Семинар 13. Понижение размерности данных (отбор признаков)¶

Основная цель: каким-либо образом "уменьшить" число признаков.
Почему это может быть важно:
Проклятие размерности¶
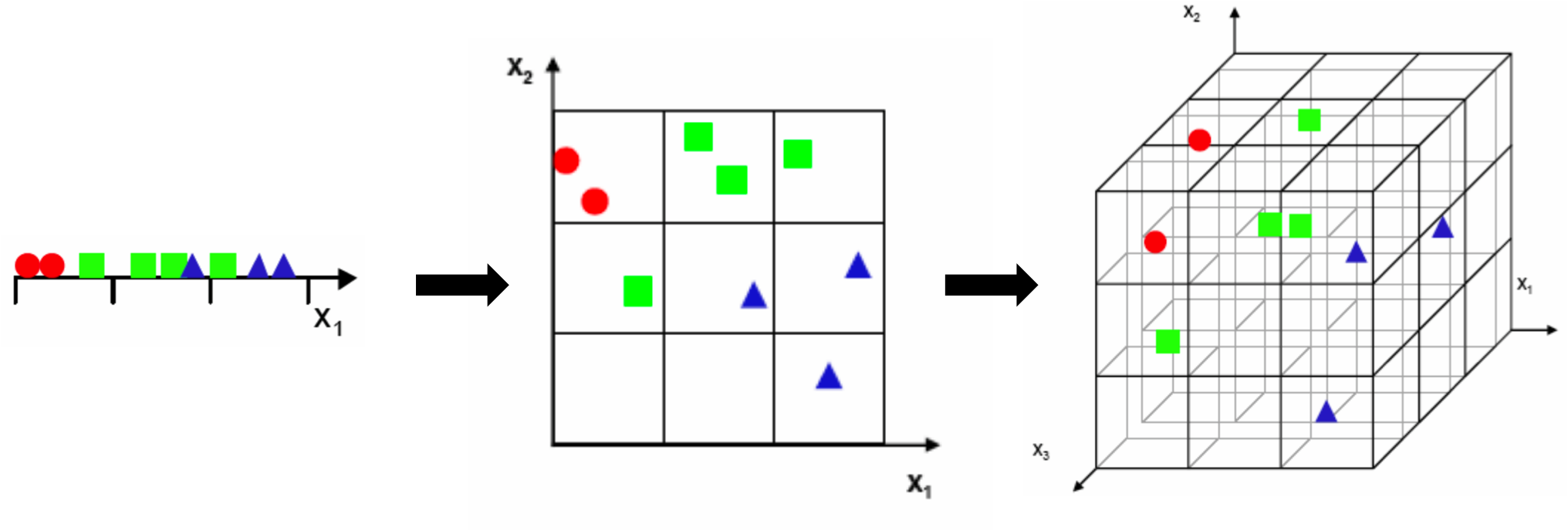
Рассмотрим пример (аналогично пончикам с лекции): пусть есть треугольники, круги и квадратики. Будем считать что признаки принимают значения только из какого-то интервала. Если есть всего один признак, то объекты лежат "примерно" рядом. В случае двух признаков они находятся дальше друг от друга. При увеличении размерности объекты будут все дальше друг от друга. То есть чем больше пространство, тем объекты становятся более "непохожими" (лежат далеко друг от друга). Получается, нужно много данных, чтобы алгоритм мог с ними работать (что порой затруднительно).
Шумовые и просто плохие признаки¶
Присутствие шума в признаках может ухудшать модель. Будем решать задачу классификации.
import numpy as np
import pandas as pd
import pylab as plt
%precision 3
%matplotlib inline
import sklearn.datasets
from sklearn.cross_validation import train_test_split
Рассмотрим некоторую случайную выборку, где все признаки "хорошие". Разделим ее на обучающую и тестовую:
X, y = sklearn.datasets.make_classification(n_redundant=0, random_state=42)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.5, random_state=42)
В качестве модели будем использовать логистическую регрессию. Для оценки качества воспользуемся метрикой Accuracy.
from sklearn.linear_model import LogisticRegressionCV
from sklearn.metrics import accuracy_score
Обучим нашу модель и посчитаем ее качество:
lr = LogisticRegressionCV(Cs=[0.01, 0.1, 1.0], random_state=42)
lr.fit(X_train, y_train)
accuracy_score(y_test, lr.predict(X_test))
0.940
Теперь к обучающим и тестовым данным добавим признак, не несущий никакой информации, а являющийся равномерным шумом на интервале от 0 до 1.
X_train_noise = np.concatenate([X_train, np.random.uniform(size=(X_train.shape[0], 1))], axis=1)
X_test_noise = np.concatenate([X_test, np.random.uniform(size=(X_test.shape[0], 1))], axis=1)
lr = LogisticRegressionCV(Cs=[0.01, 0.1, 1.0], random_state=42)
lr.fit(X_train_noise, y_train)
accuracy_score(y_test, lr.predict(X_test_noise))
0.920
Можно заметить, что качество стало чуть хуже.
Аналогично и для "плохих" признаков (в данном случае — коррелирующих). Добавим к исходным данным первый признак умноженый на 2.
X_train_corr = np.concatenate([X_train, (X_train[:,0] * 2)[:, np.newaxis]], axis=1)
X_test_corr = np.concatenate([X_test, (X_test[:, 0] * 2)[:, np.newaxis]], axis=1)
lr = LogisticRegressionCV(Cs=[0.01, 0.1, 1.0], random_state=42)
lr.fit(X_train_corr, y_train)
accuracy_score(y_test, lr.predict(X_test_corr))
0.920
Качество снова стало чуть ниже.
К сожалению, сходу не всегда понятно какие именно из признаков являются шумовыми.
Переобучение¶
Чем больше признаков, тем сложнее становится модель (например, в случае линейных — нужно находить больше коэффициентов). Таким образом, если признаков очень много, а данных не совсем — можно столкнуться с переобучением.
Какие еще проблемы возникают при большом числе признаков?
Отбор признаков¶
- Одномерные методы — оценивают важность признаков по отдельности
Например, использую оценку дисперсии признака:
from sklearn.feature_selection import VarianceThreshold
from sklearn.feature_selection import SelectKBest
from sklearn.feature_selection import f_classif
X = [[0, 0, 1],
[0, 1, 0],
[1, 0, 0],
[0, 1, 1],
[0, 1, 0],
[0, 1, 1]]
sel = VarianceThreshold(0.2)
sel.fit(X)
X_new = sel.fit_transform(X)
sel.variances_
array([ 0.139, 0.222, 0.25 ])
sel = VarianceThreshold(0.2)
X_new = sel.fit_transform(X)
X_new
array([[0, 1],
[1, 0],
[0, 0],
[1, 1],
[1, 0],
[1, 1]])
Теперь попробуем поработать с реальными данными.
Рассмотрим датасет Титаник:
data = pd.read_csv('titanic.csv')
data.head()
| PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 0 | 3 | Braund, Mr. Owen Harris | male | 22 | 1 | 0 | A/5 21171 | 7.2500 | NaN | S |
| 1 | 2 | 1 | 1 | Cumings, Mrs. John Bradley (Florence Briggs Th... | female | 38 | 1 | 0 | PC 17599 | 71.2833 | C85 | C |
| 2 | 3 | 1 | 3 | Heikkinen, Miss. Laina | female | 26 | 0 | 0 | STON/O2. 3101282 | 7.9250 | NaN | S |
| 3 | 4 | 1 | 1 | Futrelle, Mrs. Jacques Heath (Lily May Peel) | female | 35 | 1 | 0 | 113803 | 53.1000 | C123 | S |
| 4 | 5 | 0 | 3 | Allen, Mr. William Henry | male | 35 | 0 | 0 | 373450 | 8.0500 | NaN | S |
Оставим только числовые признаки (а пол перекодируем в 0 и 1), выкинем объекты с пропусками:
X = data[['Pclass', 'Age', 'SibSp', 'Parch', 'Fare']]
X['Sex'] = (data.Sex == 'male').astype('int')
X = X.dropna(axis=0)
y = data.Survived[X.index]
X.head()
| Pclass | Age | SibSp | Parch | Fare | Sex | |
|---|---|---|---|---|---|---|
| 0 | 3 | 22 | 1 | 0 | 7.2500 | 1 |
| 1 | 1 | 38 | 1 | 0 | 71.2833 | 0 |
| 2 | 3 | 26 | 0 | 0 | 7.9250 | 0 |
| 3 | 1 | 35 | 1 | 0 | 53.1000 | 0 |
| 4 | 3 | 35 | 0 | 0 | 8.0500 | 1 |
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=42)
Теперь посмотрим какие признаки с точки зрения одномерных методов важны.
Функция SelectKBest позволяет выбрать k наиболее важных признаков из модели с помощью заданного метода, после чего оставить только их. Так как в данном случае нам интересно скорее посмотреть на сами признаки, просто рассмотрим какие "важности" мы получаем, используя этот метод.
selector = SelectKBest(f_classif, k=2)
selector.fit(X_train, y_train)
SelectKBest(k=2, score_func=<function f_classif at 0x10a10f1b8>)
Посмотрим на полученные значения:
scores = selector.scores_
scores
array([ 6.771e+01, 8.380e+00, 5.096e-03, 3.647e+00, 4.239e+01,
2.354e+02])
idx = np.arange(scores.size)
width = 0.5
p1 = plt.bar(idx, scores, width, color='g')
plt.xticks(idx + width/2, X.columns)[1]
<a list of 6 Text xticklabel objects>

Итак, получили что пол, класс и цена билета хорошо связаны с целевой меткой (с точки зрения этого метода), в то время как SibSp имеет относительно малую значимость. Посмотрим, найдутся ли эти закономерности, если мы попробуем воспользоваться другой группой методов.
- Отбор с помощью моделей
Некоторые изученные модели позволяют оценить "важность" признаков.
Например:
- коэффициенты в линейных моделях можно интерпретировать как "важности" признаков в случае смасштабированных данных (а в случае L1-регуляризации коэффициенты при неважных признаках зануляются, например, в Lasso)
- RandomForest (и просто решающее дерево) умеют оценивать насколько важен был признак
Попробуем понять, являются ли эти празнаки также важными с точки зрения моделей.
Для начала рассмотрим знакомую нам линейную модель (логистическую регрессию):
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
lr = LogisticRegressionCV(Cs=[0.1, 1.0, 10], random_state=42)
lr.fit(X_train_scaled, y_train)
LogisticRegressionCV(Cs=[0.1, 1.0, 10], class_weight=None, cv=None,
dual=False, fit_intercept=True, intercept_scaling=1.0,
max_iter=100, multi_class='ovr', n_jobs=1, penalty='l2',
random_state=42, refit=True, scoring=None, solver='lbfgs',
tol=0.0001, verbose=0)
coef = lr.coef_
coef
array([[-1.026, -0.727, -0.337, -0.081, 0.111, -1.282]])
Построим коэффициенты на диаграмме для более удобного сравнения (в качестве "важности" считаем модуль коэффициента):
idx = np.arange(coef.size)
width = 0.5
p1 = plt.bar(idx, np.abs(coef[0]), width, color='g')
plt.xticks(idx + width/2, X.columns)[1]
<a list of 6 Text xticklabel objects>

И посмотрим на качество модели:
X_test_scaled = scaler.transform(X_test)
accuracy_score(y_test, lr.predict(X_test_scaled))
0.771
А теперь случайный лес:
from sklearn.ensemble import RandomForestClassifier
rf = RandomForestClassifier(n_estimators=1000, random_state=42)
rf.fit(X_train, y_train)
RandomForestClassifier(bootstrap=True, class_weight=None, criterion='gini',
max_depth=None, max_features='auto', max_leaf_nodes=None,
min_samples_leaf=1, min_samples_split=2,
min_weight_fraction_leaf=0.0, n_estimators=1000, n_jobs=1,
oob_score=False, random_state=42, verbose=0, warm_start=False)
Теперь посчитаем важности признаков:
importance = rf.feature_importances_
importance
array([ 0.089, 0.303, 0.044, 0.036, 0.268, 0.26 ])
В данном случае само значение важности не несет какой-то глубокой информации (кроме как чем больше — тем лучше), оно скорее важно для сравнения признаков между собой.
idx = np.arange(importance.size)
width = 0.5
p1 = plt.bar(idx, importance, width, color='g')
plt.xticks(idx + width/2, X.columns)[1]
<a list of 6 Text xticklabel objects>

Вполне логично, что возраст, пол и цена билета (которая неявно указывает на класс пассажира) важны в этой задаче.
accuracy_score(y_test, rf.predict(X_test))
0.782
Если сравнивать с предыдущим методом отбора признаков, то можно сказать что модели также находят указанные закономерности в данных.
Обе модели показали сравнимое качество, но в тоже время выбрали разные "важные признаки". Так как модели имеют разную природу, следовательно влияние признаков вычисляется по-разному. Это необходимо помнить, но также уметь сравнивать результаты: по обеим моделям явно видно, что возраст, как и пол, достаточно хорошие признаки. В то же время цена билета явно зависела от класса, поэтому это нормально что одна модель обратила внимание на цену, а другая — на класс.
Давайте посмотрим какое качество будет иметь случайный лес, если мы хотим оставить всего три признака:
- Pclass, Fare, Sex (от одномерного метода)
- Pclass, Age, Sex (от линейного метода)
- Age, Fare, Sex (от случайного леса)
rf = RandomForestClassifier(n_estimators=1000, random_state=42)
rf.fit(X_train[['Pclass', 'Fare', 'Sex']], y_train)
accuracy_score(y_test, rf.predict(X_test[['Pclass', 'Fare', 'Sex']]))
0.804
rf = RandomForestClassifier(n_estimators=1000, random_state=42)
rf.fit(X_train[['Pclass', 'Age', 'Sex']], y_train)
accuracy_score(y_test, rf.predict(X_test[['Pclass', 'Age', 'Sex']]))
0.771
rf = RandomForestClassifier(n_estimators=1000, random_state=42)
rf.fit(X_train[['Age', 'Fare', 'Sex']], y_train)
accuracy_score(y_test, rf.predict(X_test[['Age', 'Fare', 'Sex']]))
0.771
Обратите внимание, что отбор признаков нужно проводить на отложенной выборке.