Character Sequence to Sequence¶
In this notebook, we'll build a model that takes in a sequence of letters, and outputs a sorted version of that sequence. We'll do that using what we've learned so far about Sequence to Sequence models. This notebook was updated to work with TensorFlow 1.1 and builds on the work of Dave Currie. Check out Dave's post Text Summarization with Amazon Reviews.

Dataset¶
The dataset lives in the /data/ folder. At the moment, it is made up of the following files:
- letters_source.txt: The list of input letter sequences. Each sequence is its own line.
- letters_target.txt: The list of target sequences we'll use in the training process. Each sequence here is a response to the input sequence in letters_source.txt with the same line number.
import numpy as np
import time
import helper
source_path = 'data/letters_source.txt'
target_path = 'data/letters_target.txt'
source_sentences = helper.load_data(source_path)
target_sentences = helper.load_data(target_path)
Let's start by examining the current state of the dataset. source_sentences contains the entire input sequence file as text delimited by newline symbols.
source_sentences[:50].split('\n')
target_sentences contains the entire output sequence file as text delimited by newline symbols. Each line corresponds to the line from source_sentences. target_sentences contains a sorted characters of the line.
target_sentences[:50].split('\n')
Preprocess¶
To do anything useful with it, we'll need to turn the each string into a list of characters:

Then convert the characters to their int values as declared in our vocabulary:
def extract_character_vocab(data):
special_words = ['<PAD>', '<UNK>', '<GO>', '<EOS>']
set_words = set([character for line in data.split('\n') for character in line])
int_to_vocab = {word_i: word for word_i, word in enumerate(special_words + list(set_words))}
vocab_to_int = {word: word_i for word_i, word in int_to_vocab.items()}
return int_to_vocab, vocab_to_int
# Build int2letter and letter2int dicts
source_int_to_letter, source_letter_to_int = extract_character_vocab(source_sentences)
target_int_to_letter, target_letter_to_int = extract_character_vocab(target_sentences)
# Convert characters to ids
source_letter_ids = [[source_letter_to_int.get(letter, source_letter_to_int['<UNK>']) for letter in line] for line in source_sentences.split('\n')]
target_letter_ids = [[target_letter_to_int.get(letter, target_letter_to_int['<UNK>']) for letter in line] + [target_letter_to_int['<EOS>']] for line in target_sentences.split('\n')]
print("Example source sequence")
print(source_letter_ids[:3])
print("\n")
print("Example target sequence")
print(target_letter_ids[:3])
This is the final shape we need them to be in. We can now proceed to building the model.
from distutils.version import LooseVersion
import tensorflow as tf
from tensorflow.python.layers.core import Dense
# Check TensorFlow Version
assert LooseVersion(tf.__version__) >= LooseVersion('1.1'), 'Please use TensorFlow version 1.1 or newer'
print('TensorFlow Version: {}'.format(tf.__version__))
Hyperparameters¶
# Number of Epochs
epochs = 60
# Batch Size
batch_size = 128
# RNN Size
rnn_size = 50
# Number of Layers
num_layers = 2
# Embedding Size
encoding_embedding_size = 15
decoding_embedding_size = 15
# Learning Rate
learning_rate = 0.001
Input¶
def get_model_inputs():
input_data = tf.placeholder(tf.int32, [None, None], name='input')
targets = tf.placeholder(tf.int32, [None, None], name='targets')
lr = tf.placeholder(tf.float32, name='learning_rate')
target_sequence_length = tf.placeholder(tf.int32, (None,), name='target_sequence_length')
max_target_sequence_length = tf.reduce_max(target_sequence_length, name='max_target_len')
source_sequence_length = tf.placeholder(tf.int32, (None,), name='source_sequence_length')
return input_data, targets, lr, target_sequence_length, max_target_sequence_length, source_sequence_length
Sequence to Sequence Model¶
We can now start defining the functions that will build the seq2seq model. We are building it from the bottom up with the following components:
2.1 Encoder
- Embedding
- Encoder cell
2.2 Decoder
1- Process decoder inputs
2- Set up the decoder
- Embedding
- Decoder cell
- Dense output layer
- Training decoder
- Inference decoder
2.3 Seq2seq model connecting the encoder and decoder
2.4 Build the training graph hooking up the model with the
optimizer
2.1 Encoder¶
The first bit of the model we'll build is the encoder. Here, we'll embed the input data, construct our encoder, then pass the embedded data to the encoder.
- Embed the input data using
tf.contrib.layers.embed_sequence

- Pass the embedded input into a stack of RNNs. Save the RNN state and ignore the output.

def encoding_layer(input_data, rnn_size, num_layers,
source_sequence_length, source_vocab_size,
encoding_embedding_size):
# Encoder embedding
enc_embed_input = tf.contrib.layers.embed_sequence(input_data, source_vocab_size, encoding_embedding_size)
# RNN cell
def make_cell(rnn_size):
enc_cell = tf.contrib.rnn.LSTMCell(rnn_size,
initializer=tf.random_uniform_initializer(-0.1, 0.1, seed=2))
return enc_cell
enc_cell = tf.contrib.rnn.MultiRNNCell([make_cell(rnn_size) for _ in range(num_layers)])
enc_output, enc_state = tf.nn.dynamic_rnn(enc_cell, enc_embed_input, sequence_length=source_sequence_length, dtype=tf.float32)
return enc_output, enc_state
2.2 Decoder¶
The decoder is probably the most involved part of this model. The following steps are needed to create it:
1- Process decoder inputs
2- Set up the decoder components
- Embedding
- Decoder cell
- Dense output layer
- Training decoder
- Inference decoder
Process Decoder Input¶
In the training process, the target sequences will be used in two different places:
- Using them to calculate the loss
- Feeding them to the decoder during training to make the model more robust.
Now we need to address the second point. Let's assume our targets look like this in their letter/word form (we're doing this for readibility. At this point in the code, these sequences would be in int form):
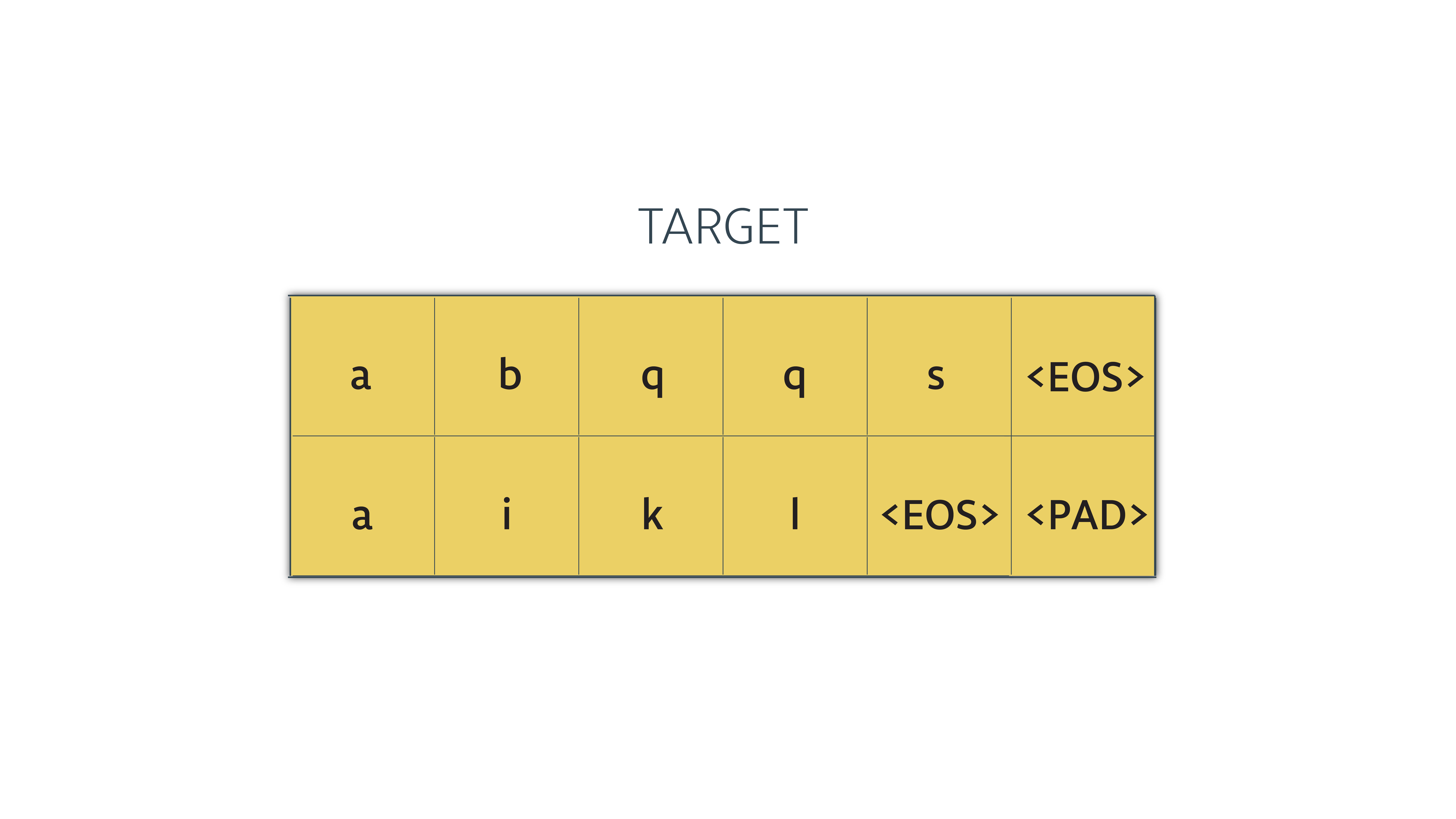
We need to do a simple transformation on the tensor before feeding it to the decoder:
1- We will feed an item of the sequence to the decoder at each time step. Think about the last timestep -- where the decoder outputs the final word in its output. The input to that step is the item before last from the target sequence. The decoder has no use for the last item in the target sequence in this scenario. So we'll need to remove the last item.
We do that using tensorflow's tf.strided_slice() method. We hand it the tensor, and the index of where to start and where to end the cutting.

2- The first item in each sequence we feed to the decoder has to be GO symbol. So We'll add that to the beginning.

Now the tensor is ready to be fed to the decoder. It looks like this (if we convert from ints to letters/symbols):

# Process the input we'll feed to the decoder
def process_decoder_input(target_data, vocab_to_int, batch_size):
'''Remove the last word id from each batch and concat the <GO> to the begining of each batch'''
ending = tf.strided_slice(target_data, [0, 0], [batch_size, -1], [1, 1])
dec_input = tf.concat([tf.fill([batch_size, 1], vocab_to_int['<GO>']), ending], 1)
return dec_input
Set up the decoder components¶
- Embedding
- Decoder cell
- Dense output layer
- Training decoder
- Inference decoder
1- Embedding¶
Now that we have prepared the inputs to the training decoder, we need to embed them so they can be ready to be passed to the decoder.
We'll create an embedding matrix like the following then have tf.nn.embedding_lookup convert our input to its embedded equivalent:

2- Decoder Cell¶
Then we declare our decoder cell. Just like the encoder, we'll use an tf.contrib.rnn.LSTMCell here as well.
We need to declare a decoder for the training process, and a decoder for the inference/prediction process. These two decoders will share their parameters (so that all the weights and biases that are set during the training phase can be used when we deploy the model).
First, we'll need to define the type of cell we'll be using for our decoder RNNs. We opted for LSTM.
3- Dense output layer¶
Before we move to declaring our decoders, we'll need to create the output layer, which will be a tensorflow.python.layers.core.Dense layer that translates the outputs of the decoder to logits that tell us which element of the decoder vocabulary the decoder is choosing to output at each time step.
4- Training decoder¶
Essentially, we'll be creating two decoders which share their parameters. One for training and one for inference. The two are similar in that both created using tf.contrib.seq2seq.BasicDecoder and tf.contrib.seq2seq.dynamic_decode. They differ, however, in that we feed the the target sequences as inputs to the training decoder at each time step to make it more robust.
We can think of the training decoder as looking like this (except that it works with sequences in batches):

The training decoder does not feed the output of each time step to the next. Rather, the inputs to the decoder time steps are the target sequence from the training dataset (the orange letters).
5- Inference decoder¶
The inference decoder is the one we'll use when we deploy our model to the wild.

We'll hand our encoder hidden state to both the training and inference decoders and have it process its output. TensorFlow handles most of the logic for us. We just have to use the appropriate methods from tf.contrib.seq2seq and supply them with the appropriate inputs.
def decoding_layer(target_letter_to_int, decoding_embedding_size, num_layers, rnn_size,
target_sequence_length, max_target_sequence_length, enc_state, dec_input):
# 1. Decoder Embedding
target_vocab_size = len(target_letter_to_int)
dec_embeddings = tf.Variable(tf.random_uniform([target_vocab_size, decoding_embedding_size]))
dec_embed_input = tf.nn.embedding_lookup(dec_embeddings, dec_input)
# 2. Construct the decoder cell
def make_cell(rnn_size):
dec_cell = tf.contrib.rnn.LSTMCell(rnn_size,
initializer=tf.random_uniform_initializer(-0.1, 0.1, seed=2))
return dec_cell
dec_cell = tf.contrib.rnn.MultiRNNCell([make_cell(rnn_size) for _ in range(num_layers)])
# 3. Dense layer to translate the decoder's output at each time
# step into a choice from the target vocabulary
output_layer = Dense(target_vocab_size,
kernel_initializer = tf.truncated_normal_initializer(mean = 0.0, stddev=0.1))
# 4. Set up a training decoder and an inference decoder
# Training Decoder
with tf.variable_scope("decode"):
# Helper for the training process. Used by BasicDecoder to read inputs.
training_helper = tf.contrib.seq2seq.TrainingHelper(inputs=dec_embed_input,
sequence_length=target_sequence_length,
time_major=False)
# Basic decoder
training_decoder = tf.contrib.seq2seq.BasicDecoder(dec_cell,
training_helper,
enc_state,
output_layer)
# Perform dynamic decoding using the decoder
training_decoder_output = tf.contrib.seq2seq.dynamic_decode(training_decoder,
impute_finished=True,
maximum_iterations=max_target_sequence_length)[0]
# 5. Inference Decoder
# Reuses the same parameters trained by the training process
with tf.variable_scope("decode", reuse=True):
start_tokens = tf.tile(tf.constant([target_letter_to_int['<GO>']], dtype=tf.int32), [batch_size], name='start_tokens')
# Helper for the inference process.
inference_helper = tf.contrib.seq2seq.GreedyEmbeddingHelper(dec_embeddings,
start_tokens,
target_letter_to_int['<EOS>'])
# Basic decoder
inference_decoder = tf.contrib.seq2seq.BasicDecoder(dec_cell,
inference_helper,
enc_state,
output_layer)
# Perform dynamic decoding using the decoder
inference_decoder_output = tf.contrib.seq2seq.dynamic_decode(inference_decoder,
impute_finished=True,
maximum_iterations=max_target_sequence_length)[0]
return training_decoder_output, inference_decoder_output
2.3 Seq2seq model¶
Let's now go a step above, and hook up the encoder and decoder using the methods we just declared
def seq2seq_model(input_data, targets, lr, target_sequence_length,
max_target_sequence_length, source_sequence_length,
source_vocab_size, target_vocab_size,
enc_embedding_size, dec_embedding_size,
rnn_size, num_layers):
# Pass the input data through the encoder. We'll ignore the encoder output, but use the state
_, enc_state = encoding_layer(input_data,
rnn_size,
num_layers,
source_sequence_length,
source_vocab_size,
encoding_embedding_size)
# Prepare the target sequences we'll feed to the decoder in training mode
dec_input = process_decoder_input(targets, target_letter_to_int, batch_size)
# Pass encoder state and decoder inputs to the decoders
training_decoder_output, inference_decoder_output = decoding_layer(target_letter_to_int,
decoding_embedding_size,
num_layers,
rnn_size,
target_sequence_length,
max_target_sequence_length,
enc_state,
dec_input)
return training_decoder_output, inference_decoder_output
Model outputs training_decoder_output and inference_decoder_output both contain a 'rnn_output' logits tensor that looks like this:

The logits we get from the training tensor we'll pass to tf.contrib.seq2seq.sequence_loss() to calculate the loss and ultimately the gradient.
# Build the graph
train_graph = tf.Graph()
# Set the graph to default to ensure that it is ready for training
with train_graph.as_default():
# Load the model inputs
input_data, targets, lr, target_sequence_length, max_target_sequence_length, source_sequence_length = get_model_inputs()
# Create the training and inference logits
training_decoder_output, inference_decoder_output = seq2seq_model(input_data,
targets,
lr,
target_sequence_length,
max_target_sequence_length,
source_sequence_length,
len(source_letter_to_int),
len(target_letter_to_int),
encoding_embedding_size,
decoding_embedding_size,
rnn_size,
num_layers)
# Create tensors for the training logits and inference logits
training_logits = tf.identity(training_decoder_output.rnn_output, 'logits')
inference_logits = tf.identity(inference_decoder_output.sample_id, name='predictions')
# Create the weights for sequence_loss
masks = tf.sequence_mask(target_sequence_length, max_target_sequence_length, dtype=tf.float32, name='masks')
with tf.name_scope("optimization"):
# Loss function
cost = tf.contrib.seq2seq.sequence_loss(
training_logits,
targets,
masks)
# Optimizer
optimizer = tf.train.AdamOptimizer(lr)
# Gradient Clipping
gradients = optimizer.compute_gradients(cost)
capped_gradients = [(tf.clip_by_value(grad, -5., 5.), var) for grad, var in gradients if grad is not None]
train_op = optimizer.apply_gradients(capped_gradients)
Get Batches¶
There's little processing involved when we retreive the batches. This is a simple example assuming batch_size = 2
Source sequences (it's actually in int form, we're showing the characters for clarity):

Target sequences (also in int, but showing letters for clarity):

def pad_sentence_batch(sentence_batch, pad_int):
"""Pad sentences with <PAD> so that each sentence of a batch has the same length"""
max_sentence = max([len(sentence) for sentence in sentence_batch])
return [sentence + [pad_int] * (max_sentence - len(sentence)) for sentence in sentence_batch]
def get_batches(targets, sources, batch_size, source_pad_int, target_pad_int):
"""Batch targets, sources, and the lengths of their sentences together"""
for batch_i in range(0, len(sources)//batch_size):
start_i = batch_i * batch_size
sources_batch = sources[start_i:start_i + batch_size]
targets_batch = targets[start_i:start_i + batch_size]
pad_sources_batch = np.array(pad_sentence_batch(sources_batch, source_pad_int))
pad_targets_batch = np.array(pad_sentence_batch(targets_batch, target_pad_int))
# Need the lengths for the _lengths parameters
pad_targets_lengths = []
for target in pad_targets_batch:
pad_targets_lengths.append(len(target))
pad_source_lengths = []
for source in pad_sources_batch:
pad_source_lengths.append(len(source))
yield pad_targets_batch, pad_sources_batch, pad_targets_lengths, pad_source_lengths
Train¶
We're now ready to train our model. If you run into OOM (out of memory) issues during training, try to decrease the batch_size.
# Split data to training and validation sets
train_source = source_letter_ids[batch_size:]
train_target = target_letter_ids[batch_size:]
valid_source = source_letter_ids[:batch_size]
valid_target = target_letter_ids[:batch_size]
(valid_targets_batch, valid_sources_batch, valid_targets_lengths, valid_sources_lengths) = next(get_batches(valid_target, valid_source, batch_size,
source_letter_to_int['<PAD>'],
target_letter_to_int['<PAD>']))
display_step = 20 # Check training loss after every 20 batches
checkpoint = "best_model.ckpt"
with tf.Session(graph=train_graph) as sess:
sess.run(tf.global_variables_initializer())
for epoch_i in range(1, epochs+1):
for batch_i, (targets_batch, sources_batch, targets_lengths, sources_lengths) in enumerate(
get_batches(train_target, train_source, batch_size,
source_letter_to_int['<PAD>'],
target_letter_to_int['<PAD>'])):
# Training step
_, loss = sess.run(
[train_op, cost],
{input_data: sources_batch,
targets: targets_batch,
lr: learning_rate,
target_sequence_length: targets_lengths,
source_sequence_length: sources_lengths})
# Debug message updating us on the status of the training
if batch_i % display_step == 0 and batch_i > 0:
# Calculate validation cost
validation_loss = sess.run(
[cost],
{input_data: valid_sources_batch,
targets: valid_targets_batch,
lr: learning_rate,
target_sequence_length: valid_targets_lengths,
source_sequence_length: valid_sources_lengths})
print('Epoch {:>3}/{} Batch {:>4}/{} - Loss: {:>6.3f} - Validation loss: {:>6.3f}'
.format(epoch_i,
epochs,
batch_i,
len(train_source) // batch_size,
loss,
validation_loss[0]))
# Save Model
saver = tf.train.Saver()
saver.save(sess, checkpoint)
print('Model Trained and Saved')
Prediction¶
def source_to_seq(text):
'''Prepare the text for the model'''
sequence_length = 7
return [source_letter_to_int.get(word, source_letter_to_int['<UNK>']) for word in text]+ [source_letter_to_int['<PAD>']]*(sequence_length-len(text))
input_sentence = 'hello'
text = source_to_seq(input_sentence)
checkpoint = "./best_model.ckpt"
loaded_graph = tf.Graph()
with tf.Session(graph=loaded_graph) as sess:
# Load saved model
loader = tf.train.import_meta_graph(checkpoint + '.meta')
loader.restore(sess, checkpoint)
input_data = loaded_graph.get_tensor_by_name('input:0')
logits = loaded_graph.get_tensor_by_name('predictions:0')
source_sequence_length = loaded_graph.get_tensor_by_name('source_sequence_length:0')
target_sequence_length = loaded_graph.get_tensor_by_name('target_sequence_length:0')
#Multiply by batch_size to match the model's input parameters
answer_logits = sess.run(logits, {input_data: [text]*batch_size,
target_sequence_length: [len(text)]*batch_size,
source_sequence_length: [len(text)]*batch_size})[0]
pad = source_letter_to_int["<PAD>"]
print('Original Text:', input_sentence)
print('\nSource')
print(' Word Ids: {}'.format([i for i in text]))
print(' Input Words: {}'.format(" ".join([source_int_to_letter[i] for i in text])))
print('\nTarget')
print(' Word Ids: {}'.format([i for i in answer_logits if i != pad]))
print(' Response Words: {}'.format(" ".join([target_int_to_letter[i] for i in answer_logits if i != pad])))