#!/usr/bin/env python
# coding: utf-8
# In[2]:
import sys; sys.version
# In[3]:
from keras.datasets import mnist
# In[4]:
# images는 손글씨 숫자 이미지, labvel은 이미지의 번호
(train_images, train_labels), (test_images, test_labels) = mnist.load_data()
# ### MNIST 데이터
# In[5]:
# train: 훈련시킹 이미지들 6만개
print('train_images type: {} / len: {}'.format(type(train_images), len(train_images)))
print('train_labels type: {} / len: {}'.format(type(train_labels), len(train_labels)))
# In[6]:
# train_label : 평가 테스트용 이미지들 1만개
print('test_images type: {} / len: {}'.format(type(test_images), len(test_images)))
print('test_labels type: {} / len: {}'.format(type(test_labels), len(test_labels)))
# In[7]:
# 차원 확인:shape
# (60000, 28, 28) -> 28x28 배열이 6만개 있다는 의미
print(train_images.shape, test_images.shape)
# - image 파일은 28x28의 배열로 이루어져 있으며 요소는 01부터 255까지 명암값으로 이루어짐.
# - 이런 이미지 파일이 6만개가 있음
#
# 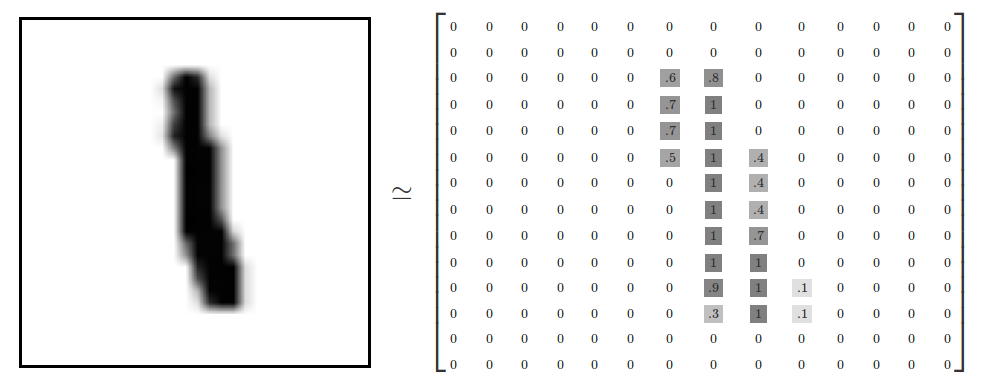 #
#  #
#
#
# ### Matplotlib: 배열을 이미지로 출력
# In[8]:
import matplotlib.pyplot as plt
# In[9]:
plt.figure(figsize=(3,3))
plt.imshow(train_images[0])
plt.show()
# ### 신경망 모델을 keras로 만들기
# In[10]:
from keras import models, layers
network = models.Sequential()
network.add(layers.Dense(512, activation='relu', input_shape=(28*28,)))
network.add(layers.Dense(10, activation='softmax', input_shape=(512,)))
network.compile(
optimizer = 'adam',
loss = 'categorical_crossentropy',
metrics = ['accuracy'],
)
# ### 데이터 정규화
# In[11]:
train_X = train_images.reshape(60000, -1)
train_X = train_X.astype('float')/ 255
test_X = test_images.reshape(10000, -1)
test_X = test_X.astype('float')/ 255
# **Reshapes** : make output to a certain shape.
# - 0~255까지 있는 명암값을 255로 나누어 0~1까지의 수로 변환
# In[12]:
from keras.utils import to_categorical
train_Y = to_categorical(train_labels)
test_Y = to_categorical(test_labels)
# In[13]:
train_Y[0] # 5
# **One-Hot Encoding** : A vector that 1 in only one demension, 0 in the remaing demesion.
# - 3일 경우 [0,0,0,1,0,0,0,0,0,0,0,0] 으로 변환.
# - 결과적으로 tran_X는 [60000,10] 실수 배열이 된다.
#
#
#
#
# ### Matplotlib: 배열을 이미지로 출력
# In[8]:
import matplotlib.pyplot as plt
# In[9]:
plt.figure(figsize=(3,3))
plt.imshow(train_images[0])
plt.show()
# ### 신경망 모델을 keras로 만들기
# In[10]:
from keras import models, layers
network = models.Sequential()
network.add(layers.Dense(512, activation='relu', input_shape=(28*28,)))
network.add(layers.Dense(10, activation='softmax', input_shape=(512,)))
network.compile(
optimizer = 'adam',
loss = 'categorical_crossentropy',
metrics = ['accuracy'],
)
# ### 데이터 정규화
# In[11]:
train_X = train_images.reshape(60000, -1)
train_X = train_X.astype('float')/ 255
test_X = test_images.reshape(10000, -1)
test_X = test_X.astype('float')/ 255
# **Reshapes** : make output to a certain shape.
# - 0~255까지 있는 명암값을 255로 나누어 0~1까지의 수로 변환
# In[12]:
from keras.utils import to_categorical
train_Y = to_categorical(train_labels)
test_Y = to_categorical(test_labels)
# In[13]:
train_Y[0] # 5
# **One-Hot Encoding** : A vector that 1 in only one demension, 0 in the remaing demesion.
# - 3일 경우 [0,0,0,1,0,0,0,0,0,0,0,0] 으로 변환.
# - 결과적으로 tran_X는 [60000,10] 실수 배열이 된다.
# 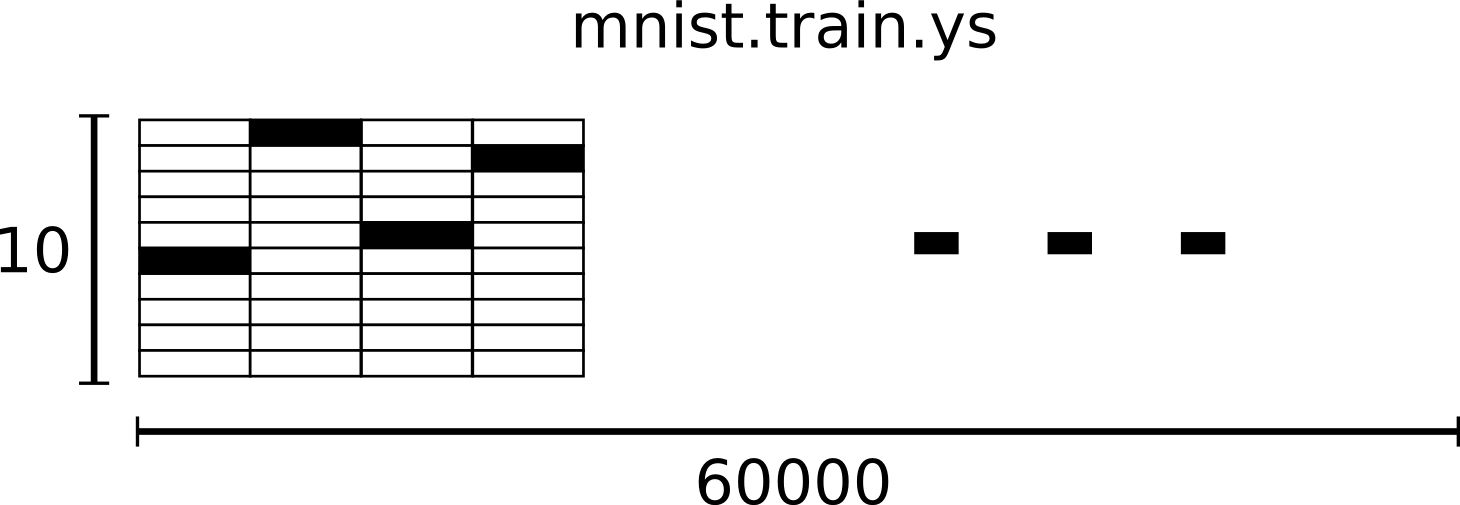 # ### 머신러닝 훈련 과정
# In[14]:
network.fit(train_X, train_Y, epochs=5, batch_size=128)
# ### 테스트셋을 사용해서 평가
# In[15]:
test_loss, test_acc = network.evaluate(test_X, test_Y)
# In[16]:
print('Accuracy : {:.3f}'.format(test_acc))
# ### 로스 데이터
# In[17]:
# test_pred: 1만개의 test_X의 예측한 값
test_pred = network.predict_classes(test_X)
import numpy as np
# correctly_predicted : 1만개의 예측된 값을 라벨값과 비교하여 참, 거짓 여부를 판단.
correctly_predicted = np.equal(test_pred, test_labels)
# In[18]:
len(test_pred), test_pred
# In[19]:
len(correctly_predicted), correctly_predicted
# In[20]:
# wong_predictions : 거짓(라벨값과 다름)으로 판단한 숫자들의 인덱스
wong_predictions = np.where(correctly_predicted == False)[0];
wong_predictions
# In[1]:
fig = plt.figure()
# In[129]:
for i in range(3):
wong_prediction = wong_predictions[i] # wong_prediction : wong_predictions에서 추출한 하나의 인덱스 번호
plt.figure(figsize=(3,3))
# 처음에 정의한 평가용 1만개의 이미지에 잘 못 인식한 숫자의 인덱스를 적용
plt.imshow(test_images[wong_prediction])
# plt.title('Predicted: {}'.format(test_pred[wong_prediction]), fontsize=30)
plt.title('Predicted: {} / Label: {}'.format(
test_pred[wong_prediction], test_labels[wong_prediction] ), fontsize=20)
plt.show()
# ### 신경망 추가
# In[137]:
network_deep = models.Sequential()
network_deep.add(layers.Dense(units=512, activation='relu', input_shape=(28*28,)))
network_deep.add(layers.Dense(units=256, activation='relu'))
network_deep.add(layers.Dense(units=256, activation='relu'))
network_deep.add(layers.Dense(units=10, activation='softmax'))
network_deep.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
# In[138]:
network_deep.fit(train_X, train_Y, epochs=5, batch_size=128)
# In[139]:
_ , acc_deep = network_deep.evaluate(test_X, test_Y)
print('Accuracy of network_deep : {:.3f}'.format(acc_deep))
# ### 클래스화
# In[159]:
from keras.models import Sequential
from keras.layers import Dense
class DNN(Sequential):
def __init__(self, input_size, output_size, *num_hidden_nodes):
super().__init__()
num_nodes = (*num_hidden_nodes, output_size)
print(num_nodes)
for idx, num_node in enumerate(num_nodes):
activation = 'relu'
if idx == 0:
self.add(Dense(num_node, activation = activation, input_shape=(input_size,)))
else:
if idx == len(num_nodes) - 1:
activation = 'softmax'
self.add(Dense(output_size, activation=activation))
self.compile(loss='categorical_crossentropy',
optimizer='adam',
metrics=['accuracy'])
# In[160]:
model = DNN(train_X.shape[1], train_Y.shape[1], 512)
# In[161]:
train_X[0].shape, train_Y[0].shape
# In[163]:
model.fit(train_X, train_Y, epochs=5, batch_size=128)
# In[175]:
test_loss, test_acc = model.evaluate(test_X, test_Y)
print('Loss:{} / Acc:{}'.format(test_loss, test_acc))
# In[184]:
# precidt : ML로 예측한 값.
precidt = model.predict_classes(test_X)
# In[177]:
import numpy as np
comapare_precidt = np.equal(test_precidt, test_labels) # 예측값과 라벨값과 비교
array_false = np.where(comapare_precidt == False)[0] # 비교해서 다른 것을 array_false에 추가.
len(array_false), array_false
# In[211]:
# 잘못 인식한 숫자중 하나를 추출해서 이미지화
for i in range(20,30):
index = array_false[i]
select = precidt[index]
label = test_labels[index]
plt.imshow(test_images[index])
plt.title('index: {}, Predict: {}, Label: {}'.format(index, select, label), fontsize=15)
plt.show()
# ### 머신러닝 훈련 과정
# In[14]:
network.fit(train_X, train_Y, epochs=5, batch_size=128)
# ### 테스트셋을 사용해서 평가
# In[15]:
test_loss, test_acc = network.evaluate(test_X, test_Y)
# In[16]:
print('Accuracy : {:.3f}'.format(test_acc))
# ### 로스 데이터
# In[17]:
# test_pred: 1만개의 test_X의 예측한 값
test_pred = network.predict_classes(test_X)
import numpy as np
# correctly_predicted : 1만개의 예측된 값을 라벨값과 비교하여 참, 거짓 여부를 판단.
correctly_predicted = np.equal(test_pred, test_labels)
# In[18]:
len(test_pred), test_pred
# In[19]:
len(correctly_predicted), correctly_predicted
# In[20]:
# wong_predictions : 거짓(라벨값과 다름)으로 판단한 숫자들의 인덱스
wong_predictions = np.where(correctly_predicted == False)[0];
wong_predictions
# In[1]:
fig = plt.figure()
# In[129]:
for i in range(3):
wong_prediction = wong_predictions[i] # wong_prediction : wong_predictions에서 추출한 하나의 인덱스 번호
plt.figure(figsize=(3,3))
# 처음에 정의한 평가용 1만개의 이미지에 잘 못 인식한 숫자의 인덱스를 적용
plt.imshow(test_images[wong_prediction])
# plt.title('Predicted: {}'.format(test_pred[wong_prediction]), fontsize=30)
plt.title('Predicted: {} / Label: {}'.format(
test_pred[wong_prediction], test_labels[wong_prediction] ), fontsize=20)
plt.show()
# ### 신경망 추가
# In[137]:
network_deep = models.Sequential()
network_deep.add(layers.Dense(units=512, activation='relu', input_shape=(28*28,)))
network_deep.add(layers.Dense(units=256, activation='relu'))
network_deep.add(layers.Dense(units=256, activation='relu'))
network_deep.add(layers.Dense(units=10, activation='softmax'))
network_deep.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
# In[138]:
network_deep.fit(train_X, train_Y, epochs=5, batch_size=128)
# In[139]:
_ , acc_deep = network_deep.evaluate(test_X, test_Y)
print('Accuracy of network_deep : {:.3f}'.format(acc_deep))
# ### 클래스화
# In[159]:
from keras.models import Sequential
from keras.layers import Dense
class DNN(Sequential):
def __init__(self, input_size, output_size, *num_hidden_nodes):
super().__init__()
num_nodes = (*num_hidden_nodes, output_size)
print(num_nodes)
for idx, num_node in enumerate(num_nodes):
activation = 'relu'
if idx == 0:
self.add(Dense(num_node, activation = activation, input_shape=(input_size,)))
else:
if idx == len(num_nodes) - 1:
activation = 'softmax'
self.add(Dense(output_size, activation=activation))
self.compile(loss='categorical_crossentropy',
optimizer='adam',
metrics=['accuracy'])
# In[160]:
model = DNN(train_X.shape[1], train_Y.shape[1], 512)
# In[161]:
train_X[0].shape, train_Y[0].shape
# In[163]:
model.fit(train_X, train_Y, epochs=5, batch_size=128)
# In[175]:
test_loss, test_acc = model.evaluate(test_X, test_Y)
print('Loss:{} / Acc:{}'.format(test_loss, test_acc))
# In[184]:
# precidt : ML로 예측한 값.
precidt = model.predict_classes(test_X)
# In[177]:
import numpy as np
comapare_precidt = np.equal(test_precidt, test_labels) # 예측값과 라벨값과 비교
array_false = np.where(comapare_precidt == False)[0] # 비교해서 다른 것을 array_false에 추가.
len(array_false), array_false
# In[211]:
# 잘못 인식한 숫자중 하나를 추출해서 이미지화
for i in range(20,30):
index = array_false[i]
select = precidt[index]
label = test_labels[index]
plt.imshow(test_images[index])
plt.title('index: {}, Predict: {}, Label: {}'.format(index, select, label), fontsize=15)
plt.show()