Scraping Recent Ofsted Reports¶
In the UK, schools are regularly inspected by Ofsted, the Office for Standards in Education, Children’s Services and Skills. Inspection reports are made public and can be searched for via the Ofsted website. Searches can be made over different time periods and across different sectors.
Here's one example of a particular investigation that required looking at reports published in the previous week (one of the available search limits) that referred to primary schools.
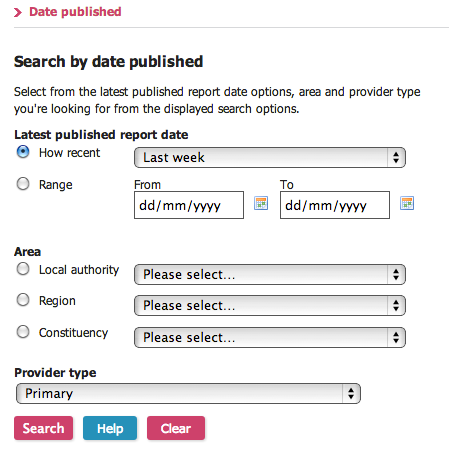
The search returns pages of two sorts:
- results listings
- individual school reports
The results listings are themselves spread over several pages:
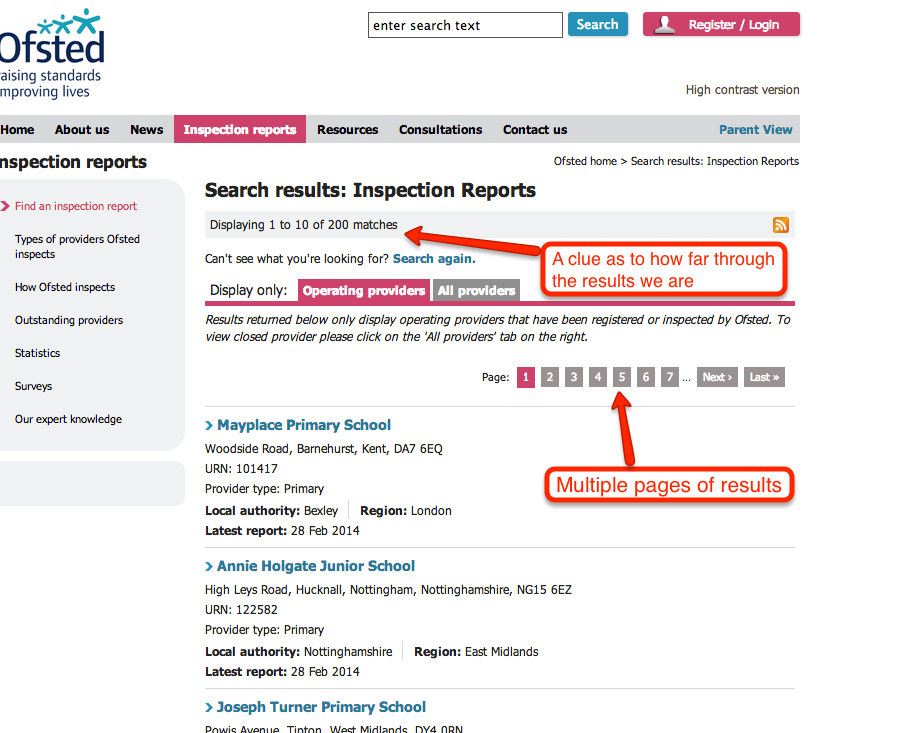
The indvidual school report pages are linked to from the results listing. The report pages are published according to a template, so they all have a similar look, and more importantly, a similar structure at the level of HTML, the language the pages are actually written in.

The brief was was capture the Overall effectiveness of each school. A further useful requirement was to obtain the information necessary to be able to pinpoint the location, even if only approximately, of the school on a map.
This notebook describes a series of simple steps taken to construct a screenscraping/webscraping tool capable of:
- getting a list of all the results of a search for primary school reports published in the last week, results that may be spread over several results pages
- getting the name, identifier, and postcode (which provides enough information to crudely plot the location) of each school identified in the results
Note that the scraper isn't necessarily as efficient as it could be. The intention as much as anything is to demonstrate one possible walkthrough of the sorts of problem solving you might engage in when trying to address this sort of task.
Obtaining Information About Each Reported School¶
The first step we will take is to look at a typical school report page. The information we primarily want to extract is the Overall effectiveness.
#The first thing we need to do is bring in some helper libraries
#We're going to load in web pages, so a tool for doing that
import urllib
#We may need to do some complex string matching, which typically require the use of regular expressions
import re
#There are various tools to help us extract information from web page defining HTML. I'm using BeautifulSoup
#If you don't have BeautifulSoup installed, uncomment and execute the following shell command
#!pip install beautifulsoup
from BeautifulSoup import BeautifulSoup
Let's start by trying to grab the information from a single report page.
Here's what the structure of the page looks like - in the Chrome browser I can use the in-built Developer Tools to inspect the HTML structure of an element:
- highlight the element in the page
- raise the context sensitive menu by right-clicking
- select Inspect Element
- view the result in the developer tools area

In this case I see that the Overall effectiveness result is contained within a <span> element that has a particular class, ins-judgement ins-judgement-2.
Let's see if we can grab that.
#First we need to load in the page from the target web address/URL
#urllib2.urlopen(url) opens the connection
#.read() reads in the HTML from the connection
#BeautifulSoup() parses the HTML and puts it in a form we can work with
url='http://www.ofsted.gov.uk/inspection-reports/find-inspection-report/provider/ELS/116734'
soup = BeautifulSoup(urllib2.urlopen(url).read())
#We can search the soup to look for span elements with the specified class
#A list of results is returned so we pick the first (in fact, only) result which has index value [0]
#Then we want to look at the text that is contained within that span element
print soup('span', {'class': 'ins-judgement ins-judgement-2'})[0].text
Good
Inspecting some other pages, we notice that the second, numerically qualified ins-judgement-N element corresponds to the the overall outcome.
This means that if we try to parse a page corresponding to a school with a different outcome, which leads to a class value of ins-judgement-3 appearing, the scrape won't work - no match will be made.
We can get round this by using a regular expression that will match the class on the first part, just the ins-judgement. In regular expression speak, the ^ means 'starting at the beginning of the string' and the .* means 'match any number (*) of any character (.)'.
print soup('span', {'class': re.compile(r"^ins-judgement.*") })[0].text
Good
We can now make a little function out of this to grab the overall assessment from any report page:
def stripper(url):
soup=BeautifulSoup(urllib2.urlopen(url).read())
return soup('span', {'class': re.compile(r"ins-judgement.*")})[0].text
url='http://www.ofsted.gov.uk/inspection-reports/find-inspection-report/provider/ELS/116734'
outcome=stripper(url)
print outcome
Good
So now we have a tool for getting the overall assessment from a report page.
The next step is to find a way of getting a list of the results, and more importantly, the web addresses/URLs for the reports listed in those results.
Parsing the Search Results Listing¶
Recall that the results were presented over several pages, each of a common design. As we did with the individual report pages, let's see if we can grab results from one page first, then worry about how to cover all the pages later.
As before, we can right click on an element in Chrome and select Inspect Element to see if there are any clues about how we can grab the element(s).
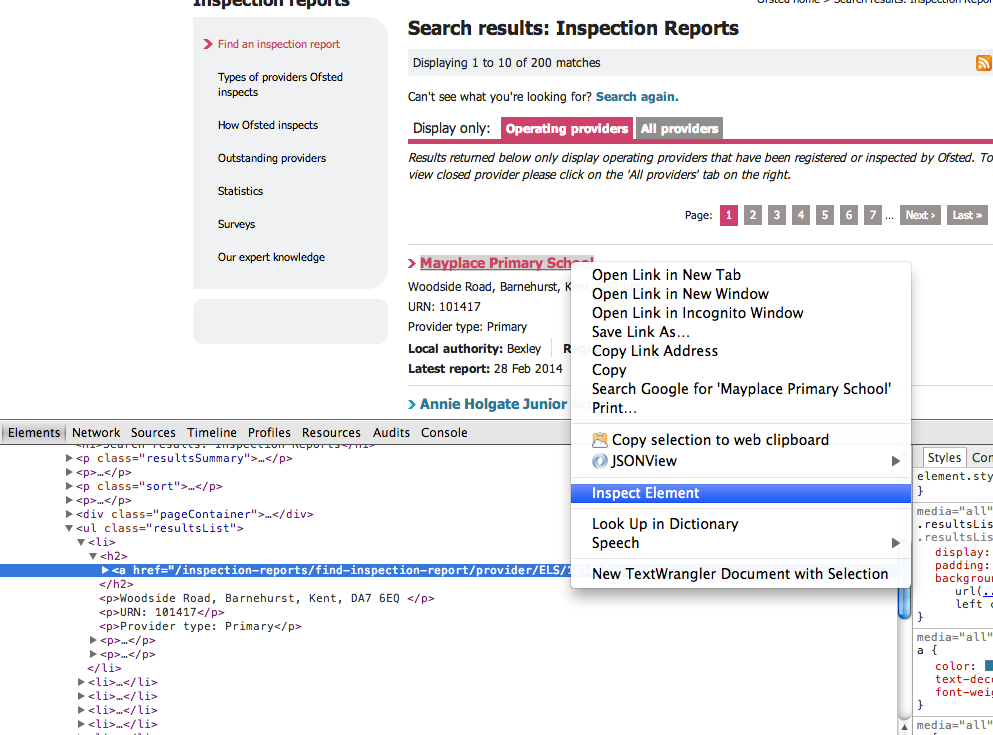
THe results appear to be contained within list items (<li>) within an unordered list (<ul>) of class resultsList.
Let's see how to grab the list of items, then for each item the URL, the significant part of which at least is contined in the href attribute of the only anchor element (<a>) in the list item:
#Identify a results page, then make some soup from it
url='http://www.ofsted.gov.uk/inspection-reports/find-inspection-report/results/any/21/any/any/any/any/any/any/any/week/0/0?page=0'
soup=BeautifulSoup(urllib2.urlopen(url).read())
for result in soup('ul',{'class':'resultsList'})[0].findAll('li'):
urlstub=result.find('a')['href']
print urlstub
/inspection-reports/find-inspection-report/provider/ELS/101417 /inspection-reports/find-inspection-report/provider/ELS/122582 /inspection-reports/find-inspection-report/provider/ELS/103970 /inspection-reports/find-inspection-report/provider/ELS/116734 /inspection-reports/find-inspection-report/provider/ELS/124196 /inspection-reports/find-inspection-report/provider/ELS/112497 /inspection-reports/find-inspection-report/provider/ELS/120778 /inspection-reports/find-inspection-report/provider/ELS/121082 /inspection-reports/find-inspection-report/provider/ELS/111939 /inspection-reports/find-inspection-report/provider/ELS/112855
Let's make a quick function that can use this stub to generate the full web address of a report page, and then get the overal assessment result back from that page.
def fullstripper(urlstub):
url='http://www.ofsted.gov.uk'+urlstub
return stripper(url)
Let's tweak the code that grabbed the partial URLs, and use the fullstripper() function to display the assessemnt outcome for the school corresponding to each one.
for result in soup('ul',{'class':'resultsList'})[0].findAll('li'):
urlstub=result.find('a')['href']
print fullstripper(urlstub)
Requires Improvement Inadequate Good Good Requires Improvement Requires Improvement Inadequate Requires Improvement Good Requires Improvement
From the HTML of the results page, I notice that the first paragraph (<p>) element in each list item contains an address. Thiese appear to be in a standard, convention form: a posctode appears at the end of each address, preceded by a comma and a space.
If we grab the first <p> element, split the string inside it at each comma, and pick the last split item, it should contain the postcode. Let's build on the previous bit of code to see if we can grab postcodes too:
for result in soup('ul',{'class':'resultsList'})[0].findAll('li'):
urlstub=result.find('a')['href']
#Rather than print the outcome, pop it into a variable
outcome=fullstripper(urlstub)
#Find the first <p> element, split on commas, get last item
pc=result.find('p').text.split(',')[-1]
print outcome, pc
Requires Improvement DA7 6EQ Inadequate NG15 6EZ Good DY4 0RN Good HR6 9LX Requires Improvement ST16 1PW Requires Improvement DE55 4BW Inadequate NR11 8UG Requires Improvement NR10 3LF Good PL34 0DU Requires Improvement DE7 6FS
Remember the URL stubs? They had the form /inspection-reports/find-inspection-report/provider/ELS/112855. The last part is actually the URN identifier for the school - let's grab that too:
for result in soup('ul',{'class':'resultsList'})[0].findAll('li'):
urlstub=result.find('a')['href']
#Grab the URN from the end of the URL stub
urn=urlstub.split('/')[-1]
#Rather than print the outcome, pop it into a variable
outcome=fullstripper(urlstub)
#Find the first <p> element, split on commas, get last item
pc=result.find('p').text.split(',')[-1]
print outcome, pc, urn
Requires Improvement DA7 6EQ 101417 Inadequate NG15 6EZ 122582 Good DY4 0RN 103970 Good HR6 9LX 116734 Requires Improvement ST16 1PW 124196 Requires Improvement DE55 4BW 112497 Inadequate NR11 8UG 120778 Requires Improvement NR10 3LF 121082 Good PL34 0DU 111939 Requires Improvement DE7 6FS 112855
Having got the postcode, there is a service we can use to get a latitude and lonigitude from somewhere around the middle of that unit postcode area. I won't go into details of how this works, but you may be able to figure it out... (JSON is Javascript Object Notation, a popular format for moving data around the web.)
#We need another helper library
import json
#Define a function to get latitude and longitude for a given UK postcode
def geoCodePostcode(postcode):
#No spaces allowed in the postcode we pass to the geocoding service
url='http://uk-postcodes.com/postcode/'+postcode.replace(' ','')+'.json'
data = json.load(urllib2.urlopen(url))
return data['geo']['lat'],data['geo']['lng']
#Let's try it
pc='MK7 6AA'
lat,lng = geoCodePostcode(pc)
print pc, lat, lng
MK7 6AA 52.0249148197 -0.709732906623
Let's work that in to where we were before:
for result in soup('ul',{'class':'resultsList'})[0].findAll('li'):
urlstub=result.find('a')['href']
#Grab the URN from the end of the URL stub
urn=urlstub.split('/')[-1]
#Rather than print the outcome, pop it into a variable
outcome=fullstripper(urlstub)
#Find the first <p> element, split on commas, get last item
pc=result.find('p').text.split(',')[-1]
#Geocode the postcode
lat,lng = geoCodePostcode(pc)
print outcome, pc, urn, lat, lng
Requires Improvement DA7 6EQ 101417 51.4568773266 0.166706916506 Inadequate NG15 6EZ 122582 53.0310189204 -1.21430274035 Good DY4 0RN 103970 52.5337301944 -2.05587338671 Good HR6 9LX 116734 52.251960633 -2.87982511819 Requires Improvement ST16 1PW 124196 52.8219450955 -2.12846752628 Requires Improvement DE55 4BW 112497 53.0698946677 -1.36432134803 Inadequate NR11 8UG 120778 52.8664965086 1.35545908317 Requires Improvement NR10 3LF 121082 52.6952250035 1.28249418915 Good PL34 0DU 111939 50.6580313296 -4.74839945855 Requires Improvement DE7 6FS 112855 52.9758021017 -1.38102662274
Looking good - but what's the name of the school? It's contained by the anchor element:

Let's be quick and scruffy in how we pull this out...we're gong to catch the 1 from the comment, but then we'll strip it out...
for result in soup('ul',{'class':'resultsList'})[0].findAll('li'):
urlstub=result.find('a')['href']
#Grab the URN from the end of the URL stub
urn=urlstub.split('/')[-1]
#Rather than print the outcome, pop it into a variable
outcome=fullstripper(urlstub)
#Find the first <p> element, split on commas, get last item
pc=result.find('p').text.split(',')[-1]
#Geocode the postcode
lat,lng = geoCodePostcode(pc)
#Get the school name and strip out the cruft
name=result.find('a').text.strip('1')
print outcome, pc, urn, lat, lng, name
Requires Improvement DA7 6EQ 101417 51.4568773266 0.166706916506 Mayplace Primary School Inadequate NG15 6EZ 122582 53.0310189204 -1.21430274035 Annie Holgate Junior School Good DY4 0RN 103970 52.5337301944 -2.05587338671 Joseph Turner Primary School Good HR6 9LX 116734 52.251960633 -2.87982511819 Shobdon Primary School Requires Improvement ST16 1PW 124196 52.8219450955 -2.12846752628 Tillington Manor Primary School Requires Improvement DE55 4BW 112497 53.0698946677 -1.36432134803 Riddings Junior School Inadequate NR11 8UG 120778 52.8664965086 1.35545908317 Antingham and Southrepps Community Primary School Requires Improvement NR10 3LF 121082 52.6952250035 1.28249418915 St Faith's CofE Primary School Good PL34 0DU 111939 50.6580313296 -4.74839945855 Tintagel Primary School Requires Improvement DE7 6FS 112855 52.9758021017 -1.38102662274 Stanley Common CofE Primary School
So we've managed to pull quite a bit of information from the results listing. It might have been tidier to extract the same information from the actual results page, in effect creating an API over the results page, but that can be left as an exercise for the reader... (i.e. just get the urlstb from the results listing then pull all the other information from an individual school report page).
The next thing we need to address is getting the results list from each results page.
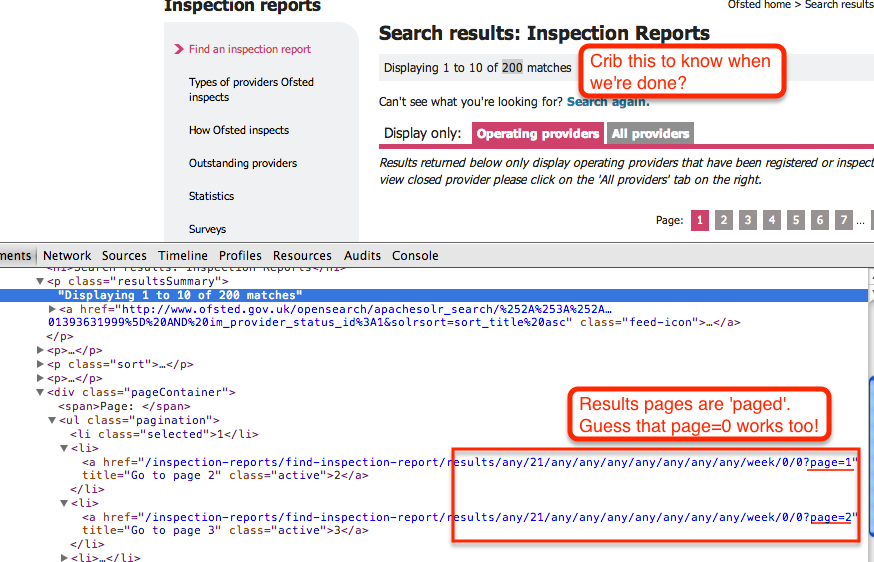
There are two things to consider:
- how do we identify each page? In this case, the results pages are numbered. We guess (and try it to check) that
page=0also works for the first results page... - how do we know when we're done? We could just load the first results page (without using a page index value) and then look for the list of other results pages, grabbing those URLs and then cycling through them. Another technique is to make use of the Displaying M to N of NN statement. When N==NN we know we're done...
#Let's have a quick try at parsing the line that sayas which results are displayed...
txt=soup('p',{'class':'resultsSummary'})[0].text
print txt
#We can use a regular expression to parse out the values of interest
m = re.match(".*Displaying \d* to (\d*) of (\d*) matches.*", txt)
print m.group(1), m.group(2)
Displaying 1 to 10 of 200 matches 10 200
Let's try to put the pieces together, by first considering the logic of it...
#Set the scraper running flag to True...
running=True
#Start with results page 0
page=0
#While we've still got results to fetch...
while running:
#Create the results page URL
stub='http://www.ofsted.gov.uk/inspection-reports/find-inspection-report/results/any/21/any/any/any/any/any/any/any/week/0/0?page='
url=stub+str(page)
soup=BeautifulSoup(urllib2.urlopen(url).read())
page=page+1
print page,'...',
#Extracting results and then fetching info on each result would go here
bit=soup('p',{'class':'resultsSummary'})[0].text
m = re.match(".*Displaying \d* to (\d*) of (\d*) matches.*", bit)
if m.group(1)==m.group(2):
running = False
1 ... 2 ... 3 ... 4 ... 5 ... 6 ... 7 ... 8 ... 9 ... 10 ... 11 ... 12 ... 13 ... 14 ... 15 ... 16 ... 17 ... 18 ... 19 ... 20 ...
running =True
page=0
#I'm going to build a list of reports
reports=[]
while running:
stub='http://www.ofsted.gov.uk/inspection-reports/find-inspection-report/results/any/21/any/any/any/any/any/any/any/week/0/0?page='
soup=BeautifulSoup(urllib2.urlopen(stub+str(page)).read())
page=page+1
print page,'...',
for result in soup('ul',{'class':'resultsList'})[0].findAll('li'):
urlstub=result.find('a')['href']
#Grab the URN from the end of the URL stub
urn=urlstub.split('/')[-1]
#Rather than print the outcome, pop it into a variable
outcome=fullstripper(urlstub)
#Find the first <p> element, split on commas, get last item
pc=result.find('p').text.split(',')[-1]
#Geocode the postcode
lat,lng = geoCodePostcode(pc)
#Get the school name and strip out the cruft
name=result.find('a').text.strip('1')
#Rather than print the data, let's add it to the report list as a line item
#print outcome, pc, urn, lat, lng, name
reports.append([outcome, pc, urn, lat, lng, name])
bit=soup('p',{'class':'resultsSummary'})[0].text
m = re.match(".*Displaying \d* to (\d*) of (\d*) matches.*", bit)
if m.group(1)==m.group(2):
running = False
1 ... 2 ... 3 ... 4 ... 5 ... 6 ... 7 ... 8 ... 9 ... 10 ... 11 ... 12 ... 13 ... 14 ... 15 ... 16 ... 17 ... 18 ... 19 ... 20 ...
#Preview the first few report lines
for report in reports[:5]:
print report
[u'Requires Improvement', u' DA7 6EQ', u'101417', 51.4568773266355, 0.16670691650597483, u'Mayplace Primary School'] [u'Inadequate', u' NG15 6EZ', u'122582', 53.03101892042224, -1.2143027403533455, u'Annie Holgate Junior School'] [u'Good', u' DY4 0RN', u'103970', 52.53373019436544, -2.055873386710021, u'Joseph Turner Primary School'] [u'Good', u' HR6 9LX', u'116734', 52.25196063299823, -2.8798251181915, u'Shobdon Primary School'] [u'Requires Improvement', u' ST16 1PW', u'124196', 52.821945095483734, -2.128467526279911, u'Tillington Manor Primary School']
Outputting the Data¶
Having grabbed all the data - and parsed it - we can write it out to a CSV file.
#Get the CSV helper library that makes sure we write nice CSV out
import csv
f = csv.writer(open('sampleReport.csv', 'wb+'))
f.writerow(['outcome', 'pc', 'urn', 'lat', 'lng', 'name'])
for report in reports:
f.writerow(report)
#Use a commandline command to preview the head of the CSV file
!head sampleReport.csv
Summary¶
So that's all there is to it... break the problem down into small steps, and then piece them together...