#!/usr/bin/env python
# coding: utf-8
# # Divvy Data Analysis
# **View on:** [nbviewer](https://nbviewer.jupyter.org/github/chrisluedtke/divvy-data-analysis/blob/master/notebook.ipynb), [Google Colab](https://colab.research.google.com/github/chrisluedtke/divvy-data-analysis/blob/master/notebook.ipynb)
#
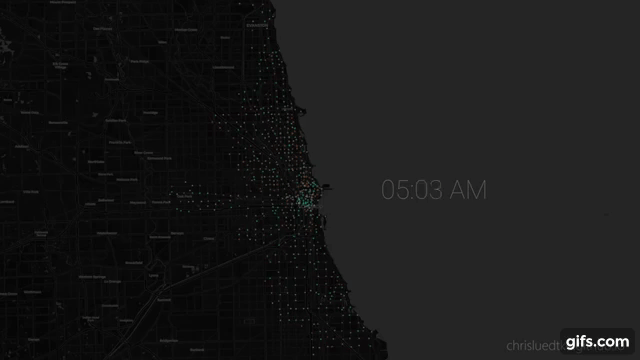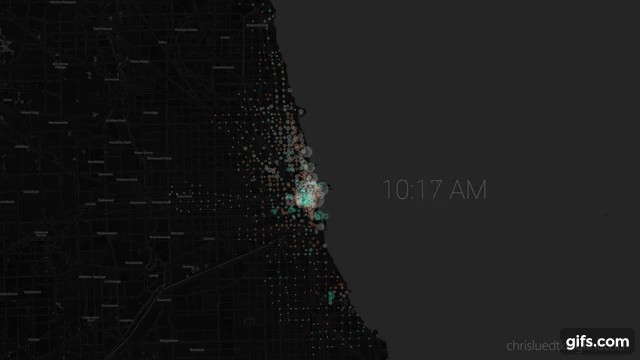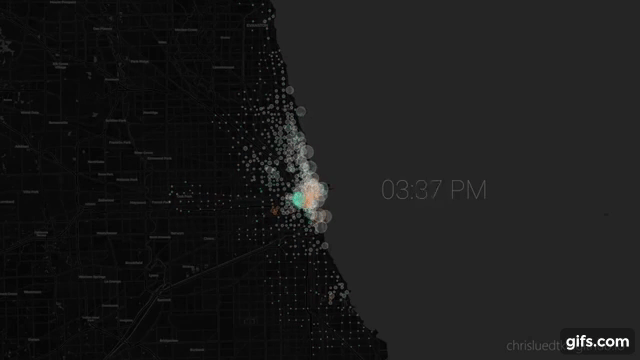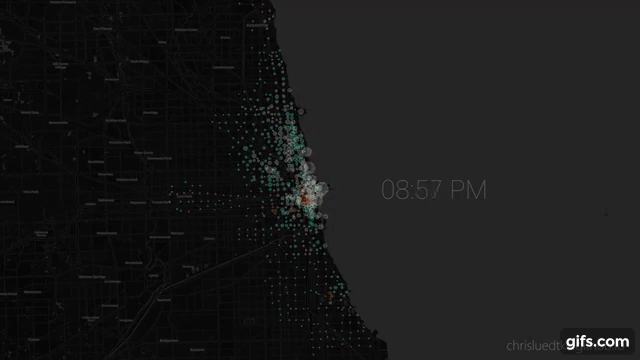
# 
# View on YouTube
#
# **Contents**
# * [Data-Sourcing](#Data-Sourcing)
# * [Exploration](#Exploration)
# * [Merge-Station-Coordinates](#Merge-Station-Coordinates)
# * [Farthest-Ridden-Bike](#Farthest-Ridden-Bike)
# * [Calculate-Distances](#Calculate-Distances)
# * [Exploration-with-Distance](#Exploration-with-Distance)
# * [Check-Daylight-Savings](#Check-Daylight-Savings)
# * [Animated-Plot](#Animated-Plot)
# * [Perception-of-Circle-Size](#Perception-of-Circle-Size)
# * [Dualmap](http://localhost:8889/notebooks/GitHub/divvy-data-analysis/notebook.ipynb#Dualmap)
# In[1]:
import os
get_ipython().run_line_magic('matplotlib', 'inline')
import folium
import folium.plugins
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import seaborn as sns
import divvydata
from nb_utils.colors import linear_gradient, polylinear_gradient
from nb_utils.data_processing import my_melt, add_empty_rows
from nb_utils.geospatial import haversine
from nb_utils.mapping import (create_map, gen_maps_by_group,
render_html_map_to_png)
pd.options.display.max_columns = None
plt.style.use('seaborn')
sns.set_context('talk', rc={'figure.figsize':(10, 7)})
# ## Data Sourcing
# Data from: https://www.divvybikes.com/system-data
# In[2]:
help(divvydata.get_historical_data)
# In[3]:
help(divvydata.StationsFeed)
# In[16]:
# rides, stations = divvydata.get_historical_data(
# years=[str(yr) for yr in range(2013,2019)],
# rides=True,
# stations=True
# )
# In[15]:
# rides.to_pickle('data/rides.pkl')
# stations.to_pickle('data/stations.pkl')
# In[8]:
rides = pd.read_pickle('data/rides.pkl')
# drop unused cols to save space
rides = rides.drop(columns=['from_station_name', 'to_station_name'])
print(rides.shape)
rides.head()
# In[9]:
stations = pd.read_pickle('data/stations.pkl')
stations = stations.rename(columns={'latitude':'lat', 'longitude':'lon'})
print(stations.shape)
stations.head()
# ## Exploration
# In[7]:
rides.isna().sum()
# In[11]:
# How many times has each bike been ridden?
bike_use = rides['bikeid'].value_counts()
print(bike_use.describe().to_string())
sns.distplot(bike_use)
plt.title('Rides per Bike');
# In[12]:
# Count of bikes released per month
frst_use = (rides.groupby('bikeid')['start_time'].min()
.dt.to_period("Q")
.rename('first_use_quarter'))
quarterly_counts = frst_use.value_counts()
all_dates = pd.date_range(start=rides.start_time.min().date(),
end=rides.start_time.max().date(),
freq='Q').to_period("Q")
all_dates = pd.Series(index=all_dates,
data=0)
all_dates.update(quarterly_counts)
all_dates.plot(kind='bar', width=1,
title='Bikes released per month');
# In[13]:
# # color bike usage by quarter first ridden
# bike_use_q = rides[['bikeid']].merge(frst_use, left_on='bikeid',
# right_index=True, how='left')
# bike_use_q = bike_use_q.sort_values('first_use_quarter')
# top8_qs = frst_use.value_counts().index[:8]
# bike_use_q = bike_use_q.loc[bike_use_q['first_use_quarter'].isin(top8_qs)]
# bike_use_grpd = bike_use_q.groupby('first_use_quarter')
# for group_name, group_df in bike_use_grpd:
# group_df = group_df['bikeid'].value_counts()
# sns.distplot(group_df)
# plt.xlim([0, 5000])
# plt.title(f'{group_name} bikes')
# plt.show();
# In[14]:
# Count of quarterly rides
(rides['start_time'].groupby([rides.start_time.dt.to_period("Q")])
.count()
.plot.bar(width=1));
# In[15]:
print('Trip Duration (Minutes)')
print(rides.tripduration.divide(60).describe().to_string())
sns.distplot(rides.loc[rides.tripduration <
rides.tripduration.quantile(.95),
'tripduration'].divide(60))
plt.title('Trip Duration (Minutes)');
# In[19]:
rides.tripduration.sum() / 60 / 60 / 24 / 365 #years
# In[20]:
sum_duration_bike = (rides.groupby('bikeid')['tripduration'].sum()
.divide(60).divide(60))
print('Bike Use (Hours)')
print(sum_duration_bike.describe().to_string())
# ## Merge Station Coordinates
# In[4]:
# Stations have moved
(stations.drop_duplicates(['id', 'lat', 'lon'])['id']
.value_counts()
.plot.hist(title='Station Instances'));
# Unfortunately, Divvy kept the same station ID while physically moving those stations around. This adds a lot of complexity to route analysis.
#
# One solution would be to round lat/lon coordinates to some [degree of precision](https://en.wikipedia.org/wiki/Decimal_degrees#Precision), and then remove duplicates on rounded position. While that may seem to reduce the problem, there would be no way to determine whether a station initially at position A, moved to position B, and then back to position A.
#
# Another approach is to calculate the rolling difference of lat/lon coordinates and filter out differences below a desired precision. Let's do that.
# In[5]:
fix_stns = stations.copy()
fix_stns = fix_stns.sort_values(['id', 'as_of_date'])
fix_stns['dist_m'] = np.concatenate(
fix_stns.groupby('id')
.apply(lambda x: haversine(
x['lat'].values, x['lon'].values,
x['lat'].shift().values, x['lon'].shift().values)).values
)
# In[6]:
# NaNs are first instance, so keep those
mask = fix_stns.dist_m.isna() | (fix_stns.dist_m > 30)
fix_stns.loc[mask, 'id'].value_counts().plot(kind='hist', title='Reduced Station Instances');
# We can assess the problem by plotting stations that have moved:
# In[7]:
df = fix_stns.loc[fix_stns.id.duplicated(keep=False)]
m = folium.Map(location=[df.lat.mean(),
df.lon.mean()],
tiles='CartoDB dark_matter',
zoom_start=12)
for g_k, g_df in df.groupby('id'):
total_dist = g_df.dist_m.sum()
if total_dist < 10:
continue
text = (f"Station {g_df.id.values[0]}
"
f"{int(total_dist)} m")
folium.PolyLine(
locations=list(zip(g_df.lat, g_df.lon)),
tooltip=text, color="#E37222", weight=3
).add_to(m)
folium.plugins.Fullscreen(
position='topright',
force_separate_button=True
).add_to(m)
m.save('maps/stations_moved.html')
m
# In[10]:
rides['end_date'] = rides['end_time'].dt.date
day_aggs = (rides.groupby(['to_station_id', 'end_date'])
.agg({'from_station_id':'median',
'tripduration':'mean',
'end_time':'count'})
.rename(columns={'from_station_id':'trip_origin_median',
'tripduration':'trip_duration_mean',
'end_time':'trip_counts'}))
# In[11]:
stn_id = 414
min_date, max_date = '2015-12-31', '2016-06-30'
grouped = fix_stns.groupby('id')
cols = ['as_of_date', 'dist_m', 'lat', 'lon']
print(grouped.get_group(stn_id)[cols].to_string(index=False))
stn_aggs = day_aggs.loc[stn_id]
dates = pd.DataFrame(data={k:0 for k in stn_aggs},
index=pd.date_range(min_date, max_date))
dates.update(stn_aggs)
for col in ['trip_duration_mean', 'trip_counts']:
plt.bar(x=dates.index, height=dates[col])
plt.xlim(min_date, max_date)
plt.title(col)
plt.show();
# #### TODO
# * subtract daily average of all active stations
# * pick a few nearby stations -- should observe that durations change after a move
# * monitor the set of station origins, should change
#
# From here I would create a lookup table for stations that have moved. The rows would span each day the station was active, and I would merge with my `rides` table on a `ride_id_date` key.
#
# But for now, I'll average each duplicated station's lat/lon positions to make things easy.
# In[8]:
stations = (fix_stns.groupby('id')['lat', 'lon'].mean())
# In[9]:
# Merge Station Coordinates
rides = (rides.merge(stations.rename(columns={'lat':'from_lat',
'lon':'from_lon'}),
left_on='from_station_id', right_index=True,
how='left')
.merge(stations.rename(columns={'lat':'to_lat',
'lon':'to_lon'}),
left_on='to_station_id', right_index=True,
how='left'))
# ## Calculate Distances
# In[11]:
rides['dist'] = haversine(rides.from_lat, rides.from_lon,
rides.to_lat, rides.to_lon)
# In[12]:
rides['taxi_dist'] = (haversine(rides.from_lat, rides.from_lon,
rides.from_lat, rides.to_lon) +
haversine(rides.to_lat, rides.to_lon,
rides.from_lat, rides.to_lon))
# In[32]:
# rides.to_pickle('data/rides_with_dist.pkl')
# ## Exploration with Distance
# In[12]:
rides = pd.read_pickle('data/rides_with_dist.pkl')
# In[13]:
rides[['dist', 'taxi_dist']].divide(1000).describe()
# In[14]:
sum_dist = rides.dist.sum()
m_to_moon = 384401000
print(round(sum_dist / m_to_moon / 2, 1), 'trips to the moon and back')
# In[15]:
(rides.dist.loc[(1 < rides.dist) &
(rides.dist < rides.dist.quantile(.99))]
.divide(1000)
.plot.hist(bins=100, title='Distance per Ride (kilometers)'));
# In[16]:
# sum distance ridden, km
dist_sum = rides.groupby('bikeid')['dist'].sum().divide(1000)
dist_sum.plot.hist(bins=100, title='Distance ridden per bike (kilometers)');
# In[17]:
print(dist_sum.sort_values(ascending=False).head().to_string())
# ## Farthest Ridden Bike
# In[3]:
rides = pd.read_pickle('data/rides_with_dist.pkl')
# In[18]:
# Path of the farthest ridden bike
df = (rides.loc[(rides.bikeid==410)]
.sort_values('start_time'))
df['start_q'] = df.start_time.dt.to_period("Q").astype(str)
# In[21]:
date_range = (pd.date_range(df['start_time'].min().date(),
df['start_time'].max().date())
.to_period("Q").astype(str).unique())
colors = [
'#fe0000', #red
'#fdfe02', #yellow
'#011efe', #blue
]
gradient = polylinear_gradient(colors, len(date_range))
date_colors = pd.Series(index=date_range, data=gradient, name='date_color')
df = df.merge(date_colors, left_on='start_q', right_index=True, how='left')
# In[27]:
m = folium.Map(location=[df.from_lat.mean(),
df.from_lon.mean()],
tiles='CartoDB dark_matter',
zoom_start=13)
for q_group, q_df in df.groupby('start_q'):
points = []
from_locs = list(zip(q_df.from_lat, q_df.from_lon))
to_locs = list(zip(q_df.to_lat, q_df.to_lon))
for from_i, to_i, in zip(from_locs, to_locs):
points.append(from_i)
points.append(to_i)
folium.PolyLine(
points,
weight=1,
color=q_df.date_color.values[0],
tooltip=q_group.replace('Q', ' Q')
).add_to(m)
folium.plugins.Fullscreen(
position='topright',
force_separate_button=True
).add_to(m)
m.save('maps/longest_ridden_rainbow.html')
m
# ## Check Daylight Savings
#
# The time component of my analysis is very important. If DST were a problem, a large number of rows could be +/- 1 hour off.
#
# Sanity check:
# In[ ]:
rides = pd.read_pickle('data/rides_with_dist.pkl')
# In[50]:
dst_start = { # clock 1:59AM to 3:00AM
'2013':'03-10',
'2014':'03-09',
'2015':'03-08',
'2016':'03-13',
'2017':'03-12',
'2018':'03-11',
}
for yy, mm_dd in dst_start.items():
uh_oh = rides.loc[(f'{yy}-{mm_dd} 01:59:59' < rides['start_time']) &
(rides['start_time'] < f'{yy}-{mm_dd} 03:00:00')]
if not uh_oh.empty:
print(uh_oh)
# In[52]:
# DST End, clock 1:59AM to 1:00AM
rides.loc[(rides.end_time < rides.start_time),
['start_time', 'end_time', 'tripduration']]
# ## Animated Plot
#
# Seeking animated plot where:
# * circles positioned at stations
# * **size** represents station usage
# * **color** represents type of use (gaining bikes or losing bikes).
# In[ ]:
rides = pd.read_pickle('data/rides_with_dist.pkl')
# In[39]:
# subsample to get a working flow before applying to large dataset
# rides = rides.sample(10000)
# In[40]:
# reshape DataFrame from 'ride' orientation to 'station interaction' orientation
rides[['from_station_id', 'start_time',
'to_station_id', 'end_time']].head()
# In[41]:
stn_agg = my_melt(rides)
# In[42]:
stn_agg.head()
# In[43]:
# actually 'half hour'
stn_agg['hour'] = (stn_agg.time.dt.hour +
stn_agg.time.dt.minute // 30 * 0.5)
# stn_agg['dow'] = stn_agg.time.dt.dayofweek
stn_agg['month'] = stn_agg.time.dt.to_period('M')
# Here I assume if the station was used any time in a month,
# then it was active/available for that entire month
stn_days = (stn_agg.groupby('station_id')['month']
.nunique()
.multiply(30)
.rename('days_active'))
# pivot to get arrival and departure count columns
id_cols = ['station_id', 'lat', 'lon', 'hour']
stn_agg = (stn_agg.pivot_table(index=id_cols, columns='type',
aggfunc='size', fill_value=0)
.reset_index()
.merge(stn_days, left_on='station_id',
right_index=True))
stn_agg['total_use'] = stn_agg.arrival + stn_agg.departure
stn_agg['avg_use'] = stn_agg.total_use.divide(stn_agg.days_active, fill_value=0)
stn_agg['pt_departures'] = stn_agg.departure.divide(stn_agg.total_use, fill_value=0.5)
# stn_agg.to_pickle('data/station_aggregates.pkl')
# In[3]:
stn_agg = pd.read_pickle('data/station_aggregates.pkl')
# In[5]:
stn_agg.head()
# In[6]:
## sanity checks
# (set(rides.to_station_id) | set(rides.from_station_id)) - set(stn_agg.station_id)
# (set(rides.to_station_id) | set(rides.from_station_id)) - set(stations.index)
# In[7]:
stn_agg.pt_departures.plot.hist(bins=50, title='dot color range');
# In[8]:
stn_agg.avg_use.plot.hist(bins=50, title='dot size range');
# ### Perception of Circle Size
#
# If we directly map the radius of each station dot to the average use of the station, a dot of radius 2 will appear non-linearly larger than a dot of radius 1. However, if we set the **area** of the dot to the average use, I would argue that the average user would not perceive the the second dot as twice as large as the first. I could not find any empirical discussion on this.
#
# https://eagereyes.org/blog/2008/linear-vs-quadratic-change
#
# In my tests, a circle radius 60 is about the largest I would like a cirlce to appear, otherwise it obscures other information.
# In[9]:
def radius(x):
'''radius when radius defined by station interactions'''
return x * 2.19
def area(x):
'''radius when area defined by station interactions'''
return ((x / np.pi) ** (1/2)) * 20
def between(x):
return x ** (58/100) * 8.7
x_vals = np.linspace(0, 27, 100)
plots = pd.DataFrame({'x_vals':x_vals,
'radius': [radius(x) for x in x_vals],
'area': [area(x) for x in x_vals],
'between': [between(x) for x in x_vals]})
plots.plot.line(x='x_vals', xlim=(0,27), ylim=(0,60))
plt.xlabel('N Station Interactions')
plt.ylabel('Circle Radius on Plot');
# In[10]:
stn_agg.loc[stn_agg.station_id==664].head()
# In[11]:
def expand_and_interpolate(df):
# expand by every half hour and fill with zeros
steps = 24 * 2
hours = pd.Series(np.linspace(0, 24, steps, endpoint=False),
index=[1]*steps, name='hour')
df = add_empty_rows(df=stn_agg, fill_series=hours,
constants=['station_id', 'lat','lon', 'days_active'])
df['pt_departures'] = df['pt_departures'].fillna(0.50)
df = df.fillna(0)
# expand by every 2 minutes and fill with interpolation
steps = 24 * 2 * 15
hours = pd.Series(np.linspace(0, 24, steps, endpoint=False).round(3),
index=[1]*steps, name='hour')
df = add_empty_rows(df=df, fill_series=hours,
constants=['station_id', 'lat','lon', 'days_active'])
# add hour 24 that matches hour 0
df = (df.append(df.loc[df['hour']==df['hour'].min()]
.assign(hour=24))
.sort_values(['station_id', 'hour']))
df[['avg_use', 'pt_departures']] = df[['avg_use', 'pt_departures']].interpolate()
return df
def get_percent_depart_gradient():
# Generate color gradient for each percentage pt_departures
strt_color = "#18f0da" #blue, gathering bikes
mid_color = "#e6e6e6" #gray
end_color = "#f06e18" #orange, "radiating" bikes
start_pos = 25
mid_width = 5
steps = int((100 - start_pos * 2 - mid_width) / 2) + 1
color_list = ([strt_color] * start_pos +
linear_gradient(strt_color, mid_color, steps) +
[mid_color] * mid_width +
linear_gradient(mid_color, end_color, steps) +
[end_color] * start_pos)
gradient = pd.Series(data=color_list,
index=np.linspace(0, 1, 101, endpoint=True).round(2),
name='color')
return gradient
# In[12]:
stn_agg_interp = expand_and_interpolate(df=stn_agg)
gradient = get_percent_depart_gradient()
stn_agg_interp['pt_departures_rd'] = stn_agg_interp['pt_departures'].round(2)
stn_agg_interp = (stn_agg_interp.drop(columns='color', errors='ignore')
.merge(gradient, left_on='pt_departures_rd',
right_index=True, how='left'))
stn_agg_interp['radius'] = stn_agg_interp.avg_use.apply(between)
# In[15]:
get_ipython().run_line_magic('pinfo2', 'create_map')
# In[38]:
create_map(stn_agg_interp.loc[stn_agg_interp.hour==17])
# In[39]:
gen_maps_by_group(stn_agg_interp, group_label='hour', height_px=1350,
width_px=int(1350*1.777), preview=True)
# From here I use `gen_maps_by_group` to generate `.html` maps for each frame of the animation, then `render_maps_dir_to_pngs` to iterate over the maps to `.png`.
# In[ ]:
maps_dir = os.path.join(os.getcwd(), 'maps')
output_dir = os.path.join(os.getcwd(), 'maps/pngs')
# In[44]:
help(render_html_map_to_png)
# ## Dualmap
# In[40]:
def add_to_dualmap(df, m, add_to):
for i, r in df.iterrows():
if r.avg_use < 0.01:
continue
popup_txt=(f'Station {r.station_id}
'
f'Avg Uses: {round(r.avg_use,1)}
'
f'Departures: {round(r.pt_departures*100)}%')
folium.CircleMarker(
location=(r.lat, r.lon),
radius=r.radius,
color=r['color'],
weight=0.5,
popup=folium.Popup(popup_txt, max_width=500),
fill=True).add_to(add_to)
return m
m = folium.plugins.DualMap(
location=(41.89, -87.63),
tiles="CartoDB dark_matter",
zoom_start=14)
m = add_to_dualmap(stn_agg_interp.loc[stn_agg_interp.hour==8],
m, m.m1)
m = add_to_dualmap(stn_agg_interp.loc[stn_agg_interp.hour==17],
m, m.m2)
m.save('maps/am_v_pm.html')
m