#!/usr/bin/env python
# coding: utf-8
# # Scraping StackOverflow
#
# In this project, we will be scraping StackOverflow website and:
#
# - [Goal 1: List Most mentioned/tagged languages along with their tag counts](#Goal1)
# - [Goal 2: List Most voted questions along with with their attributes (votes, summary, tags, number of votes, answers and views)](#Goal2)
#
# We will divide our project into the above mentioned two goals.
#
# Before starting our project, we need to understand few basics regarding Web Scraping.
# # Web Scraping Basics
#
# Before starting our project, we need to understand few basics regarding Web Pages and Web Scraping.
#
# When we visit a page, our browser makes a request to a web server. Most of the times, this request is a [GET Request](https://realpython.com/lessons/the-get-request/). Our web browser then receives a bunch of files, typically (HTML, CSS, JavaScript). HTML contains the content, CSS & JavaScript tell browser how to render the webpage. So, we will be mainly interested in the HTML file.
#
# ### HTML:
# HTML has elements called [tags](https://www.w3schools.com/html/html_elements.asp), which help in differentiating different parts of a HTML Document. Different types of tags are:
# * `html` - all content is inside this tag
# * `head` - contains title and other related files
# * `body` - contains main cotent to be displayed on the webpage
# * `div` - division or area of a page
# * `p` - paragraph
# * `a` - links
#
# We will get our content inside the body tag and use p and a tags for getting paragraphs and links.
#
# HTML also has [class and id properties](https://www.codecademy.com/articles/classes-vs-ids). These properties give HTML elements names and makes it easier for us to refer to a particular element. `Class` can be shared among multiple elements and an element can have moer then one class. Whereas, `id` needs to be unique for a given element and can be used just once in the document.
#
# ### Requests
# The requests module in python lets us easily download pages from the web.
# We can request contents of a webpage by using `requests.get()`, passing in target link as a parameter. This will give us a [response object](https://realpython.com/python-requests/#the-response).
#
# ### Beautiful Soup
# [Beautiful Soup](https://www.crummy.com/software/BeautifulSoup/bs4/doc/) library helps us parse contents of the webpage in an easy to use manner. It provides us with some very useful methods and attributes like:
# * `find()`, `select_one()` - retuns first occurence of the tag object that matches our filter
# * `find_all()`, `select()` - retuns a list of the tag object that matches our filter
# * `children` - provides list of direct nested tags of the given paramter/tag
#
# These methods help us in extracting specific portions from the webpage.
#
# ***Tip: When Scraping, we try to find common properties shared among target objects. This helps us in extracting all of them in just one or two commands.***
#
# For e.g. We want to scrap points of teams on a league table. In such a scenario, we can go to each element and extract its value. Or else, we can find a common thread (like **same class, same parent + same element type**) between all the points. And then, pass that common thread as an argument to BeautifulSoup. BeautifulSoup will then extract and return the elements to us.
# # Goal 1: Listing most tagged Languages
#
# Now that we know the basics of Web Scraping, we will move towards our first goal.
#
# In Goal 1, we have to list most tagged Languages along with their Tag Count. First, lets make a list of steps to follow:
#
# - [1. Download Webpage from stackoverflow](#1.1)
# - [2. Parse the document content into BeautifulSoup](#1.2)
# - [3. Extract Top Languages](#1.3)
# - [4. Extract their respective Tag Counts](#1.4)
# - [5. Put all code together and join the two lists](#1.5)
# - [6. Plot Data](#1.6)
# Let's import all the required libraries and packages
# In[1]:
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
import requests # Getting Webpage content
from bs4 import BeautifulSoup as bs # Scraping webpages
import matplotlib.pyplot as plt # Visualization
import matplotlib.style as style # For styling plots
from matplotlib import pyplot as mp # For Saving plots as images
# For displaying plots in jupyter notebook
get_ipython().run_line_magic('matplotlib', 'inline')
style.use('fivethirtyeight') # matplotlib Style
# ### Downloading Tags page from StackOverflow
#
# We will download the [tags page](https://stackoverflow.com/tags) from [stackoverflow](https://stackoverflow.com/), where it has all the languages listed with their tag count.
# In[2]:
# Using requests module for downloading webpage content
response = requests.get('https://stackoverflow.com/tags')
# Getting status of the request
# 200 status code means our request was successful
# 404 status code means that the resource you were looking for was not found
response.status_code
# ### Parsing the document into Beautiful Soup
# In[3]:
# Parsing html data using BeautifulSoup
soup = bs(response.content, 'html.parser')
# body
body = soup.find('body')
# printing the object type of body
type(body)
# ### Extract Top Languages
#
# In order to acheive this, we need to understand HTML structure of the document that we have. And then, narrow down to our element of interest.
#
#
# One way of doing this would be manually searching the webpage (hint: print `body` variable from above and search through it).
# Second method, is to use the browser's Developr Tools.
#
# We will use this second one. On Chrome, open [tags page](http://stackoverflow.com/tags?tab=popular) and right-click on the language name (shown in top left) and choose **Inspect**.
#
# 
# *Image for Reference*
# We can see that the Language name is inside `a` tag, which in turn is inside a lot of div tags. This seems, difficult to extract. Here, the [class](#classes) and [id](#id), we spoke about earlier comes to our rescue.
#
# If we look more closely in the image above, we can see that the `a` tag has a class of `post-tag`. Using this class along with `a` tag, we can extract all the language links in a list.
# In[4]:
lang_tags = body.find_all('a', class_='post-tag')
lang_tags[:2]
# Next, using [list comprehension](https://towardsdatascience.com/python-basics-list-comprehensions-631278f22c40), we will extract all the language names.
# In[5]:
languages = [i.text for i in lang_tags]
languages[:5]
# ### Extract Tag Counts
#
# To extract tag counts, we will follow the same process.
#
# On Chrome, open [tags page](http://stackoverflow.com/tags) and right-click on the tag count, next to the top language (shown in top left) and choose **Inspect**.
#
# 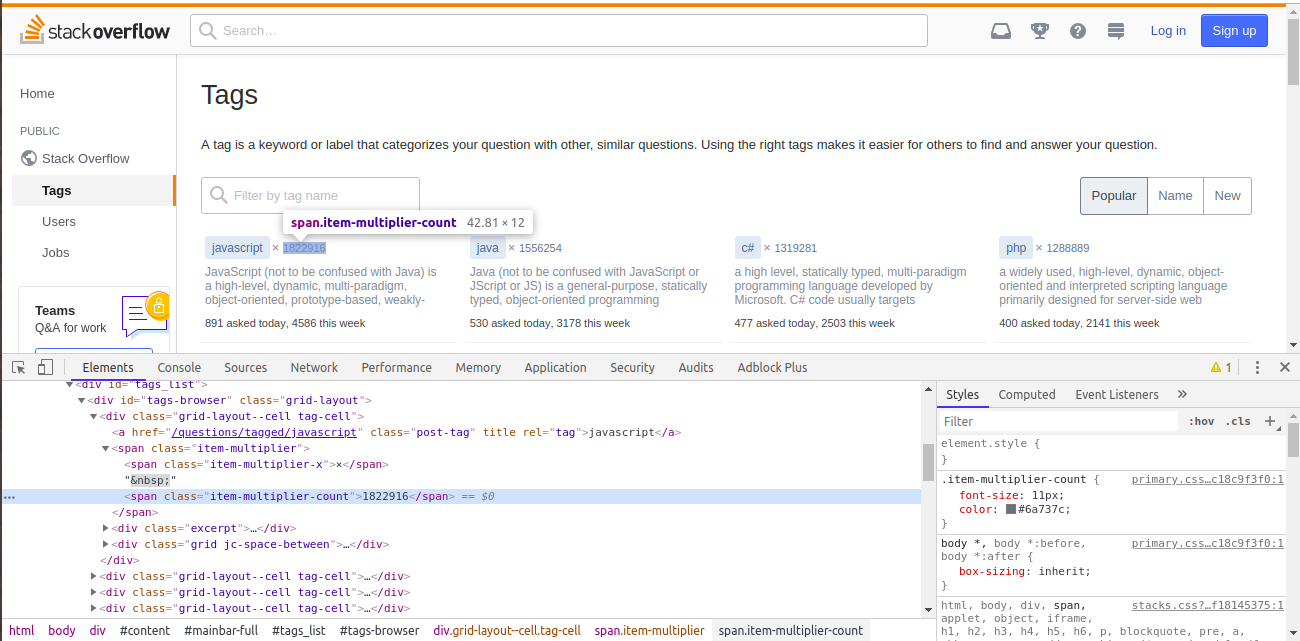
# *Image for Reference*
# Here, the tag counts are inside `span` tag, with a class of `item-multiplier-count`. Using this class along with `span` tag, we will extract all the tag count spans in a list.
# In[6]:
tag_counts = body.find_all('span', class_='item-multiplier-count')
tag_counts[:2]
# Next, using [list comprehension](https://towardsdatascience.com/python-basics-list-comprehensions-631278f22c40), we will extract all the Tag Counts.
# In[7]:
no_of_tags = [int(i.text) for i in tag_counts]
no_of_tags[:5]
# ### Put all code together and join the two lists
#
# We will use [Pandas.DataFrame](https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.html) to put the two lists together.
In order to make a DataFrame, we need to pass both the lists (in dictionary form) as argument to our function.
# In[8]:
# Function to check, if there is any error in length of the extracted bs4 object
def error_checking(list_name, length):
if (len(list_name) != length):
print("Error in {} parsing, length not equal to {}!!!".format(list_name, length))
return -1
else:
pass
def get_top_languages(url):
# Using requests module for downloading webpage content
response = requests.get(url)
# Parsing html data using BeautifulSoup
soup = bs(response.content, 'html.parser')
body = soup.find('body')
# Extracting Top Langauges
lang_tags = body.find_all('a', class_='post-tag')
error_checking(lang_tags, 36) # Error Checking
languages = [i.text for i in lang_tags] # Languages List
# Extracting Tag Counts
tag_counts = body.find_all('span', class_='item-multiplier-count')
error_checking(tag_counts, 36) # Error Checking
no_of_tags = [int(i.text) for i in tag_counts] # Tag Counts List
# Putting the two lists together
df = pd.DataFrame({'Languages':languages,
'Tag Count':no_of_tags})
return df
# ### Plot Data
# In[9]:
URL1 = 'https://stackoverflow.com/tags'
df = get_top_languages(URL1)
df.head()
# Now, we will plot the Top Languages along with their Tag Counts.
# In[10]:
plt.figure(figsize=(8, 3))
plt.bar(height=df['Tag Count'][:10], x=df['Languages'][:10])
plt.xticks(rotation=90)
plt.xlabel('Languages')
plt.ylabel('Tag Counts')
plt.savefig('lang_vs_tag_counts.png', bbox_inches='tight')
plt.show()
# # Goal 2: Listing most voted Questions
#
# Now that we have collected data using web scraping one time, it won't be difficult the next time.
# In Goal 2 part, we have to list questions with most votes along with their attributes, like:
# > - Summary
# - Tags
# - Number of Votes
# - Number of Answers
# - Number of Views
#
# I would suggest giving it a try on your own, then come here to see my solution.
#
# Similar to previous step, we will make a list of steps to act upon:
#
# - [1. Download Webpage from stackoverflow](#2.1)
# - [2. Parse the document content into BeautifulSoup](#2.2)
# - [3. Extract Top Questions](#2.3)
# - [4. Extract their respective Summary](#2.4)
# - [5. Extract their respective Tags](#2.5)
# - [6. Extract their respective no. of votes, answers and views](#2.6)
# - [7. Put all code togther and join the lists](#2.7)
# - [8. Plot Data](#2.8)
# ### Downloading Questions page from StackOverflow
#
# We will download the [questions page](https://stackoverflow.com/questions?sort=votes&pagesize=50) from [stackoverflow](https://stackoverflow.com/), where it has all the top voted questions listed.
#
# Here, I've appended `?sort=votes&pagesize=50` to the end of the defualt questions URL, to get a list of top 50 questions.
# In[11]:
# Using requests module for downloading webpage content
response1 = requests.get('https://stackoverflow.com/questions?sort=votes&pagesize=50')
# Getting status of the request
# 200 status code means our request was successful
# 404 status code means that the resource you were looking for was not found
response1.status_code
# ### A different Scraping Function
#
# In this section, we will use `select()` and `select_one()` to return BeautifulSoup objects as per our requierment. While `find_all` uses tags, `select` uses CSS Selectors in the filter. I personally tend to use the latter one more.
#
# For example:
# - `p a` — finds all a tags inside of a p tag.
# > ```soup.select('p a')```
#
# - `div.outer-text` — finds all div tags with a class of outer-text.
# - `div#first` — finds all div tags with an id of first.
# - `body p.outer-text` — finds any p tags with a class of outer-text inside of a body tag.
# ### Parsing the document into Beautiful Soup
# In[12]:
# Parsing html data using BeautifulSoup
soup1 = bs(response1.content, 'html.parser')
# body
body1 = soup1.select_one('body')
# printing the object type of body
type(body1)
# ### Extract Top Questions
#
# On Chrome, open [questions page](https://stackoverflow.com/questions?sort=votes&pagesize=50) and right-click on the top question and choose **Inspect**.
#
# 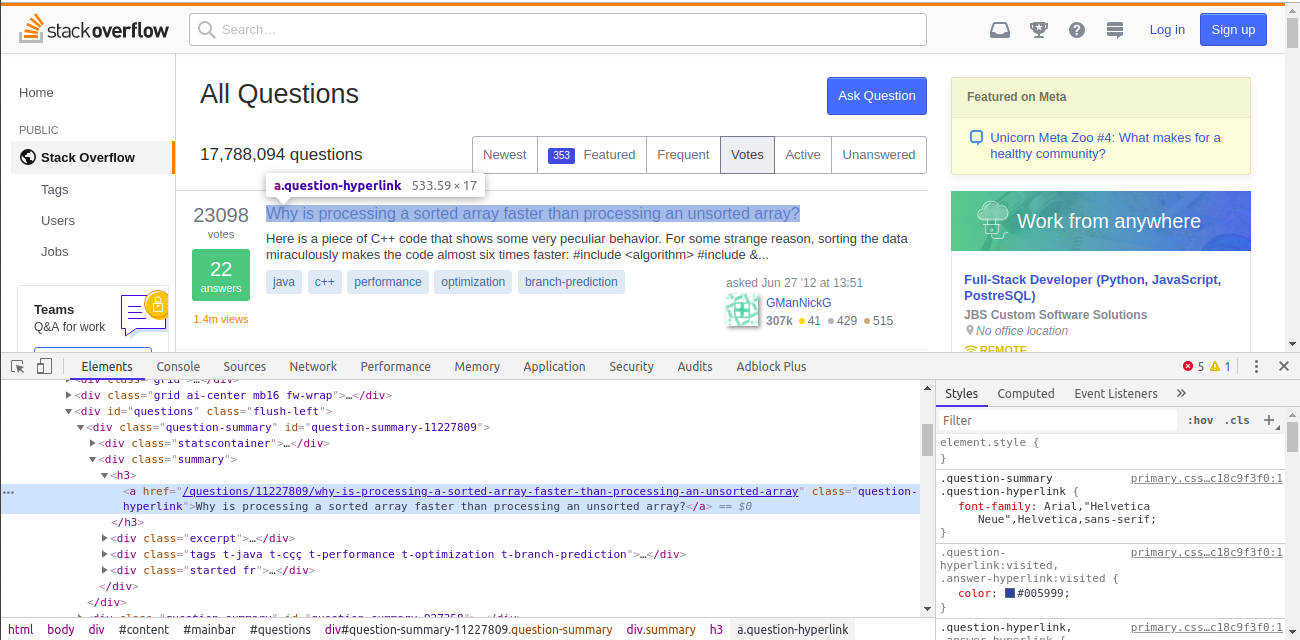
# *Image for Reference*
# We can see that the question is inside `a` tag, which has a class of `question-hyperlink`.
#
# Taking cue from our previous Goal, we can use this class along with `a` tag, to extract all the question links in a list. However, there are more question hyperlinks in sidebar which will also be extracted in this case. To avoid this scenario, we can combine `a` tag, `question-hyperlink` class with their parent `h3` tag. This will give us exactly 50 Tags.
# In[13]:
question_links = body1.select("h3 a.question-hyperlink")
question_links[:2]
# [List comprehension](https://towardsdatascience.com/python-basics-list-comprehensions-631278f22c40), to extract all the questions.
# In[14]:
questions = [i.text for i in question_links]
questions[:2]
# ### Extract Summary
#
# On Chrome, open [questions page](https://stackoverflow.com/questions?sort=votes&pagesize=50) and right-click on summary of the top question and choose **Inspect**.
#
# 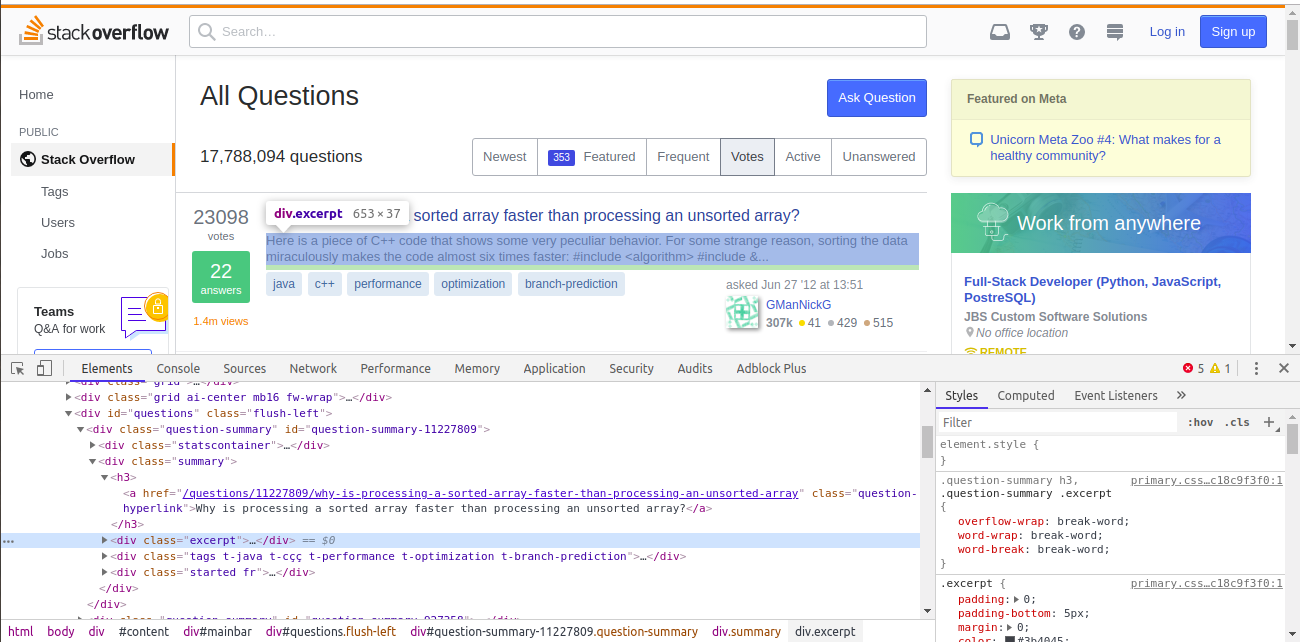
# *Image for Reference*
# We can see that the question is inside `div` tag, which has a class of `excerpt`. Using this class along with `div` tag, we can extract all the question links in a list.
# In[15]:
summary_divs = body1.select("div.excerpt")
print(summary_divs[0])
# [List comprehension](https://towardsdatascience.com/python-basics-list-comprehensions-631278f22c40), to extract all the questions.
#
# Here, we will also use [strip()](https://www.programiz.com/python-programming/methods/string/strip) method on each div's text. This is to remove both leading and trailing unwanted characters from a string.
# In[16]:
summaries = [i.text.strip() for i in summary_divs]
summaries[0]
# ### Extract Tags
#
# On Chrome, open [questions page](https://stackoverflow.com/questions?sort=votes&pagesize=50) and right-click on summary of the top question and choose **Inspect**.
#
# 
# *Image for Reference*
# Extracting **tags per question** is the most complex task in this post. Here, we cannot find unique class or id for each tag, and there are multiple tags per question that we n
# eed to store.
#
# To extract **tags per question**, we will follow a multi-step process:
#
# * As shown in figure, individual tags are in a third layer, under two nested div tags. With the upper div tag, only having unique class (`summary`).
# - First, we will extract div with `summary`class.
# - Now notice our target div is third child overall and second `div` child of the above extracted object. Here, we can use `nth-of-type()` method to extract this 2nd `div` child. Usage of this method is very easy and few exmaples can be found [here](https://gist.github.com/yoki/b7f2fcef64c893e307c4c59303ead19a#file-20_search-py). This method will extract the 2nd `div` child directly, without extracting `summary div` first.
# In[17]:
tags_divs = body1.select("div.summary > div:nth-of-type(2)")
tags_divs[0]
# * Now, we can use [list comprehension](https://towardsdatascience.com/python-basics-list-comprehensions-631278f22c40) to extract `a` tags in a list, grouped per question.
# In[18]:
a_tags_list = [i.select('a') for i in tags_divs]
# Printing first question's a tags
a_tags_list[0]
# * Now we will run a for loop for going through each question and use [list comprehension](https://towardsdatascience.com/python-basics-list-comprehensions-631278f22c40) inside it, to extract the tags names.
# In[19]:
tags = []
for a_group in a_tags_list:
tags.append([a.text for a in a_group])
tags[0]
# ### Extract Number of votes, answers and views
#
# On Chrome, open [questions page](https://stackoverflow.com/questions?sort=votes&pagesize=50) and inspect vote, answers and views for the topmost answer.
#
# 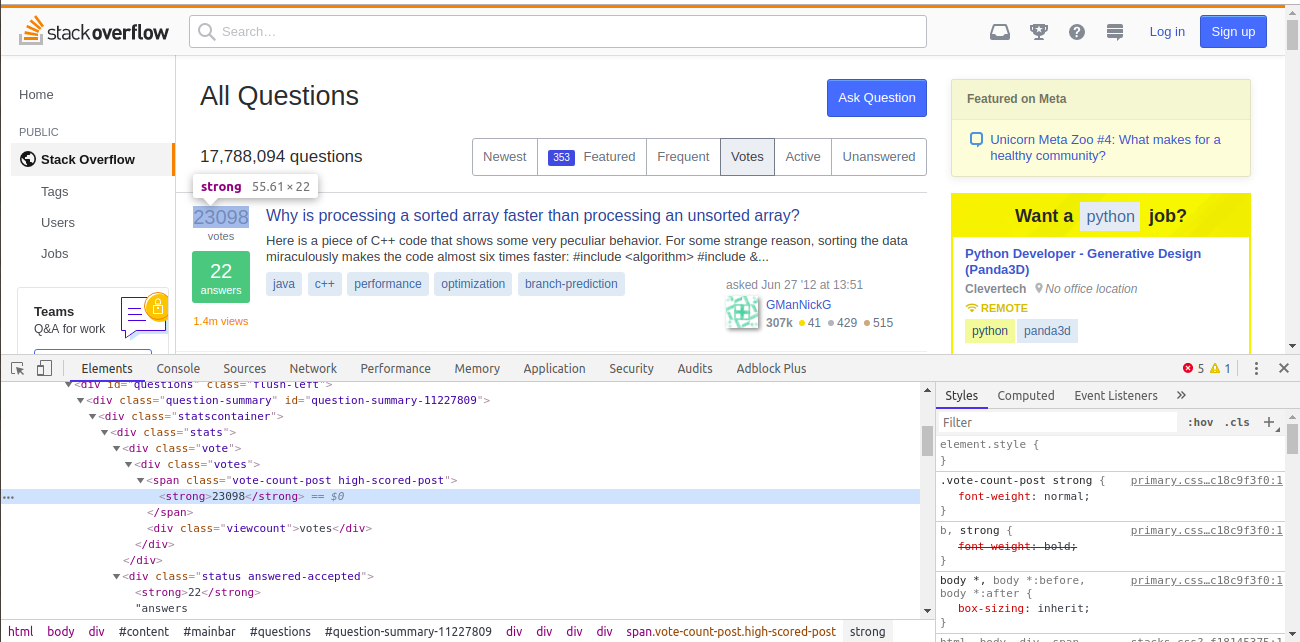
# *Image for Reference*
# ### No. of Votes
# - They can be found by using `span` tag along with `vote-count-post` class and nested `strong` tags
# In[20]:
vote_spans = body1.select("span.vote-count-post strong")
print(vote_spans[:2])
# [List comprehension](https://towardsdatascience.com/python-basics-list-comprehensions-631278f22c40), to extract vote counts.
# In[21]:
no_of_votes = [int(i.text) for i in vote_spans]
no_of_votes[:5]
# I'm not going to post images to extract last two attributes
#
# ### No. of Answers
#
# - They can be found by using `div` tag along with `status` class and nested `strong` tags. Here, we don't use `answered-accepted` because its not common among all questions, few of them (whose answer are not accepted) have the class - `answered`.
# In[22]:
answer_divs = body1.select("div.status strong")
answer_divs[:2]
# [List comprehension](https://towardsdatascience.com/python-basics-list-comprehensions-631278f22c40), to extract answer counts.
# In[23]:
no_of_answers = [int(i.text) for i in answer_divs]
no_of_answers[:5]
# ### No. of Views
# - For views, we can see two options. One is short form in number of millions and other is full number of views. We will extract the full version.
# - They can be found by using `div` tag along with `supernova` class. Then we need to clean the string and convert it into integer format.
# In[24]:
div_views = body1.select("div.supernova")
div_views[0]
# [List comprehension](https://towardsdatascience.com/python-basics-list-comprehensions-631278f22c40), to extract vote counts.
# In[25]:
no_of_views = [i['title'] for i in div_views]
no_of_views = [i[:-6].replace(',', '') for i in no_of_views]
no_of_views = [int(i) for i in no_of_views]
no_of_views[:5]
# ### Putting all of them together in a dataframe
# In[26]:
def get_top_questions(url, question_count):
# WARNING: Only enter one of these 3 values [15, 30, 50].
# Since, stackoverflow, doesn't display any other size questions list
url = url + "?sort=votes&pagesize={}".format(question_count)
# Using requests module for downloading webpage content
response = requests.get(url)
# Parsing html data using BeautifulSoup
soup = bs(response.content, 'html.parser')
body = soup.find('body')
# Extracting Top Questions
question_links = body1.select("h3 a.question-hyperlink")
error_checking(question_links, question_count) # Error Checking
questions = [i.text for i in question_links] # questions list
# Extracting Summary
summary_divs = body1.select("div.excerpt")
error_checking(summary_divs, question_count) # Error Checking
summaries = [i.text.strip() for i in summary_divs] # summaries list
# Extracting Tags
tags_divs = body1.select("div.summary > div:nth-of-type(2)")
error_checking(tags_divs, question_count) # Error Checking
a_tags_list = [i.select('a') for i in tags_divs] # tag links
tags = []
for a_group in a_tags_list:
tags.append([a.text for a in a_group]) # tags list
# Extracting Number of votes
vote_spans = body1.select("span.vote-count-post strong")
error_checking(vote_spans, question_count) # Error Checking
no_of_votes = [int(i.text) for i in vote_spans] # votes list
# Extracting Number of answers
answer_divs = body1.select("div.status strong")
error_checking(answer_divs, question_count) # Error Checking
no_of_answers = [int(i.text) for i in answer_divs] # answers list
# Extracting Number of views
div_views = body1.select("div.supernova")
error_checking(div_views, question_count) # Error Checking
no_of_views = [i['title'] for i in div_views]
no_of_views = [i[:-6].replace(',', '') for i in no_of_views]
no_of_views = [int(i) for i in no_of_views] # views list
# Putting all of them together
df = pd.DataFrame({'question': questions,
'summary': summaries,
'tags': tags,
'no_of_votes': no_of_votes,
'no_of_answers': no_of_answers,
'no_of_views': no_of_views})
return df
# ### Plotting Votes v/s Views v/s Answers
# In[27]:
URL2 = 'https://stackoverflow.com/questions'
df1 = get_top_questions(URL2, 50)
df1.head()
# In[29]:
f, ax = plt.subplots(3, 1, figsize=(12, 8))
ax[0].bar(df1.index, df1.no_of_votes)
ax[0].set_ylabel('No of Votes')
ax[1].bar(df1.index, df1.no_of_views)
ax[1].set_ylabel('No of Views')
ax[2].bar(df1.index, df1.no_of_answers)
ax[2].set_ylabel('No of Answers')
plt.xlabel('Question Number')
plt.savefig('votes_vs_views_vs_answers.png', bbox_inches='tight')
plt.show()
# Here, we may observe that there is no collinearity between the votes, views and answers related to a question.
# Useful Resources:
# - [Dataquest Tutorial 1](https://www.dataquest.io/blog/web-scraping-tutorial-python/), [2](https://www.dataquest.io/blog/web-scraping-beautifulsoup/)
# - [HackerNoon Tutorial](https://hackernoon.com/building-a-web-scraper-from-start-to-finish-bb6b95388184)
# - [RealPython Tutorial](https://realpython.com/python-web-scraping-practical-introduction/)