به نام خدا
طبقهبندی متن - Emojify!
طبقهبندی متن - Emojify!
کدها با تغییرات برگرفته از کورس Sequence Models پروفسور Andrew NG است.
https://www.coursera.org/learn/nlp-sequence-models
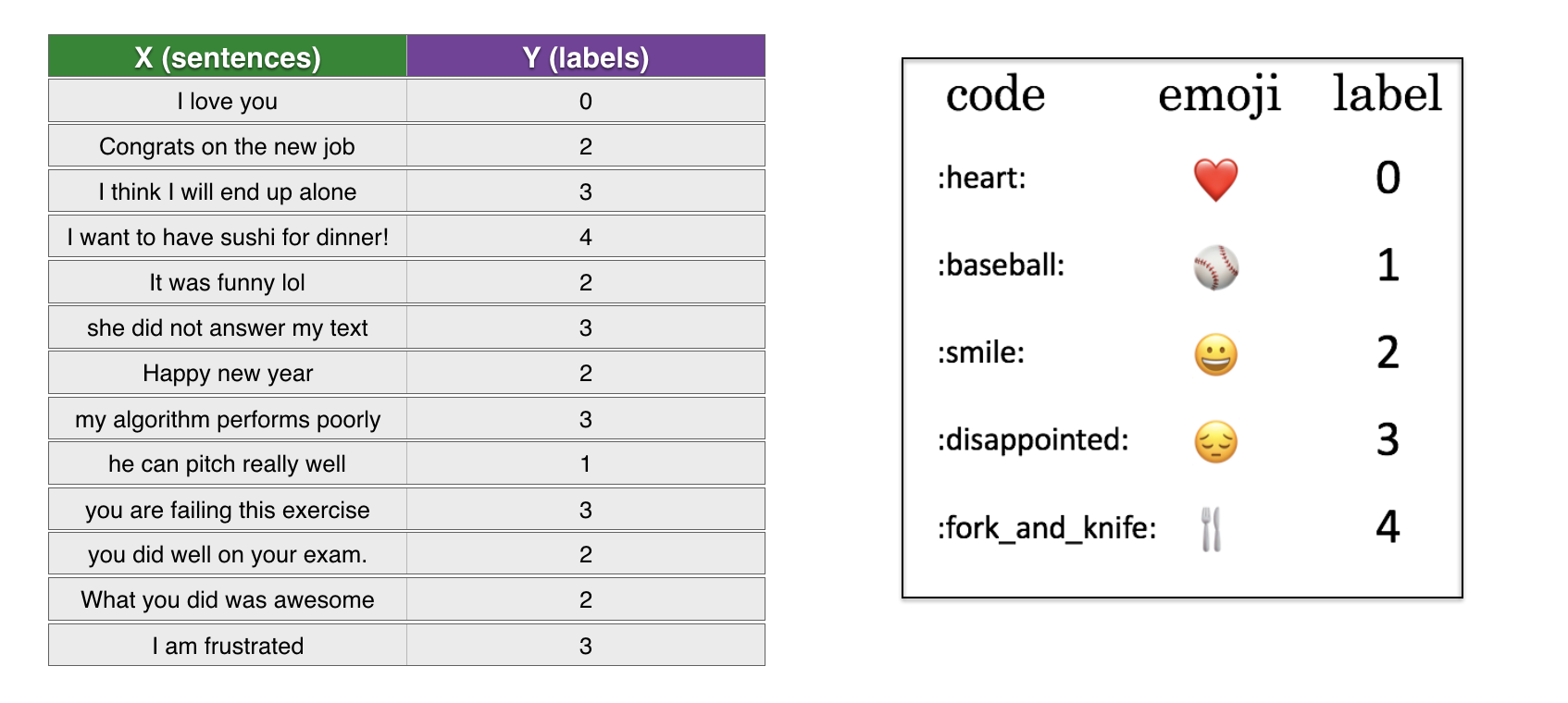
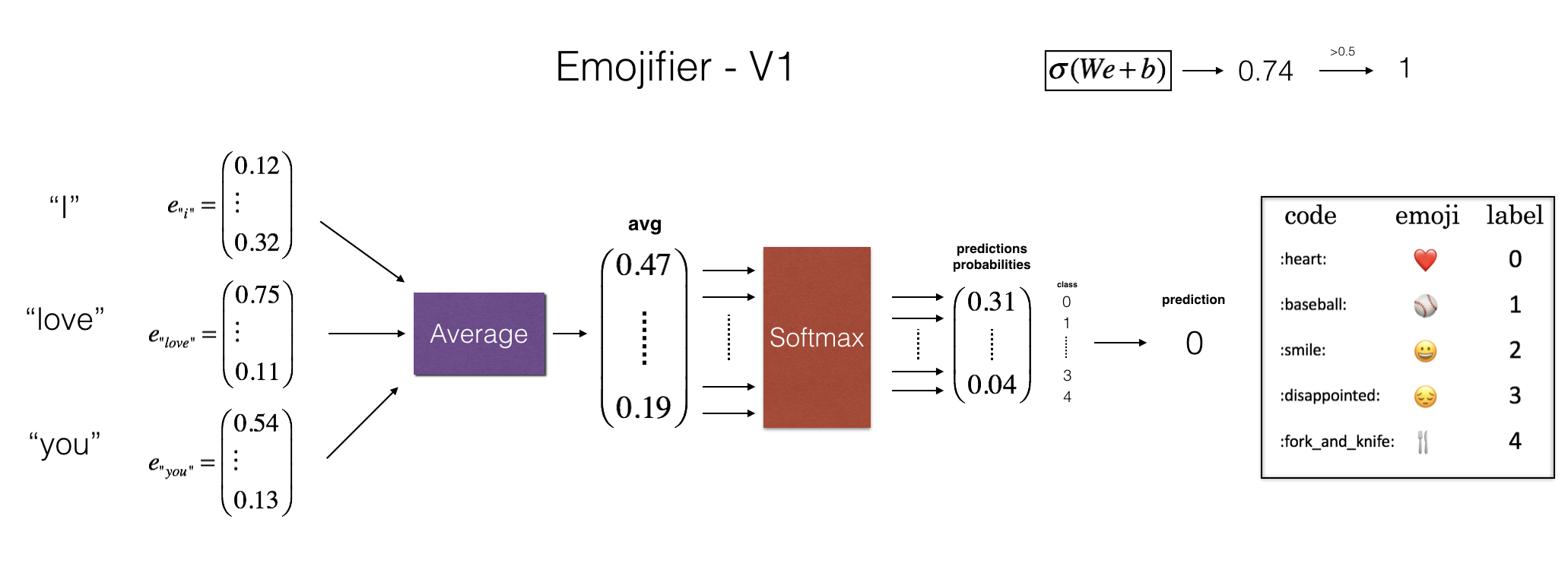
در این نوت بوک میخواهید برای جملات دلخواه یک emoji مرتبط به صورت خودکار بگذاریم!
در واقع یک طبقه بندی ساده 5 کلاسه است که هر جمله را به یک ایموجی نسبت میدهد.