Python para Desenvolvedores¶
2ª edição, revisada e ampliada¶
Capítulo 27: Persistência¶
Persistência pode ser definida como a manutenção do estado de uma estrutura de dados entre execuções de uma aplicação. A persistência libera o desenvolvedor de escrever código explicitamente para armazenar e recuperar estruturas de dados em arquivos e ajuda a manter o foco na lógica da aplicação.
Serialização¶
A forma mais simples e direta de persistência é chamada de serialização e consiste em gravar em disco uma imagem (dump) do objeto, que pode ser recarregada (load) posteriormente. No Python, a serialização é implementada de várias formas, sendo que a mais comum é através do módulo chamado pickle.
Exemplo de serialização:
- O programa tenta recuperar o dicionário
setupusando o objeto do arquivosetup.pkl. - Se conseguir, imprime o dicionário.
- Se não conseguir, cria um
setupdefault e salva emsetup.pkl.
import pickle
try:
setup = pickle.load(file('setup.pkl'))
print setup
except:
setup = {'timeout': 10,
'server': '10.0.0.1',
'port': 80
}
pickle.dump(setup, file('setup.pkl', 'w'))
{'port': 80, 'timeout': 10, 'server': '10.0.0.1'}
Na primeira execução, ele cria o arquivo. Nas posteriores, a saída é a mesma mostrada acima.
Entre os módulos da biblioteca padrão estão disponíveis outros módulos persistência, tais como:
- cPickle: versão mais eficiente de pickle, porém não pode ter subclasses.
- shelve: fornece uma classe de objetos persistentes similares ao dicionário.
Existem frameworks em Python de terceiros que oferecem formas de persistência com recursos mais avançados, como o ZODB.
Todas essas formas de persistência armazenam dados em formas binárias, que não são diretamente legíveis por seres humanos.
Para armazenar dados em forma de texto, existem módulos para Python para ler e gravar estruturas de dados em formatos:
- JSON (JavaScript Object Notation).
- YAML (YAML Ain't a Markup Language).
- XML (Extensible Markup Language).
ZODB¶
Zope Object Database (ZODB) é um banco de dados orientado a objeto que oferece uma forma de persistência quase transparente para aplicações escritas em Python e foi projetado para ter pouco impacto no código da aplicação.
ZODB suporta transações, controle de versão de objetos e pode ser conectado a outros backends através do Zope Enterprise Objects (ZEO), permitindo inclusive a criação de aplicações distribuídas em diversas máquinas conectadas por rede.
O ZODB é um componente integrante do Zope, que é um servidor de aplicações desenvolvido em Python, muito usado em Content Management Systems (CMS).
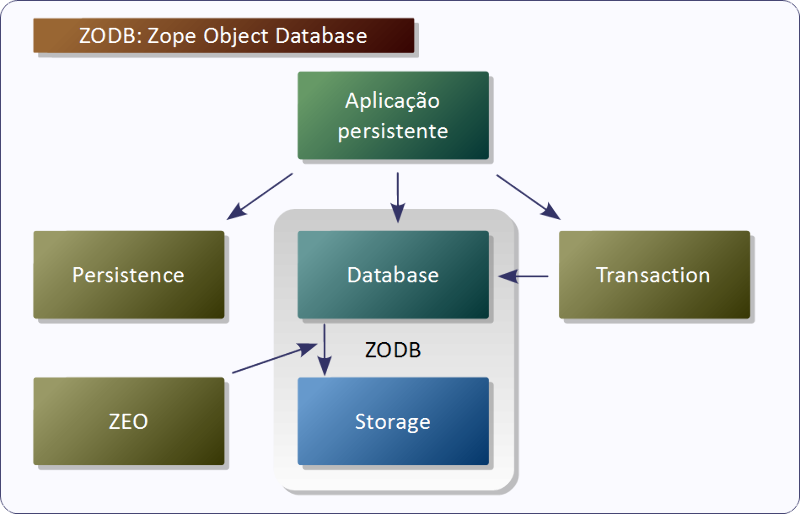
Componentes do ZODB:
- Database: permite que a aplicação faça conexões (interfaces para acesso aos objetos).
- Transaction: interface que permite tornar as alterações permanentes.
- Persistence : fornece a classe base Persistent.
- Storage: gerencia a representação persistente em disco.
- ZEO: compartilhamento de objeto entre diferentes processos e máquinas.
Exemplo de uso do ZODB:
from ZODB import FileStorage, DB
import transaction
# Definindo o armazenamento do banco
storage = FileStorage.FileStorage('people.fs')
db = DB(storage)
# Conectando
conn = db.open()
# Referência para a raiz da árvore
root = conn.root()
# Um registro persistente
root['singer'] = 'Kate Bush'
# Efetuando a alteração
transaction.commit()
print root['singer'] # Kate Bush
# Mudando um item
root['singer'] = 'Tori Amos'
print root['singer'] # Tori Amos
# Abortando...
transaction.abort()
# O item voltou ao que era antes da transação
print root['singer'] # Kate Bush
Kate Bush Tori Amos Kate Bush
O ZODB tem algumas limitações que devem ser levadas em conta durante o projeto da aplicação:
- Os objetos precisam ser “serializáveis” para serem armazenados.
- Objetos mutáveis requerem cuidados especiais.
Objetos “serializáveis” são aqueles objetos que podem ser convertidos e recuperados pelo Pickle. Entres os objetos que não podem ser processados pelo Pickle, estão aqueles implementados em módulos escritos em C, por exemplo.
YAML¶
YAML é um formato de serialização de dados para texto que representa os dados como combinações de listas, dicionários e valores escalares. Tem como principal característica ser legível por humanos.
O projeto do YAML foi muito influenciado pela sintaxe do Python e outras linguagens dinâmicas. Entre outras estruturas, a especificação do YAML define que:
- Os blocos são marcados por endentação.
- Listas são delimitadas por colchetes ou indicadas por traço.
- Chaves de dicionário são seguidas de dois pontos.
Listas podem ser representadas assim:
- Azul
- Branco
- Vermelho
Ou
[azul, branco, vermelho]
Dicionários são representados como:
cor: Branco
nome: Bandit
raca: Labrador
PyYAML é um módulo de rotinas para gerar e processar YAML no Python.
Exemplo de conversão para YAML:
import yaml
progs = {'Inglaterra':
{'Yes': ['Close To The Edge', 'Fragile'],
'Genesis': ['Foxtrot', 'The Nursery Crime'],
'King Crimson': ['Red', 'Discipline']},
'Alemanha':
{'Kraftwerk': ['Radioactivity', 'Trans Europe Express']}
}
print yaml.dump(progs)
Alemanha: Kraftwerk: [Radioactivity, Trans Europe Express] Inglaterra: Genesis: [Foxtrot, The Nursery Crime] King Crimson: [Red, Discipline] 'Yes': [Close To The Edge, Fragile]
Exemplo de leitura de YAML. Arquivo de entrada prefs.yaml:
- musica: rock
- cachorro:
cor: Branco
nome: Bandit
raca: Labrador
- outros:
instrumento: baixo
linguagem: [python, ruby]
comida: carne
Código em Python:
import pprint
import yaml
# yaml.load() pode receber um arquivo aberto
# como argumento
yml = yaml.load(file('prefs.yaml'))
# pprint.pprint() mostra a estrutura de dados
# de uma forma mais organizada do que
# o print convencional
pprint.pprint(yml)
[{'musica': 'rock'},
{'cachorro': {'cor': 'Branco', 'nome': 'Bandit', 'raca': 'Labrador'}},
{'outros': {'comida': 'carne',
'instrumento': 'baixo',
'linguagem': ['python', 'ruby']}}]
YAML é muito prático para ser usado em arquivos de configuração e outros casos onde os dados podem ser manipulados diretamente por pessoas.
JSON¶
A partir versão 2.6, foi incorporado a biblioteca do Python um módulo de suporte ao JSON (JavaScript Object Notation). O formato apresenta muitas similaridades com o YAML e tem o mesmo propósito.
Exemplo:
import json
desktop = {'arquitetura': 'pc', 'cpus': 2, 'hds': [520, 270]}
print json.dumps(desktop)
{"hds": [520, 270], "arquitetura": "pc", "cpus": 2}
O JSON usa a sintaxe do JavaScript para representar os dados e é suportado em várias linguagens.