#!/usr/bin/env python
# coding: utf-8
# # The Local News Dataset
# View this document on [Github](https://github.com/yinleon/LocalNewsDataset/blob/master/nbs/local_news_dataset.ipynb?flush_cache=true) | [NbViewer](https://nbviewer.jupyter.org/github/yinleon/LocalNewsDataset/blob/master/nbs/local_news_dataset.ipynb?flush_cache=true#datasheet)
# by [Leon Yin](https://www.leonyin.org/)
# Data scientist SMaPP Lab NYU and affiliate at Data & Society.
# ## Table of Contents
# 1. [Introduction](#intro)
# 2. [Tech Specs](#specs)
# 3. [Using the Dataset](#use)
# # 1. Introduction
# Though not particularly a noticeable part of the current discussion, 2018 has shown us that understanding "fake news", and the media (manipulation) ecosystem at large, has as much to do with local broadcasting stations as it does Alex Jones and CNN.
#
# We saw local news outlets used as a sounding board to decry mainstream media outlets as "[fake news](https://www.youtube.com/watch?v=khbihkeOISc)." We also saw Russian trolls masquerade as local news outlets to [build trust](https://www.npr.org/2018/07/12/628085238/russian-influence-campaign-sought-to-exploit-americans-trust-in-local-news) as sleeper accounts on Twitter.
#
# To help put the pieces of this disinformation ecosystem into context, we can refer to a 2016 [Pew Study](http://www.journalism.org/2016/07/07/trust-and-accuracy/) on Trust and Accuracy of the Modern Media Consumer which showed that 86% of survey respondents had "a lot" or "some" confidence in local news. This was more than their confidence of national media outlets, social media, and family and friends.
#
#
# 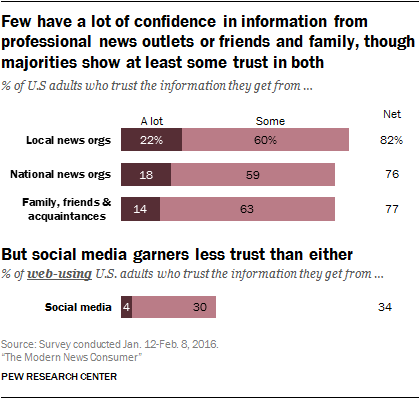 #
# Social media is the least trustworthy news source according to the 4.6K respondents of the Pew study. It's important to note that this study was published before the 2016 US Presidential Election and social media platforms were not under the same scrutiny as they are today.
#
# Perhaps the most significant finding in this study is that very few have "a lot" of trust in information from professional news outlets. Is this because so called "fake news" blurs the line between reputable and false pieces of information? Political scientist Andy Guess has shown that older (60+ yrs old) citizens are more sussceptitble to spreading links containing junk news on Facebook. Yet the mistrust economy is more than the [junk news](https://www.buzzfeednews.com/article/craigsilverman/viral-fake-election-news-outperformed-real-news-on-facebook) sites Craig Silverman analyzed when he first coined "fake news" in late 2016.
#
#
#
# Social media is the least trustworthy news source according to the 4.6K respondents of the Pew study. It's important to note that this study was published before the 2016 US Presidential Election and social media platforms were not under the same scrutiny as they are today.
#
# Perhaps the most significant finding in this study is that very few have "a lot" of trust in information from professional news outlets. Is this because so called "fake news" blurs the line between reputable and false pieces of information? Political scientist Andy Guess has shown that older (60+ yrs old) citizens are more sussceptitble to spreading links containing junk news on Facebook. Yet the mistrust economy is more than the [junk news](https://www.buzzfeednews.com/article/craigsilverman/viral-fake-election-news-outperformed-real-news-on-facebook) sites Craig Silverman analyzed when he first coined "fake news" in late 2016.
#
#  #
# In 2017, media historian Caroline Jack released a [lexicon](https://datasociety.net/output/lexicon-of-lies/) in an effort to define what was formerly referred to as "fake news," with more nuance. Jack calls this umbrella of deceptive content problematic information.
#
#
# The social media scholar Alice Marwick -- who made some of the first breakthroughs in thie field with [Becca Lewis](https://datasociety.net/output/media-manipulation-and-disinfo-online/), [recently reminded us that](https://www.georgetownlawtechreview.org/why-do-people-share-fake-news-a-sociotechnical-model-of-media-effects/GLTR-07-2018/) problematic information spreads not only through junk news headlines, but also through memes, videos and podcasts. What other mediums are we overlooking? As a hint, we can listen to Marwick and other researchers such as ethnographer [Francesca Tripoldi](https://datasociety.net/output/searching-for-alternative-facts/), who observe that problematic information is deeply connected to one's self-presentation and the reinforcement of group identity. So where does local news fit into this equation?
#
# Though local news is widely viewed as a relatively trustworthy news source, its role in the current media and information landscape is not well studied. To better understand that role, I put together the Local News Dataset in the hopes that it will accelerate research of local news across the web.
#
# ## About the Data Set
# This dataset is a machine-readable directory of state-level newspapers, TV stations and magazines. In addition to basic information such as the name of the outlet and state it is located in, all available information regarding web presence, social media (Twitter, YouTube, Facebook) and their owners is scraped, too.
#
# The sources of this dataset are [usnpl.com](www.usnpl.com)-- newspapers and magazines by state, [stationindex.com](www.stationindex.com) -- TV stations by state and by owner, and homepages of the media corporations [Meredith](http://www.meredith.com/local-media/broadcast-and-digital), [Sinclair](http://sbgi.net/tv-channels/), [Nexstar](https://www.nexstar.tv/stations/), [Tribune](http://www.tribunemedia.com/our-brands/) and [Hearst](http://www.hearst.com/broadcasting/our-markets).
#
# This dataset was inspired by ProPublica's [Congress API](https://projects.propublica.org/api-docs/congress-api/). I hope that this dataset will serve a similar purpose as a starting point for research and applications, as well as a bridge between datasets from social media, news articles and online communities.
#
# While you use this dataset, if you see irregularities, questionable entries, or missing outlets please [submit an issue](https://github.com/yinleon/LocalNewsDataset/issues/new) on Github or contact me on [Twitter](https://twitter.com/LeonYin). I'd love to hear how this dataset is put to work
#
# You can browse the dataset on [Google Sheets](https://docs.google.com/spreadsheets/d/1f3PjT2A7-qY0SHcDW30Bc_FXYC_7RxnZfCKyXpoWeuY/edit?usp=sharing)
#
# In 2017, media historian Caroline Jack released a [lexicon](https://datasociety.net/output/lexicon-of-lies/) in an effort to define what was formerly referred to as "fake news," with more nuance. Jack calls this umbrella of deceptive content problematic information.
#
#
# The social media scholar Alice Marwick -- who made some of the first breakthroughs in thie field with [Becca Lewis](https://datasociety.net/output/media-manipulation-and-disinfo-online/), [recently reminded us that](https://www.georgetownlawtechreview.org/why-do-people-share-fake-news-a-sociotechnical-model-of-media-effects/GLTR-07-2018/) problematic information spreads not only through junk news headlines, but also through memes, videos and podcasts. What other mediums are we overlooking? As a hint, we can listen to Marwick and other researchers such as ethnographer [Francesca Tripoldi](https://datasociety.net/output/searching-for-alternative-facts/), who observe that problematic information is deeply connected to one's self-presentation and the reinforcement of group identity. So where does local news fit into this equation?
#
# Though local news is widely viewed as a relatively trustworthy news source, its role in the current media and information landscape is not well studied. To better understand that role, I put together the Local News Dataset in the hopes that it will accelerate research of local news across the web.
#
# ## About the Data Set
# This dataset is a machine-readable directory of state-level newspapers, TV stations and magazines. In addition to basic information such as the name of the outlet and state it is located in, all available information regarding web presence, social media (Twitter, YouTube, Facebook) and their owners is scraped, too.
#
# The sources of this dataset are [usnpl.com](www.usnpl.com)-- newspapers and magazines by state, [stationindex.com](www.stationindex.com) -- TV stations by state and by owner, and homepages of the media corporations [Meredith](http://www.meredith.com/local-media/broadcast-and-digital), [Sinclair](http://sbgi.net/tv-channels/), [Nexstar](https://www.nexstar.tv/stations/), [Tribune](http://www.tribunemedia.com/our-brands/) and [Hearst](http://www.hearst.com/broadcasting/our-markets).
#
# This dataset was inspired by ProPublica's [Congress API](https://projects.propublica.org/api-docs/congress-api/). I hope that this dataset will serve a similar purpose as a starting point for research and applications, as well as a bridge between datasets from social media, news articles and online communities.
#
# While you use this dataset, if you see irregularities, questionable entries, or missing outlets please [submit an issue](https://github.com/yinleon/LocalNewsDataset/issues/new) on Github or contact me on [Twitter](https://twitter.com/LeonYin). I'd love to hear how this dataset is put to work
#
# You can browse the dataset on [Google Sheets](https://docs.google.com/spreadsheets/d/1f3PjT2A7-qY0SHcDW30Bc_FXYC_7RxnZfCKyXpoWeuY/edit?usp=sharing)
# Or look at the raw dataset on [Github](https://github.com/yinleon/LocalNewsDataset/blob/master/data/local_news_dataset_2018.csv)
# Or just scroll down to the [tech specs](#local_news_dataset_2018)!
#
# Happy hunting!
#
# ## Acknowledgements
# I'd like to acknowledge the work of the people behind usnpl.com and stationindex.com for compiling lists of local media outlets.
# Andreu Casas and Gregory Eady provided invaluable comments to improve this dataset for public release. Kinjal Dave provided much needed proofreading. The dataset was created by Leon Yin at the SMaPP Lab at NYU. Thank you Josh Tucker, Jonathan Nagler, Richard Bonneau and my collegue Nicole Baram.
#
#
# ## Citation
# If this dataset is helpful to you please cite it as:
# ```
# @misc{leon_yin_2018_1345145,
# author = {Leon Yin},
# title = {Local News Dataset},
# month = aug,
# year = 2018,
# doi = {10.5281/zenodo.1345145},
# url = {https://doi.org/10.5281/zenodo.1345145}
# }
#
# ```
#
# ## License
# This data is free to use, but please follow the ProPublica [Terms](#terms).
#
#
# # 2.Tech Specs
# This section is an in-depth look at what is scraped from the web and how these pieces of disparate Internet matter come together to form the [Local News Dataset](https://github.com/yinleon/LocalNewsDataset).
#
# For those who tinker...
# The intermediates can be generated and updated:
# ```>>> python download_data.py```
# The output file is created from merging and pre-processing the intermediates:
# ```>>> python merge.py```
# These [two scripts](https://github.com/yinleon/LocalNewsDataset/tree/master/py) -- and this notebook, is written in Python 3.6.5 using open sources packages listed in in [requirements.txt](https://github.com/yinleon/LocalNewsDataset/blob/master/requirements.txt).
#
# [Top of Notebook](#top)
# In[1]:
from runtimestamp.runtimestamp import runtimestamp # for reproducibility
from docs.build_docs import * # auto-generates docs
runtimestamp('Leon')
generate_docs()
# # 3. Using the Dataset
# Below is some starter code in Python to read the Local News Dataset from the web into a Pandas Dataframe.
#
# [Top of Notebook](#top)
# In[2]:
url = 'https://raw.githubusercontent.com/yinleon/LocalNewsDataset/master/data/local_news_dataset_2018.csv'
df_local = pd.read_csv(url)
# If you want to use this dataset for a list of web domains, there are a few steps you'll need to take:
# In[9]:
df_local_website.to_csv('../data/local_news_dataset_2018_for_domain_analysis.csv', index=False)
# In[3]:
df_local_website = df_local[(~df_local.domain.isnull()) &
(df_local.domain != 'facebook.com') &
(df_local.domain != 'google.com') &
(df_local.domain != 'tumblr.com') &
(df_local.domain != 'wordpress.com') &
(df_local.domain != 'comettv.com')].drop_duplicates(subset=['domain'])
# We do these steps because some entries don't have websites, at least one listed website is Facebook pages, comet TV is a nationwide franchise, and some stations share the a website.
# In[4]:
df_local_website.sample(3, random_state=303)
# For convenience this filtered dataset is available here: `https://raw.githubusercontent.com/yinleon/LocalNewsDataset/master/data/local_news_dataset_2018_for_domain_analysis.csv`
# and also here:
`http://bit.ly/local_news_dataset_domains`
# In[12]:
df_local_news_domain = pd.read_csv('http://bit.ly/local_news_dataset_domains')
df_local_news_domain.head(2)
# If you want to get Twitter accounts for all local news stations in Kansas you can filter the dataset as follows:
# In[7]:
twitter_ks = df_local[(~df_local.twitter.isnull()) &
(df_local.state == 'KS')]
twitter_ks.twitter.unique()
# We can also get an array of all domains affiliated with Sinclair:
# In[8]:
sinclair_stations = df_local[df_local.owner == 'Sinclair'].domain.unique()
sinclair_stations
# Stay tuned for more in-depth tutorials about how this dataset can be used!
# # 4. Data Sheet
# In the spirit of transparency and good documentation, I am going to answer some questions for datasets proposed in the recent paper [Datasheets for Datasets](https://arxiv.org/abs/1803.09010) by Timnit Gebru, Jamie Morgenstern, Briana Vecchione, Jennifer Wortman Vaughan, Hanna Wallach, Hal Daumeé III, Kate Crawford.
#
# [Top of Notebook](#top)
#
# ### Motivation for Dataset Creation
# *Why was the dataset created? (e.g., were there specific
# tasks in mind, or a specific gap that needed to be filled?)*
# This Dataset was created to study the role of state-level local news on Twitter.
# We wanted to find users who follow both local news outlets and members of congress.
#
# *What (other) tasks could the dataset be used for? Are
# there obvious tasks for which it should not be used?*
# The dataset can be used to query other social media platforms for local news outlet's social feeds.
# It can also serve as a list of state-level domains for link analysis. This is one use of this dataset in an uncoming report on the Internet Research Agency's use of links on Twitter.
#
# I hope that this dataset might be of interest for researchers applying to the [Social Science One and Facebook RFP](https://socialscience.one/our-facebook-partnership).
#
# *Has the dataset been used for any tasks already? If so,
# where are the results so others can compare (e.g., links to
# published papers)?*
# A study of IRA Twitter accounts sharing national, local, and junk news articles.
#
# *Who funded the creation of the dataset? If there is an
# associated grant, provide the grant number.*
# The dataset was created by Leon Yin at the SMaPP Lab at NYU. For more information, please visit our [website](https://wp.nyu.edu/smapp/).
#
# ### Dataset Composition
# *What are the instances? (that is, examples; e.g., documents,
# images, people, countries) Are there multiple types
# of instances? (e.g., movies, users, ratings; people, interactions
# between them; nodes, edges)*
# Each instance is a local news outlet.
#
#
# *Are relationships between instances made explicit in
# the data (e.g., social network links, user/movie ratings, etc.)?
# How many instances of each type are there?*
# We have relational links in this data, but that is up to you to make those connections. For counts, please refer to the spec sheet above.
#
# *What data does each instance consist of? “Raw” data
# (e.g., unprocessed text or images)? Features/attributes?*
# Each instance is a scraped entity from a website. There are no images involved. The metadata fields regarding state, website, and social accounts are scraped from raw HTML.
#
#
# *Is there a label/target associated with instances? If the instances are related to people, are subpopulations identified
# (e.g., by age, gender, etc.) and what is their distribution?*
# This is not a traditional supervised machine learning dataset.
#
# *Is everything included or does the data rely on external
# resources? (e.g., websites, tweets, datasets) If external
# resources, a) are there guarantees that they will exist, and
# remain constant, over time; b) is there an official archival
# version.*
# The data relies of external sources! There are abolutely no guarentees that data to Twitter, Youtube, Facebook, the source websites (where data is scraped), or the destination websites (homepages for news outlets).
#
# Currently there are open source libraries -- like [TweePy](http://www.tweepy.org/), to query Twitter, and my collegue Megan Brown and I are about to release a Python wrapper for the Youtube Data API library.
#
# *Are there licenses, fees or rights associated with
# any of the data?*
# This dataset is free to use. We're copying terms of use from [ProPublica](https://www.propublica.org/datastore/terms):
# ```
# In general, you may use this dataset under the following terms. However, there may be different terms included for some data sets. It is your responsibility to read carefully the specific terms included with the data you download or purchase from our website.
#
# You can’t republish the raw data in its entirety, or otherwise distribute the data (in whole or in part) on a stand-alone basis.
# You can’t change the data except to update or correct it.
# You can’t charge people money to look at the data, or sell advertising specifically against it.
# You can’t sub-license or resell the data to others.
# If you use the data for publication, you must cite Leon Yin and the SMaPP Lab.
# We do not guarantee the accuracy or completeness of the data. You acknowledge that the data may contain errors and omissions.
# We are not obligated to update the data, but in the event we do, you are solely responsible for checking our site for any updates.
# You will indemnify, hold harmless, and defend Leon Yin and the SMaPP Lab from and against any claims arising out of your use of the data.
# ```
#
# ### Data Collection Process
# *How was the data collected? (e.g., hardware apparatus/sensor,
# manual human curation, software program,
# software interface/API; how were these constructs/measures/methods
# validated?)*
# The data was collected using 4 CPUs on the NYU HPC Prince Cluster. It was written using [custom code](https://github.com/yinleon/LocalNewsDataset/tree/master/py) that utilizes the requests, beautifulsoup, and Pandas Python libraries. For this reason no APIs are used to collect this data. Data was quality checked by exploring data in Jupyter Noteooks. It was compared to lists curated by [AbilityPR](https://www.agilitypr.com/resources/top-media-outlets/) of the top 10 newspapers by state.
#
# *Who was involved in the data collection process?*
# This dataset was collected by Leon Yin.
#
# *Over what time-frame was the data collected?*
# The `process_datetime` columns capture when datasets are collected. Initial development for this project began in April 2018.
#
# *How was the data associated with each instance acquired?*
# Data is directly scraped from HTML, there is no inferred data. There is no information how the sources curate their websites-- especially TVstationindex.com and USNPL.com.
#
# *Does the dataset contain all possible instances?*
# Ths is not a sample, but the best attempt at creating a comprehensive list.
#
# *Is there information missing from the dataset and why?*
# News Outlets not listed in the websites we scrape, or the custom additions JSON are not included. We'll make attempt to take requests for additions and ammendments on GitHub with the intention of creating a website with a submission forum.
#
# *Are there any known errors, sources of noise, or redundancies
# in the data?*
# There are possible redundencies of news outlets occuring across the websites scraped. We have measures to drop duplicates, but if we missed any please submit an error in GitHub.
#
# ### Data Preprocessing
# *What preprocessing/cleaning was done?*
# Twitter Screen Names are extracted from URLs, states are parsed from raw HTML that usually contains a city name, there is no aggregation or engineered features.
#
# *Was the “raw” data saved in addition to the preprocessed/cleaned
# data?*
# The raw HTML for each site is not provided (so changes in website UI's) will crash future collection. There are no warranties for this. However the intermediate files are saved, and thoroughly documented in the [tech specs](#specs) above.
#
# *Is the preprocessing software available?*
# The dataset is a standard CSV, so any relevant open source software can be used.
#
# *Does this dataset collection/processing procedure
# achieve the motivation for creating the dataset stated
# in the first section of this datasheet?*
# The addition of Twitter Screen names makes it possible to use this data for Twitter research. The inclusion of additional fields like website, other social media platforms (Facebook, Youtube) allows for additional applications
#
#
# ### Dataset Distribution
# *How is the dataset distributed? (e.g., website, API, etc.;
# does the data have a DOI; is it archived redundantly?)*
# The dataset is being hosted on GitHub at the moment. It does not have a DOI (if you have suggestions on how to get one please reach out!). There are plans to migrate the dataset to its own website.
#
# *When will the dataset be released/first distributed?*
# August 2018.
#
# *What license (if any) is it distributed under?*
# MIT
#
# *Are there any fees or access/export restrictions?*
# Not while it is on GitHub, but if its migrated elsewhere that's possible.
#
# ### Dataset Maintenance
# *Who is supporting/hosting/maintaining the dataset?*
# The dataset is currently solely maintained by Leon Yin. This seems unsustainable, so if this project sparks an interest with you please reach out to me here: `data-smapp_lab at nyu dot edu`
#
# *Will the dataset be updated? How often and by whom?
# How will updates/revisions be documented and communicated
# (e.g., mailing list, GitHub)? Is there an erratum?*
# The dataset can be updated locally by running the scripts in this repo. Ammendments to the hosted dataset will contain a separate filepath and URL, and be documented in the README.
#
#
# *If the dataset becomes obsolete how will this be communicated?*
# If the dataset becomes obsolete, we'll make this clear in the README in the GitHub repository (or whereever it is being hosted).
#
# *Is there a repository to link to any/all papers/systems
# that use this dataset?*
# There aren't any publications that use this dataset that are published. We'll keep a list on the README or the website.
#
# *If others want to extend/augment/build on this dataset,
# is there a mechanism for them to do so?*
# Modifications can be made by adding records to the ammendments [JSON](https://github.com/yinleon/LocalNewsDataset/blob/master/data/custom_additions.json).
#
# ### Legal & Ethical Considerations
# *If the dataset relates to people (e.g., their attributes) or
# was generated by people, were they informed about the
# data collection?*
# This dataset has no people-level information. However we don't know anything about the people who generated the webpages that this dataset is built on.
#
# *Does the dataset contain information that might be considered
# sensitive or confidential?*
# To my knowledge there is no personally identifiable information in this dataset.
#
# *Does the dataset contain information that might be considered
# inappropriate or offensive?*
# I hope not!
# [Top of Notebook](#top)