Building a Simple Recommendation System in FSharp¶
Introduction¶
This year, I decided to work on a Simple Recommender for TMDB (The Movie Database) data that can be found here. I'd like to keep this article as lucid as possible with the least amount of dependencies and ceremony to highlight the ease of the domain modelling, tooling and data manipulation functionality in F#. Recommendations are given on the basis of the metadata of the movie inputted based on the genres, keywords, overview, production studio and popularity score.
This notebook is written using .NET Jupyter Notebooks whose instructions to get started can be found here. The impetus behind writing this post was to help me and others better understand the internals of a very simple Recommendation System but also to exemplify the now improving strength of the .NET ecosystem to conduct experiments by the means of a Jupyter Notebook.
The Plan¶
- We will load the CSV file, extract and clean the pertinent fields and create domain based objects off the data.
- We will create a vector that gives us the frequencies of individual words in a word soup.
- We will create functions that compute a
distancebetween the word frequency vectors and popularity of two different movies. - We will give recommendations based on the movie inputted by the user.
Data Processing¶
The first step involves installing all the pertinent nuget packages, which can be done in the following manner in addition to importing the relevant paths and setting the path to the csv containing all the data appropriately:
#r "nuget:MathNet.Numerics"
#r "nuget:MathNet.Numerics.FSharp"
#r "nuget:FSharp.Data"
// Uncomment for the IFSharp Kernel
// #load "Paket.fsx"
// Paket.Package [ "FSharp.Data"; ]
// #load "Paket.Generated.Refs.fsx"
open System
open System.Text
open FSharp.Data
open MathNet.Numerics
open System.Collections.Generic
open Microsoft.FSharp.Collections
[<Literal>]
// Data obtained from: https://www.kaggle.com/tmdb/tmdb-movie-metadata
let DataPath = "/Users/mukundraghavsharma/Desktop/F#/FSharp-Advent-2019/data/tmdb_5000_movies.csv"
=============== S T A R T ========================================== >>>> /Users/mukundraghavsharma/.nuget/packages/fsharp.data/3.3.2/typeproviders/fsharp41/netstandard2.0/FSharp.Data.DesignTime.dll >>>> /Users/mukundraghavsharma/.nuget/packages/fsharp.data/3.3.2/lib/netstandard2.0/FSharp.Data.DesignTime.dll Using: /Users/mukundraghavsharma/.nuget/packages/fsharp.data/3.3.2/typeproviders/fsharp41/netstandard2.0/FSharp.Data.DesignTime.dll
The next step is to conduct a perfunctory data exploration to view the "shape" of the columns we decide to make use of. We'll be making use of the Csv Data Provider from FSharp.Data. Alternatively, I could have used Deedle for this task.

let data = CsvFile.Load(DataPath).Cache()
printfn "%A" data.Headers
Some
[|"budget"; "genres"; "homepage"; "id"; "keywords"; "original_language";
"original_title"; "overview"; "popularity"; "production_companies";
"production_countries"; "release_date"; "revenue"; "runtime";
"spoken_languages"; "status"; "tagline"; "title"; "vote_average";
"vote_count"|]
Based on the headers, we will consider engineering 2 features:
- Word Soup: Consisting of sanitized tokens (words) based on the genres, keywords, production companies and overview.
- Similar movies would have similar genres, keywords, production companies and words in the overview and therefore could lead to good recommendations.
- Popularity: A popularity score from TMDB.
To get a sense of the shape of the data contained in the columns, let's write a helper function that gets us the first item in the column.
let getFirstItemInColumn (colName : string) =
seq { for row in data.Rows -> row.GetColumn colName }
|> Seq.head
Genres¶
getFirstItemInColumn "genres"
[{"id": 28, "name": "Action"}, {"id": 12, "name": "Adventure"}, {"id": 14, "name": "Fantasy"}, {"id": 878, "name": "Science Fiction"}]
Keywords¶
getFirstItemInColumn "keywords"
[{"id": 1463, "name": "culture clash"}, {"id": 2964, "name": "future"}, {"id": 3386, "name": "space war"}, {"id": 3388, "name": "space colony"}, {"id": 3679, "name": "society"}, {"id": 3801, "name": "space travel"}, {"id": 9685, "name": "futuristic"}, {"id": 9840, "name": "romance"}, {"id": 9882, "name": "space"}, {"id": 9951, "name": "alien"}, {"id": 10148, "name": "tribe"}, {"id": 10158, "name": "alien planet"}, {"id": 10987, "name": "cgi"}, {"id": 11399, "name": "marine"}, {"id": 13065, "name": "soldier"}, {"id": 14643, "name": "battle"}, {"id": 14720, "name": "love affair"}, {"id": 165431, "name": "anti war"}, {"id": 193554, "name": "power relations"}, {"id": 206690, "name": "mind and soul"}, {"id": 209714, "name": "3d"}]
Production Company¶
getFirstItemInColumn "production_companies"
[{"name": "Ingenious Film Partners", "id": 289}, {"name": "Twentieth Century Fox Film Corporation", "id": 306}, {"name": "Dune Entertainment", "id": 444}, {"name": "Lightstorm Entertainment", "id": 574}]
It seems like we'll need to parse the JSON and grab the name field off the payload for all the aforementioned cases.
Overview¶
getFirstItemInColumn "overview"
In the 22nd century, a paraplegic Marine is dispatched to the moon Pandora on a unique mission, but becomes torn between following orders and protecting an alien civilization.
Popularity¶
getFirstItemInColumn "popularity"
150.437577
Based on the samples of the columns considered, it seems like we'll need to sanitize the data extensively. Before we do so, let's define the domain objects we will be dealing with.
Domain¶
The pertinent columns for a movie we decided on were:
- Genres
- Keywords
- Overview
- Production Company
- Popularity
And therefore, we'd like to model the domain accordingly. We introduce a word soup and a soup list, which comprise of a concatenation of all the sanitized tokens and list of tokens of fields 1 through 4, respectively. We will extract the popularity of a movie as well and some other lists that can help us better filter.
type MovieData = { title : string;
soup : string;
soupList : string list;
genreList : string list;
prodCompanyList : string list;
popularity : double; }
Tokenization and Token Sanitization¶
Now that we are set on the domain, we need to write some auxiliary methods to sanitize the tokenized data appropriately. As a part of the token sanitization process, we will be conducting the following steps:
- Lower casing all the tokenized words: We do this to make the tokens case-agnostic so that our algorithms don't distinguish between 'Adventure' and 'adventure'.
- Removing Common Stop Words: Common stop words such as hers, again, there don't add any domain specific information about the movie and therefore can be removed as those will just add noise to our algorithm.
- Removing Punctuation: Punctuation that has no meaning in the context of tokens that can affect the algorithm. For example, without removing punctuation, we will be treating 'thief' and 'thief.' as two different tokens. Additionally, we will get rid of any non-ASCII characters here.
- Removing any empty string: Empty string will just add more noise. It's good to get rid of them early on.
let tokenizeAndClean (words : string) =
// Tokenize
let split = words.Split(' ')
// Lowercase
let lowered =
split
|> Array.map(fun s -> s.ToLower())
// Remove Common Stop Words that don't add meaning
let commonStopWords =
Set.ofList ["ourselves"; "hers"; "between"; "yourself"; "but"; "again"; "there"; "about"; "once"; "during"; "out"; "very"; "having"; "with"; "they"; "own"; "an"; "be"; "some"; "for"; "do"; "its"; "yours"; "such"; "into"; "of"; "most"; "itself"; "other"; "off"; "is"; "s"; "am"; "or"; "who"; "as"; "from"; "him"; "each"; "the"; "themselves"; "until"; "below"; "are"; "we"; "these"; "your"; "his"; "through"; "don"; "nor"; "me"; "were"; "her"; "more"; "himself"; "this"; "down"; "should"; "our"; "their"; "while"; "above"; "both"; "up"; "to"; "ours"; "had"; "she"; "all"; "no"; "when"; "at"; "any"; "before"; "them"; "same"; "and"; "been"; "have"; "in"; "will"; "on"; "does"; "yourselves"; "then"; "that"; "because"; "what"; "over"; "why"; "so"; "can"; "did"; "not"; "now"; "under"; "he"; "you"; "herself"; "has"; "just"; "where"; "too"; "only"; "myself"; "which"; "those"; "i"; "after"; "few"; "whom"; "t"; "being"; "if"; "theirs"; "my"; "against"; "a"; "by"; "doing"; "it"; "how"; "further"; "was"; "here"; "than"]
let notStopWords =
lowered
|> Array.filter(fun s -> not (Set.contains s commonStopWords))
// Remove Punctuation
let nonPunctuation =
notStopWords
|> Array.map(fun x -> x.Replace("�", "")
.Replace("'", "")
.Replace(":", "")
.Replace(".", "")
.Replace(",", "")
.Replace("-", "")
.Replace("!", "")
.Replace("?", "")
.Replace("\"", "")
.Replace(";", ""))
let removeEmptyStrings =
nonPunctuation
|> Array.filter(fun x -> not (String.IsNullOrEmpty x))
// Lexicographically sort
let sorted = Array.sort removeEmptyStrings
// Concatenate the joined data
sorted
|> Array.toList
Now that we have established the "cleanliness of tokens" contract, let's give the function to do so a quick spin.
let sample = "The quick brown. fox jumps! over the; Lazy dog"
let tokenizedSample = tokenizeAndClean sample
tokenizedSample
| index | value |
|---|---|
| 0 | brown |
| 1 | dog |
| 2 | fox |
| 3 | jumps |
| 4 | lazy |
| 5 | quick |
| 6 | the |
Column Extraction Functions¶
As we have seen before, we'll need to parse a couple of JSON fields to get the appropriate data to create the word soup. For this task, we'll be continuing to make use of FSharp.Data's Json Provider that simply works on specifying a pattern and then making use of the pattern to extract information from other patterns. We will write other helper functions that grab us this information from each row of the dataset.
// Genre
[<Literal>]
let SampleGenresJson = "[{\"id\": 28, \"name\": \"Action\"}, {\"id\": 12, \"name\": \"Adventure\"}, {\"id\": 80, \"name\": \"Crime\"}]"
type GenreProvider = JsonProvider< SampleGenresJson >
let sanitizeGenre (genres : string) : string list =
let parsed = GenreProvider.Parse(genres)
parsed
|> Array.map(fun x -> x.Name.Replace(" ", ""))
|> String.concat " "
|> tokenizeAndClean
// Keywords
[<Literal>]
let SampleKeywordsJson = "[{\"id\": 1463, \"name\": \"culture clash\"}, {\"id\": 2964, \"name\": \"future\"}, {\"id\": 3386, \"name\": \"space war\"}]"
type KeywordsProvider = JsonProvider< SampleKeywordsJson >
let sanitizeKeywords (keywords : string) : string list =
let parsed = KeywordsProvider.Parse(keywords)
parsed
|> Array.map(fun x -> x.Name.Replace(" ", ""))
|> String.concat " "
|> tokenizeAndClean
// Overview
let sanitizeOverview (overview : string) : string list =
let nonAsciiRemoved = Encoding.ASCII.GetString(Encoding.ASCII.GetBytes(overview))
tokenizeAndClean nonAsciiRemoved
|> List.filter(fun x -> x <> String.Empty)
// Production Company
[<Literal>]
let ProductionCompanyJson = "[{\"name\": \"Ingenious Film Partners\", \"id\": 289}, {\"name\": \"Twentieth Century Fox Film Corporation\", \"id\": 306}, {\"name\": \"Dune Entertainment\", \"id\": 444}, {\"name\": \"Lightstorm Entertainment\", \"id\": 574}]"
type ProductionCompanyProvider = JsonProvider< ProductionCompanyJson >
let sanitizeProductionCompany (productionCompany : string) : string list =
let parsed = ProductionCompanyProvider.Parse(productionCompany)
parsed
|> Array.map(fun x -> x.Name.Replace(" ", "")) // Lightstorm Entertainment -> LightstormEntertainment
|> String.concat " "
|> tokenizeAndClean
Load Data¶
We have now developed all the individual components to create the domain objects. Let's combine them all together in one function extractData to give us a Sequence of extracted domain objects.
This function does the following:
- Iterates over the data rows
- For each row, it extracts the title, genres, keywords, overview and production company and converts the details into a word soup and a soup list using the functions created before.
- The popularity is also extracted in a similar fashion.
- A new
MovieComparisonDataitem is created and stored in a running list that's returned as a sequence.
// Wrapper function that gets a sequence of all the domain objects.
let extractData =
let data = CsvFile.Load(DataPath).Cache()
let mutable output = []
for row in data.Rows do
let title = (row.GetColumn "title")
// Genres
let genres = sanitizeGenre (row.GetColumn "genres")
let getSoupGenres = genres |> String.concat " "
// Keywords
let keywords = sanitizeKeywords (row.GetColumn "keywords")
let getSoupKeyword = keywords |> String.concat " "
// Overview
let overview = sanitizeOverview (row.GetColumn "overview")
let getSoupOverview = overview |> String.concat " "
// Production Company
let productionCompany = sanitizeProductionCompany (row.GetColumn "production_companies")
let getSoupProductionCompany = productionCompany |> String.concat " "
// Soup
let soup = getSoupGenres + " " + getSoupKeyword + " " + getSoupOverview + " " + getSoupProductionCompany
let soupList = genres @ keywords @ overview @ productionCompany
// Popularity
let popularity = double(row.GetColumn "popularity")
// Construct data type
let movieData = { title = title;
soup = soup;
popularity = popularity;
genreList = genres;
prodCompanyList = productionCompany;
soupList = soupList }
// Append the output
output <- output @ [movieData]
output
|> Seq.ofList
For ease of use, since we'll expect the client to request a movie in the form of a string, we'll create another function that stores all the MovieData in a dictionary keyed off the movie title.
// Function that wraps the extractData functionality in a dictionary for ease of use.
let getDictOfData =
let out = Dictionary<string, MovieData>()
for w in extractData do
out.[w.title] <- w
out
// Test Function
getDictOfData
|> Seq.take 5
| index | Key | Value |
|---|---|---|
| 0 | Avatar | { FSI_0013+MovieData: title: Avatar, soup: action adventure fantasy sciencefiction 3d alien alienplanet antiwar battle cgi cultureclash future futuristic loveaffair marine mindandsoul powerrelations romance society soldier space spacecolony spacetravel spacewar tribe 22nd alien becomes century civilization dispatched following marine mission moon orders pandora paraplegic protecting torn unique duneentertainment ingeniousfilmpartners lightstormentertainment twentiethcenturyfoxfilmcorporation, soupList: [ action, adventure, fantasy, sciencefiction, 3d, alien, alienplanet, antiwar, battle, cgi ... (35 more) ], genreList: [ action, adventure, fantasy, sciencefiction ], prodCompanyList: [ duneentertainment, ingeniousfilmpartners, lightstormentertainment, twentiethcenturyfoxfilmcorporation ], popularity: 150.437577 } |
| 1 | Pirates of the Caribbean: At World's End | { FSI_0013+MovieData: title: Pirates of the Caribbean: At World's End, soup: action adventure fantasy aftercreditsstinger afterlife alliance calypso drugabuse eastindiatradingcompany exoticisland fighter loveofoneslife ocean pirate ship shipwreck strongwoman swashbuckler traitor back barbossa believed captain come dead earth edge elizabeth headed life long nothing quite seems swann turner jerrybruckheimerfilms secondmateproductions waltdisneypictures, soupList: [ action, adventure, fantasy, aftercreditsstinger, afterlife, alliance, calypso, drugabuse, eastindiatradingcompany, exoticisland ... (29 more) ], genreList: [ action, adventure, fantasy ], prodCompanyList: [ jerrybruckheimerfilms, secondmateproductions, waltdisneypictures ], popularity: 139.082615 } |
| 2 | Spectre | { FSI_0013+MovieData: title: Spectre, soup: action adventure crime basedonnovel britishsecretservice mi6 secretagent sequel spy unitedkingdom alive back battles behind bond bonds cryptic deceit forces keep layers m message organization past peels political reveal secret sends service sinister spectre terrible trail truth uncover b24 columbiapictures danjaq, soupList: [ action, adventure, crime, basedonnovel, britishsecretservice, mi6, secretagent, sequel, spy, unitedkingdom ... (30 more) ], genreList: [ action, adventure, crime ], prodCompanyList: [ b24, columbiapictures, danjaq ], popularity: 107.376788 } |
| 3 | The Dark Knight Rises | { FSI_0013+MovieData: title: The Dark Knight Rises, soup: action crime drama thriller batman burglar catburglar catwoman coverup crimefighter criminalunderworld dccomics destruction flood gothamcity hostagedrama imax secretidentity superhero terrorism terrorist timebomb tragichero vigilante villainess assumes attorney attorneys bane batman batman branded city city crimes dark death dent dents department district eight encounters enemy finest following gotham gothams harvey hunted knight kyle late later leader mysterious new overwhelms police protect protect reputation responsibility resurfaces selina subsequently terrorist villainous years dcentertainment legendarypictures syncopy warnerbros, soupList: [ action, crime, drama, thriller, batman, burglar, catburglar, catwoman, coverup, crimefighter ... (63 more) ], genreList: [ action, crime, drama, thriller ], prodCompanyList: [ dcentertainment, legendarypictures, syncopy, warnerbros ], popularity: 112.31295 } |
| 4 | John Carter | { FSI_0013+MovieData: title: John Carter, soup: action adventure sciencefiction 19thcentury 3d alien alienrace basedonnovel edgarriceburroughs escape mars marscivilization martian medallion princess spacetravel steampunk superhumanstrength swordandplanet (mars) barsoom barsoom becomes brink captain carter carter collapse conflict embroiled epic exotic former hands humanity inexplicably its john military mysterious people planet realizes rediscovers reluctantly rests survival transported warweary whos world waltdisneypictures, soupList: [ action, adventure, sciencefiction, 19thcentury, 3d, alien, alienrace, basedonnovel, edgarriceburroughs, escape ... (42 more) ], genreList: [ action, adventure, sciencefiction ], prodCompanyList: [ waltdisneypictures ], popularity: 43.926995 } |
Feature Vector Helpers¶
Now that we have the domain objects appropriately created, we'll need get the vector of the frequency of tokens and popularity. Our distance function will then compare the distance between the feature vector of different movies. The higher the distance, the less similar the words.
To generate the feature vectors, we'll need to be consistent about what we consider a feature vector to compare apples to apples. For this we'll be grabbing all the distinct words from the flattened soup list of all the movies and then computing the frequency of all the words. Finally, as the last element of the list, we'll be including the popularity score so that we just need to deal with a single vector of data.
NOTE: Vector here is used interchangably with an array to keep the language consistent with other Data Science based terminology.
The helper functions are as follows:
getAllWords: Gets the unique words from all the soup lists.getFeatureDictByMovieData: Grabs a movie data record and creates a dictionary based on the frequency of the individual words and the popularity.getFeatureDict: Wraps the functionality fromgetFeatureDictByMovieDatabut takes the movie name as an input.getFeatureVector: Returns the values of the feature dictionary for a particular movie title.
// Function gets all the distinct words from the soup list
let getAllWords =
extractData
|> Seq.map(fun x -> x.soupList)
|> Seq.concat
|> Seq.distinct
// Function to get the word frequency for a particular movie and then add the popularity to the end of the dictionary
let getFeatureDictByMovieData (movieCompare : MovieData) =
let wordFrequency = new Dictionary<string, double>()
for w in getAllWords do
let count =
movieCompare.soupList
|> List.filter(fun x -> x = w)
|> List.length
let countAsDouble = double(count)
if not (wordFrequency.ContainsKey w) then wordFrequency.[w] <- countAsDouble
else wordFrequency.[w] <- wordFrequency.[w] + countAsDouble
wordFrequency.[";popularity_score;"] <- movieCompare.popularity
wordFrequency
// Function to get feature dictionary
let getFeatureDict (movieName : string) =
if getDictOfData.ContainsKey movieName then getFeatureDictByMovieData getDictOfData.[movieName]
else
failwith "Movie Not Found!"
// Function to get the feature vector i.e. values in the feature dictionary
let getFeatureVector(movieName : string) =
let featureDict = getFeatureDict movieName
featureDict
|> Seq.map(fun x -> x.Value)
|> Seq.toArray
Let's try to get the feature vector for Avatar and The Dark Knight Rises.
printfn "Avatar Feature Dictionary:"
let avatarVector = getFeatureDict "Avatar"
printfn "%A" avatarVector
printfn "Popularity Score: %A\n" (avatarVector.[";popularity_score;"])
printfn "%A" (getFeatureVector "Avatar")
printfn "The Dark Knight Rises Feature Dictionary:"
let darkKnightVector = getFeatureDict "The Dark Knight Rises"
printfn "%A" darkKnightVector
printfn "Popularity Score: %A" (darkKnightVector.[";popularity_score;"])
printfn "%A" (getFeatureVector "The Dark Knight Rises")
Avatar Feature Dictionary: seq [[action, 1]; [adventure, 1]; [fantasy, 1]; [sciencefiction, 1]; ...] Popularity Score: 150.437577 [|1.0; 1.0; 1.0; 1.0; 1.0; 2.0; 1.0; 1.0; 1.0; 1.0; 1.0; 1.0; 1.0; 1.0; 2.0; 1.0; 1.0; 1.0; 1.0; 1.0; 1.0; 1.0; 1.0; 1.0; 1.0; 1.0; 1.0; 1.0; 1.0; 1.0; 1.0; 1.0; 1.0; 1.0; 1.0; 1.0; 1.0; 1.0; 1.0; 1.0; 1.0; 1.0; 1.0; 0.0; 0.0; 0.0; 0.0; 0.0; 0.0; 0.0; 0.0; 0.0; 0.0; 0.0; 0.0; 0.0; 0.0; 0.0; 0.0; 0.0; 0.0; 0.0; 0.0; 0.0; 0.0; 0.0; 0.0; 0.0; 0.0; 0.0; 0.0; 0.0; 0.0; 0.0; 0.0; 0.0; 0.0; 0.0; 0.0; 0.0; 0.0; 0.0; 0.0; 0.0; 0.0; 0.0; 0.0; 0.0; 0.0; 0.0; 0.0; 0.0; 0.0; 0.0; 0.0; 0.0; 0.0; 0.0; 0.0; 0.0; ...|] The Dark Knight Rises Feature Dictionary: seq [[action, 1]; [adventure, 0]; [fantasy, 0]; [sciencefiction, 0]; ...] Popularity Score: 112.31295 [|1.0; 0.0; 0.0; 0.0; 0.0; 0.0; 0.0; 0.0; 0.0; 0.0; 0.0; 0.0; 0.0; 0.0; 0.0; 0.0; 0.0; 0.0; 0.0; 0.0; 0.0; 0.0; 0.0; 0.0; 0.0; 0.0; 0.0; 0.0; 0.0; 0.0; 1.0; 0.0; 0.0; 0.0; 0.0; 0.0; 0.0; 0.0; 0.0; 0.0; 0.0; 0.0; 0.0; 0.0; 0.0; 0.0; 0.0; 0.0; 0.0; 0.0; 0.0; 0.0; 0.0; 0.0; 0.0; 0.0; 0.0; 0.0; 0.0; 0.0; 0.0; 0.0; 0.0; 0.0; 0.0; 0.0; 0.0; 0.0; 0.0; 0.0; 0.0; 0.0; 0.0; 0.0; 0.0; 0.0; 0.0; 0.0; 0.0; 1.0; 0.0; 0.0; 0.0; 0.0; 0.0; 0.0; 0.0; 0.0; 0.0; 0.0; 0.0; 0.0; 0.0; 0.0; 0.0; 0.0; 0.0; 0.0; 0.0; 0.0; ...|]
Cosine Distance¶
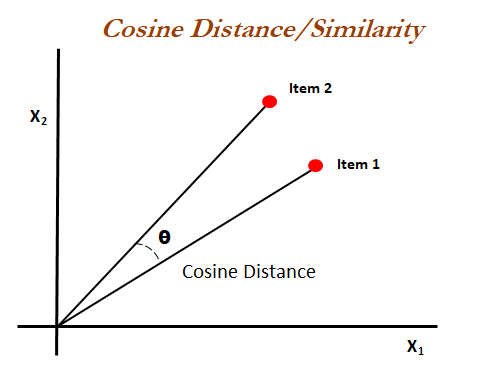
We need to numerically compute a difference between the feature vectors of two different movies and this is where the distance function comes into place. Specifically, we'll be making use of the Cosine Distance functionality to compute this difference.
Cosine Distance is given by:
$ 1 - \frac{\arccos(\text{cosine_similarity(u, v)})}{\pi} $
where:
$ \text{cosine_similarity(u, v)}= \frac{(u . v)}{ (||u|| . ||v||)} $
u and v are both input vectors.
We will be using the cosine distance functionality from the MathNet.Numerics library to compute distances between the feature vectors defined above.
Why Cosine Distance vs. Cosine Similarity?¶
According to this paper by Google, Cosine distance performs better than raw cosine similarity to compute the difference between two vectors. Thought I'd give it a shot! Inituitively, the angular distance is better at capturing the difference than simply the distance.
let x : double[] = [| 3.; 1. |]
let y : double[] = [| 3.; 3. |]
printfn "Cosine Distance when values are equal: %A" (Distance.Cosine(x, x))
printfn "Cosine Distance when values are different: %A" (Distance.Cosine(x, y))
Cosine Distance when values are equal: 0.0 Cosine Distance when values are different: 0.105572809
Now that we have seen the Cosine Distance usage, let's compute the cosine distance of two movies by first encapsulating the behavior into a function.
let computeCosineDistance (movie1 : string) (movie2 : string) : double =
// Feature Vector
let movie1Vector = getFeatureVector movie1
let movie2Vector = getFeatureVector movie2
// Compute the Cosine distance in the case the movies exist
Distance.Cosine(movie1Vector, movie2Vector)
computeCosineDistance "Avatar" "The Dark Knight Rises"
0.004311626155728665
As we can see Avatar and The Dark Knight Rises are considered to be somewhat similar based on the word soup and popularity.
Recommendations¶
Now that we have all the pieces to get our recommendations in place, we can easily wrap up the logic into one function that takes in the movie name and number of recommendations and returns back a list of tuples comprising of the name of recommended movie and the cosine distance. As mentioned before the higher the cosine distance, the more dissimilar the movie and therefore, we'd like to sort the cosine distances to take the top results.
let recommendMovies (movie : string) (recommendationCount : int) =
// Check if two lists contain any intersection - will be using this function to
let setIntersect listA listB =
Set.intersect (Set.ofList listA) (Set.ofList listB)
|> Set.isEmpty
|> not
// Filter out any unrelated movies to improve computation
let filterOutMoviesNotRelated (movie1 : MovieData) (movie2 : MovieData) =
// Filtering mechanism: If the movies don't have any genres in common, don't even consider.
let checkIfGenresExist (movie1 : MovieData) (movie2 : MovieData) =
let movie1Genres = movie1.genreList
let movie2Genres = movie2.genreList
setIntersect movie1Genres movie2Genres
// Filtering mechanism: If the movies don't have any production companies in common, don't even consider.
let checkIfProductionCompaniesExist (movie1 : MovieData) (movie2 : MovieData) =
let movie1ProdCompany = movie1.prodCompanyList
let movie2ProdCompany = movie2.prodCompanyList
setIntersect movie1ProdCompany movie2ProdCompany
(checkIfGenresExist movie1 movie2) && (checkIfProductionCompaniesExist movie1 movie2)
if getDictOfData.ContainsKey movie then
let movieData = getDictOfData.[movie]
getDictOfData
// Don't include the current item in question nor any other movie not of any of the genres of the movie
|> Seq.filter(fun x -> not(x.Value = movieData) && ( filterOutMoviesNotRelated movieData x.Value ))
// Grab a tuple of the title and cosine distance
|> Seq.map(fun x -> (x.Value.title, computeCosineDistance movie x.Value.title))
// Remove NaNs
|> Seq.filter(fun x -> not(System.Double.IsNaN(snd x)))
// Sort by distance
|> Seq.sortBy(fun x -> snd x)
// Take only the specified recommendation counts
|> Seq.take recommendationCount
// Convert to list
|> Seq.toList
else
failwith "Movie not found!"
Let's try getting recommendations for "The Dark Knight Rises"

let results =
(recommendMovies "The Dark Knight Rises" 10)
|> List.iter(fun x -> printfn "%A %A" (fst x) (snd x))
results
"The Dark Knight" 0.003000627894 "Interstellar" 0.003353724178 "Jurassic World" 0.003409615892 "Mad Max: Fury Road" 0.003462151342 "Inception" 0.003885255409 "Batman v Superman: Dawn of Justice" 0.003924230513 "Batman Begins" 0.004095903565 "One Flew Over the Cuckoo's Nest" 0.004436711406 "San Andreas" 0.004675560828 "Man of Steel" 0.004890483474
Not bad! The Dark Knight is the most similar to The Dark Knight Rises. Followed by another Christopher Nolan classic "Interstellar" that is probably equally as popular. The remainder of the movies follow a similar theme of superhero, Christopher Nolan, action based plots. One Flew Over the Cuckoo's Nest seems to be the anomaly here, though!
Conclusion¶
F# made it incredibly conducive to create a simple recommendation system! It was great fun writing this blogpost and learning about the data science tools available in the ecosystem.
The next steps of this project could be to create more specialized and advanced recommendation systems and study the behavior of different distance functions. The current recommendation system is fairly slow; I'll also want to optimize the vector creation process in the next iteration.