A Python Tour of Data Science: Introduction¶
Michaël Defferrard, PhD student, EPFL LTS2
This short primer is an introduction to the scientific Python stack for Data Science. It is designed as a tour around the major Python packages used for the main computational tasks encountered in the sexiest job of the 21st century. At the end of this tour, you'll have a broad overview of the available libraries as well as why and how they are used for each task. This notebook aims at answering the following question: which tool should I use for which task and how. Before starting, two remarks:
- There exists better / faster ways to accomplish the presented computations. The goal is to present the packages and get a sense of which problems they solve.
- It is not meant to teach you (scientific) Python. I however tried to include the main constructions and idioms of the language and packages. A good ressource to learn scientific Python is a set of lectures from J.R. Janson.
1 Data Science¶
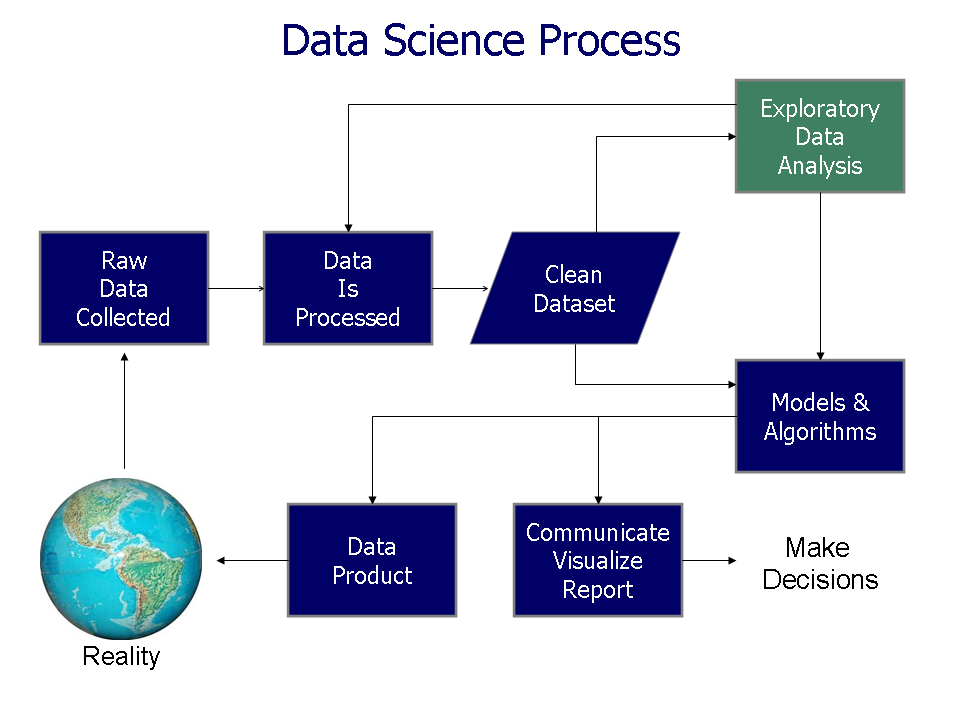
This notebook will walk you through a typical Data Science process:
- Data acquisition
- Importation
- Cleaning
- Exploration
- Data exploitation
- Pre-processing
- (Feature extraction)
- Modeling
- (Algorithm design)
- Evaluation
Our motivating example: predict whether a credit card client will default.
- It is a binary classification task: client will default or not ($y=1$ if yes; $y=0$ if no).
- We have data for 30'000 real clients from Taiwan.
- There is 23 numerical & categorical explanatory variables:
- $x_1$: amount of the given credit.
- $x_2$: gender (1 = male; 2 = female).
- $x_3$: education (1 = graduate school; 2 = university; 3 = high school; 4 = others).
- $x_4$: marital status (1 = married; 2 = single; 3 = others).
- $x_5$: age (year).
- $x_6$ to $x_{11}$: history of past payment (monthly from September to April, 2005) (-1 = pay duly; 1 = payment delay for one month; ...; 9 = payment delay for nine months and above).
- $x_{12}$ to $x_{17}$: amount of bill statement (monthly from September to April, 2005).
- $x_{18}$ to $x_{23}$: amount of previous payment (monthly from September to April, 2005).
- The data comes from the UCI ML repository.
2 Python¶
Before taking our tour, let's briefly talk about Python. First thing first, the general characteristics of the language:
- General purpose: not built for a particular usage, it works as well for scientific computing as for web and application development. It features high-level data structures and supports multiple paradigms: procedural, object-oriented and functional.
- Elegant syntax: easy-to-read and intuitive code, easy-to-learn minimalistic syntax, quick to write (low boilerplate / verbosity), maintainability scales well with size of projects.
- Expressive language: fewer lines of code, fewer bugs, easier to maintain.
Technical details:
- Dynamically typed: no need to define the type of variables, function arguments or return types. Everything is an object and can be modified at runtime.
- Automatic memory management (garbage collector): no need to explicitly allocate and deallocate memory for variables and data arrays. No memory leak bugs.
- Interpreted (JIT is coming): No need to compile the code. The Python interpreter reads and executes the python code directly. It also means that a single Python source runs anywhere a runtime is available, like on Windows, Mac, Linux and in the Cloud.
From those characteristics emerge the following advantages:
- The main advantage is ease of programming, minimizing the time required to develop, debug and maintain the code.
- The well designed language encourages many good programming practices:
- Modular and object-oriented programming, good system for packaging and re-use of code. This often results in more transparent, maintainable and bug-free code.
- Documentation tightly integrated with the code.
- A large community geared toward open-source, an extensive standard library and a large collection of add-on packages and development tools.
And the following disadvantages:
- There is two versions of Python in general use: 2 and 3. While Python 3 is around since 2008, there are still libraries which only support Python 2. While you should generally go for Python 3, a specific library or legacy code can hold you on Python 2.
- Due to its interpreted and dynamic nature, the execution of Python code can be slow compared to compiled statically typed programming languages, such as C and Fortran. That is however almost solved, see the available solutions at the end of this notebook.
- There is no compiler to catch your errors. Solutions include unit / integration tests or the use of a linter such as pyflakes, Pylint or PyChecker. Flake8 combines static analysis with style checking.
3 Why Python for Data Science¶
Let's state why is Python a language of choice for Data Scientists. Viable alternatives include matlab, R and Julia, and, for more statistical jobs, the SAS and SPSS statistical packages. The strenghs of Python are:
- Minimal development time.
- Rapid prototyping for data exploration.
- Same language and framework for R&D and production.
- A strong position in scientific computing.
- Large community of users, easy to find help and documentation.
- Extensive ecosystem of open-source scientific libraries and environments.
- Easy integration.
- Many libraries to access data from files, databases or web scraping.
- Many wrappers to legacy code, e.g. C, Fortran or Matlab.
- Available and suitable for High Performance Computing (HPC)
- Close integration with time-tested and highly optimized libraries for fast numerical mathematics like BLAS, LAPACK, ATLAS, OpenBLAS, ARPACK, MKL, etc.
- JIT and AOT compilers.
- Good support for parallel processing with processes and threads, interprocess communication (MPI) and GPU computing (OpenCL and CUDA).
4 Why Jupyter¶
Jupyter notebook is an HTML-based notebook which allows you to create and share documents that contain live code, equations, visualizations and explanatory text. It allows a clean presentation of computational results as HTML or PDF reports and is well suited for interactive tasks surch as data cleaning, transformation and exploration, numerical simulation, statistical modeling, machine learning and more. It runs everywhere (Window, Mac, Linux, Cloud) and supports multiple languages through various kernels, e.g. Python, R, Julia, Matlab.
While Jupyter is itself becoming an Integreted Development Environment (IDE), alternative scientific IDEs include Spyder and Rodeo. Non-scientific IDEs include IDLE and PyCharm. Vim and Emacs lovers (or more recently Atom and Sublime Text) will find full support of Python in their editor of choice. An interactive prompt, useful for experimentations or as a calculator, is offered by Python itself or by IPython, the Jupyter kernel for Python.
5 Installation¶
During this tour, we'll need the packages shown below, which are best installed from PyPI in a virtual environment. Please see the instructions on the README.
%%script sh
cat ../requirements.txt
numpy scipy matplotlib scikit-learn requests facebook-sdk tweepy pandas xlrd xlwt tables sqlalchemy statsmodels sympy autograd bokeh numba Cython keras theano #tensorflow jupyter ipython grip
# Windows
# !type ..\requirements.txt
The statements starting with % or %% are built-in magic commands, i.e. commands interpreted by the IPython kernel. E.g. %%script sh tells IPython to run the cell with the shell sh (like the #! line at the beginning of script).
6 Environment¶
6.1 Python¶
The Python prompt is what you get when typing python in your terminal. It is useful to test commands and check your installation. We however prefer IPython for interactive work, see below.
Python files, with the extension .py, are either scripts or modules. A Python script is a file which gets executed with either python myscript.py or ./myscript.py if it has execution permissions as well as a shabang (#!) indicating which interpreter should be used. Below is an example of a typical script. The ! in front of a command tells IPython to execute the command with the system terminal.
!cat ../check_install.py
!python ../check_install.py
!../check_install.py
# Windows
# !type ..\check_install.py
# !python ..\check_install.py
#!/bin/env python3
print('A Network Tour of Data Science: Python installation test')
import os
import sys
major, minor = sys.version_info.major, sys.version_info.minor
if major is not 3:
raise Exception('please use Python 3, you have Python {}.'.format(major))
try:
import numpy
import scipy
import matplotlib
import sklearn
import requests
import facebook
import tweepy
import pandas
import xlrd
import xlwt
import tables
import sqlalchemy
import statsmodels
import sympy
import autograd
import bokeh
import numba
import Cython
os.environ['KERAS_BACKEND'] = 'theano' # Easier for Windows users.
import keras
import theano
#import tensorflow
import jupyter
import IPython, ipykernel
except:
print('Your installation misses a package.')
print('Please look for the package name below and install it with your '
'package manager (conda, brew, apt-get, yum, pacman, etc.) or pip.')
raise
print('You did successfully install Python {}.{} and '
'most of the Python packages we will use.'.format(major, minor))
A Network Tour of Data Science: Python installation test
Using Theano backend.
You did successfully install Python 3.5 and most of the Python packages we will use.
A Network Tour of Data Science: Python installation test
Using Theano backend.
You did successfully install Python 3.5 and most of the Python packages we will use.
A Python module is similar to a script, except that it is suposed to be imported and used by another script or module. It defines objects like classes or functions which are meant to be exported. Below is an example of a typical module, composed of only one function, get_data(). Note that the module itself imports other modules (pandas, urllib and os.path).
!cat ../utils.py
# Windows: !type ..\utils.py
cat: ../utils.py: No such file or directory
6.2 IPython¶
The IPython prompt is that is what you get when running ipython in your terminal. It is more convenient than the Python prompt and is useful for interactive work like small experiments or as a powerful calculator.
6.3 Jupyter¶
The Jupyter notebook is the web interface you get when running jupyter notebook. It features a file explorer, various kernels (for Python, R, Julia) and can export any notebook to HTML / PDF (via jupyter nbconvert). The basic document is a notebook which is composed of cells who are either code, results or markdown text / math. The Jupyter notebook is the interface we'll use for most of the course.
Markdown is a lightweight markup language which is very much used to generate HTML documents (e.g. on GitHub or with static website generators). See this cheatsheet as a very short introduction. Or simply edit the cells in this notebook. Markdown can include Latex math such as $y = 2x$.
6.4 Installing and managing packages¶
As explained in the README, we prefer to work inside virtual environments. Installing packages, a collection of modules, inside or outside virtual environments is however the same.
Most of the packages, i.e. reusable pieces of code, are posted on PyPI, the Python Package Index, by their authors. The Python package manager, pip, is a command-line tool to search and download packages from PyPI.
Note that some packages, like NumPy, requires native, i.e. compiled, dependencies. That is why installing with
pip installmay fail, as it only manages Python packages. In that case you need to install those dependencies by hand or with the help of a package manager likebrewfor Mac or whatever your Linux distribution uses.
Searching for a package goes like this (can be typed in your terminal):
!pip search music21
OutputLilyPond (1.0.0) - Produce a LilyPond file from a music21 Score.
music21 (3.1.0) - A Toolkit for Computer-Aided Musical Analysis and
Manipulation.
contourviz (0.2.4) - A package that charts musical contours into a web-
based interactive using music21 and D3.js.
music22 (0.0.2.post1) - A tool for musicological analysis from audio files.
For a symbolic analysis, you can use Music21
(http://web.mit.edu/music21/). Now it is focused on
modal music analysis : Scale analysis, tonic
detection
!pip install numpy
Requirement already satisfied (use --upgrade to upgrade): numpy in /usr/lib/python3.5/site-packages
You can get the list of installed packages with pip freeze. These are all the packages that are installed and available on your system. They could have been installed by pip install packname (maybe as a dependancy), by conda install packname or by your system's package manager.
!pip freeze
appdirs==1.4.0 autograd==1.1.6 blinker==1.4 bokeh==0.12.3 Bottleneck==1.1.0 click==6.6 cycler==0.10.0 Cython==0.24.1 decorator==4.0.10 docopt==0.6.2 docutils==0.12 entrypoints==0.2.2 facebook-sdk==2.0.0 feedgenerator==1.9 flake8==3.0.4 Flask==0.11.1 future==0.15.2 gmpy2==2.0.8 grip==4.3.2 h5py==2.6.0 ipykernel==4.5.0 ipython==5.1.0 ipython-genutils==0.1.0 ipywidgets==5.2.2 isc==2.0 itsdangerous==0.24 Jinja2==2.8 jsonschema==2.5.1 jupyter==1.0.0 jupyter-client==4.4.0 jupyter-console==5.0.0 jupyter-core==4.2.0 Keras==1.1.0 llvmlite==0.13.0 louis==3.0.0 Markdown==2.6.6 MarkupSafe==0.23 matplotlib==1.5.2 mccabe==0.5.2 mistune==0.7.3 mpmath==0.19 nbconvert==4.2.0 nbformat==4.1.0 nose==1.3.7 notebook==4.2.3 numba==0.28.1 numexpr==2.6.1 numpy==1.11.2 oauthlib==2.0.0 packaging==16.7 pandas==0.19.0 path-and-address==2.0.1 path.py==8.2.1 patsy==0.4.1 pelican==3.6.3 pexpect==4.2.1 pickleshare==0.7.4 prompt-toolkit==1.0.7 ptyprocess==0.5.1 pycodestyle==2.0.0 pyflakes==1.2.3 Pygments==2.1.3 pygobject==3.20.1 pyparsing==2.1.10 python-dateutil==2.5.3 pytz==2016.6.1 pyudev==0.19.0 PyYAML==3.12 pyzmq==16.0.0 qtconsole==4.2.1 ranger==1.7.2 requests==2.11.1 requests-oauthlib==0.7.0 scikit-learn==0.18 scipy==0.18.1 simplegeneric==0.8.1 six==1.10.0 solaar==0.9.2 SQLAlchemy==1.1.0 statsmodels==0.6.1 sympy==1.0 tables==3.3.0 terminado==0.6 Theano==0.8.2 tornado==4.4.2 traitlets==4.3.1 tweepy==3.5.0 Unidecode==0.4.19 wcwidth==0.1.7 Werkzeug==0.11.11 widgetsnbextension==1.2.6 xlrd==1.0.0 xlwt==1.1.2
6.5 Code versioning¶
While mastering git is not a necessity to follow the exercises, it is a good practice to version the code you write and it will definitely be useful to you in the future.
The commands you need for the exercises is
git clone https://github.com/mdeff/ntds_2016.git
the first time to copy the repository on your computer. Once you have it, you can simply download the updates every Monday morning with
git pull
Other commands of interest if you want to maintain your own repository are add, commit and push. The basic workfow is
git clone url
# make your changes
git commit -a -m "my first commit"
git push