Setup Visdom¶
Install it with:
pip install visdom
Start the server:
python -m visdom.server
Visdom now can be accessed at http://localhost:8097 in the browser.
LDA Training Visualization¶
Knowing about the progress and performance of a model, as we train them, could be very helpful in understanding it’s learning process and makes it easier to debug and optimize them. In this notebook, we will learn how to visualize training statistics for LDA topic model in gensim. To monitor the training, a list of Metrics is passed to the LDA function call for plotting their values live as the training progresses.

Let's plot the training stats for an LDA model being trained on kaggle's fake news dataset. We will use the four evaluation metrics available for topic models in gensim: Coherence, Perplexity, Topic diff and Convergence. (using separate hold_out and test corpus for evaluating the perplexity)
from gensim.models import ldamodel
from gensim.corpora import Dictionary
import pandas as pd
import re
from gensim.parsing.preprocessing import remove_stopwords, strip_punctuation
import numpy as np
df_fake = pd.read_csv('fake.csv')
df_fake[['title', 'text', 'language']].head()
df_fake = df_fake.loc[(pd.notnull(df_fake.text)) & (df_fake.language == 'english')]
# remove stopwords and punctuations
def preprocess(row):
return strip_punctuation(remove_stopwords(row.lower()))
df_fake['text'] = df_fake['text'].apply(preprocess)
# Convert data to required input format by LDA
texts = []
for line in df_fake.text:
lowered = line.lower()
words = re.findall(r'\w+', lowered, flags = re.UNICODE | re.LOCALE)
texts.append(words)
dictionary = Dictionary(texts)
training_texts = texts[:5000]
holdout_texts = texts[5000:7500]
test_texts = texts[7500:10000]
training_corpus = [dictionary.doc2bow(text) for text in training_texts]
holdout_corpus = [dictionary.doc2bow(text) for text in holdout_texts]
test_corpus = [dictionary.doc2bow(text) for text in test_texts]
Using TensorFlow backend.
from gensim.models.callbacks import CoherenceMetric, DiffMetric, PerplexityMetric, ConvergenceMetric
# define perplexity callback for hold_out and test corpus
pl_holdout = PerplexityMetric(corpus=holdout_corpus, logger="visdom", title="Perplexity (hold_out)")
pl_test = PerplexityMetric(corpus=test_corpus, logger="visdom", title="Perplexity (test)")
# define other remaining metrics available
ch_umass = CoherenceMetric(corpus=training_corpus, coherence="u_mass", logger="visdom", title="Coherence (u_mass)")
ch_cv = CoherenceMetric(corpus=training_corpus, texts=training_texts, coherence="c_v", logger="visdom", title="Coherence (c_v)")
diff_kl = DiffMetric(distance="kullback_leibler", logger="visdom", title="Diff (kullback_leibler)")
convergence_kl = ConvergenceMetric(distance="jaccard", logger="visdom", title="Convergence (jaccard)")
callbacks = [pl_holdout, pl_test, ch_umass, ch_cv, diff_kl, convergence_kl]
# training LDA model
model = ldamodel.LdaModel(corpus=training_corpus, id2word=dictionary, num_topics=35, passes=50, chunksize=1500, iterations=200, alpha='auto', callbacks=callbacks)
When the model is set for training, you can open http://localhost:8097 to see the training progress.
# to get a metric value on a trained model
print(CoherenceMetric(corpus=training_corpus, coherence="u_mass").get_value(model=model))
-0.259766196856
The four types of graphs which are plotted for LDA:
Coherence
Coherence measures are generally based on the idea of computing the sum of pairwise scores of top n words w1, ...,wn used to describe the topic. There are four coherence measures available in gensim: u_mass, c_v, c_uci, c_npmi. A good model will generate coherent topics, i.e., topics with high topic coherence scores. Good topics can be described by a short label based on the topic terms they spit out.

Now, this graph along with the others explained below, can be used to decide if it's time to stop the training. We can see if the value stops changing after some epochs and that we are able to get the highest possible coherence of our model.
Perplexity
Perplexity is a measurement of how well a probability distribution or probability model predicts a sample. In LDA, topics are described by a probability distribution over vocabulary words. So, perplexity can be used to evaluate the topic-term distribution output by LDA.

For a good model, perplexity should be low.
Topic Difference
Topic Diff calculates the distance between two LDA models. This distance is calculated based on the topics, by either using their probability distribution over vocabulary words (kullback_leibler, hellinger) or by simply using the common vocabulary words between the topics from both model.

In the heatmap, X-axis define the Epoch no. and Y-axis define the distance between identical topics from consecutive epochs. For ex. a particular cell in the heatmap with values (x=3, y=5, z=0.4) represent the distance(=0.4) between the topic 5 from 3rd epoch and topic 5 from 2nd epoch. With increasing epochs, the distance between the identical topics should decrease.
Convergence
Convergence is the sum of the difference between all the identical topics from two consecutive epochs. It is basically the sum of column values in the heatmap above.
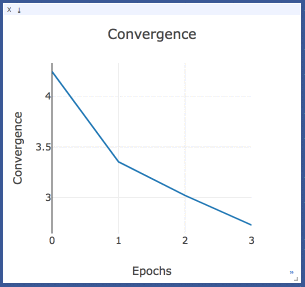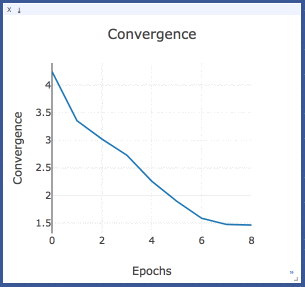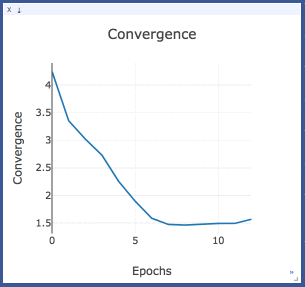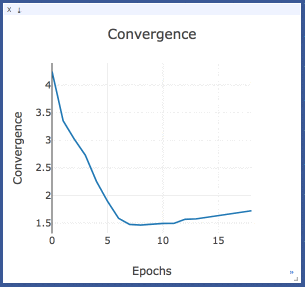
The model is said to be converged when the convergence value stops descending with increasing epochs.
Training Logs¶
We can also log the metric values after every epoch to the shell apart from visualizing them in Visdom. The only change is to define logger="shell" instead of "visdom" in the input callbacks.
import logging
from gensim.models.callbacks import CoherenceMetric, DiffMetric, PerplexityMetric, ConvergenceMetric
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
logger.setLevel(logging.DEBUG)
# define perplexity callback for hold_out and test corpus
pl_holdout = PerplexityMetric(corpus=holdout_corpus, logger="shell", title="Perplexity (hold_out)")
pl_test = PerplexityMetric(corpus=test_corpus, logger="shell", title="Perplexity (test)")
# define other remaining metrics available
ch_umass = CoherenceMetric(corpus=training_corpus, coherence="u_mass", logger="shell", title="Coherence (u_mass)")
diff_kl = DiffMetric(distance="kullback_leibler", logger="shell", title="Diff (kullback_leibler)")
convergence_jc = ConvergenceMetric(distance="jaccard", logger="shell", title="Convergence (jaccard)")
callbacks = [pl_holdout, pl_test, ch_umass, diff_kl, convergence_jc]
# training LDA model
model = ldamodel.LdaModel(corpus=training_corpus, id2word=dictionary, num_topics=35, passes=2, eval_every=None, callbacks=callbacks)
INFO:gensim.models.ldamodel:using symmetric alpha at 0.02857142857142857 INFO:gensim.models.ldamodel:using symmetric eta at 1.0996744963490807e-05 INFO:gensim.models.ldamodel:using serial LDA version on this node INFO:gensim.models.ldamodel:running online (multi-pass) LDA training, 35 topics, 2 passes over the supplied corpus of 5000 documents, updating model once every 2000 documents, evaluating perplexity every 0 documents, iterating 50x with a convergence threshold of 0.001000 WARNING:gensim.models.ldamodel:too few updates, training might not converge; consider increasing the number of passes or iterations to improve accuracy INFO:gensim.models.ldamodel:PROGRESS: pass 0, at document #2000/5000 INFO:gensim.models.ldamodel:merging changes from 2000 documents into a model of 5000 documents INFO:gensim.models.ldamodel:topic #5 (0.029): 0.019*"s" + 0.007*"clinton" + 0.006*"hillary" + 0.005*"t" + 0.005*"it" + 0.005*"people" + 0.004*"trump" + 0.003*"2016" + 0.003*"state" + 0.003*"new" INFO:gensim.models.ldamodel:topic #24 (0.029): 0.024*"s" + 0.006*"it" + 0.005*"trump" + 0.005*"t" + 0.004*"u" + 0.004*"clinton" + 0.003*"people" + 0.003*"world" + 0.003*"obama" + 0.003*"new" INFO:gensim.models.ldamodel:topic #4 (0.029): 0.012*"s" + 0.005*"people" + 0.004*"time" + 0.003*"trump" + 0.003*"t" + 0.003*"email" + 0.003*"new" + 0.003*"it" + 0.003*"war" + 0.002*"state" INFO:gensim.models.ldamodel:topic #34 (0.029): 0.011*"s" + 0.007*"trump" + 0.005*"people" + 0.004*"t" + 0.004*"clinton" + 0.003*"new" + 0.003*"government" + 0.003*"said" + 0.003*"it" + 0.003*"time" INFO:gensim.models.ldamodel:topic #25 (0.029): 0.020*"s" + 0.004*"u" + 0.004*"trump" + 0.004*"people" + 0.004*"government" + 0.004*"it" + 0.003*"american" + 0.003*"t" + 0.003*"state" + 0.003*"saudi" INFO:gensim.models.ldamodel:topic diff=24.655166, rho=1.000000 INFO:gensim.models.ldamodel:PROGRESS: pass 0, at document #4000/5000 INFO:gensim.models.ldamodel:merging changes from 2000 documents into a model of 5000 documents INFO:gensim.models.ldamodel:topic #25 (0.029): 0.016*"s" + 0.004*"people" + 0.003*"u" + 0.003*"saudi" + 0.003*"government" + 0.003*"daily" + 0.003*"trump" + 0.003*"stormer" + 0.003*"it" + 0.003*"2016" INFO:gensim.models.ldamodel:topic #32 (0.029): 0.010*"s" + 0.005*"world" + 0.005*"it" + 0.004*"horowitz" + 0.004*"ice" + 0.003*"people" + 0.003*"t" + 0.003*"like" + 0.002*"white" + 0.002*"fukushima" INFO:gensim.models.ldamodel:topic #6 (0.029): 0.018*"s" + 0.009*"clinton" + 0.009*"trump" + 0.009*"t" + 0.007*"people" + 0.007*"hillary" + 0.006*"election" + 0.005*"like" + 0.004*"new" + 0.004*"it" INFO:gensim.models.ldamodel:topic #1 (0.029): 0.009*"s" + 0.005*"comment" + 0.004*"facebook" + 0.004*"article" + 0.004*"account" + 0.004*"people" + 0.003*"war" + 0.003*"goat" + 0.003*"t" + 0.003*"disqus" INFO:gensim.models.ldamodel:topic #33 (0.029): 0.009*"s" + 0.008*"people" + 0.005*"said" + 0.004*"t" + 0.004*"it" + 0.004*"trump" + 0.003*"government" + 0.003*"clinton" + 0.003*"fbi" + 0.003*"police" INFO:gensim.models.ldamodel:topic diff=3.855081, rho=0.707107 INFO:gensim.models.ldamodel:PROGRESS: pass 0, at document #5000/5000 INFO:gensim.models.ldamodel:merging changes from 1000 documents into a model of 5000 documents INFO:gensim.models.ldamodel:topic #7 (0.029): 0.013*"s" + 0.007*"it" + 0.006*"nuclear" + 0.006*"t" + 0.006*"activation" + 0.005*"placement" + 0.004*"clinton" + 0.003*"people" + 0.003*"hillary" + 0.003*"time" INFO:gensim.models.ldamodel:topic #23 (0.029): 0.008*"s" + 0.004*"people" + 0.004*"water" + 0.003*"halloween" + 0.003*"t" + 0.003*"it" + 0.003*"silver" + 0.003*"jesus" + 0.003*"world" + 0.003*"flickr" INFO:gensim.models.ldamodel:topic #31 (0.029): 0.014*"s" + 0.006*"t" + 0.004*"it" + 0.004*"people" + 0.004*"new" + 0.003*"girl" + 0.003*"child" + 0.003*"ellison" + 0.003*"know" + 0.003*"trump" INFO:gensim.models.ldamodel:topic #13 (0.029): 0.014*"s" + 0.010*"t" + 0.005*"government" + 0.004*"school" + 0.004*"i" + 0.004*"president" + 0.003*"people" + 0.003*"trump" + 0.003*"like" + 0.003*"time" INFO:gensim.models.ldamodel:topic #25 (0.029): 0.111*"utm" + 0.015*"force" + 0.012*"s" + 0.007*"tzrwu" + 0.007*"ims" + 0.007*"infowarsstore" + 0.006*"dr" + 0.006*"25" + 0.006*"and" + 0.005*"vitamin" INFO:gensim.models.ldamodel:topic diff=2.676513, rho=0.577350 INFO:gensim.models.ldamodel:Epoch 0: Perplexity (hold_out) estimate: 2891.88630978 INFO:gensim.models.ldamodel:Epoch 0: Perplexity (test) estimate: 1874.8109115 INFO:gensim.topic_coherence.text_analysis:CorpusAccumulator accumulated stats from 1000 documents INFO:gensim.topic_coherence.text_analysis:CorpusAccumulator accumulated stats from 2000 documents INFO:gensim.topic_coherence.text_analysis:CorpusAccumulator accumulated stats from 3000 documents INFO:gensim.topic_coherence.text_analysis:CorpusAccumulator accumulated stats from 4000 documents INFO:gensim.topic_coherence.text_analysis:CorpusAccumulator accumulated stats from 5000 documents INFO:gensim.models.ldamodel:Epoch 0: Coherence (u_mass) estimate: -2.03953260715 INFO:gensim.models.ldamodel:Epoch 0: Diff (kullback_leibler) estimate: [ 0.93640518 0.95952878 0.64519803 0.78364027 0.50865099 0.90607399 0.87627853 0.77941292 0.52529268 0.5848095 0.78475031 0.86041719 0.98346917 0.79422948 0.82464972 0.53735652 0.79245303 0.64592471 0.89265179 0.78584557 0.66037967 0.613174 0.8009025 0.68748952 0.77344932 0.96950451 0.80075146 0.83959967 0.83689681 0.70191726 1. 0.69856365 0.60616776 0.81112339 0.54781754] INFO:gensim.models.ldamodel:Epoch 0: Convergence (jaccard) estimate: 34.9295467235 INFO:gensim.models.ldamodel:PROGRESS: pass 1, at document #2000/5000 INFO:gensim.models.ldamodel:merging changes from 2000 documents into a model of 5000 documents INFO:gensim.models.ldamodel:topic #13 (0.029): 0.013*"s" + 0.009*"t" + 0.006*"black" + 0.005*"school" + 0.004*"government" + 0.004*"i" + 0.003*"people" + 0.003*"president" + 0.003*"police" + 0.003*"like" INFO:gensim.models.ldamodel:topic #12 (0.029): 0.030*"infowars" + 0.023*"brain" + 0.013*"force" + 0.010*"s" + 0.009*"com" + 0.007*"life" + 0.006*"www" + 0.005*"http" + 0.005*"content" + 0.005*"source" INFO:gensim.models.ldamodel:topic #17 (0.029): 0.012*"obamacare" + 0.010*"people" + 0.009*"s" + 0.007*"care" + 0.006*"health" + 0.006*"insurance" + 0.005*"t" + 0.005*"premiums" + 0.005*"brock" + 0.004*"it" INFO:gensim.models.ldamodel:topic #10 (0.029): 0.025*"s" + 0.009*"israel" + 0.005*"said" + 0.005*"jewish" + 0.004*"american" + 0.004*"muslim" + 0.004*"t" + 0.003*"it" + 0.003*"anti" + 0.003*"israeli" INFO:gensim.models.ldamodel:topic #33 (0.029): 0.009*"s" + 0.008*"vaccine" + 0.007*"people" + 0.006*"flu" + 0.005*"vaccines" + 0.005*"virus" + 0.005*"marijuana" + 0.005*"court" + 0.005*"medical" + 0.004*"zika" INFO:gensim.models.ldamodel:topic diff=1.496938, rho=0.471405 INFO:gensim.models.ldamodel:PROGRESS: pass 1, at document #4000/5000 INFO:gensim.models.ldamodel:merging changes from 2000 documents into a model of 5000 documents INFO:gensim.models.ldamodel:topic #17 (0.029): 0.017*"obamacare" + 0.009*"people" + 0.008*"s" + 0.008*"insurance" + 0.007*"care" + 0.007*"premiums" + 0.006*"health" + 0.005*"t" + 0.005*"godlike" + 0.004*"brock" INFO:gensim.models.ldamodel:topic #28 (0.029): 0.018*"retired" + 0.016*"syria" + 0.016*"s" + 0.013*"general" + 0.011*"syrian" + 0.010*"russian" + 0.010*"air" + 0.009*"russia" + 0.009*"force" + 0.009*"army" INFO:gensim.models.ldamodel:topic #24 (0.029): 0.021*"s" + 0.008*"t" + 0.006*"it" + 0.004*"people" + 0.004*"world" + 0.004*"u" + 0.003*"that" + 0.003*"don" + 0.003*"like" + 0.003*"i" INFO:gensim.models.ldamodel:topic #4 (0.029): 0.019*"email" + 0.015*"posts" + 0.011*"new" + 0.010*"subscribe" + 0.009*"notify" + 0.009*"follow" + 0.007*"donate" + 0.006*"radioactive" + 0.005*"up" + 0.005*"receive" INFO:gensim.models.ldamodel:topic #19 (0.029): 0.013*"s" + 0.007*"said" + 0.006*"water" + 0.005*"pipeline" + 0.005*"police" + 0.004*"dakota" + 0.004*"year" + 0.004*"t" + 0.003*"2016" + 0.003*"north" INFO:gensim.models.ldamodel:topic diff=1.335664, rho=0.471405 INFO:gensim.models.ldamodel:PROGRESS: pass 1, at document #5000/5000 INFO:gensim.models.ldamodel:merging changes from 1000 documents into a model of 5000 documents INFO:gensim.models.ldamodel:topic #31 (0.029): 0.011*"s" + 0.008*"child" + 0.008*"girl" + 0.007*"parents" + 0.006*"family" + 0.005*"old" + 0.005*"t" + 0.005*"baby" + 0.005*"ellison" + 0.005*"hospital" INFO:gensim.models.ldamodel:topic #16 (0.029): 0.036*"trump" + 0.013*"white" + 0.011*"obama" + 0.009*"people" + 0.008*"s" + 0.008*"president" + 0.007*"vote" + 0.006*"america" + 0.006*"black" + 0.006*"right" INFO:gensim.models.ldamodel:topic #12 (0.029): 0.050*"infowars" + 0.042*"brain" + 0.026*"force" + 0.023*"com" + 0.015*"life" + 0.013*"wellness" + 0.011*"content" + 0.011*"www" + 0.010*"source" + 0.010*"medium" INFO:gensim.models.ldamodel:topic #18 (0.029): 0.015*"vaccine" + 0.013*"s" + 0.011*"medical" + 0.010*"doctors" + 0.009*"dr" + 0.008*"vaccines" + 0.008*"cdc" + 0.007*"children" + 0.006*"cancer" + 0.006*"autism" INFO:gensim.models.ldamodel:topic #13 (0.029): 0.013*"s" + 0.010*"t" + 0.007*"government" + 0.007*"school" + 0.004*"police" + 0.004*"black" + 0.003*"law" + 0.003*"data" + 0.003*"at" + 0.003*"youtube" INFO:gensim.models.ldamodel:topic diff=1.217662, rho=0.471405 INFO:gensim.models.ldamodel:Epoch 1: Perplexity (hold_out) estimate: 1875.59367127 INFO:gensim.models.ldamodel:Epoch 1: Perplexity (test) estimate: 1369.87404449 INFO:gensim.topic_coherence.text_analysis:CorpusAccumulator accumulated stats from 1000 documents INFO:gensim.topic_coherence.text_analysis:CorpusAccumulator accumulated stats from 2000 documents INFO:gensim.topic_coherence.text_analysis:CorpusAccumulator accumulated stats from 3000 documents INFO:gensim.topic_coherence.text_analysis:CorpusAccumulator accumulated stats from 4000 documents INFO:gensim.topic_coherence.text_analysis:CorpusAccumulator accumulated stats from 5000 documents INFO:gensim.models.ldamodel:Epoch 1: Coherence (u_mass) estimate: -3.33917142783 INFO:gensim.models.ldamodel:Epoch 1: Diff (kullback_leibler) estimate: [ 0.09301981 0.71566666 0.67676685 0.35730119 1. 0.54864275 0.24120049 0.45830206 0.96709113 0.78362169 0.33318101 0.38479912 0.62038738 0.43474664 0.31502652 0.87644947 0.5223633 0.76557247 0.41316022 0.40029654 0.84127697 0.76384605 0.13714947 0.64728141 0.3992811 0.70301974 0.17202488 0.33375843 0.55556689 0.68845743 0.23326017 0.6709471 0.75061125 0.48405455 0.81424992] INFO:gensim.models.ldamodel:Epoch 1: Convergence (jaccard) estimate: 22.293262955
The metric values can also be accessed from the model instance for custom uses.
model.metrics
defaultdict(list,
{'Coherence (u_mass)': [-2.0395326071549267, -3.339171427828973],
'Convergence (jaccard)': [34.929546723516573, 22.293262954969034],
'Diff (kullback_leibler)': [array([ 0.93640518, 0.95952878, 0.64519803, 0.78364027, 0.50865099,
0.90607399, 0.87627853, 0.77941292, 0.52529268, 0.5848095 ,
0.78475031, 0.86041719, 0.98346917, 0.79422948, 0.82464972,
0.53735652, 0.79245303, 0.64592471, 0.89265179, 0.78584557,
0.66037967, 0.613174 , 0.8009025 , 0.68748952, 0.77344932,
0.96950451, 0.80075146, 0.83959967, 0.83689681, 0.70191726,
1. , 0.69856365, 0.60616776, 0.81112339, 0.54781754]),
array([ 0.09301981, 0.71566666, 0.67676685, 0.35730119, 1. ,
0.54864275, 0.24120049, 0.45830206, 0.96709113, 0.78362169,
0.33318101, 0.38479912, 0.62038738, 0.43474664, 0.31502652,
0.87644947, 0.5223633 , 0.76557247, 0.41316022, 0.40029654,
0.84127697, 0.76384605, 0.13714947, 0.64728141, 0.3992811 ,
0.70301974, 0.17202488, 0.33375843, 0.55556689, 0.68845743,
0.23326017, 0.6709471 , 0.75061125, 0.48405455, 0.81424992])],
'Perplexity (hold_out)': [2891.8863097795142, 1875.5936712709661],
'Perplexity (test)': [1874.8109114962135, 1369.8740444934508]})