قیاس کلمات (Word analogies)
https://www.coursera.org/learn/nlp-sequence-models
import numpy as np
import os
glove_dir = 'D:/dataset/glove.6B'
embeddings_index = {}
f = open(os.path.join(glove_dir, 'glove.6B.100d.txt'), encoding="utf8")
for line in f:
values = line.split()
word = values[0]
coefs = np.asarray(values[1:], dtype='float32')
embeddings_index[word] = coefs
f.close()
1 - Cosine similarity¶
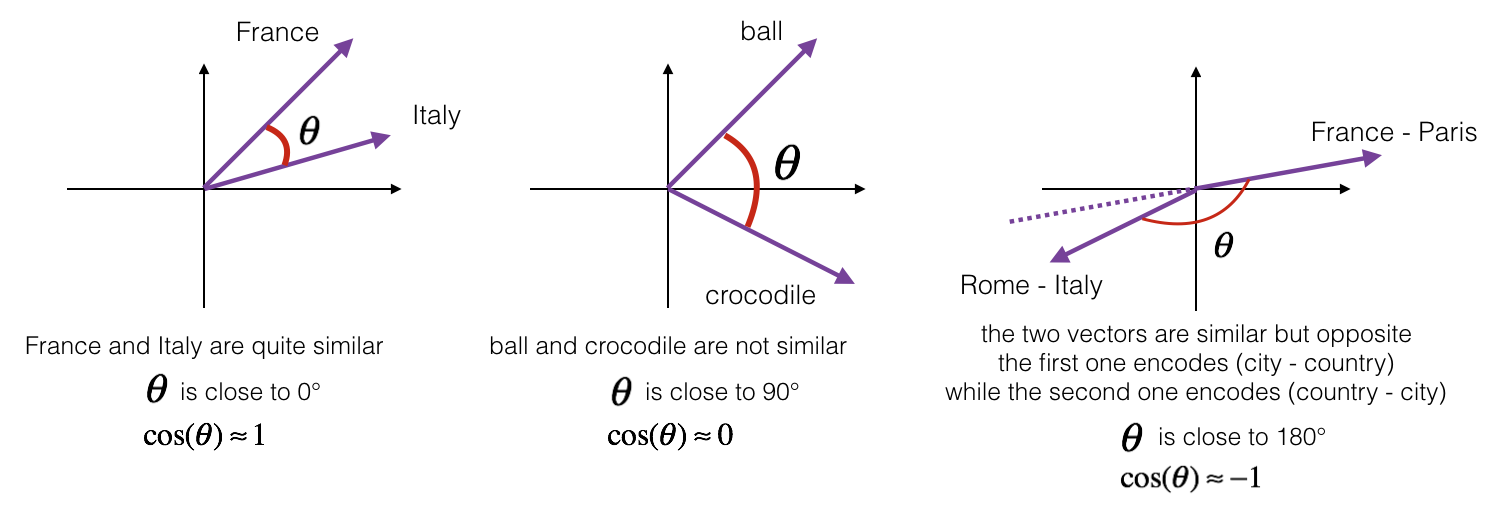
To measure how similar two words are, we need a way to measure the degree of similarity between two embedding vectors for the two words. Given two vectors $u$ and $v$, cosine similarity is defined as follows:
$$\text{CosineSimilarity(u, v)} = \frac {u . v} {||u||_2 ||v||_2} = cos(\theta) \tag{1}$$where $u.v$ is the dot product (or inner product) of two vectors, $||u||_2$ is the norm (or length) of the vector $u$, and $\theta$ is the angle between $u$ and $v$. This similarity depends on the angle between $u$ and $v$. If $u$ and $v$ are very similar, their cosine similarity will be close to 1; if they are dissimilar, the cosine similarity will take a smaller value.
from sklearn.metrics.pairwise import cosine_similarity
def similarity(u, v):
return np.squeeze(cosine_similarity(u.reshape(1, -1), v.reshape(1, -1)))
father = embeddings_index["father"]
mother = embeddings_index["mother"]
ball = embeddings_index["ball"]
crocodile = embeddings_index["crocodile"]
france = embeddings_index["france"]
tehran = embeddings_index["tehran"]
paris = embeddings_index["paris"]
iran = embeddings_index["iran"]
print("cosine_similarity(father, mother) = ", similarity(father, mother))
print("cosine_similarity(ball, crocodile) = ",similarity(ball, crocodile))
print("cosine_similarity(france - paris, tehran - iran) = ",similarity(france - paris, tehran - iran))
cosine_similarity(father, mother) = 0.86566603 cosine_similarity(ball, crocodile) = 0.15206575 cosine_similarity(france - paris, tehran - iran) = -0.6854124
2 - Word analogy task¶
In the word analogy task, we complete the sentence "a is to b as c is to ____". An example is 'man is to woman as king is to queen' . In detail, we are trying to find a word d, such that the associated word vectors $e_a, e_b, e_c, e_d$ are related in the following manner: $e_b - e_a \approx e_d - e_c$. We will measure the similarity between $e_b - e_a$ and $e_d - e_c$ using cosine similarity.
embeddings_index["father"]
array([ 0.64706 , -0.068067, 0.15468 , -0.17408 , -0.29134 , 0.76999 ,
-0.3192 , -0.25663 , -0.25082 , -0.036737, -0.25509 , 0.29636 ,
0.5776 , 0.49641 , 0.19167 , -0.83888 , 0.58482 , -0.38717 ,
-0.71591 , 0.9519 , -0.37966 , -0.1131 , 0.47154 , 0.20921 ,
0.38197 , 0.067582, -0.92879 , -1.1237 , 0.84831 , 0.68744 ,
-0.15472 , 0.92714 , 0.53371 , -0.037392, -0.856 , 0.19056 ,
-0.014594, 0.15186 , 0.53514 , -0.20306 , -0.35164 , 0.33152 ,
1.1306 , -0.72787 , -0.19724 , 0.031659, -0.24041 , -0.057617,
0.60473 , -0.49233 , -0.24405 , -0.3184 , 0.96156 , 1.0895 ,
0.21534 , -2.0542 , -1.0615 , 0.052439, 0.57958 , 0.2748 ,
0.91587 , 0.85195 , 0.36113 , -0.31901 , 0.7784 , -0.36865 ,
0.64387 , 0.33104 , -0.27181 , 0.58524 , -0.15143 , 0.11121 ,
0.2126 , -0.60345 , 0.16148 , 0.32952 , -0.1354 , -0.30629 ,
-0.89143 , 0.091912, 0.49753 , 0.55932 , 0.19329 , 0.044859,
-1.0416 , -0.41566 , -0.54174 , -0.7244 , -0.57492 , -1.1188 ,
0.087097, -0.2992 , 0.87227 , 0.86996 , -0.89641 , -0.28259 ,
-0.47295 , -0.74062 , -0.39 , -0.78099 ], dtype=float32)
def complete_analogy(word_a, word_b, word_c, embeddings_index):
# convert words to lower case
word_a, word_b, word_c = word_a.lower(), word_b.lower(), word_c.lower()
# Get the word embeddings v_a, v_b and v_c
e_a, e_b, e_c = embeddings_index[word_a], embeddings_index[word_b], embeddings_index[word_c]
words = embeddings_index.keys()
max_cosine_sim = -100 # Initialize max_cosine_sim to a large negative number
best_word = None # Initialize best_word with None, it will help keep track of the word to output
# loop over the whole word vector set
for w in words:
# to avoid best_word being one of the input words, pass on them.
if w in [word_a, word_b, word_c] :
continue
# Compute cosine similarity between the vector (e_b - e_a) and the vector ((w's vector representation) - e_c) (≈1 line)
cosine_sim = similarity(e_b - e_a, embeddings_index[w] - e_c)
# If the cosine_sim is more than the max_cosine_sim seen so far,
# then: set the new max_cosine_sim to the current cosine_sim and the best_word to the current word (≈3 lines)
if cosine_sim > max_cosine_sim:
max_cosine_sim = cosine_sim
best_word = w
return best_word
Run the cell below to test your code, this may take 1-2 minutes.
complete_analogy('china', 'chinese', 'iran', embeddings_index)
'iranian'
complete_analogy('india', 'delhi', 'iran', embeddings_index)
'tehran'
complete_analogy('man', 'woman', 'boy', embeddings_index)
'girl'
complete_analogy('small', 'smaller', 'big', embeddings_index)
'bigger'
complete_analogy('iran', 'farsi', 'canada', embeddings_index)
'inuktitut'