
R для тервера и матстата.
Домашка номер раз!
Домашка номер раз!
Данный ноутбук является домашкой по курсу «R для теории вероятностей и математической статистики» (РАНХиГС, 2019). Автор ноутбука - вот этот парень по имени Филипп. Если у вас для него есть деньги, слава или женщины, он от этого всего не откажется. Ноутбук распространяется на условиях лицензии Creative Commons Attribution-Share Alike 4.0. При использовании обязательно упоминание автора курса и аффилиации. При наличии технической возможности необходимо также указать активную гиперссылку на страницу курса. На ней можно найти другие материалы. Фрагменты кода, включенные в этот notebook, публикуются как общественное достояние.
Приветствую вас внутри первой домашки. У каждой домашки должны быть свои герои (но это не точно). Моими героями являетесь вы! Вы - герои не потому, что я хочу кого-то простебать или обидеть, а потому что, когда любишь, хочется увековечить. Кто-то называет именами любимых людей вновь открытые звёзды и острова, кто-то созданную для нира папку на рабочем столе, а кто-то делает их героями своих историй. Будем искренне верить и надеяться, что я не Джордж Мартин, и в моих историях никто не погибнет.
Краткий брифинг:
- Дедлайн: 12.05.19
- Первая домашка затрагивает то, что мы смотрели на первых двух парах.
- Тетрадка делится на две части: рыбёшки (60 баллов) и кит (40 баллов).
- Часть задач нужно решить не только с помощью симуляций, но и вручную.
- Ваша команда пытается решить как можно больше задач и присылает их мне.
Ближе к делу. С чего начинается любой скрипт? Правильно! С подгрузки пакетов :)
library("ggplot2") # Пакет для красивых графиков
library("grid") # Пакет для субплотов
# Отрегулируем размер картинок, которые будут выдаваться в нашей тетрадке
library('repr')
options(repr.plot.width=4, repr.plot.height=3)
# Внимание! Если вы делаете дз в Rstudio, то вам не нужны пакеты grid, repr и т.п.
# Вам нужен только пакет ggplot2!
Полезные функции:¶
rep(2, 5) # повторяет число 2 целых 5 раз
- 2
- 2
- 2
- 2
- 2
seq(0, 1, 0.2) # выдаёт все числа от 0 до 1 с шагом 0.2
- 0
- 0.2
- 0.4
- 0.6
- 0.8
- 1
x <- c(1, 2, 3)
y <- c(2, -1, 4)
z <- c(3, 5, 2)
pmin(x, y, z) # находит поэлементные минимумы во всех векторах
- 1
- -1
- 2
which.max(x) # выдаёт позицию максимума
cumprod(x) # кумулятивное (накапливающееся) произведение
# 1, 1*2, 1*2*3 и тд
- 1
- 2
- 6
cumsum(x) # кумулятивная сумма
# 1, 1 + 2, 1 + 2 + 3 и тд
- 1
- 3
- 6
# В R можно писать вот такие пафосные циклы:
# item будет по очереди принимать все значения из списка c(5,77,3)
# это питоновский стиль написания циклов, привыкайте :)
for(item in c(5,77,3)){
print(item^2)
}
[1] 25 [1] 5929 [1] 9
1. Мелкие рыбёшки¶
В этом разделе вас ждёт много довольно простых задачек.
[2] Задачка 1 (скучная)¶
В R куча встроенных наборов данных. Например, в наборе данных women лежит немного данных про рост и вес американских женщин.
head(women,5) # команда head позволяет посмотреть на
# первые пять строк таблички
| height | weight |
|---|---|
| 58 | 115 |
| 59 | 117 |
| 60 | 120 |
| 61 | 123 |
| 62 | 126 |
- Постройте гистограмму с распределением веса женщин
- Постройте эмпирическую функцию распределения для веса женщин
- Постройте scatterplot веса и роста
Найдите базовые характеристики распределения:
- средний вес женщины
- медианный вес женщины
- дисперсию веса женщины
- среднее квадратическое отклонения веса женщин
- эмпирические квантили уровня 5%, 50% и 95%.
- правда ли, что 50% квантиль совпал с медианой? А почему?
- почему я выбрал для этого задания именно этот датасет? (За правильный ответ на этот вопрос плюс 4 балла)
x = women$weight
qplot(x, bins=7)

ggplot(women, aes(x = weight)) + stat_ecdf( )

qplot(women$weight, women$height)

mean(x)
median(x)
var(x)
sd(x)
quantile(x,c(0.05, 0.5, 0.95))
- 5%
- 116.4
- 50%
- 135
- 95%
- 160.5
# да правда, она и есть 50% квантиль
# не буду тут это писать, спросите лично
[2] Задачка 2¶
Случайная величина $X$ имеет распределение Пуассона с $\lambda = 2$. Иногда пишут, что $X \sim Pois(2)$. С помощью симуляций оцените $P(X > 10)$, $P(X > 10 \mid X > 5)$, $P(X > 5 \cap X < 7)$, а также $E(X^7)$ и $E(X \mid X > 5)$.
Решение: Всегда, когда генерируете какую-то случайную величину, стаьте seed для воспроизводимости. Мало ли я перезапущу ваш код, а там сгенерируется совсем другое...
set.seed(42) # ставьте всегда како
n_obs = 10^6
x <- rpois(n_obs, lambda = 2) # сгенерировали выборку
mean(x)
Ещё имеет смысл проверить правда ли оценка $\lambda$ после генерации равна $2$. Если отличается, не очень хорошо. Всегда, когда делаете генерации, чётко следите за тем, что в вашей выборке предпосылки $\pm$ выполнены.
# P(X > 10)
mean(x > 10)
# либо
1 - ppois(10, lambda = 2)
# P(X > 10 | X > 5)
mean(x[x > 5] > 10)
# P(X > 5 & X < 7)
mean((x > 5) & (x < 7))
# E(X^7)
mean(x**7)
#E(X | X > 5)
mean(x[x > 5])
[1] Задачка 3¶
Предположим, что вы получаете в среднем три спам-письма в день. Какова доля дней, в которые вы получаете пять или больше спам-писем?
Решение: Нам дана свобода мыслить, как мы хотим. Предполался примерно такой ход мыслей: спам-письма это случайная величниа - счётчик. Наверное, её логично моделировать распределением Пуассона.
Можно было найти вероятность либо через функцию распределения:
# 1 - P(X <= 4) = 1 - F(4)
1 - ppois(4, lambda=3)
либо напрямую через вероятности:
# 1 - [P(X = 0) + P(X = 1) + ... + P(X = 4)]
1 - (dpois(0, lambda=3) + dpois(1, lambda=3) + dpois(2, lambda=3) + dpois(3, lambda=3) + dpois(4, lambda=3))
[4] Задачка 4¶
Куратор Вова случайным образом с возможностью повторов выбирает $5$ натуральных чисел от $1$ до $100$. После выбора он раздаёт эти числа $5$ второкурсникам. Каждый второкурсник берёт экспоненциальное распределение $Exp(\lambda_i)$, где $\lambda_i$ - число, выданное Вовой, и выбрасывает из него случайное число. Получаются случайные величины $X_1, X_2, X_3, X_4$ и $X_5$.
После этого Вова собирает все выпавшие числа назад и вычисляет
$$ Y_1 = \min(X_1, \ldots, X_5), \qquad Y_2 = \max(X_1, \ldots, X_5),$$а также
$$ Z = \frac{Y_1}{Y_1 + Y_2}.$$С помощью симуляций оцените:
a) $P(Y_2 > 3 Y_1)$
n_obs <- 10^6
x1 <- rep(0, n_obs)
y1 <- rep(0, n_obs)
y2 <- rep(0, n_obs)
for(i in 1:n_obs){
x = sample(size=5, x=1:100, replace = TRUE)
cur = rep(0, 5)
for(j in 1:5){
# важно! вектор иксов - один, их не два!
cur[j] = rexp(1, rate = x[j])
}
x1[i] = cur[1]
y1[i] = min(cur)
y2[i] = max(cur)
}
z = y1/(y1 + y2)
mean(y2 > 3*y1)
б) $E(Z)$ и $Var(Z)$
mean(z)
var(z)
в) $P(Y_2 > 3 \cdot Y_1 \mid Z > 0.5)$
usl = z > 0.5
sum(usl) # =(
# Неудачно я этот пункт сформулировал :(
г) $E(Z \mid X_1 > 80)$
mean(z[x1 > 80])
д) $Corr(Z, Y_1)$, $Corr(Z, Y_2)$, $Corr(Y_1, Y_2)$
# Тут надо было спросить у вас про интуицию, и только потом просить генерить
cor(z, y1)
cor(z, y2)
cor(y1, y2)
е) постройте гистограмму для случайной величины $Z$
qplot(z, bins=100)

[2] Задачка 5¶
Юра завёл себе две нейросетки и два сервера и начал их обучать. Две нейросети обучаются независимо на двух серверах. Время их обучения $T_1$ и $T_2$ равномерно распределено на отрезке $[1;3]$ (обучение измеряется в минутах). В процессе обучения сервер может упасть. Момент падения сервера $T$ распределён экспоненциально с параметром $\lambda = 0.3$. Момент падаения сервера не зависит от времени обучения нейросеток. Известно, что одна из нейросетей успела обучиться, а вторая не успела. Какова вероятность того, что $T \le 1.5$?
Hint: при решении задачи помните о том, что у вас две нейросетки!
T1 <- runif(n_obs, min = 1, max = 3)
T2 <- 3*runif(n_obs) + 1 # то же самое можно сгенеить вот так
T <- rexp(n_obs, rate = 0.3)
Тут генерация на формулу Байеса, но для непрерывных случайных велчин. У нас есть бсесконечное число гипотез, нас интересует отрезок $T \le 1.5$ для пересчёта :)
usl1 = (T1 >= T)&(T2 < T) # Первая не смогла обучиться, вторая смогла
usl2 = (T1 < T)&(T2 >= T) # Наоборот
# оценка для полной вероятности (кстати говоря, так то она не нужна)
mean(usl1 | usl2)
# Находим нужную вероятность
mean(T[usl1 | usl2] <= 1.5)
length(T[usl1 | usl2]) # проверка достаточно ли событий для оценки
Error in eval(expr, envir, enclos): объект 'usl1' не найден Traceback:
Важно! Если вы оцениваете вероятность, как сумму делить на сумму, то тут нужно делить не на n_obs, а на sum(usl1 | usl2), так как известно, что одна из нейросетей упала.
sum(T[usl1 | usl2] <= 1.5)/sum(usl1 | usl2)
[4] Задачка 6¶
Каждый день Света съедает случайное количество булочек, которое распределено по Пуассону с параметром $10$. Логарифм затрат в рублях на каждую булочку распределён нормально $N(2,1)$. Ксюша каждый день съедает биномиальное количество булочек $Bin(8, 0.5)$. Затраты Ксюши на каждую булочку распределены равномерно на отрезке $[2;20]$.
Решение: можно прочесть задачу двояко. Первый вариант: цена на все булочки в рамках одного дня одинаковая. Второй вариант: цена на каждую булочку в течение дня случайная. Я имел в виду первый вариант.
а) Сколько в среднем Света тратит на булочки за день?
n_obs = 10^6
x1 = rpois(n_obs, lambda = 10) # спрос светы на булочки
p1 = rnorm(n_obs, mean=2, sd=1) # цена булочек
costs1 = exp(p1)*x1 # расхрды Светы
mean(costs1)
б) Чему равна дисперсия дневных расходов Светы?
var(costs1)
в) Какова вероятность того, что за один день Света потратит больше денег, чем Ксюша?
# Осторожнее! В rbinom аргумент n - число генераций, size - число испытаний!
# rbinom(n, size, prob)
# https://www.tutorialspoint.com/r/r_binomial_distribution.htm
x2 = rbinom(n_obs, size = 8, prob = 0.5) # спрос светы на булочки
p2 = runif(n_obs, min=2, max=20) # цена булочек
costs2 = p2*x2 # расходы Ксюши
mean(costs2)
# нужная вероятность
mean(costs1 > costs2)
г) Какова условная вероятность того, что Света за день съела больше булочек, чем Ксюша, если известно, что Ксюша потратила больше денег?
usl <- costs1 < costs2
mean(x1[usl] > x2[usl])
sum(usl) # много ли у нас примеров для оценивания
[3] Задачка 7¶
Удав Анатолий любит французские багеты. Длина французского багета равна $1$ метру. За один заглот Удав Анатолий заглатывает кусок случайной длины, равномерно распределённый на отрезке $[0;1]$. Для того, чтобы съесть весь багет удаву потребуется случайное количество $N$ заглотов.
Найдите $E(N)$ и $Var(N)$. Как поменяются ответы, если багет имеет длину $2$ метра?
Кстати говоря, эту задачку можно решить руками с помощью метода первого шага. Его мы разберём на второй паре. Правда для этого придётся выписать систему из двух уравниний с интегралами. В сборнике сложных задач по терверу, культурном коде, можно найти три разных решения этой задачки. Она там находится под номером $46$.
# Багеты! Давайте начнём с одной итерации эксперемента
l = 1 # длина багета
m = 0 # число заглотов
# пока длина багета больше 0
while(l > 0){
# делай заглоты
l = l - runif(1)
m = m + 1 # на один заглот стало больше
}
m
В принципе это всё. Теперь нужно сделать этот эксперимент с заглотами много-много раз.
n_obs <- 10^6
N <- rep(0, n_obs)
for(i in 1:n_obs){
l = 1 # длина багета
m = 0 # число заглотов
# пока длина багета больше 0
while(l > 0){
# делай заглоты
l = l - runif(1)
m = m + 1 # на один заглот стало больше
}
N[i] = m # сохранили текущее число заглотов
}
mean(N)
var(N)
[2] Задачка 8¶
На шнуре длиной $1$ м случайным образом делают два разреза. С какой вероятностью хотя бы один из получившихся кусков будет длиннее $0.5 м$?
n_obs = 10^6
x1 = runif(n_obs) # первый надрез
x2 = runif(n_obs) # второй надрез
usl_1 = (x1 < x2)&(x1 > 0.5 | x2 - x1 > 0.5 | 1 - x2 > 0.5) # первый вариант
usl_2 = (x1 >= x2)&(1 - x1 > 0.5 | x1 - x2 > 0.5 | x2 > 0.5) # второй вариант
mean(usl_1 | usl_2)
[2] Задачка 9¶
Семён любит мешать не только джим бим с колой, но и распределения! И вот сейчас две трети её данных идут в смесь из экспоненциального распределения с параметром $\lambda = 1$, а остальная треть из стандартного нормального. Как это часто бывает, Сёма сначала намешал, а потом чёт подумал-подумал и всё Диме отдал. И теперь у Димы проблема со свойствами намешанного распределения.
Сгенерируйте выборку из распределения Семёна и помогите Диме оценить математическое ожидание и дисперсию случайной величины, постройте гистограмму.
n_obs <- 10^6
# round, чтобы код не бросал ошибку
X1 <- rexp(round(2/3*n_obs), rate = 1)
X2 <- rnorm(round(1/3*n_obs))
# объединили в одно целое
Y <- c(X1,X2)
mean(Y)
var(Y)
qplot(Y, bins=100) # обратите внимание на то, что правый хвост очень длинный

[3] Задачка 10¶
Помните? Мы всё это изучаем, чтобы решать реальные проблемы! С помощью генераций в R мы можем оценить любое математическое ожидание и любые вероятности. Нам позволяет сделать это великий и могучий фундаментальный ЗБЧ!
Давайте попробуем проверить несколько свойств математических ожиданий и дисперсий, которые вы доказали на лекциях по теории вероятностей в прошлом семестре. Выберите конкретные случайные величины (любые) и проверьте для них утверждения, перечисленные ниже.
# Хочу экспоненциальную и равномерную, нанизанную на экспоненциальную!
# Так зависимсоть между величинами будет
n_obs = 10^6
x = rexp(n_obs, rate = 2)
y = x + runif(n_obs, min = 2, max = 5)
a) Верно ли, что $E(X + Y) = E(X) + E(Y)$?
# a) Из курс тервера мы знаем, что это правда всегда
mean(x + y)
mean(x) + mean(y)
b) Верно ли, что $E(X \cdot Y) = E(X) \cdot E(Y)$?
# b) Ну тут явно чего-то не хватает...
mean(x*y)
mean(x)*mean(y)
# Давайте посмотрим лекции по терверу и вспомним чего не хватает :)
mean(x)*mean(y) + cov(x,y)
c) Верно ли, что $Var(X + Y) = Var(X) + Var(Y) + 2 \cdot Cov(X,Y)$?
#c) Это чистая правда! В лекциях даже доказательство есть!
var(x + y)
var(x) + var(y) + 2*cov(x,y)
d) Верно ли, что $Var(X \cdot Y) = Var(X) \cdot Var(Y)$?
#d) Ложь! Очередная! А слабо найти правильную формулу? Она довольно неочевидна :)
var(x*y)
var(x)*var(y)
e) Верно ли, что если $Cov(X, Y) = 0$, то две случайные величины независимы? Удастся ли проверить это с помощью генераций?
Это наглая ложь! Простейший пример. Пусть случайная величина $X$ равновероятно принимает три значения:
| $X$ | $-1$ | $0$ | $1$ |
|---|---|---|---|
| $P$ | 1/3 | 1/3 | 1/3 |
Пусть $Z = |X|$.
| $Z$ | $0$ | $1$ |
|---|---|---|
| $P$ | 1/3 | 2/3 |
Тогда эти две виличины явно зависимы. Одна выражается через другую. Но при этом
$$ Cov(X,Z) = E(X \cdot Z) - E(X) \cdot E(Z) = 0. $$x = sample(c(-1,0,1), size = n_obs, replace = TRUE)
z = abs(x) # задаём зависимость между z и x
cov(x,z) # получаем близкое к нулю число
[4] Задачка 11¶
Филя и Никита решили попытать счастье и попасть на стажировку в ЦБ. В качестве вступительного испытания, они получили листочки с задачками по терверу и случайным процессам. Одна из задач из листочка выглядела следующим образом:
Пусть $X \sim N(0, \sigma^2)$. Пусть $\Phi(x)$ — функция распределения для $N(0,1)$. Нужно найти математическое ожидание для случайной величины $\Phi(X)$.
Собеседователи, дав Филе и Никите задание, сказали, что у них 2 часа, и куда-то ушли. Пользоваться можно чем угодно (но это не точно). В голове у парней есть какое-то решение. Правда они в нём не уверены. Зато у них с собой есть ноутбуки. Помогите Филе и Никите оценить $E(\Phi(X))$ с помощью симуляций. Постройте для случайной величины $\Phi(X)$ гистограмму. Возьмите $\sigma = 1$, после $\sigma = 3$, после $\sigma = 100$. Как ведут себя математическое ожидание и распределение при росте дисперсии?
P.S. На стажировку в ЦБ парни конечно же не попали.
# В этом пункте всё логично, в соответствии с квантильным преобразованием
# (на него мы посмотрим на третьей паре) мы получили равномерное распределение
n_obs = 10^6
x <- rnorm(n_obs, mean=0, sd=1)
y <- pnorm(x)
mean(y)
qplot(y)
`stat_bin()` using `bins = 30`. Pick better value with `binwidth`.

# Тут уже результат будет поинтереснее и непредсказумее!
# распределение начало разъезжаться в разные стороны
n_obs = 10^6
x <- rnorm(n_obs, mean=0, sd=3)
y <- pnorm(x)
mean(y)
qplot(y)
`stat_bin()` using `bins = 30`. Pick better value with `binwidth`.

# При огромной дисперсии оно совсем-совсем разъехалось и
# в пределе получится дискретная случайная величина!
n_obs = 10^6
x <- rnorm(n_obs, mean=0, sd=100)
y <- pnorm(x)
mean(y)
qplot(y)
`stat_bin()` using `bins = 30`. Pick better value with `binwidth`.

Давайте попробуем повыяснять почему такое происходит. Для этого решим по-честному теоретическую задачку и найдём предел для функции распределения нашей новоиспечённой случайной величины. $\Phi(x)$ - функция распределения, значит принимает значения на отрезке от $0$ до $1$. Найдём функцию распределения случайной величины $Y = \Phi(X)$. Будем делать это по определению:
$$ F(y) = P(Y \le y) = \begin{cases}0, \text{ если } y \le 0 \\ 1, \text{ если } y > 1 \\ P(\Phi(X) \le y), \text{ если } y \in (0; 1]. \end{cases} $$Самая интересная тут последняя строчка. Немного поработаем с ней.
$$ P(\Phi(X) \le y) = P(X \le \Phi^{-1}(y)) = P \left( \frac{X}{\sigma} \le \frac{ \Phi^{-1}(y)}{\sigma} \right) = \Phi \left( \frac{ \Phi^{-1}(y)}{\sigma} \right). $$Дело осталось за малым, найти придел для функции распределения случайной величины $Y$. При $\sigma \to \infty$ выражение $\frac{ \Phi^{-1}(y)}{\sigma}$ сходится к нулю. Нормальное распределения симметрично относительно нуля. Значит $\Phi(0) = \frac{1}{2}$. В пределе получаем функцию
$$ F(y) = P(Y \le y) = \begin{cases}0, \text{ если } y \le 0 \\ 1, \text{ если } y > 1 \\ \frac{1}{2}, \text{ если } y \in (0; 1]. \end{cases} $$Как мы помним из лекций, функция распределения всегда задаёт какую-то одну конкретную случайную величину. В данном случае мы получили функцию распределения для случайной величины, принмающей либо значение $1$ либо $0$ с вероятностями $0.5$. Ровно этот резулььаь выше у нас получился на графике.
[6] Задачка 12¶
За генерацию можно получить только 1 балл. Она, блин, делается в две строчки. Остальное ставится за ручное решение.
Чтобы получить на посвяте стакан Уколовки, разлитый лично Димой Генераловым, нужно решить задачку по терверу. Случайные величины $X$, $Y$ и $Z$ равномерны на отрезке $[0;1]$ и независимы. Диму интересует случайная величина $(XY)^Z$. Ему очень интересно было бы узнать её распределение.
n_obs = 10^6
X <- runif(n_obs)
Y <- runif(n_obs)
Z <- runif(n_obs)
M = (X*Y)**Z
qplot(M)
`stat_bin()` using `bins = 30`. Pick better value with `binwidth`.

# Понравилось у парней, что они проверили что распределение равномерное тестом Колмогорова.
# Про это мы будем говорить в будущем, поэтому это забегание вперёд паровоза, но забегание правильное.
ks.test(M, "punif", 0, 1)
One-sample Kolmogorov-Smirnov test data: M D = 0.00078834, p-value = 0.5632 alternative hypothesis: two-sided
Это было довольно просто, не так ли? Давайте займёмся кое-чем более интересным, попробуем найти плотность распределения случайной величины $(XY)^Z$ вручную. Это не особо сложно. Перед нами просто-напросто возникнет несколько интегралов, которые придётся взять. Задача, как и Удав Анатолий из культурного кода. Но её решения там нет.
a) Какое распределение имеет случайная величина $- \ln X$?
Решение:
$X, Y, Z$ распределены равномерно на $[0; 1]$. Для них $F(x) = x$. Давайте найдём плотность случайной величины $X_1 = -\ln X$. План будет таким: из определения найдём функцию распределения, а потом возьмём от неё производную. Погнали:
$$ F(x_1) = P(X_1 \le x_1) = P(- \ln X \le x_1) = P(\ln X \ge -x_1) = 1 - P(\ln X \le -x_1) = 1 - P(X \le e^{-x_1}) = 1 - e^{-x_1} $$Берём производную, получаем плотность распределения:
$$ f(x_1) = F'(x_1) = -e^{x_1} $$Не забываем про область определения случайной величины. Если $x \in [0; 1]$, тогда $-\ln x \in [0; + \infty)$. Выходит, что $X_1$ имеет экспоненциальное распределение, $Exp(1)$.
б) Какое распределение у случайной величины $-(\ln X + \ln Y)$
Решение:
Нам надо понять как распределена сумма $X_1 + Y_1$, то есть сумма двух независимых экспоненциальных случайных величин. Можно пойти в семинары, вспомнить формулу свёртки и воспользоваться ей. Вспомните как она выводится, ибо в следующем пункте нам надо будет самостоятельно вывести свёртку для произведения. Итак, $U = X_1 + Y_1$. Формула свёртки выглядит как-то так:
$$ f(u) = \int_{-\infty}^{+\infty} -e^{-x_1} \cdot - e^{-(u - x_1)} dx_1 $$Немного поразбираемся в том, как ведут себя наши случайные величины. Обе принимают значение от $0$ до $+\infty$. У первой экспоненты в степени всё хорошо всегда, $x_1$ модет ползать по всему отреку. Для второй экспоненты, в степени находится $x_2 = u - x_1$. Мы знаем, $x_2$ должен принимать значения от $0$ до $+\infty$. Но если $x_1 > u$, тогда наступает беда и степень становится отрицательной. Когда $x_2$ отрицательный, плотность принимает нулевое значение.

Получается, что на отрезке $[0; u]$ наша плотность будет ненулевой. В диапазоне между отчаянием и надеждой $(-\infty; 0)$ и $(u; +\infty)$. Случайная величина зануляется.
На $u$ никих дополнительных ограничений не накладывалось. Она бегает от $[0; + \infty)$, как ей и положено.
в) Найдите функцию распределения для случайной величины $-Z (\ln X + \ln Y)$
Решение:
Нам нужно вывести аналог формулы свёртки для произведения, а после найти как распределена случайная величина $T = U \cdot Z$. Посмним, что $U$ бегает от $0$ до $+\infty$, а $Z$ от $0$ до $1$. Выведем для $T$ функцию распределения:
$$ F_T(t) = P(T \le t) = P(Z \cdot U \le t) $$Нам нужно найти эту вероятность. Случайные величины взаимосвязаны между собой формулой $t = x_1 \cdot x_2$. Нарисуем картиночку.

Нас интересует область, где $x_1 \cdot x_2 \le t$, то есть $x_2 \le \frac{t}{x_1}$. То есть область под синей кривой. Будем держать в голове, что по оси $x_2$ мы можем поднятся наверх только до $1$. Эта ось отвечает за случайную величину $Z$.
Выходит, что вероятность того, что при произвольном $t$ выполнится $x_1 \cdot x_2 \le t$ равна площади под синей кривой. То есть
$$ F_T(t) = P(T \le t) = P(Z \cdot U \le t) = \int_0^1 \int_0^{\frac{t}{x_2}} f(x_1) \cdot f(x_2) dx_1 dx_2. $$Взяв этот двойной интеграл, получаем функцию распределения:
$$ = \int_0^1 \int_0^{\frac{t}{x_2}} x_1 \cdot e^{-x_1} \cdot 1 \cdot dx_1 dx_2 = 1-e^{-t}. $$Для полноты картины выведем формулу свёртки для произведения случайных величин (так скучно написал эту фразу, аж самому тошно). Интерал выше - это функция распределения. Чтобы получить из неё плотность, нужно взять производную по $t$. Сделаем это. Не будем забывать, что $x_1 = \frac{t}{x_2}$.
$$ f_T(t) = \int_0^1 \frac{1}{x_2} \cdot f(\frac{t}{x_2}) \cdot f(x_2) d x_2 $$Если воспользоваться этой формулой, можно получить
$$ f_T(t) = e^{-t}. $$Обратите внимание, что здесь мы играли только в положительной области ($x > 0, y>0$). Если бы игра шла на всей числовой прямой, формула была бы немного другой. Пример выведения формулы для частного случайных величин можно глянуть в Гнеденко на странице 143. Там же, кстати говоря, можно найти выведение плотностей для $\chi^2_n$, Cтьюдента и Фишира. Мало ли вас всегда интересовало почему они именно такие.
г) Наконец вы готовы ответить на главный вопрос: какое распределение у $(XY)^Z$.
Решение:
Мы получили, что $T = -Z (\ln X + \ln Y) = -\ln(XY)^{Z} \sim Exp(1)$. Интересующая нас $W = (XY)^Z = e^{-T}$.
$$ F(w) = P(W \le w) = P(e^{-T} \le w) = P(-T \le \ln w) = 1 - P(T \le - \ln w) = 1 - (1 - e^{-\ln w}) = w $$Посмотрим на область определения. $T$ распределена от $0$ до $+\infty$. Значит $e^{-T}$ от $0$ до $1$. Получаем на выходе, что $W \sim U[0;1]$.
[2] Задачка 13¶
Пока все однокурсники Самира занимались одномерными случайными величинами, он увлёкся матрицами. И вот теперь он хочет пропихнуть свои увлечения в теорию вероятностей. Самир собирается сгенерировать случайную квадратную матрицу $A$, где каждый элемент матрицы взят из равномерного на $[0;1]$ распределения.
Пусть случайная величина $X$ — это определитель случайной матрицы. Помогите Самиру найти $E(X)$. Чему равна вероятность того, что матрица $A$ вырождена? Постройте для этой случайной величины гистограмму.
Пусть случайная величина $Y$ — это самое большое собственное значение этой матрицы. Помогите Самиру найти $E(Y)$. Постройте гистограмму.
Перед тем как решать задачу, выскажите свои априорные представления относительно этих распределений, опираясь на свою интуицию и знание линала. Подтвердились ли они?
n_obs = 10^5
# размерность матрицы можно было зафиксировать, можно было выбирать
# на каждом шаге рандомно (почему бы и нет, в условии ничего ж не прописано)
# в решении поступлю вторым способом
x <- rep(0, n_obs)
y <- rep(0, n_obs)
for(i in 1:n_obs){
n = sample(2:10, size = 1) # выберем какуюнибудь размерность
A = matrix(runif(n^2), nrow=n, ncol=n, byrow=T)
x[i] <- det(A)
# иногда собственные числа бывают комплексными, будем брать модуль от них
# (почему нет? в условии это не запрещалось)
y[i] <- max(abs(eigen(A)$values))
}
qplot(x, bins=100)

mean(x) # билзко к нулю, с чего бы этого...
qplot(y, bins=100) # классная же гистограмма! просто огненная!

mean(y)
[4] Задачка 14¶
Закон больших чисел — это теорема, которая позволяет людям зарабатывать деньги! В 1600-х годах люди научились составлять актуарные таблицы. Это такие таблицы, где указана ожидаемая продолжительность жизни для данного возраста и пола. Люди начали собирать данные о смертности и оценивать вероятность дожития человека до определённого возраста. На этом строились тарифы на страхование.
Появление подобных таблиц обязано зарождению в течение 1600-х годов теории вероятности, которая впервые объяснила людям как случайные вещи при достаточно больших масштабах сглаживаются и становятся очень даже предсказуемыми. Надо признать, что у страхования было довольно трудное детство — как раз потому, что люди плоховато понимали концепцию вероятности. В голове довольно трудно удержать её. Многие люди и по сей день ошибочно думают, что могут влиять на случайность каким-то образом. Например, некоторые думают, что чаще других выбрасывают на кубике шестёрки. Более того, люди довольно плохо понимают условные вероятности.
Несмотря на всё это недопонимание, страховые компании в наше время на диверсификации рисков делают кэш. Давайте представим, что мы в их шкуре и замутим простенький бизнес, связанный со страховками. Конечно же бизнес мы будем делать в России. Для того, чтобы как следует сделать его, мы нашли актуарные таблицы для России 2009 года выпуска.
df = read.csv('/Users/fulyankin/Yandex.Disk.localized/R/R_prob_data/aktuar2009.csv', sep=';', dec=',')
head(df)
| X | Мужчины.и.женщины.город | Мужчины.город | Женщины.город | Мужчины.и.женщины.село | Мужчины.село | Женщины.село |
|---|---|---|---|---|---|---|
| 0 лет | 0.992525 | 0.991658 | 0.993442 | 0.990321 | 0.989209 | 0.991496 |
| 1 год | 0.999307 | 0.999221 | 0.999397 | 0.998812 | 0.998709 | 0.998921 |
| 2 года | 0.999558 | 0.999517 | 0.999601 | 0.999358 | 0.999298 | 0.999420 |
| 3 года | 0.999668 | 0.999609 | 0.999730 | 0.999441 | 0.999288 | 0.999601 |
| 4 года | 0.999700 | 0.999671 | 0.999731 | 0.999524 | 0.999445 | 0.999607 |
| 5 лет | 0.999695 | 0.999636 | 0.999757 | 0.999515 | 0.999444 | 0.999589 |
В табличке находится вероятность того, что человек проживёт конкретный год. В первой строке вероятность дожить до года, во второй до 2 лет, если человек уже дожил до года и так далее. Значит, если мы хотим узнать, какова вероятность того, что человек проживёт два года, мы должны умножить вероятность прожить первый год на вероятность прожить второй год. Из части полезные функции, которая была в самом начале, можно узнать, что посчитать такую вероятность, помогает функция cumprod. Давайте посмотрим каково в России живётся женщинам и мужчинам.
df['age'] = 0:100
df['man_prob'] = cumprod(df[,3]) # вероятность дожить до какого-то возраста
df['woman_prob'] = cumprod(df[,4])
ggplot(df, aes(age))+
geom_line(aes(y=man_prob, colour = "man"))+
geom_line(aes(y=woman_prob, colour = "woman"))

Что мы видим? А ничего хорошего. Рыжая кривая — вероятность того, что мужчина доживёт до конкретного возраста. Голубая - женщина. Женщины намного живучее, чем мужчины. Страховать их от несчастий намного выгоднее. Было бы интересно узнать насколько это выгоднее. Будем смотреть на женщин и мужчин, которые живут в городах.
Пусть мы продаём страховки только 25-летним городским дамам. Сколько нужно клиентов, чтобы с вероятностью 99% прибыль оказалась положительной.
Пусть мы продаём страховки только 60-летним городским дамам по той же цене. Сколько нужно клиентов, чтобы с вероятностью 99% прибыль оказалась положительной.
Для простоты будем предполагать, что выплата в случае смерти составляет $10^6$ рублей.
df_small = df[c('X','Женщины.город')]
p_wom = as.numeric(df_small[df_small['X'] == '25 лет'][2])
p_wom
Давайте начнём с теории (всё то, что я буду писать ниже, было у вас в лекциях в первом семестре после формулы Лапласа, переосмыслите их). Прикинем исходя из ЦПТ сколько нам нужно людей для положительной прибыли. Мы помним, что если $X_i$ — прибыль с одной страховки и $L$ - её цена, а $M$ - выплаты, тогда
| $X_i$ | $L$ | $L - M$ |
|---|---|---|
| $P(\ldots)$ | $p$ | $1 - p$ |
Средняя прибыль компании составит $\frac{1}{n} \sum X_i$. По закону больших чисел:
$$ \frac{1}{n} \sum_{i=1}^n X_i \overset{p}{\to} E(X_i) $$У нас число $n$ может быть конечным, поэтому нас интересует число $n$ такое, что
$$ P \left( \frac{1}{n} \sum X_i > 0 \right) > 0.99 $$Найдём математическое ожидание и дисперсию случайной величины $X_i$:
\begin{equation} \begin{aligned} E(X_i) = L - (1 - p) \cdot M \\ Var(X_i) = M^2 \cdot p \cdot (1-p) \end{aligned} \end{equation}По ЦПТ
$$ \bar x \sim N \left( E(X_i), \frac{Var(X_i)}{n} \right), $$Знание этого факта позволяет нам найти в явном виде формулу для $n$. Давайте сделаем это. Мы хотим, чтобы
$$ P(\bar x > 0) > 0.99. $$Найдём вероятность того, что среднее больше нуля.
$$ P \left( \bar x > 0 \right) = P \left( \frac{\bar x - E(X_i)}{\sqrt{\frac{Var(X_i)}{n}}} > \frac{- E(X_i)}{\sqrt{\frac{Var(X_i)}{n}}} \right) = 1 - \Phi \left(\frac{- E(X_i)}{\sqrt{\frac{Var(X_i)}{n}}} \right) = \Phi \left(\frac{E(X_i)}{\sqrt{\frac{Var(X_i)}{n}}} \right) > 0.99 $$Получается, что
$$ \frac{E(X_i)}{\sqrt{\frac{Var(X_i)}{n}}} > u_{0.99}. $$Отсюда находим, что требуемое число клиентов должно быть таким:
$$ n > \left(\frac{u_{0.99}}{E(X_i)}\right)^2 \cdot Var(X_i) $$Для начала просто вобьём формулку.
L = 10000 # цена страховки
M = 10^6 # выплата, при наступлении страхового случая
mu = L - (1 - p_wom)*M
cat('теоретический средний доход:', mu,'\n')
s2 = M^2*p_wom*(1 - p_wom)
cat('теоретическая дисперсия:', s2, '\n')
p_wom = as.numeric(df_small[df_small['X'] == '25 лет'][2])
cat('Вероятность дожить:', p_wom,'\n')
n = s2*(qnorm(0.99)/mu)**2
cat('Число клиентов:', n,'\n')
теоретический средний доход: 9013 теоретическая дисперсия: 986025831 Вероятность дожить: 0.999013 Число клиентов: 65.68994
Обратите внимание на тот факт, что из-за большой дисперсии, даже при высоком теоретическом доходе, нам необходимо довольно большое число клиентов. Давайте убедимся в том, что мы правильно вывели формулу, и попробуем посимулировать это добро для разных взносов и разных $n,$ начиная с которых мы получаем положительную прибыль.
Просто меняйте $L$ и $M$, запускайте код выше, смотрите на оптимальное $n$. После запускайте ячейку ниже и убеждайтесь в том, что вероятность того, что средняя прибыли окажется больше нуля и правда выше $0.99$.
k = 0
for(i in 1:10^6){
x <- rnorm(n+1, mean=mu, sd=sqrt(s2))
if(mean(x) > 0){
k = k + 1
}
}
k/10^6
Поосторожнее с ценой, в окрестности которой ожидаемая прибыль равна нулю. На самом деле во всей этой ситуации вполне осмысленен вопрос: а какого чёрта, мы решили взять и апроксимировать поведение среднего нормальным распределением? Если мы попробуем сделать большое количество генераций и посмотреть что происхиодит с распределением, мы увидим, что даже при больших $n$ у нас есть проблемы.
L = 10000 # цена страховки
M = 10^6 # выплата, при наступлении страхового случая
mns = rep(0,10^6)
for(i in 1:10^6){
mns[i] = mean(sample(c(L, L - M), size=1000, prob = c(p_wom, 1 - p_wom),replace=TRUE))
}
qplot(mns)
`stat_bin()` using `bins = 30`. Pick better value with `binwidth`.

При этом, если бы вероятность дожить до конца года у женщин была бы поменьше, мы бы могли увидеть привычный нам купол.
L = 10000 # цена страховки
M = 10^6 # выплата, при наступлении страхового случая
mns = rep(0,10^6)
for(i in 1:10^6){
mns[i] = mean(sample(c(L, L - M), size=1000, prob = c(0.8, 1 - 0.8),replace=TRUE))
}
qplot(mns)
`stat_bin()` using `bins = 30`. Pick better value with `binwidth`.

Дело в том, что при маленьком $p$ сходимость к нормальному распределению идёт очень-очень медленно, и нам необходимо сделать на порядок больше симуляций, чтобы получить купол.
В лекциях по терверу вы говорили, что кода $p$ или $(1-p)$ близко к нулю, мы имеем дело с редкими событиями. Для таких них лучше себя зарекомендовала апроксимация Пуассона. Давайте посмотрим, что нам про оптимальную численность скажет оно. Переведём $X_i$ в Бернуллиевскую случайную величину.
| $X_i$ | $L$ | $L - M$ |
|---|---|---|
| $P(\ldots)$ | $p$ | $1 - p$ |
Если $Y_i = \frac{X_i - L}{M} \cdot (-1)$, тогда
| $Y_i$ | $0$ | $1$ |
|---|---|---|
| $P(\ldots)$ | $p$ | $1 - p$ |
Вероятность $1-p$ - это вероятность успеха. Она очень близка к нулю. В прибилжении Пуассона именно это и требуется. Начинаем искать вероятность.
$$ P(\bar X \ge 0) = P \left(\sum X_i \ge 0\right) = P\left(\sum(L - M \cdot Y_i \ge 0\right) = P\left(nL - M \sum Y_i \ge 0\right) = P\left(\sum Y_i \le n \cdot \frac{L}{M}\right). $$Кажется, что формула готова.
L = 10000
for(n in 1:10){
cat(ppois(n*L/M, lambda = n*(1-p_wom)),'\n')
}
0.9990135 0.9980279 0.9970434 0.9960598 0.9950772 0.9940955 0.9931148 0.9921351 0.9911563 0.9901785
Вот незадача! Уже при первом же человеке апроксимация выдаёт нам нужный результат. Дальше вероятность будет сначала убывать, потом увеличится и уйдёт к единице.
L = 10000
prob = rep(0, 1000)
for(n in 1:1000){
prob[n] = ppois(n*L/M, lambda = n*(1-p_wom))
}
qplot(1:1000, prob, geom = 'line')

Если по-честному проделать симуляции, у вас в качестве ответа вывалится единица. Конечно же, чисто формально, это правильно, но мы же большая фирма и хотим много денег... Поэтому лучше взять более большое $n$.
При генерациях для $p_{wom} = 0.98$ все получали адекатный результат, так как $10^6$ симуляций вполне хватало.
- Выясните, начиная с какого возраста страховка для мужчин стоит дешевле, чем страховка для женщин.
# где вероятность впервые окажется больше, тот возраст и подойдёт
max(which(df$Женщины.город - df$Мужчины.город > 0)) + 1
[6] Задачка 15 (Парадокс дней рождений)¶
Вы когда-нибудь слышали про парадокс дней рождений? На википедии есть статья. Остановитесь, не нужно её гуглить. Давайте попробуем поразмышлять. Как думаете, какова вероятность того, что в комнате, в которой находится $23$ человека, хотя бы у двоих из них дни рождения совпадают (не у вас с кем-нибудь совпадёт, а у двоих произвольных людей)?
Внимание, ответ: вероятность этого $0.5$. Если в комнате $50$ человек, то вероятность этого возрастает до $0.97$. Получается, что если вы находитесь в большой аудитории, то вы смело можете ставить деньги на то, что в ней дни рождения у каких-нибудь двух произвольных людей совпадут. Делая такие ставки довольно часто, вы сможете обогатиться. Конечно же, иногда вы будете проигрывать, но математическое ожидание такой игры будет суперположительным. Например, если вы будете ставить $1000$ рублей, ваш ожидаемый выигрыш составит
$$ E(X) = 0.97\cdot1000 - 0.03\cdot1000. $$Слабо найти вероятность того, что хотя бы у двоих людей из $n$ дни рождения совпадут? Если слабо, добро пожаловать на википедию.
Почему нам трудно в это поверить? Ответ математический: степени трудно осознать. Как визирь в древней задаче про шахматы и зёрнышки, мы плохо понимаем степенную функцию. Даже если мы подучились математике и статистике, это всё равно как-то непривычно. Вот пример неправильной логики: какова вероятность выпадения $10$ решек подряд?
Нетренированный мозг может составить примерно такую цепочку мыслей: одна решка - $50%$, две решки - $25%$. Значит, десяток решек в $10$ раз труднее, ну то есть $5%$. Ну вот мы и облажались. Реальный шанс это $0.5^{10}$. Ошиблись немного. Примерно в $50$ раз.
Итак, в произвольной группе из $50$ человек вероятность того, что хотя бы у двоих людей дни рождения совпадут, равна $0.97$. Но это всё только в теории. При решении задачи мы предполагаем, что рождения людей равномерно распределены в течение года. Однако на практике это может быть не так. В связи с этим реальная вероятность может отличаться от теоретической.
В этой задачке вам предстоит проверить парадокс дней рождений на эмпирических данных. В табличке vk_bdates.csv лежит информация о $4589300$ пользователей из вконтакте. В табличке можно найти данные о имени пользователя first_name, его поле sex, его родном городе home_town, городе проживания city, дне bdate, месяце bmonth и годе byear рождения. Также там лежит информация о том удалена ли его страничка deactivated.
[3] Простая часть (её решение можно найти во второй домашке прошлого года):
Попробуйте на основе данных из этой таблички проверить парадокс дней рождений. Проверять его мы будем, конечно же в R. Обратите внимание, что часто придётся прогонять один и тот же код. Не надо его копировать. Оформите его в виде функции.
Таблица тут: https://yadi.sk/d/hcysIe6d3Uv8rr
df = read.csv('/Users/fulyankin/Yandex.Disk.localized/R/R_prob_data/vk_bdates.csv', sep='\t', dec='.')
dim(df) # размер таблицы
head(df,10) # её шапочка
- 4589300
- 11
| X | city | deactivated | first_name | home_town | id | last_name | sex | byear | bmonth | bday |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | Москва | Илья | 5 | Перекопский | 2 | NA | 11 | 18 | ||
| 1 | Санкт-Петербург | Николай | 6 | Дуров | 2 | NA | NA | NA | ||
| 2 | Санкт-Петербург | Михаил | Санкт-Петербург | 11 | Петров | 2 | NA | 12 | 18 | |
| 3 | Санкт-Петербург | Татьяна | 34 | Плуталова | 1 | NA | NA | NA | ||
| 4 | banned | Габриел | 47 | Шалел | 2 | NA | NA | NA | ||
| 5 | Сергей | 57 | Владимиров | 2 | NA | NA | NA | |||
| 6 | Москва | Людмила | 71 | Романченко | 1 | NA | 2 | 7 | ||
| 7 | Санкт-Петербург | Наташа | 74 | Филимонова | 1 | 1988 | 7 | 18 | ||
| 8 | banned | Давид | 79 | Спектер | 2 | NA | NA | NA | ||
| 9 | Санкт-Петербург | Фёдор | Санкт-Петербург | 84 | Медведев | 2 | NA | NA | NA |
# Когда будете строить такой график, избавьтесь от колонки NA
# Это позволяет сделать грамотное выполнение 1 и 2 пунктов инструкции :)
ggplot(df, aes(x=factor(bmonth)))+
geom_bar(stat="count", width=0.7, fill="steelblue")

От вас требуется:
1. Удалить из таблички всех людей, чьи страницы были забанены или удалены.
# Будем работать с табличками в пакете dplyr, если он у вас не стоит, поставьте
library('dplyr')
options(repr.plot.width=8, repr.plot.height=3) # размер картинок
Attaching package: ‘dplyr’
The following objects are masked from ‘package:stats’:
filter, lag
The following objects are masked from ‘package:base’:
intersect, setdiff, setequal, union
# Посмотрим какие у нас в колонке deactivated бывают значения.
# Можно сделать это напрямую
# команда select вытащила столбец из таблицы, distinct оставила уникальные значения
distinct(select(df, deactivated))
| deactivated |
|---|
| banned |
| deleted |
# А можно сделать это через трубочку, которая будет последовательно применять
# команды к тому, что стоит слева :)
df %>% select(deactivated) %>% distinct()
| deactivated |
|---|
| banned |
| deleted |
# Посмотрим сколько у нас в таблице заблоченых и удалённых людей
# cat это модный print
cat('Были забанены:', sum(df$deactivated == 'banned'),'\n')
cat('Удалили свои страницы:', sum(df$deactivated == 'deleted'))
Были забанены: 255167 Удалили свои страницы: 635954
# 1. Чистим таблицу от удалённых и забаненых
df_clean = df %>% filter(deactivated != 'banned', deactivated != 'deleted')
head(df_clean)
| X | city | deactivated | first_name | home_town | id | last_name | sex | byear | bmonth | bday |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | Москва | Илья | 5 | Перекопский | 2 | NA | 11 | 18 | ||
| 1 | Санкт-Петербург | Николай | 6 | Дуров | 2 | NA | NA | NA | ||
| 2 | Санкт-Петербург | Михаил | Санкт-Петербург | 11 | Петров | 2 | NA | 12 | 18 | |
| 3 | Санкт-Петербург | Татьяна | 34 | Плуталова | 1 | NA | NA | NA | ||
| 5 | Сергей | 57 | Владимиров | 2 | NA | NA | NA | |||
| 6 | Москва | Людмила | 71 | Романченко | 1 | NA | 2 | 7 |
# Срез df_clean = df[(df$deactivated != 'banned')&(df$deactivated != 'deleted'),]
# дал бы на выход то же самое, но он бы отработал медленнее деплировской фильтрации.
# Ниже все срезы мы будем делать командой filter().
2. Удалить из таблички всех людей, для которых недоступны день и месяц рождения.
# 2. Дропаем NA по дням и месяцам
df_dropna = df_clean %>% filter(!is.na(bday),!is.na(bmonth))
dim(df_dropna) # число строк довольно сильно упало :(
head(df_dropna)
- 2570799
- 11
| X | city | deactivated | first_name | home_town | id | last_name | sex | byear | bmonth | bday |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | Москва | Илья | 5 | Перекопский | 2 | NA | 11 | 18 | ||
| 2 | Санкт-Петербург | Михаил | Санкт-Петербург | 11 | Петров | 2 | NA | 12 | 18 | |
| 6 | Москва | Людмила | 71 | Романченко | 1 | NA | 2 | 7 | ||
| 7 | Санкт-Петербург | Наташа | 74 | Филимонова | 1 | 1988 | 7 | 18 | ||
| 10 | Санкт-Петербург | Михаил | 175 | Захаренков | 2 | 1981 | 11 | 23 | ||
| 13 | Turku | Павел | St. Petersburg | 208 | Антипов | 2 | NA | 11 | 30 |
3. Постройте гистограмму, на которой было бы понятно в какой месяц родилось какое количество людей. Команда для этого приведена ниже. Как считате, помесячная рождаемость имеет равномерное распределение?
# 3. Гистограмма с рождаемостью по месяцам
ggplot(df_dropna, aes(x=factor(bmonth)))+
geom_bar(stat="count", width=0.7, fill="steelblue") +
xlab('Month') + ylab('Count')

Такс такс такс, что тут у нас. Учитывая, что выборка довольно большого объёма, сложно списать разницу в высоте столбиков на случайность. Если мы будем проверять гипотезу о равномерности распределения, скорее всего, она будет отвергаться. Почему-то в конце года рождается меньше людей.
4. Постройте точно такую же гистограмму для дней рождений. Вас ждёт небольшой сюрприз. Избавьтесь от этого сюрприза, чтобы он не замусоривал данные. Как считате, подневная рождаемость имеет равномерное распределение?
# 4. Аналогичная картинка для дней
ggplot(df_dropna, aes(x=factor(bday)))+
geom_bar(stat="count", width=0.7, fill="steelblue") +
xlab('Days') + ylab('Count')

# Что за?!
df_dropna %>% select(bday) %>% distinct() %>% tail()
| bday | |
|---|---|
| 34 | 1984 |
| 35 | -99 |
| 36 | 666 |
| 37 | -1234567890 |
| 38 | 313 |
| 39 | -111 |
Сюрприз! Вконтакте есть баги в записях. Служба поддержки отвечат, что в давнем времени была возможность обходить валидацию и писать некорректные данные в некоторые поля. Придётся нам отфильтровать это.
df_dropna = df_dropna %>% filter(bday >=0, bday <=31)
ggplot(df_dropna, aes(x=factor(bday)))+
geom_bar(stat="count", width=0.7, fill="steelblue") +
xlab('Days') + ylab('Count')

Снова равномерное распределение не особо наблюдается. Почему-то дети любят рождаться в самом начале месяца.
5. Эмпирически оцените вероятность того, что в группе из 50 произвольных людей найдутся хотя бы двое с одинаковым днём рождения. Для этого напишите цикл, в ходе которого из таблички с помощью команды sample будет делаться подвыборка из 50 строк. Для этих 50 строк внутри условия вы должны проверить совпадение дней рождений. Если совпало, то нужно запомнить это в переменную счётчик, которую вы впоследствии, чтобы получить вероятность, поделите на длину цикла.
# создадим колонку с датами рождения, подпишем рандомный год, чтобы не париться
df_dropna = df_dropna %>% mutate(bdate = paste(bmonth,bday,'2000',sep = '-'))
head(df_dropna)
| X | city | deactivated | first_name | home_town | id | last_name | sex | byear | bmonth | bday | bdate |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | Москва | Илья | 5 | Перекопский | 2 | NA | 11 | 18 | 11-18-2000 | ||
| 2 | Санкт-Петербург | Михаил | Санкт-Петербург | 11 | Петров | 2 | NA | 12 | 18 | 12-18-2000 | |
| 6 | Москва | Людмила | 71 | Романченко | 1 | NA | 2 | 7 | 2-7-2000 | ||
| 7 | Санкт-Петербург | Наташа | 74 | Филимонова | 1 | 1988 | 7 | 18 | 7-18-2000 | ||
| 10 | Санкт-Петербург | Михаил | 175 | Захаренков | 2 | 1981 | 11 | 23 | 11-23-2000 | ||
| 13 | Turku | Павел | St. Petersburg | 208 | Антипов | 2 | NA | 11 | 30 | 11-30-2000 |
# sample_n выбрала рандомные 50 строк
# после мы выбрали колонку с датами
# в колонке с датами оставили уникальные значения
# подсчитали их количество
# если уникальных значений меньше 50, значит два др совпали
df_dropna %>% sample_n(50) %>% select(bdate) %>% distinct() %>% nrow()
# Засунем всё это в функцию
# Аргументы:
# df - таблица
# n_ppl - сколько случайных людей должно оказаться в комнате
# n_obs - сколько генераций с выбором людей надо сделать
# col_name - какая колонка нас интересует
prob_estimator <- function(df, n_ppl, n_obs, colname){
m = 0
for(i in 1:n_obs){
k = df %>% sample_n(n_ppl) %>% select(colname) %>% distinct() %>% nrow()
if(k != n_ppl){
m = m + 1
}
}
return(m/n_obs)
}
# для 100 человек
prob_estimator(df_dropna, 100, 1000, 'bdate')
# Посмотрим то же самое для 23 человек
prob_estimator(df_dropna, 23, 1000, 'bdate')
Вроде бы всё более-менее согласуется с теорией и вероятности получаются похожими на неё, хоть и немного другими. Попробуем позапускать эксперимент на разном числе людей в группе. Оценки будем строить на основе $1000$ наблюдений. На основе запусков составим следущую забавную табличку:
| Людей в группе | Теоретическая вероятность | Эмпирическая вероятность |
|---|---|---|
| 10 | 0.12 | 0.13 |
| 20 | 0.41 | 0.45 |
| 30 | 0.70 | 0.71 |
| 50 | 0.97 | 0.98 |
| 100 | 0.99 | 1 |
Поосторожнее с идеей проверить правильной ли получилась табличка. Код для оценивания всех вероятностей в ней работает довольно долго.
В конечном счёте наши оценки довольно похожи на цифры, полученные в теории. Парадокс дней рождений разрешён в нашу пользу. На самом деле неплохо было бы построить для каждой из долей доверительный интервалы и чисто формально проверить гипотезу о том, что каждая из долей совпадает с теоретической, но это мы оставим до будущих занятий.
6. Попробуйте проделать ту же оценку отдельно для подмножества женщин и подмножества мужчин. Насколько оценки вероятностей разнятся?
df_male = df_dropna %>% filter(sex == 2)
df_female = df_dropna %>% filter(sex == 1)
prob_estimator(df_male, 50, 1000, 'bdate')
prob_estimator(df_female, 50, 1000, 'bdate')
prob_estimator(df_male, 23, 1000, 'bdate')
prob_estimator(df_female, 23, 1000, 'bdate')
Оценки разнятся не то чтобы особо сильно. Опять же, было бы неплохо проверить гипотезу о равенстве долей для мужчин и женщин. Но это тоже остаётся на будущее.
На самом деле мы с вами только что впервые попробовали вскрыть внутренности сундука, о котором мы говорили на прошлой паре, по итоговой выборке. Закон больших чисел в форме Бернулли (помните из лекций по терверу?) позволил нам оценить вероятность события на основе его частоты. Очень круто, когда математика разрешает тебе сделать что-нибудь клёвое.
[3] Простая часть, решения которой в домашке прошло года нет
1. Сколько в итоговой, прошедшей все фильтры из предыдущего пункта, выборке есть уникальных имён? Какое мужское имя самое популярное? Какое женское имя самое популярное? Постройте гистограмму для 30 самых популярных имён.
# уникальных имён
df_dropna %>% select(first_name) %>% distinct() %>% nrow()
# из них мужские
df_male %>% select(first_name) %>% distinct() %>% nrow()
# из них женские
df_female %>% select(first_name) %>% distinct() %>% nrow()
Будем делать вид, что Максим - Макс и т.п это разные имена. Мы пока не умеем исправлять такие вещи. Но в будущем обязательно научимся на каком-нибудь курсе по анализу текстов. :3
# группировка по именам для каждого считаем число потом сортируем топ внизу
df_male %>% group_by(first_name) %>% summarise(count = n()) %>% arrange(count) %>% tail(10)
| first_name | count |
|---|---|
| Иван | 19541 |
| Евгений | 20313 |
| Денис | 20865 |
| Никита | 22458 |
| Максим | 31290 |
| Дмитрий | 32661 |
| Алексей | 33392 |
| Сергей | 43808 |
| Андрей | 44452 |
| Александр | 57455 |
# группировка по именам для каждого считаем число потом сортируем топ внизу
df_female %>% group_by(first_name) %>% summarise(count = n()) %>% arrange(count) %>% tail(10)
| first_name | count |
|---|---|
| Мария | 22829 |
| Виктория | 23204 |
| Ольга | 23805 |
| Юлия | 24084 |
| Ирина | 24522 |
| Екатерина | 24988 |
| Анна | 25332 |
| Татьяна | 26215 |
| Елена | 30588 |
| Анастасия | 37298 |
2. Оцените вероятность того, что в группе из 50 произвольных людей найдутся хотя бы двое с одинаковыми именами. Она оказалась больше или меньше, чем в пункте про дни рождения?
# используем ту же самую функцию,но меняем имя колонки
prob_estimator(df_dropna, 50, 1000, 'first_name')
3. Разнятся ли эти вероятности между мужчинами и женщинами?
# используем ту же самую функцию, но меняем имя колонки и имя таблиц
prob_estimator(df_male, 50, 1000, 'first_name')
prob_estimator(df_female, 50, 1000, 'first_name')
[2] Задачка 16¶
Предположим, что рост $100$ второкурсников распределен нормально со средним $175$ см и стандартным отклонением $8$ см. Если сделать выборку в $5$ человек и посчитать по ней средний рост $\bar x$, то какими будут $E(\bar x)$ и $Var(\bar x)$, если выборки делаются
а) с возвращением, то есть наблюдения $x_1, \ldots, x_5$ производятся независимо;
б) без возвращения, то есть наблюдения зависимы.
Решите задачу вручную и проверьте своё решение с помощью симуляций.
set.seed(40)
x <- rnorm(100, mean=175, sd=8)
# Нужно сгенерить так, чтобы значения были близки к теории,
# иначе дальнейшие сэмплы будут далеки от расчётов на бумажке
mean(x)
sd(x)
Cценарий 1: отбор без повторения.
Тут ничего особенного. Всё ровно как в лекциях.
\begin{equation} \begin{aligned} & E(\bar x) = \frac{1}{n} \sum_{i=1}^n E(x_i) = E(x_i) = 175 \\ & Var(\bar x) = \frac{1}{n^2} \sum_{i=1}^n Var(x_i) = \frac{Var(x_i)}{n} = \frac{8^2}{5} = 12.8 \end{aligned} \end{equation}# Делаем n_obs выборок с возвращением
n_obs = 10^6
mean_1 = rep(0, n_obs)
for(i in 1:n_obs){
sample_1 = sample(x, size=5, replace = TRUE)
mean_1[i] = mean(sample_1)
}
mean(mean_1)
var(mean_1)
Cценарий 2: отбор c повторением.
Тут происходит несчастье. Раньше иы всегда пользовались тем, что выборка независимо одинаково распределена. Тут это неправда. Каждое наблюдение, которое мы вытягиваем не может быть вытянуто второй раз. Это влияет на следущее наблюдение. Между случайными величинами $X_1, \ldots, X_n$ возникает связь. Давайте посмотрим что из-за этой связи произойдёт с дисперсией среднего.
\begin{equation} \begin{aligned} & E(\bar x) = \frac{1}{n} \sum_{i=1}^n E(x_i) = E(x_i) = 175 \\ & Var(\bar x) = \frac{n \cdot Var(x_i) + 2 \cdot C_n^2 \cdot Cov(x_i,x_j)}{n^2} \end{aligned} \end{equation}Ковариацию можно найти, вспомнив что сумма случайностей неслучайна, как в семинарской задачке с кубиком. У нас всего $100$ второкурсников. Это размер нашей генеральной совокупности. То есть $X_1 + \ldots + X_{100}$ всегда будет какой-то константой. Ковариация случайной величины и константы это ноль. Получаем, что:
\begin{equation} \begin{aligned} &Cov(X_1, X_1 + \ldots + X_{100}) = 0 \\ &Cov(X_1, X_1) + Cov(X_1,X_2) + \ldots + Cov(X_1, X_{100}) = 0 \\ &Var(X_1) + (n-1) \cdot Cov(X_1,X_2) = 0 \\ &Cov(X_1,X_2) = -\frac{Var(X_1)}{n-1} \end{aligned} \end{equation}Добиваем задачку.
$$ Var(\bar x) = \frac{n \cdot Var(x_i) + 2 \cdot C_n^2 \cdot Cov(x_i,x_j)}{n^2} = \frac{5 \cdot 8^2 + 5 \cdot 4 \cdot (- ^64/_{99})}{25} = 12.28 $$Получается, что при повторных выборках дисперсия меньше. Давайте сгенерируем это добро, а после обсудим что это всё означает с теоретической точки зрения.
# Делаем n_obs выборок без возвращения
mean_2 = rep(0, n_obs)
for(i in 1:n_obs){
sample_2 = sample(x, size=5, replace = FALSE)
mean_2[i] = mean(sample_2)
}
mean(mean_2)
var(mean_2)
Мораль: В матстате, перед построением оценки или доверительного интервала, мы постоянно предполагаем, что наши наблюдения $x_1, \ldots, x_n$ одинаково и независимо распределены. В реальности это может быть не так. В задачке выше при большой выборке ковариация между соседними наблюдениями будет ничтожно маленькой и мы можем смело пренебрегать той маленькой взаимосвязью между наблюдениями, так как она никак не скажется на итоговых результатах.
А, что если выборка очень маленькая? Мало ли ковариация будет положительной, а дисперсия большой... Тогда все предпосылке катятся в пекло. Эта задачка именно об этом. Попытайтесь придумать ситуацию, когда в выборке между наблюдениями резко возникает зависимость, причём ещё и положительная.
[2] Задачка 17¶
У Маши 30 разных пар туфель. И она говорит, что мало! Пёс Шарик утащил без разбору на левые и правые $17$ туфель. Какова вероятность того, что у Маши останется ровно $13$ полных пар? Пусть случайная величина $X$ — число полных пар у Маши. Найдите $E(X)$ и $Var(X)$.
Решите задачу вручную и проверьте своё решение с помощью симуляций.
Найдём вероятность того, что у Маши останется 13 полных пар. Шарик тащит $17$ туфелек. Всего вариантов стащить туфли у него $C_{60}^{17}$, потому что всего у Маши туфелек $60$ штук. Чтобы у Маши осталось ровно $13$ пар, остальные $17$ Шарик должен подпортить. Значит он сначала выбирает $17$ пар из $30$, а после в каждой паре выбирает какую туфельку покорёжить. Получаем $C_{30}^{17} \cdot 2^{17}$ способов. Итого:
$$ P(A) = \frac{C_{30}^{17} \cdot 2^{17}}{C_{60}^{17}} \approx 0.04 $$Найдём теперь математическое ожидание числа оставшихся пар. Пусть $X$ - число полных пар у Маши. Разобьём эту случайную величину в сумму простейших $X = X_1 + \ldots + X_{30}$, где
\begin{equation*} X_i = \begin{cases} 1, &\text{если i-ая пара осталась}\\ 0, &\text{если i-ая пара не осталась} \end{cases} \end{equation*}Найдём $P(X_i = 1)$. Для этого нужно, чтобы Шарик точно не трогал нашу пару, но трогал остальные. Это может произойти $C_{58}^{17}$ способами, то есть
$$ P(X_i = 1) = \frac{C_{58}^{17}}{C_{60}^{17}} \approx 0.51 $$Получается, что
$$ E(X) = E(X_1) + \ldots + E(X_{30}) = 30 \cdot E(X_i) = 30 \cdot P(X_i = 1) \approx 15.3 $$Теперь найдём дисперсию числа оставшихся пар.
$$ Var(X) = Var(X_1 +....+ X_{30}) = Var(X_1) +....+ Var(X_{30}) + 2Cov(X_1,X_2) +.....+2Cov(X_{29},X_{30}) = 30 \cdot Var(X1) + 2 \cdot C_{30}^{2} \cdot Cov(X_1,X_2) $$Найдём дисперсию $X_1$.
$$ Var(X_1) = E(X_1^2) - E(X_1)^2 = P(X_1 = 1) - (P(X_1 = 1))^2 \approx 0.249 $$Теперь нам нужно найти ковариацию. Для этого нам понадобится $E(X_1 \cdot X_2) = P(X_1 = 1, X_2 = 1)$. Чтобы ни первая, ни вторая пара не оказались у Шарика, он должен вынести какие-то другие пары, получаетcя, что
$$ E(X_1 \cdot X_2) = P(X_1 = 1, X_2 = 1) = \frac{C_{56}^{17}}{C_{60}^{17}} $$Выходит, что
$$ Cov(X_1, X_2) = E(X_1 \cdot X_2) - E(X_1) \cdot E(X_2) \approx -0.0071. $$В итоге получаем, что
$$ Var(X) = 30 \cdot 0.038 - 2 \cdot C_{30}^2 \cdot 0.0072 \approx 1.24 $$Ну а теперь симуляции.
n_obs <- 10^6
# сколько и когда оставалось у Маши
masha <- rep(0, n_obs)
for(j in 1:n_obs){
# тут лежат туфли, первые 30 индексов - левые, вторые 30 - правые
# 0 означает, что туфля у Маши, 1 что у Шарика
shoes <- rep(0, 60)
# Шарик делает свой ход
ind <- sample(1:60, size = 17, replace = FALSE)
shoes[ind] <- 1 # пометим единичкое все туфли, которые Шарик украл
# смотрим какие туфли в одинаковом состоянии
both <- (shoes[1:30] == shoes[31:60])
# при этом они должны быть у Маши
masha[j] = sum(shoes[1:30][both] != 1)
}
mean(masha==13) # вероятность, что у Маши останется ровно 13 пар
mean(masha) # среднее число пар у Маши
var(masha) # дисперсия числа пар
[3] Задачка 18¶
ЛСП постоянно подбрасывает монетку и орёт "орёл - решка".
- Когда выпадает $OPOP$, ЛСП успокаивается и ныряет в ванну. Сколько в среднем раз ему нужно подбросить монетку, чтобы нырнуть?
- Когда выпадает комбинация $POPP$, ЛСП просто теряется в мире цифрового глянца. Сколько в среднем раз ему нужно подбросить монетку, чтобы потеряться?
- Пусть теперь ЛСП хочет получить любую из этих двух комбинаций. Какова вероятность того, что ЛСП потеряется, а не нырнёт, то есть что $POPP$ появится раньше, чем $OPOP$?
Решите задачку вручную и проверьте своё решение с помощью симуляций.
Решение:
- Нарисуем граф состояний для этой игры. Искать среднее число ходов будем методом первого шага.
Такс. Мы подкинули монету. Выпал либо орел, либо решка. Если решка, то для нас ничего не поменялось и мы как будто бы в начале игры. Если орёл, то мы накопили одну полезную букву. Дальше монетку подкидываем второй раз. Есл орёл, то мы ничего не накопили, остаёмся в той же вершине. Если решка, то мы накопили вторую полезную букву и получили $OP$.
Снова подкинули монетку. Если выпала решка, то все наши накопления пошли на смарку и мы откатились в начало игры. Если выпал орёл, мы получили $OPO$. Дальше снова кидаем монетку и илбо получаем $OPOP$, либо выпадает орёл, который портит наши накопления и мы откатываемся в состояние $O$, потому что мы получаем $OPOO$. И самое полезное для нас это первый орёл, который поможет начать копить историю заново. Граф готов.
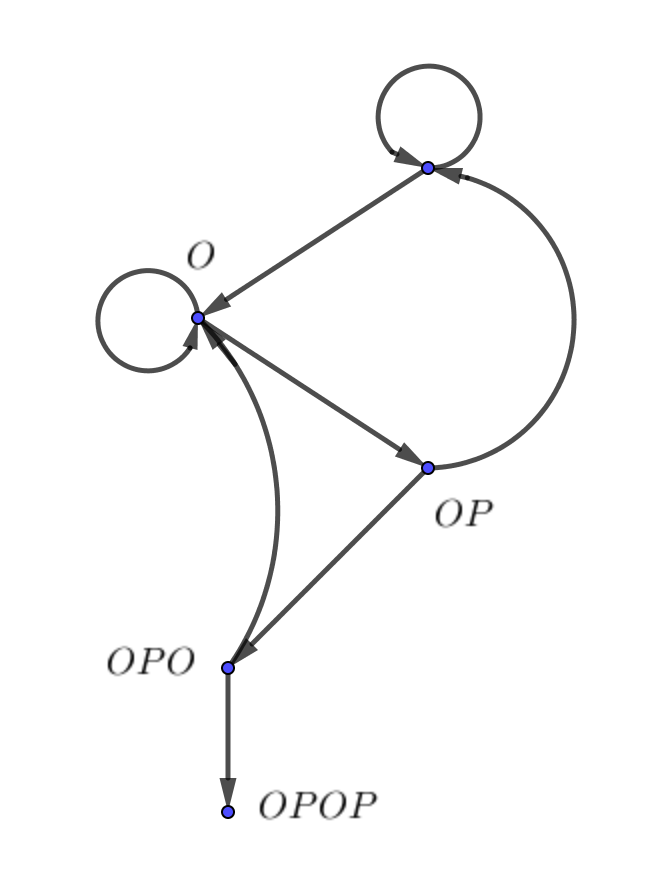
Теперь составим систему уравнений. Пусть $e_i$ - среднее число шагов до попадания в вершину $OPOP$ из вершины $i$. Пусть вершина $O$ - вторая, $OP$ - третья и так далее. Делаем шаг из первой вершины.
$$ e_1 = \frac{1}{2} \cdot (1 + e_1) + \frac{1}{2} \cdot (1 + e_2). $$Если выпал орёл, мы сделали один шаг и остались в $1$. Если выпала решка, мы сделали один шаг и попали в $2$. Уравнение для первой вершины готово, нужно ещё три. Составляем их по аналогии.
$$ \begin{cases} e_1 =& \frac{1}{2} \cdot (1 + e_1) + \frac{1}{2} \cdot (1 + e_2) \\ e_2 =& \frac{1}{2} \cdot (1 + e_2) + \frac{1}{2} \cdot (1 + e_3) \\ e_3 =& \frac{1}{2} \cdot (1 + e_1) + \frac{1}{2} \cdot (1 + e_4) \\ e_4 =& \frac{1}{2} \cdot (1 + e_2) + \frac{1}{2} \cdot 1 \\ \end{cases} $$Решаем систему, получаем, что $e_1 = 20$. Теперь симуляции.
# Сначала код для одной симуляции!
# Пущай 1 - орёл, 0 - решка, мы хотим 1010
k = 4 # сколько сделано шагов
x = sample(x = c(1,0), size = 4, replace=TRUE)
# пока последние 4 символа не такие как нам надо, подбрасываем монетку
while(sum(x[(k-3):k] == c(1,0,1,0)) !=4 ){
x = append(x, sample(x = c(1,0), size = 1))
k = k + 1
}
k
# Теперь повторяем симуляцию много раза
n_obs = 10^5
T <- rep(0, n_obs)
for(i in 1:n_obs){
k = 4 # сколько сделано шагов
x = sample(x = c(1,0), size = 4, replace=TRUE)
# пока последние 4 символа не такие как нам надо, подбрасываем монетку
while(sum(x[(k-3):k] == c(1,0,1,0)) !=4 ){
x = append(x, sample(x = c(1,0), size = 1))
k = k + 1
}
T[i] = k
}
# P.S. Осторожнее с while! Случайно можно впасть в вечный цикл...
mean(T)
qplot(T, bins=100)

- Снова рисуем граф состояний.

По аналогии с тем, что было в предыдущем пункте, составляем систему и решаем её.
$$ \begin{cases} e_1 =& \frac{1}{2} \cdot (1 + e_1) + \frac{1}{2} \cdot (1 + e_2) \\ e_2 =& \frac{1}{2} \cdot (1 + e_2) + \frac{1}{2} \cdot (1 + e_3) \\ e_3 =& \frac{1}{2} \cdot (1 + e_1) + \frac{1}{2} \cdot (1 + e_4) \\ e_4 =& \frac{1}{2} \cdot (1 + e_3) + \frac{1}{2} \cdot 1 \\ \end{cases} $$Получаем, что $e_1 = 18$. Обратите внимание, что разница между двумя графами в четвёртом уравнении. Из-за этого разные результаты. Пункт с симуляциями пропустим, так как они один в один такие же, как в предыдущем пункте, но надо последовательность прсото заменить на другую.
- Ну и ещё разок нарисуем граф состояний.
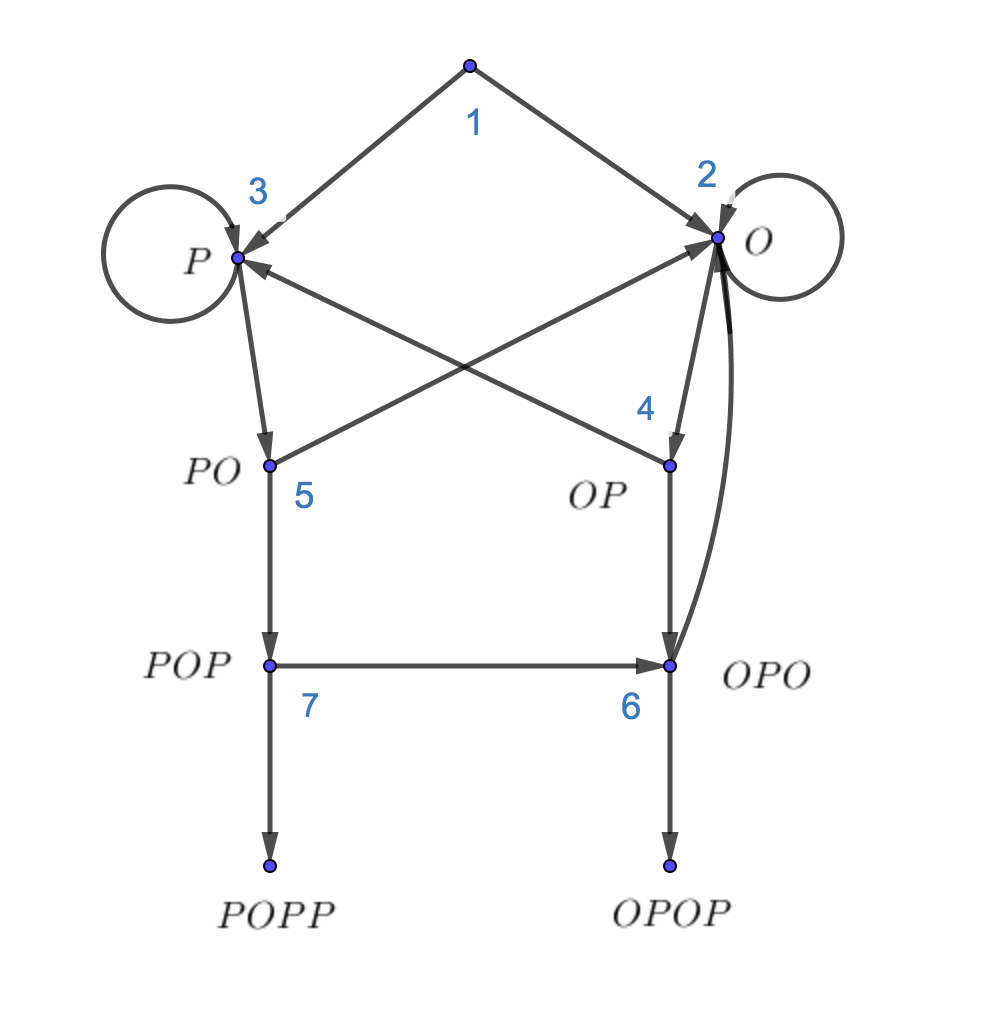
Тут нас уже интересуют не математические ожидания, а вероятности. Судя
Пусть $p_i$ - вероятность оказаться в $OPOP$, находясь при этом в вершине $i$. Составляем систему уравнений:
$$ \begin{cases} p_1 = \frac{1}{2} \cdot p_2 + \frac{1}{2} \cdot p_3 \\ p_2 = \frac{1}{2} \cdot p_2 + \frac{1}{2} \cdot p_4 \\ p_3 = \frac{1}{2} \cdot p_5 + \frac{1}{2} \cdot p_3 \\ p_4 = \frac{1}{2} \cdot p_6 + \frac{1}{2} \cdot p_3 \\ p_5 = \frac{1}{2} \cdot p_2 + \frac{1}{2} \cdot p_7 \\ p_6 = \frac{1}{2} \cdot p_2 + \frac{1}{2} \cdot 1 \\ p_7 = \frac{1}{2} \cdot p_6 + \frac{1}{2} \cdot 0 \\ \end{cases} $$Решаем систему, получаем что $P(OPOP) = \frac{9}{14}.$ При этом $P(POPP) = 1 - P(OPOP) = \frac{5}{14}$, так как игра не будет длиться вечно. Теперь симуляции. Повторим код из первой симуляции и будем следить за появлением двух последовательностей.
# Теперь повторяем симуляцию много раза
n_obs = 10^4
m <- 0 # счётчик для ОРОР
for(i in 1:n_obs){
k = 4 # сколько сделано шагов
x = sample(x = c(1,0), size = 4, replace=TRUE)
# проверка того, что произошло в первые шаги (иначе оценка сильно ниже!!!)
if(sum(x[(k-3):k] == c(1,0,1,0)) == 4){
m = m + 1
}
# пока последние 4 символа не такие как нам надо, подбрасываем монетку
while((sum(x[(k-3):k] == c(1,0,1,0)) !=4)&(sum(x[(k-3):k] == c(0,1,0,0)) !=4)){
x = append(x, sample(x = c(1,0), size = 1))
k = k + 1
if(sum(x[(k-3):k] == c(1,0,1,0)) == 4){
m = m + 1
}
}
}
m/n_obs
9/14
Мораль: в методе первого шага обычно просто достаточно понять как именно выглядит рекурентная связь внутри нашего графа. И задачка сразу же раскалывается :)
[2] Задачка 19¶
Решите задачки вручную:
$k$ различных космонавтов собираются высадиться на $m$ различных планет. Каждый космонавт выбирает себе планету независимо и равновероятно. Пусть $X$ — количество планет, на которые никто не высадился. Найдите $E(X)$.
В ряд стоят $n$ гномов. Издали на них смотрит дракон. Гномы разной высоты. Сколько в среднем гномов видит дракон? Какова дисперсия числа увиденных гномов?
Решение:
- Сначала про космонавтов. Пусть $k$ - число космонавтов, а $m$ - число различных планет. Построим случайную величину $X$ - число планет, на которых никто не высадился. Тогда $X = X_1 + \ldots + X_m$. Случайная величина $X_i$ будет принимать значение $1$, если на $i$-ую планету никто не высадился и $0$, если на $i-$ую планету кто-то высадился. Найдём вероятность того, что $X_i = 1$. На нашей планете никого быть не должно. Все должны быть на чужой. Значит
Мы готовы найти итоговый ответ:
$$ E(X) = E(X_1 + \ldots + X_m) = E(X_1) + \ldots + E(X_m) = m \cdot E(X_i) = m \cdot P(X_i = 1) = m \cdot \left(\frac{m-1}{m} \right)^k. $$- Теперь про гномов. Пусть $n$ - число гномов. Случайная величина $X$ - число тех гномов, которых видит дракон. Введём случайную величину $X_i$ по следующему правилу:
Какова вероятность того, что дракон увидит самого мелкого гнома? Коненчо же, $P(X_1 = 1) = \frac{(n-1)!}{n!} = \frac{1}{n}$. Если он стоит первым, его видно. Иначе нет. Какова вероятность того, что дракон увидит предпоследнего по высоте гнома? Ну либо он до мелкого, либо после (но тогда оба в начале очереди). Остальные двигаются как угодно. Получаем, что $P(X_2 = 1) = \frac{(n-2)!}{n!} + \frac{(n-1)!}{n!} = \frac{1}{n-1}$. По аналогии получаем остальные вероятности. Выходит, что
$$ E(X) = E(X_1) + \ldots + E(X_n) = \frac{1}{n} + \ldots + \frac{1}{3} + \frac{1}{2} + 1. $$Теперь дисперсия. Случайные величны $X_i$ и $X_j$ независимы. Например, возьмём первых двух гномов. Пусть $X_2 = 1$. Даёт ли это нам информацию о том, что происходит с первым гномом? Видит ли его дракон?
$$ P(X_1 = 1 \mid X_2 = 1) = \frac{P(X_1 = 1 \cap X_2 = 1)}{P(X_2 = 1)} = \frac{\frac{(n-2)!}{n!}}{\frac{1}{(n-1)}} = \frac{1}{n} = P(X_1 = 1). $$Аналогичные рассуждения можно построить для любых $i,j$. Выходит, что случайные величины независимые. Осталось только заметить, что $E(X_i^2) = E(X_i)$ и получить, что
$$ Var(X_k) = E(X_k) - E(X_k)^2 = \frac{1}{k} - \frac{1}{k^2}. $$Тогда
$$ Var(X) = \sum\limits_{k=1}^{n}(\frac{1}{k} - \frac{1}{k^2}) $$[4] Задачка 20¶
Илье Муромцу предстоит дорога к камню. И от камня начинаются ещё три дороги. Каждая из тех дорог снова оканчивается камнем. И от каждого камня начинаются ещё три дороги. И каждые три дороги кончаются камнем.... И так далее до бесконечности. На каждой дороге можно встретить живущего на ней трёхголового Змея Горыныча с вероятностью (хм, вы не поверите!) одна третья. Какова вероятность того, что у Ильи Муромца существует возможность пройти свой бесконечный жизненный путь, так ни разу и не встретив Змея Горыныча?
Решите задачу вручную и проверьте своё решение с помощью симуляции.
Hint: наверное, лучше всего делать симуляции с помощью рекурсивной функции на походы Ильи Муромца.
Решение: Эта задачка была сложной. Для начала нарисуем граф состояний и попытаемся понять как именно в нём устроен метод первого шага.
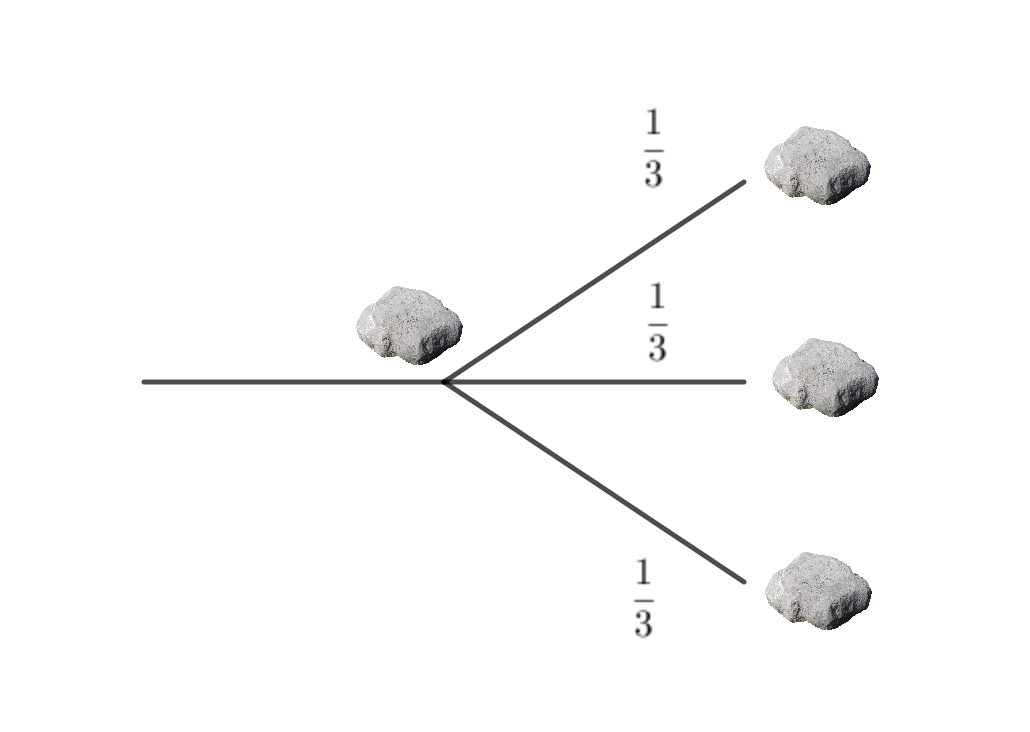
Обозначим буквой $p$ вероятность того, что существует бесконечный жизненный путь из нашей стартовой точки. Проходим по первой дороге. Вероятность, что нас не сожрут равна $1 - \frac{1}{3}$. Дальше нам надо пойти по одной из трёх дорог. Каждая из них ведет к новому камню. Получается, что мы оказались в той же самой ситуации, в которой были в самом начале. Вероятность выжить, путешествую по каждой из трёх дорог равна $p$.
Нас интересует наличие дороги хотябы по одному из трёх путей. Чтобы получить вероятность этого, перейдём к противоположному событию. Дважды. С вероятнотью $(1 - p)^3$ ни по одной дороге жизненного пути нет. С вероятностью $1 - (1 - p)^3$ хотя бы по одной дороге он есть. Получается уравнение
$$ p = \frac{1}{3} \cdot 0 + \frac{2}{3} \cdot( 1 - (1 - p)^3 ) = \frac{2}{3} \cdot (1 - (1 - p)^3) $$Немного поколдуем надо ним
$$ \begin{aligned} p &= \frac{2}{3} \cdot (1 - (1 - p)^3) \\ 1-p &= 1 - \frac{2}{3} \cdot (1 - (1 - p)^3) \\ 1-p &= \frac{1}{3} + \frac{2}{3} (1-p)^3 \\ t &= \frac{1}{3} + \frac{2}{3} t^3 \\ \end{aligned} $$В итоге мы получили кубическое уравнение
$$ 2t^3 - 3t + 1 = 0. $$Как мы решали такие уравнения на линале? Просто угадывали первый корень и сводили всё к квадратному. Сразу видно, что один из корней $t = 1$. Поделим уравнение на $(t - 1)$. Получим $(t-1) \cdot (2t^2 + 2t - 1) = 0$. Решаем квадратное уравнение, получаем корни $\frac{1}{2} \cdot (-1 \pm \sqrt{3})$. Вспоминаем, что $t = 1 - p$. Получаем три решения:
$$ p = 0, \quad p = \frac{1}{2} \cdot (3 \pm \sqrt{3}) $$Одно из решений больше $1$ и не подходит по ограничениям на вероятность. Решение с нулём скучное. Оно точно не будет правдой. При желании можно доказать это (страница 39 культурного кода). Для этого просто нужно осознать, что в краевой ситуации, когда Змеев Горынычей нет, нелевое решение будет давать неадекватный результат.
(3 - sqrt(3))/2
Теперь симуляции. Ключевая проблема для симуляций заключается в том, что Илья Муромец должен найти бесконечный жизненный путь. У нас нет столько компьютерных мощностей, чтобы бесконечные пути симулировать. Нам придётся доходить до какого-то определённого периода (например, сотого или тысячного) и начиная с него говорить, что Илья вышел на бесконечный путь. По-другому никак не выйдет. Давайте попробуем написать функцию, которая помогает Илье ходить по его жизненным дорогам. Можно сделать это с рекурсией, можно без. Мы попробуем с рекурсией.
max_recursion <- 5 # ограничение на количество походов Ильи вглубь
life_path <- function(stone_number){
stone_number = stone_number + 1 # продвинулись на один камень вглубь
# идём по нашим трём дорогам, если ещё не превысили максимальный путь
exist = TRUE
if(stone_number < max_recursion){
path_1 <- life_path(stone_number)
path_2 <- life_path(stone_number)
path_3 <- life_path(stone_number)
# если путь существует то хотя бы одна функция выдаст 1
exist <- (path_1 == 1)|(path_2 == 1)|(path_3 == 1)
}
# сгенерировали змея горыныча на нашей дороге
x <- sample(size = 1, x = c(0,1), prob = c(2/3,1/3), replace = TRUE)
if((x == 1)|(exist == FALSE)){
return(0)
} else {
return(1)
}
}
life_path(0)
n_obs <- 10^4
# сюда записываем ответ на вопрос "а есть ли путь?"
ilusha <- rep(0, n_obs)
# пошли симуляции
for(i in 1:n_obs){
ilusha[i] <- life_path(0)
}
# даже при ограничении в глубине в 5 походов, получаем точность в два знака =)
mean(ilusha) # вероятность того, что путь существует
2. [40+] Кит-рисёрчер¶
Добро пожаловать в Кита. Кит — это большая рисёрчерская задача с огромным количеством вопросов. В ките есть как ручные вопросы, так и вопросы для симуляций. За каждый вопрос даётся какое-то количество баллов. В каких-то вопросах требуется решить задачу руками на бумажке. В каких-то вопросах требуется произвести симуляцию в R. Продвинтесь в своём рисёрче над этим китом как можно глубже и срубите куш из баллов.
Частично решение этого кита можно найти в логах предыдущего года. Если на вас нападёт отчаяние, можете заглянуть в них.
Эконом играет в киллера! Всего участие в игре принимает $100$ человек. Краткие правила игры:
- Каждый игрок одновременно и убийца и жертва.
- Игроку даётся конверт, в котором лежит имя человека, которого он должен убить.
- Сам игрок также находится у кого-то в конверте. Нужно не допустить своей смерти.
- Чтобы убить другого игрока, надо оказаться с ним наедине и застрелить из пальца.
- Жертва убитого становится новой жертвой игрока.
- Побеждает тот, кто совершит наибольшее число убийств.
Организаторы игры сразу же столкнулись с несколькими проблемами. Первая проблема - это суицидники. Если Максиму в конверте попался Максим, то Максим должен убить сам себя. Он - суицидник. В такой ситуации организаторам придётся поменять конверт. Хотелось бы, чтобы подобных ситуаций было как можно меньше.
a)[1] Какова вероятность, что суицидником окажется именно Максим? Найдите эту вероятность руками.
Ответ: Всего раздач конвертов может быть $n!$, вариантов, когда в конверте у Максима именно он, $(n-1)!$. Значит вероятность суицида для Максима $\frac{1}{n}$.
б) [1] Оцените с помощью симуляций вероятность того, что хотя бы один человек получит в конверте сам себя.
n_obs = 10^6 # устроим миллион раздач!
n = 100 # число игроков
x = rep(0, n_obs) # сюда будем заносить число суицидников
for(i in 1:n_obs){
konv = sample(1:n) # раздача конвертов (случайная перестановка)
x[i] = sum(konv == 1:n) # число суицидников в раздаче
}
sum(x > 0)/n_obs # вероятность хотя бы одного суицида
в) [2] Найдите руками вероятность того, что хотя бы один человек получит сам себя.
Ответ: Это вопрос на беспорядки. Помните? Мы нахоидили их число на паре через формулу включений. Мы спрашивали, какова вероятность того, что никто в баре не сядет на своё место. В итоге мы выяснили, что это примерно $\frac{1}{e}$. Тут один в один та же самая задачка. Вероятность, что ни один человек не получит в конверте себя это то же самое, что ни один человек не сядет на своё место.
Нас интересует дополнение к беспорядку, что будет хотя бы один суицидник. Вычитаем $\frac{1}{e}$ из $1$, получаем ответ. Точно такой же, как при генерации в пункте б.
1 - 1/exp(1)
г) [2] Пусть случайная величина $X$ - количество суицидников. Оцените $E(X)$ с помощью симуляций. Проинтерпретируйте величину $E(X)$. Что она означает для организаторов игры?
mean(x) # среднее число суицидников
# Организаторы должны быть готовы заменить один конверт.
# Один из игроков достанет себя, и это тервер, а не закон подлости.
д) [2] Найдите $E(X)$ руками.
Ответ: Мы можем разложить случайную величину $X$ в сумму индексов. Пусть
$$ X = X_1 + \ldots + X_n, где $$
случайная величина $X_i$ принимает значение $1$ только тогда, когда у человека в конверте он же сам. Вероятность этого события мы нашли в первом пункте на примере Максима. Выходит, что
$$ E(X_i) = P(X_i = 1) \cdot 1 + P(X_i = 0) \cdot 0 = P(X_i = 1) = \frac{1}{n}. $$Ещё мы знаем, что $E(X_1 + X_2 + \ldots + X_n) = E(X_1) + \ldots + E(X_n)$ всегда. Значит $E(X) = n \cdot E(X_1) = 1$.
Вторая проблема - это мэтчинги. Если у Глеба в конверте оказалась Аня, а у Ани в конверте оказался Глеб, то между ними возник мэтчинг. Когда игроки останутся наедине, они попробуют убить друг друга, и у них ничего не выйдет. Организаторам придётся заменить Ане и Глебу конверты с жертвами.
е) [1] Какова вероятность того, что мэтчинг возникнет именно между Аней и Глебом?
Ответ: нужно зафиксировать двоих. Они друг у друга, остальных можно двигать как угодно.
$$ P(\text{мэтчинг у Ани и Глеба}) = \frac{(n-2)!}{n!} = \frac{1}{n \cdot (n-1)} = 0.0001 $$ж) [3] Оцените вероятность того, что в раздаче возник хотя бы один мэтчинг.
Внимание! В решении прошлого года, в этом пункте была ошибка! Я забыл удалить из раздач суицидников. Спасибо Юре Белякову, что нашёл эту ошибку.
# Мэтчинги это уже чуть более серьёзный разговор. На позиции i должно оказаться j, а на позиции j i
# Простой пример: [3,5,1,2,4]
# Между 3 и 1 игроком мэтчинг, так как x[1] = 3, а x[3] = 1
# это то же самое что и x[x[1]] = 1 или x[x[3]] = 3
z = c(3,5,1,2,4)
sum(z[z] == 1:5) # получается двойка
z = c(3,2,1,5,4) # два мэтчинга и суицидник
sum(z[z] == 1:5) # нечётное число
konv = sample(1:n) # раздача конвертов
sum(konv[konv] == 1:n) %/% 2 # число мэтчингов
# А теперь всё вместе!
n_obs = 10^6 # устроим миллион раздач!
n = 100 # число игроков
y = rep(0, n_obs) # сюда будем заносить число мэтчингов в раздаче
for(i in 1:n_obs){
konv = sample(1:n) # раздача конвертов
match = konv[konv] == 1:n # есть мэтчинг
suic = konv != 1:n # не суицидники
y[i] = sum(suic & match) %/% 2 # число мэтчингов
}
sum(y > 0)/n_obs # вероятность хотя бы одного мэтчинга
з) [3] Пусть случайная величина $Y$ - количество мэтчингов. Оцените $E(Y)$. Проинтерпретируйте величину $E(Y)$. Что она означает для организаторов?
mean(y)
# В среднем мэтчинг будет возникать в одной из двух игр,
# не такая страшная проблема как суицид, но надо быть готовым
и) [3] Найдите $E(Y)$ руками.
Ответ: Поступим точно такжеб как и с суицидами. Разобьём $Y$ в сумму простейших. Пусть случайные величины $Y_{1,2}, Y_{1,3} \ldots Y_{99,100}$ устроены как:
\begin{equation*} Y_{i,j} = \begin{cases} 1 &\text{, если у $i$-го игрока есть мэтчинг с $j$-им игроком}\\ 0 &\text{, иначе,} \end{cases} \end{equation*}тогда $Y = Y_{1,2} + \ldots + Y_{99,100}$. Вероятность мэтчинга мы уже нашли выше. Оказалось, что это $p(Y_{i,j} = 1) = \frac{1}{(n-1)\cdot n}$. В итоге получаем, что
$$ E(Y) = E(Y_{1,2} + Y_{1,3} + \ldots + Y_{99,100}) = E(Y_{1,2}) + \ldots + E(Y_{99,100}) = C_{100}^2 \cdot E(Y_{1,2}) = \frac{4950} {99 \cdot 100} = 0.5 $$к) [1] Кроме мэтчингов в игре существуют цепи. Например, у Ахмеда в конверте могла оказаться Рита, у Риты Максим, а у Максима Ахмед. Игроки выстраиваются в цепь. После того как Рита убьёт Максима, а затем Ахмеда, цепь замкнётся, и у Риты окажется она же сама. Какова вероятность того, что в игре ни один игрок в ходе замыкания такой цепи не окажется сам у себя?
Ответ: Тем, кто написал 0 и пояснили, что в конце то пара полюбак будет, балл не снимал. На самом деле подразумевалось, что последние два человека не могут убить друг-друга и игра прекращается. Фактически в пункте спрашивается какова вероятность того, что все игроки выстроятся в одну огромную цепь.
Введем событие A - вся игра - большая цепь. Игроки получают конверты по-очереди. Нужно, чтобы первый человек получил не себя. Пусть первый игрок - Рита. Вероятность, что Рита получит не себя = $\frac {99}{100}$. Пусть это произошло и она получила Ахмеда. Теперь необходимо, чтобы Ахмед получил не Риту, а себя он уже получить не может, тк он у Риты. Вероятность получить не Риту = $\frac{98}{99}$. Пусть Ахмед получил Олю. Тогда чтобы цепь сохранялась, она должна получить не Риту, не Ахмеда и не себя. Себя она получить не может тк она попалась Ахмеду, Ахмеда она тоже не может получить, тк он у Риты. Тогда необходимо получить не Риту, вероятность этого = $\frac{97}{98}$. И так далее. Пусть предпоследним получил конверт Максим, чтобы цепь сохранилась, он должен получить не Риту. Так как все до этого получали не Риту, то она находится где-то в одном из двух оставшихся конвертов. Вероятность получить не Риту = $\frac{1}{2}$. И наконец бедный Олег получает конверт последним в котором находится именно Рита, вероятность этого = 1.
Таким образом $P(A) = \frac{99}{100} \cdot \frac{98}{99} \ldots \cdot \frac{1}{2} \cdot 1 = \frac{1}{100}$
л) [х.з.] Вы понимаете, что любая раздача конвертов приводит к появлению какого-то количества подобных цепей. Каждая цепь — это какой-то граф. В итоговом графе может существовать различное количество компонент связности. Когда цепь в каждой из них замыкается, у человека в конверте оказывается он сам. Пусть случайная величина $Z$ — количество таких компонент, возникшее в игре при раздаче. Найдите $E(Z)$. Постройте для $Z$ гистограмму.
Именно это я попросил сделать в прошлом году. Моё решение получилось довольно убойным. Его можно найти в прошлогодней домашке. Если вы сможете сделать это проще, накину баллов.
Для полноты картины воспроизведу тут код из прошлого года:
# Можно было бы конечно написать огромную функцию с огромными циклами, но мы не будем
# Немного пораскинем мозгами и придумаем более простой алгоритм поиска цепей.
# При решении прошлого пункта мы с вами начились искать пары делая z[z]
z = c(3,2,1)
z
z[z] # Пары меняются местами => profit
- 3
- 2
- 1
- 1
- 2
- 3
# По аналогии можно искать и тройки
z = c(3,1,2)
z
x = z[z]
x
x[z] # Но для поиска троек придется сделать z[z] два раза
- 3
- 1
- 2
- 2
- 3
- 1
- 1
- 2
- 3
# Соответственно z[z] три раза поможет нам найти четвёрки
z = c(4,1,2,3)
x = z[z]
z
x
y = x[z]
y
y[z]
- 4
- 1
- 2
- 3
- 3
- 4
- 1
- 2
- 2
- 3
- 4
- 1
- 1
- 2
- 3
- 4
# Кажется, что алгоритм готов! На самом деле не совсем.
# Давайте посмотрим на случай из тройки и пары:
z = c(4,5,2,1,3)
z
x = z[z] # При первой махинации пара встанет на свои места
x
y = x[z] # При второй махинации тройка встанет на свои места, а пара испортится
y
y[z] # При третьей махинации тройка испотится, а пара встанет на места
- 4
- 5
- 2
- 1
- 3
- 1
- 3
- 5
- 4
- 2
- 4
- 2
- 3
- 1
- 5
- 1
- 5
- 2
- 4
- 3
# Проблема в том, что у перестановок разный цикл и когда одна из них входит
# в норму, другая неизбежно портится. Но выход есть. Будем искуственно вмешиваться
# в работу перестановок и не давать двигаться тем позициям, которые уже оказались
# на своих местах.
z = c(4,5,2,1,3)
z
yp = z==1:5 # смотрим кто уже на своих местах
y = z[yp] # запоминаем их
x = z[z] # При первой махинации пара встанет на свои места
x[yp] = y # Выправляем то, что уже было на своих местах, но перемешалось
x
yp = x==1:5 # снова смотрим кто на своих местах
y = x[yp] # запоминаем их
x = x[z] # на своих местах оказываются тройки, пара смешивается
x[yp] = y # исправляем это
x
- 4
- 5
- 2
- 1
- 3
- 1
- 3
- 5
- 4
- 2
- 1
- 2
- 3
- 4
- 5
# Напишем функцию для одной перестановки
permutation <- function(vect, z){
yp = vect==1:length(vect)
y = vect[yp]
x = vect[z]
x[yp] = y
return(x)
}
z = c(4,5,2,1,3)
x = permutation(z,z)
x
x = permutation(x,z)
x
- 1
- 3
- 5
- 4
- 2
- 1
- 2
- 3
- 4
- 5
# Отлично! Функция готова, остался цикл.
n = 100
konv = sample(1:n)
i_iter = 1 # счётчик для итераций (цепи такого размера мы сейчас нашли)
i_chain = sum(konv == 1:n) # число цепей, суицидники - цепи длины 1
i_sum = sum(konv == 1:n) # люди, которые на текущей итерации на своей позиции
x = konv # Копируем раздачу, чтобы был вектор, который мы будем менять
cat(' Число суицидников:', i_chain, '\n\n')
while(i_sum != n){ # цикл идёт пока все не встанут на свои места
x = permutation(x,konv) # сделали перестановку
i_iter = i_iter + 1 # плюс одна итерация
# выяснили сколько цепей было обнаружено на данном шаге
chain_count = (sum(x == 1:n) - i_sum) / i_iter
# увеличили счётчик цепей на число найденных цепей
i_chain = i_chain + chain_count
# увеличили сумму с людьми на своих же позициях
i_sum = i_sum + (sum(x == 1:n) - i_sum)
if(chain_count > 0){
cat(' Длина цепи:', i_iter, '\n', 'Число цепей:', chain_count, '\n\n')
}
}
cat('Всего цепей в игре:',i_chain)
Число суицидников: 0 Длина цепи: 14 Число цепей: 1 Длина цепи: 42 Число цепей: 1 Длина цепи: 44 Число цепей: 1 Всего цепей в игре: 3
# Нам нужно узнать среднее число цепей в игре. Значит цикл по размотке придётся
# запускать много-много раз. Давайте оформим его как функцию.
one_chain <- function(konv){
n = length(konv)
i_iter = 1 # счётчик для итераций (цепи такого размера мы сейчас нашли)
i_chain = sum(konv == 1:n) # число цепей, суицидники - цепи длины 1
i_sum = sum(konv == 1:n) # люди, которые на текущей итерации на своей позиции
x = konv # Копируем раздачу, чтобы был вектор, который мы будем менять
while(i_sum != n){ # цикл идёт пока все не встанут на свои места
x = permutation(x,konv) # сделали перестановку
i_iter = i_iter + 1 # плюс одна итерация
# выяснили сколько цепей было обнаружено на данном шаге
chain_count = (sum(x == 1:n) - i_sum) / i_iter
# увеличили счётчик цепей на число найденных цепей
i_chain = i_chain + chain_count
# увеличили сумму с людьми на своих же позициях
i_sum = i_sum + (sum(x == 1:n) - i_sum)
}
return(i_chain)
}
n_obs = 10^5
s = rep(0,n_obs) # вектор для числа цепей
for(i in 1:n_obs){
s[i] = one_chain(sample(1:n))
}
s[1:10] # вот оно, количество цепей в каждой игре :)
- 3
- 6
- 4
- 6
- 9
- 9
- 4
- 5
- 4
- 6
mean(s) # вот и получили среднее число цепей
qplot(s, bins=15) # ну и, конечно, гистограмка

# ради интереса для пункта к) можно найти оценку вероятности, что в игре будет одна цепь
mean(s == 1)
Усложняем ситуацию! Предположим, что на игру отводится $24 \cdot 60$ часов. Последовательность убийств — это поток событий. Время, которое проходит между убийствами описывается экспоненциальным распределением с параметром $\alpha = 0.08$.
м) [1] Сколько в среднем проходит часов между убийствами?
Ответ: Если $X \sim Exp(0.08)$, тогда $E(X) = \frac{1}{0.08} = 12.5$. Выходит, что между убийствами в среднем проходит $12.5$ часов.
н) [5] Какова вероятность того, что через $30$ дней в игре останется меньше $50$ человек? При симуляциях можно считать, что если в какой-то момент человек оказался в конверте сам у себя, он умирает. Если возник мэтчинг, умирают оба человека. Цепочку, на которой происходит убийство, выбирайте случайно на основе равномерного распределения.
Ответ: По условию время убийства никак не зависит от того, как именно произошла раздача конвертов и сколько человек на данный момент остаётся в игре. Возникает мысль, что для того, чтобы понять с какой вероятностью через $30$ дней в игре останется меньше $50$ человек, нам вообще не нужно генерировать раздачи конвертов. Более того, нам вообще не нужно выбирать какой именно человек умрёт. Потому что для нас важен только факт того, что человек умер.
Если так сделать, можно получить близкий к ответу результат, но оценка будет завышена, потому что по условию пункта, люди у которых мэтчинг, умирают. В ходе выбора той пары, где происходит выстрел, могут возникать такие мэтчинги. Будут умирать лишние люди. Интересно насколько большим будет эффект от них. Попробуем реализовать оба варианта. С завязкой на игру, и без завязки на игру.
n_obs <- 10^5
died_cnt <- rep(0, n_obs) # тут колекционируем мёртвых
for(i in 1:n_obs){
time <- 24*30 # время на половину игры
k <- 0 # число мёртвых
while(time > 0){
pau <- rexp(1, rate = 0.08) # время между убийствами в часах
k = k + 1
time = time - pau
}
died_cnt[i] = k
}
mean(died_cnt > 50) # так как всего у нас 100 человек в игре
Хорошо, теперь абсолютно то же самое, но в этот раз будем внимательно наблюдать за мэтчингами и выбирать тех, кто умрёт в текущую итерацию, случайно.
# шаг первый - понимаем сколько людей должно умереть в течение разадчи
n = 100 # число игроков
time <- 24*30 # время на половину игры
k <- 0 # число убийств
while(time > 0){
pau <- rexp(1, rate = 0.08) # время между убийствами в часах
k = k + 1
time = time - pau
}
# шаг второй - раздаём конверты и убиваем людей
konv = sample(1:n) # раздача конвертов
died_ppl = 1:n # вектор, куда будем писать мёртвых
# все суицидники и мэтчинги мертвы
died_ppl[konv[konv] == 1:n] = 0
cat('Смертей должно быть:', k, '\n')
while((k > 0)&(sum(died_ppl == 0) < 100)){
# выбираем индекс живого человека, который сделает свой выстрел в нашей цепи
idx = sample(died_ppl[died_ppl != 0],size = 1)
# выстрел идёт в человека konv[idx], помечаем его как мёртвого
died_ppl[konv[idx]] = 0
# отбираем у него конверт и отдаем его idx
konv[idx] = konv[konv[idx]]
# если вдруг возникли мэтчинги или суициды, зануляем их
died_ppl[konv[konv] == 1:n] = 0
k = k - 1 # сколько убийств осталось сделать
}
cat('Реально умерло:', sum(died_ppl == 0))
Смертей должно быть: 67 Реально умерло: 67
Оформим второй кусок кода как функцию. В пунктах ниже мы будем его переиспользовать.
kill_people <- function(n, k){
# шаг второй - раздаём конверты и убиваем людей
konv = sample(1:n) # раздача конвертов
died_ppl = 1:n # вектор, куда будем писать мёртвых
# все суицидники и мэтчинги мертвы
died_ppl[konv[konv] == 1:n] = 0
while((k > 0)&(sum(died_ppl == 0) < 100)){
# выбираем индекс живого человека, который сделает свой выстрел в нашей цепи
idx = sample(died_ppl[died_ppl != 0],size = 1)
# выстрел идёт в человека konv[idx], помечаем его как мёртвого
died_ppl[konv[idx]] = 0
# отбираем у него конверт и отдаем его idx
konv[idx] = konv[konv[idx]]
# если вдруг возникли мэтчинги или суициды, зануляем их
died_ppl[konv[konv] == 1:n] = 0
k = k - 1 # сколько убийств осталось сделать
}
return(sum(died_ppl == 0))
}
Теперь цикл!
n_obs = 10^4 # число симуляций
died_cnt <- rep(0, n_obs)
for(i in 1:n_obs){
# шаг первый - понимаем сколько людей должно умереть в течение разадчи
n = 100 # число игроков
time <- 24*30 # время на половину игры
k <- 0 # число убийств
while(time > 0){
pau <- rexp(1, rate = 0.08) # время между убийствами в часах
k = k + 1
time = time - pau
}
died_cnt[i] = kill_people(n, k)
}
mean(died_cnt > 50) # так как всего у нас 100 человек в игре
о) [5] Найдите математическое ожидание числа игроков, выживших после $30$ дней.
100 - mean(died_cnt)
Предположим, что со временем игра протухает. Поначалу всем весело и все хотят убивать, но ближе к середине энтузиазм скатывается в ноль. Пусть $\alpha$ в самом начале равна $0.08$. Каждые 48 часов она уменьшается в два раза.
п) [5] Какова вероятность того, что через $30$ дней в игре останется меньше $50$ человек? Каково математическое ожидание выживших?
Ответ: Ну, всё что тут требуется это поменять код, который генерирует время между убийствами. Остальное остаётся прежним.
n_obs = 10^4
died_cnt <- rep(0, n_obs)
for(i in 1:n_obs){
n = 100
time <- 24*30
k <- 0
while(time > 0){
# делим параметр на число прошедших 48-часовок
alpha = 0.08/(2*((24*30 - time)%/%48))
pau <- rexp(1, rate = alpha)
k = k + 1
time = time - pau
}
died_cnt[i] = kill_people(n, k)
}
alpha
mean(died_cnt > 50) # так как всего у нас 100 человек в игре
100 - mean(died_cnt)
Организаторы игры не хотят, чтобы игра протухла. Перед тем как запустить игру, они построили кучу симуляций и решили, что каждые $7$ дней в полночь они будут награждать самого топового убийцу специальным призом. Каждый раз, когда происходит награждение, $\alpha$ подскакивает на $0.02$.
р) [5] Какова вероятность того, что через $30$ дней в игре останется меньше $50$ человек? Каково математическое ожидание выживших?
# тот же код, что и в предыдущем пункте, но с условием на альфу.