Algunas perlitas¶
Generadores¶
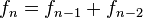


In [1]:
def fibonacci(n):
valores = []
a, b = 0, 1
while len(valores) < n:
valores.append(b)
a, b = b, a + b
return valores
In [2]:
fibonacci(10)
Out[2]:
[1, 1, 2, 3, 5, 8, 13, 21, 34, 55]
In [3]:
%timeit fibonacci(1000)
1000 loops, best of 3: 230 µs per loop
In [4]:
def fibonacci_gen(n):
a, b, i = 0, 1, 0
while i < n:
yield b
a, b = b, a + b
i += 1
In [5]:
fibonacci_gen(10)
Out[5]:
<generator object fibonacci_gen at 0x7f83441583f0>
In [6]:
%timeit fibonacci_gen(1000)
The slowest run took 30.60 times longer than the fastest. This could mean that an intermediate result is being cached 1000000 loops, best of 3: 270 ns per loop
List Comprehensions¶
In [7]:
valores = [3, 4, 1, 8, 12, 92, 34, 1, 52, 11, 8]
In [8]:
[x ** 2 for x in valores]
Out[8]:
[9, 16, 1, 64, 144, 8464, 1156, 1, 2704, 121, 64]
In [9]:
[x ** 2 for x in valores if x < 15]
Out[9]:
[9, 16, 1, 64, 144, 1, 121, 64]
Espacio de nombres¶
In [10]:
def funcion(x, y):
print(x, y)
In [11]:
funcion(3, 4)
3 4
In [12]:
x = 5
def funcion(x, y):
print(x, y)
In [13]:
funcion(3, 4)
3 4
In [14]:
z = 5
def funcion(x, y):
global z
z = 8
print(x, y)
In [15]:
print(z)
5
In [16]:
funcion(3, 4)
3 4
In [17]:
print(z)
8
Context Managers¶
In [18]:
%%file usuarios.csv
juan,gonzalez,33
pedro,martinez,24
susana,romero,54
Writing usuarios.csv
In [19]:
import csv
with open('usuarios.csv', 'r') as fh:
for line in csv.reader(fh):
line = [l.capitalize() for l in line]
print('Nombre: {}\nApellido: {}\nEdad: {}\n\n'.format(
line[0], line[1], line[2]))
Nombre: Juan Apellido: Gonzalez Edad: 33 Nombre: Pedro Apellido: Martinez Edad: 24 Nombre: Susana Apellido: Romero Edad: 54
Decoradores¶
In [20]:
def alcubo(n):
return n ** 3
In [21]:
alcubo(5)
Out[21]:
125
In [22]:
import time
def log(f):
def wrapper(*args, **kwargs):
st = time.time()
print('Antes: {}'.format(st))
resultado = f(*args, **kwargs)
et = time.time()
print('Despues: {}'.format(et))
print('Tiempo total: {}'.format(et - st))
return resultado
return wrapper
In [23]:
@log
def alcubo(n):
return n ** 3
In [24]:
alcubo(5)
Antes: 1432863987.6773825 Despues: 1432863987.6774247 Tiempo total: 4.220008850097656e-05
Out[24]:
125
In [ ]: