Benford's Law and Stripe Transaction Amounts¶
Benford's Law describes a frequency distribution of first digits found in many real-life data sources. It is often overlooked by fraudsters in detective novels, who generate expenses whose digit distributions are random, and are thus easily exposed as fabricated.
In this notebook we'll look at the distribution of first digits of charge amounts across all Stripe charges, and see how it compares to the distribution predicted by Benford's Law.
First, we'll have to do a bit of boilerplate to get the notebook set up...
%matplotlib inline
# standard path wrangling to make notebook reproducible in dev and prod
import sys
from os.path import dirname, abspath
from os import getcwd
try:
root = dirname(dirname(abspath(__file__)))
except NameError:
root = dirname(getcwd())
sys.path.append(root)
from lib import auto_impala
# imports specific to this notebook
from impala.util import as_pandas
import brewer2mpl
import math
from scipy.stats import chisquare
import pandas as pd
import brewer2mpl
import lib.display_utils
True Digit Distribution¶
We can now query Impala to get the first digits of all real charges. We use helpers from Impyla to load these results directly into a pandas dataframe.
Note, this helper around defining the query just lets us syntax-highlight it for readability - passing in your query as a string will work as well
query = lib.display_utils.sql_query_from_file('examples/first_digits.sql')
query
SELECT
quotient(presentment__amount, pow(10, floor(log10(presentment__amount)))) AS "First Digit",
count(*) as "Count"
FROM denormalized.charges
WHERE is_live_sale
GROUP BY 1
with auto_impala() as cursor:
cursor.execute(query)
df = as_pandas(cursor)
# Clean up the dataframe a bit
df = df.dropna().sort('first digit').set_index('first digit')
Benford's Law Distribution¶
Now that we have the distribution of first digits across Stripe transactions, we'll want to calculate the distribution predicted by Benford's Law
Wikipedia describes the digit distribution of Benford's Law like so:
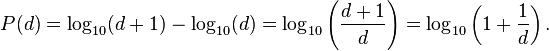
We can implement this as a function of the digit:
def benfordp(digit):
return math.log10(1. + (1./digit))
scaled_df = df / df.sum()[0]
scaled_df.rename(columns={'count': 'True Rate'}, inplace=True)
benford_series = pd.Series(map(benfordp, scaled_df.index), index=scaled_df.index)
benford_df = pd.DataFrame(benford_series, columns=['Benford Rate'])
Putting It Together¶
We'll create a new dataframe with the true rate alongside the rates that Benford's Law predicts. The notebook gives us a nice formatted display of this dataframe too.
joined_df = pd.concat([benford_df, scaled_df], axis=1)
joined_df
| Benford Rate | True Rate | |
|---|---|---|
| first digit | ||
| 1 | 0.301030 | 0.305680 |
| 2 | 0.176091 | 0.176187 |
| 3 | 0.124939 | 0.105398 |
| 4 | 0.096910 | 0.091885 |
| 5 | 0.079181 | 0.110171 |
| 6 | 0.066947 | 0.054765 |
| 7 | 0.057992 | 0.046189 |
| 8 | 0.051153 | 0.036322 |
| 9 | 0.045757 | 0.073403 |
9 rows × 2 columns
I'm told that Jeff Bezos has an uncanny ability to look at a wall of numbers and spot a trend. For the rest of us, it's more useful to plot the results. Dataframe objects have a plot method that does the right thing
colors = brewer2mpl.wesanderson.Moonrise1.mpl_colors # oh yeah
joined_df.plot(kind='bar', figsize=(14,10), title="Charge 1st Digits vs Benford's Law", color=colors)
<matplotlib.axes.AxesSubplot at 0x59b8cd0>

Looks pretty good! Note the divergences at 5 and 9 - prices like $9.99 are reasonably common and expected, but prices like $5 or $50 somewhat less so. Fascinating
Statistical Tests¶
Now, while we can inuitively see that these distributions are similar, we'd prefer to be able to test that quantitatively. We'll use a chi-squared test to compare the two. Specifically, we compute the p-value relative to the counts predicted by Benford's Law, which represents, roughly, the probability that the data that we observed was drawn from the Benford's Law distribution.
More specifically, we create a fake set of observations distributed according to Benford's Law and equal in magnitude to the set of real observations. The chi-squared test then computes the probability that the two sets of observations, real and fake, were drawn from the same distribution.
And the p-value is.......
chi2_score, p_value = chisquare(df['count'], benford_series * df.sum()[0])
p_value
0.0
0.0? What? This means that we can say with a very great amount of certainty that our charge amounts are not distributed according to Benford's Law. Maybe we're making them all up .. don't tell our investors!
More interestingly, while the distribution of the first digits of our charges look similar to Benford's Law when we eyeball it, the number of observations is large enough that we can say with confidence that the two distributions are in fact different.
Fin¶
I hope this has been a helpful introduction to what you can do with IPython Notebooks and nbviewer. As a recap, we used Impyla to execute queries from within the notebook and get the data that we wanted to inspect. We then used Pandas dataframes to wrangle, inspect, and combine that data with other sources. We used Pandas' built-in plotting helpers (powered by matplotlib) to visualize the data, and used scipy to run statistical tests against it. These are just some of the most common data packages in the Python ecosystem - anything else is potentially fair game as well!
Best of all, this notebook is fully reproducible. Anybody should be able to clone the repo, open this notebook, and press "Run All" and get the same results - albeit with newer data. This means that anyone can pick up where the original author left off, add other plots, or try to run the same analysis with a modified SQL query. I hope this will lead to more collaboartion on data-driven reports, more rigorous review, and more information disseminated throughout the company. Question the answers!