#!/usr/bin/env python
# coding: utf-8
# # Upload Trove newspaper articles to Omeka-S
#
# I was keen to play around with [Omeka-S](https://omeka.org/s/) – the new, Linked Open Data powered version of Omeka. In particular I wanted to understand its [API](https://omeka.org/s/docs/developer/key_concepts/api/), its use of [JSON-LD](https://json-ld.org/), and how I could create and use relationships between different types of entities. I decided that one way of exploring these things was to build a pipeline that would make it easy to upload Trove newspaper articles to an Omeka site. I recently figured out how to generate nice thumbnails from newspaper articles, so I could add images as well. But what about the 'Linked' part of LOD? I thought I'd not only create records for the newspaper articles, I'd create records for each cited newspaper and link them to the articles. Things not strings!
#
# Of course, this is not the only way to get Trove records into Omeka. You can save them to [Zotero](https://www.zotero.org/) and then use the [Zotero Import module](https://omeka.org/s/docs/user-manual/modules/zoteroimport/) to upload to Omeka. My [first Omeka 'how to'](http://discontents.com.au/some-exhibition-magic-with-zotero-and-omeka/) (written 8 years ago!) talked about using the Zotero Import plugin to upload records from the National Archives of Australia. While the import module works well, I wanted the flexibility to generate new images on the fly, modify the metadata, and unflatten the Zotero records to build newspaper-to-article relationships. I also wanted to be able to get newspaper articles from other sources, such as Trove lists.
#
# As I started playing around I realised I could rejig my thumbnail generator to [get an image of the whole article](https://nbviewer.jupyter.org/github/GLAM-Workbench/trove-newspapers/blob/master/Save-Trove-newspaper-article-as-image.ipynb). This is useful because Trove's article download options tend to slice up images in unpleasant ways. So I decided to upload the complete image (or images if the article is published across multiple pages) and let Omeka create the derivative versions. I also decided to upload the PDF version of the article generated by Trove as an alternative.
#
# In summary, you can use this notebook to:
#
# * Get a Trove newspaper article using the Trove API
# * Generate an image for the article
# * Search the Omeka site using the API to see if the newspaper that published the article already has a record, if not create one.
# * Upload the article details to Omeka using the API, including a link to the newspaper record, as well as the article image(s) and PDF files.
#
# But what newspaper articles are we uploading? I've created four different ways of selecting articles for upload. There are further details and configuration options for each of these methods below:
#
# * [Option 1: Upload a Trove newspaper search](#Option-1%3A-Upload-a-Trove-newspaper-search)
# * [Option 2: Upload newspaper articles from a Trove list](#Option-2%3A-Upload-newspaper-articles-from-a-Trove-list)
# * [Option 3: Upload Trove newspaper articles saved in Zotero](#Option-3%3A-Upload-Trove-newspaper-articles-saved-in-Zotero)
# * [Option 4: Upload a list of article ids](#Option-4%3A-Upload-a-list-of-article-ids)
#
# There's a fair bit of configuration involved in getting this all working, so make sure you follow the instructions under [Basic configuration](#Basic-configuration) and [Preparing Omeka-S](#Preparing-Omeka-S) before proceeding.
#
# ## An example
#
# Here's an example of a [newspaper article](https://trove.nla.gov.au/newspaper/article/162833980) in Trove:
#
# 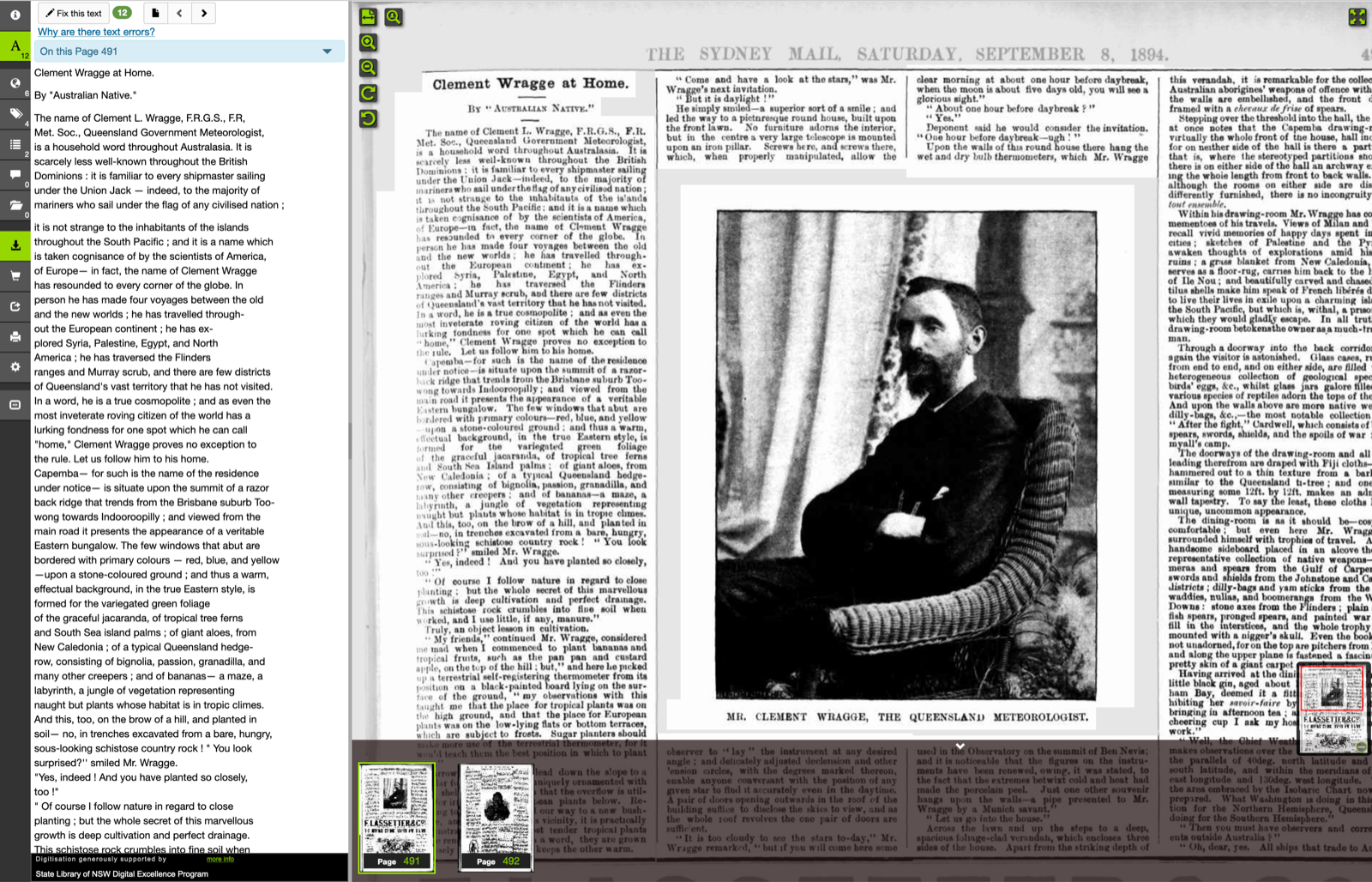 #
# Here's the same article after it's been imported into Omeka. Note that the article is linked to the newspaper that published it using the `isPartOf` property. You can also see the images and PDF of the article that were automatically uploaded along with the metadata.
#
#
#
# Here's the same article after it's been imported into Omeka. Note that the article is linked to the newspaper that published it using the `isPartOf` property. You can also see the images and PDF of the article that were automatically uploaded along with the metadata.
#
#  #
# And here's the record for the linked newspaper:
#
#
#
# And here's the record for the linked newspaper:
#
# 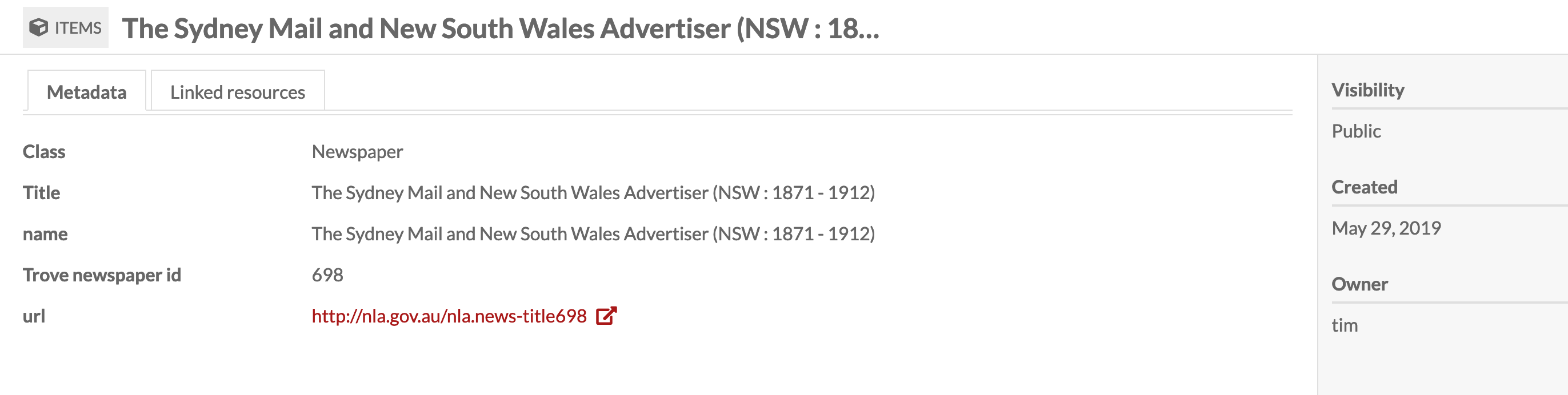 #
# ## Basic configuration
#
# First of all you need an Omeka-S site to upload to! If you don't have a site, a handy server, or a preferred web host, I'd suggest you set up an account with [Reclaim Hosting](https://reclaimhosting.com/) – they're affordable, have excellent support, and provide a one-click installer for Omeka-S. You'll be up and running very quickly.
#
# Once you have your Omeka-S site, you need to add some configuration values in the cell below:
#
# * `API_URL` – the url (or endpoint) of your Omeka site's API. This is basically just the url of your site with `/api` on the end.
# * `KEY_IDENTITY` and `KEY_CREDENTIAL` these are the authentication keys you need to upload new records to Omeka-S.
# * `TROVE_API_KEY` – authentication key to access the Trove API
#
# See below for instructions on generating your keys.
#
# ### Generating your Omeka keys
#
# 1. To generate your keys, log in to the admin interface of your Omeka-S site and click on 'Users' in the side menu.
# 2. Find your user account in the list and then click on the pencil icon to edit your details.
# 3. Click on the 'API keys' tab.
# 4. In the 'New key label' box, enter a name for your key – something like 'Trove upload' would be fine.
# 5. Click on the 'Save' button.
# 6. A message will appear with your `key_identity` and `key_credential` values – the `key_credential` is only ever displayed once, so copy them both now!
#
# ### Trove API key
#
# To get your Trove API key, just [follow these instructions](http://help.nla.gov.au/trove/building-with-trove/api).
#
# In[13]:
# CONFIGURATION
# Things you need to change!
# Paste your values in below!
# The url of your Omeka site's api (basically your Omeka site site url with '/api' on the end)
API_URL = 'http://your.omeka.site/api'
# The keys to your Omeka site
KEY_IDENTITY = 'YOUR OMEKA KEY IDENTITY'
KEY_CREDENTIAL = 'YOUR OMEKA KEY CREDENTIAL'
# Your Trove API key
TROVE_API_KEY = 'YOUR TROVE API KEY'
# Resize images so this is the max dimension -- the Trove page images are very big, so you might want to resize before uploading to Omeka
# Set this to None if you want them as big as possible (this might be useful if you're using the Omeka IIIF server & Universal viewer modules)
MAX_IMAGE_SIZE = 3000
# ## Preparing Omeka-S
#
# Before we start uploading newspaper articles we need to set up the vocabularies and templates we need in Omeka to describe them.
#
# ### Installing the schema.org vocabulary
#
# Omeka uses defined vocabularies to describe items. A number of vocabularies are built-in, but we're going to add the widely-used [Schema.org](https://schema.org/) vocabularly. Amongst many other things, Schema.org includes classes for both `Newspaper` and `NewsArticle`. You can download the [Schema.org definition files here](https://schema.org/docs/developers.html). In the instructions below, I suggest installing the 'all layers' version of the definition file, as this includes the [Bib extension](https://bib.schema.org/) as well as [Pending changes](https://pending.schema.org/) such as `ArchiveComponent` and `ArchiveOrganization`.
#
# To install Schema.org in Omeka:
#
# 1. Log in to the admin interface of your Omeka-S site and click on 'Vocabularies' in the side menu.
# 2. Click on the 'Import new vocabulary button.
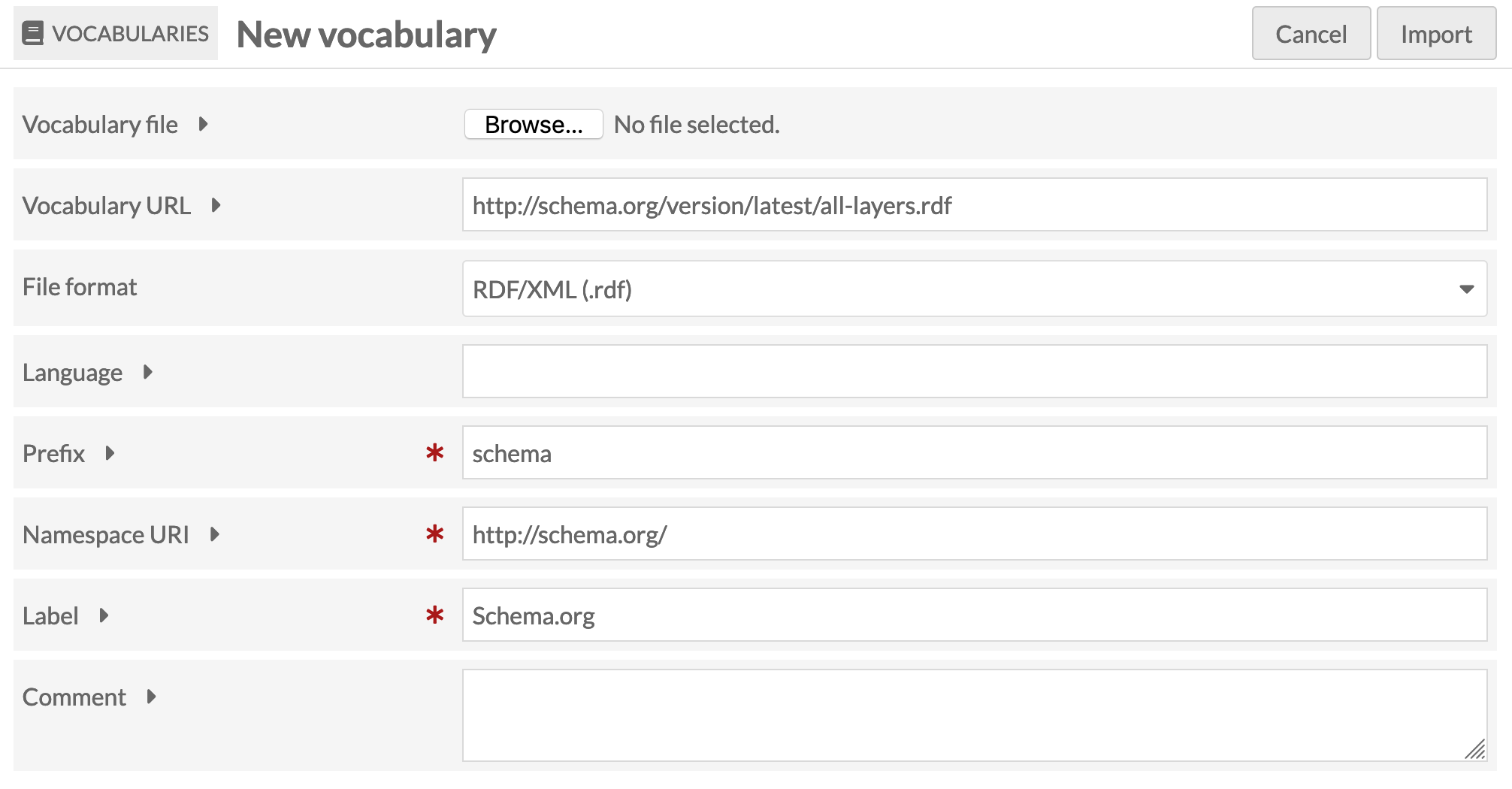
# 3. In the `Vocabularly url` field enter http://schema.org/version/latest/all-layers.rdf
# 4. In the `File format` field select 'RDF/XML'
# 5. In the `Prefix` field enter 'schema'
# 6. In the `Namespace URI` field enter http://schema.org/
# 7. In the `Label` field enter 'Schema.org'
# 8. Click 'Import' to complete the installation.
#
# This is what the import form should look like:
#
#
#
# ## Basic configuration
#
# First of all you need an Omeka-S site to upload to! If you don't have a site, a handy server, or a preferred web host, I'd suggest you set up an account with [Reclaim Hosting](https://reclaimhosting.com/) – they're affordable, have excellent support, and provide a one-click installer for Omeka-S. You'll be up and running very quickly.
#
# Once you have your Omeka-S site, you need to add some configuration values in the cell below:
#
# * `API_URL` – the url (or endpoint) of your Omeka site's API. This is basically just the url of your site with `/api` on the end.
# * `KEY_IDENTITY` and `KEY_CREDENTIAL` these are the authentication keys you need to upload new records to Omeka-S.
# * `TROVE_API_KEY` – authentication key to access the Trove API
#
# See below for instructions on generating your keys.
#
# ### Generating your Omeka keys
#
# 1. To generate your keys, log in to the admin interface of your Omeka-S site and click on 'Users' in the side menu.
# 2. Find your user account in the list and then click on the pencil icon to edit your details.
# 3. Click on the 'API keys' tab.
# 4. In the 'New key label' box, enter a name for your key – something like 'Trove upload' would be fine.
# 5. Click on the 'Save' button.
# 6. A message will appear with your `key_identity` and `key_credential` values – the `key_credential` is only ever displayed once, so copy them both now!
#
# ### Trove API key
#
# To get your Trove API key, just [follow these instructions](http://help.nla.gov.au/trove/building-with-trove/api).
#
# In[13]:
# CONFIGURATION
# Things you need to change!
# Paste your values in below!
# The url of your Omeka site's api (basically your Omeka site site url with '/api' on the end)
API_URL = 'http://your.omeka.site/api'
# The keys to your Omeka site
KEY_IDENTITY = 'YOUR OMEKA KEY IDENTITY'
KEY_CREDENTIAL = 'YOUR OMEKA KEY CREDENTIAL'
# Your Trove API key
TROVE_API_KEY = 'YOUR TROVE API KEY'
# Resize images so this is the max dimension -- the Trove page images are very big, so you might want to resize before uploading to Omeka
# Set this to None if you want them as big as possible (this might be useful if you're using the Omeka IIIF server & Universal viewer modules)
MAX_IMAGE_SIZE = 3000
# ## Preparing Omeka-S
#
# Before we start uploading newspaper articles we need to set up the vocabularies and templates we need in Omeka to describe them.
#
# ### Installing the schema.org vocabulary
#
# Omeka uses defined vocabularies to describe items. A number of vocabularies are built-in, but we're going to add the widely-used [Schema.org](https://schema.org/) vocabularly. Amongst many other things, Schema.org includes classes for both `Newspaper` and `NewsArticle`. You can download the [Schema.org definition files here](https://schema.org/docs/developers.html). In the instructions below, I suggest installing the 'all layers' version of the definition file, as this includes the [Bib extension](https://bib.schema.org/) as well as [Pending changes](https://pending.schema.org/) such as `ArchiveComponent` and `ArchiveOrganization`.
#
# To install Schema.org in Omeka:
#
# 1. Log in to the admin interface of your Omeka-S site and click on 'Vocabularies' in the side menu.
# 2. Click on the 'Import new vocabulary button.
# 3. In the `Vocabularly url` field enter http://schema.org/version/latest/all-layers.rdf
# 4. In the `File format` field select 'RDF/XML'
# 5. In the `Prefix` field enter 'schema'
# 6. In the `Namespace URI` field enter http://schema.org/
# 7. In the `Label` field enter 'Schema.org'
# 8. Click 'Import' to complete the installation.
#
# This is what the import form should look like:
#
#  #
# See the Omeka-S documentation for [more information on managing vocabularies](https://omeka.org/s/docs/user-manual/content/vocabularies/).
#
# ### Installing the Numeric Data Type module
#
# The [Numeric Data Type module](https://omeka.org/s/docs/user-manual/modules/numericdatatypes/) gives you more options in defining the data type of a field. In particular, you can identify certain values as ISO formatted dates so they can then be properly formatted, sorted, and searched. The template I've created for newspaper articles (see below) uses the 'timestamp' data type to import the dates of the newspaper articles, so you'll need to install this module before importing the templates.
#
# 1. Download the [Numeric Data Type module](https://omeka.org/s/modules/NumericDataTypes/) to your computer.
# 2. Upload the zipped module to the modules folder of your Omeka site.
# 3. Unzip the module.
# 4. Log in to the admin interface of your Omeka-S site and click on 'Modules' in the side menu.
# 5. Click on the 'Install' button.
#
# See the Omeka-S documentation for [more information on installing modules](https://omeka.org/s/docs/user-manual/modules/#installing-modules).
#
# ### Importing the resource templates
#
# One of the powerful features of Omeka is the ability to define the types of items you're working with using 'resource templates'. These resource templates associate the items with specific vocabulary classes and list the expected properties. I've created resource templates for 'Newspaper' and 'Newspaper article' and exported them as JSON. The Trove upload code looks for these templates, so they need to be imported into your Omeka site.
#
# 1. Download [Newspaper.json](templates/Newspaper.json) and [Newspaper_article.json](templates/Newspaper_article.json) to your own computer.
# 2. Log in to the admin interface of your Omeka-S site and click on 'Resource templates' in the side menu.
# 3. Click on the 'Import' button
# 4. Click on 'Browse' and select the `Newspaper.json` file you downloaded.
# 5. Click on the 'Review import' button.
# 6. Click on the 'Complete import' button.
# 7. Click the 'Edit Resource Template' button.
# 8. Find the `name` property and click on the pencil icon to edit it.
# 9. Check the box next to 'Use for resource title', then click on the 'Set changes' button.
# 10. Find the `description` property and click on the pencil icon to edit it.
# 11. Check the box next to 'Use for resource description', then click on the 'Set changes' button.
# 12. Click on the 'Save' button.
# 13. Repeat the same procedure to import `Newspaper_article.json`, but check at the 'Review import' stage to make sure that the selected data type for the `datePublished` property is `Timestamp`.
#
# Note that I've deliberately kept the templates fairly simple. You might want to add additional properties. However, if you change or remove any of the existing properties, you'll probably also have to edit the `add_article()` function below.
#
# See the Omeka-S documentation for [more information on managing resource templates](https://omeka.org/s/docs/user-manual/content/resource-template/).
# ## Define all the functions that we need
#
# Hit **Shift+Enter** to run each of the cells below and set up all the basic functions we need.
# In[1]:
import requests
from IPython.display import display, HTML, JSON
import json
from bs4 import BeautifulSoup
from PIL import Image
from io import BytesIO
import re
import arrow
import os
from tqdm.auto import tqdm
from pyzotero import zotero
from requests.adapters import HTTPAdapter
from requests.packages.urllib3.util.retry import Retry
s = requests.Session()
retries = Retry(total=10, backoff_factor=1, status_forcelist=[ 502, 503, 504, 524 ])
s.mount('http://', HTTPAdapter(max_retries=retries))
s.mount('https://', HTTPAdapter(max_retries=retries))
# In[ ]:
# SOME GENERAL FUNCTIONS FOR WORKING WITH OMEKA
def get_resource_class(resource_template_id):
'''
Gets the resource class associated with a given resource template.
'''
response = s.get('{}/resource_templates/{}'.format(API_URL, resource_template_id))
data = response.json()
return data['o:resource_class']
def get_resource_properties(resource_template_id):
'''
Gets basic info about the properties in a resource template including:
- property term
- property id
- data type
'''
properties = []
response = s.get('{}/resource_templates/{}'.format(API_URL, resource_template_id))
data = response.json()
for prop in data['o:resource_template_property']:
prop_url = prop['o:property']['@id']
# The resource template doesn't include property terms, so we have to go to the property data
prop_response = s.get(prop_url)
prop_data = prop_response.json()
# Give a default data type of literal if there's not one defined in the resource template
data_type = 'literal' if prop['o:data_type'] is None else prop['o:data_type']
properties.append({'term': prop_data['o:term'], 'property_id': prop_data['o:id'], 'type': data_type})
return properties
def prepare_payload(resource_template_id):
'''
Create a skeleton payload for the creation of a new item based on the given resource template.
'''
resource_class = get_resource_class(resource_template_id)
properties = get_resource_properties(resource_template_id)
payload = {
'o:resource_class': {
'@id': resource_class['@id'],
'o:id': resource_class['o:id']
},
'o:resource_template': {
'@id': '{}/resource_templates/{}'.format(API_URL, resource_template_id),
'o:id': resource_template_id
},
"o:thumbnail": None,
"o:media": [ ],
"o:item_set": [ ]
}
for prop in properties:
payload[prop['term']] = [{
'type': prop['type'],
'property_id': prop['property_id']
}]
return payload
def get_template_id(label):
params = {
'label': label
}
response = s.get('{}/resource_templates/'.format(API_URL), params=params)
return response.json()[0]['o:id']
# SPECIFIC FUNCTIONS FOR UPLOADING TROVE NEWSPAPERS
def get_article(article_id):
'''Retrieve an individual newspaper article from the Trove API.'''
url = 'http://api.trove.nla.gov.au/v2/newspaper/{}'.format(article_id)
params = {
'include': 'articleText',
'encoding': 'json',
'key': TROVE_API_KEY
}
response = s.get(url, params=params)
return response.json()['article']
def get_total_results(params):
'''
Get the total number of results for a Trove search.
'''
these_params = params.copy()
these_params['n'] = 0
response = s.get('https://api.trove.nla.gov.au/v2/result', params=these_params)
data = response.json()
return int(data['response']['zone'][0]['records']['total'])
def get_newspaper_id_property(template_resource_id):
properties = get_resource_properties(template_resource_id)
for prop in properties:
if prop['term'] == 'schema:identifier':
return prop['property_id']
def find_newspaper(newspaper_id, template_resource_id):
id_prop = get_newspaper_id_property(template_resource_id)
newspaper_class_id = get_resource_class(template_resource_id)
params = {
'property[0][joiner]': 'and', # and / or joins multiple property searches
'property[0][property]': id_prop, # property id
'property[0][type]': 'eq', # See above for options
'property[0][text]': newspaper_id,
'resource_class_id': [newspaper_class_id],
'item_set_id': []
}
response = s.get('{}/items'.format(API_URL), params=params)
data = response.json()
try:
newspaper_id = data[0]['o:id']
except (IndexError, KeyError):
newspaper_id = None
return newspaper_id
def get_newspaper(newspaper):
'''
Checks to see if there's already a record for the given newspaper in Omeka.
If not, it creates one.
Returns the Omeka id for the newspaper.
'''
template_id = get_template_id('Newspaper')
newspaper_id = find_newspaper(newspaper['id'], template_id)
if not newspaper_id:
payload = prepare_payload(template_id)
payload['schema:identifier'][0]['@value'] = newspaper['id']
payload['schema:name'][0]['@value'] = newspaper['value']
payload['schema:url'][0]['@id'] = 'http://nla.gov.au/nla.news-title{}'.format(newspaper['id'])
# print(payload)
params = {
'key_identity': KEY_IDENTITY,
'key_credential': KEY_CREDENTIAL
}
response = s.post('{}/items/'.format(API_URL), json=payload, params=params)
data = response.json()
newspaper_id = data['o:id']
return newspaper_id
def get_newspaper_pdf(article_id):
'''
Use my proxy app to get the url to the PDF copy of an article.
'''
response = s.get('https://trove-proxy.herokuapp.com/pdf/{}'.format(article_id))
response = s.get(response.text)
filename = '{}.pdf'.format(article_id)
with open(filename, 'wb') as pdf_file:
pdf_file.write(response.content)
return filename
def find_article(article_id, template_resource_id):
id_prop = get_newspaper_id_property(template_resource_id)
article_class_id = get_resource_class(template_resource_id)
params = {
'property[0][joiner]': 'and', # and / or joins multiple property searches
'property[0][property]': id_prop, # property id
'property[0][type]': 'eq', # See above for options
'property[0][text]': article_id,
'resource_class_id': [article_class_id],
'item_set_id': []
}
response = s.get('{}/items'.format(API_URL), params=params)
data = response.json()
try:
article_id = data[0]['o:id']
except (IndexError, KeyError):
article_id = None
return article_id
def add_article(article):
'''
Add a newspaper aticle (and image) to Omeka.
'''
template_id = get_template_id('Newspaper article')
article_id = find_article(article['id'], template_id)
if article_id is None:
payload = prepare_payload(template_id)
payload['schema:identifier'][0]['@value'] = article['id']
payload['schema:name'][0]['@value'] = article['heading']
# A basic citation
payload['schema:description'][0]['@value'] = '{}, {}, page {}'.format(arrow.get(article['date']).format('D MMM YYYY'), article['title']['value'], article['page'])
payload['schema:datePublished'][0]['@value'] = article['date']
# Fails silently if you don't turn the page number into a string
payload['schema:pagination'][0]['@value'] = str(article['page'])
# Get the id of the newspaper item record
newspaper_id = get_newspaper(article['title'])
# Connect to the newspaper record
payload['schema:isPartOf'][0]['type'] = 'resource:item'
payload['schema:isPartOf'][0]['@id'] = '{}/items/{}'.format(API_URL, newspaper_id)
payload['schema:isPartOf'][0]['value_resource_id'] = newspaper_id
payload['schema:isPartOf'][0]['value_resource_name'] = 'items'
# Link to Trove
payload['schema:url'][0]['@id'] = 'http://nla.gov.au/nla.news-article{}'.format(article['id'])
# Remove html tags from article text
try:
soup = BeautifulSoup(article['articleText'])
article_text = soup.get_text()
# Add full text
payload['schema:text'][0]['@value'] = article_text
except KeyError:
pass
# Data for image file upload
payload['o:media'] = []
files = {}
images = get_page_images(article['id'])
for index, image in enumerate(images):
page_id = image[:-4]
payload['o:media'].append({'o:ingester': 'upload', 'file_index': str(index), 'o:item': {}, 'dcterms:title': [{'property_id': 1, '@value': 'Page: {}'.format(page_id), 'type': 'literal'}]})
with open(image, 'rb') as f:
files['file[{}]'.format(index)] = f.read()
pdf_file = get_newspaper_pdf(article['id'])
payload['o:media'].append({'o:ingester': 'upload', 'file_index': str(index+1), 'o:item': {}, 'dcterms:title': [{'property_id': 1, '@value': 'PDF: {}'.format(article['id']), 'type': 'literal'}]})
with open(pdf_file, 'rb') as f:
files['file[{}]'.format(str(index+1))] = f.read()
files['data'] = (None, json.dumps(payload), 'application/json')
params = {
'key_identity': KEY_IDENTITY,
'key_credential': KEY_CREDENTIAL
}
# Post the files!
response = s.post('{}/items/'.format(API_URL), files=files, params=params)
# Clean up
for image in images:
os.remove(image)
os.remove(pdf_file)
# display(JSON(response.json()))
def get_box(zones):
# Start with the first element, but...
left = 10000
right = 0
top = 10000
bottom = 0
page_id = zones[0]['data-page-id']
for zone in zones:
if int(zone['data-y']) < top:
top = int(zone['data-y'])
if int(zone['data-x']) < left:
left = int(zone['data-x'])
if (int(zone['data-x']) + int(zone['data-w'])) > right:
right = int(zone['data-x']) + int(zone['data-w'])
if (int(zone['data-y']) + int(zone['data-h'])) > bottom:
bottom = int(zone['data-y']) + int(zone['data-h'])
return {'page_id': page_id, 'left': left, 'top': top, 'right': right, 'bottom': bottom}
def get_article_boxes(article_url):
'''
Positional information about the article is attached to each line of the OCR output in data attributes.
This function loads the HTML version of the article and scrapes the x, y, and width values for each line of text
to determine the coordinates of a box around the article.
'''
boxes = []
response = s.get(article_url)
soup = BeautifulSoup(response.text, 'lxml')
# Lines of OCR are in divs with the class 'zone'
# 'onPage' limits to those on the current page
zones = soup.select('div.zone.onPage')
boxes.append(get_box(zones))
off_page_zones = soup.select('div.zone.offPage')
if off_page_zones:
current_page = off_page_zones[0]['data-page-id']
zones = []
for zone in off_page_zones:
if zone['data-page-id'] == current_page:
zones.append(zone)
else:
boxes.append(get_box(zones))
zones = [zone]
current_page = zone['data-page-id']
boxes.append(get_box(zones))
return boxes
def get_page_images(article_id):
'''
Extract an image of the article from the page image(s), save it, and return the filename(s).
'''
images = []
# Get position of article on the page(s)
boxes = get_article_boxes('http://nla.gov.au/nla.news-article{}'.format(article_id))
for box in boxes:
# print(box)
# Construct the url we need to download the page image
page_url = 'https://trove.nla.gov.au/ndp/imageservice/nla.news-page{}/level{}'.format(box['page_id'], 7)
# Download the page image
response = s.get(page_url)
# Open download as an image for editing
img = Image.open(BytesIO(response.content))
# Use coordinates of top line to create a square box to crop thumbnail
points = (box['left'], box['top'], box['right'], box['bottom'])
# Crop image to article box
cropped = img.crop(points)
# Resize if necessary
if MAX_IMAGE_SIZE:
cropped.thumbnail((MAX_IMAGE_SIZE, MAX_IMAGE_SIZE), Image.ANTIALIAS)
# Save and display thumbnail
cropped_file = '{}.jpg'.format(box['page_id'])
cropped.save(cropped_file)
images.append(cropped_file)
return images
# ## Select your upload method
#
# Select the method you want to use to select and process your articles and follow the associated instructions.
#
# ----
#
# ### Option 1: Upload a Trove newspaper search
#
# This will attempt to upload **all** the newspaper articles returned by a search to your Omeka site. Obviously you want to **restrict your search** to make sure you're only getting the articles you want – use things like facets and date ranges to keep the result set to a manageable size. **You have been warned...**
#
# Once you've constructed your search, enter the various parameters below. You might want to add additional facets such as `l-decade` or `l-year`. Check out [Trove's API documentation](https://help.nla.gov.au/trove/building-with-trove/api-version-2-technical-guide) to see all the options.
#
# Once you've edited the search details, hit **Shift+Enter** to run the cells below and start your upload.
# In[ ]:
def upload_trove_search(params):
start = '*'
total = get_total_results(params)
with tqdm(total=total) as pbar:
while start:
params['s'] = start
response = s.get('https://api.trove.nla.gov.au/v2/result', params=params)
data = response.json()
# The nextStart parameter is used to get the next page of results.
# If there's no nextStart then it means we're on the last page of results.
try:
start = data['response']['zone'][0]['records']['nextStart']
except KeyError:
start = None
for article in data['response']['zone'][0]['records']['article']:
add_article(article)
pbar.update(1)
# In[ ]:
# Edit/add search values and parameters as required. These are an example only!
trove_params = {
'q': '"inigo jones"', # required -- change to anything you might enter in the Trove search box (including double quotes for phrases and boolean operators like AND)
'zone': 'newspaper', # don't change this
'l-illustrated': 'true', # edit or remove -- limits to illustrated articles
'l-illtype': 'Photo', # edit or remove -- limits to illustrations with photos
'l-word': '1000+ Words', # edit or remove -- limits to article with more than 1000 words
'include': 'articleText', # don't change this
'encoding': 'json', # don't change this
'key': TROVE_API_KEY # don't change this
}
upload_trove_search(trove_params)
# ----
#
# ### Option 2: Upload newspaper articles from a Trove list
#
# You can upload any newspaper articles stored in a Trove list to your Omeka site.
#
# To find the `list_id`, just go to the list's web page. The `list_id` is the string of numbers that appears after 'id=' in the url. Once you have your `list_id`, paste it where indicated in the cell below.
#
# Once you've edited the list details, hit **Shift+Enter** to run the cells below and start your upload.
# In[ ]:
def upload_trove_list(list_id):
'''
Upload any newspaper articles in the given Trove list to Omeka.
'''
url = 'http://api.trove.nla.gov.au/v2/list/{}'.format(list_id)
params = {
'include': 'listItems',
'encoding': 'json',
'key': TROVE_API_KEY
}
response = s.get(url, params=params)
data = response.json()
for item in tqdm(data['list'][0]['listItem']):
for zone, record in item.items():
if zone == 'article':
article = get_article(record['id'])
add_article(article)
# In[ ]:
# Paste the identifier of your list between the quotes
list_id = '[Your list ID]'
upload_trove_list(list_id)
# ----
#
# ### Option 3: Upload Trove newspaper articles saved in Zotero
#
# You can upload any Trove newspaper articles stored in a Zotero collection to your Omeka site.
#
# To access Zotero you need four pieces of information:
#
# * `ZOTERO_KEY` – generate an API for this application by [going here](https://www.zotero.org/settings/keys/new) once you've logged into the Zotero web site. Your key only need read access.
# * `LIBRARY_ID` – a string of numbers that identifies your library. For personal libraries, go to [this page](https://www.zotero.org/settings/keys/) once you've logged into the Zotero web site and look for the line that says 'Your userID for use in API calls is...'. For group libraries, just open the groups web page – the `LIBRARY_ID` will be the string of numbers after '/groups/' in the url.
# * `LIBRARY_TYPE` – either 'user' or 'group', depending on whether it's a personal library of a group library.
# * `collection_id` – the id of the collection that contains your Trove newspaper articles. Just open the collection on the Zotero website – the `collection_id` is the string of letters and numbers that comes after '/collectionKey/' in the url.
#
# For additional information see the [Pyzotero](https://github.com/urschrei/pyzotero) documention.
#
# When you have all the values you need, simply paste them where indicated in the cells below.
#
# Once you've added your details, hit **Shift+Enter** to run the cells below and start your upload.
# In[ ]:
# ENTER YOUR VALUES BETWEEN THE QUOTES WHERE INDICATED
ZOTERO_KEY = 'YOUR ZOTERO KEY' # The Zotero API key you generated
LIBRARY_TYPE = 'user' # user or group
LIBRARY_ID = 'YOUR ZOTERO ID' # Either a personal user id or a group id
# In[ ]:
def upload_zotero_collection(coll_id):
'''
Upload any Trove newspaper articles in the given collection to Omeka.
'''
zot = zotero.Zotero(LIBRARY_ID, LIBRARY_TYPE, ZOTERO_KEY)
items = zot.everything(zot.collection_items(coll_id))
articles = []
for item in items:
# Filter out things that aren't newspaper articles
try:
url = item['data']['url']
if item['data']['itemType'] == 'newspaperArticle' and 'nla.news-article' in url:
article_id = re.search('(\d+)$', url).group(1)
articles.append(article_id)
except KeyError:
pass
for article_id in tqdm(articles):
article = get_article(article_id)
add_article(article)
# In[ ]:
# Paste your collection ID between the quotes below.
collection_id = 'YOUR COLLECTION ID'
upload_zotero_collection(collection_id)
# ----
#
# ### Option 4: Upload a list of article ids
#
# This is useful for testing – just get some Trove newspaper article identifiers (the number in the url) and upload them to your Omeka site.
#
# Once you've edited the list of article, hit **Shift+Enter** to run the cells below and start your upload.
# In[ ]:
# Edit the list of articles as you see fit...
article_ids = [
135348864,
70068753,
193580452
]
for article_id in tqdm(article_ids):
article = get_article(article_id)
add_article(article)
# ## Future developments
#
# * I'd originally hoped to use the Omeka-S API to do most of the configuration, including importing vocabularies and resource templates. But I [just couldn't get it to work properly](https://forum.omeka.org/t/upload-resource-template-via-api/8855/5). If I figure it out I'll add the details.
#
# * It would be good to be able to upload other types of things from Trove such as images, maps and journal articles. This should be possible, however, things are not as standardised as they are with the newspaper articles, so it'll take a bit of work. Let me know if you're interested and it'll give me a bit more motivation.
#
# * Also, going back to my Omeka how-to from 8 years back, I'll be creating a RecordSearch to Omeka-S pipeline as well.
# ----
#
# Created by [Tim Sherratt](https://timsherratt.org/) for the [GLAM Workbench](https://glam-workbench.github.io/).
#
# See the Omeka-S documentation for [more information on managing vocabularies](https://omeka.org/s/docs/user-manual/content/vocabularies/).
#
# ### Installing the Numeric Data Type module
#
# The [Numeric Data Type module](https://omeka.org/s/docs/user-manual/modules/numericdatatypes/) gives you more options in defining the data type of a field. In particular, you can identify certain values as ISO formatted dates so they can then be properly formatted, sorted, and searched. The template I've created for newspaper articles (see below) uses the 'timestamp' data type to import the dates of the newspaper articles, so you'll need to install this module before importing the templates.
#
# 1. Download the [Numeric Data Type module](https://omeka.org/s/modules/NumericDataTypes/) to your computer.
# 2. Upload the zipped module to the modules folder of your Omeka site.
# 3. Unzip the module.
# 4. Log in to the admin interface of your Omeka-S site and click on 'Modules' in the side menu.
# 5. Click on the 'Install' button.
#
# See the Omeka-S documentation for [more information on installing modules](https://omeka.org/s/docs/user-manual/modules/#installing-modules).
#
# ### Importing the resource templates
#
# One of the powerful features of Omeka is the ability to define the types of items you're working with using 'resource templates'. These resource templates associate the items with specific vocabulary classes and list the expected properties. I've created resource templates for 'Newspaper' and 'Newspaper article' and exported them as JSON. The Trove upload code looks for these templates, so they need to be imported into your Omeka site.
#
# 1. Download [Newspaper.json](templates/Newspaper.json) and [Newspaper_article.json](templates/Newspaper_article.json) to your own computer.
# 2. Log in to the admin interface of your Omeka-S site and click on 'Resource templates' in the side menu.
# 3. Click on the 'Import' button
# 4. Click on 'Browse' and select the `Newspaper.json` file you downloaded.
# 5. Click on the 'Review import' button.
# 6. Click on the 'Complete import' button.
# 7. Click the 'Edit Resource Template' button.
# 8. Find the `name` property and click on the pencil icon to edit it.
# 9. Check the box next to 'Use for resource title', then click on the 'Set changes' button.
# 10. Find the `description` property and click on the pencil icon to edit it.
# 11. Check the box next to 'Use for resource description', then click on the 'Set changes' button.
# 12. Click on the 'Save' button.
# 13. Repeat the same procedure to import `Newspaper_article.json`, but check at the 'Review import' stage to make sure that the selected data type for the `datePublished` property is `Timestamp`.
#
# Note that I've deliberately kept the templates fairly simple. You might want to add additional properties. However, if you change or remove any of the existing properties, you'll probably also have to edit the `add_article()` function below.
#
# See the Omeka-S documentation for [more information on managing resource templates](https://omeka.org/s/docs/user-manual/content/resource-template/).
# ## Define all the functions that we need
#
# Hit **Shift+Enter** to run each of the cells below and set up all the basic functions we need.
# In[1]:
import requests
from IPython.display import display, HTML, JSON
import json
from bs4 import BeautifulSoup
from PIL import Image
from io import BytesIO
import re
import arrow
import os
from tqdm.auto import tqdm
from pyzotero import zotero
from requests.adapters import HTTPAdapter
from requests.packages.urllib3.util.retry import Retry
s = requests.Session()
retries = Retry(total=10, backoff_factor=1, status_forcelist=[ 502, 503, 504, 524 ])
s.mount('http://', HTTPAdapter(max_retries=retries))
s.mount('https://', HTTPAdapter(max_retries=retries))
# In[ ]:
# SOME GENERAL FUNCTIONS FOR WORKING WITH OMEKA
def get_resource_class(resource_template_id):
'''
Gets the resource class associated with a given resource template.
'''
response = s.get('{}/resource_templates/{}'.format(API_URL, resource_template_id))
data = response.json()
return data['o:resource_class']
def get_resource_properties(resource_template_id):
'''
Gets basic info about the properties in a resource template including:
- property term
- property id
- data type
'''
properties = []
response = s.get('{}/resource_templates/{}'.format(API_URL, resource_template_id))
data = response.json()
for prop in data['o:resource_template_property']:
prop_url = prop['o:property']['@id']
# The resource template doesn't include property terms, so we have to go to the property data
prop_response = s.get(prop_url)
prop_data = prop_response.json()
# Give a default data type of literal if there's not one defined in the resource template
data_type = 'literal' if prop['o:data_type'] is None else prop['o:data_type']
properties.append({'term': prop_data['o:term'], 'property_id': prop_data['o:id'], 'type': data_type})
return properties
def prepare_payload(resource_template_id):
'''
Create a skeleton payload for the creation of a new item based on the given resource template.
'''
resource_class = get_resource_class(resource_template_id)
properties = get_resource_properties(resource_template_id)
payload = {
'o:resource_class': {
'@id': resource_class['@id'],
'o:id': resource_class['o:id']
},
'o:resource_template': {
'@id': '{}/resource_templates/{}'.format(API_URL, resource_template_id),
'o:id': resource_template_id
},
"o:thumbnail": None,
"o:media": [ ],
"o:item_set": [ ]
}
for prop in properties:
payload[prop['term']] = [{
'type': prop['type'],
'property_id': prop['property_id']
}]
return payload
def get_template_id(label):
params = {
'label': label
}
response = s.get('{}/resource_templates/'.format(API_URL), params=params)
return response.json()[0]['o:id']
# SPECIFIC FUNCTIONS FOR UPLOADING TROVE NEWSPAPERS
def get_article(article_id):
'''Retrieve an individual newspaper article from the Trove API.'''
url = 'http://api.trove.nla.gov.au/v2/newspaper/{}'.format(article_id)
params = {
'include': 'articleText',
'encoding': 'json',
'key': TROVE_API_KEY
}
response = s.get(url, params=params)
return response.json()['article']
def get_total_results(params):
'''
Get the total number of results for a Trove search.
'''
these_params = params.copy()
these_params['n'] = 0
response = s.get('https://api.trove.nla.gov.au/v2/result', params=these_params)
data = response.json()
return int(data['response']['zone'][0]['records']['total'])
def get_newspaper_id_property(template_resource_id):
properties = get_resource_properties(template_resource_id)
for prop in properties:
if prop['term'] == 'schema:identifier':
return prop['property_id']
def find_newspaper(newspaper_id, template_resource_id):
id_prop = get_newspaper_id_property(template_resource_id)
newspaper_class_id = get_resource_class(template_resource_id)
params = {
'property[0][joiner]': 'and', # and / or joins multiple property searches
'property[0][property]': id_prop, # property id
'property[0][type]': 'eq', # See above for options
'property[0][text]': newspaper_id,
'resource_class_id': [newspaper_class_id],
'item_set_id': []
}
response = s.get('{}/items'.format(API_URL), params=params)
data = response.json()
try:
newspaper_id = data[0]['o:id']
except (IndexError, KeyError):
newspaper_id = None
return newspaper_id
def get_newspaper(newspaper):
'''
Checks to see if there's already a record for the given newspaper in Omeka.
If not, it creates one.
Returns the Omeka id for the newspaper.
'''
template_id = get_template_id('Newspaper')
newspaper_id = find_newspaper(newspaper['id'], template_id)
if not newspaper_id:
payload = prepare_payload(template_id)
payload['schema:identifier'][0]['@value'] = newspaper['id']
payload['schema:name'][0]['@value'] = newspaper['value']
payload['schema:url'][0]['@id'] = 'http://nla.gov.au/nla.news-title{}'.format(newspaper['id'])
# print(payload)
params = {
'key_identity': KEY_IDENTITY,
'key_credential': KEY_CREDENTIAL
}
response = s.post('{}/items/'.format(API_URL), json=payload, params=params)
data = response.json()
newspaper_id = data['o:id']
return newspaper_id
def get_newspaper_pdf(article_id):
'''
Use my proxy app to get the url to the PDF copy of an article.
'''
response = s.get('https://trove-proxy.herokuapp.com/pdf/{}'.format(article_id))
response = s.get(response.text)
filename = '{}.pdf'.format(article_id)
with open(filename, 'wb') as pdf_file:
pdf_file.write(response.content)
return filename
def find_article(article_id, template_resource_id):
id_prop = get_newspaper_id_property(template_resource_id)
article_class_id = get_resource_class(template_resource_id)
params = {
'property[0][joiner]': 'and', # and / or joins multiple property searches
'property[0][property]': id_prop, # property id
'property[0][type]': 'eq', # See above for options
'property[0][text]': article_id,
'resource_class_id': [article_class_id],
'item_set_id': []
}
response = s.get('{}/items'.format(API_URL), params=params)
data = response.json()
try:
article_id = data[0]['o:id']
except (IndexError, KeyError):
article_id = None
return article_id
def add_article(article):
'''
Add a newspaper aticle (and image) to Omeka.
'''
template_id = get_template_id('Newspaper article')
article_id = find_article(article['id'], template_id)
if article_id is None:
payload = prepare_payload(template_id)
payload['schema:identifier'][0]['@value'] = article['id']
payload['schema:name'][0]['@value'] = article['heading']
# A basic citation
payload['schema:description'][0]['@value'] = '{}, {}, page {}'.format(arrow.get(article['date']).format('D MMM YYYY'), article['title']['value'], article['page'])
payload['schema:datePublished'][0]['@value'] = article['date']
# Fails silently if you don't turn the page number into a string
payload['schema:pagination'][0]['@value'] = str(article['page'])
# Get the id of the newspaper item record
newspaper_id = get_newspaper(article['title'])
# Connect to the newspaper record
payload['schema:isPartOf'][0]['type'] = 'resource:item'
payload['schema:isPartOf'][0]['@id'] = '{}/items/{}'.format(API_URL, newspaper_id)
payload['schema:isPartOf'][0]['value_resource_id'] = newspaper_id
payload['schema:isPartOf'][0]['value_resource_name'] = 'items'
# Link to Trove
payload['schema:url'][0]['@id'] = 'http://nla.gov.au/nla.news-article{}'.format(article['id'])
# Remove html tags from article text
try:
soup = BeautifulSoup(article['articleText'])
article_text = soup.get_text()
# Add full text
payload['schema:text'][0]['@value'] = article_text
except KeyError:
pass
# Data for image file upload
payload['o:media'] = []
files = {}
images = get_page_images(article['id'])
for index, image in enumerate(images):
page_id = image[:-4]
payload['o:media'].append({'o:ingester': 'upload', 'file_index': str(index), 'o:item': {}, 'dcterms:title': [{'property_id': 1, '@value': 'Page: {}'.format(page_id), 'type': 'literal'}]})
with open(image, 'rb') as f:
files['file[{}]'.format(index)] = f.read()
pdf_file = get_newspaper_pdf(article['id'])
payload['o:media'].append({'o:ingester': 'upload', 'file_index': str(index+1), 'o:item': {}, 'dcterms:title': [{'property_id': 1, '@value': 'PDF: {}'.format(article['id']), 'type': 'literal'}]})
with open(pdf_file, 'rb') as f:
files['file[{}]'.format(str(index+1))] = f.read()
files['data'] = (None, json.dumps(payload), 'application/json')
params = {
'key_identity': KEY_IDENTITY,
'key_credential': KEY_CREDENTIAL
}
# Post the files!
response = s.post('{}/items/'.format(API_URL), files=files, params=params)
# Clean up
for image in images:
os.remove(image)
os.remove(pdf_file)
# display(JSON(response.json()))
def get_box(zones):
# Start with the first element, but...
left = 10000
right = 0
top = 10000
bottom = 0
page_id = zones[0]['data-page-id']
for zone in zones:
if int(zone['data-y']) < top:
top = int(zone['data-y'])
if int(zone['data-x']) < left:
left = int(zone['data-x'])
if (int(zone['data-x']) + int(zone['data-w'])) > right:
right = int(zone['data-x']) + int(zone['data-w'])
if (int(zone['data-y']) + int(zone['data-h'])) > bottom:
bottom = int(zone['data-y']) + int(zone['data-h'])
return {'page_id': page_id, 'left': left, 'top': top, 'right': right, 'bottom': bottom}
def get_article_boxes(article_url):
'''
Positional information about the article is attached to each line of the OCR output in data attributes.
This function loads the HTML version of the article and scrapes the x, y, and width values for each line of text
to determine the coordinates of a box around the article.
'''
boxes = []
response = s.get(article_url)
soup = BeautifulSoup(response.text, 'lxml')
# Lines of OCR are in divs with the class 'zone'
# 'onPage' limits to those on the current page
zones = soup.select('div.zone.onPage')
boxes.append(get_box(zones))
off_page_zones = soup.select('div.zone.offPage')
if off_page_zones:
current_page = off_page_zones[0]['data-page-id']
zones = []
for zone in off_page_zones:
if zone['data-page-id'] == current_page:
zones.append(zone)
else:
boxes.append(get_box(zones))
zones = [zone]
current_page = zone['data-page-id']
boxes.append(get_box(zones))
return boxes
def get_page_images(article_id):
'''
Extract an image of the article from the page image(s), save it, and return the filename(s).
'''
images = []
# Get position of article on the page(s)
boxes = get_article_boxes('http://nla.gov.au/nla.news-article{}'.format(article_id))
for box in boxes:
# print(box)
# Construct the url we need to download the page image
page_url = 'https://trove.nla.gov.au/ndp/imageservice/nla.news-page{}/level{}'.format(box['page_id'], 7)
# Download the page image
response = s.get(page_url)
# Open download as an image for editing
img = Image.open(BytesIO(response.content))
# Use coordinates of top line to create a square box to crop thumbnail
points = (box['left'], box['top'], box['right'], box['bottom'])
# Crop image to article box
cropped = img.crop(points)
# Resize if necessary
if MAX_IMAGE_SIZE:
cropped.thumbnail((MAX_IMAGE_SIZE, MAX_IMAGE_SIZE), Image.ANTIALIAS)
# Save and display thumbnail
cropped_file = '{}.jpg'.format(box['page_id'])
cropped.save(cropped_file)
images.append(cropped_file)
return images
# ## Select your upload method
#
# Select the method you want to use to select and process your articles and follow the associated instructions.
#
# ----
#
# ### Option 1: Upload a Trove newspaper search
#
# This will attempt to upload **all** the newspaper articles returned by a search to your Omeka site. Obviously you want to **restrict your search** to make sure you're only getting the articles you want – use things like facets and date ranges to keep the result set to a manageable size. **You have been warned...**
#
# Once you've constructed your search, enter the various parameters below. You might want to add additional facets such as `l-decade` or `l-year`. Check out [Trove's API documentation](https://help.nla.gov.au/trove/building-with-trove/api-version-2-technical-guide) to see all the options.
#
# Once you've edited the search details, hit **Shift+Enter** to run the cells below and start your upload.
# In[ ]:
def upload_trove_search(params):
start = '*'
total = get_total_results(params)
with tqdm(total=total) as pbar:
while start:
params['s'] = start
response = s.get('https://api.trove.nla.gov.au/v2/result', params=params)
data = response.json()
# The nextStart parameter is used to get the next page of results.
# If there's no nextStart then it means we're on the last page of results.
try:
start = data['response']['zone'][0]['records']['nextStart']
except KeyError:
start = None
for article in data['response']['zone'][0]['records']['article']:
add_article(article)
pbar.update(1)
# In[ ]:
# Edit/add search values and parameters as required. These are an example only!
trove_params = {
'q': '"inigo jones"', # required -- change to anything you might enter in the Trove search box (including double quotes for phrases and boolean operators like AND)
'zone': 'newspaper', # don't change this
'l-illustrated': 'true', # edit or remove -- limits to illustrated articles
'l-illtype': 'Photo', # edit or remove -- limits to illustrations with photos
'l-word': '1000+ Words', # edit or remove -- limits to article with more than 1000 words
'include': 'articleText', # don't change this
'encoding': 'json', # don't change this
'key': TROVE_API_KEY # don't change this
}
upload_trove_search(trove_params)
# ----
#
# ### Option 2: Upload newspaper articles from a Trove list
#
# You can upload any newspaper articles stored in a Trove list to your Omeka site.
#
# To find the `list_id`, just go to the list's web page. The `list_id` is the string of numbers that appears after 'id=' in the url. Once you have your `list_id`, paste it where indicated in the cell below.
#
# Once you've edited the list details, hit **Shift+Enter** to run the cells below and start your upload.
# In[ ]:
def upload_trove_list(list_id):
'''
Upload any newspaper articles in the given Trove list to Omeka.
'''
url = 'http://api.trove.nla.gov.au/v2/list/{}'.format(list_id)
params = {
'include': 'listItems',
'encoding': 'json',
'key': TROVE_API_KEY
}
response = s.get(url, params=params)
data = response.json()
for item in tqdm(data['list'][0]['listItem']):
for zone, record in item.items():
if zone == 'article':
article = get_article(record['id'])
add_article(article)
# In[ ]:
# Paste the identifier of your list between the quotes
list_id = '[Your list ID]'
upload_trove_list(list_id)
# ----
#
# ### Option 3: Upload Trove newspaper articles saved in Zotero
#
# You can upload any Trove newspaper articles stored in a Zotero collection to your Omeka site.
#
# To access Zotero you need four pieces of information:
#
# * `ZOTERO_KEY` – generate an API for this application by [going here](https://www.zotero.org/settings/keys/new) once you've logged into the Zotero web site. Your key only need read access.
# * `LIBRARY_ID` – a string of numbers that identifies your library. For personal libraries, go to [this page](https://www.zotero.org/settings/keys/) once you've logged into the Zotero web site and look for the line that says 'Your userID for use in API calls is...'. For group libraries, just open the groups web page – the `LIBRARY_ID` will be the string of numbers after '/groups/' in the url.
# * `LIBRARY_TYPE` – either 'user' or 'group', depending on whether it's a personal library of a group library.
# * `collection_id` – the id of the collection that contains your Trove newspaper articles. Just open the collection on the Zotero website – the `collection_id` is the string of letters and numbers that comes after '/collectionKey/' in the url.
#
# For additional information see the [Pyzotero](https://github.com/urschrei/pyzotero) documention.
#
# When you have all the values you need, simply paste them where indicated in the cells below.
#
# Once you've added your details, hit **Shift+Enter** to run the cells below and start your upload.
# In[ ]:
# ENTER YOUR VALUES BETWEEN THE QUOTES WHERE INDICATED
ZOTERO_KEY = 'YOUR ZOTERO KEY' # The Zotero API key you generated
LIBRARY_TYPE = 'user' # user or group
LIBRARY_ID = 'YOUR ZOTERO ID' # Either a personal user id or a group id
# In[ ]:
def upload_zotero_collection(coll_id):
'''
Upload any Trove newspaper articles in the given collection to Omeka.
'''
zot = zotero.Zotero(LIBRARY_ID, LIBRARY_TYPE, ZOTERO_KEY)
items = zot.everything(zot.collection_items(coll_id))
articles = []
for item in items:
# Filter out things that aren't newspaper articles
try:
url = item['data']['url']
if item['data']['itemType'] == 'newspaperArticle' and 'nla.news-article' in url:
article_id = re.search('(\d+)$', url).group(1)
articles.append(article_id)
except KeyError:
pass
for article_id in tqdm(articles):
article = get_article(article_id)
add_article(article)
# In[ ]:
# Paste your collection ID between the quotes below.
collection_id = 'YOUR COLLECTION ID'
upload_zotero_collection(collection_id)
# ----
#
# ### Option 4: Upload a list of article ids
#
# This is useful for testing – just get some Trove newspaper article identifiers (the number in the url) and upload them to your Omeka site.
#
# Once you've edited the list of article, hit **Shift+Enter** to run the cells below and start your upload.
# In[ ]:
# Edit the list of articles as you see fit...
article_ids = [
135348864,
70068753,
193580452
]
for article_id in tqdm(article_ids):
article = get_article(article_id)
add_article(article)
# ## Future developments
#
# * I'd originally hoped to use the Omeka-S API to do most of the configuration, including importing vocabularies and resource templates. But I [just couldn't get it to work properly](https://forum.omeka.org/t/upload-resource-template-via-api/8855/5). If I figure it out I'll add the details.
#
# * It would be good to be able to upload other types of things from Trove such as images, maps and journal articles. This should be possible, however, things are not as standardised as they are with the newspaper articles, so it'll take a bit of work. Let me know if you're interested and it'll give me a bit more motivation.
#
# * Also, going back to my Omeka how-to from 8 years back, I'll be creating a RecordSearch to Omeka-S pipeline as well.
# ----
#
# Created by [Tim Sherratt](https://timsherratt.org/) for the [GLAM Workbench](https://glam-workbench.github.io/).