Mixed Precision Training (PyTorch, TF2.X)¶
- train faster and bigger
- author: Sajjad Ayoubi
Most deep learning frameworks, including PyTorch & Tensorflow, train with 32-bit floating point (FP32) arithmetic by default. However this is not essential to achieve full accuracy for many deep learning models. NVIDIA researchers developed a methodology for mixed-precision training, which combined single-precision (FP32) with half-precision (e.g. FP16) format when training a network, and achieved the same accuracy as FP32 training using the same hyperparameters, with additional performance benefits on NVIDIA GPUs:
- Shorter training time;
- Lower memory requirements, enabling larger batch sizes, larger models, or larger inputs.
Among NVIDIA GPUs, those with compute capability 7.0 or higher will see the greatest performance benefit from mixed precision because they have special hardware units, called Tensor Cores, to accelerate float16 matrix multiplications and convolutions. Older GPUs offer no math performance benefit for using mixed precision, however memory and bandwidth savings can enable some speedups. You can look up the compute capability for your GPU at NVIDIA's CUDA GPU web page. Examples of GPUs that will benefit most from mixed precision include RTX GPUs, the V100, and the A100.
- For many real-world models, mixed precision also allows you to double the batch size without running out of memory, as float16 tensors take half the memory
- Note: If running this guide in Google Colab, the GPU runtime typically has a P100 connected. The P100 has compute capability 6.0 and is not expected to show a significant speedup.
Performance Benchmarks¶
- FP16 on NVIDIA V100 vs. FP32 on V100
AMP with FP16 is the most performant option for DL training on the V100. In Table 1, we can observe that for various models, AMP on V100 provides a speedup of 1.5x to 5.5x over FP32 on V100 while converging to the same final accuracy.
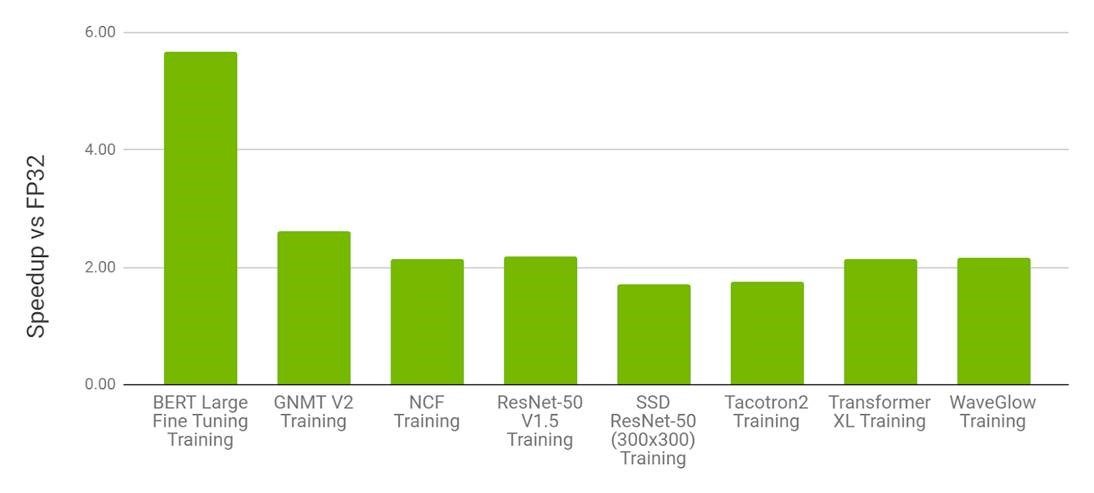
Figure 2. Performance of mixed precision training on NVIDIA 8xV100 vs. FP32 training on 8xV100 GPU. Bars represent the speedup factor of V100 AMP over V100 FP32. The higher the better.
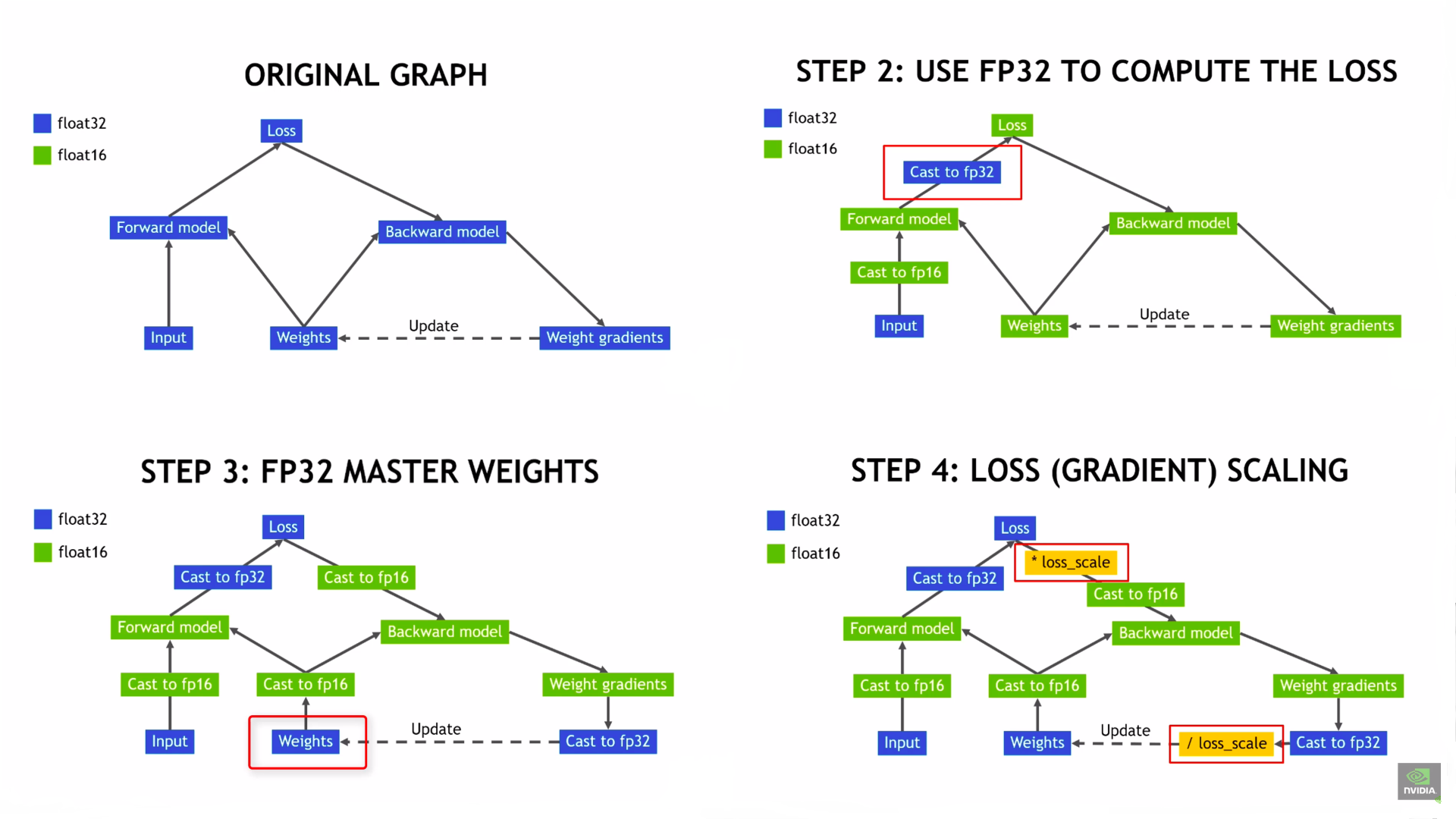
Gradient Scaling¶
If the forward pass for a particular op has float16 inputs, the backward pass for that op will produce float16 gradients. Gradient values with small magnitudes may not be representable in float16. These values will flush to zero (“underflow”), so the update for the corresponding parameters will be lost.
To prevent underflow, “gradient scaling” multiplies the network’s loss(es) by a scale factor and invokes a backward pass on the scaled loss(es). Gradients flowing backward through the network are then scaled by the same factor. In other words, gradient values have a larger magnitude, so they don’t flush to zero.
Each parameter’s gradient should be unscaled before the optimizer updates the parameters, so the scale factor does not interfere with the learning rate.
we have tow steps
- multiply the loss by some large number
- after computing grads, we rescale the gradients with divide by that number to bring them back to their correct values
we can do it with something like this: (it's pseudocode)
loss = model(inputs)
# We assume `grads` are float32. We do not want to divide float16 gradients
grads = compute_gradient(loss*512, model.weights)
grads /= 512
# then update the weights
Choosing a loss scale can be tricky. If the loss scale is too low, gradients may still underflow to zero. If too high, the opposite the problem occurs: the gradients may overflow to infinity.
- don't worry about it frameworks as PyTorch and TF set it dynamically for you
PyTorch¶
For the PyTorch 1.6 release, developers at NVIDIA and Facebook moved mixed precision functionality into PyTorch core as the AMP package, torch.cuda.amp
- amp stands for auto mixed-precision
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torchvision.models import mobilenet_v2
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0), (255))])
train_ds = datasets.CIFAR10('./', download=True, transform=transform)
train_dl = torch.utils.data.DataLoader(train_ds, batch_size=128, shuffle=True, num_workers=4)
Files already downloaded and verified
# for mixed precision training
from torch.cuda.amp import GradScaler # for gradient and loss sclaing
from torch.cuda.amp import autocast # Casts operations in float16 & 32 automatically
- define a new model
device = 'cuda'
model = mobilenet_v2()
model.classifier = nn.Linear(1280, 10)
model.to(device)
# create optimizer and loss
optimizer = optim.Adam(model.parameters(), lr=0.005)
loss_fn = nn.CrossEntropyLoss().to(device)
Training
autocast()has no effect outside regions where it’s enabled
fp16 = True
# defince scaler for loss and grad scaling
# Creates once at the beginning of training
scaler = GradScaler(enabled=fp16)
loss_avg = 0.0
for i, (inputs, labels) in enumerate(train_dl):
optimizer.zero_grad()
# Casts operations to mixed precision
with autocast(enabled=fp16):
outputs = model(inputs.to(device))
loss = loss_fn(outputs, labels.to(device))
loss_avg = (loss_avg * i + loss) / (i+1)
# Scales the loss, and calls backward()
# to create scaled gradients
scaler.scale(loss).backward()
# Unscales gradients and calls
# or skips optimizer.step()
scaler.step(optimizer)
scaler.update()
# simple logging
if i%100==0:
print('[%d, %4d] loss: %.4f' %(i+1, len(train_dl), loss_avg))
[1, 391] loss: 2.4166 [101, 391] loss: 2.1503 [201, 391] loss: 1.9664 [301, 391] loss: 1.8769
- all together
def train(fp16=True, device='cuda'):
scaler = GradScaler(enabled=fp16)
loss_avg = 0.0
for i, (inputs, labels) in enumerate(train_dl):
optimizer.zero_grad() # set_to_none=True here can modestly improve performance
# Casts operations to mixed precision
with autocast(enabled=fp16):
outputs = model(inputs.to(device))
loss = loss_fn(outputs, labels.to(device))
loss_avg = (loss_avg * i + loss.item()) / (i+1)
# Scales the loss, and calls backward()
# to create scaled gradients
scaler.scale(loss).backward()
# you can use grad norm as usual
torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm='inf')
# Unscales gradients and calls
# or skips optimizer.step()
scaler.step(optimizer)
scaler.update()
if i%100==0:
print('[%d, %4d] loss: %.4f' %(i, len(train_dl), loss_avg))n_dl), loss_avg))
train(fp16=True)
[0, 391] loss: 1.4084 [100, 391] loss: 1.4822 [200, 391] loss: 1.4601 [300, 391] loss: 1.4331
train(fp16=False)
[0, 391] loss: 1.2830 [100, 391] loss: 1.2331 [200, 391] loss: 1.2164 [300, 391] loss: 1.2011
Saving/Resuming
To save/resume Amp-enabled runs with bitwise accuracy, use scaler.state_dict and scaler.load_state_dict.
When saving, save the scaler state dict alongside the usual model and optimizer state dicts. Do this either at the beginning of an iteration before any forward passes, or at the end of an iteration after scaler.update().
For More details Torch doc on Mixed precision
Keras & TF 2.X¶
import tensorflow as tf
from tensorflow.keras.applications import MobileNetV2
from tensorflow.keras.layers import Dense, Activation
- To use mixed precision in Keras, you need to set a tf.keras.mixed_precision Policy, typically referred to as a dtype policy. Dtype policies specify the dtypes layers will run in. In this guide, you will construct a policy from the string 'mixed_float16' and set it as the global policy. This will cause subsequently created layers to use mixed precision with a mix of float16 and float32.
# for mixed precision training
from tensorflow.keras import mixed_precision
# set global dtype for all keras.layers
mixed_precision.set_global_policy('mixed_float16') # default is float32, if you use TPUs change it to mixed_bfloat16
- Computations are done in float16 for performance
- but variables must be kept in float32 for numeric stability.
print('Compute dtype: ', mixed_precision.global_policy().compute_dtype)
print('Variable dtype: ', mixed_precision.global_policy().variable_dtype)
Compute dtype: float16 Variable dtype: float32
- This example cast the input data from int8 to float32. We don't cast to float16 since the division by 255 is on the CPU, which runs float16 operations slower than float32 operations. In this case, the performance difference in negligible, but in general you should run input processing math in float32 if it runs on the CPU. The first layer of the model will cast the inputs to float16, as each layer casts floating-point inputs to its compute dtype.
(x_train, y_train), (x_test, y_test) = keras.datasets.cifar10.load_data()
x_train = x_train.astype('float32') / 255
x_test = x_test.astype('float32') / 255
- Each layer has a policy and uses the global policy by default which is
float16- You can override the dtype of any layer to be float32 by passing
dtype='float32'
- You can override the dtype of any layer to be float32 by passing
- Very small toy models typically do not benefit from mixed precision, because overhead from the TensorFlow runtime typically dominates the execution time, making any performance improvement on the GPU negligible
model = tf.keras.Sequential()
model.add(MobileNetV2(include_top=False, input_shape=(32, 32, 3)))
model.add(Dense(10)) # use global policy which is float16
# If your model ends in softmax, make sure it is float32. And regardless of what your model ends in, make sure the output is float32.
model.add(Activation('softmax', dtype='float32'))
- Even if the model does not end in a softmax, the outputs should still be float32
- for computing loss in float32 we need outputs on float32
- if you have not acsses to your last layer (like in applications), use this
outputs = keras.layers.Activation('linear', dtype='float32')(outputs)
model.compile(loss='sparse_categorical_crossentropy', optimizer='adam')
history = model.fit(x_train, y_train, batch_size=32, epochs=2, validation_split=0.2)
Epoch 1/2 1250/1250 [==============================] - 72s 47ms/step - loss: 1.9050 - val_loss: 7.5213 Epoch 2/2 1250/1250 [==============================] - 55s 44ms/step - loss: 1.7229 - val_loss: 7.7043
def train(fp16=True, epochs=1):
# set floating point
if fp16: mixed_precision.set_global_policy('mixed_float16')
else: mixed_precision.set_global_policy('float32')
# create & compile model
model = tf.keras.Sequential()
model.add(MobileNetV2(include_top=False, input_shape=(32, 32, 3)))
model.add(Dense(10))
model.add(Activation('softmax', dtype='float32')) # last layer must be float32
model.compile(loss='sparse_categorical_crossentropy', optimizer='adam')
# training
model.fit(x_train, y_train, epochs=epochs, batch_size=64)
train(fp16=True)
782/782 [==============================] - 57s 55ms/step - loss: 1.6211
train(fp16=False)
782/782 [==============================] - 34s 37ms/step - loss: 1.6675
Custom Training Loop¶
- TensorFlow dynamically determines the gradient scale so you do not have to choose one manually. If you use
keras.Model.fit, gradient scaling is done for you so you do not have to do any extra work. If you use a custom training loop, you must explicitly use the special optimizer wrapperkeras.mixed_precision.LossScaleOptimizerin order to use loss (and grad) scaling
If you use a custom training loop with
mixed_float16- you need to wrap your optimizer with a
tf.keras.mixed_precision.LossScaleOptimizer - Then call
optimizer.get_scaled_lossto scale the loss, - and
optimizer.get_unscaled_gradientsto unscale the gradients.
- you need to wrap your optimizer with a
see the following example
class Fp16Training(tf.keras.Model):
def train_step(self, data):
x, y = data
with tf.GradientTape() as tape:
y_pred = self(x, training=True)
loss = self.compiled_loss(y, y_pred, regularization_losses=self.losses)
# scale loss with optimizer
scaled_loss = optimizer.get_scaled_loss(loss)
# used scaled loss for compute gradient
scaled_gradients = tape.gradient(scaled_loss, self.trainable_variables)
# unscaled gradients to default value for stable training
grads = optimizer.get_unscaled_gradients(scaled_gradients)
self.optimizer.apply_gradients(zip(grads, self.trainable_variables))
# as usual
self.compiled_metrics.update_state(y, y_pred)
return {m.name: m.result() for m in self.metrics}
# write it as usally
def test_step(self, data): pass
model = tf.keras.Sequential()
model.add(MobileNetV2(include_top=False, input_shape=(32, 32, 3)))
model.add(Dense(10))
# last layer or outputs must be float32 if use from_logits=True set dtype in last Dense
model.add(Activation('softmax', dtype='float32'))
# use custom trainig loop
cuistom_model = Fp16Training(model.inputs, model.outputs)
# optimizer with loss-scaler & and gradient unscaler
optimizer = keras.optimizers.Adam()
optimizer = mixed_precision.LossScaleOptimizer(optimizer)
# compile model
cuistom_model.compile(loss='sparse_categorical_crossentropy', optimizer=optimizer)
cuistom_model.fit(x_train, y_train, batch_size=32, epochs=1)
1563/1563 [==============================] - 74s 42ms/step - loss: 1.9542
<tensorflow.python.keras.callbacks.History at 0x7f2de9545090>
For More details TF doc on Mixed precision
Performance¶
modern NVIDIA GPUs use a special hardware unit called Tensor Cores that can multiply float16 matrices very quickly.
However, Tensor Cores requires certain dimensions of tensors to be a multiple of 8
Matmul dimensions are not Tensor Core-friendly. Make sure matmuls’ participating sizes are multiples of 8. (For NLP models with encoders/decoders, this can be subtle. Also, convolutions used to have similar size constraints for Tensor Core use, but for CuDNN versions 7.3 and later, no such constraints exist
- I think that now we need to define models like this:
batch_size = 8*4
layer_input = 8*20
layer_output = 8*40
channel_number = 8*64