关联分析¶
引子¶
今天我们考虑另一个问题,在餐饮企业中: 如何根据在大量的历史菜单数据,挖掘出客户点餐的规则,也就是说,当他下了某个菜品的订单时推荐相关联的菜品?
这样的问题可以通过关联分析来解决。
关联规则分析也称为购物篮分析,最早是为了发现超市销售数据库中不同的商品之间的关联关系。例如,一个超市的经理想要更多地了解顾客的购物习惯,比如“哪组商品可能会在一次购物中同时购买?”或者“某顾客购买了个人电脑,那该顾客三个月后购买数码相机的概率有多大?”他可能会发现如果购买了面包的顾客同时非常有可能会购买牛奶,这就导出了一条关联规则“面包=>牛奶”,其中面包称为规则的前项,而牛奶称为后项。
常用的关联算法有:
- Apriori:关联规则最常用也是最经典的算法,其核心思想是通过连接产生候选项及其支持度然后通过剪枝生成频繁项集*
- FP-Tree
- Eclat算法
- 灰色关联法
我们今天详细介绍第一种:Apriori算法
今天我们介绍以下几个问题:
** 1. 频繁模式**
2. 关联规则
3. 关联分析
1. 频繁模式¶
首先介绍几个概念。
频繁模式¶
即频繁出现在数据集中的模式。例如频繁项集、频繁序列
- 项集;项集是项的集合。包含k个项的项集称为k项集,如集合{牛奶,麦片,糖}是一个3项集。
支持度¶
项集A、B同时发生的概率称为关联规则的支持度
(X, Y)频繁项集的支持度为:$$support=P(XY)=\frac{N_{(x\bigcup{y})}}{N}$$
置信度¶
项集A发生,则项集B发生的概率为关联规则的置信度。$$ c(x\Rightarrow y)= P(Y|X) = \frac{N_{(x\bigcup y)}}{N(x)}$$
最小支持度和最小置信度¶
最小支持度是用户或专家定义的衡量支持度的一个阈值,表示项目集在统计意义上的最低重要性;最小置信度是用户或专家定义的衡量置信度的一个阈值,表示关联规则的最低可靠性。同时满足最小支持度阈值和最小置信度阈值的规则称作强规则。
事务数据集¶
我们先看这样一个数据集:这个数据记录的是超市的订单数据。tid指的是用户id。
 将这个数据称为**事务数据集**,也就是看每一名顾客购买了什么。
将这个数据称为**事务数据集**,也就是看每一名顾客购买了什么。
 这里我们就可以计算{橙汁, 洗洁精}这个项集的支持度了:
**支持度 =3/6= 50%。**
这里我们就可以计算{橙汁, 洗洁精}这个项集的支持度了:
**支持度 =3/6= 50%。**
二元表示¶
我们进一步将事务数据集转化为以下这种二元表示。

在上面这个例子中,{橙汁, 洗洁精}的支持度为50%,也就是说,橙汁和洗洁精同时出现的概率为百分之五十。那么,我们是否可以推测出,购买了橙汁,就会购买洗洁精呢?如果这个推测成立的话,这就是一条关联规则。
2. 关联规则¶
- 关联是事务数据中存在于一部分物品集合和另一部分物品集合之间的相关性或因果结构。
- 这种关联可以用关联规则形式来表示。
在这个例子中,如果我们说 **{橙汁} ---> {洗洁精}** 是一条关联规则,那么它的置信度为$$c(橙汁\Rightarrow 洗洁精)= P(洗洁精|橙汁) = \frac{N_{(洗洁精\bigcup 橙汁)}}{N(橙汁)}=\frac{3}{5}=60{\%}$$
$$c(洗洁精\Rightarrow 橙汁)= P(橙汁|洗洁精) = \frac{N_{(橙汁\bigcup 洗洁精)}}{N(洗洁精)}=\frac{3}{3}=100{\%}$$
3. 关联分析¶
所谓关联分析,就是指发现满足最小支持度与最小置信度的关联规则。它包含两个步骤:
- 发现频繁项目集(或称大项目集):即发现哪些东西会一起购买。
- 根据频繁项目集,产生置信度大于最小置信度的关联规则
接下来我们就来介绍关联算法中的Apriori算法
4. Apriori算法¶
Apriori算法的主要思想是找出存在于事务数据集中的最大的频繁项集,再利用得到的最大频繁项集与预先设定的最小置信度阈值生成强关联规则。
Apriori算法的实现有两个过程
过程一:找出所有的频繁项集,最终得到最大频繁项集$L_k$
- 1.产生频繁一项集L1(k=1)
- 2.由两个k项频繁项集合并形成一个k+1 项频繁项集候选Ck+1。
- 3.剪枝Ck+1,形成k+1项频繁项集
- 4.k=k+1,重复2、3步,直到3中Ck+1为空集或者K为最大项数。
我们用一个具体的例子来看。例如以下数据集。
 假定最小支持度设定为:22%(绝对次数为2)
首先产生频繁一项集L1。然后将两个1项频繁项集合并形成一个2项频繁项集候选C2。这里我们需要进行**剪枝**,也就是将支持度计数小于2的项集删去,得到L2。
假定最小支持度设定为:22%(绝对次数为2)
首先产生频繁一项集L1。然后将两个1项频繁项集合并形成一个2项频繁项集候选C2。这里我们需要进行**剪枝**,也就是将支持度计数小于2的项集删去,得到L2。
 然后将两个2项频繁项集合并形成一个3项频繁项集候选C3。其中,带有红色标识的部分需要删去,这是因为在C2中,我们已经删去了支持度小于2的项集,所以带红标识的项集也不应该保留。得到最终的C3。同理得到C4为空集。所以最终的频繁项集为$L=L1\bigcup L2 \bigcup L3$,其中L3是最大的频繁项集。
然后将两个2项频繁项集合并形成一个3项频繁项集候选C3。其中,带有红色标识的部分需要删去,这是因为在C2中,我们已经删去了支持度小于2的项集,所以带红标识的项集也不应该保留。得到最终的C3。同理得到C4为空集。所以最终的频繁项集为$L=L1\bigcup L2 \bigcup L3$,其中L3是最大的频繁项集。
 **由频繁项集产生关联规则**
**由频繁项集产生关联规则**
对每个大项目集 l 产生其所有的子集,对每个子集a,检验规则$$a\Rightarrow (l-a)$$的置信度并保留满足最小置信度阈值的规则。
假定X', X''是X的子集, X= X'UX''
CONF(X$\Rightarrow$Y)=supp(XY)/supp(X) CONF(X'$\Rightarrow$YUX'')= supp(XY)/supp(X')≤ CONF(X$\Rightarrow$Y)
IF 规则X$\Rightarrow$Y不满足置信度阀值 THEN X'$\Rightarrow$YUX''的规则一定也不满足置信度阀值 例如,假定最小置信度为60%
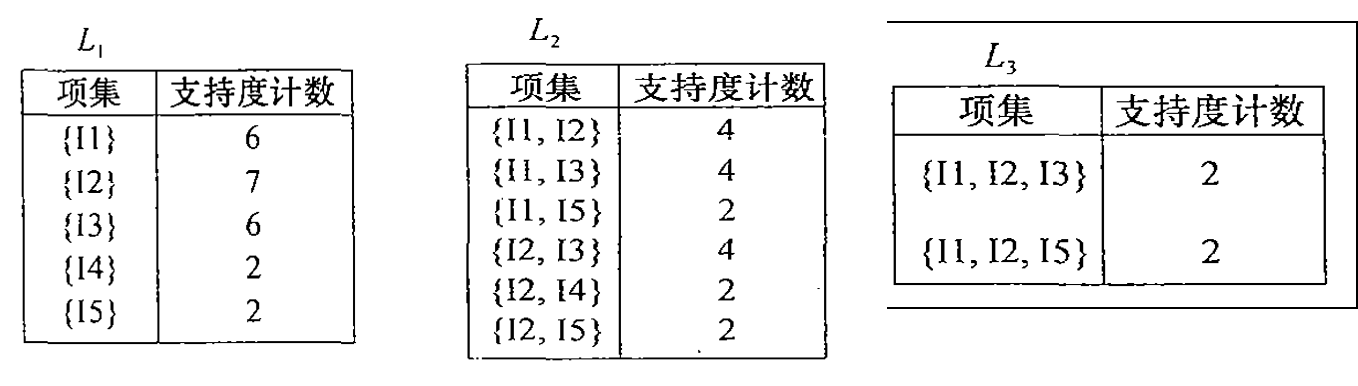
 就第一条关联规则进行解释:客户点了菜品2和3,再点菜品2的概率是50%。
就第一条关联规则进行解释:客户点了菜品2和3,再点菜品2的概率是50%。
5. 实例¶
#########定义Apriori算法#########
import pandas as pd
# 定义连接函数,用于实现L_{k-1}到C_k的连接
#其中,ms表示连接符,默认'--',用来区分不同元素,如A--B。
# x为数据
def connect_string(x, ms):
x = list(map(lambda i:sorted(i.split(ms)), x))#拆分x中的元素
l = len(x[0])#项集元素的个数,如1项集则有1个元素
r = []# 用于存放C_k
for i in range(len(x)):#len(x)为项集的个数
for j in range(i, len(x)):
if x[i][:l-1] == x[j][:l-1] and x[i][l-1] != x[j][l-1]:
r.append(x[i][:l-1]+sorted([x[j][l-1],x[i][l-1]]))
return r
#寻找关联规则的函数
def find_rule(d, support, confidence, ms = u'--'):
result = pd.DataFrame(index=['support', 'confidence']) #定义输出结果
support_series = 1.0*d.sum()/len(d) #支持度序列
column = list(support_series[support_series > support].index) #初步根据支持度筛选
k = 0
while len(column) > 1:
k = k+1
print(u'\n正在进行第%s次搜索...' %k)
column = connect_string(column, ms)
print(u'数目:%s...' %len(column))
sf = lambda i: d[i].prod(axis=1, numeric_only = True) #新一批支持度的计算函数,求P(XY)
#创建连接数据,这一步耗时、耗内存最严重。当数据集较大时,可以考虑并行运算优化。
d_2 = pd.DataFrame(list(map(sf,column)), index = [ms.join(i) for i in column]).T
support_series_2 = 1.0*d_2[[ms.join(i) for i in column]].sum()/len(d) #计算连接后的支持度
column = list(support_series_2[support_series_2 > support].index) #新一轮支持度筛选
support_series = support_series.append(support_series_2)
column2 = []
for i in column: #遍历可能的推理,如{A,B,C}究竟是A+B-->C还是B+C-->A还是C+A-->B?
i = i.split(ms)
for j in range(len(i)):
column2.append(i[:j]+i[j+1:]+i[j:j+1])
cofidence_series = pd.Series(index=[ms.join(i) for i in column2]) #定义置信度序列
for i in column2: #计算置信度序列
cofidence_series[ms.join(i)] = support_series[ms.join(sorted(i))]/support_series[ms.join(i[:len(i)-1])]
for i in cofidence_series[cofidence_series > confidence].index: #置信度筛选
result[i] = 0.0
result[i]['confidence'] = cofidence_series[i]
result[i]['support'] = support_series[ms.join(sorted(i.split(ms)))]
result = result.T.sort(['confidence','support'], ascending = False) #结果整理,输出
print(u'\n第%s次搜索出结果啦!!!' %k)
print(u'\n结果为:')
print(result)
result = result.T
return result.T
#########定义Apriori算法#########
#########运用Apriori算法进行关联分析#########
#导入数据
data = pd.read_excel('data/menu_orders.xls', header = None)#原始数据集是事务数据集
print(u'\n转换原始数据至0-1矩阵...')
#将事务数据集转化为二元表示
ct = lambda x : pd.Series(1, index = x[pd.notnull(x)]) #用匿名函数转换0-1矩阵的过渡函数,里面的取值变为了index
b = map(ct, data.as_matrix()) #转换为numpy的array形式,然后再用map方式执行匿名函数
#这里为什么要用as_matrix转换?因为map函数第二个参数一般为数组
data1 = pd.DataFrame(list(b)).fillna(0)#map结果需要用list()才能显示
support = 0.2#定义支持度
confidence = 0.5 #最小置信度
ms = '---'#定义连接符
find_rule(data1, support, confidence, ms)
转换原始数据至0-1矩阵...
正在进行第1次搜索...
数目:6...
第1次搜索出结果啦!!!
结果为:
support confidence
e---a 0.3 1.000000
e---c 0.3 1.000000
a---b 0.5 0.714286
c---a 0.5 0.714286
a---c 0.5 0.714286
c---b 0.5 0.714286
b---a 0.5 0.625000
b---c 0.5 0.625000
正在进行第2次搜索...
数目:3...
第2次搜索出结果啦!!!
结果为:
support confidence
e---a 0.3 1.000000
e---c 0.3 1.000000
c---e---a 0.3 1.000000
a---e---c 0.3 1.000000
a---b 0.5 0.714286
c---a 0.5 0.714286
a---c 0.5 0.714286
c---b 0.5 0.714286
b---a 0.5 0.625000
b---c 0.5 0.625000
b---c---a 0.3 0.600000
a---c---b 0.3 0.600000
a---b---c 0.3 0.600000
a---c---e 0.3 0.600000
正在进行第3次搜索...
数目:0...
第3次搜索出结果啦!!!
结果为:
support confidence
e---a 0.3 1.000000
e---c 0.3 1.000000
c---e---a 0.3 1.000000
a---e---c 0.3 1.000000
a---b 0.5 0.714286
c---a 0.5 0.714286
a---c 0.5 0.714286
c---b 0.5 0.714286
b---a 0.5 0.625000
b---c 0.5 0.625000
b---c---a 0.3 0.600000
a---c---b 0.3 0.600000
a---b---c 0.3 0.600000
a---c---e 0.3 0.600000
C:\Anaconda3\lib\site-packages\ipykernel\__main__.py:50: FutureWarning: sort(columns=....) is deprecated, use sort_values(by=.....)
| support | confidence | |
|---|---|---|
| e---a | 0.3 | 1.000000 |
| e---c | 0.3 | 1.000000 |
| c---e---a | 0.3 | 1.000000 |
| a---e---c | 0.3 | 1.000000 |
| a---b | 0.5 | 0.714286 |
| c---a | 0.5 | 0.714286 |
| a---c | 0.5 | 0.714286 |
| c---b | 0.5 | 0.714286 |
| b---a | 0.5 | 0.625000 |
| b---c | 0.5 | 0.625000 |
| b---c---a | 0.3 | 0.600000 |
| a---c---b | 0.3 | 0.600000 |
| a---b---c | 0.3 | 0.600000 |
| a---c---e | 0.3 | 0.600000 |
其中,e---a表示e发生能够推出a发生,置信度为100%,支持度为30%;b---c---a表示b、 c同时发生时能够推出a发生,置信度为60%,支持度为30%等。搜索出来的关联规则不一定 具有实际意义,需要根据问题背景筛选适当的有意义的规则,并赋予合理的解释。