Rhythm and Timbre Analysis from Music
Rhythm Pattern Music Features
Extraction and Application Tutorial
Thomas Lidy and Alexander Schindler
lidy@ifs.tuwien.ac.at
Institute of Software Technology and Interactive Systems
TU Wien
http://www.ifs.tuwien.ac.at/mir
Table of Contents¶
1. Requirements¶
This Tutorial uses iPython Notebook for interactive coding. If you use iPython Notebook, you can interactively execute your code (and the code here in the tutorial) directly in the Web browser. Otherwise you can copy & paste code from here to your prefered Python editor.
# to install iPython notebook on your computer, use this in Terminal
sudo pip install "ipython[notebook]"
RP Extract Library¶
This is our mean library for rhythmic and timbral audio feature analysis:
- RP_extract Rhythm Patterns Audio Feature Extraction Library (includes Wavio for reading wav files (incl. 24 bit))
download ZIP or check out from GitHub:
# in Terminal
git clone https://github.com/tuwien-musicir/rp_extract.git
Python Libraries¶
RP_extract depends on the following libraries. If not already included in your Python installation, please install these Python libraries using pip or easy_install:
- Numpy: the fundamental package for scientific computing with Python. It implements a wide range of fast and powerful algebraic functions.
- Scipy: Scientific Python library
- matplotlib: only needed for plotting (if you skipt the plots below, you are fine without)
They can usually be installed via Python PIP installer on command line:
# in Terminal
sudo pip install numpy scipy matplotlib
Additional Libraries¶
These libraries are used in the later tutorial steps, but not necessarily needed if you want to use the RP_extract library alone:
- mir_utils: these are additional functions used for the Soundcloud Demo data set in the tutorial below
- Soundcloud API: used to retrieve and analyze music from Soundcloud.com
- urllib: for downloading content from the web (may be pre-installed already, then you can skip it)
- unicsv: used in rp_extract_files.py for batch iteration over many wav or mp3 files, and storing features in CSV (only needed when you want to do batch feature extraction to CSV)
- sklearn: Scikit-Learn machine learning package - used in later tutorial steps for finding similar songs and/or using machine learning / classification
# in Terminal
sudo pip install soundcloud urllib unicsv scikit-learn
git clone https://github.com/tuwien-musicir/mir_utils.git
MP3 Decoder¶
If you want to use MP3 files as input, you need to have one of the following MP3 decoders installed in your system:
- Windows: FFMpeg (ffmpeg.exe is included in RP_extract library on Github above, nothing to install)
- Mac: Lame for Mac or FFMPeg for Mac
- Linux: please install mpg123, lame or ffmpeg from your Software Install Center or Package Repository
Note: If you don't install it to a path which can be found by the operating system, use this to add path where you installed the MP3 decoder binary to your system PATH so Python can call it:
import os
path = '/path/to/ffmpeg/'
os.environ['PATH'] += os.pathsep + path
Import + Test your Environment¶
If you have installed all required libraries, the follwing imports should run without errors.
%pylab inline
import warnings
warnings.filterwarnings('ignore')
%load_ext autoreload
%autoreload 2
# numerical processing and scientific libraries
import numpy as np
# plotting
import matplotlib.pyplot as plt
# reading wav and mp3 files
from audiofile_read import * # included in the rp_extract git package
# Rhythm Pattern Audio Extraction Library
from rp_extract_python import rp_extract
from rp_plot import * # can be skipped if you don't want to do any plots
# misc
from urllib import urlopen
import urllib2
import gzip
import StringIO
Populating the interactive namespace from numpy and matplotlib
Feature Extraction is the core of content-based description of audio files. With feature extraction from audio, a computer is able to recognize the content of a piece of music without the need of annotated labels such as artist, song title or genre. This is the essential basis for information retrieval tasks, such as similarity based searches (query-by-example, query-by-humming, etc.), automatic classification into categories, or automatic organization and clustering of music archives.
Content-based description requires the development of feature extraction techniques that analyze the acoustic characteristics of the signal. Features extracted from the audio signal are intended to describe the stylistic content of the music, e.g. beat, presence of voice, timbre, etc.
We use methods from digital signal processing and consider psycho-acoustic models in order to extract suitable semantic information from music. We developed various feature sets, which are appropriate for different tasks.
Load Audio Files¶
Load audio data from wav or mp3 file¶
We provide a library (audiofile_read.py) that is capable of reading WAV and MP3 files (MP3 through an external decoder, see Installation Requirements above).
Take any MP3 or WAV file on your disk - or download one from e.g. freemusicarchive.org.
# provide/adjust the path to your wav or mp3 file
audiofile = "music/1972-048 Elvis Presley - Burning Love 22khz.mp3"
samplerate, samplewidth, wavedata = audiofile_read(audiofile)
Decoding mp3 with: lame --quiet --decode "music/1972-048 Elvis Presley - Burning Love 22khz.mp3" "/var/folders/1_/bnncmvw96qvfqdy3yg98mzjm0000gn/T/tmpinv1MG.wav"
samplerate, samplewidth, wavedata = audiofile_read(audiofile, normalize=False)
Decoding mp3 with: lame --quiet --decode "music/1972-048 Elvis Presley - Burning Love 22khz.mp3" "/var/folders/1_/bnncmvw96qvfqdy3yg98mzjm0000gn/T/tmpHlV0MG.wav"
wavedata.shape
(5135, 2)
Note about Normalization: Normalization is automatically done by audiofile_read() above.
Usually, an audio file stores integer values for the samples. However, for audio processing we need float values that's why the audiofile_read library already converts the input data to float values in the range of (-1,1).
This is taken care of by audiofile_read. In the rare case you don't want to normalize, use this line instead of the one above:
samplerate, samplewidth, wavedata = audiofile_read(audiofile, normalize=False)
In case you use another library to read in WAV files (such as scipy.io.wavfile.read) please have a look into audiofile_read code to do the normalization in the same way. Note that scipy.io.wavfile.read does not correctly read 24bit WAV files.
Audio Information¶
Let's print some information about the audio file just read:
nsamples = wavedata.shape[0]
nchannels = wavedata.shape[1]
print "Successfully read audio file:", audiofile
print samplerate, "Hz,", samplewidth*8, "bit,", nchannels, "channel(s),", nsamples, "samples"
Successfully read audio file: music/1972-048 Elvis Presley - Burning Love 22khz.mp3 22050 Hz, 16 bit, 2 channel(s), 5135 samples
Plot Wave form¶
we use this to check if the WAV or MP3 file has been correctly loaded
max_samples_plot = 4 * samplerate # limit number of samples to plot (to 4 sec), to avoid graphical overflow
if nsamples < max_samples_plot:
max_samples_plot = nsamples
plot_waveform(wavedata[0:max_samples_plot], 16, 5);
Plotting Stereo

<matplotlib.figure.Figure at 0x1105508d0>
Audio Pre-processing¶
For audio processing and feature extraction, we use a single channel only.
Therefore in case we have a stereo signal, we combine the separate channels:
# use combine the channels by calculating their geometric mean
wavedata_mono = np.mean(wavedata, axis=1)
Below an example waveform of a mono channel after combining the stereo channels by arithmetic mean:
plot_waveform(wavedata_mono[0:max_samples_plot], 16, 3)
Plotting Mono

<matplotlib.figure.Figure at 0x1120e0e50>
plotstft(wavedata_mono, samplerate, binsize=512, ignore=True);

Rhythm Patterns¶
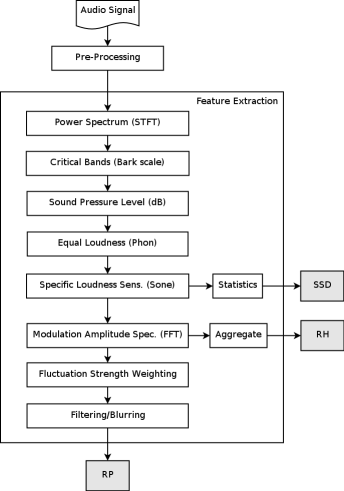
Rhythm Patterns (also called Fluctuation Patterns) describe modulation amplitudes for a range of modulation frequencies on "critical bands" of the human auditory range, i.e. fluctuations (or rhythm) on a number of frequency bands. The feature extraction process for the Rhythm Patterns is composed of two stages:
First, the specific loudness sensation in different frequency bands is computed, by using a Short Time FFT, grouping the resulting frequency bands to psycho-acoustically motivated critical-bands, applying spreading functions to account for masking effects and successive transformation into the decibel, Phon and Sone scales. This results in a power spectrum that reflects human loudness sensation (Sonogram).
In the second step, the spectrum is transformed into a time-invariant representation based on the modulation frequency, which is achieved by applying another discrete Fourier transform, resulting in amplitude modulations of the loudness in individual critical bands. These amplitude modulations have different effects on human hearing sensation depending on their frequency, the most significant of which, referred to as fluctuation strength, is most intense at 4 Hz and decreasing towards 15 Hz. From that data, reoccurring patterns in the individual critical bands, resembling rhythm, are extracted, which – after applying Gaussian smoothing to diminish small variations – result in a time-invariant, comparable representation of the rhythmic patterns in the individual critical bands.
features = rp_extract(wavedata, # the two-channel wave-data of the audio-file
samplerate, # the samplerate of the audio-file
extract_rp = True, # <== extract this feature!
transform_db = True, # apply psycho-accoustic transformation
transform_phon = True, # apply psycho-accoustic transformation
transform_sone = True, # apply psycho-accoustic transformation
fluctuation_strength_weighting=True, # apply psycho-accoustic transformation
skip_leadin_fadeout = 1, # skip lead-in/fade-out. value = number of segments skipped
step_width = 1) #
plotrp(features['rp'])

Statistical Spectrum Descriptor¶
The Sonogram is calculated as in the first part of the Rhythm Patterns calculation. According to the occurrence of beats or other rhythmic variation of energy on a specific critical band, statistical measures are able to describe the audio content. Our goal is to describe the rhythmic content of a piece of audio by computing the following statistical moments on the Sonogram values of each of the critical bands:
- mean, median, variance, skewness, kurtosis, min- and max-value
features = rp_extract(wavedata, # the two-channel wave-data of the audio-file
samplerate, # the samplerate of the audio-file
extract_ssd = True, # <== extract this feature!
transform_db = True, # apply psycho-accoustic transformation
transform_phon = True, # apply psycho-accoustic transformation
transform_sone = True, # apply psycho-accoustic transformation
fluctuation_strength_weighting=True, # apply psycho-accoustic transformation
skip_leadin_fadeout = 1, # skip lead-in/fade-out. value = number of segments skipped
step_width = 1) #
plotssd(features['ssd'])

Rhythm Histogram¶
The Rhythm Histogram features we use are a descriptor for general rhythmics in an audio document. Contrary to the Rhythm Patterns and the Statistical Spectrum Descriptor, information is not stored per critical band. Rather, the magnitudes of each modulation frequency bin of all critical bands are summed up, to form a histogram of "rhythmic energy" per modulation frequency. The histogram contains 60 bins which reflect modulation frequency between 0 and 10 Hz. For a given piece of audio, the Rhythm Histogram feature set is calculated by taking the median of the histograms of every 6 second segment processed.
features = rp_extract(wavedata, # the two-channel wave-data of the audio-file
samplerate, # the samplerate of the audio-file
extract_rh = True, # <== extract this feature!
transform_db = True, # apply psycho-accoustic transformation
transform_phon = True, # apply psycho-accoustic transformation
transform_sone = True, # apply psycho-accoustic transformation
fluctuation_strength_weighting=True, # apply psycho-accoustic transformation
skip_leadin_fadeout = 1, # skip lead-in/fade-out. value = number of segments skipped
step_width = 1) #
plotrh(features['rh'])

Get rough BPM from Rhythm Histogram¶
By looking at the maximum peak of a Rhythm Histogram, we can determine the beats per minute (BPM) very roughly by multiplying the Index of the Rhythm Histogram bin by the modulation frequency resolution (0.168 Hz) * 60. The resolution of this is however only at +/- 10 bpm.
maxbin = features['rh'].argmax(axis=0) + 1 # +1 because it starts from 0
mod_freq_res = 1.0 / (2**18/44100.0) # resolution of modulation frequency axis (0.168 Hz) (= 1/(segment_size/samplerate))
#print mod_freq_res * 60 # resolution
bpm = maxbin * mod_freq_res * 60
print bpm
60.5621337891
Modulation Frequency Variance Descriptor¶
This descriptor measures variations over the critical frequency bands for a specific modulation frequency (derived from a rhythm pattern).
Considering a rhythm pattern, i.e. a matrix representing the amplitudes of 60 modulation frequencies on 24 critical bands, an MVD vector is derived by computing statistical measures (mean, median, variance, skewness, kurtosis, min and max) for each modulation frequency over the 24 bands. A vector is computed for each of the 60 modulation frequencies. Then, an MVD descriptor for an audio file is computed by the mean of multiple MVDs from the audio file's segments, leading to a 420-dimensional vector.
Temporal Statistical Spectrum Descriptor¶
Feature sets are frequently computed on a per segment basis and do not incorporate time series aspects. As a consequence, TSSD features describe variations over time by including a temporal dimension. Statistical measures (mean, median, variance, skewness, kurtosis, min and max) are computed over the individual statistical spec- trum descriptors extracted from segments at different time positions within a piece of audio. This captures timbral variations and changes over time in the audio spectrum, for all the critical Bark-bands. Thus, a change of rhythmic, instruments, voices, etc. over time is reflected by this feature set. The dimension is 7 times the dimension of an SSD (i.e. 1176).
Temporal Rhythm Histograms¶
Statistical measures (mean, median, variance, skewness, kurtosis, min and max) are computed over the individual Rhythm Histograms extracted from various segments in a piece of audio. Thus, change and variation of rhythmic aspects in time are captured by this descriptor.
Extract All Features¶
To extract ALL or selected ones of the before described features, you can use this command:
# adapt the fext array to your needs:
fext = ['rp','ssd','rh','mvd'] # sh, tssd, trh
features = rp_extract(wavedata,
samplerate,
extract_rp = ('rp' in fext), # extract Rhythm Patterns features
extract_ssd = ('ssd' in fext), # extract Statistical Spectrum Descriptor
extract_sh = ('sh' in fext), # extract Statistical Histograms
extract_tssd = ('tssd' in fext), # extract temporal Statistical Spectrum Descriptor
extract_rh = ('rh' in fext), # extract Rhythm Histogram features
extract_trh = ('trh' in fext), # extract temporal Rhythm Histogram features
extract_mvd = ('mvd' in fext), # extract Modulation Frequency Variance Descriptor
spectral_masking=True,
transform_db=True,
transform_phon=True,
transform_sone=True,
fluctuation_strength_weighting=True,
skip_leadin_fadeout=1,
step_width=1)
# let's see what we got in our dict
print features.keys()
['ssd', 'rh', 'rp', 'mvd']
# list the feature type dimensions
for k in features.keys():
print k, features[k].shape
ssd (168,) rh (60,) rp (1440,) mvd (420,)
Analyze Songs from Soundcloud¶
4.1. Getting Songs from Soundcloud¶
In this step we are going to analyze songs from Soundcloud, using the Soundcloud API.
Please get your own API key first by clicking "Register New App" on https://developers.soundcloud.com.
Then we can start using the Soundcloud API:
# START SOUNDCLOUD API
import soundcloud
import urllib # for mp3 download
# To use soundcloud-python, you must first create a Client instance, passing at a minimum the client id you
# obtained when you registered your app:
# If you only need read-only access to public resources, simply provide a client id when creating a Client instance:
my_client_id= 'insert your soundcloud client id here'
client = soundcloud.Client(client_id=my_client_id)
# if there is no error after this, it should have worked
Get Track Info¶
# GET TRACK INFO
#soundcloud_url = 'http://soundcloud.com/forss/flickermood'
soundcloud_url = 'https://soundcloud.com/majorlazer/be-together-feat-wild-belle'
track = client.get('/resolve', url=soundcloud_url)
print "TRACK ID:", track.id
print "Title:", track.title
print "Artist: ", track.user['username']
print "Genre: ", track.genre
print track.bpm, "bpm"
print track.playback_count, "times played"
print track.download_count, "times downloaded"
print "Downloadable?", track.downloadable
TRACK ID: 208199477 Title: Major Lazer - Be Together (feat. Wild Belle) Artist: Major Lazer [OFFICIAL] Genre: Major Lazer None bpm 3736959 times played 0 times downloaded Downloadable? False
# if you want to see all information contained in 'track':
print vars(track)
Get Track URLs¶
if hasattr(track, 'download_url'):
print track.download_url
print track.stream_url
stream = client.get('/tracks/%d/streams' % track.id)
#print vars(stream)
print stream.http_mp3_128_url
https://api.soundcloud.com/tracks/208199477/stream https://ec-media.sndcdn.com/rUaqgMEvIAq2.128.mp3?f10880d39085a94a0418a7ef69b03d522cd6dfee9399eeb9a52202986afbb739d5ae703a547444c2ea4f10b53ee73e1d9907dbfbf42076407dc7bc785d37ea1a66e03f6405
Download Preview MP3¶
# set the MP3 download directory
mp3_dir = './music'
mp3_file = mp3_dir + os.sep + "%s.mp3" % track.title
# Download the 128 kbit stream MP3
urllib.urlretrieve (stream.http_mp3_128_url, mp3_file)
print "Downloaded " + mp3_file
Downloaded ./music/Major Lazer - Be Together (feat. Wild Belle).mp3
Iterate over a List of Soundcloud Tracks¶
This will take a number of Souncloud URLs and get the track info for them and download the mp3 stream if available.
# use your own soundcloud urls here
soundcloud_urls = [
'https://soundcloud.com/absencemusik/lana-del-rey-born-to-die-absence-remix',
'https://soundcloud.com/princefoxmusic/raindrops-feat-kerli-prince-fox-remix',
'https://soundcloud.com/octobersveryown/remyboyz-my-way-rmx-ft-drake'
]
mp3_dir = './music'
mp3_files = []
own_track_ids = []
for url in soundcloud_urls:
print url
track = client.get('/resolve', url=url)
mp3_file = mp3_dir + os.sep + "%s.mp3" % track.title
mp3_files.append(mp3_file)
own_track_ids.append(track.id)
stream = client.get('/tracks/%d/streams' % track.id)
if hasattr(stream, 'http_mp3_128_url'):
mp3_url = stream.http_mp3_128_url
elif hasattr(stream, 'preview_mp3_128_url'): # if we cant get the full mp3 we take the 1:30 preview
mp3_url = stream.preview_mp3_128_url
else:
print "No MP3 can be downloaded for this song."
mp3_url = None # in this case we can't get an mp3
if not mp3_url == None:
urllib.urlretrieve (mp3_url, mp3_file) # Download the 128 kbit stream MP3
print "Downloaded " + mp3_file
# show list of mp3 files we got:
# print mp3_files
https://soundcloud.com/absencemusik/lana-del-rey-born-to-die-absence-remix Downloaded ./music/Lana Del Rey - Born To Die (Absence Remix).mp3 https://soundcloud.com/princefoxmusic/raindrops-feat-kerli-prince-fox-remix Downloaded ./music/SNBRN - Raindrops feat. Kerli (Prince Fox Remix).mp3 https://soundcloud.com/octobersveryown/remyboyz-my-way-rmx-ft-drake Downloaded ./music/Remy Boyz - My Way RMX Ft. Drake.mp3
Analyze the previously loaded Songs¶
Now this combines reading all the MP3s we've got and analyzing the features
# mp3_files is the list of downloaded Soundcloud files as stored above (mp3_files.append())
# all_features will be a list of dict entries for all files
all_features = []
for mp3 in mp3_files:
# Read the Audio file
samplerate, samplewidth, wavedata = audiofile_read(mp3)
print "Successfully read audio file:", mp3
nsamples = wavedata.shape[0]
nchannels = wavedata.shape[1]
print samplerate, "Hz,", samplewidth*8, "bit,", nchannels, "channel(s),", nsamples, "samples"
# Extract the Audio Features
# (adapt the fext array to your needs)
fext = ['rp','ssd','rh','mvd'] # sh, tssd, trh
features = rp_extract(wavedata,
samplerate,
extract_rp = ('rp' in fext), # extract Rhythm Patterns features
extract_ssd = ('ssd' in fext), # extract Statistical Spectrum Descriptor
extract_sh = ('sh' in fext), # extract Statistical Histograms
extract_tssd = ('tssd' in fext), # extract temporal Statistical Spectrum Descriptor
extract_rh = ('rh' in fext), # extract Rhythm Histogram features
extract_trh = ('trh' in fext), # extract temporal Rhythm Histogram features
extract_mvd = ('mvd' in fext), # extract Modulation Frequency Variance Descriptor
)
all_features.append(features)
print "Finished analyzing", len(mp3_files), "files."
Decoding mp3 with: lame --quiet --decode "./music/Lana Del Rey - Born To Die (Absence Remix).mp3" "/var/folders/1_/bnncmvw96qvfqdy3yg98mzjm0000gn/T/tmpAppw6p.wav" Successfully read audio file: ./music/Lana Del Rey - Born To Die (Absence Remix).mp3 44100 Hz, 16 bit, 2 channel(s), 12197376 samples Decoding mp3 with: lame --quiet --decode "./music/SNBRN - Raindrops feat. Kerli (Prince Fox Remix).mp3" "/var/folders/1_/bnncmvw96qvfqdy3yg98mzjm0000gn/T/tmpH1nCQa.wav" Successfully read audio file: ./music/SNBRN - Raindrops feat. Kerli (Prince Fox Remix).mp3 44100 Hz, 16 bit, 2 channel(s), 8695296 samples Decoding mp3 with: lame --quiet --decode "./music/Remy Boyz - My Way RMX Ft. Drake.mp3" "/var/folders/1_/bnncmvw96qvfqdy3yg98mzjm0000gn/T/tmpsaGK_v.wav" Successfully read audio file: ./music/Remy Boyz - My Way RMX Ft. Drake.mp3 44100 Hz, 16 bit, 2 channel(s), 3957743 samples Finished analyzing 3 files.
Note: also see source file rp_extract_files.py on how to iterate over ALL mp3 or wav files in a directory.
Look at the results¶
# iterates over all featuers (files) we extracted
for feat in all_features:
plotrp(feat['rp'])
plotrh(feat['rh'])
maxbin = feat['rh'].argmax(axis=0) + 1 # +1 because it starts from 0
bpm = maxbin * mod_freq_res * 60
print "roughly", round(bpm), "bpm"


roughly 242.0 bpm


roughly 10.0 bpm


roughly 30.0 bpm
Further Example: Get a list of tracks by Genre¶
This is an example on how to retrieve Songs from Soundcloud by genre and/or bpm.
currently this does not work ... (issue on Soundcloud side?)
# currently this does not work
genre = 'Dancehall'
curr_offset = 0 # Note: the API has a limit of 50 items per response, so to get more you have to query multiple times with an offset.
tracks = client.get('/tracks', genres=genre, offset=curr_offset)
print "Retrieved", len(tracks), "track objects data"
# original Soundcloud example, searching for genre and bpm
# currently this does not work
tracks = client.get('/tracks', genres='punk', bpm={'from': 120})
In these application scenarios we try to find similar songs or classify music into different categories.
For these Use Cases we need to import a few additional functions from the sklearn package and from mir_utils (installed from git above in parallel to rp_extract):
# IMPORTING mir_utils (installed from git above in parallel to rp_extract (otherwise ajust path))
import sys
sys.path.append("../mir_utils")
from demo.NotebookUtils import *
from demo.PlottingUtils import *
from demo.Soundcloud_Demo_Dataset import SoundcloudDemodatasetHandler
# IMPORTS for NearestNeighbor Search
from sklearn.preprocessing import StandardScaler
from sklearn.neighbors import NearestNeighbors
The Soundcloud Demo Dataset¶
The Soundcloud Demo Dataset is a collection of commonly known mainstream radio songs hosted on the online streaming platform Soundcloud. The Dataset is available as playlist and is intended to be used to demonstrate the performance of MIR algorithms with the help of well known songs.
# show the data set as Souncloud playlist
iframe = '<iframe width="100%" height="450" scrolling="no" frameborder="no" src="https://w.soundcloud.com/player/?url=https%3A//api.soundcloud.com/playlists/106852365&auto_play=false&hide_related=false&show_comments=true&show_user=true&show_reposts=false&visual=false"></iframe>'
HTML(iframe)
The SoundcloudDemodatasetHandler abstracts the access to the TU-Wien server. On this server the extracted features are stored as csv-files. The SoundcloudDemodatasetHandler remotely loads the features and returns them by request. The features have been extracted using the method explained in the previous sections.
# first argument is local file path for downloaded MP3s and local metadata (if present, otherwise None)
scds = SoundcloudDemodatasetHandler(None, lazy=False)
Finding rhythmically similar songs¶
# Initialize the similarity search object
sim_song_search = NearestNeighbors(n_neighbors = 6, metric='euclidean')
Finding rhythmically similar songs using Rhythm Histograms¶
# set feature type
feature_set = 'rh'
# get features from Soundcloud demo set
demoset_features = scds.features[feature_set]["data"]
# Normalize the extracted features
scaled_feature_space = StandardScaler().fit_transform(demoset_features)
# Fit the Nearest-Neighbor search object to the extracted features
sim_song_search.fit(scaled_feature_space)
NearestNeighbors(algorithm='auto', leaf_size=30, metric='euclidean',
metric_params=None, n_neighbors=6, p=2, radius=1.0)
Our query-song:¶
This is a query song from the pre-analyzed data set:
query_track_soundcloud_id = 68687842 # Mr. Saxobeat
HTML(scds.getPlayerHTMLForID(query_track_soundcloud_id))
Retrieve the feature vector for the query song¶
query_track_feature_vector = scaled_feature_space[scds.features[feature_set]["ids"] == query_track_soundcloud_id]
Search the nearest neighbors of the query-feature-vector¶
This retrieves the most similar song indices and their distance:
(distances, similar_songs) = sim_song_search.kneighbors(query_track_feature_vector, return_distance=True)
print distances
print similar_songs
[[ 0. 6.02261617 7.76291163 7.80470254 8.63645209 8.90034496]] [[37 9 24 36 40 10]]
# For now we use only the song indices without distances
similar_songs = sim_song_search.kneighbors(query_track_feature_vector, return_distance=False)[0]
# because we are searching in the entire collection, the top-most result is the query song itself. Thus, we can skip it.
similar_songs = similar_songs[1:]
Lookup the corresponding Soundcloud-IDs¶
similar_soundcloud_ids = scds.features[feature_set]["ids"][similar_songs]
print similar_soundcloud_ids
[108622874 59732818 19505822 70343006 40279580]
Listen to the results¶
SoundcloudTracklist(similar_soundcloud_ids, width=90, height=120, visual=False)
Finding rhythmically similar songs using Rhythm Patterns¶
This time we define a function that performs steps analogously to the RH retrieval above:
def search_similar_songs_by_id(query_song_id, feature_set, skip_query=True):
scaled_feature_space = StandardScaler().fit_transform(scds.features[feature_set]["data"])
sim_song_search.fit(scaled_feature_space);
query_track_feature_vector = scaled_feature_space[scds.features[feature_set]["ids"] == query_song_id]
similar_songs = sim_song_search.kneighbors(query_track_feature_vector, return_distance=False)[0]
if skip_query:
similar_songs = similar_songs[1:]
similar_soundcloud_ids = scds.features[feature_set]["ids"][similar_songs]
return similar_soundcloud_ids
similar_soundcloud_ids = search_similar_songs_by_id(query_track_soundcloud_id,
feature_set='rp')
SoundcloudTracklist(similar_soundcloud_ids, width=90, height=120, visual=False)
Finding songs based on Timbral Similarity¶
Finding songs based on timbral similarity using Statistical Spectral Descriptors¶
similar_soundcloud_ids = search_similar_songs_by_id(query_track_soundcloud_id,
feature_set='ssd')
SoundcloudTracklist(similar_soundcloud_ids, width=90, height=120, visual=False)
Compare the Results of Timbral and Rhythmic Similarity¶
First entry is query-track
track_id = 68687842 # 40439758
results_track_1 = search_similar_songs_by_id(track_id, feature_set='ssd', skip_query=False)
results_track_2 = search_similar_songs_by_id(track_id, feature_set='rh', skip_query=False)
compareSimilarityResults([results_track_1, results_track_2],
width=100, height=120, visual=False,
columns=['Statistical Spectrum Descriptors', 'Rhythm Histograms'])
Using your Own Query Song from the self-extracted Souncloud tracks above¶
# check which files we got
mp3_files
[u'./music/Lana Del Rey - Born To Die (Absence Remix).mp3', u'./music/SNBRN - Raindrops feat. Kerli (Prince Fox Remix).mp3', u'./music/Remy Boyz - My Way RMX Ft. Drake.mp3']
# select from the list above the number of the song you want to use as a query (counting from 1)
song_id = 3 # count from 1
# select the feature vector type
feat_type = 'rp' # 'rh' or 'ssd' or 'rp'
# from the all_features data structure, we get the desired feature vector belonging to that song
query_feature_vector = all_features[song_id - 1][feat_type]
# get all the feature vectors of desired feature type from the Soundcloud demo set
demo_features = scds.features[feat_type]["data"]
# Initialize Neighbour Search space with demo set features
sim_song_search.fit(demo_features)
NearestNeighbors(algorithm='auto', leaf_size=30, metric='euclidean',
metric_params=None, n_neighbors=6, p=2, radius=1.0)
# use our own query_feature_vector for search in the demo set
(distances, similar_songs) = sim_song_search.kneighbors(query_feature_vector, return_distance=True)
print distances
print similar_songs
[[ 8.60906013 8.62923708 8.75274749 8.77687295 8.77928625 8.82950523]] [[36 40 42 1 37 10]]
# now we got the song indices for similar songs in the demo set
similar_songs = similar_songs[0]
similar_songs
array([36, 40, 42, 1, 37, 10])
# and we get the according Soundcloud Track IDs
similar_soundcloud_ids = scds.features[feat_type]["ids"][similar_songs]
similar_soundcloud_ids
array([19505822, 70343006, 11312719, 12285350, 68687842, 40279580])
# we add our own Track ID at the beginning to show the seed song below:
my_track_id = own_track_ids[song_id - 1]
print my_track_id
result = np.insert(similar_soundcloud_ids,0,my_track_id)
204088308
Visual Player with the Songs most similar to our Own Song¶
first song is the query song
print "Feature Type:", feat_type
SoundcloudTracklist(result, width=90, height=120, visual=False)
Feature Type: rp
Add On: Combining different Music Descriptors¶
Here we merge SSD and RH features together to account for both timbral and rhythmic similarity:
def search_similar_songs_with_combined_sets(scds, query_song_id, feature_sets, skip_query=True, n_neighbors=6):
features = scds.getCombinedFeaturesets(feature_sets)
sim_song_search = NearestNeighbors(n_neighbors = n_neighbors, metric='l2')
#
scaled_feature_space = StandardScaler().fit_transform(features)
#
sim_song_search.fit(scaled_feature_space);
#
query_track_feature_vector = scaled_feature_space[scds.getFeatureIndexByID(query_song_id, feature_sets[0])]
#
similar_songs = sim_song_search.kneighbors(query_track_feature_vector, return_distance=False)[0]
if skip_query:
similar_songs = similar_songs[1:]
#
similar_soundcloud_ids = scds.getIdsByIndex(similar_songs, feature_sets[0])
return similar_soundcloud_ids
feature_sets = ['ssd','rh']
compareSimilarityResults([search_similar_songs_with_combined_sets(scds, 68687842, feature_sets=feature_sets, n_neighbors=5),
search_similar_songs_with_combined_sets(scds, 40439758, feature_sets=feature_sets, n_neighbors=5)],
width=100, height=120, visual=False,
columns=[scds.getNameByID(68687842),
scds.getNameByID(40439758)])