Computer Vision¶
In this notebook we're going to cover the basics of computer vision using CNNs. So far we've explored using CNNs for text but their initial origin began with computer vision tasks.
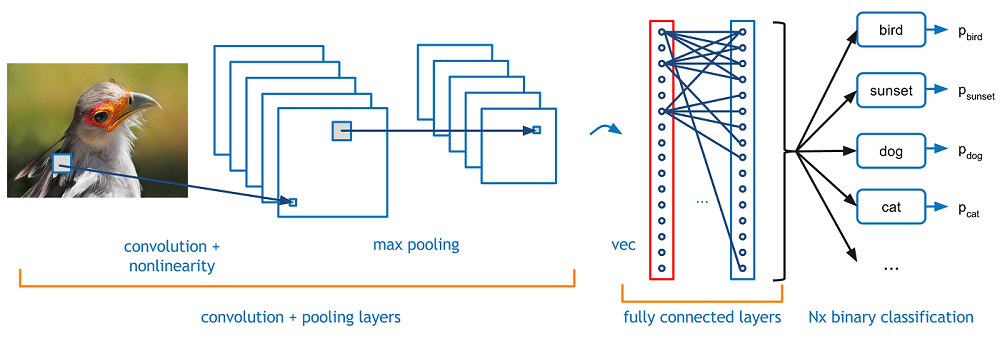
Set up¶
!pip3 install torch torchvision
!pip install Pillow==4.0.0
!pip install PIL
!pip install image
import os
from argparse import Namespace
import collections
import json
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
from PIL import Image
import re
import torch
# Set Numpy and PyTorch seeds
def set_seeds(seed, cuda):
np.random.seed(seed)
torch.manual_seed(seed)
if cuda:
torch.cuda.manual_seed_all(seed)
# Creating directories
def create_dirs(dirpath):
if not os.path.exists(dirpath):
os.makedirs(dirpath)
Data¶
We're going to first get some data. A popular computer vision classification dataset is CIFAR10 which contains images from ten unique classes.
# Don't worry we aren't using tensorflow, just using it to get some data
import tensorflow as tf
import matplotlib.pyplot as plt
# Load data and combine
(x_train, y_train), (x_test, y_test) = tf.keras.datasets.cifar10.load_data()
X = np.vstack([x_train, x_test])
y = np.vstack([y_train, y_test]).squeeze(1)
print ("x:", X.shape)
print ("y:", y.shape)
Downloading data from https://www.cs.toronto.edu/~kriz/cifar-10-python.tar.gz 170500096/170498071 [==============================] - 50s 0us/step x: (60000, 32, 32, 3) y: (60000,)
Each image has length 32, width 32 and three color channels (RGB). We are going to save these images in a directory. Each image will have it's own directory (name will be the class).
!rm -rf cifar10_data
# Classes
classes = {0: 'plane', 1: 'car', 2: 'bird', 3: 'cat', 4: 'deer', 5: 'dog',
6: 'frog', 7: 'horse', 8: 'ship', 9: 'truck'}
# Create image directories
data_dir = "cifar10_data"
os.mkdir(data_dir)
for _class in classes.values():
os.mkdir(os.path.join(data_dir, _class))
# Save images for each class
for i, (image, label) in enumerate(zip(X, y)):
_class = classes[label]
im = Image.fromarray(image)
im.save(os.path.join(data_dir, _class, "{0:02d}.png".format(i)))
# Visualize some samples
num_samples = len(classes)
for i, _class in enumerate(classes.values()):
for file in os.listdir(os.path.join(data_dir, _class)):
if file.endswith(".png"):
plt.subplot(1, num_samples, i+1)
plt.title("{0}".format(_class))
img = Image.open(os.path.join(data_dir, _class, file))
plt.imshow(img)
plt.axis("off")
break

Classification¶
Our task will be to classify the class given the image. We're going to architect a basic CNN to process the input images and produce a classification.
Arguments¶
With image data, we won't be save our split data files. We will only read from the image directory.
args = Namespace(
seed=1234,
cuda=True,
shuffle=True,
data_dir="cifar10_data",
vectorizer_file="vectorizer.json",
model_state_file="model.pth",
save_dir="cifar10_model",
train_size=0.7,
val_size=0.15,
test_size=0.15,
num_epochs=10,
early_stopping_criteria=5,
learning_rate=1e-3,
batch_size=128,
num_filters=100,
hidden_dim=100,
dropout_p=0.1,
)
# Set seeds
set_seeds(seed=args.seed, cuda=args.cuda)
# Create save dir
create_dirs(args.save_dir)
# Expand filepaths
args.vectorizer_file = os.path.join(args.save_dir, args.vectorizer_file)
args.model_state_file = os.path.join(args.save_dir, args.model_state_file)
# Check CUDA
if not torch.cuda.is_available():
args.cuda = False
args.device = torch.device("cuda" if args.cuda else "cpu")
print("Using CUDA: {}".format(args.cuda))
Using CUDA: True
Data¶
# Convert image file to NumPy array
def img_to_array(fp):
img = Image.open(fp)
array = np.asarray(img, dtype="float32")
return array
# Load data
data = []
for i, _class in enumerate(classes.values()):
for file in os.listdir(os.path.join(data_dir, _class)):
if file.endswith(".png"):
full_filepath = os.path.join(data_dir, _class, file)
data.append({"image": img_to_array(full_filepath), "category": _class})
# Convert to Pandas DataFrame
df = pd.DataFrame(data)
print ("Image shape:", df.image[0].shape)
df.head()
Image shape: (32, 32, 3)
| category | image | |
|---|---|---|
| 0 | plane | [[[160.0, 173.0, 167.0], [151.0, 164.0, 155.0]... |
| 1 | plane | [[[190.0, 228.0, 243.0], [188.0, 223.0, 238.0]... |
| 2 | plane | [[[255.0, 255.0, 255.0], [253.0, 254.0, 251.0]... |
| 3 | plane | [[[193.0, 216.0, 227.0], [191.0, 213.0, 225.0]... |
| 4 | plane | [[[234.0, 234.0, 234.0], [231.0, 231.0, 231.0]... |
by_category = collections.defaultdict(list)
for _, row in df.iterrows():
by_category[row.category].append(row.to_dict())
for category in by_category:
print ("{0}: {1}".format(category, len(by_category[category])))
plane: 6000 car: 6000 bird: 6000 cat: 6000 deer: 6000 dog: 6000 frog: 6000 horse: 6000 ship: 6000 truck: 6000
final_list = []
for _, item_list in sorted(by_category.items()):
if args.shuffle:
np.random.shuffle(item_list)
n = len(item_list)
n_train = int(args.train_size*n)
n_val = int(args.val_size*n)
n_test = int(args.test_size*n)
# Give data point a split attribute
for item in item_list[:n_train]:
item['split'] = 'train'
for item in item_list[n_train:n_train+n_val]:
item['split'] = 'val'
for item in item_list[n_train+n_val:]:
item['split'] = 'test'
# Add to final list
final_list.extend(item_list)
split_df = pd.DataFrame(final_list)
split_df["split"].value_counts()
train 42000 test 9000 val 9000 Name: split, dtype: int64
Vocabulary¶
class Vocabulary(object):
def __init__(self, token_to_idx=None):
# Token to index
if token_to_idx is None:
token_to_idx = {}
self.token_to_idx = token_to_idx
# Index to token
self.idx_to_token = {idx: token \
for token, idx in self.token_to_idx.items()}
def to_serializable(self):
return {'token_to_idx': self.token_to_idx}
@classmethod
def from_serializable(cls, contents):
return cls(**contents)
def add_token(self, token):
if token in self.token_to_idx:
index = self.token_to_idx[token]
else:
index = len(self.token_to_idx)
self.token_to_idx[token] = index
self.idx_to_token[index] = token
return index
def add_tokens(self, tokens):
return [self.add_token[token] for token in tokens]
def lookup_token(self, token):
return self.token_to_idx[token]
def lookup_index(self, index):
if index not in self.idx_to_token:
raise KeyError("the index (%d) is not in the Vocabulary" % index)
return self.idx_to_token[index]
def __str__(self):
return "<Vocabulary(size=%d)>" % len(self)
def __len__(self):
return len(self.token_to_idx)
# Vocabulary instance
category_vocab = Vocabulary()
for index, row in df.iterrows():
category_vocab.add_token(row.category)
print (category_vocab) # __str__
print (len(category_vocab)) # __len__
index = category_vocab.lookup_token("dog")
print (index)
print (category_vocab.lookup_index(index))
<Vocabulary(size=10)> 10 5 dog
Sequence vocbulary¶
from collections import Counter
import string
class SequenceVocabulary():
def __init__(self, train_means, train_stds):
self.train_means = train_means
self.train_stds = train_stds
def to_serializable(self):
contents = {'train_means': self.train_means,
'train_stds': self.train_stds}
return contents
@classmethod
def from_dataframe(cls, df):
train_data = df[df.split == "train"]
means = {0:[], 1:[], 2:[]}
stds = {0:[], 1:[], 2:[]}
for image in train_data.image:
for dim in range(3):
means[dim].append(np.mean(image[:, :, dim]))
stds[dim].append(np.std(image[:, :, dim]))
train_means = np.array((np.mean(means[0]), np.mean(means[1]),
np.mean(means[2])), dtype="float64").tolist()
train_stds = np.array((np.mean(stds[0]), np.mean(stds[1]),
np.mean(stds[2])), dtype="float64").tolist()
return cls(train_means, train_stds)
def __str__(self):
return "<SequenceVocabulary(train_means: {0}, train_stds: {1}>".format(
self.train_means, self.train_stds)
# Create SequenceVocabulary instance
image_vocab = SequenceVocabulary.from_dataframe(split_df)
print (image_vocab) # __str__
<SequenceVocabulary(train_means: [125.44353485107422, 123.07293701171875, 113.99832153320312], train_stds: [51.60729217529297, 50.876190185546875, 51.25827407836914]>
Vectorizer¶
class ImageVectorizer(object):
def __init__(self, image_vocab, category_vocab):
self.image_vocab = image_vocab
self.category_vocab = category_vocab
def vectorize(self, image):
# Avoid modifying the actual df
image = np.copy(image)
# Normalize
for dim in range(3):
mean = self.image_vocab.train_means[dim]
std = self.image_vocab.train_stds[dim]
image[:, :, dim] = ((image[:, :, dim] - mean) / std)
# Reshape frok (32, 32, 3) to (3, 32, 32)
image = np.swapaxes(image, 0, 2)
image = np.swapaxes(image, 1, 2)
return image
@classmethod
def from_dataframe(cls, df):
# Create class vocab
category_vocab = Vocabulary()
for category in sorted(set(df.category)):
category_vocab.add_token(category)
# Create image vocab
image_vocab = SequenceVocabulary.from_dataframe(df)
return cls(image_vocab, category_vocab)
@classmethod
def from_serializable(cls, contents):
image_vocab = SequenceVocabulary.from_serializable(contents['image_vocab'])
category_vocab = Vocabulary.from_serializable(contents['category_vocab'])
return cls(image_vocab=image_vocab,
category_vocab=category_vocab)
def to_serializable(self):
return {'image_vocab': self.image_vocab.to_serializable(),
'category_vocab': self.category_vocab.to_serializable()}
# Vectorizer instance
vectorizer = ImageVectorizer.from_dataframe(split_df)
print (vectorizer.image_vocab)
print (vectorizer.category_vocab)
image_vector = vectorizer.vectorize(split_df.iloc[0].image)
print (image_vector.shape)
<SequenceVocabulary(train_means: [125.44353485107422, 123.07293701171875, 113.99832153320312], train_stds: [51.60729217529297, 50.876190185546875, 51.25827407836914]> <Vocabulary(size=10)> (3, 32, 32)
Dataset¶
from torch.utils.data import Dataset, DataLoader
class ImageDataset(Dataset):
def __init__(self, df, vectorizer):
self.df = df
self.vectorizer = vectorizer
# Data splits
self.train_df = self.df[self.df.split=='train']
self.train_size = len(self.train_df)
self.val_df = self.df[self.df.split=='val']
self.val_size = len(self.val_df)
self.test_df = self.df[self.df.split=='test']
self.test_size = len(self.test_df)
self.lookup_dict = {'train': (self.train_df, self.train_size),
'val': (self.val_df, self.val_size),
'test': (self.test_df, self.test_size)}
self.set_split('train')
# Class weights (for imbalances)
class_counts = df.category.value_counts().to_dict()
def sort_key(item):
return self.vectorizer.category_vocab.lookup_token(item[0])
sorted_counts = sorted(class_counts.items(), key=sort_key)
frequencies = [count for _, count in sorted_counts]
self.class_weights = 1.0 / torch.tensor(frequencies, dtype=torch.float32)
@classmethod
def load_dataset_and_make_vectorizer(cls, df):
train_df = df[df.split=='train']
return cls(df, ImageVectorizer.from_dataframe(train_df))
@classmethod
def load_dataset_and_load_vectorizer(cls, df, vectorizer_filepath):
vectorizer = cls.load_vectorizer_only(vectorizer_filepath)
return cls(df, vectorizer)
def load_vectorizer_only(vectorizer_filepath):
with open(vectorizer_filepath) as fp:
return ImageVectorizer.from_serializable(json.load(fp))
def save_vectorizer(self, vectorizer_filepath):
with open(vectorizer_filepath, "w") as fp:
json.dump(self.vectorizer.to_serializable(), fp)
def set_split(self, split="train"):
self.target_split = split
self.target_df, self.target_size = self.lookup_dict[split]
def __str__(self):
return "<Dataset(split={0}, size={1})".format(
self.target_split, self.target_size)
def __len__(self):
return self.target_size
def __getitem__(self, index):
row = self.target_df.iloc[index]
image_vector = self.vectorizer.vectorize(row.image)
category_index = self.vectorizer.category_vocab.lookup_token(row.category)
return {'image': image_vector,
'category': category_index}
def get_num_batches(self, batch_size):
return len(self) // batch_size
def generate_batches(self, batch_size, shuffle=True, drop_last=True, device="cpu"):
dataloader = DataLoader(dataset=self, batch_size=batch_size,
shuffle=shuffle, drop_last=drop_last)
for data_dict in dataloader:
out_data_dict = {}
for name, tensor in data_dict.items():
out_data_dict[name] = data_dict[name].to(device)
yield out_data_dict
# Dataset instance
dataset = ImageDataset.load_dataset_and_make_vectorizer(split_df)
print (dataset) # __str__
input_ = dataset[10] # __getitem__
print (input_['image'].shape)
category = input_['category']
print (dataset.vectorizer.category_vocab.lookup_index(category))
print (dataset.class_weights)
<Dataset(split=train, size=42000)
(3, 32, 32)
bird
tensor([0.0002, 0.0002, 0.0002, 0.0002, 0.0002, 0.0002, 0.0002, 0.0002, 0.0002,
0.0002])
Model¶
import torch.nn as nn
import torch.nn.functional as F
class ImageModel(nn.Module):
def __init__(self, num_hidden_units, num_classes, dropout_p):
super(ImageModel, self).__init__()
self.conv1 = nn.Conv2d(3, 10, kernel_size=5) # input_channels:3 , output_channels:10 (aka num filters)
self.conv2 = nn.Conv2d(10, 20, kernel_size=5)
self.conv_dropout = nn.Dropout2d(dropout_p)
self.fc1 = nn.Linear(20*5*5, num_hidden_units)
self.dropout = nn.Dropout(dropout_p)
self.fc2 = nn.Linear(num_hidden_units, num_classes)
def forward(self, x, apply_softmax=False):
# Conv pool
z = self.conv1(x) # (N, 10, 28, 28)
z = F.max_pool2d(z, 2) # (N, 10, 14, 14)
z = F.relu(z)
# Conv pool
z = self.conv2(z) # (N, 20, 10, 10)
z = self.conv_dropout(z)
z = F.max_pool2d(z, 2) # (N, 20, 5, 5)
z = F.relu(z)
# Flatten
z = z.view(-1, 20*5*5)
# FC
z = F.relu(self.fc1(z))
z = self.dropout(z)
y_pred = self.fc2(z)
if apply_softmax:
y_pred = F.softmax(y_pred, dim=1)
return y_pred
Training¶
import torch.optim as optim
class Trainer(object):
def __init__(self, dataset, model, model_state_file, save_dir, device,
shuffle, num_epochs, batch_size, learning_rate,
early_stopping_criteria):
self.dataset = dataset
self.class_weights = dataset.class_weights.to(device)
self.device = device
self.model = model.to(device)
self.save_dir = save_dir
self.device = device
self.shuffle = shuffle
self.num_epochs = num_epochs
self.batch_size = batch_size
self.loss_func = nn.CrossEntropyLoss(self.class_weights)
self.optimizer = optim.Adam(self.model.parameters(), lr=learning_rate)
self.scheduler = optim.lr_scheduler.ReduceLROnPlateau(
optimizer=self.optimizer, mode='min', factor=0.5, patience=1)
self.train_state = {
'stop_early': False,
'early_stopping_step': 0,
'early_stopping_best_val': 1e8,
'early_stopping_criteria': early_stopping_criteria,
'learning_rate': learning_rate,
'epoch_index': 0,
'train_loss': [],
'train_acc': [],
'val_loss': [],
'val_acc': [],
'test_loss': -1,
'test_acc': -1,
'model_filename': model_state_file}
def update_train_state(self):
# Verbose
print ("[EPOCH]: {0:02d} | [LR]: {1} | [TRAIN LOSS]: {2:.2f} | [TRAIN ACC]: {3:.1f}% | [VAL LOSS]: {4:.2f} | [VAL ACC]: {5:.1f}%".format(
self.train_state['epoch_index'], self.train_state['learning_rate'],
self.train_state['train_loss'][-1], self.train_state['train_acc'][-1],
self.train_state['val_loss'][-1], self.train_state['val_acc'][-1]))
# Save one model at least
if self.train_state['epoch_index'] == 0:
torch.save(self.model.state_dict(), self.train_state['model_filename'])
self.train_state['stop_early'] = False
# Save model if performance improved
elif self.train_state['epoch_index'] >= 1:
loss_tm1, loss_t = self.train_state['val_loss'][-2:]
# If loss worsened
if loss_t >= self.train_state['early_stopping_best_val']:
# Update step
self.train_state['early_stopping_step'] += 1
# Loss decreased
else:
# Save the best model
if loss_t < self.train_state['early_stopping_best_val']:
torch.save(self.model.state_dict(), self.train_state['model_filename'])
# Reset early stopping step
self.train_state['early_stopping_step'] = 0
# Stop early ?
self.train_state['stop_early'] = self.train_state['early_stopping_step'] \
>= self.train_state['early_stopping_criteria']
return self.train_state
def compute_accuracy(self, y_pred, y_target):
_, y_pred_indices = y_pred.max(dim=1)
n_correct = torch.eq(y_pred_indices, y_target).sum().item()
return n_correct / len(y_pred_indices) * 100
def run_train_loop(self):
for epoch_index in range(self.num_epochs):
self.train_state['epoch_index'] = epoch_index
# Iterate over train dataset
# initialize batch generator, set loss and acc to 0, set train mode on
self.dataset.set_split('train')
batch_generator = self.dataset.generate_batches(
batch_size=self.batch_size, shuffle=self.shuffle,
device=self.device)
running_loss = 0.0
running_acc = 0.0
self.model.train()
for batch_index, batch_dict in enumerate(batch_generator):
# zero the gradients
self.optimizer.zero_grad()
# compute the output
y_pred = self.model(x=batch_dict['image'])
# compute the loss
loss = self.loss_func(y_pred, batch_dict['category'])
loss_t = loss.item()
running_loss += (loss_t - running_loss) / (batch_index + 1)
# compute gradients using loss
loss.backward()
# use optimizer to take a gradient step
self.optimizer.step()
# compute the accuracy
acc_t = self.compute_accuracy(y_pred, batch_dict['category'])
running_acc += (acc_t - running_acc) / (batch_index + 1)
self.train_state['train_loss'].append(running_loss)
self.train_state['train_acc'].append(running_acc)
# Iterate over val dataset
# initialize batch generator, set loss and acc to 0, set eval mode on
self.dataset.set_split('val')
batch_generator = self.dataset.generate_batches(
batch_size=self.batch_size, shuffle=self.shuffle, device=self.device)
running_loss = 0.
running_acc = 0.
self.model.eval()
for batch_index, batch_dict in enumerate(batch_generator):
# compute the output
y_pred = self.model(x=batch_dict['image'])
# compute the loss
loss = self.loss_func(y_pred, batch_dict['category'])
loss_t = loss.to("cpu").item()
running_loss += (loss_t - running_loss) / (batch_index + 1)
# compute the accuracy
acc_t = self.compute_accuracy(y_pred, batch_dict['category'])
running_acc += (acc_t - running_acc) / (batch_index + 1)
self.train_state['val_loss'].append(running_loss)
self.train_state['val_acc'].append(running_acc)
self.train_state = self.update_train_state()
self.scheduler.step(self.train_state['val_loss'][-1])
if self.train_state['stop_early']:
break
def run_test_loop(self):
# initialize batch generator, set loss and acc to 0, set eval mode on
self.dataset.set_split('test')
batch_generator = self.dataset.generate_batches(
batch_size=self.batch_size, shuffle=self.shuffle, device=self.device)
running_loss = 0.0
running_acc = 0.0
self.model.eval()
for batch_index, batch_dict in enumerate(batch_generator):
# compute the output
y_pred = self.model(x=batch_dict['image'])
# compute the loss
loss = self.loss_func(y_pred, batch_dict['category'])
loss_t = loss.item()
running_loss += (loss_t - running_loss) / (batch_index + 1)
# compute the accuracy
acc_t = self.compute_accuracy(y_pred, batch_dict['category'])
running_acc += (acc_t - running_acc) / (batch_index + 1)
self.train_state['test_loss'] = running_loss
self.train_state['test_acc'] = running_acc
def plot_performance(self):
# Figure size
plt.figure(figsize=(15,5))
# Plot Loss
plt.subplot(1, 2, 1)
plt.title("Loss")
plt.plot(trainer.train_state["train_loss"], label="train")
plt.plot(trainer.train_state["val_loss"], label="val")
plt.legend(loc='upper right')
# Plot Accuracy
plt.subplot(1, 2, 2)
plt.title("Accuracy")
plt.plot(trainer.train_state["train_acc"], label="train")
plt.plot(trainer.train_state["val_acc"], label="val")
plt.legend(loc='lower right')
# Save figure
plt.savefig(os.path.join(self.save_dir, "performance.png"))
# Show plots
plt.show()
def save_train_state(self):
with open(os.path.join(self.save_dir, "train_state.json"), "w") as fp:
json.dump(self.train_state, fp)
# Initialization
dataset = ImageDataset.load_dataset_and_make_vectorizer(split_df)
dataset.save_vectorizer(args.vectorizer_file)
vectorizer = dataset.vectorizer
model = ImageModel(num_hidden_units=args.hidden_dim,
num_classes=len(vectorizer.category_vocab),
dropout_p=args.dropout_p)
print (model.named_modules)
<bound method Module.named_modules of ImageModel( (conv1): Conv2d(3, 10, kernel_size=(5, 5), stride=(1, 1)) (conv2): Conv2d(10, 20, kernel_size=(5, 5), stride=(1, 1)) (conv_dropout): Dropout2d(p=0.1) (fc1): Linear(in_features=500, out_features=100, bias=True) (dropout): Dropout(p=0.1) (fc2): Linear(in_features=100, out_features=10, bias=True) )>
# Train
trainer = Trainer(dataset=dataset, model=model,
model_state_file=args.model_state_file,
save_dir=args.save_dir, device=args.device,
shuffle=args.shuffle, num_epochs=args.num_epochs,
batch_size=args.batch_size, learning_rate=args.learning_rate,
early_stopping_criteria=args.early_stopping_criteria)
trainer.run_train_loop()
# Plot performance
trainer.plot_performance()

# Test performance
trainer.run_test_loop()
print("Test loss: {0:.2f}".format(trainer.train_state['test_loss']))
print("Test Accuracy: {0:.1f}%".format(trainer.train_state['test_acc']))
Test loss: 0.94 Test Accuracy: 67.7%
# Save all results
trainer.save_train_state()
~66% test performance for our Cifar10 dataset is not bad but we can do way better.
Transfer learning¶
In this section, we're going to use a pretrained model that performs very well on a different dataset. We're going to take the architecture and the initial convolutional weights from the model to use on our data. We will freeze the initial convolutional weights and fine tune the later convolutional and fully-connected layers.
Transfer learning works here because the initial convolution layers act as excellent feature extractors for common spatial features that are shared across images regardless of their class. We're going to leverage these large, pretrained models' feature extractors for our own dataset.
from torchvision import models
model_names = sorted(name for name in models.__dict__
if name.islower() and not name.startswith("__")
and callable(models.__dict__[name]))
print (model_names)
['alexnet', 'densenet121', 'densenet161', 'densenet169', 'densenet201', 'inception_v3', 'resnet101', 'resnet152', 'resnet18', 'resnet34', 'resnet50', 'squeezenet1_0', 'squeezenet1_1', 'vgg11', 'vgg11_bn', 'vgg13', 'vgg13_bn', 'vgg16', 'vgg16_bn', 'vgg19', 'vgg19_bn']
model_name = 'vgg19_bn'
vgg_19bn = models.__dict__[model_name](pretrained=True) # Set false to train from scratch
print (vgg_19bn.named_parameters)
Downloading: "https://download.pytorch.org/models/vgg19_bn-c79401a0.pth" to /root/.torch/models/vgg19_bn-c79401a0.pth 100%|██████████| 574769405/574769405 [00:29<00:00, 19305160.82it/s]
<bound method Module.named_parameters of VGG(
(features): Sequential(
(0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace)
(3): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(4): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU(inplace)
(6): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(7): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(8): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(9): ReLU(inplace)
(10): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(11): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(12): ReLU(inplace)
(13): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(14): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(15): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(16): ReLU(inplace)
(17): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(18): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(19): ReLU(inplace)
(20): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(21): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(22): ReLU(inplace)
(23): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(24): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(25): ReLU(inplace)
(26): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(27): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(28): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(29): ReLU(inplace)
(30): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(31): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(32): ReLU(inplace)
(33): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(34): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(35): ReLU(inplace)
(36): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(37): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(38): ReLU(inplace)
(39): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(40): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(41): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(42): ReLU(inplace)
(43): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(44): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(45): ReLU(inplace)
(46): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(47): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(48): ReLU(inplace)
(49): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(50): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(51): ReLU(inplace)
(52): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(classifier): Sequential(
(0): Linear(in_features=25088, out_features=4096, bias=True)
(1): ReLU(inplace)
(2): Dropout(p=0.5)
(3): Linear(in_features=4096, out_features=4096, bias=True)
(4): ReLU(inplace)
(5): Dropout(p=0.5)
(6): Linear(in_features=4096, out_features=1000, bias=True)
)
)>
The VGG model we chose has a features and a classifier component. The features component is composed of convolution and pooling layers which act as feature extractors. The classifier component is composed on fully connected layers. We're going to freeze most of the feature component and design our own FC layers for our CIFAR10 task. You can access the default code for all models at /usr/local/lib/python3.6/dist-packages/torchvision/models if you prefer cloning and modifying that instead.
class ImageModel(nn.Module):
def __init__(self, feature_extractor, num_hidden_units,
num_classes, dropout_p):
super(ImageModel, self).__init__()
# Pretrained feature extractor
self.feature_extractor = feature_extractor
# FC weights
self.classifier = nn.Sequential(
nn.Linear(512, 250, bias=True),
nn.ReLU(),
nn.Dropout(0.5),
nn.Linear(250, 100, bias=True),
nn.ReLU(),
nn.Dropout(0.5),
nn.Linear(100, 10, bias=True),
)
def forward(self, x, apply_softmax=False):
# Feature extractor
z = self.feature_extractor(x)
z = z.view(x.size(0), -1)
# FC
y_pred = self.classifier(z)
if apply_softmax:
y_pred = F.softmax(y_pred, dim=1)
return y_pred
# Initialization
dataset = ImageDataset.load_dataset_and_make_vectorizer(split_df)
dataset.save_vectorizer(args.vectorizer_file)
vectorizer = dataset.vectorizer
model = ImageModel(feature_extractor=vgg_19bn.features,
num_hidden_units=args.hidden_dim,
num_classes=len(vectorizer.category_vocab),
dropout_p=args.dropout_p)
print (model.named_parameters)
<bound method Module.named_parameters of ImageModel(
(feature_extractor): Sequential(
(0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace)
(3): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(4): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU(inplace)
(6): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(7): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(8): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(9): ReLU(inplace)
(10): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(11): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(12): ReLU(inplace)
(13): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(14): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(15): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(16): ReLU(inplace)
(17): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(18): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(19): ReLU(inplace)
(20): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(21): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(22): ReLU(inplace)
(23): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(24): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(25): ReLU(inplace)
(26): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(27): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(28): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(29): ReLU(inplace)
(30): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(31): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(32): ReLU(inplace)
(33): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(34): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(35): ReLU(inplace)
(36): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(37): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(38): ReLU(inplace)
(39): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(40): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(41): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(42): ReLU(inplace)
(43): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(44): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(45): ReLU(inplace)
(46): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(47): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(48): ReLU(inplace)
(49): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(50): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(51): ReLU(inplace)
(52): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(classifier): Sequential(
(0): Linear(in_features=512, out_features=250, bias=True)
(1): ReLU()
(2): Dropout(p=0.5)
(3): Linear(in_features=250, out_features=100, bias=True)
(4): ReLU()
(5): Dropout(p=0.5)
(6): Linear(in_features=100, out_features=10, bias=True)
)
)>
# Finetune last few conv layers and FC layers
for i, param in enumerate(model.feature_extractor.parameters()):
if i < 36:
param.requires_grad = False
else:
param.requires_grad = True
# Train
trainer = Trainer(dataset=dataset, model=model,
model_state_file=args.model_state_file,
save_dir=args.save_dir, device=args.device,
shuffle=args.shuffle, num_epochs=args.num_epochs,
batch_size=args.batch_size, learning_rate=args.learning_rate,
early_stopping_criteria=args.early_stopping_criteria)
trainer.run_train_loop()
# Plot performance
trainer.plot_performance()

# Test performance
trainer.run_test_loop()
print("Test loss: {0:.2f}".format(trainer.train_state['test_loss']))
print("Test Accuracy: {0:.1f}%".format(trainer.train_state['test_acc']))
Test loss: 0.53 Test Accuracy: 84.5%
# Save all results
trainer.save_train_state()
Much better performance! If you let it train long enough, we'll actually reah ~95% accuracy :)
Inference¶
from pylab import rcParams
rcParams['figure.figsize'] = 1, 1
class Inference(object):
def __init__(self, model, vectorizer):
self.model = model
self.model.to("cpu")
self.vectorizer = vectorizer
def predict_category(self, image):
# Vectorize
image_vector = self.vectorizer.vectorize(image)
image_vector = torch.tensor(image_vector).unsqueeze(0)
# Forward pass
self.model.eval()
y_pred = self.model(x=image_vector, apply_softmax=True)
# Top category
y_prob, indices = y_pred.max(dim=1)
index = indices.item()
# Predicted category
category = vectorizer.category_vocab.lookup_index(index)
probability = y_prob.item()
return {'category': category, 'probability': probability}
def predict_top_k(self, image, k):
# Vectorize
image_vector = self.vectorizer.vectorize(image)
image_vector = torch.tensor(image_vector).unsqueeze(0)
# Forward pass
self.model.eval()
y_pred = self.model(x=image_vector, apply_softmax=True)
# Top k categories
y_prob, indices = torch.topk(y_pred, k=k)
probabilities = y_prob.detach().numpy()[0]
indices = indices.detach().numpy()[0]
# Results
results = []
for probability, index in zip(probabilities, indices):
category = self.vectorizer.category_vocab.lookup_index(index)
results.append({'category': category, 'probability': probability})
return results
# Get a sample
sample = split_df[split_df.split=="test"].iloc[1000]
# Inference
inference = Inference(model=model, vectorizer=vectorizer)
prediction = inference.predict_category(sample.image)
print ("Actual:", sample.category)
plt.imshow(sample.image)
plt.axis("off")
print("({} → p={:0.2f})".format(prediction['category'],
prediction['probability']))
Actual: car (car → p=1.00)

# # Top-k inference
top_k = inference.predict_top_k(sample.image, k=len(vectorizer.category_vocab))
print ("Actual:", sample.category)
plt.imshow(sample.image)
plt.axis("off")
for result in top_k:
print ("{} → (p={:0.2f})".format(result['category'],
result['probability']))
Actual: car car → (p=1.00) ship → (p=0.00) truck → (p=0.00) plane → (p=0.00) cat → (p=0.00) bird → (p=0.00) frog → (p=0.00) deer → (p=0.00) horse → (p=0.00) dog → (p=0.00)
TODO¶
- segmentation
- interpretability via activation maps
- processing images of different sizes
- save split_dataframe (wiht numpy image arrays) to csv and reload dataframe from csv during inference