The Modifiable Areal Unit Problem, visually, in Python¶
The Modifiable Areal Unit Problem (MAUP) is a well know phenomenon for any researcher interested in spatial issues. In this notebook, we'll get our hands dirty experimenting with different geographical configurations and will see, in a practical way, some of the implications of the MAUP. In doing this, we'll also tour some of the basic functionality in geopandas.
To motivate this exercise, let us start from the end and show how, the exact same underlying geography, can generate radically different maps, depending on how we aggregate it:
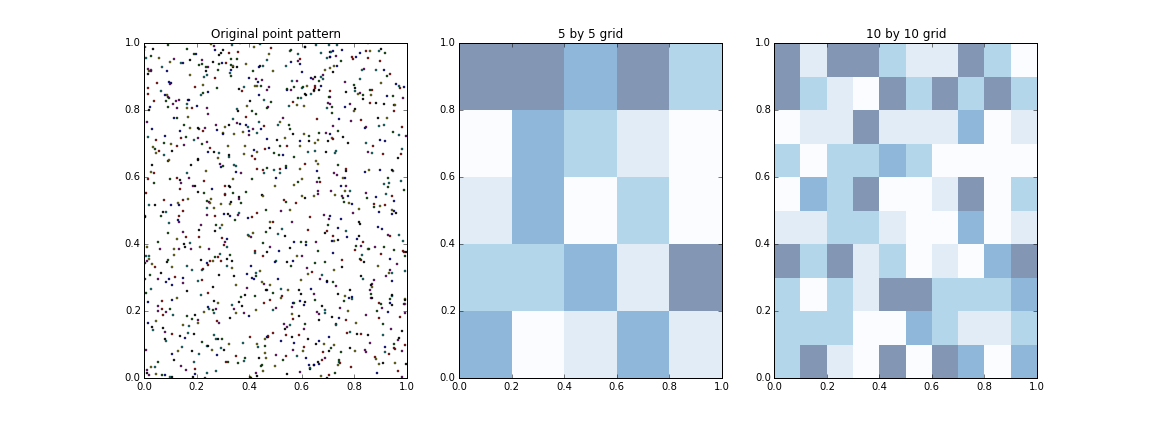
In this case, we have started from a set of points located in a hypothetical geography (left panel). We can think of them as firms located over a regional economy, the distribution of a particular species of trees over space, or any other phenomenon where the main unit of observation can be described as points located somewhere in space. Now, in the central pane, we have overlayed a five by five grid and, for every polygon, which we could think of a regions, we have counted the number of units and assigned a color based on its value. In the right pane, we have done the same, using the same underlying distribution of points, but have overlaid a ten by ten grid of polygons.
The gist of the MAUP is that, even though the original distribution is the same, the representation we access by looking at the aggregate can vary dramatically depending on the characteristics of this aggregation. In our example, the units were points and the aggregation were simple polygons in a grid. But the same problem occurs, for example, when we look at income over individuals and aggregate the average in neighborhoods, regions or countries: if the units we use for this aggregation are not meaningful, in other words, if they don't match well the underlying process, there can be substantial distortions.
Now we have the conceptual idea clear, let's see how we have arrived to the picture above! Before anything, here are the libraries you'll need to run this notebook:
%matplotlib inline
import matplotlib.pyplot as plt
import geopandas as gpd
import pandas as pd
import numpy as np
from itertools import product
from shapely.geometry import Polygon, Point
Generate polygon geographies¶
First we need an engine that generates grids of different sides. This will allow us later to easily create many geographies with different characteristics, which will dictate the aggregation process. We can solve this problem with the following method, which generates polygons and collects them into a GeoSeries:
def gridder(nr, nc):
'''
Return a grid with `nr` by `nc` polygons
...
Arguments
---------
nr : int
Number of rows
nc : int
Number of columns
'''
x_breaks = np.linspace(0, 1, nc+1)
y_breaks = np.linspace(0, 1, nr+1)
polys = []
for x, y in product(range(nc), range(nr)):
poly = [(x_breaks[x], y_breaks[y]), \
(x_breaks[x], y_breaks[y+1]), \
(x_breaks[x+1], y_breaks[y+1]), \
(x_breaks[x+1], y_breaks[y])]
polys.append(Polygon(poly))
return gpd.GeoSeries(polys)
Once defined, it's easy to generate a grid of, for example, four by three polygons:
polys = gridder(3, 4)
polys.plot(alpha=0)
plt.show()

Generate points within the geography¶
Now we have the "engine" to generate the geography, we need to create observations that we can pinpoint over space. The easiest way is to randomly generate points within the bounding box of the geographies we create, and store them in a different GeoSeries. That's exactly what the following function does:
def gen_pts(n):
'''
Generate `n` points over space and return them as a GeoSeries
...
Arguments
---------
n : int
Number of points to generate
Return
------
pts : GeoSeries
Series with the generated points
'''
xy = pd.DataFrame(np.random.random((n, 2)), columns=['X', 'Y'])
pts = gpd.GeoSeries(xy.apply(Point, axis=1))
return pts
This allows us to create, for example, 100 points:
# Set the seed to always get the same locations
np.random.seed(123)
pts = gen_pts(100)
pts.head()
0 POINT (0.6964691855978616 0.2861393349503795) 1 POINT (0.2268514535642031 0.5513147690828912) 2 POINT (0.7194689697855631 0.423106460124461) 3 POINT (0.9807641983846155 0.6848297385848633) 4 POINT (0.4809319014843609 0.3921175181941505) dtype: object
Since we already have tools to create both the underlying points and a geography in which to aggregate it, let us imagine what this could look like. In fact, stop imagining and simply plot them:
f, ax = plt.subplots(1)
polys.plot(alpha=0, axes=ax)
pts.plot(axes=ax)
plt.show()

Aggregate points to polygon¶
Now, to get to a map like those above, we need a way to assign how many points are within each polygon. The following method does exactly that, albeit in a fairly computationally expensive way. There are faster ways to do it in geopandas (spatial join, I'm looking at you), but they require additional dependencies, and are not as intuitive as this one I think. For now, this approach will have to do:
def map_pt2poly(pts, polys):
'''
Join points to the polygon where they fall into
NOTE: computationally inefficient, so slow on large sizes
...
Arguments
---------
pts : GeoSeries
Series with the points
polys : GeoSeries
Series with the polygons
Returns
-------
mapa : Series
Indexed series where the index is the point ID and the value is
the polygon ID.
'''
mapa = []
for i, pt in pts.iteritems():
for j, poly in polys.iteritems():
if poly.contains(pt):
mapa.append((i, j))
pass
mapa = np.array(mapa)
mapa = pd.Series(mapa[:, 1], index=mapa[:, 0])
return mapa
Check how we can collect the count for each polygon in a GeoDataFrame that also holds their geometries:
pt2poly = map_pt2poly(pts, polys)
count = pt2poly.groupby(pt2poly).size()
db = gpd.GeoDataFrame({'geometry': polys, 'count': count})
db.head()
| count | geometry | |
|---|---|---|
| 0 | 4 | POLYGON ((0 0, 0 0.3333333333333333, 0.25 0.33... |
| 1 | 8 | POLYGON ((0 0.3333333333333333, 0 0.6666666666... |
| 2 | 9 | POLYGON ((0 0.6666666666666666, 0 1, 0.25 1, 0... |
| 3 | 8 | POLYGON ((0.25 0, 0.25 0.3333333333333333, 0.5... |
| 4 | 12 | POLYGON ((0.25 0.3333333333333333, 0.25 0.6666... |
At this point, we have everything we need to make a map of the counts of points per polygon:
db.plot(column='count', scheme='quantiles', legend=True, colormap='Blues')
<matplotlib.axes._subplots.AxesSubplot at 0x10e55a8d0>

Automated¶
Although we have all the pieces, one of the beauties of scripting languages like Python is that they allow you wrap different functionality so that obtaining the final outcome is easier than repeating every step every time you need the final product. In this case, we can ease the process by encapsulating the process above into a single method that takes nr, nc and the points we want to plot and generate a table of counts per polygon:
def count_table(nr, nc, pts):
'''
Create a table with counts of points in `pts` assigned to a geography of
`nr` rows and `nc` columns
...
Arguments
---------
nr : int
Number of rows
nc : int
Number of columns
pts : GeoSeries
Series with the generated points
Returns
-------
tab : GeoDataFrame
Table with the geometries of the polygons and the count of
points that fall into each of them
'''
polys = gridder(nr, nc)
walk = map_pt2poly(pts, polys)
count = walk.groupby(walk).size().reindex(polys.index).fillna(0)
tab = gpd.GeoDataFrame({'geometry': polys, 'count': count})
return tab
For example, we can generate the counts for a five by five grid:
counts_5x5 = count_table(5, 5, pts)
counts_5x5.head()
| count | geometry | |
|---|---|---|
| 0 | 3 | POLYGON ((0 0, 0 0.2, 0.2 0.2, 0.2 0, 0 0)) |
| 1 | 2 | POLYGON ((0 0.2, 0 0.4, 0.2 0.4, 0.2 0.2, 0 0.2)) |
| 2 | 4 | POLYGON ((0 0.4, 0 0.6000000000000001, 0.2 0.6... |
| 3 | 4 | POLYGON ((0 0.6000000000000001, 0 0.8, 0.2 0.8... |
| 4 | 4 | POLYGON ((0 0.8, 0 1, 0.2 1, 0.2 0.8, 0 0.8)) |
And quickly plot it on quantile map using PySAL under the hood:
counts_5x5.plot(column='count', scheme='quantiles', colormap='Blues')
<matplotlib.axes._subplots.AxesSubplot at 0x10cec7e10>

Further MAUP exploration¶
Now we have all the pieces we require in an accessible way, let's explore what the choropleth looks like for the same set of points when we aggregate them into different geographies:
%%time
np.random.seed(123)
pts = gen_pts(1000)
sizes = [5, 10]
f, axs = plt.subplots(1, len(sizes)+1, figsize=(9*len(sizes), 6))
pts.plot(axes=axs[0])
axs[0].set_title('Original point pattern')
for size, ax in zip(sizes, axs[1:]):
tab = count_table(size, size, pts)
tab.plot(column='count', scheme='quantiles', \
colormap='Blues', axes=ax, linewidth=0)
ax.set_title("%i by %i grid"%(size, size))
plt.show()

CPU times: user 3.43 s, sys: 42.8 ms, total: 3.48 s Wall time: 3.48 s
We can also generate a plot for each case in which we compare the points, with the geography, with the final map:
def plot_case(nr, nc, pts):
'''
Generate an image with the original distribution, the geography, and the resulting map
...
Arguments
---------
nr : int
Number of rows
nc : int
Number of columns
pts : GeoSeries
Series with the generated points
'''
tab = count_table(nr, nc, pts)
f, axs = plt.subplots(1, 3, figsize=(18, 6))
pts.plot(axes=axs[0])
tab.plot(alpha=0, axes=axs[1])
tab.plot(column='count', scheme='quantiles', \
colormap='Blues', axes=axs[2], linewidth=0)
plt.show()
plot_case(7, 4, pts)

And then run if for several cases:
np.random.seed(123)
pts = gen_pts(500)
plot_case(2, 2, pts)
plot_case(5, 5, pts)
plot_case(10, 10, pts)




The Modifiable Areal Unit Problem, visually, in Python by Dani Arribas-Bel is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License.