
Данный ноутбук является конспектом по курсу «R для теории вероятностей и математической статистики» (РАНХиГС, 2019). Автор ноутбука - вот этот парень по имени Филипп. Если у вас для него есть деньги, слава или женщины, он от этого всего не откажется. Ноутбук распространяется на условиях лицензии Creative Commons Attribution-Share Alike 4.0. При использовании обязательно упоминание автора курса и аффилиации. При наличии технической возможности необходимо также указать активную гиперссылку на страницу курса. На ней можно найти другие материалы. Фрагменты кода, включенные в этот notebook, публикуются как общественное достояние.
В прошлый раз мы с вами поговорили точечные оценки, их свойства и доверительные интервалы. Также мы немного вспомнили метод моментов, который помогает эти самые точечные оценки получать. Сегодня мы во всех подробностях обсудим другой метод получения точечных оценок, метод максимального правдоподобия.
Метод максимального правдоподобия — это основная лошадка современной статистики. Функция правдоподобия встречается абсолютно во всех областях от эконометрики и байесовской статистики до нейронных сетей и рекомендательных систем. Из-за этого очень важно как следует понять как она устроена. В этой тетрадке именно этим мы и займёмся. Итак, сегодня в программе:
- Что такое метод максимального правдоподобия, вырабатываем интуицию
- Решаем задачу про конфеты и смотрим на свойства оценок максимального правдоподобия
- Из метода максимального правдоподобия на нас неожиданно выпрыгивает информация Фишера, разбираемся с тем почему эта штука называется информацией Фишера
- Решаем несколько задачек
- Строим тест отношения правдоподобий (НЕ ПУТАТЬ С ЛЕММОЙ Неймана-Пирсона из ваших лекций, где тоже фигурировало отношение правдоподобий! Это разные вещи!)
library("ggplot2") # Пакет для красивых графиков
library("grid") # Пакет для субплотов
# Отрегулируем размер картинок, которые будут выдаваться в нашей тетрадке
library('repr')
options(repr.plot.width=4, repr.plot.height=3)
# В этом блоке написаны несколько функций, которые рисуют красивые картинки для проверки гипотез.
# Можно не обращать на них внимание :)
# Область, которую надо будет закрасить на графике
limitRange <- function(fun, min, max) {
function(x) {
y <- fun(x)
y[x < min | x > max] <- NA
return(y)
}
}
# Эта страшная функция нужна для карсивых картинок для хи-квадрат распределения
chi_stat_picture <- function(chi_stat, n, alpha =0.05, alternative = 'two-sided'){
# Опции для размеров графика
options(repr.plot.width=6, repr.plot.height=3)
# Какие области надо закрасить (зависит от алтиернативы)
if(alternative == 'two-sided'){
chi_crit1 <- qchisq(1-(alpha/2), df=n)
chi_crit2 <- qchisq(alpha/2, df=n)
dlimit_left <- limitRange(function(x) dchisq(x, df=n), 0, chi_crit2)
dlimit_right <- limitRange(function(x) dchisq(x, df=n), chi_crit1, Inf)
}
if(alternative == 'less'){
chi_crit2 <- qchisq(alpha,df=n)
dlimit_left <- limitRange(function(x) dchisq(x, df=n), 0, chi_crit2)
dlimit_right <- limitRange(function(x) dchisq(x, df=n), Inf, Inf)
}
if(alternative == 'greater'){
chi_crit1 <- qchisq(1 - alpha,df=n)
dlimit_left <- limitRange(function(x) dchisq(x, df=n), 0, 0)
dlimit_right <- limitRange(function(x) dchisq(x, df=n), chi_crit1, Inf)
}
# Основная картинка
p <- ggplot(data.frame(x=c(0, qchisq(1-(alpha/2), df=n) + 2)), aes(x = x))+
stat_function(fun=dchisq, args = list(df=n)) + # вся функция
stat_function(fun=dlimit_left, geom="area", fill="blue", alpha=0.2) +
stat_function(fun=dlimit_right, geom="area", fill="blue", alpha=0.2) +
geom_point(aes(x=chi_stat,y=0), color="red", size=2) +
geom_vline(xintercept = chi_stat, size=0.3, linetype="dashed", color="red") +
annotate("text", label=round(chi_stat,2), x= chi_stat, y=0.2, parse=T, size=4, color="darkred")
# Рисуем критические точки
if(alternative == 'two-sided'){
p <- p + annotate("text", label=round(chi_crit1,2), x=chi_crit1+0.1, y=-0.02, parse=T, size=4) +
annotate("text", label=round(chi_crit2,2), x=chi_crit2-0.1, y=-0.02, parse=T, size=4)
}
if(alternative == 'less'){
p <- p + annotate("text", label=round(chi_crit2,2), x=chi_crit2-0.1, y=-0.02, parse=T, size=4)
}
if(alternative == 'greater'){
p <- p + annotate("text", label=round(chi_crit1,2), x=chi_crit1+0.1, y=-0.02, parse=T, size=4)
}
# Немного заключительных настроек, связанных с темой и вывод на экран
p <- p + theme(
axis.text.x = element_blank(),
axis.text.y = element_blank(),
axis.ticks = element_blank(),
axis.title.x = element_blank(),
axis.title.y = element_blank()
)
return(p)
}
1. Задача про фонтан¶
Задача про фонтан¶
- Юра приехал в южный город и увидел, что там есть фонтан и он работает
- Теперь все мысли Юры о том, как часто работает этот фонтан

Задача про фонтан¶
Гипотезы:
- Фонтан работает раз в году и нам повезло приехать в правильный день
- Фонтан работает каждые выходные, а мы как раз приехали в выходные
- Фонтан работает всегда

Мы хотим оценить параметр $\theta$ - работоспособность фонтана. У нас есть в голове несколько гипотез о том, какие именно значения может принимать $\theta$. У нас есть одно наблюдение
$$x_1 = \text{сегодня фонтан работал}.$$Перед нами стоит непосильная задача. Мы должны, руководствуясь этим наблюдением, выбрать для параметра оптимальное значение. Метод максимального правдоподобия подсказывает нам неплохой принцип принятия решения: что я вижу, то и есть на самом деле. Давайте попробуем формализовать этот принцип на языке математики.
Найдём вероятность получить наблюдение $x_1$ в нашу коллекцию, пройдясь по всем гипотезам. Та гипотеза, при которой эта вероятность будет самой большой - самая правдоподобная. На ней мы и остановимся. Какова вероятность увидеть работающий фонтан именно сегодня, если он работает раз в году? Довольно низкая, всего лишь $\frac{1}{365}$. Потому что дней в году всего $365$, и мы должны приехать в правильный.
Какова вероятность увидеть работающий фонтан именно сегодня, если он работает только по выходным? В году примерно треть дней - выходные. Значит вероятность составит $\sim \frac{1}{3}$. Кстати говоря, можно записать это как
$$P(x_1 = \text{работает} \mid \theta = \text{по выходным}).$$Какова вероятность увидеть работающий фонтан, если он работает каждый день? Правильно! Это единица. Что у нас получается? Мы нашли вероятность получить наше наблюдение, $P(x_1 \mid \theta)$ при разных значениях $\theta$. Потом мы сказали, что, наверное, самым приемлимым будет такое $\theta$, при котором вероятность увидеть выборку, максимальна и решили задачу
$$ P(x_1 \mid \theta) \to \max_{\theta}. $$Вероятность получить нашу выборку при конкретном значении парметра называется правдоподобием. Мы пытаемся её максимизировать. Поэтому оценка, получаемая на выходе называется оценкой максимального правдоподобия.
Задача про фонтан¶
Гипотезы:
- Фонтан работает раз в году и нам повезло приехать в правильный день $\color{red}{\frac{1}{365}}$
- Фонтан работает каждые выходные, а мы как раз приехали в выходные $\color{red}{\sim \frac{1}{3}}$
- Фонтан работает всегда $\color{red}{1}$
2. Правдоподобие и информация Фишера¶
Давайте немного формализуем задачу. Для этого я тут продублирую материалы из лекций.
Выборка выпрыгнула из сундука: $x_1, \ldots, x_n$

Мы не знаем, кто выплюнул на нас её из сундука, но можем предположить, что это случайная величина с полотностью $f(x \mid \theta)$. Про $\theta$ ничего не знаем. Видим выборку, хотим оценить.
Запишем правдоподобие наших данных, то есть вероятность пронаблюдать именно эту выборку:
$$L( \theta \mid x_1, \ldots, x_n) = f(x_1, \ldots, x_n \mid \theta) = \prod_{i=1}^n f(x_i \mid \theta) \to \max_{\theta}$$Наша выборка фиксирована. При разных значениях $\theta$ мы получаем большую или меньшую вероятность получить выборку близку к наблюдаемой. Было бы круто найти такое значение $\theta$, для которого эта вероятность оказалась бы максимальной.
Обратите внимание, что функцию $L( \theta \mid x_1, \ldots, x_n)$ уже нельзя трактовать как плотность распределения. Параметр $\theta$ здесь не рассматривается как случайная величина, он фиксирован. Интеграл $L( \theta \mid x_1, \ldots, x_n)$ по всем возможным значениям $\theta$ не будет равен единице.
Для максимизации правдоподобия нам придётся брать производные. Куда приятнее их брать от логарифма:
$$ \ln L( \theta \mid x_1, \ldots, x_n) = \sum_{i=1}^n \ln f(x_i \mid \theta) \to \max_{\theta} $$Берём производную и приравниваем её к нулю.
$$ \frac{\partial \ln L}{\partial \theta} = \sum_{i=1}^n \frac{\partial \ln f(x_i \mid \theta)}{\partial \theta} = 0 $$Решив это уравнение мы получим оценку максимального правдоподобия.
Посмотрим на одно слагаемое $\ln f(x_i \mid \theta)$. Его можно интерпретировать как логарифм правдоподобия, посчитанного на основании только одного наблюдения $x_i$.
Когда у нас в выборке появляются новые наблюдения, к нашей функции плюсуется дополнительное слагаемое. Интересно было бы посмотреть на то, как при этом функция изменяется. У нас есть R. Сгенерируем выборку объёма $5$ из нормального стандартного распределения и посмотрим.
x <- rnorm(5)
x
- -0.258773899310492
- 0.10831577995345
- -0.906998279353357
- -1.15404167868822
- -0.376380937725577
Выпишем для нормального распределения логарифмическую функцию правдоподобия. Она будет зависеть от двух векторов: выборки и параметров.
Предположим, что $\sigma = 1$, и нам хочется оценить только $\mu$. Перебьём такую функцию в R.
# mu - оцениваемый параметр
# x - вектор данных
log_lik <- function(mu, x) {
n <- length(x)
result <- -n/2*log(2*pi)-n/2*log(1)-sum((x-mu)^2)/(2*1)
return(result)
}
Найдём значение нашей функции в какой-нибудь точке. Какое из значений $\mu$ более правдоподобно?
log_lik(1,x)
log_lik(10,x)
Теперь посмотрим как правдоподобие выглядит на картинке.
mu = seq(-12,12,0.01)
lnL = rep(0,length(mu))
for(i in 1:length(lnL)){
lnL[i] = log_lik(mu[i], x)
}
qplot(mu, lnL, geom='line')

Максимум достигается в районе нуля, но не чётко в нуле.
Построим такие же функции для отдельных наблюдений.
mu = seq(-12,12,0.01)
lnL = rep(0,length(mu))
lnL1 = rep(0,length(mu))
lnL2 = rep(0,length(mu))
for(i in 1:length(lnL)){
lnL[i] = log_lik(mu[i], x)
lnL1[i] = log_lik(mu[i], x[1])
lnL2[i] = log_lik(mu[i], x[2])
}
df_L = data.frame(mu=mu,lnL = lnL, lnL1 = lnL1, lnL2 = lnL2)
ggplot(df_L, aes(x=mu))+
geom_line(aes(y=lnL))+
geom_line(aes(y=lnL1),color='red')+
geom_line(aes(y=lnL2),color='red')

Черная функция для всей выборки равна сумме логарифмических правдоподобий для отдельных наблюдений (красные линии). У каждого слагаемого своя выпуклость. Чем более выпукло слагаемое, тем более острым оно делает пик при суммировании Общая функция правдоподобия имеет более выраженный максимум по сравнению с функциями правдоподобия для отдельных наблюдений
Можно построить аналогичную картинку, на которой мы будем постепенно накапливать наблюдения внутри нашей суммы. При добавлении всё новых слагаемых, максимум будет становиться более чётким.
lnL = rep(0,length(mu))
lnL1 = rep(0,length(mu))
lnL2 = rep(0,length(mu))
lnL3 = rep(0,length(mu))
lnL4 = rep(0,length(mu))
lnL5 = rep(0,length(mu))
for(i in 1:length(lnL)){
lnL[i] = log_lik(mu[i], x)
lnL1[i] = log_lik(mu[i], x[1])
lnL2[i] = log_lik(mu[i], x[1:2])
lnL3[i] = log_lik(mu[i], x[1:3])
lnL4[i] = log_lik(mu[i], x[1:4])
}
df_L = data.frame(mu=mu,lnL = lnL, lnL1 = lnL1, lnL2 = lnL2,
lnL3 = lnL3,lnL4 = lnL4)
ggplot(df_L, aes(x=mu))+
geom_line(aes(y=lnL))+
geom_line(aes(y=lnL1),color='red')+
geom_line(aes(y=lnL2),color='red')+
geom_line(aes(y=lnL3),color='red')+
geom_line(aes(y=lnL4),color='red')

Каждая красная линия - добавление к сумме нового слагаемоего. С каждым слагаемым максимум становится всё более выраженым. Каждое слагаемое добавляет нам информации. Объём этой информации зависит от выпуклости функции правдоподобия для отдельного наблюдения.
Чем более выпукла функция, тем более выражен максимум, тем более сильно мы уверенны в том, что оценка параметра была найдена хорошо.
Что отвечает за выпуклость функции? Правильно! Вторая производная. Именно её, взятую со знаком минус, интерпретируют как наблюдённую информацию.
$$ I_o(\theta) = - \left( \frac{\partial^2 \ln L}{\partial \theta^2} \right) $$Почему со знаком минус? Потому что у нас максимум, в точке максимума вторая производная отрицательна. А информация должна быть положительной. Если параметр векторный, то в этом случае наблюдённая информация представляется наблюдённой информационной матрицей:
$$ I_o(\theta) = - \left( \frac{\partial^2 \ln L}{\partial \theta_i \partial \theta_j} \right) = - H $$Индекс $"o"$ в данном случае обозначает observed, информацию, которую мы реально видели. В матрице $I_o(\theta)$ во всех клетках стоят числа. Они зависят от конкретных значений наблюдений.
Обратите внимание, что на первой картинке, правдоподобия, построенные для разных наблюдений выпуклы по разному. Получается, что каждое наблюдение вносит в заострённость нашего правдоподобия разный вклад, то есть в каждом наблюдении содержится разное количество информации.
Математическое ожидание этой матрицы по распределению $x$ называется информационной матрицей Фишера.
$$ I(\theta) = - E\left( \frac{\partial^2 \ln L}{\partial \theta_i \partial \theta_j} \right) = -E(H) $$Ожидаемая информация зависит только от закона распределения наблюдений. Она отражает то, какую информацию в среднем вносит в наше правдоподобие, каждое наблюдение.
Если функция плотности $f(x \mid \theta)$ удовлетворяет условиям регулярности, то тогда для любой несмещённой оценки $\hat \theta$ выполняется неравенство Рао-Фреше-Крамера:
$$ Var(\hat \theta) \ge [I(\theta)]^{-1} $$Более того, в этом случае
$$ I(\theta) = - E\left( \frac{\partial^2 \ln L}{\partial \theta^2} \right) = E\left[ \left( \frac{\partial \ln L}{\partial \theta} \right)^2 \right], $$но доказывать это здесь, мы не будем. А вот условия регулярности чуть ниже обсудим. До них нам осталось чуточку потерпеть. При тех же условиях регулярности, оценка максимального правдоподоия обладает набором приятных асимптотических свойств:
- Инвариантность, если $\hat \theta$ оценка для $\theta$, то $g(\hat \theta)$ оценка для $g(\theta)$
- Состоятельность
- Асимптотическая несмещённость
- Асимптотическая эффективность
- Асимптотическая нормальность:
Асимптотическую нормальность обычно используют на практике для строительства доверительных интервалов и проверки гипотез. Чтобы сделать это, нужно найти подходящую оценку для информации Фишера, посчитанную на основе выборки.
Обычно поступают двумя путями: либо заменяют в матрице Гессе, $-H$, все $\theta$ на оценки, либо заменяют в матрице $-E(H)$ все $\theta$ на оценки. Именно так мы с вами поступим, когда будем решать задачки.
Теперь про условия регулярности. Они бывают очень разными. Каждый автор учебника формулирует их по-своему. По большому счёту всё сводится к двум вещам:
- Область определения случайной величины не зависит от параметра
- Можно брать производные и с ними всё хоршо
В книге Черновой, которую я рекомендую вам полностью прочитать (её книгу по тереру тоже), требуется, чтобы $\sqrt{f(x, \theta)}$ была всюду диффириенцируема по $\theta$ и чтобы информация фишера была конечной и существовала. На самом деле можно брать разные условия регулярности и доказывать, что одни следуют из других.
Условия регулярности нужны, чтобы при доказательстве свойств оценок максимального правдоподобия, обходить узкие места. Грубо говоря, в доказательстве нужно взять производную? Она должна существовать. В доказательстве нужно поменять местами интеграл и производную? Давайте ка вспомним какие условия нужны для этого в матане и потребуем их! Не более того. И это как-то скучно. За любой математической конструкцией должна быть какая-то интуиция. Давайте попробуем её нащупать.
Дело в том, что распределения случайных величин бывают разными. Есть простые, гладкие распределения вроде нормального или экспоненциального. У них есть математические ожидания, производные, область определения не зависит от значения параметра. Из-за этого метод максимального правдоподобия отрабатывает на ура. Если случайная величина устроена сложно, то внутри метода что-то ломается. В таких ситуациях говорят, что столкнулись с нерегулярным случаем. В самом конце пары мы поговорим о равномерном распределении, где есть зависимость области определения случайной величины от оцениваемого параметра. Забавно, что равномерное распределение оказывается сложным с точки зрения условий регулярности.
3. Задача про M&M-сины¶
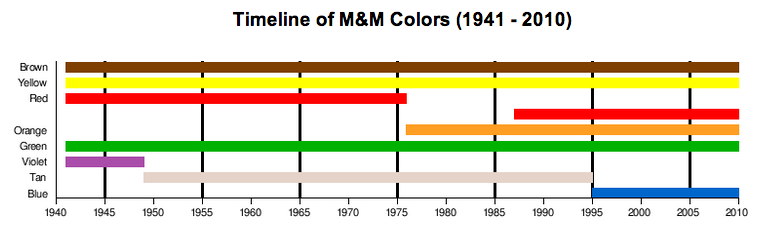
На картинке ниже находится эм-энд-мсовый тймлайн. Можно посмотреть в какие годы какими были цвета у конфеток.
Я купил несколько упаковок с конфетками и посчитал как часто в них встречаются жёлтые конфетки и красные конфетки. Красных оказалось $46$ штук. Жёлтых $44$ штуки. Остальных цветов $237$ штук.
Великий и могучий сундук вывалил на меня такие числа. Теперь я хочу узнать что внутри. Я предполагаю, что данные порождались следущей случайной величиной:
| $X$ | красная | жёлтая | другой цвет |
|---|---|---|---|
| $P(X=k)$ | $p_1$ | $p_2$ | $1-p_1 - p_2$ |
У нас в выборке есть $X_1$ красных конфеток и $X_2$ жёлтых. $p_1$ и $p_2$ это ненаблюдаемые константы. $X_1$ и $X_2$ это наблюдаемые случайные величины. Наша цель найти $\hat p_1(X_1, X_2)$ и $\hat p_2(X_1, X_2)$.
Для этого выписываем функцию правдоподобия!
$$ L = p_1^{X_1} \cdot p_2^{X_2} \cdot (1-p_1-p_2)^{n-X_1-X_2} $$Логарифмируем её:
$$ ln L = X_1 \ln p_1 + X_2 \ln p_2 + (n - X_1 - X_2) \ln(1-p_1-p_2) $$Чтобы найти максимум, берём производные!
$$ \begin{cases} \frac{\partial \ln L}{\partial p_1} = \frac{X_1}{p_1} - \frac{n-X_1-X_2}{1-p_1-p_2} \\ \frac{\partial \ln L}{\partial p_2} = \frac{X_2}{p_2} - \frac{n-X_1-X_2}{1-p_1-p_2} \end{cases} $$Приравниваем всё это добро к нулю, над буквами $p$ появляются колпачки. С этого момента мы имеем дело с оценками параметров. При настоящих значениях $p$ производные могут быть не равны нулю в доставшихся нам $x_i$.
В результате решения системы получаем, что
$$ \begin{cases} \hat p_1^{ML} = \frac{X_1}{n} \\ \hat p_2^{ML} = \frac{X_2}{n} \end{cases} $$В общем то это довольно логичный результат. То, что я вижу вне ящика, то и происходит в ящике. Таковы наши оценки.
Займёмся вторыми производными. Через них найдём оценку информационной матрицы $I$. Это можно сделать двумя способами:
- найти $-H$ и подставить в неё $\hat p$
- найти $-E(H)$ и подставить в неё $\hat p$
Дальше на основе $\hat I$ мы можем найти оценку для $Var(\hat p)$. Эта оценка позволит нам построить для оценок $\hat p$ доверительные интервалы и понять насколько точными получились наши результаты.
Найдём матрицу Гессе:
$$ H = \begin{pmatrix} \frac{\partial^2 \ln L}{\partial p_1^2}, \frac{\partial^2 \ln L}{\partial p_1 \partial p_2} \\ \frac{\partial^2 \ln L}{\partial p_2 \partial p_1}, \frac{\partial^2 \ln L}{\partial p_2^2} \end{pmatrix} $$Сделать это несложно. Нужно просто взять четыре производные.
$$ H = \begin{pmatrix} -\frac{X_1}{p_1^2} - \frac{n-X_1 -X_2}{(1-p_1-p_2)^2}, - \frac{n-X_1 -X_2}{(1-p_1-p_2)^2} \\ - \frac{n-X_1 -X_2}{(1-p_1-p_2)^2}, -\frac{X_2}{p_2^2} - \frac{n-X_1 -X_2}{(1-p_1-p_2)^2} \end{pmatrix} $$Значение $-H$ в точке $\hat p$ будет оценкой информационной матрицы, $\hat I$. Осталось подставить в неё $\hat p$ и обратить. Делать это вручную лениво. Давайте воспользуемся для этого мощью R.
# задаем оценку информационной матрицы руками
# Первый способ - подставим в -H оценки параметров:
x1 = 46
x2 = 44
x3 = 237
n = x1 + x2 + x3
hat.I <- matrix(c(x1/0.14^2+237/0.73^2, 237/0.73^2,
237/0.73^2, x2/0.14^2+237/0.73^2),nrow=2)
hat.I
| 2791.6751 | 444.7363 |
| 444.7363 | 2689.6343 |
# считаем обратную --- это будет оценка ковариационной матрицы ошибок
hat.Var <- solve(hat.I)
hat.Var
| 3.678990e-04 | -6.083283e-05 |
| -6.083283e-05 | 3.818566e-04 |
Мы получили оценку ковариационной матрицы для наших параметров $\hat p_1$ и $\hat p_2$. На диагонали стоят оценки дисперсий этих параметров, на побочной диагонали стоит ковариация между нашими оценками.
Построи оценку ковариационной матрицы вторым способом. Для этого найдём $E(H)$. Как мы помним, $X_i \sim Bin(n,p_1)$. Значит $E(X_1) = np_1$. Получается, что:
$$ E(H) = \begin{pmatrix} -\frac{n}{p_1} - \frac{n}{1-p_1-p_2}, - \frac{n}{1-p_1-p_2} \\ - \frac{n}{1-p_1-p_2}, -\frac{n}{p_2} - \frac{n}{1-p_1-p_2} \end{pmatrix} $$Подставими в матрицу $\hat p$ и обратим её.
# Второй способ - подставим в -E(H) оценки параметров:
hat.I <- matrix(c(n/0.14 + n/0.73, n/0.73,
n/0.73, n/0.14 + n/0.73),nrow=2)
hat.I
| 2783.6595 | 447.9452 |
| 447.9452 | 2783.6595 |
# считаем обратную --- это будет оценка ковариационной матрицы ошибок
hat.Var <- solve(hat.I)
hat.Var
| 3.687892e-04 | -5.934538e-05 |
| -5.934538e-05 | 3.687892e-04 |
Вопрос: являются ли оценки зависимыми?
4. Пакет maxLik¶
Это милый результат, но он довольно ручной. Мне бы хотелось теперь проделать все те же изыскания в R от начала до конца. Для этого будем использовать пакет maxLik.
Выписываем нашу логарифмическую функцию правдоподобия. Она будет зависеть от двух аргументов: выборки и параметров, которые нужно оценить. В дальнейшем нам нужно максимизировать функцию правдоподобия.
# install.packages('maxLik') # если пакет не установлен
library('maxLik') # пакет для метода макс. правдоподобия
# Логарифмическое правдоподобие
lnL <- function(p,X) {
ans <- X[1]*log(p[1])+X[2]*log(p[2])+ (X[3])*log(1-p[1]-p[2])
return(ans)
}
# Задаём точку для старта, а также выборку, которая пойдёт на вход lnL
res <- maxLik(lnL, start=c(0.1,0.1), X=c(44, 46, 237))
Loading required package: miscTools Please cite the 'maxLik' package as: Henningsen, Arne and Toomet, Ott (2011). maxLik: A package for maximum likelihood estimation in R. Computational Statistics 26(3), 443-458. DOI 10.1007/s00180-010-0217-1. If you have questions, suggestions, or comments regarding the 'maxLik' package, please use a forum or 'tracker' at maxLik's R-Forge site: https://r-forge.r-project.org/projects/maxlik/
summary(res) # краткий отчет о результатах оценивания
# первый столбик --- сами оценки по методу максимального правдоподобия
# второй столбик --- оценки стандартных ошибок
# т.е. корни из диагональных элементов оценённой ковариационной матрицы
# в третьем и четвёртом столбиках проверятся гипотеза о равенстве этих параметров нулю,
# но об этом позже :)
--------------------------------------------
Maximum Likelihood estimation
Newton-Raphson maximisation, 4 iterations
Return code 1: gradient close to zero
Log-Likelihood: -254.7649
2 free parameters
Estimates:
Estimate Std. error t value Pr(> t)
[1,] 0.13456 0.01887 7.130 1.00e-12 ***
[2,] 0.14067 0.01923 7.316 2.55e-13 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
--------------------------------------------
# можно вытащить протокол из summary в табличку
result_table = summary(res)
result_table$estimate
| Estimate | Std. error | t value | Pr(> t) |
|---|---|---|---|
| 0.1345566 | 0.01887130 | 7.130222 | 1.002075e-12 |
| 0.1406728 | 0.01922697 | 7.316428 | 2.546578e-13 |
# можно вытащить ещё чего-нибудь эдакого
result_table$loglik
p = res$estimate # оценки
p
- 0.134556574942643
- 0.140672782905346
res$hessian # оценка матрицы Гессе
| -2881.3361 | -451.1946 |
| -451.1946 | -2775.7210 |
p_var = solve(-1*res$hessian) # оценка ковариационной матрицы оценок
p_var
| 3.561261e-04 | -5.788845e-05 |
| -5.788845e-05 | 3.696765e-04 |
Упражнение: Давайте же построим асимптотический доверительный интервал для $\hat p_1$:
alpha = 0.05
z_alpha = qnorm(1 - alpha/2)
p[1] - z_alpha*sqrt(p_var[1,1])
p[1] + z_alpha*sqrt(p_var[1,1])
Упражнение: как построить доверительный интервал для разницы $\hat p_1 - \hat p_2$?
diff_std = sqrt(p_var[1,1] + p_var[2,2] - 2*p_var[1,2])
diff = p[1] - p[2]
diff - z_alpha*diff_std
diff + z_alpha*diff_std
Ноль попал в доверительный интервал. Что это, означает?
df = read.csv('/Users/fulyankin/Yandex.Disk.localized/R/R_prob_data/coal.csv', sep=',')
head(df)
| X | year | count |
|---|---|---|
| 1 | 1851 | 4 |
| 2 | 1852 | 5 |
| 3 | 1853 | 4 |
| 4 | 1854 | 1 |
| 5 | 1855 | 0 |
| 6 | 1856 | 4 |
x <- df$count # наша выборка
length(x) # размер выборки
qplot(x, bins=30)

Судя по гистограмме уместно предположить, что число аварий имеет распределение Пуассона, $Poiss(\lambda)$. Попробуем оценить параметр $\lambda$ методом максимального правдоподобия.
Вероятность значения: $$ P(X = k) = \frac{e^{-\lambda} \lambda^k}{k!}$$
Логарифмическое правдоподобие: $$ \ln L = \sum x_i \ln \lambda - n \lambda$$
Производная номер один: $$ \frac{\partial \ln L}{\partial \lambda} = \frac{\sum x_i}{\lambda} - n $$
Оценка максимального правдоподобия: $$\hat \lambda^{ML} = \bar x$$
А теперь всё то эе самое, но в R!
lnL <- function(lambda, x) {
n <- length(x)
answer <- -lambda*n+log(lambda)*sum(x)
return(answer)
}
# Пара значений функции
lnL(1, x)
lnL(0.5, x)
Кстати говоря, можно было не делать все эти расчёты и вбить функцию правдоподобия вот так:
lnL_2 <- function(lambda, x) {
answer <- dpois(x = x, lambda = lambda)
return(sum(log(answer)))
}
lnL_2(1, x)
Точка на выходе получилась другой, потому что в ручном варианте мы избавились от всех лишних констант. Тут они остались. Если мы будем максимизировать lnL_2 вместо lnL, мы получим тот же результат. Но таскать за собой константы не очень хочется. Иногда они портят процедуру сходимости, поэтому мы будем использовать ручной вариант. В домашках, в тех местах, где сложно вбить функцию правдоподобия в явном виде (например, гамма-распределение), используйте вариант с lnL_2.
Давайте посмотрим как выглядит наша функция правдоподобия на картинке. Мы ещё никогда не смотрели на неё на реальной выборке.
lambda = seq(0.1, 10, 0.1)
likelihood = lnL(lambda, x)
qplot(lambda, likelihood, geom='line')

Ещё давайте посмотрим небольшую гифку с тем, как эта функция правдоподобия накапливается из отдельных наблюдений.
Давайте найдём оценку максимального правдоподобия. Пакет позволяет.
result <- maxLik(lnL, start=2, x=x)
summary(result)
--------------------------------------------
Maximum Likelihood estimation
Newton-Raphson maximisation, 4 iterations
Return code 1: gradient close to zero
Log-Likelihood: -89.04906
1 free parameters
Estimates:
Estimate Std. error t value Pr(> t)
[1,] 1.7054 0.1234 13.82 <2e-16 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
--------------------------------------------
# сверимся с теорией! Оценка получилась хорошей :)
mean(x)
# Вытащим оценку в отдельную переменную
lambda_hat <- result$estimate
Оценка есть. Теперь хотим доверительный интервал. Сначала построим его вручную, чтобы закрепить теорию. Для этого нам нужна вторая производная :
$$ \frac{\partial^2 \ln L}{\partial \lambda^2} = -\frac{\sum x_i}{\lambda^2} $$В этой задачке только один параметр. Поэтому матрица гессе это только одна единственная производная. Давайте найдём оценку дисперсии для нашей $\hat \lambda$:
$$ - H = \frac{\sum x_i}{\lambda^2} $$$$ - E(H) = \frac{n}{\lambda} $$# Первая оценка:
1/(sum(x)/lambda_hat^2)
# Вторая оценка:
1/(length(x)/lambda_hat)
# Оценка из пакета:
-1*1/result$hessian
| 0.01523463 |
Давайте попробуем воспользоваться этой оценкой. Мы с вами помним, что оценка максимального правдоподобия довольно няшная. Она имеет асимптотически нормальное распределение:
$$\hat \lambda \sim N(\lambda, 0.015)$$Давайте построим для неё, отталкиваясь от этой информации доверительный интервал.
alpha = 0.05
z_alpha = qnorm(1 - alpha/2)
se = sqrt(-1*1/result$hessian)
lambda_left = lambda_hat - z_alpha*se
lambda_right = lambda_hat + z_alpha*se
cat('Параметр lambda с вероятностью 95% лежит между',lambda_left, 'и',lambda_right)
Параметр lambda с вероятностью 95% лежит между 1.463441 и 1.947273
Обратите внимание, что интервал получился довольно коротким. Это сигнализирует о высокой точности оценки. Давайте посмотрим с какой вероятностью в следующем году произойдёт какое количество катастроф, то есть построим прогноз для наших угольных шахт:
f <- 0:5
round(exp(-lambda_hat)*lambda_hat^f/factorial(f),2)
- 0.18
- 0.31
- 0.26
- 0.15
- 0.06
- 0.02
Вероятнее всего на шахте произойдёт две катастрофы. Надо быть готовым к этому.
На практике распределение Пуассона часто используют во всемирной организации здравоохрания. У каждого вируса гриппа есть свои особенности и нельзя привить людей сразу от всех недугов. Поэтому с помощью распределения Пуассона пытаются прогнозировать какие разновидности гриппа будут самыми популярными. Вакцину для прививок специфицируют именно под эти разновидности. Ясное дело, что они оценивают на основе распределения Пуассона более сложные модели. Например, Пуассоновскую регрессию. Если захотите со мной ещё факультативов, поговорим про неё в будущем.
Остался последний нюанс. Выше мы сказали, что если функция плотности $f(x \mid \theta)$ удовлетворяет условиям регулярности, то тогда для любой несмещённой оценки $\hat \theta$ выполняется:
$$ I(\theta) = E\left( \frac{\partial^2 \ln L}{\partial \theta^2} \right) = E\left[ \left( \frac{\partial \ln L}{\partial \theta} \right)^2 \right], $$то есть вторая производная является ничем иным как информацией Фишера. Давайте убедимся в этом на примере распределения Пуассона. Для простоты будем считать, что у нас есть только одно наблюдение и
$$\ln L = \ln f(x,\lambda).$$Если мы откроем семинары/лекции или ручками найдём информацию Фишера для распределения Пуассона, мы увидим, что:
$$ J(\lambda) = \frac{1}{\lambda} $$Это совпадает с $-E(H)$ для одного наблюдения. Остановитесь! И задумайтесь о том в чём смысл информации Фишера, при чём тут вторая производная и почему это информация. Если вы смогли ответить на эти вопросы, двигайтесь дальше. Если не смогли, то перечитайте начало блокнота. Если вы всё ещё ничего не поняли, пишите в лс :)
6. Задача про наркотики, сбор статистики¶
7. Тест отношения правдоподобий¶
Метод максимального правдоподобия очень распространён. Он используется практически везде. Ещё одноим его полезным своством является то, что с его помощью можно проверять гипотезы. Можно просто брать и смотреть насколько они правдоподобны с точки зрения собранной выборки.
Давайте посмотрим на ситуацию с шахтами. Нарисуем на картинке функцию правдоподобия, а также точку оптимума. Она будет красной. Кроме неё, нарисуем ещё одну синюю точку.
lambda = seq(0.1, 10, 0.1)
likelihood = lnL(lambda, x)
df_L = data.frame(lambda=lambda, likelihood = likelihood)
ggplot(df_L, aes(x=lambda))+
geom_line(aes(y=likelihood)) +
geom_point(aes(x=lambda_hat ,y=lnL(lambda_hat, x)), color="red", size=2) +
geom_point(aes(x=1 ,y=lnL(1, x)), color="blue", size=2)

По выборке мы получили в качестве оптимума красную точку. Любая оценка, полученная по выборке - случайная величина. А что, если наши данные просто так выпали, что оптимум в красной точке, а на самом деле он в синей, и $\lambda = 1$.
Тест отношения правдоподобий позволяе проверить гипотезы о любых ограничениях на параметры, заданные внутри модели. Нампример, в нашей ситуации гипотеза
$$ H_0: \lambda = 1 $$Накладывает ограничение на параметр $\lambda$. Если значение правдоподобия в синей точке не очень сильно отличается от значения в красной точке, мы можем сказать, что данные не противоречат гипотезе и она не отвергается. Осталось только понять как будет распределено расстояние между правдоподобиями. Это же тоже случайные величины.
Оказыватеся, что это расстояние между правдоподобиями распределено как
$$ LR = 2\cdot(\ln L(\hat \theta_{ML}) - \ln L(\theta_0)) \sim \chi^2_q, $$где $q$ это количество ограничений. Проверка любой параметрической гипотезы благодаря методу максимального правдоподобия сводится к простому рецепту:
- Оцениваем модель без ограничений.
- Оцениваем модель с ограничением, которое на неё накладывает $H_0$.
- Смотрим как сильно отличаются правдоподобия.
Этот рецепт называется тестом отношения правдоподобий. Кстати говоря, этот тест хорош ещё и тем, что в случае простых гипотез, на его основе можно построить критерий максимальной мощности. Про это говорит лемма Неймана-Пирсона, которая была у вас в лекциях. Но о ней мы поговорим в другой раз. Сейчас давайте попробуем воспользоваться тестом отношения правдоподобий и проверить гипотезу о том, что $\lambda = 1$.
Найдём наблюдаемое значение статистики:
lambda_0 = 1
LR_obs = 2*(lnL(lambda_hat, x) - lnL(lambda_0, x))
LR_obs
Теперь критическое значение.
alpha = 0.05
qchisq(1 - alpha/2, df = 1)
Построим для этого добра картинку по аналогии с теми, которые были в тетрадке про гипотезы.
chi_stat_picture(LR_obs, 1)

Наблюдаемое значение статистики попадает глубоко в хвост. Получается, что расстояние между двумя правдоподобиями слишком большое, и гипотеза об ограничении отвергается.
8. Толи нормальные толи равномерные весы¶
Решим ещё одну задачку. Пусть Ира раздобыла два золотых слитка массой $m$ каждый (для неё это вообще не проблема, её отец же король, а она принцесса). Также она раздобыла весы, которые работают с погрешностью.
Сначала Ира положила на весы первый золотой слиток и получила в результате взвешивания $m + \varepsilon_1$, где $ \varepsilon_1$ - случайная величина, ошибка первого взвешивания. Затем Ира положила на весы сразу оба слитка и получил в результате взвешивания $2m + \varepsilon_2$, где $ \varepsilon_2$ - случайная величина, ошибка второго взвешивания. Оказалось, что $y_1 = 60$, $y_2 = 110$.
a) Теперь Ира хочет с помощью метода максимального правдоподобия оценить вес слитка $m$ и погрешность весов $\sigma$, если ошибки не зависят друг от друга и при этом
$$\varepsilon_i \sim N(0,\sigma^2)$$b) Ира хочет $80\%$ доверительные интревалы для обоих параметров
с) Ира хочет проверить гипотезу о том, что $m = 70$ с помощью статистики отношения правдоподобий.
d) А ещё у Иры есть такая гипотеза: $\mu = 60$, $\sigma = 15$.
Для начала осознаем как распределена выборка.
\begin{equation*} \begin{aligned} & y_1 = m + \varepsilon_1 \sim N(m, \sigma^2) \\ & y_2 = 2m + \varepsilon_2 \sim N(2m, \sigma^2) \end{aligned} \end{equation*}Выписываем функцию правдоподобия:
$$ L = \frac{1}{\sqrt{2 \pi \sigma^2}} \cdot e^{-\frac{(y_1 - m)^2}{2 \sigma^2}} \cdot \frac{1}{\sqrt{2 \pi \sigma^2}} \cdot e^{-\frac{(y_2 - 2m)^2}{2 \sigma^2}} $$Прологарифмируем:
$$ \ln L \propto - \ln \sigma^2 - \frac{(y_1 -m)^2 + (y_2 - 2m)^2}{2 \sigma^2} $$Значком $\propto$ обычно обозначают равенство с точностью до константы. Мы, когда выписывали логарифм правдоподобия, избавились от лишних констант, которые никак не влияли на решение задачи. Вбиваем функцию в R.
y <- c(60, 110)
lnL <- function(th, y){
return(-log(th[2]) - ((y[1] - th[1])^2 + (y[2] - 2*th[1])^2)/(2*th[2]))
}
# все наши параметры в векторе th
lnL(c(2,2), y)
Находим оптимум:
result <- maxLik(lnL, start=c(2,4), y=y)
summary(result)
Warning message in log(th[2]): “созданы NaN”Warning message in log(th[2]): “созданы NaN”Warning message in log(th[2]): “созданы NaN”Warning message in log(th[2]): “созданы NaN”Warning message in log(th[2]): “созданы NaN”Warning message in log(th[2]): “созданы NaN”Warning message in log(th[2]): “созданы NaN”Warning message in log(th[2]): “созданы NaN”Warning message in log(th[2]): “созданы NaN”Warning message in log(th[2]): “созданы NaN”Warning message in log(th[2]): “созданы NaN”Warning message in log(th[2]): “созданы NaN”Warning message in log(th[2]): “созданы NaN”Warning message in log(th[2]): “созданы NaN”Warning message in log(th[2]): “созданы NaN”Warning message in log(th[2]): “созданы NaN”Warning message in log(th[2]): “созданы NaN”Warning message in log(th[2]): “созданы NaN”Warning message in log(th[2]): “созданы NaN”Warning message in log(th[2]): “созданы NaN”Warning message in log(th[2]): “созданы NaN”Warning message in log(th[2]): “созданы NaN”Warning message in log(th[2]): “созданы NaN”
--------------------------------------------
Maximum Likelihood estimation
Newton-Raphson maximisation, 21 iterations
Return code 1: gradient close to zero
Log-Likelihood: -3.302585
2 free parameters
Estimates:
Estimate Std. error t value Pr(> t)
[1,] 56.000 1.414 39.600 <2e-16 ***
[2,] 10.000 9.895 1.011 0.312
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
--------------------------------------------
При желании можно свериться с ручными оценками:
\begin{equation*} \begin{aligned} & \hat m = \frac{y_1 + 2 \cdot y_2}{5} \\ & \hat \sigma^2 = \frac{1}{2} \cdot((y_1 - \hat m)^2 + (y_2 - 2 \hat m)^2) \end{aligned} \end{equation*}Давайте построим $80%$ доверительный интервал для $\sigma^2$.
table <- summary(result)$estimate
table
| Estimate | Std. error | t value | Pr(> t) |
|---|---|---|---|
| 56.00000 | 1.414151 | 39.599740 | 0.0000000 |
| 9.99991 | 9.894662 | 1.010637 | 0.3121903 |
alpha = 0.2
z_alpha = qnorm(1 - alpha/2)
left = table[2,1] - z_alpha*table[2,2]
right = table[2,1] + z_alpha*table[2,2]
cat('Параметр mu с вероятностью 95% лежит между', left, 'и',right, '\n')
cat('Длина интервала:', right - left)
Параметр mu с вероятностью 95% лежит между -2.68061 и 22.68043 Длина интервала: 25.36104
Теперь проверим гипотезу, что $m = 70$. Для этого будем использовать статистику отношения правдоподобий. Зафиксируем значение $\mu$ и найдём оптимальную оценку для $\sigma$.
mu0 = 70
lnL_resricted <- function(th, y){
return(-log(th) - ((y[1] - mu0)^2 + (y[2] - 2*mu0)^2)/(2*th))
}
result_restricted <- maxLik(lnL_resricted, start=4, y=y)
summary(result_restricted)
--------------------------------------------
Maximum Likelihood estimation
Newton-Raphson maximisation, 32 iterations
Return code 1: gradient close to zero
Log-Likelihood: -7.214608
1 free parameters
Estimates:
Estimate Std. error t value Pr(> t)
[1,] 500.03 23.73 21.07 <2e-16 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
--------------------------------------------
Теперь можем найти наблюдаемое значение статистики и сравнить его с критическим:
LR_obs = 2*(lnL(result$estimate, y) - lnL_resricted(result_restricted$estimate, y))
chi_stat_picture(LR_obs, 1)

Видим, что гипотеза отвергается.
Пришло время завершающей гипотезы о том, что одновременно $\mu = 60$ и $\sigma = 15$. В обычных параметрических критериях мы не обсуждали критерий, который мог бы протестировать сразу же два ограничения. Статистика отношения правдоподобий первый из них.
mu0 = 60
sigma0 = 70
LR_obs = 2*(lnL(result$estimate, y) - lnL(c(mu0,sigma0), y))
Вспоминаем, что
$$ LR = 2\cdot(\ln L(\hat \theta_{ML}) - \ln L(\theta_0)) \sim \chi^2_q, $$где $q$ это количество ограничений. В нашей гипотезе сразу два ограничения. Поэтому число степеней свободы, $q=2$. Давайте найдём наблюдаемое значение статистики и критическое.
chi_stat_picture(LR_obs, 2)

Гипотеза не отвергается.
9. Киллер и тренд во времени.¶
Помнитеб в первой домашке мы изучали с помощью симуляций игру в Киллера. В послених пунктах домашки мы смотрели, насколько быстро игра протухнет, если интерес к ней падает. На экономе мы играли в киллера дважды. У нас есть немного статистике по игре. Целых два наблюдений. Время между смертями в перой игре и время между смертями во второй игре. Давайте подгрузим их.
game_1 = read.csv('killer_time1.csv', sep = '\t', dec=',')$hours_between_kill/24
qplot(game_1)
`stat_bin()` using `bins = 30`. Pick better value with `binwidth`.

game_2 = read.csv('killer_time2.csv', sep = '\t', dec=',')$hours_between_kill/24
qplot(game_2)
`stat_bin()` using `bins = 30`. Pick better value with `binwidth`.

Предположим, что время между смертями имеет экспоненциальное распределение. Судя по гистограммам это похоже на правду. Можно даже гипотезу об этом проверить, при желании. На самом деле время между наступлением событий не всегда распределено экспоненциально. В домашке вы это увидите на примере гейзеров.
Окей, давайте попробуем методом максимального правдоподобия оценить для одной из игр параметр $\alpha$.
lnL <- function(alpha, x) {
n <- length(x)
answer <- -alpha*sum(x)+log(alpha)*n
return(answer)
}
result <- maxLik(lnL, start=1, x=game_1)
summary(result)
--------------------------------------------
Maximum Likelihood estimation
Newton-Raphson maximisation, 6 iterations
Return code 1: gradient close to zero
Log-Likelihood: -53.19531
1 free parameters
Estimates:
Estimate Std. error t value Pr(> t)
[1,] 0.6202 0.1034 6 1.97e-09 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
--------------------------------------------
1/mean(game_1)
Вроде бы совпало. Теперь давайте попробуем усложнить модель. Мы с вами говорили, что протухание в игре должно как-то зависеть от времени, прошедшего с её начала. При симуляциях в первой домашке, мы брали какие-то дискретные моменты времени, и изменяли в них значение $\alpha$. Давайте сделаем умнее. Предположим, что $\alpha$ это функция от времени, прошедшего с начала игры.
Например, предположим, что затухание интереса к игре происходит линейно, то есть
$$ \alpha = \beta_0 + \beta_1 \cdot t. $$В таком случае $X_i \sim Exp(\beta_0 + \beta_1 \cdot t)$, и нам надо оценить параметры $\beta_0$ и $\beta_1$ вместо $\alpha$. Вобьём функцию правдоподобия для такой ситуации.
betwen_kill = c(game_1, game_2)
time = c(cumsum(game_1), cumsum(game_2))
X = data.frame(time = time, betwen_kill = betwen_kill)
head(X)
| time | betwen_kill |
|---|---|
| 0.249382 | 0.2493820 |
| 1.248449 | 0.9990668 |
| 2.317757 | 1.0693085 |
| 3.821953 | 1.5041962 |
| 3.997485 | 0.1755315 |
| 4.238015 | 0.2405298 |
lnL <- function(beta, X) {
alpha = beta[1] + beta[2]*X$time
answer = sum(log(dexp(X$betwen_kill, rate = alpha)))
return(answer)
}
result <- maxLik(lnL, start=c(1, 1), X=X)
summary(result)
Warning message in dexp(X$betwen_kill, rate = alpha): “созданы NaN”Warning message in dexp(X$betwen_kill, rate = alpha): “созданы NaN”Warning message in dexp(X$betwen_kill, rate = alpha): “созданы NaN”Warning message in dexp(X$betwen_kill, rate = alpha): “созданы NaN”Warning message in dexp(X$betwen_kill, rate = alpha): “созданы NaN”Warning message in dexp(X$betwen_kill, rate = alpha): “созданы NaN”Warning message in dexp(X$betwen_kill, rate = alpha): “созданы NaN”Warning message in dexp(X$betwen_kill, rate = alpha): “созданы NaN”Warning message in dexp(X$betwen_kill, rate = alpha): “созданы NaN”Warning message in dexp(X$betwen_kill, rate = alpha): “созданы NaN”Warning message in dexp(X$betwen_kill, rate = alpha): “созданы NaN”Warning message in dexp(X$betwen_kill, rate = alpha): “созданы NaN”Warning message in dexp(X$betwen_kill, rate = alpha): “созданы NaN”Warning message in dexp(X$betwen_kill, rate = alpha): “созданы NaN”Warning message in dexp(X$betwen_kill, rate = alpha): “созданы NaN”Warning message in dexp(X$betwen_kill, rate = alpha): “созданы NaN”Warning message in dexp(X$betwen_kill, rate = alpha): “созданы NaN”Warning message in dexp(X$betwen_kill, rate = alpha): “созданы NaN”Warning message in dexp(X$betwen_kill, rate = alpha): “созданы NaN”Warning message in dexp(X$betwen_kill, rate = alpha): “созданы NaN”Warning message in dexp(X$betwen_kill, rate = alpha): “созданы NaN”Warning message in dexp(X$betwen_kill, rate = alpha): “созданы NaN”Warning message in dexp(X$betwen_kill, rate = alpha): “созданы NaN”Warning message in dexp(X$betwen_kill, rate = alpha): “созданы NaN”Warning message in dexp(X$betwen_kill, rate = alpha): “созданы NaN”Warning message in dexp(X$betwen_kill, rate = alpha): “созданы NaN”
--------------------------------------------
Maximum Likelihood estimation
Newton-Raphson maximisation, 11 iterations
Return code 1: gradient close to zero
Log-Likelihood: -79.27675
2 free parameters
Estimates:
Estimate Std. error t value Pr(> t)
[1,] 0.904094 0.142894 6.327 2.50e-10 ***
[2,] -0.013288 0.003077 -4.319 1.57e-05 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
--------------------------------------------
ggplot(X, aes(x=time))+
geom_point(aes(y=betwen_kill)) +
geom_line(aes(y=0.9 - 0.01*betwen_kill), col='red')

Можно попробовать более сложную гипотезу. Например, что
$$ \alpha = \beta_0 + \beta_1 \cdot e^{\beta_2 \cdot t} $$lnL <- function(beta, X) {
alpha = beta[1] + beta[2]*exp(beta[3]*X$time)
answer = sum(log(dexp(X$betwen_kill, rate = alpha)))
return(answer)
}
result <- maxLik(lnL, start=c(1, 1, -2), X=X)
summary(result)
Warning message in dexp(X$betwen_kill, rate = alpha): “созданы NaN”Warning message in dexp(X$betwen_kill, rate = alpha): “созданы NaN”Warning message in dexp(X$betwen_kill, rate = alpha): “созданы NaN”Warning message in dexp(X$betwen_kill, rate = alpha): “созданы NaN”Warning message in dexp(X$betwen_kill, rate = alpha): “созданы NaN”Warning message in dexp(X$betwen_kill, rate = alpha): “созданы NaN”Warning message in dexp(X$betwen_kill, rate = alpha): “созданы NaN”Warning message in dexp(X$betwen_kill, rate = alpha): “созданы NaN”Warning message in dexp(X$betwen_kill, rate = alpha): “созданы NaN”Warning message in dexp(X$betwen_kill, rate = alpha): “созданы NaN”Warning message in dexp(X$betwen_kill, rate = alpha): “созданы NaN”Warning message in dexp(X$betwen_kill, rate = alpha): “созданы NaN”Warning message in dexp(X$betwen_kill, rate = alpha): “созданы NaN”Warning message in dexp(X$betwen_kill, rate = alpha): “созданы NaN”Warning message in dexp(X$betwen_kill, rate = alpha): “созданы NaN”Warning message in dexp(X$betwen_kill, rate = alpha): “созданы NaN”Warning message in dexp(X$betwen_kill, rate = alpha): “созданы NaN”Warning message in dexp(X$betwen_kill, rate = alpha): “созданы NaN”Warning message in dexp(X$betwen_kill, rate = alpha): “созданы NaN”Warning message in dexp(X$betwen_kill, rate = alpha): “созданы NaN”Warning message in dexp(X$betwen_kill, rate = alpha): “созданы NaN”Warning message in dexp(X$betwen_kill, rate = alpha): “созданы NaN”Warning message in dexp(X$betwen_kill, rate = alpha): “созданы NaN”Warning message in dexp(X$betwen_kill, rate = alpha): “созданы NaN”Warning message in dexp(X$betwen_kill, rate = alpha): “созданы NaN”Warning message in dexp(X$betwen_kill, rate = alpha): “созданы NaN”Warning message in dexp(X$betwen_kill, rate = alpha): “созданы NaN”Warning message in dexp(X$betwen_kill, rate = alpha): “созданы NaN”Warning message in dexp(X$betwen_kill, rate = alpha): “созданы NaN”Warning message in dexp(X$betwen_kill, rate = alpha): “созданы NaN”Warning message in dexp(X$betwen_kill, rate = alpha): “созданы NaN”Warning message in dexp(X$betwen_kill, rate = alpha): “созданы NaN”Warning message in dexp(X$betwen_kill, rate = alpha): “созданы NaN”Warning message in dexp(X$betwen_kill, rate = alpha): “созданы NaN”Warning message in dexp(X$betwen_kill, rate = alpha): “созданы NaN”Warning message in dexp(X$betwen_kill, rate = alpha): “созданы NaN”Warning message in dexp(X$betwen_kill, rate = alpha): “созданы NaN”Warning message in dexp(X$betwen_kill, rate = alpha): “созданы NaN”Warning message in dexp(X$betwen_kill, rate = alpha): “созданы NaN”Warning message in dexp(X$betwen_kill, rate = alpha): “созданы NaN”Warning message in dexp(X$betwen_kill, rate = alpha): “созданы NaN”Warning message in dexp(X$betwen_kill, rate = alpha): “созданы NaN”Warning message in dexp(X$betwen_kill, rate = alpha): “созданы NaN”Warning message in dexp(X$betwen_kill, rate = alpha): “созданы NaN”Warning message in dexp(X$betwen_kill, rate = alpha): “созданы NaN”Warning message in dexp(X$betwen_kill, rate = alpha): “созданы NaN”Warning message in dexp(X$betwen_kill, rate = alpha): “созданы NaN”Warning message in dexp(X$betwen_kill, rate = alpha): “созданы NaN”Warning message in dexp(X$betwen_kill, rate = alpha): “созданы NaN”Warning message in dexp(X$betwen_kill, rate = alpha): “созданы NaN”Warning message in dexp(X$betwen_kill, rate = alpha): “созданы NaN”Warning message in dexp(X$betwen_kill, rate = alpha): “созданы NaN”Warning message in dexp(X$betwen_kill, rate = alpha): “созданы NaN”Warning message in dexp(X$betwen_kill, rate = alpha): “созданы NaN”Warning message in dexp(X$betwen_kill, rate = alpha): “созданы NaN”Warning message in dexp(X$betwen_kill, rate = alpha): “созданы NaN”Warning message in dexp(X$betwen_kill, rate = alpha): “созданы NaN”Warning message in dexp(X$betwen_kill, rate = alpha): “созданы NaN”Warning message in dexp(X$betwen_kill, rate = alpha): “созданы NaN”Warning message in dexp(X$betwen_kill, rate = alpha): “созданы NaN”Warning message in dexp(X$betwen_kill, rate = alpha): “созданы NaN”Warning message in dexp(X$betwen_kill, rate = alpha): “созданы NaN”Warning message in dexp(X$betwen_kill, rate = alpha): “созданы NaN”
--------------------------------------------
Maximum Likelihood estimation
Newton-Raphson maximisation, 10 iterations
Return code 1: gradient close to zero
Log-Likelihood: -74.64443
3 free parameters
Estimates:
Estimate Std. error t value Pr(> t)
[1,] 0.20592 0.08887 2.317 0.02050 *
[2,] 1.69736 0.53791 3.155 0.00160 **
[3,] -0.09203 0.03551 -2.591 0.00956 **
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
--------------------------------------------
b = result$estimate
ggplot(X, aes(x=time))+
geom_point(aes(y=betwen_kill)) +
geom_line(aes(y=b[1] + b[2]*exp(b[3]*betwen_kill)), col='red')

Давайте посмотрим внимательно на протокол оценивания. Вполне возможно, что трэнд незначим, и на самом деле параметр $\alpha$ никак не зависит от времени, которое длится игра. В протоколе для каждого из коэффициентов трэнда проверяется гипотеза о том, что они равны нулю. Это делается на основе асимптотически нормального распределения, так как метод максимального правдоподобия хорошо дружит с ЦПТ.
summary(result)
--------------------------------------------
Maximum Likelihood estimation
Newton-Raphson maximisation, 10 iterations
Return code 1: gradient close to zero
Log-Likelihood: -74.64443
3 free parameters
Estimates:
Estimate Std. error t value Pr(> t)
[1,] 0.20592 0.08887 2.317 0.02050 *
[2,] 1.69736 0.53791 3.155 0.00160 **
[3,] -0.09203 0.03551 -2.591 0.00956 **
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
--------------------------------------------
В нашем случае все три коэффициента по отдельности значимы. Тем не менее, они могут оказаться нулевыми по отдельности. Давайте проверим гипотезу об этом тестом максимального правдоподобия. В этот раз $q=3$, так как мы зануляем сразу три коэффициента.
LR_obs = 2*(lnL(b, X) - lnL(c(0,0,0), X))
chi_stat_picture(LR_obs, 3)

Отличная новость! Гипотеза отвергается. Это означает, что при симуляции игры в Киллера мы можем попробовать использовать оценённую нами модель.
Что мы сегодня осознали?¶
- Метод максимального правдоподобия - что я вижу, то и есть на самом деле.
- Производные содержут в себе информацию и именно они используются для её передачи в современной статистике и машинном обучении. Например, вторая производная функции правдоподобия говорит о том, насколько ярко выражен пик правдоподобия.
- Информация Фишера говорит о острие пика, это усреднённая по выборке вторая производная, взятая со знаком минус (потому что мы максимизируем правдоподобие, в оптимуме вторая производная отрицательна, надо это компенсировать ещё одним минусом).