News Headline Analysis¶
In this project we're analyzing news headlines written by two journalists – a finance reporter from the Business Insider, and a celebrity reporter from the Huffington post – to find similarities and differences between the ways that these authors write headlines for their news articles and blog posts. Our selected reporters are:
- Akin Oyedele the Business Insider who covers market updates; and
- Carly Ledbetter from the Huffington Post who mainly writes about celebrities.
Approach¶
We're initially going to collect and parse news headline from each of the authors, to obtain a parse tree, and then we're going to extract certain information from these parse trees that are indicative of the overall structure of the headline.
Next, we will define a simple sequence similarity metric to compare any pair of headlines quantitatively, and we will apply the same method to all of the headlines we've gathered for each author, to find out how similar each pair of headlines is.
Finally, we're going to use K-Means and tSNE to produce a visual map of all the headlines, where we can see the similarities and the differences between the two authors more clearly.
Data¶
For this project we've gathered 700 headlines for each author using the AYLIEN News API which we're going to analyze using Python. You can obtain the Pickled data files directly from the GitHub repository, or by using the data collection notebook that we've prepared for this project.
A primer on parse trees¶
In linguistics, a parse tree is a rooted tree that represents the syntactic structure of a sentence, according to some pre-defined grammar.
For a simple sentence like "The cat sat on the mat", a parse tree might look like this:
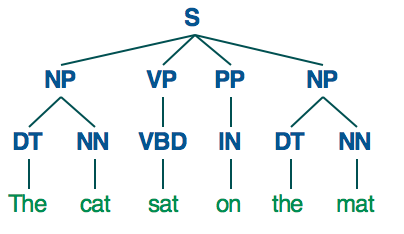
We're going to use the Pattern library for Python to parse the headlines and create parse trees for them:
from pattern.en import parsetree
Let's see an example:
s = parsetree('The cat sat on the mat.')
for sentence in s:
for chunk in sentence.chunks:
print chunk.type, [(w.string, w.type) for w in chunk.words]
NP [(u'The', u'DT'), (u'cat', u'NN')] VP [(u'sat', u'VBD')] PP [(u'on', u'IN')] NP [(u'the', u'DT'), (u'mat', u'NN')]
Loading the data¶
Let's load the Pickled data file for the first author (Akin Oyedele) which contains 700 headlines, and let's see an example of what a headline might look like:
import cPickle as pickle
author1 = pickle.load( open( "author1.p", "rb" ) )
author1[0]
{u'title': u"One corner of the real-estate market might've peaked"}
Parsing the data¶
Now that we have all the headlines for the first author loaded, we're going to analyze them, and create parse trees for each headline, and store them together with some basic information about the headline in the same object:
for story in author1:
story["title_length"] = len(story["title"])
story["title_chunks"] = [chunk.type for chunk in parsetree(story["title"])[0].chunks]
story["title_chunks_length"] = len(story["title_chunks"])
author1[0]
{u'title': u"One corner of the real-estate market might've peaked",
'title_chunks': [u'NP', u'PP', u'NP', u'VP'],
'title_chunks_length': 4,
'title_length': 52}
Let's see what the numeric attributes for headlines written by this author look like. We're going to use Pandas for this.
import pandas as pd
df1 = pd.DataFrame.from_dict(author1)
df1.describe()
| title_chunks_length | title_length | |
|---|---|---|
| count | 700.000000 | 700.000000 |
| mean | 5.691429 | 57.730000 |
| std | 3.762884 | 28.035283 |
| min | 1.000000 | 9.000000 |
| 25% | 2.000000 | 35.000000 |
| 50% | 5.000000 | 53.000000 |
| 75% | 7.000000 | 77.000000 |
| max | 30.000000 | 188.000000 |
From this information, we're going to extract the chunk type sequence of each headline (i.e. the first level of the parse tree) and use it as an indicator of the overall structure of the headline. So in the above example, we would extract and use the following sequence of chunk types in our analysis:
['NP', 'PP', 'NP', 'VP']
Similarity¶
We have loaded all the headlines written by the first author, and created and stored their parse trees. Next, we need to find a similarity metric that given two chunk type sequences, tells us how similar these two headlines are, from a structural perspective.
For that we're going to use the SequenceMatcher class of difflib, which produces a similarity score between 0 and 1 for any two sequences (Python lists):
import difflib
print "Similarity scores for...\n"
print "Two identical sequences: ", difflib.SequenceMatcher(None,["A","B","C"],["A","B","C"]).ratio()
print "Two similar sequences: ", difflib.SequenceMatcher(None,["A","B","C"],["A","B","D"]).ratio()
print "Two completely different sequences: ", difflib.SequenceMatcher(None,["A","B","C"],["X","Y","Z"]).ratio()
Similarity scores for... Two identical sequences: 1.0 Two similar sequences: 0.666666666667 Two completely different sequences: 0.0
Now let's see how that works with our chunk type sequences, for two randomly selected headlines from the first author:
v1 = author1[3]["title_chunks"]
v2 = author1[1]["title_chunks"]
print v1, v2, difflib.SequenceMatcher(None,v1,v2).ratio()
[u'NP', u'NP', u'VP', u'NP', u'NP', u'VP', u'PP'] [u'NP', u'VP', u'NP', u'PP', u'NP', u'NP'] 0.615384615385
Pair-wise similarity matrix for the headlines¶
We're now going to apply the same sequence similarity metric to all of our headlines, and create a 700x700 matrix of pairwise similarity scores between the headlines:
import numpy as np
chunks = [author["title_chunks"] for author in author1]
m = np.zeros((700,700))
for i, chunkx in enumerate(chunks):
for j, chunky in enumerate(chunks):
m[i][j] = difflib.SequenceMatcher(None,chunkx,chunky).ratio()
Visualization¶
To make things clearer and more understandable, let's try and put all the headlines written by the first author on a 2d scatter plot, where similarly structured headlines are close together.
For that we're going to first use tSNE to reduce the dimensionality of our similarity matrix from 700 down to 2:
from sklearn.manifold import TSNE
tsne_model = TSNE(n_components=2, verbose=1, random_state=0)
tsne = tsne_model.fit_transform(m)
[t-SNE] Computing pairwise distances... [t-SNE] Computed conditional probabilities for sample 700 / 700 [t-SNE] Mean sigma: 0.000000 [t-SNE] Error after 83 iterations with early exaggeration: 13.379313 [t-SNE] Error after 144 iterations: 0.633875
And to a bit of color to our visualization, let's K-Means to identify 5 clusters of similar headlines, which we will use in our visualization:
from sklearn.cluster import MiniBatchKMeans
kmeans_model = MiniBatchKMeans(n_clusters=5, init='k-means++', n_init=1,
init_size=1000, batch_size=1000, verbose=False, max_iter=1000)
kmeans = kmeans_model.fit(m)
kmeans_clusters = kmeans.predict(m)
kmeans_distances = kmeans.transform(m)
Finally let's plot the actual chart using Bokeh:
import bokeh.plotting as bp
from bokeh.models import HoverTool, BoxSelectTool
from bokeh.plotting import figure, show, output_notebook
colormap = np.array([
"#1f77b4", "#aec7e8", "#ff7f0e", "#ffbb78", "#2ca02c",
"#98df8a", "#d62728", "#ff9896", "#9467bd", "#c5b0d5",
"#8c564b", "#c49c94", "#e377c2", "#f7b6d2", "#7f7f7f",
"#c7c7c7", "#bcbd22", "#dbdb8d", "#17becf", "#9edae5"
])
output_notebook()
plot_author1 = bp.figure(plot_width=900, plot_height=700, title="Author1",
tools="pan,wheel_zoom,box_zoom,reset,hover,previewsave",
x_axis_type=None, y_axis_type=None, min_border=1)
plot_author1.scatter(x=tsne[:,0], y=tsne[:,1],
color=colormap[kmeans_clusters],
source=bp.ColumnDataSource({
"chunks": [x["title_chunks"] for x in author1],
"title": [x["title"] for x in author1],
"cluster": kmeans_clusters
}))
hover = plot_author1.select(dict(type=HoverTool))
hover.tooltips={"chunks": "@chunks (title: \"@title\")", "cluster": "@cluster"}
show(plot_author1)
<Bokeh Notebook handle for In[6]>
The above interactive chart shows a number of dense groups of headlines, as well as some sparse ones. Some of the dense groups that stand out more are:
- The NP, VP group on the left, which typically consists of short, snappy stock update headlines such as "Viacom is crashing";
- The VP, NP group on the top right, which is mostly announcement headlines in the "Here comes the..." format; and
- The NP, VP, ADJP, PP, VP group at bottom left, where we have headlines such as "Industrial production falls more than expected" or "ADP private payrolls rise more than expected".
If you look closely you will find other interesting groups, as well as their similarities/disimilarities when compared to their neighbors.
Comparing the two authors¶
Finally, let's load the headlines for the second author and see how they compare to the ones from the first one. The steps are quite similar to the above, except this time we're going to calculate the similarity of both sets of headlines and store it in a 1400x1400 matrix:
author2 = pickle.load( open( "author2.p", "rb" ) )
for story in author2:
story["title_length"] = len(story["title"])
story["title_chunks"] = [chunk.type for chunk in parsetree(story["title"])[0].chunks]
story["title_chunks_length"] = len(story["title_chunks"])
pd.DataFrame.from_dict(author2).describe()
| title_chunks_length | title_length | |
|---|---|---|
| count | 700.000000 | 700.000000 |
| mean | 5.452857 | 62.532857 |
| std | 1.896252 | 9.996154 |
| min | 1.000000 | 35.000000 |
| 25% | 4.000000 | 57.000000 |
| 50% | 5.000000 | 62.000000 |
| 75% | 7.000000 | 68.000000 |
| max | 13.000000 | 96.000000 |
The basic stats don't show a significant difference between the headlines written by the two authors.
chunks_joint = [author["title_chunks"] for author in (author1+author2)]
m_joint = np.zeros((1400,1400))
for i, chunkx in enumerate(chunks_joint):
for j, chunky in enumerate(chunks_joint):
sm=difflib.SequenceMatcher(None,chunkx,chunky)
m_joint[i][j] = sm.ratio()
Now that we have analyzed the headlines for the second author, let's see how many common patterns exist between the two authors:
set1= [author["title_chunks"] for author in author1]
set2= [author["title_chunks"] for author in author2]
list_new = [itm for itm in set1 if itm in set2]
len(list_new)
347
We observe that about 50% (347/700) of the headlines have a similar structure.
Visualization of headlines by the two authors¶
Our approach here is quite similar to what we did for the first author. The only difference is that here we're going to use colors to indicate the author and not the cluster this time (blue for author1 and orange for author2).
tsne_joint = tsne_model.fit_transform(m_joint)
[t-SNE] Computing pairwise distances... [t-SNE] Computed conditional probabilities for sample 1000 / 1400 [t-SNE] Computed conditional probabilities for sample 1400 / 1400 [t-SNE] Mean sigma: 0.000000 [t-SNE] Error after 83 iterations with early exaggeration: 16.425770 [t-SNE] Error after 148 iterations: 0.942156
plot_joint = bp.figure(plot_width=900, plot_height=700, title="Author1 vs. Author2",
tools="pan,wheel_zoom,box_zoom,reset,hover,previewsave",
x_axis_type=None, y_axis_type=None, min_border=1)
plot_joint.scatter(x=tsne_joint[:,0], y=tsne_joint[:,1],
color=colormap[([0] * 700 + [3] * 700)],
source=bp.ColumnDataSource({
"chunks": [x["title_chunks"] for x in author1] + [x["title_chunks"] for x in author2],
"title": [x["title"] for x in author1] + [x["title"] for x in author2]
}))
hover = plot_joint.select(dict(type=HoverTool))
hover.tooltips={"chunks": "@chunks (title: \"@title\")"}
show(plot_joint)
<Bokeh Notebook handle for In[6]>
Here we observe the same dense and sparse patterns, as well as groups of points that are somewhat unique to each author, or shared by both authors.
- The bottom right cluster is almost exclusive to the first author, as it covers the short financial/stock report headlines such as "Here comes CPI", but it also covers some of the headlines from the first author such as "There's Another Leonardo DiCaprio Doppelgänger". Same could be said about the top middle cluster.
- The top right cluster mostly contains single-verb headlines about celebrities doing things, such as "Kylie Jenner Graces Coachella With Her Peachy Presence" or "Kate Hudson Celebrated Her Birthday With A Few Shirtless Men" but it also includes market report headlines from the first author such as "Oil rig count plunges for 7th straight week".
We're sure you can find more interesting observations by looking closely at the above chart.
Conclusion and Future Work¶
In this project we've shown how one can retrieve and analyze news headlines, evaluate their structure and similarity, and build an interactive map to visualize them clearly.
Some of the weaknesses of our approach, and ways to improve upon them are:
- Using entire parse trees instead of just the chunk types
- Using a tree or graph similarity metric instead of a sequence similarity one (ideally a linguistic-aware one too)
- Better pre-processing to identify and normalize Named Entities, etc.
In a future post, we're going to study the correlations between various headline structures and some external metrics such as the number of Shares and Likes on Social Media platforms, and see if we can uncover any interesting patterns.