R для тервера и матстата
Шо за случайности да как их генерить

Данный ноутбук является конспектом по курсу «R для теории вероятностей и математической статистики» (РАНХиГС, 2019). Автор ноутбука - вот этот парень по имени Филипп. Если у вас для него есть деньги, слава или женщины, он от этого всего не откажется. Ноутбук распространяется на условиях лицензии Creative Commons Attribution-Share Alike 4.0. При использовании обязательно упоминание автора курса и аффилиации. При наличии технической возможности необходимо также указать активную гиперссылку на страницу курса. На ней можно найти другие материалы. Фрагменты кода, включенные в этот notebook, публикуются как общественное достояние.
Чем будем заниматься¶
Посмотрим на то, что уже заботали под новым углом
Немного углубим знания, выработаем интуицию
Будем смотреть презы, писать код, болтать, решать задачки на доске
Посмотрим на примеры задач, которые приходится решать аналитикам
В чём будем заниматься¶
Конечно же в R
R очень лёгок в освоении
Одна из самыз красивых визуализаций данных
Очень хорош в работе со статистикой
Много готовых пакетов и большое комьюнити
Используется многими компаниями в работе, вот устаревший мини-список
Чему мы хотим научиться¶
- Увидеть картину мира целиком, а не отдельные её части
- Чётко осознавать какие именно методы из статистики можно применить к задаче
- Понимать что за задача перед нами стоит и уметь переводить её на язык математики
- Использовать всю мощь R для этих целей
Про активности¶
Не делаешь сам $\Rightarrow$ никогда не научишься $\Rightarrow$ $4$
большиеогромные домашки, за каждую можно набрать $100$ балловДомашки делаются в командах по три человека
Баллы ставятся на команду
Для зачёта и оценки $10$ надо набрать на команду $100$ баллов
В каждой домашке много рыбёшек и большой кит, можно решать только то, к чему лежит душа
Регистрация команд¶
- Нужно разбиться на команды по три человека и зарегистрироваться в форме
- Название своей команды нужно держать в тайне, у нас анонимное состязание, потому что есть супер-приз
Суперприз¶
Две команды, набравшие наибольшее количество баллов свожу почилить с винишком, пиццей и настолками на крышу Яндекса
Команда может претендовать на крышу, если она набрала больше $100$ баллов

Страничка курса со всей инфой:¶
Показать как сдавать домашки!¶
- Опасность: не смочь собрать в R домашку
- Лечение: написать мне и попросить помочь, я всегда отвечу
- Я в академии в четверг весь день, иногда в пятницу, можно подойти с ноутом
- В команде вас трое, а файл на всех один: разделение труда. Кто-то решает, кто-то вбивает.
- Видео с запуском R и созданием pdf с домашкой

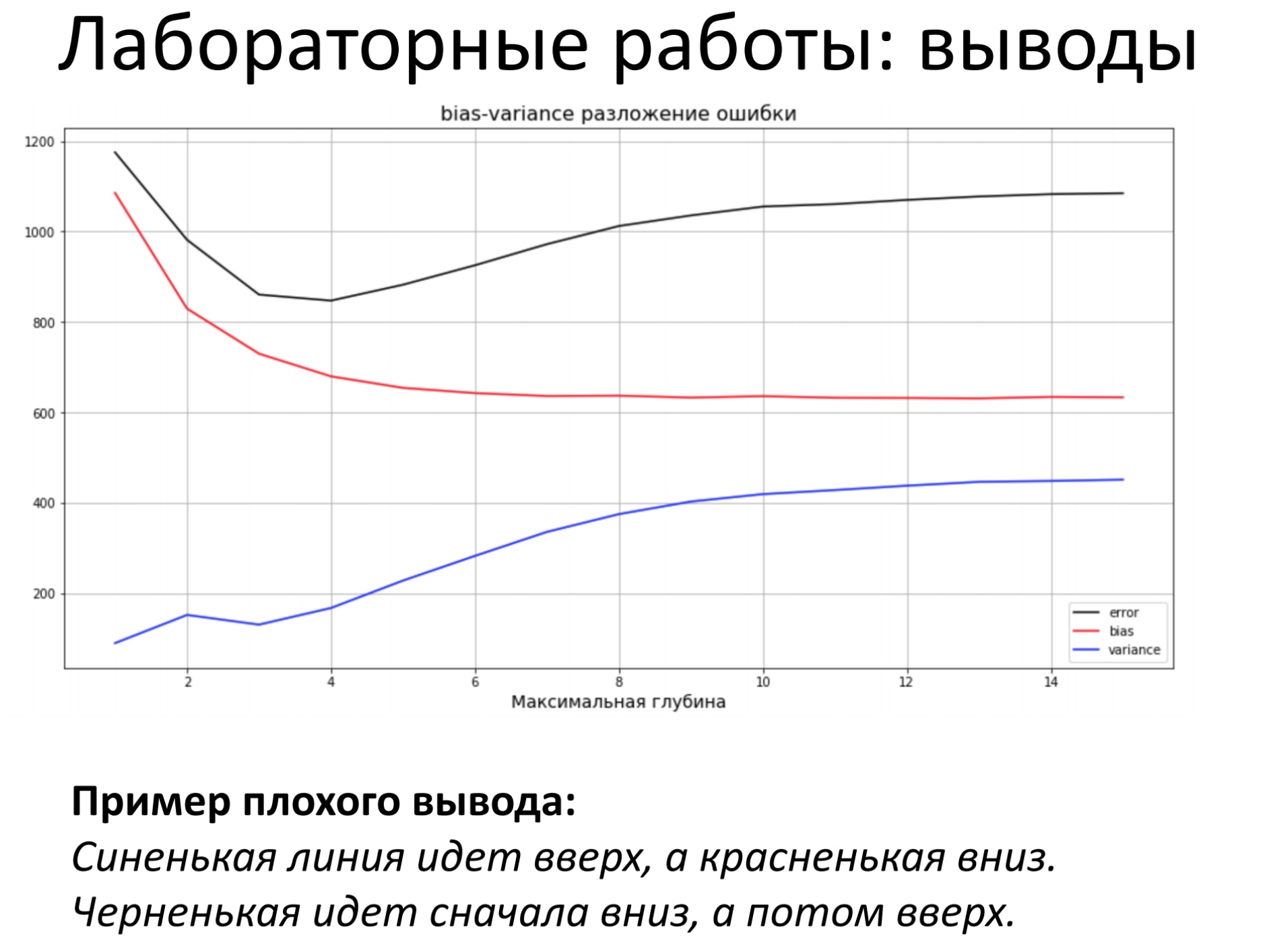
1. Зачем мы учили тервер?¶
Теория вероятностей¶
Мы изучали вероятности
Мы изучали события
Мы изучали случайные величины и их распределения
ЗАЧЕМ МЫ ЭТО ДЕЛАЛИ?
Случайные ли величины?¶


Демон Лапласа¶

Байесовский взгляд на вероятность¶
Лаплас: детерминизм, мы могли бы идеально прогнозировать вселенную, если бы измерили точное положение каждого атома. Издержки этого огромны.
Между совершенством природы и несовершенством человеческого познания огромный разрыв.
Неопределённость — результат этого разрыва. Случайность — это результат нашего невежества, а вероятность способ это невежество измерить.
Частотный взгляд на вероятность¶
Наука не может рассматривать вероятность как субъективную меру невежества.
Можно оценивать вероятности только тех событий, которые происходят более одного раза.
Вопрос «Какова вероятность, что кандидат N победит на выборах?» не имеет ответа, так как событие уникально и не обладает «частотой».
Что мы имеем¶

Сундук — различные процесс порождения данных. Теория вероятностей изучает этот сундук. В реальности мы его не видим.
В реальном мире мы видим выборки, которые сундук выплёвывает на нас. Математическая статистика изучает испражнения сундука и по ним пытается восстановить его внутренности.
Хлам из сундука¶


Базовые теоремы¶
Все манипуляции по восстановлению внутренностей сундука по его испражнениям позволяет делать ряд теорем.
Некоторые из них вы уже выучили!
Что это за теоремы?
2. Закон больших чисел¶
Закон больших чисел¶
ЗБЧ утверждает, что среднее арифметическое большого числа похожих случайных величин «стабилизируется» с рочтом их числа
Как бы сильно случайные величины не отклонялись от своего среднего значения, эти отклонения взаимно гасятся и среднее арифметическое приближается к постоянной величине
- ЗБЧ сформулировано довольно много: Чебышёва,Хинчина и тд
Закон больших чисел¶

Вопрос про больницы¶
- Есть две больницы: маленькая и большая

В обеих принимают роды, выяснилось, что в одной из больниц оценка вероятности появления мальчика составила $0.7$
В какой из больниц это произошло и почему?
Вопрос про больницы¶
Есть две больницы: маленькая и большая
- Скорее всего, это произошло в маленькой больнице. При малых объёмах выборки вероятность отклониться от $0.5$ больше. Именно это нашёптывает нам ЗБЧ.
Слабая форма ЗБЧ (Пафнутий Львович Чебышёв)¶
Пусть $X_1, \ldots, X_n$ попарно независимые и одинаково распределённые случайные величины с конечным вторым моментом, $E(X_i^2) < \infty$, тогда имеет место сходимость:
$$ \frac{X_1 + \ldots + X_n}{n} \overset{p}{\to} E(X_1) $$Сильная форма ЗБЧ¶
Пусть $X_1, \ldots, X_n$ попарно независимые и одинаково распределённые случайные величины с конечным вторым моментом, $E(X_i^2) < \infty$, причём $\sum_{k=1}^{\infty} \frac{Var(X_k)}{k^2} < \infty$, тогда имеет место сходимость
$$ \frac{X_1 + \ldots + X_n}{n} \overset{п.н.}{\to} E(X_1) $$Страховые компании¶
Примерно с $1600$-х годов ЗБЧ позволяет зарабатывать деньги на страховании
Упражнение: для $25$-летней девушки вероятность прожить ещё год составляет $0.9$. Страховка в год стоить $1000$ рублей при взносе в $110$ рублей. Какой будет средняя прибыль компании с одной страховки?
Страховые компании¶
$X_i$ — прибыль с одной страховки
| $X_i$ | $110$ | $-890$ |
|---|---|---|
| $P(\ldots)$ | $0.9$ | $0.1$ |
Средняя прибыль компании составит $\frac{1}{n} \sum X_i$. По закону больших чисел:
$$ \frac{1}{n} \sum_{i=1}^n X_i \overset{p}{\to} E(X_1) = 0.9 \cdot 110 - 0.1 \cdot 890 = 10 $$Генерации разных штук¶
Другой ништяк, который нам разрешает ЗБЧ — генерация случайных величин для оценки разных математических ожиданий и т.п.
Не можешь посчитать? Сгенерируй!
Обычно такие генерации называют методом Монте-Карло
Метод Монте-Карло¶
- Метод Монте-Карло это общее название группы численных методов, основанных на получении большого числа реализаций случайного процесса, который формируется таким образом, чтобы его вероятностные характеристики совпадали с аналогичными величинами решаемой задачи
3. Генерации в R¶
library("ggplot2") # Пакет для красивых графиков
# Если вы работаете в R-studio, вы можете избежать подгрузки пакетов ниже
# Отрегулируем размер картинок, которые будут выдаваться в нашей тетрадке
library('repr')
library("grid") # Пакет для субплотов
options(repr.plot.width=4, repr.plot.height=3)
Генерации в R¶
Чтобы сварить в R любую случайную величину, нужно знать четыре буквы: $r$, $d$, $p$ и $q$.
rnormэта команда сгенерирует выборку из нормального распределенияdnormэта команда вычислит значение плотности в указанной точкеpnormэта команда находит вероятностьqnormэта команда находит квантили
Генерируем нормальную выборку¶
Хочу сгенерировать нормальную случайную величину $X \sim N(\mu, \sigma^2)$:
$$ f(x) = \frac{1}{\sigma \sqrt{2 \pi}} \cdot e^{-\frac{(x - \mu)^2}{2 \sigma^2}} $$x <- rnorm(4, mean=5, sd=3) # если дисперсия 9,
x # то стандартное отклонение 3
- 3.44389035979933
- 7.59097440961776
- 3.6506566737062
- 4.72979997241011
Хочу узнать $f(3)$
dnorm(3, mean=5, sd=3)
Хочу узнать $F(3) = P(X < 3) = \int_{-\infty}^3 f(x)dx$
pnorm(3, mean=5, sd=3)
Хочу узнать $P(4 < X < 9)$ - ?
Хочу узнать
$$P(4 < X < 9) = \int_4^9 f(x) dx = F(9) - F(4)$$pnorm(9, mean=5, sd=3) - pnorm(4, mean=5, sd=3)
Квантиль уровня $\gamma$ это такое число $q$, что:
$$ P(X < q) = \gamma $$qnorm(1 - 0.05/2, mean=0, sd=1)
x <- c(0.95, 0.975, 0.995)
qnorm(x, mean = 0, sd = 1)
- 1.64485362695147
- 1.95996398454005
- 2.5758293035489
# квантили для другого распределения!
x <- c(0.95, 0.975, 0.995)
qt(x, df = 10)
- 1.81246112281168
- 2.22813885198627
- 3.16927267261695
Что сгенерирует код?
rnorm(10)
- -0.707120663342578
- -0.980011188525533
- 0.396645732489923
- -0.839942216948569
- 1.75183863777376
- 1.08577247385991
- -0.396472256977632
- -0.893778576611249
- -0.274953778469149
- -0.630480321588603
Характеристики случайных величин¶
x <- rnorm(1000, mean=5, sd=3)
mean(x) # среднее
var(x) # выборочная дисперсия
sd(x) # выборочное стандартное отклонение
median(x) # выборочная медиана
Гистограмма¶
library("ggplot2") # пакет для красивых картинок
x <- rnorm(1000, mean=5, sd=3)
qplot(x) # гистограма
`stat_bin()` using `bins = 30`. Pick better value with `binwidth`.

Плотность распределения¶
library("ggplot2") # пакет для красивых картинок
x <- seq(-5, 15, by=0.01)
y <- dnorm(x, mean=5, sd=3)
qplot(x, y, geom="line")

Функция распределения¶
library("ggplot2") # пакет для красивых картинок
x <- seq(-5, 15, by=0.01)
y <- pnorm(x, mean=5, sd=3)
qplot(x, y, geom="line")

Зачем всё это надо?!¶
- Чтобы решать реальные проблемы! Например, пусть $X \sim N(5,3)$. Как найти $E \left(\frac{1}{X} \right)$?
- Спосбо первый:
Чтобы решать реальные проблемы! Например, пусть $X \sim N(5,3)$. Как найти $E \left(\frac{1}{X} \right)$?
Спосбо второй (ЗБЧ разрешает нам так делать):
n_obs <- 10^6 # число наблюдений
x <- rnorm(n_obs, mean = 5, sd = 3)
mean(1/x)
Зачем всё это надо?¶
$X_1, X_2, X_3 \sim U[0;2]$, независимые
Хотим знать $P(X_1 + X_2 + X_3^2 > 5)$
n_obs <- 10^6
x_1 <- runif(n_obs, min = 0, max = 2)
x_2 <- runif(n_obs, min = 0, max = 2)
x_3 <- runif(n_obs, min = 0, max = 2)
success <- x_1 + x_2 + x_3^2 > 5
success[1:5]
sum(success) / n_obs
- FALSE
- FALSE
- FALSE
- FALSE
- TRUE
Зачем всё это надо?¶
$X_1, X_2, X_3 \sim U[0;2]$, независимые
Хотим знать $$P(X_1 + X_2 > 0.8 \mid X_3 < 0.1)$$
n_obs <- 10^6
x_1 <- runif(n_obs, min = 0, max = 2)
x_2 <- runif(n_obs, min = 0, max = 2)
x_3 <- runif(n_obs, min = 0, max = 2)
uslovie <- x_3 < 0.1
x_1[1:3]
uslovie[1:3]
x_1[uslovie][1:3]
- 0.415671448688954
- 0.721095726825297
- 1.74133329978213
- FALSE
- FALSE
- TRUE
- 1.74133329978213
- 1.82215116219595
- 0.446165119297802
n_obs <- 10^6
x_1 <- runif(n_obs, min = 0, max = 2)
x_2 <- runif(n_obs, min = 0, max = 2)
x_3 <- runif(n_obs, min = 0, max = 2)
uslovie <- x_3 < 0.1
success <- x_1[uslovie] + x_2[uslovie] > 0.8
sum(success)/n_obs
Генерация выборок¶
- С такой же лёгкостью можно генерировать любые выборки
sample(1:10, size = 8) # выборка без повторений
- 4
- 3
- 6
- 10
- 5
- 8
- 1
- 7
sample(1:10, size = 8, replace = TRUE) # с повторениями
- 8
- 10
- 3
- 5
- 6
- 9
- 9
- 6
# неправильная монетка
sample(c("Орёл", "Решка"), size = 5, replace = TRUE, prob = c(0.3, 0.7))
- 'Решка'
- 'Решка'
- 'Решка'
- 'Решка'
- 'Решка'
ЗБЧ и монетка¶
x <- sample(c("Орёл", "Решка"), size = 10^6, replace = TRUE, prob = c(0.3, 0.7))
sum(x == 'Орёл')/length(x)
4. Центральная предельная теорема (ЦПТ)¶
ЦПТ¶
При определённых условиях сумма достаточно большого числа случайных величин имеет распределение близкое к нормальному
Главное: чтобы случайные величины были похожи и не было такого, что одна резко выделяется на фоне остальных
Есть много разных ЦПТ с разными условиями
Классическая формулировка ЦПТ¶
Пусть $X_1, \ldots, X_n, \ldots$ — последовательность независимых одинаковых случайных велчин с конечным вторым моментом $E(X_i^2) < \infty$. Тогда
$$ \frac{(X_1 + \ldots + X_n) - n \cdot E(X_1)}{\sqrt{n \cdot Var(X_1)}} \overset{d}{\to} N(0,1) $$
ЦПТ и равномерное распределение¶
- Пусть $X \sim U[-1;1]$, пусть $Y = X_1 + \ldots + X_n$
n = 10^4
X1 <- runif(n, min = -1, max = 1)
X2 <- runif(n, min = -1, max = 1)
X3 <- runif(n, min = -1, max = 1)
X4 <- runif(n, min = -1, max = 1)
qplot(X1, bins = 70)

qplot(X1 + X2, bins = 70)

qplot(X1 + X2 + X3, bins = 70)

qplot(X1 + X2 + X3 + X4, bins = 70)

ЦПТ для равномерного¶

ЦПТ для $\chi^2_1$¶

Доска Гальтона¶


ЦПТ на пальцевых пальцах¶
- $Y$ — время прихода Стаса на первую пару
- На Стаса прыгнул кот и он проснулся пораньше, ускорение на $X_1$
- Пока готовил завтрак, убежало молоко, задержка на $X_2$
- Быстро приехал автобус, ускорение на $X_3$
- Встал в неожиданную пробку, задержка на $X_4$

ЦПТ и ЗБЧ как скорости¶
В ЗБЧ:
$$ \frac{X_1 + \ldots + X_n - n E(X_1)}{n} \overset{p}{\to} 0 $$В ЦПТ та же дробь домножается на $\sqrt{n}$, это замедляет сходимость и мы приходим к более интересному результату:
$$ \sqrt{n} \cdot \frac{X_1 + \ldots + X_n - n E(X_1)}{n} \overset{d}{\to} N(0, Var(X_1)) $$Крайнестан и среднестан¶
ЦПТ и ЗБЧ работают в среднестане
А что, если какая-то одна случайная величина выбивается?
Тогда мы перемещаемся из среднестана в крайнестан и сталкиваемся с проблемой тяжёлых хвостов
О тяжёлых хвостах мы ещё поговорим, они часто выскакивают в мире финансов
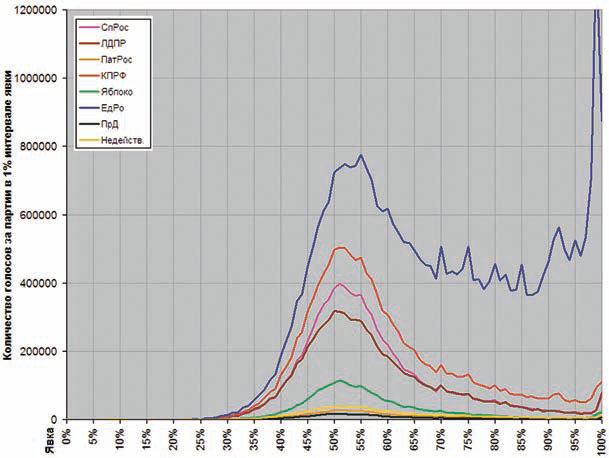
Фальш в среднестане¶

Фальш на выборах¶
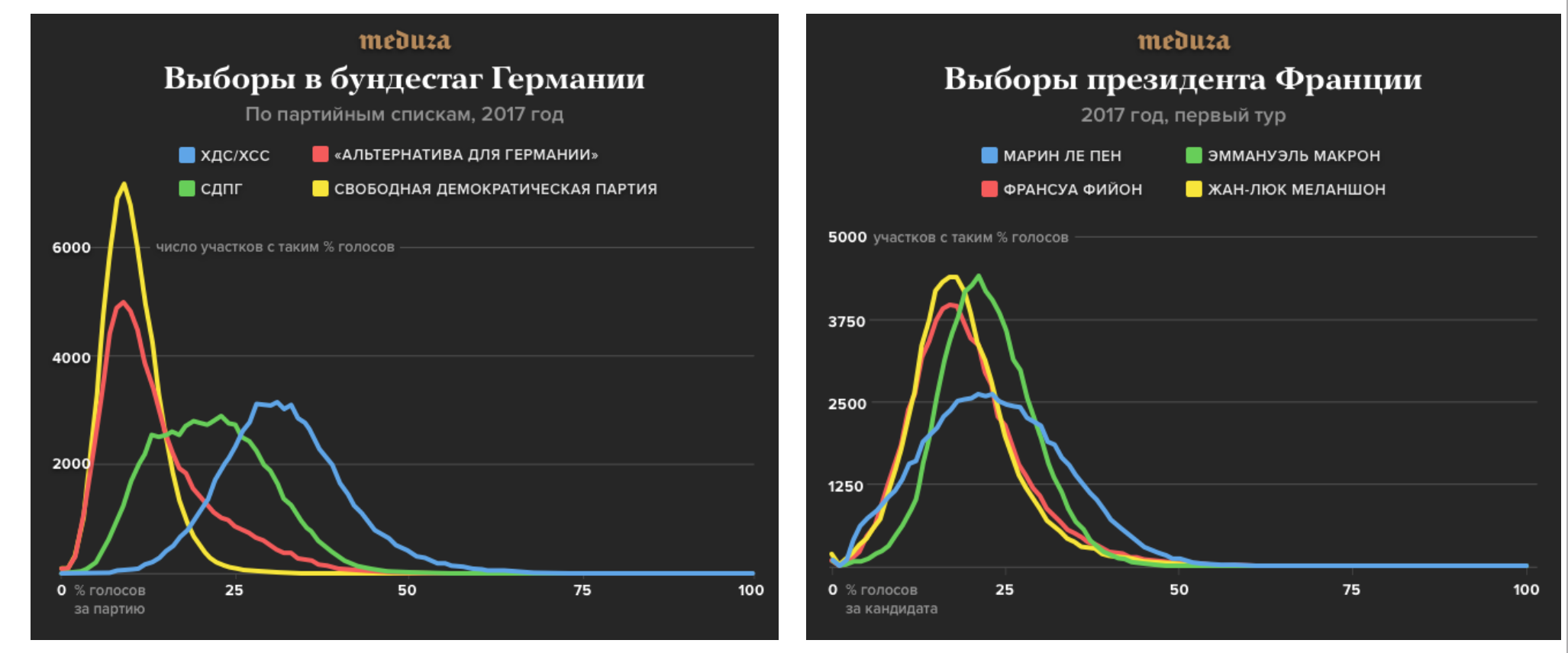
Фальш на выборах¶
5. Решаем вместе задачки на генерации¶
5.1 Камила, Вика и монетки¶
Две монеты, вероятности орла равны $0.6$ и $0.4$. Камила подбрасывает первую монетку до появления орла. Вика вторую.
а) Найдите с помощью симуляций вероятность того, что Вика сделает больше подбрасываний, чем Камила
а) Найдите с помощью симуляций вероятность того, что Вика сделает больше подбрасываний, чем Камила
n_obs = 10^6
p1 = 0.6
p2 = 0.4
# симулируем подбрасывания Вики и Камилы
x_kamila = rgeom(n_obs, prob = p1)
x_vika = rgeom(n_obs, prob = p2)
x_kamila[1:10] # в векторе стоит число подбрасываний до первого орла
- 0
- 0
- 0
- 1
- 0
- 0
- 0
- 0
- 2
- 1
sum(x_vika > x_kamila)/n_obs
б) Камила сделает больше подбрасываний, чем Вика;
n_obs = 10^6
p1 = 0.6
p2 = 0.4
# симулируем подбрасывания Вики и Камилы
x_kamila = rgeom(n_obs, prob = p1)
x_vika = rgeom(n_obs, prob = p2)
x_kamila[1:10] # в векторе стоит число подбрасываний до первого орла
- 0
- 1
- 2
- 0
- 0
- 1
- 0
- 2
- 0
- 0
sum(x_vika < x_kamila)/n_obs
в) Камила и Вика сделают одинаковое число подбрасываний
sum(x_vika == x_kamila)/n_obs
г) Верно ли, что в сумме эти три вероятности дают единицу? Логично ли это?
sum(x_vika > x_kamila)/n_obs + sum(x_vika < x_kamila)/n_obs + sum(x_vika == x_kamila)/n_obs
5.2 Человек и параход¶
Иван Фёдорович Крузенштерн (ШТО?!) случайным образом с возможностью повторов выбирает $10$ натуральных чисел от $1$ до $100$. Пусть $X$ — минимум из этих чисел, а $Y$ — максимум. С помощью симуляций оцените:
а) $P(Y > 3X)$
natural <- sample(1:100, size = 5, replace = TRUE)
natural
- 95
- 37
- 87
- 49
- 46
min(natural) # случайная величина X
max(natural) # случайная величина Y
а) $P(Y > 3X)$
n_obs = 10^6
x = rep(0, n_obs)
y = rep(0, n_obs)
for(i in 1:n_obs){
natural = sample(1:100, size = 10, replace = TRUE) # сгенерировали выборку
x[i] = min(natural) # нашли минимум и максимум для неё
y[i] = max(natural)
}
x[1:5]
- 2
- 3
- 5
- 13
- 10
success = y > 3*x
success[1:5]
- TRUE
- TRUE
- TRUE
- TRUE
- TRUE
sum(success) / n_obs
б) $E(X \cdot Y)$
mean(x*y)
в) $P(Y > 3X \mid Y < X^2)$
z <- c(1,2,3,4,5,6,7)
z > 4
z[z > 4]
- FALSE
- FALSE
- FALSE
- FALSE
- TRUE
- TRUE
- TRUE
- 5
- 6
- 7
usl = y < x^2
usl[1:5]
- FALSE
- FALSE
- FALSE
- TRUE
- TRUE
success <- y[usl] > 3*x[usl]
sum(success) / sum(usl)
г) $E(X \cdot Y \mid Y < X^2)$
mean(x[usl]*y[usl])
д) $E \left( \frac{X}{X + 2Y} \right)$
z = x/(x + 2*y)
mean(z)
е) $Corr(X,Y)$
cor(x,y)
5.3 Call me maybe¶
Известно, что в пятизначном номере телефона все цифры разные. Какова вероятность того, что при этом условии среди них только одна цифра чётная (номер может начинаться с нуля)?
# генерируем номер телефона
sample(size = 5, 0:9, replace = FALSE)
- 5
- 7
- 8
- 6
- 3
# проверяем все цифры на чётность
sample(size = 5, 0:9, replace = FALSE) %% 2
- 0
- 0
- 0
- 1
- 1
# смотрим сколько в сумме нечётных цифр
sum(sample(size = 5, 0:9, replace = FALSE) %% 2)
# и всё это в цикле!
n_obs = 10^6
m = 0
for( i in 1:n_obs){
# если 4 нечётные, значит одна чётная
if(sum(sample(size = 5, 0:9, replace = FALSE) %% 2) == 4){
m = m + 1
}
}
m/n_obs
5.4 О спорт, ты — мир¶
Для $20$ участников соревнований, среди которых $8$ российских, в гостинице забронировано $20$ номеров. Из них $12$ с видом на море. Участники соревнований наугад получают ключи от номернов. Найдите вероятность того, что номера с видом на море достанутся всем российским спортсменам.
# вектор номеров
room = c(rep('море',12),rep('пустошь',8))
room[1:5]
- 'море'
- 'море'
- 'море'
- 'море'
- 'море'
sample(room)[1:5] # перемешаем номера
- 'пустошь'
- 'пустошь'
- 'море'
- 'море'
- 'море'
# Будем считать что первые 8 позиций вектора относятся к россиянам
sample(room)[1:8] == 'море'
- FALSE
- TRUE
- FALSE
- FALSE
- FALSE
- TRUE
- TRUE
- FALSE
n_obs = 10^6
# комнаты
room = c(rep('море',12),rep('пустошь',8))
m = 0
for(i in 1:n_obs){
if(sum(sample(room)[1:8] == 'море') == 8){
m = m + 1
}
}
m/n_obs
5.5 Ещё не успели забыть ЗБЧ?¶
- В начале пары мы смотрели такую картинку, давайте нарисуем её сами!
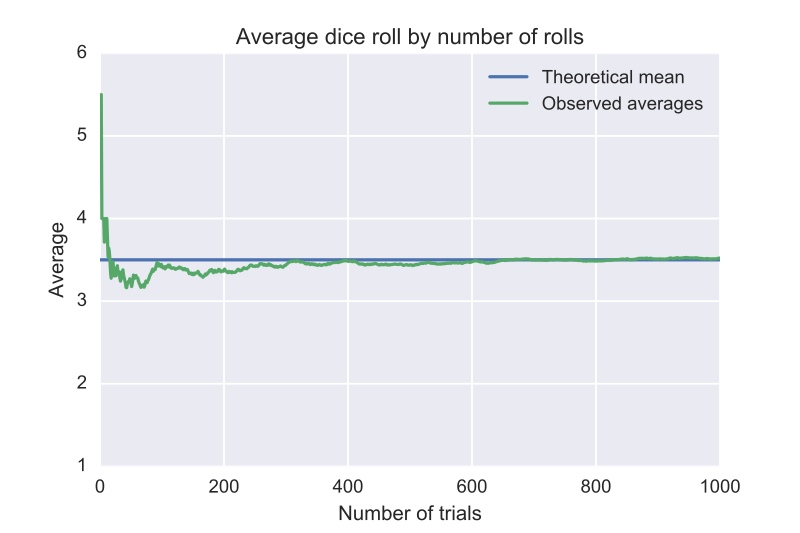
Игральная кость. Нам хочется узнать какое среднее значение на ней будет выпадать при увеличении количества бросков.
sample(1:6, size = 1, replace = TRUE)
sample(1:6, size = 2, replace = TRUE)
sample(1:6, size = 3, replace = TRUE)
sample(1:6, size = 4, replace = TRUE)
- 5
- 3
- 4
- 3
- 4
- 2
- 6
- 1
- 2
n_obs = 500
kubik = rep(0, n_obs)
for(n in 1:n_obs){ # n - количество подбрасываний кубика
# Сделали выборку
smpl = sample(1:6, size = n, replace = TRUE)
# Подсчитали среднее значение и запомнили его
kubik[n] = mean(smpl)
}
kubik[1:5]
- 4
- 6
- 3.66666666666667
- 3.5
- 4.2
qplot(1:n_obs, kubik, geom='line', xlab='number of observations', ylab='result')

df = data.frame(n = 1:n_obs, kubik = kubik, mean = rep(3.5,n_obs))
head(df,2)
| n | kubik | mean |
|---|---|---|
| 1 | 4 | 3.5 |
| 2 | 6 | 3.5 |
# https://colorscheme.ru/color-converter.html
ggplot(df, aes(n)) +
geom_line(aes(y=kubik), color="#0aa120", alpha = 0.6) +
geom_line(aes(y=mean), color="blue",size=1.2) +
xlab('number of observations') + ylab('result') +
ggtitle('Law of large numbers')

5.6 Миша продаёт газеты¶
Миша и газетный бизнес¶
Смешная предыстория, которая не влезла на слайд.
Покупать газету Миша решил по $15$ рублей, а продавать за $30$. Количество потенциальных покупателей - случайная величина с распределением Пуассона. Опытным путём было установлено, что среднее значение этой величины равно $50$. Нераспроданные газеты ничего не стоят. Пусть $n$- количество газет, максимизирующее ожидаемую прибыль Мишы.
С помощью компьютера найдите оптимальное значение $n$ и ожидаемую прибыль.
Стохастическая прибыль¶
$$ \Pi = 30 \cdot X - 15 \cdot n \to \max_{n} $$n_obs = 10^6 # число наблюдений
cost = 15 # издержки на покупку газеты
price = 30 # цена, по которой будем продавать газету
x = rpois(n_obs, lambda = 50) # среднее значение совпадает с lambda
x[1:5]
profit = x*price - 20*cost
profit[1:5]
# найдём среднюю прибыль
mean(profit)
- 51
- 40
- 35
- 62
- 53
- 1230
- 900
- 750
- 1560
- 1290
n_obs = 10^6 # число наблюдений
profits = rep(0,100) # будем записывать средние прибыли
for(s in 1:100){
x = rpois(n_obs, lambda = 50) # генерируем покупочки
x[x > s] = s # нельзя продать лишнее
profits[s] = mean(x*price - s*cost) # запоминем среднюю прибыль
}
qplot(1:100, profits, geom='line')

max(profits)
which.max(profits)
sqrt(var(profits))
Дисперсия прибыли¶
n_obs = 10^6 # число наблюдений
profits = rep(0,100) # будем записывать средние прибыли
std_error = rep(0,100) # сюда будем записыват ошибку
for(s in 1:100){
x = rpois(n_obs, lambda = 50) # генерируем покупочки
x[x > s] = s # нельзя продать лишнее
profits[s] = mean(x*price - s*cost) # запоминем среднюю прибыль
std_error[s] = sqrt(var(x*price - s*cost)) # запоминаем дисперсию
}
df = data.frame(s = 1:100, profit = profits, std_error = std_error)
head(df,2)
| s | profit | std_error |
|---|---|---|
| 1 | 15 | 0 |
| 2 | 30 | 0 |
ggplot(df, aes(s)) +
geom_line(aes(y=profit), colour="blue") +
geom_ribbon(aes(ymin = profit - 2*std_error,
ymax = profit + 2*std_error), alpha=0.2)

5.7 Зёрна¶
set.seed(42)
rnorm(1, mean = 2, sd = 3)
rnorm(1, mean = 2, sd = 3)
6. Случайные величины бывают очень разными¶
picture <- function(x){
df = data.frame(sample = x)
# Размеры картинки
options(repr.plot.width=8, repr.plot.height=3)
binwidth = 1 # ширина бинов
p1 = ggplot(df, aes(x = sample, binwidth = binwidth))+
# Наносим гистограмму
geom_histogram(aes(y=..density..), binwidth = binwidth, colour = "white",
fill = "cornflowerblue", size = 0.1)
# цвет линий разделителей, заливка, толщина линий разделителей
p2 = ggplot(df, aes(x = sample, binwidth = binwidth))+
stat_ecdf(color = "darkred", size = 1)
# Располагаем графики рядом. Этот код нужен только для юпитерской тетрадки.
pushViewport(viewport(layout = grid.layout(1, 2)))
print(p1, vp = viewport(layout.pos.row = 1, layout.pos.col = 1))
print(p2, vp = viewport(layout.pos.row = 1, layout.pos.col = 2))
}
- Как бы вы замоделировали подбрасывание монетки?
- Как бы вы замоделировали число попаданий в баскетбольную корзину?
- Биномиальное распределение используется для моделирования числа успехов в серии из $n$ испытаний
n = 1000
size = 20
p = 0.5
x <- rbinom(n, size = size, prob = p)
picture(x)

- Число людей в очереди

n = 1000
# Распределение Пуассона, Pois(lambda)
lambda =3
x <- rpois(n, lambda = lambda)
picture(x)

Распределение Пуассона часто используется для моделирования "событий-счётчиков", при этом $\lambda$ это интенсивность потока событий.
Если у нас ест несколько суммирующихся между собой потоков, их интенсивности суммируются. То есть, если
- Точное время прихода Стаса на первую пару

- Погрешность весов
n = 1000
# Нормальное распределение, N(mu, sigma)
mu = 0; sigma = 1
x <- rnorm(n, mean = mu, sd = sigma)
picture(x)

- Время до поломки станка, время до смерти, любое время между событиями в потоке

n = 10000
# Экспоненциальное распределение, Exp(alpha)
alpha = 0.1
x <- rexp(n, rate = alpha)
picture(x)

- У экспоненциального распределения нет памяти, то есть если $X \sim Exp(\alpha)$, тогда $P(X > s+t \mid X \ge s) = P(X > t)$
- Пример: пусть автобусы приходят на остановку случайно, но с некоторой фиксированной средней интенсивностью. Тогда количество времени, уже затраченное пассажиром на ожидание автобуса, не влияет на время, которое ему ещё придётся прождать
- Время между потоком пуассоновских событий имеет экспоненциальное распределение
- $Exp(\frac{1}{2}) = \chi^2_2$
- Время, в которое в течение суток родится ребёнок
# Равномерное распределение, U[mn;mx]
n = 10000
mn=0; mx=24
x <- runif(n, min = mn, max = mx)
picture(x)

Взаимосвязи между распределениями¶
Что мы сделали?¶
- Поняли, что тервер и матстат помогают нам выразить наше невежество
- Вспомнили что такое ЗБЧ и ЦПТ и поговорили о том какие вещи они нам разрешают делать
- Поговорили о том как в R генерируются случайные величины и решили пару задачек
- Обсудили, что распределения бывают разными
- Поделились на команды
- Приступили к решению первой домашки