#!/usr/bin/env python
# coding: utf-8
# # Деревья решений
# Шестаков А.В. Майнор по анализу данных 05/04/2016
# На прошлых занятиях мы рассматривали **линейные** модели классификации и регрессии. Деревья решений - совсем другая история. Во-первых, потому что их можно использовать и для регрессии и для классификации, а во-вторых линейностью там только слегка веет.
#
# Формально, деревья решений можно представить в виде вложенного набора правил "Если - То", но гораздо нагляднее изображать их именно в виде дерева.
#
# Например, дерево может выглядеть так:
#
# 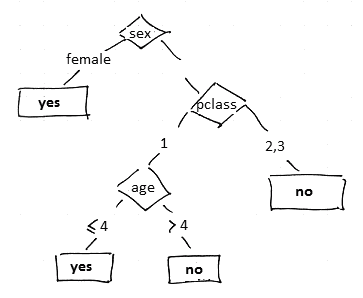 # ### Классификация с деревьями решений
# Давайте попробуем вспомнить, как они стоятся. Рассмотрим следующий набор данных
#
#
# | ID | Refund | Marital Status | Income | Cheat
# |-
# | 1 | Yes | Single | 125K | No
# | 2 | No | Married | 100K | No
# | 3 | No | Single | 70K | No
# | 4 | Yes | Married | 120K | No
# | 5 | No | Divorced | 95K | Yes
# | 6 | No | Married | 60K | No
# | 7 | Yes | Divorced | 220K | No
# | 8 | No | Single | 85K | Yes
# | 9 | No | Married | 75K | No
# | 10 | No | Single | 90K | Yes
#
# Имеем 3 признака и класс *Cheat*. Нужно выбрать признак, который наилучшим образом дифференцирует между классами. Посчитать это можно с помощью Impurity Measures и прироста информации:
#
# **Impurity Measures: (меры неравенства\неопределенности)**
# * Gini index $I(S) = 1 - \sum\limits_k (p_k)^2$
# * Entropy $I(S) = -\sum\limits_k p_k \log(p_k)$
# * Missclassification error $I(S) = 1 - \max\limits_k p_k$
#
# $p_k$ - доля класса $k$ в узле дерева $S$
#
# **Прирост информации: (насколько уменьшится неопределенность)**
# ### Классификация с деревьями решений
# Давайте попробуем вспомнить, как они стоятся. Рассмотрим следующий набор данных
#
#
# | ID | Refund | Marital Status | Income | Cheat
# |-
# | 1 | Yes | Single | 125K | No
# | 2 | No | Married | 100K | No
# | 3 | No | Single | 70K | No
# | 4 | Yes | Married | 120K | No
# | 5 | No | Divorced | 95K | Yes
# | 6 | No | Married | 60K | No
# | 7 | Yes | Divorced | 220K | No
# | 8 | No | Single | 85K | Yes
# | 9 | No | Married | 75K | No
# | 10 | No | Single | 90K | Yes
#
# Имеем 3 признака и класс *Cheat*. Нужно выбрать признак, который наилучшим образом дифференцирует между классами. Посчитать это можно с помощью Impurity Measures и прироста информации:
#
# **Impurity Measures: (меры неравенства\неопределенности)**
# * Gini index $I(S) = 1 - \sum\limits_k (p_k)^2$
# * Entropy $I(S) = -\sum\limits_k p_k \log(p_k)$
# * Missclassification error $I(S) = 1 - \max\limits_k p_k$
#
# $p_k$ - доля класса $k$ в узле дерева $S$
#
# **Прирост информации: (насколько уменьшится неопределенность)**
# $$ Gain(S, A) = I(S) - \sum\limits_v\frac{|S_v|}{|S|}\cdot I(S_v),$$ где $A$ - это некий атрибут, а $v$ - его значения
#
# Например, для нашей таблицы:
# $$I(S) = -(\frac{3}{10}\log(\frac{3}{10}) + \frac{7}{10}\log(\frac{7}{10})) = 0.61$$
#
# Возьмем, например, атрибут *Marital Status*
#
# $$Gain(S, \text{`Marital Status`}) = I(S) - (\frac{4}{10}\cdot I(S_{single}) + \frac{2}{10}\cdot I(S_{divorced}) + \frac{4}{10}\cdot I(S_{married})) = 0.19$$
#
# Проделаем тоже самое для остальных атрибутов..
# In[ ]:
# Your code here
# ### Регрессия с деревьями решений
# В этом случае всё очень похоже, с той разницой, что мы будем пытаться уменьшить среднюю квадратичную ошибку
# $$I(S) = \frac{1}{|S|} \sum\limits_{i \in S} (y_i - c)^2 $$
# $$ c = \frac{1}{|S|}\sum\limits_{i \in S} y_i $$
# ### Как посмотреть на деревья?
# Для этого вам понадобится специальная библиотека по работе с графами `graphviz`. [Здесь](http://scikit-learn.org/stable/modules/tree.html) вы можете увидеть пример нарисованного в Python дерева.
#
# Если вы хотите увидеть правила, то можно использовать код [отсюда](http://stackoverflow.com/questions/20224526/how-to-extract-the-decision-rules-from-scikit-learn-decision-tree)
# In[ ]:
def get_code(tree, feature_names):
left = tree.tree_.children_left
right = tree.tree_.children_right
threshold = tree.tree_.threshold
features = [feature_names[i] for i in tree.tree_.feature]
value = tree.tree_.value
def recurse(left, right, threshold, features, node):
if (threshold[node] != -2):
print "if ( " + features[node] + " <= " + str(threshold[node]) + " ) {"
if left[node] != -1:
recurse (left, right, threshold, features,left[node])
print "} else {"
if right[node] != -1:
recurse (left, right, threshold, features,right[node])
print "}"
else:
print "return " + str(value[node])
recurse(left, right, threshold, features, 0)
# ### Немного интуиции
# In[ ]:
import pandas as pd
import numpy as np
import subprocess
from sklearn.datasets import make_circles
from sklearn.tree import DecisionTreeRegressor
from sklearn.tree import DecisionTreeClassifier
from sklearn.tree import export_graphviz
import matplotlib.pyplot as plt
plt.style.use('ggplot')
get_ipython().run_line_magic('matplotlib', 'inline')
# #### Классификация
# In[ ]:
X, y = make_circles(n_samples=500, noise=0.1, factor=0.2)
# In[ ]:
# Your code here
# In[ ]:
with open('tree.dot', 'w') as fout:
export_graphviz(tree, out_file=fout, feature_names=['x1', 'x2'], class_names=['0', '1'])
command = ['dot', '-Tpng', 'tree.dot', '-o', 'tree.png']
subprocess.check_call(command)
plt.figure(figsize=(10, 10))
plt.imshow(plt.imread('tree.png'))
plt.axis('off')
# #### Регрессия
# In[ ]:
X = np.linspace(-5, 5, 100)
X += np.random.randn(X.shape[0])
y = 5*np.sin(2*X) + X**2
y += 2*np.random.randn(y.shape[0])
# In[ ]:
plt.scatter(X, y)
# In[ ]:
# Your code here
# In[ ]:
with open('tree.dot', 'w') as fout:
export_graphviz(tree, out_file=fout, feature_names=['x1'])
command = ['dot', '-Tpng', 'tree.dot', '-o', 'tree.png']
subprocess.check_call(command)
plt.figure(figsize=(20, 20))
plt.imshow(plt.imread('tree.png'))
plt.axis('off')
# ### Перейдем к практике
# Загрузите [данные](https://www.dropbox.com/s/3t1moa1wpflx2u9/california.dat?dl=0).
#
# **Задание 1:** Найти оптимальную глубину дерева.
# Разделите выборку на train-test в пропорции 70/30.
# Обучите деревья с глубиной от `1` до `30`. Для каждой глубины расчитайте среднюю квадратичную ошибку на train и на test
# Изобразите эти ошибки на одном графике, сделайте вывод по поводу оптимальной глубины дерева.
# In[ ]:
# Your code here
# **Задание 2:** Выведите важности признаков. Для этого воспользуйтесь `DecisionTreeRegressor.feature_importances_`
# In[ ]:
# Your code here
# **Задание 3:** Поразмышляйте на темы:
# * Нужна ли нормировка признаков для деревьев решений?
# * Обработки пропусков в данных.
# * Как сделать разделяющие плоскости непараллельные осям?