나이브 베이즈Naive Bayse - 베르누이Bernoulli와 다항분포Multinomial 나이브 베이즈 비교¶
2017.05.19 조준우 metamath@gmail.com
수정: 2019.07.14
이 문서는 밑바닥부터 시작하는 데이터 과학[1]의 나이브 베이즈 단원에 대한 보충 설명이다. 책의 설명이 좀 부족하다 생각되어 보충 문서를 작성하게 되었다. 책에서 일반적인 나이브 베이즈 가정을 간결한 문장과 내용으로 잘 설명하고 있으나 베르누이 나이브 베이즈Bernoulli Naive Bayes에 대한 설명은 전혀 없는데 예제 코드는 이것을 구현하고 있다는데 있다. 다항분포 나이브 베이즈 모델과 베르누이 나이브 베이즈 모델을 잘 이해하기 위해서는 책에서 설명하는 나이브 베이즈 가정만으로는 부족하고 확률변수와 확률분포에 대한 이해가 조금 더 필요한데 여기에서 기본적으로 관련 내용을 간략하게 정리한 후 코드와 함께 살펴 보도록 한다. 책에서도 스팸메일 분류기를 예로 들어 설명하므로 여기서도 기본적으로 스펨 메일 분류를 예로 설명하도록 한다.
1. 문제 정의¶
어떤 문서(또는 메세지) $\mathcal{D}$가 있을 때 이 문서가 스팸($S$)클래스에 속하는지 일반 문서($ \neg S$)클래스에 속하는지 분류하는 문제가 있다고 하자. 그리고 우리에게 꽤 많은 단어들에 대해서 그 단어가 스팸메일에 나타날 확률과 일반메일에 나타날 확률에 대한 데이터를 가지고 있다고 하자. 예를 들면 "Sale은 일반메일에서 3%확률로 나타나고, 스팸메일에서 60%확률로 나타난다" 이런 데이터를 수만개 단어에 대해서 가지고 있다는 것이다. 기호로 적으면 $P(\text{'Naive'}|S)$와 $P(\text{'Naive'}|\neg S)$를 데이터로 가지고 있는 것이다. 우리가 풀고 싶은 문제는 $P(S\,|\,\mathcal{D})$ 와 $P(\neg S\,|\,\mathcal{D})$중 어느쪽이 더 큰가 하는 문제이다. $P(S\,|\,\mathcal{D})$ 는 문서 $\mathcal{D}$가 주어졌다는 가정하에서 그 문서가 스팸일 확률 즉 조건부 확률을 나타낸다. $P(\neg S\,|\,\mathcal{D})$는 문서 $\mathcal{D}$가 주어졌다는 가정하에서 그 문서가 스팸이 아닐 확률을 나타낸다. 해당 문제를 해결하기 위해 주어진 도큐먼트로 부터 판단에 사용할 특징feature를 추출해야 하는데 이때 어떤 확률분포를 사용하는지에 따라 특징벡터가 달라지게 된다. 일단 그 내용은 잠시뒤로 미루고 지금은 $\mathcal{D}$로 부터 단어를 추출하여 특징 벡터 $\mathbf{x}=(x_{1}, x_{2}, ... , x_{n})$가 준비되었다하고 이야기를 계속 하자. 그럼 특징벡터 $\mathbf{x}$가 관찰되었을 때 그 벡터가 $S$에 속할 확률은 베이즈정리를 사용해서 아래와 같이 쓸 수 있다.
$$ P(S\,|\,x_{1}, x_{2}, ... , x_{n}) = \frac{P(x_{1}, x_{2}, ... , x_{n}\,|\,S)\,P(S)}{P(x_{1}, x_{2}, ... , x_{n})}$$이때 특징벡터의 각 요소가 조건부 독립이라는 가정을 하면, 다시 말해 문서 $d$가 스팸이라는 가정하에 'love'이라는 단어가 나올 확률은 'partner'라는 단어가 나올 확률과 아무 상관이 없다고 가정하면 (실제로는 상관이 있을것이다. 그래서 이런 가정을 책[1]에서 '말도 안되는 가정'이라고 이야기한다.) 다음과 같이 다시 쓸 수 있다.
$$ P(S\,|\,x_{1}, x_{2}, ... , x_{n}) = \frac{P(x_{1}\,|\,S)\,P(x_{2}\,|\,S) \cdots P(x_{n}\,|\,S)\,P(S)}{P(x_{1})\,P(x_{2}) \cdots P(x_{n})}$$조건부 독립가정때문에 이제 $P(S\,|\, \mathbf{x})$와 $P( \neg S\,|\, \mathbf{x})$ 를 구하기 위해서는 $P(x_{1}\,|\,S)$, $P(x_{2}\,|\,S)$같은 것들을 알면되게 되었다. 그런데 이미 우리는 이런 데이터를 엄청 많이 가지고 있다고 했다. 분모는 확률들의 곱이라 양수 인데 우리는 $P(S\,|\, \mathbf{x})$와 $P( \neg S\,|\, \mathbf{x})$의 크기 비교를 할것이므로 계산하지 않아도 무방하다. 즉 다음과 같다.
$$ P(S\,|\,x_{1}, x_{2}, ... , x_{n}) \propto P(x_{1}\,|\,S)\,P(x_{2}\,|\,S) \cdots P(x_{n}\,|\,S)\,P(S)$$따라서 문서로부터 적절히 특징벡터를 추출하는 방법, 기존 데이터로 부터 $P(S\,|\, \mathbf{x})$와 $P( \neg S\,|\, \mathbf{x})$를 계산하는 방법, 전체 문서에서 스팸과 스팸이 아닌 문서가 차지하는 비율인 사전확률 $P(S)$, $P(\neg S)$을 구하는 방법을 알면 문제를 해결 할 수 있게 된다.
2. 실습¶
import os, math, random, re, glob
from collections import Counter, defaultdict
2.1.보조 함수 정의¶
우선 실습에 필요한 보조함수를 정의한다. tokenize 함수는 하나의 도큐먼트(메세지)를 단어별로 쪼갠 다음 중복을 제거하여 되돌리고, tokenize2는 단어별로 쪼갠 다음 중복 단어가 있다면 그대로 허용한채 되돌린다. split_data는 주어진 기존 데이터(학습데이터)를 학습용과 테스트용으로 분리하여 되돌린다. (여기 사용된 코드들은 "밑바닥부터 시작하는 데이터 과학"의 코드를 대부분 이용하고 다항분포 나이브 베이즈 모델과 베르누이 나이브 베이즈 모델 구분하여 구현하기 위해 약간의 코드를 수정 추가했다.)
def split_data(data, prob):
"""
split data into fractions [prob, 1 - prob]
"""
results = [], []
for row in data:
results[0 if random.random() < prob else 1].append(row)
return results
def tokenize(message):
"""
주어진 메세지를 단어 단위로 자른 집합을 되돌림(단어의 중복제거)
"""
message = message.lower() # convert to lowercase
all_words = re.findall("[a-z0-9']+", message) # extract the words
return set(all_words) # remove duplicates
def tokenize2(message):
"""
주어진 메세지를 단어 단위로 자른 집합을 되돌림(중복 단어 허용)
"""
message = message.lower() # convert to lowercase
all_words = re.findall("[a-z0-9']+", message) # extract the words
return all_words # duplicates
2.2. 데이터 로딩¶
"밑바닥부터 시작하는 데이터 과학"의 예제 소스 저장소에서 학습에 사용할 데이터 폴더 3개를 내려 받는다. 우선 3개 폴더에 있는 메일 데이터로 부터 제목을 추출하면 제목이 약 3423개가 추출이 된다. 이 3000여개의 도큐먼트에 대해 어떤 것이 스팸메일 제목인지 아닌지를 이미 다 알고 있다. 학습과 그 결과를 확인하기위해 이 3000여개의 데이터를 약 2500여개의 학습데이터와 800여개의 테스트 데이터로 나눈다.
#############################################################
# 데이터 만들기
# data = [ (메일의 제목, 스팸인가?아닌가? True or False), (), (), ... ]
#############################################################
data = []
#학습데이터는 스팸메일과 일반메일의 제목으로 한다.
subject_regex = re.compile(r"^Subject:\s+")
# 데이터가 들어있는 폴더 3개를 돌면서...
for fn in ['easy_ham' , 'hard_ham', 'spam']:
is_spam = "ham" not in fn
#디렉토리 내의 파일 리스트...
for fn2 in glob.iglob(fn+"/*") :
with open(fn2,'r',encoding='ISO-8859-1') as file:
for line in file:
if line.startswith("Subject:"):
subject = subject_regex.sub("", line).strip()
data.append((subject, is_spam))
print("전체 데이터 개수 : {} ".format(len(data)))
print("\n")
#############################################################
# data를 train_data, test_data로 나눔
#############################################################
random.seed(0)
train_data, test_data = split_data(data, 0.75)
print("학습 데이터 개수 : {} ".format(len(train_data)))
#############################################################
# 학습데이터 중에 스팸메일 개수와 일반메일 개수를 카운팅
#############################################################
num_spams = len([is_spam
for message, is_spam in train_data
if is_spam])
num_non_spams = len(train_data) - num_spams
print("학습데이터 중 스팸 메일 개수 : {} ".format(num_spams))
print("학습데이터 중 일반 메일 개수 : {} ".format(num_non_spams))
print("\n")
print("테스트 데이터 개수 : {} ".format(len(test_data)))
t_num_spams = len([is_spam
for message, is_spam in test_data
if is_spam])
t_num_non_spams = len(test_data) - t_num_spams
print("테스트데이터 중 스팸 메일 개수 : {} ".format(t_num_spams))
print("테스트데이터 중 일반 메일 개수 : {} ".format(t_num_non_spams))
전체 데이터 개수 : 3423 학습 데이터 개수 : 2547 학습데이터 중 스팸 메일 개수 : 364 학습데이터 중 일반 메일 개수 : 2183 테스트 데이터 개수 : 876 테스트데이터 중 스팸 메일 개수 : 139 테스트데이터 중 일반 메일 개수 : 737
2.3. 학습¶
2.3.1 사전확률 $P(S)$, $P(\neg S)$ 구하기¶
앞서 적절히 특징벡터를 추출하는 방법, 기존 데이터로 부터 $P(S\,|\, \mathbf{x})$와 $P( \neg S\,|\, \mathbf{x})$를 계산하는 방법, 사전확률 $P(S)$, $P(\neg S)$을 구하는 방법을 알면 분류기를 만들 수 있다고 했다. 사전확률 $P(S)$, $P(\neg S)$을 구하는 방법은 간단한다. 전체 도큐먼트 3000여개에 대해 이미 스팸, 햄(스펨이 아닌 경우를 가르킴)을 알고 았으므로 사전확률은 아래처럼 구할 수 았다.
$$ P(S) = \frac{\text{#spam}}{\text{#Document}} $$$$ P(\neg S) = \frac{\text{#ham}}{\text{#Document}} $$2.3.2 가능도Likelihood 구하기¶
나이브베이즈 분류기의 학습은 주어진 데이터를 바탕으로 가능도 $P(w_{i}\,|\,S)$, $P(w_{i}\,|\, \neg S)$를 계산하는 과정이다. 가능도는 학습데이터에 존재하는 모든 데이터에 대해서 구하게 된다. 문서의 앞에서 엄청 많은 단어에 대해 스펨클래스에서 그 단어가 나타날 확률을 이미 가지고 있다고 했는데 그 데이터를 만드는 작업을 하는 것이다. 일단 학습데이터에 존재하는 단어들을 사전에 담고 각 단어에 대해 스팸에서 출현한 횟수, 일반메일에서 출현한 횟수를 저장한다. 이때 베르누이 분포 모델을 쓸 경우 출현한 횟수가 많다 하더라도 1만 카운팅하고 다항분포 모델에서는 출현 수 만큼 그대로 카운팅한다. 이 자료를 단어장 $V$라 한다. 아래 코드가 있다.
for message, is_spam in train_data:
"""
베르누이 분포 모델의 경우 워드카운팅
한 문서(message)에서 단어를 추출하고 중복을 제거한 후 그 유일 단어들에 대해서
한번씩만 +1 을 함 결국 word가 해당 문서에 나왔다, 안나왔다만 표시
"""
for word in tokenize(message): #중복을 제거한 단어들
brn_counts[word][0 if is_spam else 1] += 1
"""
다항 분포 모델의 경우 워드카운팅
이번에는 중복을 제거하지 않고 카운팅을 함 그래서 한 문서에 word가 10번나오면
10번 +1이 되서 결과적으로 해당 문서에 word가 몇번 나왔는지 저장하게 됨
"""
for word in tokenize2(message): #중복을 제거하지 않은 단어들
mtnm_counts[word][0 if is_spam else 1] += 1
brn_counts는 특정 단어가 스팸 클래스에 나타난 문서수와 햄 클래스에 나타난 문서수를 저장하게 되고 mtnm_counts는 특정 단어가 스팸 클래스에 나타난 횟수, 햄 클래스에 나타난 횟수를 저장하게 된다. 구체적으로 아래처럼 저장된다.
brn_counts['naive'][0] # 스팸 클래스에서 naive란 단어가 출현하는 문서 수를 저장
brn_counts['naive'][1] # 햄 클래스에서 naive란 단어가 출현하는 문서 수를 저장
mtnm_counts['naive'][0] # 스팸 클래스에 있는 문서에서 naive 단어가 출현한 총 횟수
mtnm_counts['naive'][1] # 햄 클래스에 있는 문서에서 naive 단어가 출현한 총 횟수
# 이런 식으로 단어장의 모든 단어에 대해서 계산한다.
2.3.2.1 베르누이 나이브 베이즈¶
이제 문서를 특징벡터로 나타내는 방식을 알아볼 차례이다. $V$는 나이브베이즈 모델에서 사용하는 단어 $|V|$개가 들어 있는 단어장이라고 하자. 즉 $V$는 다음과 같은 배열이다.
$$ V = (w_1, w_2, \dots , w_{|V|}) $$여기서 $w_i$는 단어를 나타낸다. 이제 어떤 샘플 문서를 $\mathcal{D}$라고 하자. 이 문서를 벡터화 해서 표시한 것을 특징 벡터라고 하는데 길이가 $|V|$인 벡터를 만들어 각 자리를 확률변수 $X_i$로 쓰기로 한다.
$$ \mathcal{D} = (X_1, X_2, \dots, X_{|V|})^{\text{T}} $$$X_i$는 베르누이 확률변수로 0 또는 1을 가진다. 따라서 특징벡터화 된 문서 $\mathcal{D}$의 각 성분은 다음과 같은 의미를 가진다.
$$ \mathcal{D} = (D\text{에 } w_1 \text{이 있으면 1 없으면0}, D\text{에 }w_2 \text{가 있으면 1 없으면0}, \dots, D\text{에 }w_{|V|} \text{가 있으면 1 없으면0})^{\text{T}} $$예를들어 $\mathcal{D} = (1, 0, 0, 1, 1, 0, 0, 1, 0, 0)^{\text{T}}$라면 단어장 $V$이 단어중 1번, 4번, 5번, 8번 단어가 이 문서에 출현한 것이다. 이처럼 단어의 출현 여부를 따져서 문서를 벡터로 변환한다. 당연하게도 모든 문서는 길이 $|V|$짜리 벡터로 변환되게 된다. 정리하면 문서를 길이 $|V|$짜리 벡터로 만드는데 각 자리를 베르누이 확률변수로 만드는 것이다. 이런 모델을 베르누이 나이브 베이즈라 한다.
이 특징벡터의 각 자리는 베르누이 확률변수이므로 각 변수에 대한 확률질량함수를 정의해야 한다. 베르누이 확률변수에 대한 확률질량함수는 다음처럼 정의된다.
$$ P(X=x) = p^x (1-p)^{1-x} $$위 정의를 사용해서 문서의 클래스가 $C_k$로 가정했을 때 우리가 정의한 확률변수 $X_i$의 확률 질량함수를 써보면 다음처럼 될 것이다. 즉 각 확률변수 $X_i$의 분포에 대한 파라미터 $p_i$를 결정해야 한다.
$$ P(X_{i}=x_i \,|\, C_k) =p_i^{x_i}(1-p_i)^{1-x_i} $$식에서 $P(X_{i}=x_i \,|\, C_k)$의 의미는 문서의 클래스가 $C_k$라 했을 때 단어 $w_i$가 출현할 확률($x_i=1$인 경우) 또는 출현하지 않을 확률($x_i=0$인 경우)이 된다. 따라서 파리미터 $p_i$를 $P(w_{i}\,|\,C_{k})$로 고쳐쓰면
$$ P(X_{i}=x_i \,|\, C_k) = P(w_{i}\,|\,C_{k})^{x_i}(1-P(w_{i}\,|\,C_{k}))^{1-x_i} $$그러면 문서 전체의 가능도는 나이브 베이즈 가정에 따라 다음처럼 된다.
$$ P(\mathcal{D} \,|\, C_k) = \prod_{i=1}^{|V|} P(w_{i}\,|\,C_{k})^{x_i}(1-P(w_{i}\,|\,C_{k}))^{1-x_i} $$이제 $P(w_{i}\,|\,C_{k})$를 어떻게 구할 것인가 생각해봐야 한다. (우리 문제에서는 $k=2$인 경우로 $C_{1}=S$, $C_{2}= \neg S $ 로 생각하면 됨) 특정 단어 $w_{i}$가 문서에 나타날 확률은 자연계에 분명 존재할 것이다. 우리가 그것을 정확히 모를 뿐이다. (이 세상에 존재하는 문서란 문서는 모두 가지고 와서 단어 $w_i$가 나타난 문서의 수를 세면 된다.) $w_{i}$가 제약이 없이 그냥 문서에 나타날 확률(엄밀히 말하면 문서라는것도 일종의 제약이다)과 특정 제약이 있는 경우, 예를 들어 스팸문서에 나타날 확률은 엄연히 다를 것이다. 우리는 메일중에서 스팸메일에 나타날 확률, 햄메일에 나타날 확률을 알면 되므로 $P(w_{i}\,|\,S)$, $P(w_{i}\,|\,\neg S)$를 알고 싶은 것이다. 자연상태에 존재하는 이 확률분포를 정확히 알 방법은 없다. (세상에 존재하는 모든 이메일을 다 모아서 스팸과 햄으로 분류하고 그 중 $w_i$가 나타나는 문서수를 세면 된다.) 따라서 우리가 가지고 있는 데이터를 바탕으로 근사된 $\hat{P}(w_{i}\,|\,S)$, $\hat{P}(w_{i}\,|\,\neg S)$ 구하여야 한다.
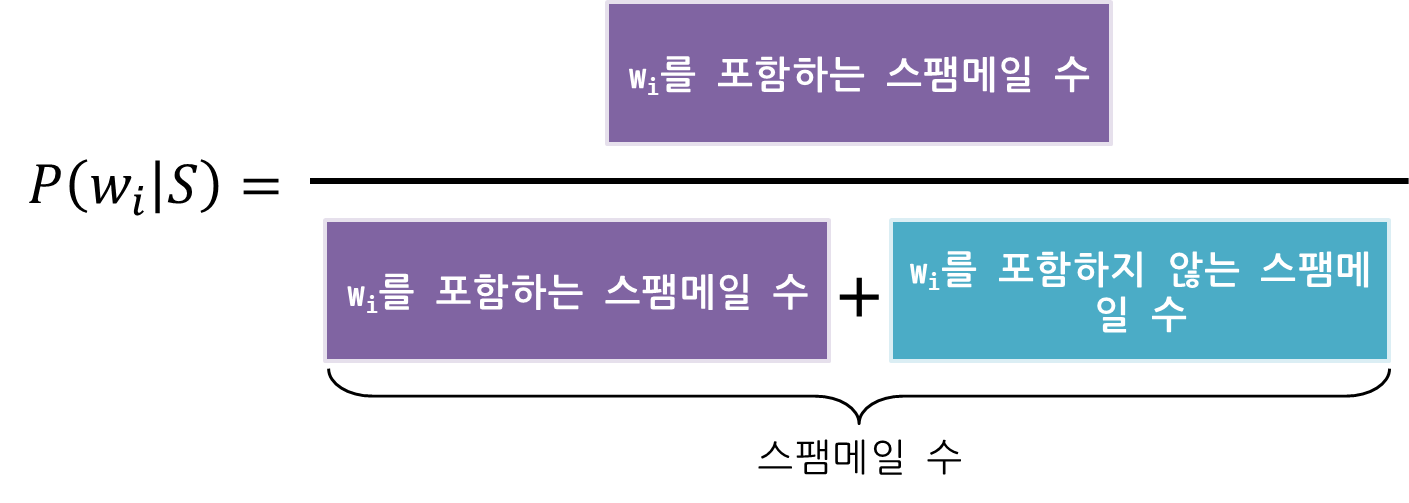
베르누이 모델에서 단어장 $V$ 중 특정 단어 $w_i$가 특정 문서 클래스 $C_k$에 나타날 확률 $P(w_i \,|\, C_k)$는

로 계산한다.
예를 들어 총 10개의 문서가 있는 C라는 클래스에서 naive라는 단어가 1번 문서에 3번, 2번 문서에 5번 나오고 3번~10번 문서에는 나오지 않은 상황이라면 베르누이 모델의 경우 $\hat{P}(\text{'naive'}|C) = \frac{2}{10}$이 된다.
2.3.2.2 다항분포 나이브 베이즈¶
이번에는 다항분포 나이브 베이즈를 알아보자. 먼저 베르누이 확률분포를 일반화한 멀티누이multinoulli 확률분포에 대해 간략히 알아보기로 하자. 이 분포는 카테고리categorical 확률분포라고도 한다.
베르누이 확률변수는 0 또는 1을 가지는 이진 변수였다. 즉 선택 가능한 항목이 2개인 셈이다. 이를 일반화 하여 선택가능한 항목이 여러개가 되면 어떻게 될까? 예를 들어 항목이 6개라면 확률변수는 1~6까지 값을 가지게 될 것이다. 이 때 확률변수가 가지는 값을 정수로 쓰지 않고 많은 경우 원 핫 인코딩 벡터로 표시하게 된다. $X=4$이면 다음처럼 표시하는 것이다.
$$X = (0,0,0,1,0,0)^{\text{T}}$$베르누이 확률변수의 예로 동전던지기를 들 수 있듯이 멀티누이 확률변수의 예는 주사위 던지기를 들 수 있겠다. 주사위를 던져서 나오는 눈 수를 값으로 가지는 확률변수 $X$는 멀티누이 확률변수인 것이다. 멀티누이 확률 변수는 어느 한 자리만 1이고 나머지는 0인 벡터로 표시할 수 있다. 그래서 각 자리가 1이 될 확률 $p_i$를 정해서 다음처럼 멀티누이 확률변수의 확률질량함수를 나타낼 수 있다.
$$ P(X = x) = \prod_{i=1}^K p_i^{x_i} $$여기서 $K$는 멀티누이 확률변수 벡터의 길이, 즉 항목 수이다. 이 때 $p_i$는 각 자리수가 1이 될 확률이므로 $\sum_{i=1}^K p_i = 1$이 되어야 한다. 주사위 각 눈이 나올 확률을 모두 더하면 1이 되는 것과 같은 이야기다.
이제 주사위를 10번 던진다고 해보자. 그래서 1이 3번, 2가 2번, 3이 1번, 4가 2번, 5가 2번, 6이 0번 나왔다고 해보자. 이를 벡터로 나타내면 $(3, 2, 1, 2, 2, 0)^{\text{T}}$가 될 것이다. 다시 한번 10번을 던지면 결과는 $(2, 2, 1, 2, 1, 2)^{\text{T}}$일 수도 있다. 이런 벡터변수를 확률변수로 봤을 때 이 변수들이 따르는 분포가 있는데 이를 다항분포라 한다. 멀티누이 확률변수의 각 시행은 서로 독립이므로 다음처럼 다항분포의 확률질량함수는 멀티누이 확률질량함수를 곱하고 여기에 정규화 상수를 추가로 곱하는 형태가 된다.
$$ \text{Mult}(x_1, x_2, \dots, x_K) = \frac{N!}{x_1! x_2! \cdots x_K!} \prod_{i=1}^K p_i^{x_i} $$이 경우는 $\sum_{i=1}^K x_i = N$이라는 제약조건을 가지게 된다. 이 정도로 다항분포를 따르는 확률변수의 정의를 이야기하고 다시 원래 문제로 돌아가보자.
베르누이 나이브 베이즈에서 문서 $\mathcal{D}$는 각 자리가 베르누이 확률변수인 길이 $|V|$인 특징벡터로 변환되었다. 이제 약간 시각을 다르게 하여 문서 $\mathcal{D}$를 다항분포를 따르는 확률변수로 변환시켜보자. 벡터의 길이는 $|V|$로 동일하지만 각 요소 자리에 단어의 출현 여부를 0, 1로 기록하는 것이 아니라 출현 횟수를 기록하는 것이다.
예를 들어 전체 단어 수가 10개인 경우 어떤 문서 $\mathcal{D}$는 각 모델에 대해서 다음처럼 변환 될 수 있다.
베르누이 나이브 베이즈: $\mathcal{D}=(1, 0, 0, 1, 1, 0, 0, 1, 0, 0)^{\text{T}}$
다항분포 나이브 베이즈: $\mathcal{D}=(2, 0, 0, 4, 1, 0, 0, 3, 0, 0)^{\text{T}}$
두 모델의 차이는 문서 $\mathcal{D}$에 '1번, 4번, 5번, 8번 단어가 나왔다'로 해석하느냐 '1번 단어가 2번, 4번 단어가 4번, 5번 단어가 1번, 8번 단어가 3번 나왔다'로 해석하느냐의 차이이다.
베르누이 나이브 베이즈처럼 다항분포 나이브 베이즈의 경우도 각 자리에 부여될 파라미터 $P(w_{i}\,|\,C_{k})$를 모두 구해야 하는데 구체적인 계산법은 잠시 뒤로 미루고 일단 구해졌다고 가정하자. 그러면 문서 전체의 가능도는 다음과 같이 된다.
$$ P(\mathcal{D} \,|\, C_k) = \frac{N!}{ \prod_{i=1}^{|V|} x_i !} \prod_{i=1}^{|V|} P(w_{i}\,|\,C_{k})^{x_i} $$여기서 $N$은 $V$에 있는 모든 단어가 $D$에 나타난 총 횟수인데 각 샘플마다 모두 다르게 된다.
지금까지 상황을 좀 쉬운 예로 다시한번 정리하고 이로부터 다항분포의 파라미터를 유도해보자. 우리가 주사위를 여러번 던져서 각 자리수가 나오는 횟수를 기록하면 이것이 다항분포를 따른다고 했었다. 이렇게 한 실험을 다음과 같은 행렬로 정리했다고 가정하자. 단 이 주사위는 각 눈이 나올 확률이 공평하게 $\frac1 6$아닌 주사위다.
$$ \mathbf{M} = \begin{bmatrix} 2 & 1 & 3 & 3 & 2 & 0 \\ 3 & 1 & 4 & 2 & 1 & 1 \\ 4 & 2 & 5 & 2 & 2 & 2 \end{bmatrix} $$위 행렬에서 한 행은 주사위 여러번 던지는 실험의 결과를 정리한 것이다. 첫번째 실험은 총 11번 주사위를 던진 실험으로 그 결과가 1행에 표시되었다. 두번째 실험은 12번 주사위를 던졌고 그 결과를 2행에 표시했으며, 세번째 행은 17번 실험한 것을 나타낸다. 각 눈의 수는 행렬에 기록된 것처럼 나왔다 하자. 그러면 각 행은 다항분포 확률변수가 되며 이에 대한 각각의 확률값은 다음처럼 계산될 수 있다.
$$ \begin{aligned} \text{Mult}(x_1=2, x_2=1, x_3=3, x_4=3, x_5=2, x_6=0) = \frac{11!}{2! \times 1! \times 3! \times 3! \times 2! \times 0!} \prod_{i=1}^6 p_i^{x_i} \\[5pt] \text{Mult}(x_1=3, x_2=1, x_3=4, x_4=2, x_5=1, x_6=1) = \frac{12!}{3! \times 1! \times 4! \times 2! \times 1! \times 1!} \prod_{i=1}^6 p_i^{x_i} \\[5pt] \text{Mult}(x_1=4, x_2=2, x_3=5, x_4=2, x_5=2, x_6=2) = \frac{20!}{4! \times 2! \times 5! \times 2! \times 2! \times 2!} \prod_{i=1}^6 p_i^{x_i} \end{aligned} $$이제 각 눈이 나올 확률 $p_i$를 생각해보자. 상식적으로 생각해봐도 $p_1$은 전체 시도 횟수에 대해서 1이 나온 수가 차지하는 비율일 것이다. 실험을 총 40번했고 1은 9번 나왔으므로 $p_1=\frac{9}{40}$이다. 나머지 파라미터도 모두 그렇게 계산된다. 다항분포 나이브 베이즈도 이것과 정확하게 동일한 상황을 문서에 적용하고 있다.
위 $\mathbf{M}$행렬을 그대로 문서에 적용해보자. 훈련 샘플로 사용되는 특정 문서 클래스에 대한 문서는 총 3개가 있는 경우가 될 것이다. 우리 문제에서 생각해보면 스팸 메일이 총 3개 있다고 생각해도 좋다. 단어장 $V$에 있는 전체 단어는 6개가 된다. 그리고 1번 문서는 1번에서 6번까지 단어가 각각 2번, 1번, 3번, 3번, 2번, 0번 등장한 것이다.
이 상황에서 1번 단어 $w_1$이 현재 문서 클래스 $C_k$에 나타날 확률 $P(w_i \,|\, C_k)$을 주사위의 경우처럼 똑같이 생각해서 다음과 같이 구할 수 있을것이다.

만약 1번 단어가 'naive'라는 단어였으면 다항분포 모델의 경우는 $\hat{P}(\text{'naive'}|C_k) = \frac{9}{40} $이 된다.
우리는 문서의 클래스에 대한 가능도 $P(\mathbf{D} \,|\, C_k)$의 상대적 크기차만 비교할 것이므로 정규화 상수는 중요치 않고 다음 관계를 이용하게 된다.
$$ P(\mathcal{D} \,|\, C_k) \propto \prod_{i=1}^{|V|} P(w_{i}\,|\,C_{k})^{x_i} $$이것으로 두가지 나이브 베이즈 모델에서 문서의 가능도를 구하기 위한 각 단어의 가능도를 구하는 방법을 상세히 알아보았다.
2.3.3 스무딩 적용¶
훈련 세트에 있는 3888개의 단어에 대해 베르누이 모델을 위해 특정 단어가 나타나는 스팸메일의 수, 특정 단어가 나타나는 일반메일의 수, 다항분포 모델을 위해 그 단어가 스팸메일에 나타나는 출현 수와 일반메일에 나타나는 출현 수를 계산한다. 이 후 그 정보를 이용하여 방금 설명한것 처럼 $P(w_{i}\,|\,S)$, $P(w_{i}\,|\, \neg S)$ 계산해서 저장을 하는데 이 때 라플라스 스무딩laplace smoothing을 적용해야 한다. 스무딩 적용 이유는 책[1]에 잘 나와있기 때문에 별도로 언급하지 않고 어떤 원리로 스무딩을 적용하는지 두가지 경우에 대해 나눠서 설명한다.
2.3.3.1 베르누이 나이브 베이즈¶
스무딩의 목적이 가능도가 0이 되는 것을 방지하기 위함이라 분자에 적당한 수 k를 더해서 0이되는 것을 막는 것인데 그냥 분자에만 k를 더하면 안된다. 다시 한번 아래 그림을 보고 베르누이 분포 모델에서 가능도를 구하는 방법을 생각해보자.
전체 스팸메일 수가 분모에 가고 분자에 특정 단어를 포함하는 스팸메일 수가 온다. 문제는 어떤 특정 단어가 일반메일에만 나타나고 스팸메일에는 한번도 안나타나는 경우 가능도는 0이 되고 그 단어가 포함된 스팸메일은 절대로 스팸으로 분류되지 않는다는 것이다. 이런 현상을 막기위해 분자에 임의의 수 k를 더해준다. 그리고, 당연하게도 분모는 그 단어가 나타나는 스팸메일과 일반메일의 합이므로 일반메일 그룹에도 k를 더해준다. 따라서 베르누이 분포 모델의 경우 가능도는 아래와 같이 구한다. (결국 분모에는 2k가 더해짐)

2.3.3.2 다항분포 나이브 베이즈¶
반면 다항분포 모델에서는 가능도가 아래 그림처럼 단어의 출현수로 계산이 된다. 그래서 특정 단어가 스팸메일에 0번 출현했다면 (출현하지 않았다면) 같은 문제가 생기게 된다.

이때도 역시 분자에 k를 더해 k번 출현한 것으로 가정한다. 이는 우리가 모은 스팸메일 데이터 이전에 우리가 모으지 못한 어떤 스팸메일 군에서 k번 출현했을 것이다 라고 가정하는 것이다. 그렇다면 당연히 다른 단어들에도 k번 이미 출현했다고 가정해야 하므로 분모의 모든 단어의 출현수에 k를 더해 준다. 이 경우 분모에는 (k $\times$ '단어장 단어 개수') 가 더해지게 된다.

아래 코드는 설명한 스무딩을 적용해서 가능도를 구하는 과정이다.
"""
베르누이 분포를 사용하는 모델의 경우
spam : w가 포함된 스팸문서 수
num_spam : 스팸문서 수
분자에 k, 분모에 2k 더함
결과 : [(단어1, P(단어1|S), P(단어1|ㄱS), ... (단어n, P(단어n|S), P(단어n|ㄱS)]
"""
k = 0.5 #smoothing factor
brn_word_probs =[(w,
(spam + k) / (num_spams + 2*k),
(non_spam + k) / (num_non_spams + 2*k))
for w, (spam, non_spam) in brn_counts.items()]
"""
다항 분포를 사용하는 모델의 경우
spam : w의 스팸메일 출현 수
Vfs : V에 있는 단어들이 스팸메일에 나타난 총 출현 수
Vs : |V| 즉, 단어장에 유일단어 수
분자에 k, 분모에 k*|V| 더함
결과 : [(단어1, P(단어1|S), P(단어1|ㄱS), ... (단어n, P(단어n|S), P(단어n|ㄱS)]
"""
k = 0.1
mtnm_word_probs =[(w,
(spam + k) / (Vfs + k*Vs),
(non_spam + k) / (Vfh + k*Vh))
for w, (spam, non_spam) in mtnm_counts.items()]
코드 결과에서 확인할 수 있듯이 3888개의 단어에 대해 위 작업을 수행하였다.
"""
학습 목표 : P(w|S), P(w|¬S) 를 만든다.
먼저 단어를 각 메일에서 나온 횟수를 카운트한다.
counts := dict('word1':[스팸메일에 나온 수, 일반메일에 나온 수], 'word2':[스팸메일에 나온 수, 일반메일에 나온 수], ... )
"""
#############################################################
# 사전확률 P(S), P(¬S) 를 계산
#############################################################
prior_S = num_spams / (num_spams+num_non_spams)
prior_non_S = num_non_spams / (num_spams+num_non_spams)
print("클래스 사전확률")
print("P(S) : {:f} ".format(prior_S))
print("P(¬S) : {:f} ".format(prior_non_S))
print("\n")
all_words = {'spam':[], 'ham':[]}
brn_counts = defaultdict(lambda: [0, 0])
mtnm_counts = defaultdict(lambda: [0, 0])
for message, is_spam in train_data:
for word in tokenize(message):
brn_counts[word][0 if is_spam else 1] += 1
for word in tokenize2(message):
mtnm_counts[word][0 if is_spam else 1] += 1
if is_spam :
all_words['spam'].append(word)
else:
all_words['ham'].append(word)
Vfs = len(all_words['spam'])
Vfh = len(all_words['ham'])
Vs = len(set(all_words['spam']))
Vh = len(set(all_words['ham']))
print("스팸메일에 있는 유일 단어 총수 : {}".format(Vs))
print("그 단어들의 총 출연수(중복포함) : {}".format(Vfs))
print("\n")
print("일반메일에 있는 유일 단어 총수 : {}".format(Vh))
print("그 단어들의 총 출연수(중복포함) : {}".format(Vfh))
print("\n")
#############################################################
# 가능도 P(w|S), P(w|¬S) 를 계산
#############################################################
"""
turn the word_counts into a dictionary of triplets
word_probs = {word1:(p(word1|S), p(word1|¬S)) , word2:(p(word2|S), p(word2|¬S)), ... }
"""
k = 0.1 #smoothing factor
brn_word_probs =[(w,
(spam + k) / (num_spams + 2 * k),
(non_spam + k) / (num_non_spams + 2 * k))
for w, (spam, non_spam) in brn_counts.items()]
k = 0.1
mtnm_word_probs =[(w,
(spam + k) / (Vfs + k*Vs),
(non_spam + k) / (Vfh + k*Vh))
for w, (spam, non_spam) in mtnm_counts.items()]
print("학습 단어장의 크기:{}".format(len(brn_counts)))
클래스 사전확률 P(S) : 0.142913 P(¬S) : 0.857087 스팸메일에 있는 유일 단어 총수 : 1023 그 단어들의 총 출연수(중복포함) : 2288 일반메일에 있는 유일 단어 총수 : 3289 그 단어들의 총 출연수(중복포함) : 13294 학습 단어장의 크기:3888
2.4. 분류¶
주어진 메시지에 대한 스팸 여부를 판별한다. 학습데이터에 있는 모든 단어들에 대해 $P(w_{i}\,|\,S)$, $P(w_{i}\,|\, \neg S)$를 계산해두었으므로 주어진 메세지를 단어로 분리한 후 특징 벡터로 만들고 모든 단어의 가능도 값을 곱한다.
2.4.1 베르누이 나이브 베이즈¶
2.4.1.1 특징 벡터 만들기¶
베르누이 분포 모델에서는 $V$의 단어가 주어진 $d$에 나왔는지 안나왔는지만 판단하므로 다음의 예와 같이 특징벡터를 만든다.
V = [w1, w2, w3, w4, w5, w6, w7, w8] #학습데이터로 부터 추출된 단어장
d = "w2 w5 w2 w7 w5 w5"
x = [0, 1, 0, 0, 1, 0, 1, 0]
V의 각 단어가 d에 나왔는지 판단 확률변수 $X_1=0$, $X_2=1$, $X_3=0$, $X_4=0$, $X_5=1$, $X_6=0$, $X_7=1$, $X_8=0$ 처럼 된다.
2.4.1.2 가능도 계산¶
이 후 아래 수식을 이용하여 가능도를 곱해 나간다.
$$ \begin{align} P(C_{k} \,|\, \mathbf{x}) &\propto P(\mathbf{x} \,|\, C_{k})P(C_{k}) \\[5pt] &\propto P(C_{k}) \prod_{i=1}^{|V|} p(w_{i}\,|\,C_{k})^{x_i} ( 1-p(w_{i}\,|\,C_{k}))^{1-x_{i}} \end{align} $$여기서, $\mathbf{x}$는 입력된 메세지가 변환된 특징벡터, $|V|$은 학습된 전체단어의 개수이고, $x_{i}$는 $\mathbf{x}$의 요소이며 학습된 단어장의 i번째 단어인 $w_{i}$가 입력된 메세지에 포함되면 1 없으면 0을 가지는 바이너리 변수이다. 수식에 모든 요소들은 이미 다 앞에서 계산해 둔 것들이다. 그리고 책에서는 사전확률 $P(S)$, $P(\neg S)$를 곱하지 않는데 여기서는 명시적으로 곱해주었다. 구체적인 코드는 아래와 같다.
#입력된 메세지를 단어별로 자른다. 여기선 잘린 단어의 중복 허용안함
message_words = tokenize(message)
# 클래스 사전확률을 곱해주고 P(S)*∏P(w|S) , P(¬S)*∏P(w|¬S)
log_prob_if_spam ,log_prob_if_not_spam = math.log(prior_S),math.log(prior_non_S)
for word, prob_if_spam, prob_if_not_spam in brn_word_probs:
# for each word in the message,
# add the log probability of seeing it
if word in message_words:
log_prob_if_spam += math.log(prob_if_spam)
log_prob_if_not_spam += math.log(prob_if_not_spam)
# for each word that's not in the message
# add the log probability of _not_ seeing it
else:
log_prob_if_spam += math.log(1.0 - prob_if_spam)
log_prob_if_not_spam += math.log(1.0 - prob_if_not_spam)
2.4.2 다항분포 나이브 베이즈¶
2.4.2.1 특징 벡터 만들기¶
다항분포 모델에서는 $V$의 단어가 주어진 $d$에 몇번 나왔는지 판단하므로 다음의 예와 같이 특징벡터를 만든다.
V = [w1, w2, w3, w4, w5, w6, w7, w8] #학습데이터로 부터 추출된 단어장
d = "w2 w5 w2 w7 w5 w5"
x = [0, 2, 0, 0, 3, 0, 1, 0]
V의 각 단어가 d에 몇번 나왔는지 판단 하므로 확률변수는 $X_1=0$, $X_2=2$, $X_3=0$, $X_4=0$, $X_5=3$, $X_6=0$, $X_7=1$, $X_8=0$ 처럼 된다.
2.4.2.2 가능도 계산¶
이 후 아래 수식을 이용하여 가능도를 곱해 나간다.
$$ \begin{align} P(C_{k}\,|\,\mathbf{x} ) &\propto P(\mathbf{x} \,|\, C_{k})P(C_{k}) \\[5pt] &\propto P(C_{k}) \prod_{i=1}^{|V|} P(w_{i}\,|\,C_{k})^{x_i} \end{align} $$여기서, $\mathbf{x}$는 입력된 메세지가 변환된 특징벡터, $|V|$은 학습된 전체단어의 개수이고, $x_{i}$는 $\mathbf{x}$의 요소이며 학습된 단어장의 i번째 단어인 $w_{i}$가 입력된 메세지에 나타난 출현수이다. 역시 수식에 모든 요소들은 이미 다 앞에서 계산해 둔 것들이다. 구현에 있어서 한가지 팁이 있는데 어차피 단어장 $V$의 단어중 $d$에 한번도 나타나지 않은 단어의 가능도는 $P(w_{i}\,|\,C_{k})^{0}=1$이 되므로 구현에서는 $d$에 속하는 단어의 가능도만 곱하면 된다. 구체적인 코드는 아래와 같다.
#입력된 메세지를 단어별로 자른다. 여기선 잘린 단어의 중복 허용
message_words = tokenize2(message)
# 클래스 사전확률을 곱해주고 P(S)*∏P(w|S) , P(¬S)*∏P(w|¬S)
log_prob_if_spam ,log_prob_if_not_spam = math.log(prior_S),math.log(prior_non_S)
for word, prob_if_spam, prob_if_not_spam in mtnm_word_probs:
# for each word in the message,
if word in message_words:
# ∏p(w|S) , ∏p(w|¬S) -> ∑ log(p(w|S)) , ∑ log(p(w|¬S))
log_prob_if_spam += math.log(prob_if_spam)
log_prob_if_not_spam += math.log(prob_if_not_spam)
###############################################################################
def brn_spam_probability(message):
"""
책에서 설명은 기본적인 다항분포 나이브베이즈를 설명하고 코드는
베르누이 나이브 베이즈로 작성 되어 있다.
https://nlp.stanford.edu/IR-book/html/htmledition/the-bernoulli-model-1.html
https://www.datascienceschool.net/view-notebook/c19b48e3c7b048668f2bb0a113bd25f7/
그러면서 아무런 언급이 없음.
"""
global prior_S, prior_non_S
message_words = tokenize(message)
log_prob_if_spam ,log_prob_if_not_spam = math.log(prior_S),math.log(prior_non_S)
#log_prob_if_spam = log_prob_if_not_spam = 0.0
for word, prob_if_spam, prob_if_not_spam in brn_word_probs:
# for each word in the message,
# add the log probability of seeing it
if word in message_words:
log_prob_if_spam += math.log(prob_if_spam)
log_prob_if_not_spam += math.log(prob_if_not_spam)
# for each word that's not in the message
# add the log probability of _not_ seeing it
else:
log_prob_if_spam += math.log(1.0 - prob_if_spam)
log_prob_if_not_spam += math.log(1.0 - prob_if_not_spam)
prob_if_spam = math.exp(log_prob_if_spam)
prob_if_not_spam = math.exp(log_prob_if_not_spam)
return prob_if_spam / (prob_if_spam + prob_if_not_spam)
def mtnm_spam_probability(message):
"""
주어진 메세지가 스팸인지 아닌지 학습된 likelihood 로부터 계산한다.
일반적인 multinomial 나이브베이즈로 작성.
"""
global prior_S, prior_non_S
message_words = tokenize2(message)
# 클래스 사전확률을 곱해주고 P(S)*∏P(w|S) , P(¬S)*∏P(w|¬S)
log_prob_if_spam ,log_prob_if_not_spam = math.log(prior_S),math.log(prior_non_S)
for word, prob_if_spam, prob_if_not_spam in mtnm_word_probs:
# for each word in the message,
if word in message_words:
# ∏p(w|S) , ∏p(w|¬S) -> ∑ log(p(w|S)) , ∑ log(p(w|¬S))
log_prob_if_spam += math.log(prob_if_spam)
log_prob_if_not_spam += math.log(prob_if_not_spam)
prob_if_spam = math.exp(log_prob_if_spam)
prob_if_not_spam = math.exp(log_prob_if_not_spam)
return prob_if_spam / (prob_if_spam + prob_if_not_spam)
###############################################################################
#테스트 데이터를 분류한다.
brn_classified = [(subject, is_spam, brn_spam_probability(subject))
for subject, is_spam in test_data]
mtnm_classified = [(subject, is_spam, mtnm_spam_probability(subject))
for subject, is_spam in test_data]
#분류된 결과를 성공 실패로 나눠서 카운팅한다.
counts = Counter((is_spam, spam_prob > 0.5) # (actual, predicted)
for _, is_spam, spam_prob in brn_classified)
print("베르누이 나이브 베이즈")
print("일반 메일을 일반 메일이라고 분류한 경우 : {}".format(counts[(False,False)]))
print("일반 메일을 스팸 메일이라고 분류한 경우 : {}".format(counts[(False,True)]))
print("스팸 메일을 스팸 메일이라고 분류한 경우 : {}".format(counts[(True,True)]))
print("스팸 메일을 일반 메일이라고 분류한 경우 : {}".format(counts[(True,False)]))
print("정밀도 : {:f}".format( counts[(True,True)] / (counts[(True,True)]+counts[(False,True)]) ) )
print("재현율 : {:f}".format( counts[(True,True)] / (counts[(True,True)]+counts[(True,False)]) ) )
print("\n")
counts = Counter((is_spam, spam_prob > 0.5) # (actual, predicted)
for _, is_spam, spam_prob in mtnm_classified)
print("다항분포 나이브 베이즈")
print("일반 메일을 일반 메일이라고 분류한 경우 : {}".format(counts[(False,False)]))
print("일반 메일을 스팸 메일이라고 분류한 경우 : {}".format(counts[(False,True)]))
print("스팸 메일을 스팸 메일이라고 분류한 경우 : {}".format(counts[(True,True)]))
print("스팸 메일을 일반 메일이라고 분류한 경우 : {}".format(counts[(True,False)]))
print("정밀도 : {:f}".format( counts[(True,True)] / (counts[(True,True)]+counts[(False,True)]) ) )
print("재현율 : {:f}".format( counts[(True,True)] / (counts[(True,True)]+counts[(True,False)]) ) )
베르누이 나이브 베이즈 일반 메일을 일반 메일이라고 분류한 경우 : 708 일반 메일을 스팸 메일이라고 분류한 경우 : 29 스팸 메일을 스팸 메일이라고 분류한 경우 : 108 스팸 메일을 일반 메일이라고 분류한 경우 : 31 정밀도 : 0.788321 재현율 : 0.776978 다항분포 나이브 베이즈 일반 메일을 일반 메일이라고 분류한 경우 : 698 일반 메일을 스팸 메일이라고 분류한 경우 : 39 스팸 메일을 스팸 메일이라고 분류한 경우 : 114 스팸 메일을 일반 메일이라고 분류한 경우 : 25 정밀도 : 0.745098 재현율 : 0.820144
두 경우 모두에서 코드 몇줄로는 썩 나쁘지 않은 결과를 나타내었음을 확인할 수 있다.
3. 참고문헌¶
밑바닥부터 시작하는 데이터 과학Data Science from Scratch, 한빛미디어, Orelly, 조엘 그루스
Introduction to Information Retrieval, Cambridge University Press. 2008. (Chapter 13 Text classification and Naive Bayes) https://nlp.stanford.edu/IR-book/
Lecture Note for Informatics, Univ. of Edinburgh http://www.inf.ed.ac.uk/teaching/courses/inf2b/lectureSchedule.html
%%html
<link href='https://fonts.googleapis.com/earlyaccess/notosanskr.css' rel='stylesheet' type='text/css'>
<!--https://github.com/kattergil/NotoSerifKR-Web/stargazers-->
<link href='https://cdn.rawgit.com/kattergil/NotoSerifKR-Web/5e08423b/stylesheet/NotoSerif-Web.css' rel='stylesheet' type='text/css'>
<!--https://github.com/Joungkyun/font-d2coding-->
<link href="http://cdn.jsdelivr.net/gh/joungkyun/font-d2coding/d2coding.css" rel="stylesheet" type="text/css">
<style>
h1 { font-family: 'Noto Sans KR' !important; color:#348ABD !important; }
h2 { font-family: 'Noto Sans KR' !important; color:#467821 !important; }
h3 { font-family: 'Noto Sans KR' !important; color:#A60628 !important; }
h4 { font-family: 'Noto Sans KR' !important; color:#7A68A6 !important; }
p:not(.navbar-text) { font-family: 'Noto Serif KR', 'Nanum Myeongjo'; font-size: 11pt; line-height: 200%; text-indent: 10px; }
li:not(.dropdown):not(.p-TabBar-tab):not(.p-MenuBar-item):not(.jp-DirListing-item):not(.p-CommandPalette-header):not(.p-CommandPalette-item):not(.jp-RunningSessions-item):not(.p-Menu-item)
{ font-family: 'Noto Serif KR', 'Nanum Myeongjo'; font-size: 12pt; line-height: 200%; }
table { font-family: 'Noto Sans KR' !important; font-size: 11pt !important; }
li > p { text-indent: 0px; }
li > ul { margin-top: 0px !important; }
sup { font-family: 'Noto Sans KR'; font-size: 9pt; }
code, pre { font-family: D2Coding, 'D2 coding' !important; font-size: 11pt !important; line-height: 130% !important;}
.code-body { font-family: D2Coding, 'D2 coding' !important; font-size: 11pt !important;}
.ns { font-family: 'Noto Sans KR'; font-size: 15pt;}
.summary {
font-family: 'Georgia'; font-size: 12pt; line-height: 200%;
border-left:3px solid #D55E00;
padding-left:20px;
margin-top:10px;
margin-left:15px;
}
.green { color:#467821 !important; }
.comment { font-family: 'Noto Sans KR'; font-size: 10pt; }
</style>