from __future__ import unicode_literals, print_function, division
import glob
import random
from io import open
import torch
import torch.optim as optim
from sklearn.metrics import classification_report, confusion_matrix, accuracy_score
from torch import nn as nn, autograd
from torch.nn import functional as F
from torch.nn.utils.rnn import pack_padded_sequence, pad_packed_sequence
from torch.utils.data import Dataset, DataLoader
random.seed(1)
###
# Thanks to http://pytorch.org/tutorials/intermediate/char_rnn_classification_tutorial.html
# for these code snippets
###
def findFiles(path): return glob.glob(path)
import unicodedata
import string
all_letters = string.ascii_letters + " .,;'"
n_letters = len(all_letters)
# Turn a Unicode string to plain ASCII, thanks to http://stackoverflow.com/a/518232/2809427
def unicodeToAscii(s):
return ''.join(
c for c in unicodedata.normalize('NFD', s)
if unicodedata.category(c) != 'Mn'
and c in all_letters
)
# Build the category_lines dictionary, a list of names per language
category_lines = {}
all_categories = []
# Read a file and split into lines
def readLines(filename):
lines = open(filename, encoding='utf-8').read().strip().split('\n')
return [unicodeToAscii(line) for line in lines]
data = list()
for filename in findFiles('data/names/*.txt'):
category = filename.split('/')[-1].split('.')[0]
all_categories.append(category)
lines = readLines(filename)
for l in lines:
data.append((l, category))
data = random.sample(data, len(data))
TRAIN_BATCH_SIZE = 32
VALIDATION_BATCH_SIZE = 1
TEST_BATCH_SIZE = 1
"""
We are going to use the Dataset interface provided
by pytorch wich is really convenient when it comes to
batching our data
"""
class PaddedTensorDataset(Dataset):
"""Dataset wrapping data, target and length tensors.
Each sample will be retrieved by indexing both tensors along the first
dimension.
Arguments:
data_tensor (Tensor): contains sample data.
target_tensor (Tensor): contains sample targets (labels).
length (Tensor): contains sample lengths.
raw_data (Any): The data that has been transformed into tensor, useful for debugging
"""
def __init__(self, data_tensor, target_tensor, length_tensor, raw_data):
assert data_tensor.size(0) == target_tensor.size(0) == length_tensor.size(0)
self.data_tensor = data_tensor
self.target_tensor = target_tensor
self.length_tensor = length_tensor
self.raw_data = raw_data
def __getitem__(self, index):
return self.data_tensor[index], self.target_tensor[index], self.length_tensor[index], self.raw_data[index]
def __len__(self):
return self.data_tensor.size(0)
"""
A couple useful method
"""
def vectorize_data(data, to_ix):
return [[to_ix[tok] if tok in to_ix else to_ix['UNK'] for tok in seq] for seq, y in data] # Figure 1
def pad_sequences(vectorized_seqs, seq_lengths):
seq_tensor = torch.zeros((len(vectorized_seqs), seq_lengths.max())).long()
for idx, (seq, seqlen) in enumerate(zip(vectorized_seqs, seq_lengths)):
seq_tensor[idx, :seqlen] = torch.LongTensor(seq)
return seq_tensor
def create_dataset(data, x_to_ix, y_to_ix, bs=4):
vectorized_seqs = vectorize_data(data, x_to_ix)
seq_lengths = torch.LongTensor([len(s) for s in vectorized_seqs])
seq_tensor = pad_sequences(vectorized_seqs, seq_lengths) # Figure 2
target_tensor = torch.LongTensor([y_to_ix[y] for _, y in data])
raw_data = [x for x, _ in data]
return DataLoader(PaddedTensorDataset(seq_tensor, target_tensor, seq_lengths, raw_data), batch_size=bs)
def sort_batch(batch, ys, lengths):
seq_lengths, perm_idx = lengths.sort(0, descending=True)
seq_tensor = batch[perm_idx]
targ_tensor = ys[perm_idx]
return seq_tensor.transpose(0, 1), targ_tensor, seq_lengths
def train_dev_test_split(data):
train_ratio = int(len(data) * 0.8) # 80% of dataset
train = data[:train_ratio]
test = data[train_ratio:]
valid_ratio = int(len(train) * 0.8) # 20% of train set
dev = train[valid_ratio:]
return train, dev, test
def build_vocab_tag_sets(data):
vocab = set()
tags = set()
for name in data:
chars = set(name[0])
vocab = vocab.union(chars)
tags.add(name[1])
return vocab, tags
def make_to_ix(data, to_ix=None):
if to_ix is None:
to_ix = dict()
for c in data:
to_ix[c] = len(to_ix)
return to_ix
def apply(model, criterion, batch, targets, lengths):
pred = model(torch.autograd.Variable(batch), lengths.cpu().numpy())
loss = criterion(pred, torch.autograd.Variable(targets))
return pred, loss
"""
Training and evaluation methods
"""
def train_model(model, optimizer, train, dev, x_to_ix, y_to_ix):
criterion = nn.NLLLoss(size_average=False)
for epoch in range(20):
print("Epoch {}".format(epoch))
y_true = list()
y_pred = list()
total_loss = 0
for batch, targets, lengths, raw_data in create_dataset(train, x_to_ix, y_to_ix, bs=TRAIN_BATCH_SIZE):
batch, targets, lengths = sort_batch(batch, targets, lengths)
model.zero_grad()
pred, loss = apply(model, criterion, batch, targets, lengths)
loss.backward()
optimizer.step()
pred_idx = torch.max(pred, 1)[1]
y_true += list(targets.int())
y_pred += list(pred_idx.data.int())
total_loss += loss
acc = accuracy_score(y_true, y_pred)
val_loss, val_acc = evaluate_validation_set(model, dev, x_to_ix, y_to_ix, criterion)
print("Train loss: {} - acc: {} \nValidation loss: {} - acc: {}".format(list(total_loss.data.float())[0]/len(train), acc,
val_loss, val_acc))
return model
def evaluate_validation_set(model, devset, x_to_ix, y_to_ix, criterion):
y_true = list()
y_pred = list()
total_loss = 0
for batch, targets, lengths, raw_data in create_dataset(devset, x_to_ix, y_to_ix, bs=VALIDATION_BATCH_SIZE):
batch, targets, lengths = sort_batch(batch, targets, lengths)
pred, loss = apply(model, criterion, batch, targets, lengths)
pred_idx = torch.max(pred, 1)[1]
y_true += list(targets.int())
y_pred += list(pred_idx.data.int())
total_loss += loss
acc = accuracy_score(y_true, y_pred)
return list(total_loss.data.float())[0]/len(devset), acc
def evaluate_test_set(model, test, x_to_ix, y_to_ix):
y_true = list()
y_pred = list()
for batch, targets, lengths, raw_data in create_dataset(test, x_to_ix, y_to_ix, bs=TEST_BATCH_SIZE):
batch, targets, lengths = sort_batch(batch, targets, lengths)
pred = model(torch.autograd.Variable(batch), lengths.cpu().numpy())
pred_idx = torch.max(pred, 1)[1]
y_true += list(targets.int())
y_pred += list(pred_idx.data.int())
print(len(y_true), len(y_pred))
print(classification_report(y_true, y_pred))
print(confusion_matrix(y_true, y_pred))
"""
Our Recurrent Model
"""
class NamesRNN(nn.Module):
def __init__(self, vocab_size, embedding_dim, hidden_dim, output_size):
super(NamesRNN, self).__init__()
self.embedding_dim = embedding_dim
self.hidden_dim = hidden_dim
self.vocab_size = vocab_size
self.char_embeds = nn.Embedding(vocab_size, embedding_dim)
self.lstm = nn.LSTM(embedding_dim, hidden_dim, num_layers=1)
self.fully_connected_layer = nn.Linear(hidden_dim, output_size)
self.softmax = nn.LogSoftmax()
def init_hidden(self, batch):
return (autograd.Variable(torch.randn(2, batch, self.hidden_dim)),
autograd.Variable(torch.randn(2, batch, self.hidden_dim)))
def _get_lstm_features(self, names, lengths):
self.hidden = self.init_hidden(names.size(-1))
embeds = self.char_embeds(names) # Figure 4
packed_input = pack_padded_sequence(embeds, lengths) # Figure 5
packed_output, (ht, ct) = self.lstm(packed_input, self.hidden) # Figure 6
lstm_out, _ = pad_packed_sequence(packed_output) # Figure 7
lstm_out = torch.transpose(lstm_out, 0, 1)
lstm_out = torch.transpose(lstm_out, 1, 2)
lstm_out = F.tanh(lstm_out) # Figure 8
lstm_out, indices = F.max_pool1d(lstm_out, lstm_out.size(2), return_indices=True) # Figure 9
lstm_out = lstm_out.squeeze(2)
lstm_out = F.tanh(lstm_out)
lstm_feats = self.fully_connected_layer(lstm_out)
output = self.softmax(lstm_feats) # Figure 10
return output
def forward(self, name, lengths):
return self._get_lstm_features(name, lengths)
"""
Method for debugging purpose
"""
def filter_for_visual_example(train):
new_t = list()
for x in train:
if len(x[0]) == 6:
new_t.append(x)
break
for x in train:
if len(x[0]) == 5:
new_t.append(x)
break
for x in train:
if len(x[0]) == 4:
new_t.append(x)
break
for x in train:
if len(x[0]) == 3:
new_t.append(x)
break
return new_t
"""
The actual train and evaluation
"""
train, dev, test = train_dev_test_split(data)
# train = filter_for_visual_example(train)
# print(train)
vocab, tags = build_vocab_tag_sets(train)
chars_to_idx = {
'PAD': 0,
'UNK': 1
}
chars_to_idx = make_to_ix(sorted(list(vocab)), chars_to_idx) # Really important to sort it if you save your model for later!
tags_to_idx = make_to_ix(sorted(list(tags)))
model = NamesRNN(len(chars_to_idx), 128, 32, len(tags))
optimizer = optim.SGD(model.parameters(), lr=0.01, weight_decay=1e-4)
model = train_model(model, optimizer, train, dev, chars_to_idx, tags_to_idx)
evaluate_test_set(model, test, chars_to_idx, tags_to_idx)
I try to make the figures as close as possible as the representation of pytorch while using the PyCharm Debugger. I think it will offer a better understanding of what is actually going on with all the tensors
Figure 1: One Hot String¶

Figure 2: Padded String¶

Figure 3: Batched Input¶

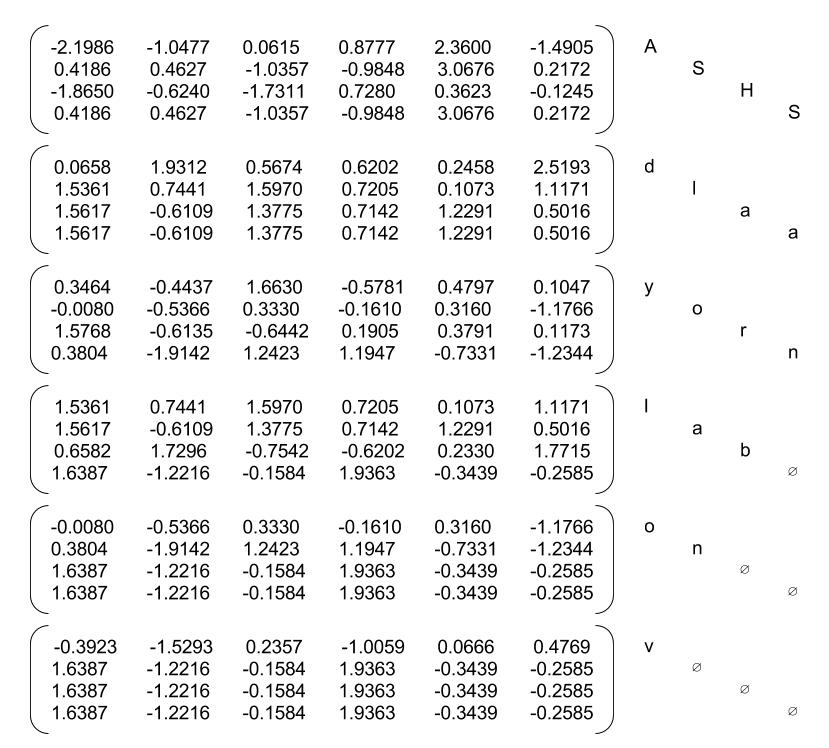
Figure 5: Packed Embeddings¶

This piece here is the most interesting. Note that the data structure used is a PackedSequence. A packed sequence contains "batches" which tells how many rows to take for each timestep.
In this case, the batch_sizes are [4, 4, 4, 3, 2, 1]. This means that all four first letters of each word will be fed into the LSTM at timestep 1. Then another 4 until the name "San" has exhausted. We then go on with 3 embeddings rows, 2 and then 1 which is equivalent to the letter "v" in the name "Adylov".
Figure 6: Packed LSTM Output¶

The LSTM will output a PackedSequence since that's what we fed it with. We can see that there are 4 columns since our LSTM has 4 hidden units.

Figure 8: Reshaped Output¶

We now reshaped our output so we can have each hidden units for each names.
Figure 9: Max Pooling¶

We then apply max pooling on each hidden representation for a name. We then end up with a column vector representation for each name.
Figure 10: Predictions¶

We then feed this output as an input to a Linear layer follow by a softmax which give log probabilities over the set of possible classes. Note here that the network has not been train so the predictions are all wrong.