 ## Открытый курс по машинному обучению
## Открытый курс по машинному обучению
TeaPOT ¶
Что такое автоматизированное машинное обучение (automated ml)¶
Теория обучения машин (machine learning, машинное обучение) находится на стыке прикладной статистики, численных методов оптимизации, дискретного анализа, и за последние 50 лет оформилась в самостоятельную математическую дисциплину. Методы машинного обучения составляют основу еще более молодой дисциплины — интеллектуального анализа данных (data mining). Перенося эти определения на automated machine learning (AML), можно сказать, что это − «Теория автоматического / автоматизированного обучения машин».
Чтобы применять машинное обучение для решения конкретных кейсов, необходимо постоянно:
- Настраивать гиперпараметры моделей;
- Пробовать новые алгоритмы;
- Добавлять в модели различные представления исходных признаков
От этих рутинных операций, как и от части операций в подготовке и очистке данных, аналитиков или data scientist’ов можно избавить с помощью автоматизации.
Автоматизированный алгоритм может перебрать все стандартные комбинации и выдать некоторое базовое решение, которое квалифицированный специалист сможет взять за основу и дальше улучшать. Однако во многих случаях результатов работы автоматизированного алгоритма окажется достаточно и без дополнительных улучшений, и их можно будет использовать непосредственно.
На сегодняшний день можно выделить два наиболее результативных пакета автоматизированного машинного обучения. Оба они используют библиотеку машинного обучения sklearn языка Python и активно разрабатываются. Первый из них — библиотека Auto-sklearn, разработанный во Фрайбургском университете. Вторым лидирующим решением в области автоматизированного машинного обучения выступает библиотека TeaPOT (TPOT).
Как определяют TPOT сами авторы - это инструмент Python, который автоматически создает и оптимизирует конвейеры (pipeline) машинного обучения с использованием генетического программирования. TPOT автоматизирует самую утомительную часть машинного обучения, исследуя тысячи возможных конвейеров, чтобы найти лучший для ваших данных.
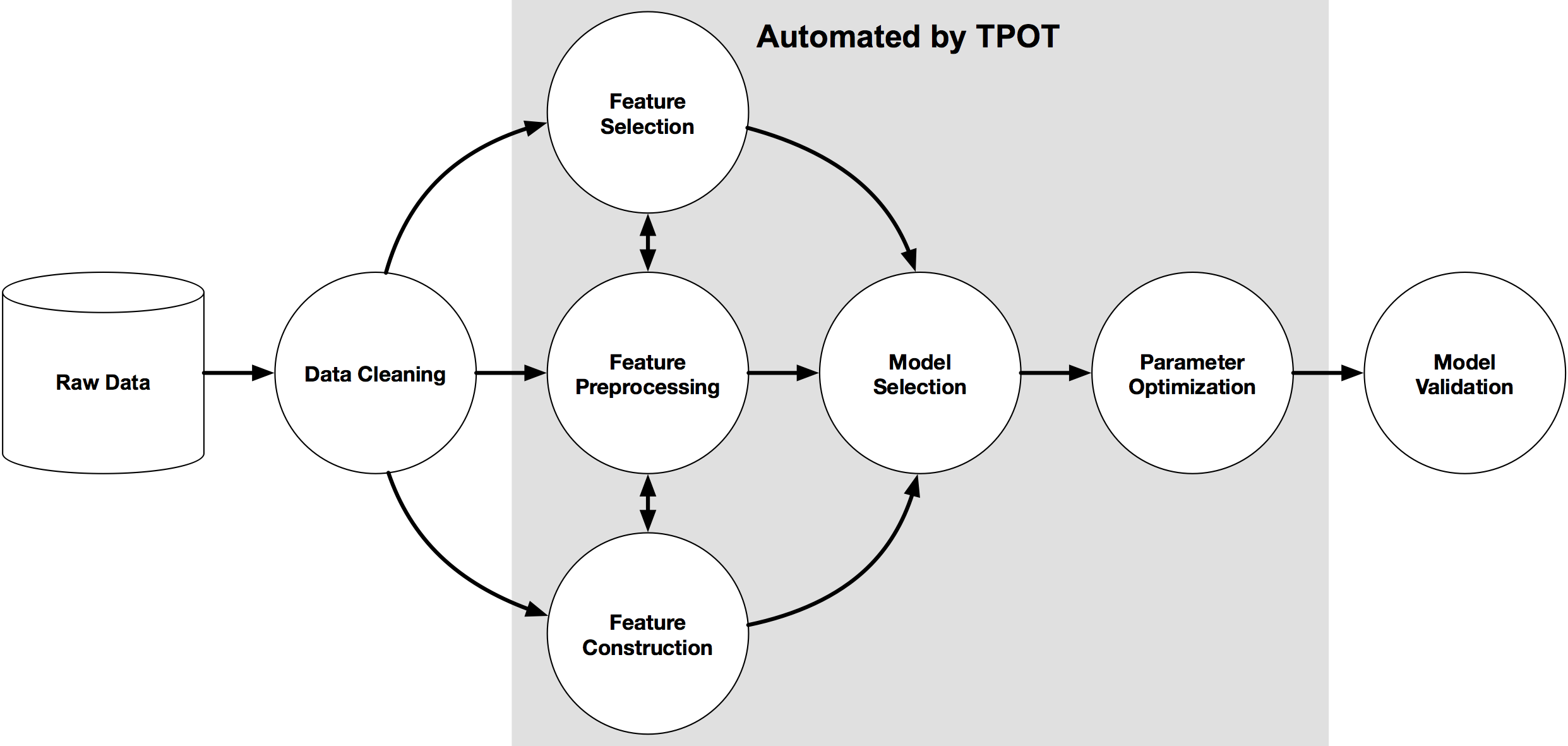
Установка TPOT¶
Требует предварительной установки следующих пакетов: NumPy, SciPy, scikit-learn, DEAP, update_checker, tqdm, pywin32 (для Windows), xgboost, scikit-mdr и skrebate:
- conda install numpy scipy scikit-learn
- pip install deap update_checker tqdm
- pip install pywin32
- pip install xgboost
- pip install scikit-mdr skrebate
- pip install tpot
Пример использования на Iris Flower Classification¶
from tpot import TPOTClassifier
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
import numpy as np
iris = load_iris()
X_train, X_test, y_train, y_test = train_test_split(iris.data.astype(np.float64),
iris.target.astype(np.float64), train_size=0.75, test_size=0.25)
tpot = TPOTClassifier(generations=5, population_size=50, verbosity=2)
tpot.fit(X_train, y_train)
print(tpot.score(X_test, y_test))
tpot.export('tpot_iris_pipeline.py')
/home/suser/anaconda3/lib/python3.5/site-packages/sklearn/cross_validation.py:44: DeprecationWarning: This module was deprecated in version 0.18 in favor of the model_selection module into which all the refactored classes and functions are moved. Also note that the interface of the new CV iterators are different from that of this module. This module will be removed in 0.20. "This module will be removed in 0.20.", DeprecationWarning) Optimization Progress: 33%|███▎ | 100/300 [00:25<00:29, 6.70pipeline/s]
Generation 1 - Current best internal CV score: 0.9739130434782609
Optimization Progress: 50%|█████ | 150/300 [00:44<00:25, 5.80pipeline/s]
Generation 2 - Current best internal CV score: 0.9739130434782609
Optimization Progress: 67%|██████▋ | 200/300 [00:51<00:13, 7.54pipeline/s]
Generation 3 - Current best internal CV score: 0.9739130434782609
Optimization Progress: 83%|████████▎ | 250/300 [01:09<00:07, 6.95pipeline/s]
Generation 4 - Current best internal CV score: 0.9739130434782609
Generation 5 - Current best internal CV score: 0.9739130434782609 Best pipeline: LogisticRegression(input_matrix, LogisticRegression__C=5.0, LogisticRegression__dual=DEFAULT, LogisticRegression__penalty=l2) 0.973684210526
#Содержание 'tpot_iris_pipeline.py' (может отличаться - не зафиксировала random seed):
#import numpy as np
#from sklearn.model_selection import train_test_split
#from sklearn.naive_bayes import GaussianNB
#from sklearn.pipeline import make_pipeline
#from sklearn.preprocessing import Normalizer
# NOTE: Make sure that the class is labeled 'class' in the data file
#tpot_data = np.recfromcsv('PATH/TO/DATA/FILE', delimiter='COLUMN_SEPARATOR', dtype=np.float64)
#features = np.delete(tpot_data.view(np.float64).reshape(tpot_data.size, -1), tpot_data.dtype.names.index('class'), axis=1)
#training_features, testing_features, training_classes, testing_classes = \
# train_test_split(features, tpot_data['class'], random_state=42)
#exported_pipeline = make_pipeline(
# Normalizer(norm="l2"),
# GaussianNB()
#)
#exported_pipeline.fit(training_features, training_classes)
#results = exported_pipeline.predict(testing_features)
Получаем точность при тестировании примерно 97%.
Описание некоторых параметров TPOT¶
- generations - любое положительное целое число - Число итераций в процессе оптимизации конвейерного процесса. Как правило, TPOT будет работать лучше, если вы дадите ему больше поколений (и, следовательно, времени), чтобы оптимизировать конвейер.
- population_size - любое положительное целое число - Количество особей, оставшихся в популяции для каждого поколения.
- offspring_size - любое положительное целое число - Число потомков в каждом поколении.
- verbosity - Какое количество информации выдает TPOT при запуске. 0 = none, 1 = minimal, 2 = high, 3 = all.
- mutation_rate - [0.0,1.0] - Скорость мутации алгоритма. Для какого количества конвейеров применяются случайные изменения в каждом поколении. Рекомендуется оставить значение по-умолчанию.
- crossover_rate - [0.0,1.0] - Скорость селекции для алгоритма. Показывает какое количество конвейеров "порождает" каждое поколение. Также рекомендуется оставить значение по-умолчанию.
Пример использования на данных соревнования Catch Me If You Can¶
import pandas as pd
# загрузим обучающую и тестовую выборки
train_df = pd.read_csv('../../data/websites_train_sessions.csv',
index_col='session_id')
test_df = pd.read_csv('../../data/websites_test_sessions.csv',
index_col='session_id')
# приведем колонки time1, ..., time10 к временному формату
times = ['time%s' % i for i in range(1, 11)]
train_df[times] = train_df[times].apply(pd.to_datetime)
test_df[times] = test_df[times].apply(pd.to_datetime)
# отсортируем данные по времени
train_df = train_df.sort_values(by='time1')
# посмотрим на заголовок обучающей выборки
train_df.head()
| site1 | time1 | site2 | time2 | site3 | time3 | site4 | time4 | site5 | time5 | ... | time6 | site7 | time7 | site8 | time8 | site9 | time9 | site10 | time10 | target | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| session_id | |||||||||||||||||||||
| 21669 | 56 | 2013-01-12 08:05:57 | 55.0 | 2013-01-12 08:05:57 | NaN | NaT | NaN | NaT | NaN | NaT | ... | NaT | NaN | NaT | NaN | NaT | NaN | NaT | NaN | NaT | 0 |
| 54843 | 56 | 2013-01-12 08:37:23 | 55.0 | 2013-01-12 08:37:23 | 56.0 | 2013-01-12 09:07:07 | 55.0 | 2013-01-12 09:07:09 | NaN | NaT | ... | NaT | NaN | NaT | NaN | NaT | NaN | NaT | NaN | NaT | 0 |
| 77292 | 946 | 2013-01-12 08:50:13 | 946.0 | 2013-01-12 08:50:14 | 951.0 | 2013-01-12 08:50:15 | 946.0 | 2013-01-12 08:50:15 | 946.0 | 2013-01-12 08:50:16 | ... | 2013-01-12 08:50:16 | 948.0 | 2013-01-12 08:50:16 | 784.0 | 2013-01-12 08:50:16 | 949.0 | 2013-01-12 08:50:17 | 946.0 | 2013-01-12 08:50:17 | 0 |
| 114021 | 945 | 2013-01-12 08:50:17 | 948.0 | 2013-01-12 08:50:17 | 949.0 | 2013-01-12 08:50:18 | 948.0 | 2013-01-12 08:50:18 | 945.0 | 2013-01-12 08:50:18 | ... | 2013-01-12 08:50:18 | 947.0 | 2013-01-12 08:50:19 | 945.0 | 2013-01-12 08:50:19 | 946.0 | 2013-01-12 08:50:19 | 946.0 | 2013-01-12 08:50:20 | 0 |
| 146670 | 947 | 2013-01-12 08:50:20 | 950.0 | 2013-01-12 08:50:20 | 948.0 | 2013-01-12 08:50:20 | 947.0 | 2013-01-12 08:50:21 | 950.0 | 2013-01-12 08:50:21 | ... | 2013-01-12 08:50:21 | 946.0 | 2013-01-12 08:50:21 | 951.0 | 2013-01-12 08:50:22 | 946.0 | 2013-01-12 08:50:22 | 947.0 | 2013-01-12 08:50:22 | 0 |
5 rows × 21 columns
import pickle
# приведем колонки site1, ..., site10 к целочисленному формату и заменим пропуски нулями
sites = ['site%s' % i for i in range(1, 11)]
train_df[sites] = train_df[sites].fillna(0).astype('int')
test_df[sites] = test_df[sites].fillna(0).astype('int')
# загрузим словарик сайтов
with open(r"../../data/site_dic.pkl", "rb") as input_file:
site_dict = pickle.load(input_file)
# датафрейм словарика сайтов
sites_dict = pd.DataFrame(list(site_dict.keys()), index=list(site_dict.values()), columns=['site'])
print(u'всего сайтов:', sites_dict.shape[0])
sites_dict.head()
# создадим отдельный датафрейм, где будем работать со временем
time_df = pd.DataFrame(index=train_df.index)
time_df['target'] = train_df['target']
# найдем время начала и окончания сессии
time_df['min'] = train_df[times].min(axis=1)
time_df['max'] = train_df[times].max(axis=1)
# вычислим длительность сессии и переведем в секунды
time_df['seconds'] = (time_df['max'] - time_df['min']) / np.timedelta64(1, 's')
#time_df.head()
всего сайтов: 48371
# наша целевая переменная
train_df.rename(columns={'target': 'class'}, inplace=True)
y_train = train_df['class']
# объединенная таблица исходных данных
full_df = pd.concat([train_df.drop('class', axis=1), test_df])
# индекс, по которому будем отделять обучающую выборку от тестовой
idx_split = train_df.shape[0]
# табличка с индексами посещенных сайтов в сессии
full_sites = full_df[sites]
full_sites.head()
| site1 | site2 | site3 | site4 | site5 | site6 | site7 | site8 | site9 | site10 | |
|---|---|---|---|---|---|---|---|---|---|---|
| session_id | ||||||||||
| 21669 | 56 | 55 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 54843 | 56 | 55 | 56 | 55 | 0 | 0 | 0 | 0 | 0 | 0 |
| 77292 | 946 | 946 | 951 | 946 | 946 | 945 | 948 | 784 | 949 | 946 |
| 114021 | 945 | 948 | 949 | 948 | 945 | 946 | 947 | 945 | 946 | 946 |
| 146670 | 947 | 950 | 948 | 947 | 950 | 952 | 946 | 951 | 946 | 947 |
from scipy.sparse import csr_matrix
from scipy.sparse import hstack
# последовательность с индексами
sites_flatten = full_sites.values.flatten()
# искомая матрица
full_sites_sparse = csr_matrix(([1] * sites_flatten.shape[0],
sites_flatten,
range(0, sites_flatten.shape[0] + 10, 10)))[:, 1:]
Построение модели¶
from tpot import TPOTClassifier
def get_tpot(X, y,seed=42, ratio = 0.9):
# разделим выборку на обучающую и валидационную
idx = round(X.shape[0] * ratio)
# обучение классификатора
tpot = TPOTClassifier(generations = 2, population_size = 3, verbosity=2,max_time_mins=3, max_eval_time_mins=0.04)
tpot.fit(X[:idx, :], y[:idx])
return tpot
%%time
# выделим из объединенной выборки только обучающую (для которой есть ответы)
X_train = full_sites_sparse[:idx_split, :]
tpot = get_tpot(X_train, y_train)
Optimization Progress: 100%|██████████| 6/6 [00:51<00:00, 5.60s/pipeline]
Generation 1 - Current best internal CV score: 0.9910913434983444
Generation 2 - Current best internal CV score: 0.9910913434983444 TPOT closed prematurely. Will use the current best pipeline. Best pipeline: BernoulliNB(Nystroem(input_matrix, Nystroem__gamma=0.5, Nystroem__kernel=sigmoid, Nystroem__n_components=1), BernoulliNB__alpha=0.01, BernoulliNB__fit_prior=False) CPU times: user 4min 39s, sys: 6.38 s, total: 4min 45s Wall time: 4min 41s
# функция для записи прогнозов в файл
def write_to_submission_file(predicted_labels, out_file,
target='target', index_label="session_id"):
predicted_df = pd.DataFrame(predicted_labels,
index = np.arange(1, predicted_labels.shape[0] + 1),
columns=[target])
predicted_df.to_csv(out_file, index_label=index_label)
X_test = full_sites_sparse[idx_split:,:]
y_test = tpot.predict(X_test)
write_to_submission_file(y_test, 'tpot_baseline.csv')
Вывод¶
В результате не удалось побить даже первый бейзлайн. Score = 0.5. Возможно TPOT так работает на разреженных матрицах. В любом случае дальше нужно подбирать параметры классификатора самостоятельно, либо давать свой словарь TPOT-у (параметр config_dict)