout -- <file>..." to discard changes in working directory)
modified: a.txt
no changes added to commit (use "git add" and/or "git commit -a")
Now, a.txt is in the repo, but our changes to it are not. Helpfully, git status guides us a bit here, and suggests git add a.txt will do what we need. Let's do that and check git status one more time.
$ git add a.txt
$ git status
On branch master
Changes to be committed:
(use "git reset HEAD <file>..." to unstage)
modified: a.txt
We can finish the commit as before by running git commit.
$ git commit -m "Fixed important bug with a.txt."

Before moving on, we stress that everything we've done so far has been offline. We haven't used any server at all to do this, because git init just made a new repository for us entirely. All of our commits have been to that repository on our local machine. In practice, however, Git really shines when it works with one or more servers (being decentralized, we needn't limit ourselves to just one), as you can then pull and push changes between your repository and external servers. To do this, then, we can either run our own server (which is not a bad idea, but is well beyond the scope of this workshop), or you can use a service which provides Git hosting for you. Thankfully, several such services exist, including GitHub, Bitbucket, GitLab, and Visual Studio Team Services.
Here, we'll use GitHub as an example, owing to its relative popularity, but most of this example should work on other hosting providers with at most minor modifications. Roughly speaking, we'll proceed in four steps:
- Sign up for an account (and any academic discounts)
- Upload SSH public keys to new account
- Make a new repository
- Clone the new reposistory to our laptop
Setting up a GitHub account¶
The first thing we'll need to do is set up a GitHub account. Initially, GitHub allows us to create free public repositories, meaning that any files within are publicly available. To avoid trolls pilfering our public repositories for their riches, we'd prefer private repositories with restricted access. Fortunately, GitHub provides free private repositories to users with an educational email address - go to education.github.com, click "Request a discount", enter your GitHub login credentials, complete the brief survey, and await email confirmation. This may take several days, but that's okay because what we create during this workshop will most likely not be monumental enough to keep secret.
In any case, once you have a GitHub account, you can use the web interface to perform many server-side Git operations quickly and easily. Largely, we'll use the GitHub web site to manage things on the server, and command-line Git or Git integration for our preferred text editors to manage things on our local systems. Between the two, we will have a very efficient and flexible version control procedure in place to support our research and other projects.
To do this, though, we'd like to communicate with the GitHub server securely... which is exactly what SSH is for! To assign your SSH public key to your GitHub account, click the Settings option from the drop-down User tab in the upper-right corner. In the page that appears, navigate through the SSH and GPG keys option, and click on New SSH key. In the Title box, give your local computer a name. Now we need to give GitHub our public SSH key. Let's display it on the command line.
$ cat ~/.ssh/id_rsa.pub
NB: Notice the .pub. Without that, you're printing your entire private* key to the screen.*
Copy the entire public key, beginning with "ssh-rsa" and continuing all the way through any web-address-looking characters at the end. Paste it into the key field and then Add SSH key.
Now that we've told GitHub our SSH public key, we can use SSH to authenticate ourselves to GitHub in all future steps. Thus, we're now all set to begin using GitHub. Let's make a new repository on GitHub, so that we can sync up our existing epqis16-tmp-repo to it. Select the New repository menu item from the GitHub web interface's "+▼" menu.

This will take you to a new page where you're asked a few things about the new repository you'd like to create.
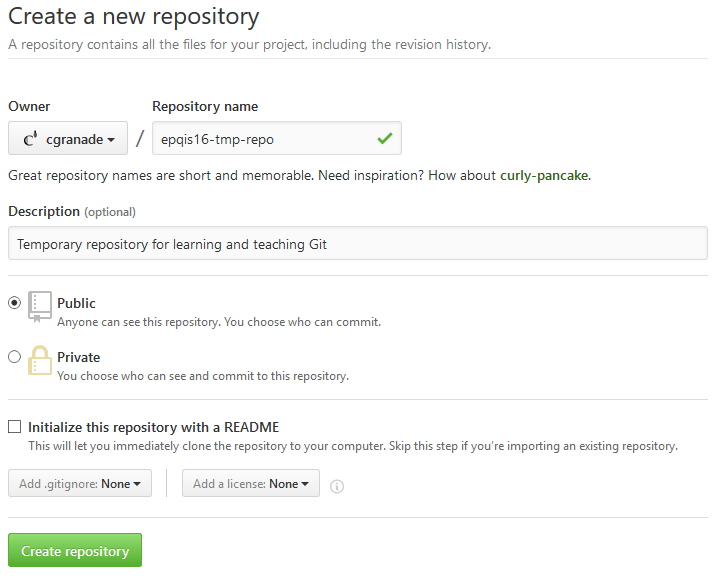
- Repository name: Straightforwardly, this is the name of the repository. By default, this is also the name of the folder containing the repository, so something short and easy-to-type is preferable. We suggest lowercase names that are separated by hyphen characters (
-; if you use an en dash–, you are evil). - Description: A short description that will appear under your repository name on the GitHub page for your new repository. This has no technical impact, so choose something human-readable and informative.
- Public/Private: Selects whether others can see your repository or not. Unless you have an compelling reason to prefer Private, we strongly suggest Public for most research uses.
- Initialize this repository with a README: For subtle technical reasons, you can't make copies of a Git repository that has no files in it, so GitHub will offer to put at least one file in it to start you off. Since we already have a local repository that we'd like to use, we'll take the advice presented and skip this step for now.
- Add
.gitignore/Add a license: These options allow you to initialize your repository with a.gitignorefile (we'll explain this later) and/or a file describing the copyright license your project falls under. Both of these are almost always good ideas, but we'll skip both for now since we're dealing with a simple example.
Once everything is filled in, press Create repository to make your new repository on GitHub. This will take you to a new page that suggests running the following commands in your local repository. Be sure to change the username and repository name based on what you chose above.
$ git remote add origin git@github.com:cgranade/eqpis16-tmp-repo.git
$ git push -u origin master
Counting objects: 6, done.
Delta compression using up to 4 threads.
Compressing objects: 100% (2/2), done.
Writing objects: 100% (6/6), 1.73 KiB | 0 bytes/s, done.
Total 6 (delta 0), reused 0 (delta 0)
To github.com:cgranade/eqpis16-tmp-repo.git
* [new branch] master -> master
Branch master set up to track remote branch master from origin.
If this command fails with an authentication error, that often means that your SSH client isn't providing a key that GitHub recognizes. On Windows, the most common cause of this is that you forgot to add your key to Pageant; thankfully, that's very easy to fix. Right click on the Pageant icon and select Add key... as described above. If the error persists, double-check that your public key has been properly added to your GitHub profile.
NB ( Windows-only): The push command above may fail if you haven't connected to GitHub before using PuTTY/Plink, instead presenting a prompt with no way to select "y". To fix that, cancel the push by pressing Ctrl+C, then run plink git@github.com. If you installed Plink somewhere else, you may need to specify its full path as specified by $Env:GIT_SSH.
We'll break things down a bit more in the next section, but the rough version of what's going on here is that git remote add tells your local repository to record the existence of another, related repository, and to give that remote the name origin.
The next command then pushes your commits to the server. The -u flag (short for upstream) tells Git which remote that you want to associate with this push. The argument master refers to a branch, but to explain that, we first need a bit more theory.
NB: Note that in practice, you'll almost always want to pull changes into a project, rather than push them. In particular, if you're contributing changes to repository that you don't have push access to, you can use a Git hosting service to send them a pull request, asking them to pull your changes.
If you create a repository on the server, then copy it to your machine (a process known as cloning), then Git will automatically name the server repository origin for you. Since we already have epqis16-tmp-repo locally, let's see how that works with another repository. In particular, these lecture notes are all stored and developed as a Git repository, so let's use git clone to download them! You can find the Git URL for cloning from the GitHub repo using the Clone or download button.
NB: This tutorial covers using SSH to clone, push and pull, but GitHub defaults to HTTPS due to missing SSH support on Windows. If GitHub suggests cloning with HTTPS, make sure to use the Use SSH link instead.

In any case, once we have the clone URL, we can proceed to use git clone to make a new copy locally. Use cd to navigate to where you'd like to store your new copy, then run the following in bash or PowerShell:
$ git clone git@github.com:QuinnPhys/PythonWorkshop-science.git
Once this is done, you have your own completely independent copy of the lecture notes for this workshop! Note that GitHub also sets the remote for your copy, making it easy to pull new changes down to your copy.
$ cd PythonWorkshop-science
$ git remote -v
origin git@github.com:QuinnPhys/PythonWorkshop-science.git (fetch)
origin git@github.com:QuinnPhys/PythonWorkshop-science.git (push)
NB: Here, the -v argument stands for "verbose," and instructs Git to tell us details about each remote, rather than just listing their names.
Using Git for Decentralized Version Control¶
Now that we have a repository that's synced with a server, and have played around with making a few commits of our own, let's take a step back and look at the how everything works in terms of the directed acyclic graph (DAG) structure that we mentioned earlier.
For example, suppose that we've made three commits in total to our new repository. Then, the DAG would have three nodes (one for each commit), each a set of changes from their parent, as indicated by a directed edge. The most recent commit in this case is referred to by a kind of label called a branch. By default, a new Git repository has only one branch, called master. Putting it all together, the picture looks something like this:

Since each remote repository is a complete repository in its own right, our picture has multiple DAGs once we include a remote (note that the GitHub and Bitbucket web interfaces, as well as common desktop applications, will often collapse these into a single picture for brevity; here, we show everything in terms of multiple DAGs to illustrate the concept). For instance, suppose that you make a new commit on your local repository, bringing you to a total of four. In that case, your master branch moves forward with that commit, but origin's master doesn't have that commit and stays in place. Running git push then makes the new commit available to the server (origin) and advances its master to match our local repository. Pictorially, we represent this with the two DAGs below, with the results of git push shown in red.

The opposite of this, git pull, fetches new commits from remote repositories and advances your branches accordingly. Of course, if this was all Git could do, we'd basically have a rather unwieldy and needlessly complicated reimplementation of Dropbox. Thankfully, where Git really shines is that commits can have multiple children, indicating that different changes are made from the same starting point. We can then merge these later with a special kind of commit called a merge (unimaginative naming is sometimes for the best) that has two parents instead of a normal commit, which always has just one parent.
One way that merging can arise is if someone has made changes on the remote that aren't reflected on your local repository and vice versa. Let's add some labels to the commits and see how this might happen:

Here, origin has a commit c that we're missing, but we have a commit d that origin is missing.
NB: this being a toy example, we've labeled commits as single letters. Normally, commits have names given by cryptographic hashes of their contents, and are often abbreviated to 7-character hexadecimal strings.
If we try to git push now, it won't work, because the remote will reject our push and insist that we merge things up locally. Instead, we have to git pull, which will add c to our local repository and start a new merge that inherits from both c and d. In many cases, Git can automatically figure out how to make this new merge, because the changes in the two parents won't conflict with each other. (We'll deal with the, er, interesting case below.) After completing the merge, whether automatically or through manual suffering, our local DAG will now look something like this:

This now has our master strictly ahead of origin's master, so we can push without losing information. The remote will now accept the push, and we can get on with our lives, knowing we've successfully included both our changes and those from our collaborators (which could include our past selves working on different machines).
NB: This also illustrates a common and useful practice of always pulling before pushing. As mentioned above, pulling is, in most ways, much simpler to deal with.
More commonly, merging happens as a result of introducing new branches. As mentioned before, a branch is just a label for a particular commit. That allows us to attach a label to those commits that indicate work along a particular topic. In their best practices called GitHub Flow, GitHub recommends that whenever you start work on a particular topic within a project, such as new content, a new feature, or a bug fix, you also make a new branch to track that work. Commonly, these topic branches will be given names such as feature-foo or fix-bar, but neither Git nor GitHub enforce this in any way whatsoever.
Branches are made by the git branch command, and can then be checked out using git checkout. In general, you can checkout a commit to make your local repository reflect the state of the repository at that point in the DAG. Let's take a quick break from the theory to see this in action.
$ git branch feature-carp
$ git checkout feature-carp
This makes a new branch called feature-carp, so named because we'll use it to track a topic that's related to adding carp to our project, then changes our working copy to represent this branch. We can confirm this in the usual way with git status:
$ git status
On branch feature-carp
nothing to commit, working tree clean
Let's make a new commit on this branch.
$ echo "trout" > fish.txt
$ git add fish.txt
$ git commit -m "Needs more fish."
[feature-carp dc99f94] Needs more fish.
1 file changed, 0 insertions(+), 0 deletions(-)
create mode 100644 fish.txt
$ git status
On branch feature-carp
nothing to commit, working tree clean
Importantly, we can always go back to another branch, so long as that would not overwrite uncommited changes.
$ git checkout master
$ ls
a.txt
$ git checkout feature-carp
$ ls
a.txt fish.txt
If we want to make our new branch available to a remote, we need to say which branch of the remote our new branch should follow. (Some editors, such as VS Code, refer to this as publishing a branch, but that terminology is not used by Git itself.) If we try to push without doing this, recent versions of Git will guide us:
$ git push
fatal: The current branch feature-carp has no upstream branch.
To push the current branch and set the remote as upstream, use
git push --set-upstream origin feature-carp
$ git push --set-upstream origin feature-carp
Counting objects: 3, done.
Delta compression using up to 4 threads.
Compressing objects: 100% (2/2), done.
Writing objects: 100% (3/3), 941 bytes | 0 bytes/s, done.
Total 3 (delta 0), reused 0 (delta 0)
To github.com:cgranade/eqpis16-tmp-repo.git
* [new branch] feature-carp -> feature-carp
Branch feature-carp set up to track remote branch feature-carp from origin.
NB: if you're using an older version of Git, you'll instead see the message that "Everything is up to date." From the perspective of Git, this is very much the case, since you haven't said what to compare your new branch to.
We can now push as normal, since our branch remembers which upstream branch it corresponds to.
$ echo "carp" > fish.txt
$ git add fish.txt
$ git commit -m "Fixed wrong kind of fish."
[feature-carp 62daacf] Fixed wrong kind of fish.
$ git push
Counting objects: 3, done.
Delta compression using up to 4 threads.
Compressing objects: 100% (2/2), done.
Writing objects: 100% (3/3), 943 bytes | 0 bytes/s, done.
Total 3 (delta 0), reused 0 (delta 0)
To github.com:cgranade/eqpis16-tmp-repo.git
dc99f94..62daacf feature-carp -> feature-carp
Since merging this new branch into master would be very boring (there's no need for a merge commit, even, as master has nothing that feature-carp is missing), let's make the example slightly more interesting by creating a new commit directly on master. This is generally not recommended, but helps us make something quickly.
$ git checkout master
$ echo "blah" > b.txt
$ git add b.txt
$ git commit -m "Creating conflicts for no reason."
$ git push
Going back to the DAG picture, we have something that looks like this:

We can now merge feature-carp into master so that master reflects both our new changes there and those introduced by the feature-carp branch.
$ git merge feature-carp
Merge made by the 'recursive' strategy.
fish.txt | Bin 0 -> 14 bytes
1 file changed, 0 insertions(+), 0 deletions(-)
create mode 100644 fish.txt
$ git push
Counting objects: 2, done.
Delta compression using up to 4 threads.
Compressing objects: 100% (2/2), done.
Writing objects: 100% (2/2), 984 bytes | 0 bytes/s, done.
Total 2 (delta 0), reused 0 (delta 0)
To github.com:cgranade/eqpis16-tmp-repo.git
e4957d8..b016bfe master -> master
Since the feature-carp branch is now redundant, we can safely delete it without losing any changes.
NB: this will not delete it on the origin remote; use the GitHub web interface for that.
$ git branch -d feature-carp
Deleted branch feature-carp (was 62daacf).
To put it all together, below we've shown a more complicated hypothetical situation involving three branches: master, feature-1, and feature-2, along with the effects of several Git commands. It takes some practice to manage branches and conflicts, but the end result is having a very powerful tool at your disposal for working with your collaborators to get research done.

What is Forking?¶
Put together, the fundamental operations of cloning, branching, pulling and pushing enable a range of different ways of structuring projects. One of the most powerful structures enabled is known as forking. A fork of a repository is a clone of that repository that is hosted along side the original but owned by someone else. The fork can then be cloned like any other repository, or even forked again. This makes it much easier to contribute bug fixes, documentation, new features, etc. to open-source projects. Though a full explanation of forking is beyond the scope of this lecture, we'll briefly summarize here. In doing so, we'll again follow GitHub's workflow and notation for the most part, but the concepts work pretty similarly elsewhere.
As an example, consider the InstrumentKit library that we'll explore in Lecture 6. This library has support for controlling a very large number of different experimental instruments, but there's always many more out there that could be supported. With traditional version control systems like Subversion, it would be very hard to send a new instrument driver to InstrumentKit for inclusion, but with Git, it is much simpler. In this example, you could follow a few steps to send in your support for a new instrument:
- Fork the InstrumentKit repo from
Galvant/InstrumentKitto<your username>/InstrumentKitusing the button on GitHub's web interface. - Clone your fork of the
InstrumentKitrepo to your computer. - Checkout a new branch
feature-fancy-instrumentto develop your new driver in. - Make the new driver and commit it.
- Push the new branch
feature-fancy-instrumentto your fork. - Ask
Galvant/InstrumentKitto pull your fork's branch into a branch on their repo.
Importantly, most of these steps are just the same as if you were working on your own project, introducing very little additional work to help out a different part of your community.
Further Reading:
Conflict Avoidance Resolution¶
Conflicts happen. While Git can figure out a very large number of your merges automatically, some of those conflicts require human insight to resolve. When that happens, things can get hairy fast. In light of this, we won't give a complete guide here for how to get out of merge hells, but rather a rough outline along with external resources. Roughly speaking, a merge conflict proceeds in a few steps:
git mergeorgit pullstarts a merge.- Git dumps an error message to the screen indicating that the merge can't be completed automatically:
Auto-merging foo.txt
CONFLICT (content): Merge conflict in foo.txt
Automatic merge failed; fix conflicts and then commit the result.
- The affected file (in this example,
foo.txt) is then updated with conflict markers<<<<<<<and>>>>>>>. These markers indicate regions of the affected file that differ in each of the two parents going into the merge.
NB: git status is your friend. Really. Run it often during merge conflicts to see what's going on and when.
At this point, you can either fix the conflicts by opening the file in a text editor and looking for and resolving the conflict markers, or you can use git mergetool to fire up a merge program. For the first approach, we recommend using VS Code's Git merge support to highlight conflicts without installing additional software. After resolving all conflicts, run git add to tell Git that you've resolved them. Run git commit to finish the merge.
Using a dedicated merge program is more powerful, however. In particular, git mergetool will launch a three-way merge tool (for example, Meld or macOS / OS X opendiff) that shows each parent of the merge side-by-side with the your post-merge file. The first time you need to do a three-way merge is very painful indeed, but we promise, it gets easier with practice, so please don't get discouraged.
External resources:
Text Editor Integration¶
As discussed in Lecture 0, both Sublime Text and VS Code have very nice Git support. For the most part, this Git support provides us with a convenient way to run Git commands, such that it is still essential to know what the underlying command line invocations are and what they do. For instance, let's look at how to make a new commit in each of Sublime Text and VS Code. We'll leave the rest to their respective documentation.
Sublime Text¶
Use File → Open Folder to open epqis16-tmp-repo. From the side bar, open one of the text files and make some changes, pressing Ctrl+S to save them. From the Command Palette (Ctrl+Shift+P), choose Git: Status. This will open up a little palette that summarizes which files are modified (M), untracked (??), delted (D), etc.

At this point, you can use Git: Add and Git: Commit to from the Command Palette to make a new commit, or Git: Quick Commit to make a commit from changes in the current file.
VS Code¶
Use File → Open Folder to open epqis16-tmp-repo. From the side bar, open one of the text files and make some changes, pressing Ctrl+S to save them. Press the Git icon  from the side bar on the left (shortcut: Ctrl+Shift+G) to show a list of unstaged changes. Either press the + icon on the Git side bar or use Git: Stage from the Command Palette (Ctrl+Shift+P) to add your changes to the staging area.
from the side bar on the left (shortcut: Ctrl+Shift+G) to show a list of unstaged changes. Either press the + icon on the Git side bar or use Git: Stage from the Command Palette (Ctrl+Shift+P) to add your changes to the staging area.

From there, enter a message into the Git sidebar by clicking it, or by using Git: Commit from the Command Palette. Press Ctrl+Enter to finish your message, and Git: Push from the Command Palette to push.
NB: You can also highlight individual changes on the Git sidebar to show those changes in a side-by-side view.
Other Git Commands and Features¶
As above, we'll more briefly cover a few other Git features. We encourage you to explore Git further!
git diff— One of the most powerful Git features is its ability to quickly compare different commits, providing summaries of what changes were made and when. Together with modern text editors and programs likercs-latexdiff, Git provides rich information about the history of a project. Many Git hosting services, such as GitHub, Bitbucket, and GitLab, providediffinformation through their respective web interfaces, making it easy to see changes directly online.git checkout— Though we've seen several uses ofgit checkoutabove, this command is much more powerful than we've explored so far. It can be used to restore individual files, change branches, view old commits, or even commits from other remote repositories.git reset— If you've ever staged something that you didn't mean to,git resetcan revert the staging area without losing changes. This command is also very powerful, though, and can be used for many other things, such as permanently moving commits between branches.git stash— If you want to temporarily save changes for making a commit later,git stashcan make a kind of hidden temporary commit called a stash. These stashes are great for keeping rough changes out of the way while you push, pull, merge and otherwise juggle commits.git tag— Tags are very similar to branches, but don't move with new commits, instead permanently identifying individual commits by human-readable names. Most commonly, tags are used to denote particular versions, allowing commands likegit checkout v1.0to work like you'd hope.git cherry-pick— Cherry picking allows you to select a subset of commits from a different branch, rather than merging the entire thing in at once. This is very useful in breaking merge operations down into more manageable pieces, or for amending other people's pull requests.