
|
#



#  #
# |
#
# George Box (via Dustin Tran):
#
|
#
#  #
# |
#
#  #
# |
#
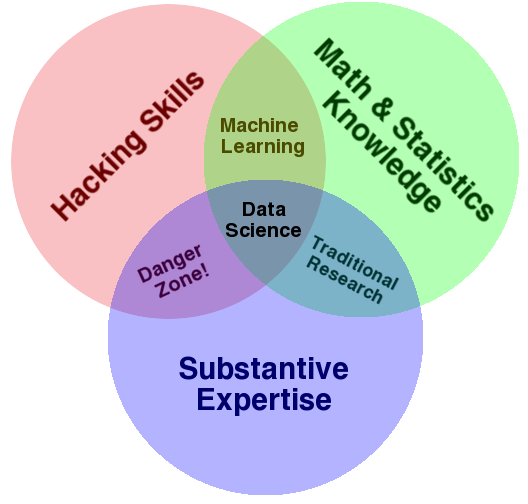 |
#  |
#


 #
# ### [@AustinRochford](https://twitter.com/AustinRochford) • [austinrochford.com](http://austinrochford.com) • [github.com/AustinRochford](http://github.com/AustinRochford)
#
# ### [austin.rochford@gmail.com](mailto:arochford@monetate.com) • [arochford@monetate.com](mailto:arochford@monetate.com)
# The code in the following cell converts this notebook to an HTML slideshow powered by [reveal.js](http://lab.hakim.se/reveal-js/).
# In[134]:
get_ipython().run_cell_magic('bash', '', 'jupyter nbconvert \\\n --to=slides \\\n --reveal-prefix=https://cdnjs.cloudflare.com/ajax/libs/reveal.js/3.2.0/ \\\n --output=nba-fouls-pydata-nyc-2017 \\\n ./PyData\\ NYC\\ 2017\\ Understanding\\ NBA\\ Foul\\ Calls\\ with\\ Python.ipynb\n')
#
# ### [@AustinRochford](https://twitter.com/AustinRochford) • [austinrochford.com](http://austinrochford.com) • [github.com/AustinRochford](http://github.com/AustinRochford)
#
# ### [austin.rochford@gmail.com](mailto:arochford@monetate.com) • [arochford@monetate.com](mailto:arochford@monetate.com)
# The code in the following cell converts this notebook to an HTML slideshow powered by [reveal.js](http://lab.hakim.se/reveal-js/).
# In[134]:
get_ipython().run_cell_magic('bash', '', 'jupyter nbconvert \\\n --to=slides \\\n --reveal-prefix=https://cdnjs.cloudflare.com/ajax/libs/reveal.js/3.2.0/ \\\n --output=nba-fouls-pydata-nyc-2017 \\\n ./PyData\\ NYC\\ 2017\\ Understanding\\ NBA\\ Foul\\ Calls\\ with\\ Python.ipynb\n')