教師あり学習(サポートベクトルマシン)¶
- 本実習では、教師あり学習のうち、サポートベクトルマシン(SVM: Support Vector Machine)を使います。
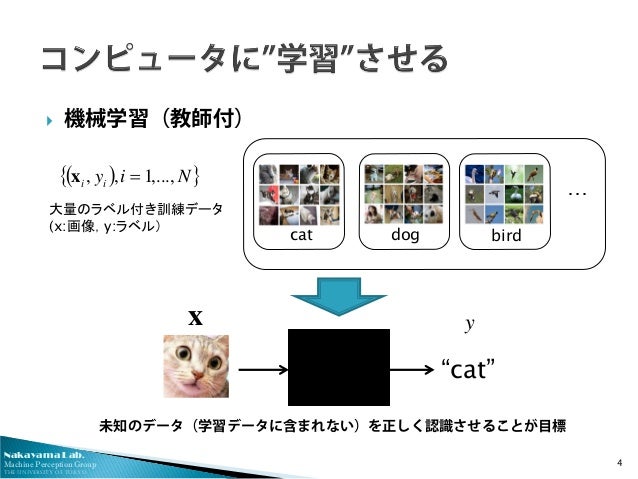
- 機械学習とは→ コンピューターに"学習"させる
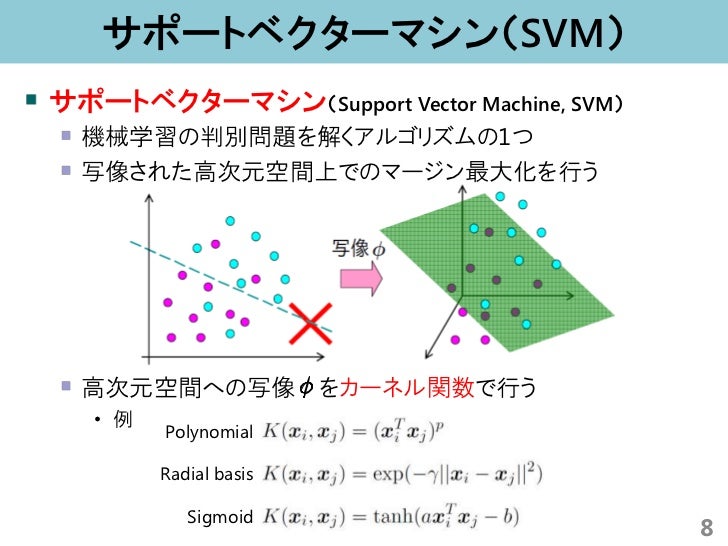
- サポートベクターマシン ・ サポートベクターマシンとは
{kind=link}
{kind=link}
#(シャープ)以降の文字はプログラムに影響しません。
# 図やグラフを図示するためのライブラリをインポートする。
import matplotlib.pyplot as plt
import matplotlib.ticker as ticker
%matplotlib inline
# 数値計算やデータフレーム操作に関するライブラリをインポートする
import numpy as np
import pandas as pd
from pandas.tools import plotting # 高度なプロットを行うツールのインポート
# URL によるリソースへのアクセスを提供するライブラリをインポートする。
# import urllib # Python 2 の場合
import urllib.request # Python 3 の場合
import sklearn #機械学習のライブラリ
from sklearn.decomposition import PCA #主成分分析器
「スイス銀行紙幣データ」を例に説明します。これは、本物のスイス紙幣の紙幣(真札)と偽札の横幅長などの測定値のデータです。果たして、真札と偽札とを機械学習で区別できるでしょうか?
# ウェブ上のリソースを指定する
url = 'https://raw.githubusercontent.com/maskot1977/ipython_notebook/master/toydata/sbnote_dataJt.txt'
# 指定したURLからリソースをダウンロードし、名前をつける。
# urllib.urlretrieve(url, 'sbnote_dataJt.txt') # Python 2 の場合
urllib.request.urlretrieve(url, 'sbnote_dataJt.txt') # Python 3 の場合
('sbnote_dataJt.txt', <http.client.HTTPMessage at 0x1098f40f0>)
df = pd.read_csv('sbnote_dataJt.txt', sep='\t', index_col=0) # データの読み込み
df
| length | left | right | bottom | top | diagonal | class | |
|---|---|---|---|---|---|---|---|
| Note | |||||||
| 1 | 214.8 | 131.0 | 131.1 | 9.0 | 9.7 | 141.0 | 0 |
| 2 | 214.6 | 129.7 | 129.7 | 8.1 | 9.5 | 141.7 | 0 |
| 3 | 214.8 | 129.7 | 129.7 | 8.7 | 9.6 | 142.2 | 0 |
| 4 | 214.8 | 129.7 | 129.6 | 7.5 | 10.4 | 142.0 | 0 |
| 5 | 215.0 | 129.6 | 129.7 | 10.4 | 7.7 | 141.8 | 0 |
| 6 | 215.7 | 130.8 | 130.5 | 9.0 | 10.1 | 141.4 | 0 |
| 7 | 215.5 | 129.5 | 129.7 | 7.9 | 9.6 | 141.6 | 0 |
| 8 | 214.5 | 129.6 | 129.2 | 7.2 | 10.7 | 141.7 | 0 |
| 9 | 214.9 | 129.4 | 129.7 | 8.2 | 11.0 | 141.9 | 0 |
| 10 | 215.2 | 130.4 | 130.3 | 9.2 | 10.0 | 140.7 | 0 |
| 11 | 215.3 | 130.4 | 130.3 | 7.9 | 11.7 | 141.8 | 0 |
| 12 | 215.1 | 129.5 | 129.6 | 7.7 | 10.5 | 142.2 | 0 |
| 13 | 215.2 | 130.8 | 129.6 | 7.9 | 10.8 | 141.4 | 0 |
| 14 | 214.7 | 129.7 | 129.7 | 7.7 | 10.9 | 141.7 | 0 |
| 15 | 215.1 | 129.9 | 129.7 | 7.7 | 10.8 | 141.8 | 0 |
| 16 | 214.5 | 129.8 | 129.8 | 9.3 | 8.5 | 141.6 | 0 |
| 17 | 214.6 | 129.9 | 130.1 | 8.2 | 9.8 | 141.7 | 0 |
| 18 | 215.0 | 129.9 | 129.7 | 9.0 | 9.0 | 141.9 | 0 |
| 19 | 215.2 | 129.6 | 129.6 | 7.4 | 11.5 | 141.5 | 0 |
| 20 | 214.7 | 130.2 | 129.9 | 8.6 | 10.0 | 141.9 | 0 |
| 21 | 215.0 | 129.9 | 129.3 | 8.4 | 10.0 | 141.4 | 0 |
| 22 | 215.6 | 130.5 | 130.0 | 8.1 | 10.3 | 141.6 | 0 |
| 23 | 215.3 | 130.6 | 130.0 | 8.4 | 10.8 | 141.5 | 0 |
| 24 | 215.7 | 130.2 | 130.0 | 8.7 | 10.0 | 141.6 | 0 |
| 25 | 215.1 | 129.7 | 129.9 | 7.4 | 10.8 | 141.1 | 0 |
| 26 | 215.3 | 130.4 | 130.4 | 8.0 | 11.0 | 142.3 | 0 |
| 27 | 215.5 | 130.2 | 130.1 | 8.9 | 9.8 | 142.4 | 0 |
| 28 | 215.1 | 130.3 | 130.3 | 9.8 | 9.5 | 141.9 | 0 |
| 29 | 215.1 | 130.0 | 130.0 | 7.4 | 10.5 | 141.8 | 0 |
| 30 | 214.8 | 129.7 | 129.3 | 8.3 | 9.0 | 142.0 | 0 |
| ... | ... | ... | ... | ... | ... | ... | ... |
| 171 | 213.9 | 130.7 | 130.5 | 8.7 | 11.5 | 137.8 | 1 |
| 172 | 214.2 | 130.6 | 130.4 | 12.0 | 10.2 | 139.6 | 1 |
| 173 | 214.8 | 130.5 | 130.3 | 11.8 | 10.5 | 139.4 | 1 |
| 174 | 214.8 | 129.6 | 130.0 | 10.4 | 11.6 | 139.2 | 1 |
| 175 | 214.8 | 130.1 | 130.0 | 11.4 | 10.5 | 139.6 | 1 |
| 176 | 214.9 | 130.4 | 130.2 | 11.9 | 10.7 | 139.0 | 1 |
| 177 | 214.3 | 130.1 | 130.1 | 11.6 | 10.5 | 139.7 | 1 |
| 178 | 214.5 | 130.4 | 130.0 | 9.9 | 12.0 | 139.6 | 1 |
| 179 | 214.8 | 130.5 | 130.3 | 10.2 | 12.1 | 139.1 | 1 |
| 180 | 214.5 | 130.2 | 130.4 | 8.2 | 11.8 | 137.8 | 1 |
| 181 | 215.0 | 130.4 | 130.1 | 11.4 | 10.7 | 139.1 | 1 |
| 182 | 214.8 | 130.6 | 130.6 | 8.0 | 11.4 | 138.7 | 1 |
| 183 | 215.0 | 130.5 | 130.1 | 11.0 | 11.4 | 139.3 | 1 |
| 184 | 214.6 | 130.5 | 130.4 | 10.1 | 11.4 | 139.3 | 1 |
| 185 | 214.7 | 130.2 | 130.1 | 10.7 | 11.1 | 139.5 | 1 |
| 186 | 214.7 | 130.4 | 130.0 | 11.5 | 10.7 | 139.4 | 1 |
| 187 | 214.5 | 130.4 | 130.0 | 8.0 | 12.2 | 138.5 | 1 |
| 188 | 214.8 | 130.0 | 129.7 | 11.4 | 10.6 | 139.2 | 1 |
| 189 | 214.8 | 129.9 | 130.2 | 9.6 | 11.9 | 139.4 | 1 |
| 190 | 214.6 | 130.3 | 130.2 | 12.7 | 9.1 | 139.2 | 1 |
| 191 | 215.1 | 130.2 | 129.8 | 10.2 | 12.0 | 139.4 | 1 |
| 192 | 215.4 | 130.5 | 130.6 | 8.8 | 11.0 | 138.6 | 1 |
| 193 | 214.7 | 130.3 | 130.2 | 10.8 | 11.1 | 139.2 | 1 |
| 194 | 215.0 | 130.5 | 130.3 | 9.6 | 11.0 | 138.5 | 1 |
| 195 | 214.9 | 130.3 | 130.5 | 11.6 | 10.6 | 139.8 | 1 |
| 196 | 215.0 | 130.4 | 130.3 | 9.9 | 12.1 | 139.6 | 1 |
| 197 | 215.1 | 130.3 | 129.9 | 10.3 | 11.5 | 139.7 | 1 |
| 198 | 214.8 | 130.3 | 130.4 | 10.6 | 11.1 | 140.0 | 1 |
| 199 | 214.7 | 130.7 | 130.8 | 11.2 | 11.2 | 139.4 | 1 |
| 200 | 214.3 | 129.9 | 129.9 | 10.2 | 11.5 | 139.6 | 1 |
200 rows × 7 columns
"class" が札の真偽を表します(0: 真札, 1:偽札)
# 散布図行列
plotting.scatter_matrix(df[list(df.columns[:-1])], figsize=(10, 10))
plt.show()

# 色分けした散布図行列
color_codes = ["#FF0000", "#0000FF", "#00FF00"]
class_names = list(set(df.iloc[:, -1]))
colors = [color_codes[class_names.index(x)] for x in list(df.iloc[:, -1])]
plotting.scatter_matrix(df[list(df.columns[:6])], figsize=(10, 10), color=colors)
plt.show()

上の散布図行列から、真札と偽札の間には、それぞれ違った特徴がありそうだと分かります。
# 行列の正規化
dfs = df.iloc[:, :-1].apply(lambda x: (x-x.mean())/x.std(), axis=0).fillna(0)
#主成分分析の実行
pca = PCA()
pca.fit(dfs.iloc[:, :])
# データを主成分空間に写像 = 次元圧縮
feature = pca.transform(dfs.iloc[:, :])
# 第一主成分と第二主成分でプロットする
plt.figure(figsize=(8, 8))
for x, y, name in zip(feature[:, 0], feature[:, 1], dfs.index):
plt.text(x, y, name, alpha=0.5, size=10)
plt.scatter(feature[:, 0], feature[:, 1], alpha=0.8)
plt.grid()
plt.show()

上の主成分分析の結果を見ても、大きく2群に分かれることがわかりました。真札と偽札で色分けをしたらどうなるでしょうか?
color_codes = ["#FF0000", "#0000FF", "#00FF00"]
class_names = list(set(df.iloc[:, -1]))
colors = [color_codes[class_names.index(x)] for x in list(df.iloc[:, -1])]
#主成分分析の実行
pca = PCA()
pca.fit(dfs.iloc[:, :])
# データを主成分空間に写像 = 次元圧縮
feature = pca.transform(dfs.iloc[:, :])
# 第一主成分と第二主成分でプロットする
plt.figure(figsize=(8, 8))
for x, y, name in zip(feature[:, 0], feature[:, 1], dfs.index):
plt.text(x, y, name, alpha=0.5, size=10)
plt.scatter(feature[:, 0], feature[:, 1], alpha=0.8, c=colors)
plt.grid()
plt.show()

これまでの解析で、真札と偽札にははっきりとした特徴の違いがあることが分かりました。では次に、これを自動的に区別するための機械学習モデルを作りましょう。
データの整形¶
Nをサンプル数、Mを特徴量の数とする。__data__から__target__を予測する問題を解く。
- feature_names : 特徴量の名前(M次元のベクトル)
- target_names : 目的変数の名前
- sample_names : サンプルの名前(N次元のベクトル)
- data : 説明変数(N行M列の行列)
- target : 目的変数(N次元のベクトル)
feature_names = df.columns[:-1]
target_names = list(set(df.iloc[:, -1]))
sample_names = df.index
data = df.iloc[:, :-1]
target = df.iloc[:, -1]
{kind=link}
from sklearn import cross_validation as cv
train_data, test_data, train_target, test_target = cv.train_test_split(data, target, test_size=0.5)
train_data
| Sepal.Length | Sepal.Width | Petal.Length | Petal.Width | |
|---|---|---|---|---|
| 54 | 5.5 | 2.3 | 4.0 | 1.3 |
| 127 | 6.2 | 2.8 | 4.8 | 1.8 |
| 66 | 6.7 | 3.1 | 4.4 | 1.4 |
| 70 | 5.6 | 2.5 | 3.9 | 1.1 |
| 44 | 5.0 | 3.5 | 1.6 | 0.6 |
| 21 | 5.4 | 3.4 | 1.7 | 0.2 |
| 122 | 5.6 | 2.8 | 4.9 | 2.0 |
| 91 | 5.5 | 2.6 | 4.4 | 1.2 |
| 80 | 5.7 | 2.6 | 3.5 | 1.0 |
| 121 | 6.9 | 3.2 | 5.7 | 2.3 |
| 36 | 5.0 | 3.2 | 1.2 | 0.2 |
| 37 | 5.5 | 3.5 | 1.3 | 0.2 |
| 4 | 4.6 | 3.1 | 1.5 | 0.2 |
| 69 | 6.2 | 2.2 | 4.5 | 1.5 |
| 34 | 5.5 | 4.2 | 1.4 | 0.2 |
| 135 | 6.1 | 2.6 | 5.6 | 1.4 |
| 40 | 5.1 | 3.4 | 1.5 | 0.2 |
| 53 | 6.9 | 3.1 | 4.9 | 1.5 |
| 117 | 6.5 | 3.0 | 5.5 | 1.8 |
| 52 | 6.4 | 3.2 | 4.5 | 1.5 |
| 14 | 4.3 | 3.0 | 1.1 | 0.1 |
| 150 | 5.9 | 3.0 | 5.1 | 1.8 |
| 62 | 5.9 | 3.0 | 4.2 | 1.5 |
| 147 | 6.3 | 2.5 | 5.0 | 1.9 |
| 145 | 6.7 | 3.3 | 5.7 | 2.5 |
| 146 | 6.7 | 3.0 | 5.2 | 2.3 |
| 27 | 5.0 | 3.4 | 1.6 | 0.4 |
| 12 | 4.8 | 3.4 | 1.6 | 0.2 |
| 63 | 6.0 | 2.2 | 4.0 | 1.0 |
| 101 | 6.3 | 3.3 | 6.0 | 2.5 |
| ... | ... | ... | ... | ... |
| 2 | 4.9 | 3.0 | 1.4 | 0.2 |
| 105 | 6.5 | 3.0 | 5.8 | 2.2 |
| 130 | 7.2 | 3.0 | 5.8 | 1.6 |
| 132 | 7.9 | 3.8 | 6.4 | 2.0 |
| 126 | 7.2 | 3.2 | 6.0 | 1.8 |
| 17 | 5.4 | 3.9 | 1.3 | 0.4 |
| 82 | 5.5 | 2.4 | 3.7 | 1.0 |
| 15 | 5.8 | 4.0 | 1.2 | 0.2 |
| 50 | 5.0 | 3.3 | 1.4 | 0.2 |
| 5 | 5.0 | 3.6 | 1.4 | 0.2 |
| 18 | 5.1 | 3.5 | 1.4 | 0.3 |
| 57 | 6.3 | 3.3 | 4.7 | 1.6 |
| 33 | 5.2 | 4.1 | 1.5 | 0.1 |
| 98 | 6.2 | 2.9 | 4.3 | 1.3 |
| 24 | 5.1 | 3.3 | 1.7 | 0.5 |
| 67 | 5.6 | 3.0 | 4.5 | 1.5 |
| 7 | 4.6 | 3.4 | 1.4 | 0.3 |
| 113 | 6.8 | 3.0 | 5.5 | 2.1 |
| 118 | 7.7 | 3.8 | 6.7 | 2.2 |
| 120 | 6.0 | 2.2 | 5.0 | 1.5 |
| 9 | 4.4 | 2.9 | 1.4 | 0.2 |
| 38 | 4.9 | 3.6 | 1.4 | 0.1 |
| 56 | 5.7 | 2.8 | 4.5 | 1.3 |
| 133 | 6.4 | 2.8 | 5.6 | 2.2 |
| 88 | 6.3 | 2.3 | 4.4 | 1.3 |
| 99 | 5.1 | 2.5 | 3.0 | 1.1 |
| 74 | 6.1 | 2.8 | 4.7 | 1.2 |
| 46 | 4.8 | 3.0 | 1.4 | 0.3 |
| 1 | 5.1 | 3.5 | 1.4 | 0.2 |
| 77 | 6.8 | 2.8 | 4.8 | 1.4 |
75 rows × 4 columns
SVMで学習・予測¶
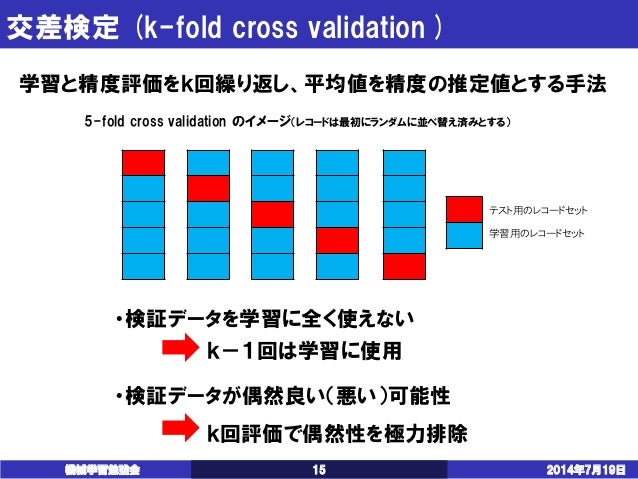
学習用データ( train_data と train_target ) の関係を学習して、テスト用データ( test_data )から正解( test_target ) を予測する、という流れになります。
# 様々なパラメータ(ハイパーパラメータという)で学習し、分離性能の最も良いモデルを選択する。
parameters = [
{'kernel': ['linear'], 'C': [1, 10, 100, 1000]},
{'kernel': ['rbf'], 'C': [1, 10, 100, 1000], 'gamma': [1e-2, 1e-3, 1e-4]},
{'kernel': ['poly'],'C': [1, 10, 100, 1000], 'degree': [2, 3, 4, 5]}]
from sklearn import svm
from sklearn.metrics import accuracy_score
import time
start = time.time()
from sklearn import grid_search
# train_data を使って、SVM による学習を行う
gs = grid_search.GridSearchCV(svm.SVC(), parameters, n_jobs=2).fit(train_data, train_target)
# 分離性能の最も良かったモデルが何だったか出力する
print(gs.best_estimator_)
# モデル構築に使わなかったデータを用いて、予測性能を評価する
pred_target = gs.predict(test_data)
print ("Accuracy_score:{0}".format(accuracy_score(test_target, pred_target)))
elapsed_time = time.time() - start
print("elapsed_time:{0}".format(elapsed_time))
SVC(C=1, cache_size=200, class_weight=None, coef0=0.0, degree=3, gamma=0.0, kernel='linear', max_iter=-1, probability=False, random_state=None, shrinking=True, tol=0.001, verbose=False) Accuracy_score:0.99 elapsed_time:0.5719201564788818
Accuracy score (正解率)が非常に高いことが分かります。この問題は、SVMで解くには簡単すぎるようです。
# 予測結果と、本当の答えを比較する
df = pd.DataFrame(columns=['test', 'pred'])
df['test'] = test_target # 本当の答え
df['pred'] = pred_target # 予測された答え
df.T
| Note | 20 | 149 | 113 | 54 | 90 | 99 | 183 | 100 | 62 | 105 | ... | 118 | 161 | 128 | 16 | 67 | 68 | 166 | 117 | 63 | 169 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| test | 0 | 1 | 1 | 0 | 0 | 0 | 1 | 0 | 0 | 1 | ... | 1 | 1 | 1 | 0 | 0 | 0 | 1 | 1 | 0 | 1 |
| pred | 0 | 1 | 1 | 0 | 0 | 0 | 1 | 0 | 0 | 1 | ... | 1 | 1 | 1 | 0 | 0 | 0 | 1 | 1 | 0 | 1 |
2 rows × 100 columns
# 予測結果を本当の答えの比較を、混合行列(confusion matrix)で表現する
from sklearn.metrics import confusion_matrix
cm = confusion_matrix(test_target, pred_target)
pd.DataFrame(cm)
| 0 | 1 | |
|---|---|---|
| 0 | 54 | 1 |
| 1 | 0 | 45 |
# 混合行列(confusion matrix)をカラーマップで見やすくする
plt.imshow(cm, interpolation='nearest', cmap=plt.cm.coolwarm)
plt.colorbar()
tick_marks = np.arange(len(target_names))
plt.xticks(tick_marks, target_names, rotation=45)
plt.yticks(tick_marks, target_names)
plt.tight_layout()
plt.ylabel('True label')
plt.xlabel('Predicted label')
<matplotlib.text.Text at 0x10c62ca90>

続いて、「あやめのデータ」を例に説明します。これは、3種類のあやめの測定値のデータです。果たして、これらの測定値から3種類のあやめを区別できるでしょうか?
以下の計算は、扱うデータこそ違いますが、ほとんど同じ操作で行っています。
url = 'https://raw.githubusercontent.com/maskot1977/ipython_notebook/master/toydata/iris.txt'
# 指定したURLからリソースをダウンロードし、名前をつける。
# urllib.urlretrieve(url, 'iris.txt') # Python 2 の場合
urllib.request.urlretrieve(url, 'iris.txt') # Python 3 の場合
('iris.txt', <http.client.HTTPMessage at 0x10c760f98>)
df = pd.read_csv('iris.txt', sep='\t', index_col=0) # データの読み込み
df
| Sepal.Length | Sepal.Width | Petal.Length | Petal.Width | Species | |
|---|---|---|---|---|---|
| 1 | 5.1 | 3.5 | 1.4 | 0.2 | setosa |
| 2 | 4.9 | 3.0 | 1.4 | 0.2 | setosa |
| 3 | 4.7 | 3.2 | 1.3 | 0.2 | setosa |
| 4 | 4.6 | 3.1 | 1.5 | 0.2 | setosa |
| 5 | 5.0 | 3.6 | 1.4 | 0.2 | setosa |
| 6 | 5.4 | 3.9 | 1.7 | 0.4 | setosa |
| 7 | 4.6 | 3.4 | 1.4 | 0.3 | setosa |
| 8 | 5.0 | 3.4 | 1.5 | 0.2 | setosa |
| 9 | 4.4 | 2.9 | 1.4 | 0.2 | setosa |
| 10 | 4.9 | 3.1 | 1.5 | 0.1 | setosa |
| 11 | 5.4 | 3.7 | 1.5 | 0.2 | setosa |
| 12 | 4.8 | 3.4 | 1.6 | 0.2 | setosa |
| 13 | 4.8 | 3.0 | 1.4 | 0.1 | setosa |
| 14 | 4.3 | 3.0 | 1.1 | 0.1 | setosa |
| 15 | 5.8 | 4.0 | 1.2 | 0.2 | setosa |
| 16 | 5.7 | 4.4 | 1.5 | 0.4 | setosa |
| 17 | 5.4 | 3.9 | 1.3 | 0.4 | setosa |
| 18 | 5.1 | 3.5 | 1.4 | 0.3 | setosa |
| 19 | 5.7 | 3.8 | 1.7 | 0.3 | setosa |
| 20 | 5.1 | 3.8 | 1.5 | 0.3 | setosa |
| 21 | 5.4 | 3.4 | 1.7 | 0.2 | setosa |
| 22 | 5.1 | 3.7 | 1.5 | 0.4 | setosa |
| 23 | 4.6 | 3.6 | 1.0 | 0.2 | setosa |
| 24 | 5.1 | 3.3 | 1.7 | 0.5 | setosa |
| 25 | 4.8 | 3.4 | 1.9 | 0.2 | setosa |
| 26 | 5.0 | 3.0 | 1.6 | 0.2 | setosa |
| 27 | 5.0 | 3.4 | 1.6 | 0.4 | setosa |
| 28 | 5.2 | 3.5 | 1.5 | 0.2 | setosa |
| 29 | 5.2 | 3.4 | 1.4 | 0.2 | setosa |
| 30 | 4.7 | 3.2 | 1.6 | 0.2 | setosa |
| ... | ... | ... | ... | ... | ... |
| 121 | 6.9 | 3.2 | 5.7 | 2.3 | virginica |
| 122 | 5.6 | 2.8 | 4.9 | 2.0 | virginica |
| 123 | 7.7 | 2.8 | 6.7 | 2.0 | virginica |
| 124 | 6.3 | 2.7 | 4.9 | 1.8 | virginica |
| 125 | 6.7 | 3.3 | 5.7 | 2.1 | virginica |
| 126 | 7.2 | 3.2 | 6.0 | 1.8 | virginica |
| 127 | 6.2 | 2.8 | 4.8 | 1.8 | virginica |
| 128 | 6.1 | 3.0 | 4.9 | 1.8 | virginica |
| 129 | 6.4 | 2.8 | 5.6 | 2.1 | virginica |
| 130 | 7.2 | 3.0 | 5.8 | 1.6 | virginica |
| 131 | 7.4 | 2.8 | 6.1 | 1.9 | virginica |
| 132 | 7.9 | 3.8 | 6.4 | 2.0 | virginica |
| 133 | 6.4 | 2.8 | 5.6 | 2.2 | virginica |
| 134 | 6.3 | 2.8 | 5.1 | 1.5 | virginica |
| 135 | 6.1 | 2.6 | 5.6 | 1.4 | virginica |
| 136 | 7.7 | 3.0 | 6.1 | 2.3 | virginica |
| 137 | 6.3 | 3.4 | 5.6 | 2.4 | virginica |
| 138 | 6.4 | 3.1 | 5.5 | 1.8 | virginica |
| 139 | 6.0 | 3.0 | 4.8 | 1.8 | virginica |
| 140 | 6.9 | 3.1 | 5.4 | 2.1 | virginica |
| 141 | 6.7 | 3.1 | 5.6 | 2.4 | virginica |
| 142 | 6.9 | 3.1 | 5.1 | 2.3 | virginica |
| 143 | 5.8 | 2.7 | 5.1 | 1.9 | virginica |
| 144 | 6.8 | 3.2 | 5.9 | 2.3 | virginica |
| 145 | 6.7 | 3.3 | 5.7 | 2.5 | virginica |
| 146 | 6.7 | 3.0 | 5.2 | 2.3 | virginica |
| 147 | 6.3 | 2.5 | 5.0 | 1.9 | virginica |
| 148 | 6.5 | 3.0 | 5.2 | 2.0 | virginica |
| 149 | 6.2 | 3.4 | 5.4 | 2.3 | virginica |
| 150 | 5.9 | 3.0 | 5.1 | 1.8 | virginica |
150 rows × 5 columns
# 散布図行列
plotting.scatter_matrix(df[list(df.columns[:-1])], figsize=(10, 10))
plt.show()

# 散布図行列
color_codes = ["#FF0000", "#0000FF", "#00FF00"]
class_names = list(set(df.iloc[:, -1]))
colors = [color_codes[class_names.index(x)] for x in list(df.iloc[:, -1])]
plotting.scatter_matrix(df[list(df.columns[:6])], figsize=(10, 10), color=colors)
plt.show()

# データの正規化
dfs = df.iloc[:, :-1].apply(lambda x: (x-x.mean())/x.std(), axis=0).fillna(0)
#主成分分析の実行
pca = PCA()
pca.fit(dfs.iloc[:, :])
# データを主成分空間に写像 = 次元圧縮
feature = pca.transform(dfs.iloc[:, :])
# 第一主成分と第二主成分でプロットする
plt.figure(figsize=(8, 8))
for x, y, name in zip(feature[:, 0], feature[:, 1], dfs.index):
plt.text(x, y, name, alpha=0.5, size=10)
plt.scatter(feature[:, 0], feature[:, 1], alpha=0.8)
plt.grid()
plt.show()

color_codes = ["#FF0000", "#0000FF", "#00FF00"]
class_names = list(set(df.iloc[:, -1]))
colors = [color_codes[class_names.index(x)] for x in list(df.iloc[:, -1])]
#主成分分析の実行
pca = PCA()
pca.fit(dfs.iloc[:, :])
# データを主成分空間に写像 = 次元圧縮
feature = pca.transform(dfs.iloc[:, :])
# 第一主成分と第二主成分でプロットする
plt.figure(figsize=(8, 8))
for x, y, name in zip(feature[:, 0], feature[:, 1], dfs.index):
plt.text(x, y, name, alpha=0.5, size=10)
plt.scatter(feature[:, 0], feature[:, 1], alpha=0.8, c=colors)
plt.grid()
plt.show()

データの整形¶
Nをサンプル数、Mを特徴量の数とする。__data__から__target__を予測する問題を解く。
- feature_names : 特徴量の名前(M次元のベクトル)
- target_names : 目的変数の名前
- sample_names : サンプルの名前(N次元のベクトル)
- data : 説明変数(N行M列の行列)
- target : 目的変数(N次元のベクトル)
feature_names = df.columns[:-1]
target_names = list(set(df.iloc[:, -1]))
sample_names = df.index
data = df.iloc[:, :-1]
target = df.iloc[:, -1]
from sklearn import cross_validation as cv
train_data, test_data, train_target, test_target = cv.train_test_split(data, target, test_size=0.5)
train_data
| Sepal.Length | Sepal.Width | Petal.Length | Petal.Width | |
|---|---|---|---|---|
| 112 | 6.4 | 2.7 | 5.3 | 1.9 |
| 127 | 6.2 | 2.8 | 4.8 | 1.8 |
| 15 | 5.8 | 4.0 | 1.2 | 0.2 |
| 8 | 5.0 | 3.4 | 1.5 | 0.2 |
| 70 | 5.6 | 2.5 | 3.9 | 1.1 |
| 13 | 4.8 | 3.0 | 1.4 | 0.1 |
| 145 | 6.7 | 3.3 | 5.7 | 2.5 |
| 84 | 6.0 | 2.7 | 5.1 | 1.6 |
| 59 | 6.6 | 2.9 | 4.6 | 1.3 |
| 67 | 5.6 | 3.0 | 4.5 | 1.5 |
| 138 | 6.4 | 3.1 | 5.5 | 1.8 |
| 143 | 5.8 | 2.7 | 5.1 | 1.9 |
| 114 | 5.7 | 2.5 | 5.0 | 2.0 |
| 23 | 4.6 | 3.6 | 1.0 | 0.2 |
| 21 | 5.4 | 3.4 | 1.7 | 0.2 |
| 44 | 5.0 | 3.5 | 1.6 | 0.6 |
| 132 | 7.9 | 3.8 | 6.4 | 2.0 |
| 42 | 4.5 | 2.3 | 1.3 | 0.3 |
| 43 | 4.4 | 3.2 | 1.3 | 0.2 |
| 105 | 6.5 | 3.0 | 5.8 | 2.2 |
| 142 | 6.9 | 3.1 | 5.1 | 2.3 |
| 27 | 5.0 | 3.4 | 1.6 | 0.4 |
| 79 | 6.0 | 2.9 | 4.5 | 1.5 |
| 131 | 7.4 | 2.8 | 6.1 | 1.9 |
| 82 | 5.5 | 2.4 | 3.7 | 1.0 |
| 110 | 7.2 | 3.6 | 6.1 | 2.5 |
| 4 | 4.6 | 3.1 | 1.5 | 0.2 |
| 94 | 5.0 | 2.3 | 3.3 | 1.0 |
| 102 | 5.8 | 2.7 | 5.1 | 1.9 |
| 18 | 5.1 | 3.5 | 1.4 | 0.3 |
| ... | ... | ... | ... | ... |
| 41 | 5.0 | 3.5 | 1.3 | 0.3 |
| 74 | 6.1 | 2.8 | 4.7 | 1.2 |
| 87 | 6.7 | 3.1 | 4.7 | 1.5 |
| 146 | 6.7 | 3.0 | 5.2 | 2.3 |
| 85 | 5.4 | 3.0 | 4.5 | 1.5 |
| 1 | 5.1 | 3.5 | 1.4 | 0.2 |
| 29 | 5.2 | 3.4 | 1.4 | 0.2 |
| 149 | 6.2 | 3.4 | 5.4 | 2.3 |
| 76 | 6.6 | 3.0 | 4.4 | 1.4 |
| 22 | 5.1 | 3.7 | 1.5 | 0.4 |
| 28 | 5.2 | 3.5 | 1.5 | 0.2 |
| 117 | 6.5 | 3.0 | 5.5 | 1.8 |
| 20 | 5.1 | 3.8 | 1.5 | 0.3 |
| 46 | 4.8 | 3.0 | 1.4 | 0.3 |
| 19 | 5.7 | 3.8 | 1.7 | 0.3 |
| 147 | 6.3 | 2.5 | 5.0 | 1.9 |
| 92 | 6.1 | 3.0 | 4.6 | 1.4 |
| 144 | 6.8 | 3.2 | 5.9 | 2.3 |
| 96 | 5.7 | 3.0 | 4.2 | 1.2 |
| 50 | 5.0 | 3.3 | 1.4 | 0.2 |
| 5 | 5.0 | 3.6 | 1.4 | 0.2 |
| 126 | 7.2 | 3.2 | 6.0 | 1.8 |
| 134 | 6.3 | 2.8 | 5.1 | 1.5 |
| 30 | 4.7 | 3.2 | 1.6 | 0.2 |
| 118 | 7.7 | 3.8 | 6.7 | 2.2 |
| 58 | 4.9 | 2.4 | 3.3 | 1.0 |
| 10 | 4.9 | 3.1 | 1.5 | 0.1 |
| 3 | 4.7 | 3.2 | 1.3 | 0.2 |
| 65 | 5.6 | 2.9 | 3.6 | 1.3 |
| 56 | 5.7 | 2.8 | 4.5 | 1.3 |
75 rows × 4 columns
SVMで学習・予測¶
学習用データ( train_data と train_target ) の関係を学習して、テスト用データ( test_data )から正解( test_target ) を予測する、という流れになります。
parameters = [
{'kernel': ['linear'], 'C': [1, 10, 100, 1000]},
{'kernel': ['rbf'], 'C': [1, 10, 100, 1000], 'gamma': [1e-2, 1e-3, 1e-4]},
{'kernel': ['poly'],'C': [1, 10, 100, 1000], 'degree': [2, 3, 4, 5]}]
from sklearn import svm
from sklearn.metrics import accuracy_score
import time
start = time.time()
from sklearn import grid_search
gs = grid_search.GridSearchCV(svm.SVC(), parameters, n_jobs=2).fit(train_data, train_target)
print(gs.best_estimator_)
pred_target = gs.predict(test_data)
print ("Accuracy_score:{0}".format(accuracy_score(test_target, pred_target)))
elapsed_time = time.time() - start
print("elapsed_time:{0}".format(elapsed_time))
SVC(C=1, cache_size=200, class_weight=None, coef0=0.0, degree=3, gamma=0.0, kernel='linear', max_iter=-1, probability=False, random_state=None, shrinking=True, tol=0.001, verbose=False) Accuracy_score:0.9733333333333334 elapsed_time:0.5098891258239746
df = pd.DataFrame(columns=['test', 'pred'])
df['test'] = test_target
df['pred'] = pred_target
df.T
| 85 | 79 | 35 | 108 | 65 | 142 | 41 | 112 | 13 | 106 | ... | 119 | 97 | 32 | 42 | 139 | 23 | 51 | 134 | 124 | 76 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| test | versicolor | versicolor | setosa | virginica | versicolor | virginica | setosa | virginica | setosa | virginica | ... | virginica | versicolor | setosa | setosa | virginica | setosa | versicolor | virginica | virginica | versicolor |
| pred | versicolor | versicolor | setosa | virginica | versicolor | virginica | setosa | virginica | setosa | virginica | ... | virginica | versicolor | setosa | setosa | virginica | setosa | versicolor | virginica | virginica | versicolor |
2 rows × 75 columns
from sklearn.metrics import confusion_matrix
cm = confusion_matrix(test_target, pred_target)
pd.DataFrame(cm)
| 0 | 1 | 2 | |
|---|---|---|---|
| 0 | 22 | 0 | 0 |
| 1 | 0 | 25 | 2 |
| 2 | 0 | 0 | 26 |
plt.imshow(cm, interpolation='nearest', cmap=plt.cm.coolwarm)
plt.colorbar()
tick_marks = np.arange(len(target_names))
plt.xticks(tick_marks, target_names, rotation=45)
plt.yticks(tick_marks, target_names)
plt.tight_layout()
plt.ylabel('True label')
plt.xlabel('Predicted label')
<matplotlib.text.Text at 0x10c466518>

setosa とそれ以外は簡単に区別できますが、versicolorとvirginicaの区別は、たまに間違えることもあるようですね。