cs1001.py , Tel Aviv University, Fall 2020
Recitation 12¶
We discussed two text-compression algorithms: Huffman coding and Lempel-Ziv.
Takeaways:¶
- Huffman Coding is a lossless compression technique. Given a corpus, a character frequency analysis is performed and a prefix free tree is built according to the analysis
- Given a text, the characters are encoded using the tree
- Given an encoding, decoding is performed in a "greedy" manner (for this reason a prefix free encoding is crucial)
- While Huffman coding is optimal, if the character frequency of the corpus differs from that of the encoded text, the compression can be inefficient
Code for printing several outputs in one cell (not part of the recitation):¶
from IPython.core.interactiveshell import InteractiveShell
InteractiveShell.ast_node_interactivity = "all"
Huffman Coding¶
Generates a variable-length, prefix-free code, based on the character frequencies in corpus string. Notice that there are several degrees of freedom that could lead to different tree structures.

def ascii2bit_stream(text):
""" Translates ASCII text to binary reprersentation using
7 bits per character. Assume only ASCII chars """
return "".join([bin(ord(c))[2:].zfill(7) for c in text])
########################################################
#### HUFFMAN CODE
########################################################
def char_count(text):
""" Counts the number of each character in text.
Returns a dictionary, with keys being the observed characters,
values being the counts """
d = {}
for ch in text:
if ch in d:
d[ch] += 1
else:
d[ch] = 1
return d
def build_huffman_tree(char_count_dict):
""" Recieves dictionary with char:count entries
Generates a LIST structure representing
the binary Huffman encoding tree """
queue = [(c,cnt) for (c,cnt) in char_count_dict.items()]
while len(queue) > 1:
#print(queue)
# combine two smallest elements
A, cntA = extract_min(queue) # smallest in queue
B, cntB = extract_min(queue) # next smallest
chars = [A,B]
weight = cntA + cntB # combined weight
queue.append((chars, weight)) # insert combined node
# only root node left
#print("final queue:", queue)
root, weight_trash = extract_min(queue) # weight_trash unused
return root #a LIST representing the tree structure
def extract_min(queue):
""" queue is a list of 2-tuples (x,y).
remove and return the tuple with minimal y """
min_pair = min(queue, key = lambda pair: pair[1])
queue.remove(min_pair)
return min_pair
def generate_code(huff_tree, prefix=""):
""" Receives a Huffman tree with embedded encoding,
and a prefix of encodings.
returns a dictionary where characters are
keys and associated binary strings are values."""
if isinstance(huff_tree, str): # a leaf
return {huff_tree: prefix}
else:
lchild, rchild = huff_tree[0], huff_tree[1]
codebook = {}
codebook.update(generate_code(lchild, prefix+'0'))
codebook.update(generate_code(rchild, prefix+'1'))
# oh, the beauty of recursion...
return codebook
def compress(text, encoding_dict):
""" compress text using encoding dictionary """
assert isinstance(text, str)
return "".join(encoding_dict[ch] for ch in text)
def reverse_dict(d):
""" build the "reverse" of encoding dictionary """
return {y:x for (x,y) in d.items()}
def decompress(bits, decoding_dict):
prefix = ""
result = []
for bit in bits:
prefix += bit
if prefix in decoding_dict:
result.append(decoding_dict[prefix])
prefix = "" #restart
assert prefix == "" # must finish last codeword
return "".join(result) # converts list of chars to a string
The Huffman Encoding Process¶
s = "live and let live"
Frequency dictionary
count_dict = char_count(s)
count_dict
{'l': 3, 'i': 2, 'v': 2, 'e': 3, ' ': 3, 'a': 1, 'n': 1, 'd': 1, 't': 1}
Build a Huffman tree:
The function returns a list which represents a binary tree as follows:
- A string in the list is a leaf
- Otherwise, a list of size two represents two sub-trees: the left subtree and the right subtree
The set of indices that lead to a leaf (char) correspond to the path leading to the leaf, and therefore to the encoding of the character in the final Huffman code
huff_tree = build_huffman_tree(count_dict)
# A list with two elements
huff_tree
# The left subtree of the root
huff_tree[0]
# The right subtree of the root
huff_tree[1]
# Leaves correspond to characters in the final code
huff_tree[0][0]
huff_tree[0][1][1]
[[' ', ['i', 'v']], [[['a', 'n'], ['d', 't']], ['l', 'e']]]
[' ', ['i', 'v']]
[[['a', 'n'], ['d', 't']], ['l', 'e']]
' '
'v'
Generate binary representation for each char in the corpus based on the tree
d = generate_code(huff_tree)
d
{' ': '00',
'i': '010',
'v': '011',
'a': '1000',
'n': '1001',
'd': '1010',
't': '1011',
'l': '110',
'e': '111'}
Compressing some text using our code
text1 = "tell"
compress(text1, d)
len(compress(text1, d))#4+3+3+3
'1011111110110'
13
unicode_conversion = ascii2bit_stream("tell") #when we convert every character to 7 bits
len(unicode_conversion)#4*7
28
Decoding
e = reverse_dict(d)
e
{'00': ' ',
'010': 'i',
'011': 'v',
'1000': 'a',
'1001': 'n',
'1010': 'd',
'1011': 't',
'110': 'l',
'111': 'e'}
decompress('1011111110110', e)
'tell'
Handling missing characters¶
asci = str.join("",[chr(c) for c in range(128)])
asci
'\x00\x01\x02\x03\x04\x05\x06\x07\x08\t\n\x0b\x0c\r\x0e\x0f\x10\x11\x12\x13\x14\x15\x16\x17\x18\x19\x1a\x1b\x1c\x1d\x1e\x1f !"#$%&\'()*+,-./0123456789:;<=>?@ABCDEFGHIJKLMNOPQRSTUVWXYZ[\\]^_`abcdefghijklmnopqrstuvwxyz{|}~\x7f'
Computing the compression ratio¶
def compression_ratio(text, corpus):
d = generate_code(build_huffman_tree(char_count(corpus)))
len_compress = len(compress(text, d))
len_ascii = len(ascii2bit_stream(text)) #len(text)*7
return len_compress/len_ascii
compression_ratio("ab", "ab")
1/7
0.14285714285714285
0.14285714285714285
compression_ratio("ab", "abcd")
2/7
0.2857142857142857
0.2857142857142857
compression_ratio("hello", "a"*100 + asci)
8/7
1.1428571428571428
1.1428571428571428
Alternative Huffman Trees (2014aa)¶
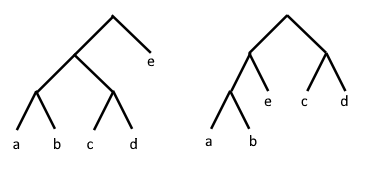
Two Huffman trees will be called alternative trees if they are generated by the same corpus but the sequence of coding lengths they generate is different.
For example, given the corpus abcdd the following trees are alternative:

Since the sequence of lengths they generate is $2, 2, 2, 2$ and $3, 3, 2, 1$ respectively, and the following trees are not alternative:

Since they all generate trees with coding lengths $3, 3, 2, 1$
Note: this definition does not address our Python implementation of the algorithm but instead refers to an algorithm where at each point two nodes of minimal weights are extracted arbitrarily.
- Show two alternative trees for the corpus
abcdee.
Answer:
- Prove or disprove: there exists a corpus of five distinct letters that can generate the following alternative trees. If true, give such a corpus, if false, explain why this is impossible:

Answer: the claim is true, and one such corpus is abcddeee
- Prove or disprove: if a corpus has unique frequencies then it cannot have two alternative trees.
Answer: the claim is false. Consider the corpus aabbbccccddddd (with unique frequencies $2, 3, 4, 5$) and note that it can generate the following alternative trees:
Lempel-Ziv¶
The LZ compression algorithm works by encoding succinct representations of repetitions in the text. A repetition of the form [offset,length], means that the next length characters appeared offset characters earlier.
- It might be that: offset < length
- Usually, offset < 4096 and length < 32

import math
def str_to_ascii(text):
""" Gets rid of on ascii characters in text"""
return ''.join(ch for ch in text if ord(ch)<128)
def maxmatch(T, p, w=2**12-1, max_length=2**5-1):
""" finds a maximum match of length k<=2**5-1 in a
w long window, T[p:p+k] with T[p-m:p-m+k].
Returns m (offset) and k (match length) """
assert isinstance(T,str)
n = len(T)
maxmatch = 0
offset = 0
# Why do we need the min here?
for m in range(1, min(p+1, w)):
k = 0
# Why do we need the min here?
while k < min(n-p, max_length) and T[p-m+k] == T[p+k]:
k += 1
# at this point, T[p-m:p-m+k]==T[p:p+k]
if maxmatch < k:
maxmatch = k
offset = m
return offset, maxmatch
# returned offset is smallest one (closest to p) among
# all max matches (m starts at 1)
def LZW_compress(text, w=2**12-1, max_length=2**5-1):
"""LZW compression of an ascii text. Produces
a list comprising of either ascii characters
or pairs [m,k] where m is an offset and
k is a match (both are non negative integers) """
result = []
n = len(text)
p = 0
while p<n:
m,k = maxmatch(text, p, w, max_length)
if k<2:
result.append(text[p]) # a single char
p += 1
else:
result.append([m,k]) # two or more chars in match
p += k
return result # produces a list composed of chars and pairs
def LZW_decompress(compressed, w=2**12-1, max_length=2**5-1):
"""LZW decompression from intermediate format to ascii text"""
result = []
n = len(compressed)
p = 0
while p<n:
if type(compressed[p]) == str: # char, as opposed to a pair
result.append(compressed[p])
p+=1
else:
m,k = compressed[p]
p += 1
for i in range(0,k):
# append k times to result;
result.append(result[-m])
# fixed offset m "to the left", as result itself grows
return "".join(result)
def LZW_compress2(text, w=2**12-1, max_length=2**5-1):
"""LZW compression of an ascii text. Produces
a list comprising of either ascii characters
or pairs [m,k] where m is an offset and
k>3 is a match (both are non negative integers) """
result = []
n = len(text)
p = 0
while p<n:
m,k = maxmatch(text, p, w, max_length)
if k<3: # modified from k<2
result.append(text[p]) # a single char
p += 1 #even if k was 2 (why?)
else:
result.append([m,k]) # two or more chars in match
p += k
return result # produces a list composed of chars and pairs
def inter_to_bin(lst, w=2**12-1, max_length=2**5-1):
""" converts intermediate format compressed list
to a string of bits"""
offset_width = math.ceil(math.log(w,2))
match_width = math.ceil(math.log(max_length, 2))
#print(offset_width,match_width) # for debugging
result = []
for elem in lst:
if type(elem) == str:
result.append("0")
result.append('{:07b}'.format(ord(elem)))
elif type(elem) == list:
result.append("1")
m,k = elem
result.append(str(bin(m)[2:]).zfill(offset_width))
result.append(str(bin(k)[2:]).zfill(match_width))
return "".join(ch for ch in result)
def bin_to_inter(compressed, w=2**12-1, max_length=2**5-1):
""" converts a compressed string of bits
to intermediate compressed format """
offset_width = math.ceil(math.log(w,2))
match_width = math.ceil(math.log(max_length,2))
#print(offset_width,match_width) # for debugging
result = []
n = len(compressed)
p = 0
while p<n:
if compressed[p] == "0": # single ascii char
p += 1
char = chr(int(compressed[p:p+7], 2))
result.append(char)
p += 7
elif compressed[p] == "1": # repeat of length > 2
p += 1
m = int(compressed[p:p+offset_width],2)
p += offset_width
k = int(compressed[p:p+match_width],2)
p += match_width
result.append([m,k])
return result
#########################
### Various executions
#########################
def process1(text):
""" packages the whole process using LZ_compress """
atext = str_to_ascii(text)
inter = LZW_compress(atext)
binn = inter_to_bin(inter)
inter2 = bin_to_inter(binn)
text2 = LZW_decompress(inter)
return inter, binn, inter2, text2
def process2(text):
""" packages the whole process using LZ_compress2 """
atext = str_to_ascii(text)
inter = LZW_compress2(atext)
binn = inter_to_bin(inter)
inter2 = bin_to_inter(binn)
text2 = LZW_decompress(inter2)
return inter, binn, inter2, text2
The LZ Encoding Process¶
inter1, bits, inter2, text2 = process2("abcdabc")
What is the encoded representation?
inter1
bits
['a', 'b', 'c', 'd', [4, 3]]
'01100001011000100110001101100100100000000010000011'
len(bits)#8*4+18
50
How do we really encode the chars?
[bits[8*i:8*(i+1)] for i in range(4)]
[bin(ord(c))[2:] for c in "abcd"]
['01100001', '01100010', '01100011', '01100100']
['1100001', '1100010', '1100011', '1100100']
Going back
text2
'abcdabc'
Another example
inter1, bits, inter2, text2 = process2("xyzxyzwxyzw")
inter1
['x', 'y', 'z', [3, 3], 'w', [4, 4]]
Compression ratio¶
def lz_ratio(text):
inter1, bits, inter2, text2 = process2(text)
return len(bits)/(len(text)*7)
lz_ratio('a' * 1000)
lz_ratio('a' * 10000)
0.086
0.08317142857142858
So what happens for increasing lz_ratio('a' * n) as $n \to \infty$?
Each repetition in the LZ compression requires 18 bits and we need $n/31$ such windows. On the other hand, the regular ASCII representation requires 7 bits per character, thus the ratio approaches $18/(31\cdot 7)$
18/(31*7)
0.08294930875576037
lz_ratio('hello')
lz_ratio('hello' * 2)
(8*5+18) / (7*10)
1.1428571428571428
0.8285714285714286
0.8285714285714286
Comparing Huffman and LZ compression ratios¶
import random
asci = str.join("",[chr(c) for c in range(128)])
rand = "".join([random.choice(asci) for i in range(1000)])
s = "".join([chr(ord("a")+i-1)*i for i in range(1,27)])
s
'abbcccddddeeeeeffffffggggggghhhhhhhhiiiiiiiiijjjjjjjjjjkkkkkkkkkkkllllllllllllmmmmmmmmmmmmmnnnnnnnnnnnnnnoooooooooooooooppppppppppppppppqqqqqqqqqqqqqqqqqrrrrrrrrrrrrrrrrrrsssssssssssssssssssttttttttttttttttttttuuuuuuuuuuuuuuuuuuuuuvvvvvvvvvvvvvvvvvvvvvvwwwwwwwwwwwwwwwwwwwwwwwxxxxxxxxxxxxxxxxxxxxxxxxyyyyyyyyyyyyyyyyyyyyyyyyyzzzzzzzzzzzzzzzzzzzzzzzzzz'
def compare_lz_huffman(text):
print("Huffman compression ratio:", compression_ratio(text,text+asci))
print("LZ compression ratio:", lz_ratio(text))
compare_lz_huffman(rand)
compare_lz_huffman(s)
compare_lz_huffman(open("looking_glass.txt", "r").read()[:10000])
Huffman compression ratio: 0.9935714285714285 LZ compression ratio: 1.1428571428571428 Huffman compression ratio: 0.6866096866096866 LZ compression ratio: 0.2629222629222629 Huffman compression ratio: 0.6538857142857143 LZ compression ratio: 0.6195142857142857
An explanation of the results can be found here