Getting data from markup languages¶
So far we've discussed a number of sources for data: CSV files, web APIs, and unstructured text. There's a lot of data on the internet locked up in one of two "markup" languages: XML and HTML. Our goal today is to discuss and put into practice a few methods for extracting data from documents written in these languages.
HTML¶
HTML stands for "hypertext markup language." Most of the documents you see when you're browsing the web are written in this format. In most browsers, there's a "View Source" option that allows you to see the HTML source code for any page you're looking at. For example, in Chrome, you can CTRL-click anywhere on the page, or go to View > Developer > View Source:
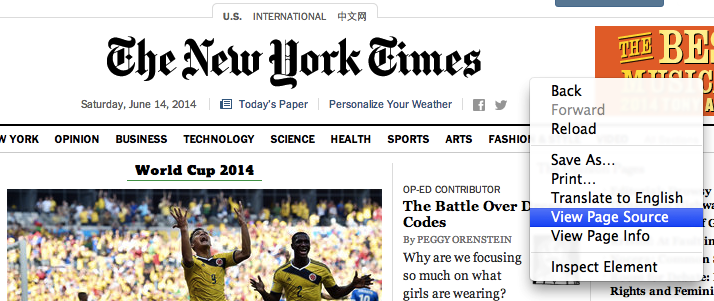
You'll see something that looks like this, a mish-mash of angle brackets and quotes and slashes and text. This is HTML.

What HTML looks like¶
HTML consists of a series of tags. Tags have a name, a series of key/value pairs called attributes, and some textual content. Attributes are optional. Here's a simple example, using the HTML <p> tag (p means "paragraph"):
<p>Mother said there'd be days like these.</p>
This example has just one tag in it: a <p> tag. The source code for a tag has two parts, its opening tag (<p>) and its closing tag (</p>). In between the opening and closing tag, you see the tag's contents (in this case, the text Mother said there'd be days like these.).
Here's another example, using the HTML <div> tag:
<div class="header" style="background: blue;">Mammoth Falls</div>
In this example, the tag's name is div. The tag has two attributes: class, with value header, and style, with value background: blue;. The contents of this tag is Mammoth Falls.
Tags can contain other tags, in a hierarchical relationship. For example, here's some HTML to make a bulletted list:
<ul>
<li>Item one</li>
<li>Item two</li>
<li>Item three</li>
</ul>
The <ul> tag (ul stands for "unordered list") in this example has three other <li> tags inside of it (li stands for "list item"). The <ul> tag is said to be the "parent" of the <li> tags, and the <li> tags are the "children" of the <ul> tag. All tags grouped under a particular parent tag are called "siblings."
HTML's shortcomings¶
HTML documents are intended to add "markup" to text to add information that allows browsers to display the text in different ways---e.g., HTML markup might tell the browser to make the font of the text a particular size, or to position it in a particular place on the screen.
Because the primary purpose of HTML is to change the appearance of text, HTML markup usually does not tell us anything useful about what the text means, or what kind of data it contains. When you look at a web page in the browser, it might appear to contain a list of newspaper articles, or a table with birth rates, or a series of names with associated biographies, or whatever. But that's information that we get, as humans, from reading the page. There's (usually) no easy way to extract this information with a computer program.
HTML is also notoriously messy---web browsers are very forgiving of syntax errors and other irregularities in HTML (like mismatched or unclosed tags). (This is in contrast to data formats like JSON, where even small errors will fail to be parsed.) For this reason, we need special libraries to parse HTML into data structures that our Python programs can use, libraries that can make a "good guess" about what the structure of an HTML document is, even when that structure is written incorrectly or inconsistently.
Beautiful Soup is a Python library that parses HTML (even if it's poorly formatted) and allows us to extract and manipulate its contents. We'll be using this library in the examples that follow.
Keep in mind that there are only sketchy rules for what HTML elements "mean"---semantic information you figure out for one web page might not apply to the next. Values for class attributes especially are meaningful only in the context of a single page.
Note: There's an effort to add semantic information to HTML markup called HTML Microformats. If sites added microformats to their markup, you'd be able to write code that could more reliably extract information from web pages, because there would be a common language for what tags with particular classes and attributes mean. Alas, microformats remain unpopular, and until the anarcho-collectivists win a greater mindshare, we can count only on our own individual readings of individual HTML documents.
Inspecting HTML's anatomy with Developer Tools¶
I've crafted a very simple example of HTML for us to work with. It concerns kittens. Here's the rendered version, and here's the HTML source code.
Now we're going to use Developer Tools in Chrome to take a look at how kittens.html is organized. Click on the "rendered version" link above. In Chrome, ctrl-click (or right click) anywhere on the page and select "Inspect Element." This will open Chrome's Developer Tools. Your screen should look (something) like this:
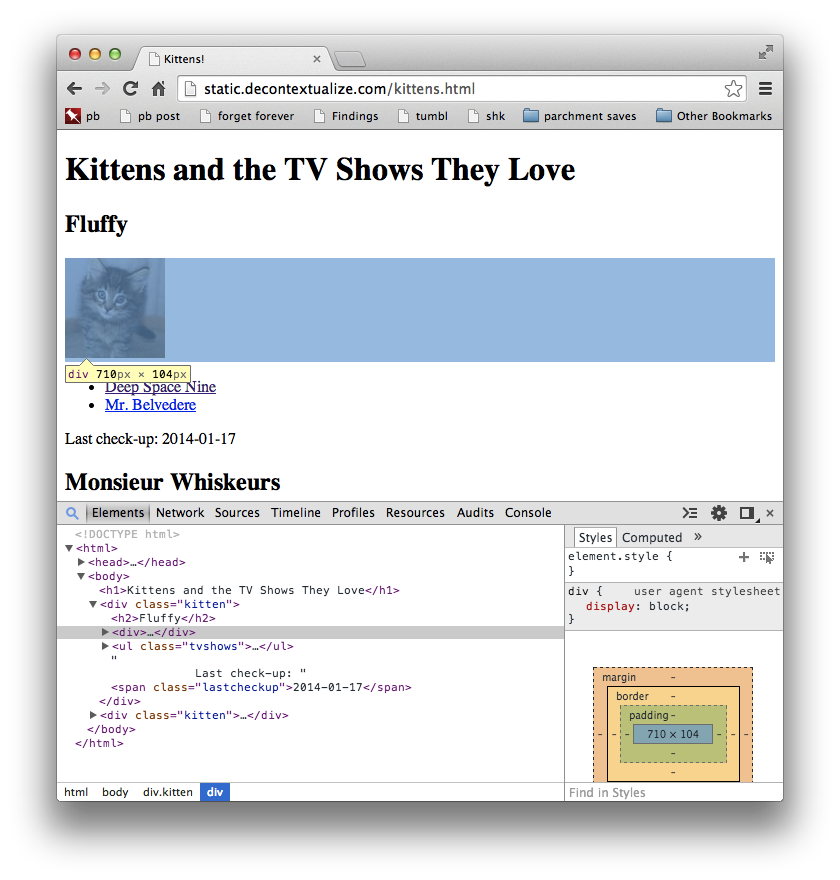
In the upper panel, you see the web page you're inspecting. In the lower panel, you see a version of the HTML source code, with little arrows next to some of the lines. (The little arrows allow you to collapse parts of the HTML source that are hierarchically related.) As you move your mouse over the elements in the top panel, different parts of the source code will be highlighted. Chrome is showing you which parts of the source code are causing which parts of the page to show up. Pretty spiffy!
This relationship also works in reverse: you can move your mouse over some part of the source code in the lower panel, which will highlight in the top panel what that source code corresponds to on the page. We'll be using this later to visually identify the parts of the page that are interesting to us, so we can write code that extracts the contents of those parts automatically.
Characterizing the structure of kittens¶
Here's what the source code of kittens.html looks like:
<!doctype html>
<html>
<head>
<title>Kittens!</title>
</head>
<body>
<h1>Kittens and the TV Shows They Love</h1>
<div class="kitten">
<h2>Fluffy</h2>
<div><img src="http://placekitten.com/100/100"></div>
<ul class="tvshows">
<li><a href="http://www.imdb.com/title/tt0106145/">Deep Space Nine</a></li>
<li><a href="http://www.imdb.com/title/tt0088576/">Mr. Belvedere</a></li>
</ul>
Last check-up: <span class="lastcheckup">2014-01-17</span>
</div>
<div class="kitten">
<h2>Monsieur Whiskeurs</h2>
<div><img src="http://placekitten.com/150/100"></div>
<ul class="tvshows">
<li><a href="http://www.imdb.com/title/tt0106179/">The X-Files</a></li>
<li><a href="http://www.imdb.com/title/tt0098800/">Fresh Prince</a></li>
</ul>
Last check-up: <span class="lastcheckup">2013-11-02</span>
</div>
</body>
</html>
This is pretty well organized HTML, but if you don't know how to read HTML, it will still look like a big jumble. Here's how I would characterize the structure of this HTML, reading in my own idea of what the meaning of the elements are.
- We have two "kittens," both of which are contained in
<div>tags with classkitten. - Each "kitten"
<div>has an<h2>tag with that kitten's name. - There's an image for each kitten, specified with an
<img>tag. - Each kitten has a list (a
<ul>with classtvshows) of television shows, contained within<li>tags. - Those list items themselves have links (
<a>tags) with anhrefattribute that contains a link to an IMDB entry for that show.
BONUS QUIZ: What's the parent tag of
<a href="http://www.imdb.com/title/tt0088576/">Mr. Belvedere</a>? Both<div class="kitten">tags share a parent tag---what is it? What attributes are present on both<img>tags?
Scraping kittens with Beautiful Soup¶
We've examined kittens.html a bit now. What we'd like to do is write some code that is going to extract information from the HTML, like "what is the last checkup date for each of these kittens?" or "what are Monsieur Whiskeur's favorite TV shows?" To do so, we need to parse the HTML, and create a representation of it in our program that we can manipulate with Python.
As mentioned above, HTML is hard to parse by hand. (Don't even try it. In particular, don't parse HTML with regular expressions.)
Beautiful Soup is a Python library that will parse the HTML for us, and give us some Python objects that we can call methods on to poke at the data contained therein.
The first thing we need to do is fetch the source code of that page. We can do that with our old friend urllib.urlopen():
import urllib
html_str = urllib.urlopen("https://raw.githubusercontent.com/ledeprogram/courses/master/databases/data/kittens.html").read()
Now html_str is a string that contains the HTML source code of the page in question:
print html_str
<!doctype html> <html> <head> <title>Kittens!</title> </head> <body> <h1>Kittens and the TV Shows They Love</h1> <div class="kitten"> <h2>Fluffy</h2> <div><img src="http://placekitten.com/100/100"></div> <ul class="tvshows"> <li> <a href="http://www.imdb.com/title/tt0106145/">Deep Space Nine</a> </li> <li> <a href="http://www.imdb.com/title/tt0088576/">Mr. Belvedere</a> </li> </ul> Last check-up: <span class="lastcheckup">2014-01-17</span> </div> <div class="kitten"> <h2>Monsieur Whiskeurs</h2> <div><img src="http://placekitten.com/150/100"></div> <ul class="tvshows"> <li> <a href="http://www.imdb.com/title/tt0106179/">The X-Files</a> </li> <li> <a href="http://www.imdb.com/title/tt0098800/">Fresh Prince</a> </li> </ul> Last check-up: <span class="lastcheckup">2013-11-02</span> </div> </body> </html>
Rad. Now we want to be able to ask questions about what's in the HTML. To do so, we're going to give the string to Beautiful Soup to parse.
from bs4 import BeautifulSoup
document = BeautifulSoup(html_str)
print type(document)
<class 'bs4.BeautifulSoup'>
We've created a BeautifulSoup object and assigned it to a variable document. This object supports a number of interesting methods. We'll focus on just a few.
Finding a tag¶
HTML documents are composed of tags. To represent this, Beautiful Soup has a type of value that represents tags. We can use the .find() method of the BeautifulSoup object to find a tag that matches a particular tag name. For example:
h1_tag = document.find('h1')
print type(h1_tag)
<class 'bs4.element.Tag'>
A Tag object has several interesting attributes and methods. The string attribute of a Tag object, for example, returns a string representing that tag's contents:
print h1_tag.string
Kittens and the TV Shows They Love
You can access the attributes of a tag by treating the tag object as though it were a dictionary, using the square-bracket index syntax, with the name of the attribute whose value you want as a string inside the brackets. For example, to print out the src attribute of the first <img> tag in the document:
img_tag = document.find('img')
print img_tag['src']
http://placekitten.com/100/100
Note: You might have noticed that there is more than one
<img>tag inkittens.html! If more than one tag matches the name you pass to.find(), it returns only the first matching tag. (A better name for.find()might befind_first.)
Finding multiple tags¶
It's often the case that we want to find not just one tag that matches particular criteria, but ALL tags matching those criteria. For that, we use the .find_all() method of the BeautifulSoup object. For example, to find all h2 tags in the document:
h2_tags = document.find_all('h2')
print type(h2_tags)
[tag.string for tag in h2_tags]
<class 'bs4.element.ResultSet'>
[u'Fluffy', u'Monsieur Whiskeurs']
Both the .find() and .find_all() methods can search not just for tags with particular names, but also for tags that have particular attributes. For that, we use the attrs keyword argument, giving it a dictionary that associates attribute names as keys and the desired attribute value as values. For example, to find all span tags with a class attribute of lastcheckup:
checkup_tags = document.find_all('span', attrs={'class': 'lastcheckup'})
[tag.string for tag in checkup_tags]
[u'2014-01-17', u'2013-11-02']
Note: Beautiful Soup's
.find()and.find_all()methods are actually more powerful than we're letting on here. Check out the details in the official Beautiful Soup documentation.
Finding tags within tags¶
Let's say that we wanted to print out a list of the name of each kitten, along with a list of the names of that kitten's favorite TV shows. In other words, we want to print out something that looks like this:
Fluffy: Deep Space Nine, Mr. Belvedere
Monsieur Whiskeurs: The X-Files, Fresh Prince
In order to do this, we need to find not just tags with particular names, but tags with particular hierarchical relationships with other tags. I.e., we need to identify all of the kittens, and then find the shows that belong to that kitten. This kind of search is made easy by the fact tht you can use .find() and .find_all() methods not just on the entire document, but on individual tags. When you use these methods on tags, they search for matching tags that are specifically children of the tag that you call them on.
In our kittens example, we can see that information about individual kittens is grouped together under <div> tags with a class attribute of kitten. So, to find a list of all <div> tags with class set to kitten, we might do this:
kitten_tags = document.find_all("div", attrs={"class": "kitten"})
Now, we'll loop over that list of tags and find, inside each of them, the <h2> tag that is its child:
for kitten_tag in kitten_tags:
h2_tag = kitten_tag.find('h2')
print h2_tag.string
Fluffy Monsieur Whiskeurs
Now, we'll go one extra step. Looping over all of the kitten tags, we'll find not just the <h2> tag with the kitten's name, but all <a> tags (which contain the names of the TV shows that we were looking for):
for kitten_tag in kitten_tags:
h2_tag = kitten_tag.find('h2')
a_tags = kitten_tag.find_all('a')
a_tag_strings = [tag.string for tag in a_tags]
a_tag_strings_joined = ", ".join(a_tag_strings)
print h2_tag.string + ": " + a_tag_strings_joined
Fluffy: Deep Space Nine, Mr. Belvedere Monsieur Whiskeurs: The X-Files, Fresh Prince
EXERCISE: Modify the code above to print out a list of kitten names along with the last check-up date for that kitten.
EXTRA FUN EXERCISE: Rewrite the code above to create a dictionary that maps kitten names to a list of links to that kitten's favorite shows. I.e., you should end up with a dictionary that looks like this:
{u'Fluffy': [u'http://www.imdb.com/title/tt0106145/',
u'http://www.imdb.com/title/tt0088576/'],
u'Monsieur Whiskeurs': [u'http://www.imdb.com/title/tt0106179/',
u'http://www.imdb.com/title/tt0098800/']}
Finding sibling tags¶
Often, the tags we're looking for don't have a distinguishing characteristic, like a class attribute, that allows us to find them using .find() and .find_all(), and the tags also aren't in a parent-child relationship. This can be tricky! Take the following HTML snippet, for example:
cheese_html = """
<h2>Camembert</h2>
<p>A soft cheese made in the Camembert region of France.</p>
<h2>Cheddar</h2>
<p>A yellow cheese made in the Cheddar region of... France, probably, idk whatevs.</p>
"""
If our task was to create a dictionary that maps the name of the cheese to the description that follows in the <p> tag directly afterward, we'd be out of luck. Fortunately, Beautiful Soup has a .find_next_sibling() method, which allows us to search for the next tag that is a sibling of the tag you're calling it on (i.e., the two tags share a parent), that also matches particular criteria. So, for example, to accomplish the task outlined above:
document = BeautifulSoup(cheese_html)
cheese_dict = {}
for h2_tag in document.find_all('h2'):
cheese_name = h2_tag.string
cheese_desc_tag = h2_tag.find_next_sibling('p')
cheese_dict[cheese_name] = cheese_desc_tag.string
cheese_dict
{u'Camembert': u'A soft cheese made in the Camembert region of France.',
u'Cheddar': u'A yellow cheese made in the Cheddar region of... France, probably, idk whatevs.'}
You now know most of what you need to know to scrape web pages effectively. Good job!
When things go wrong with Beautiful Soup¶
A number of things might go wrong with Beautiful Soup. You might, for example, search for a tag that doesn't exist in the document:
footer_tag = document.find("footer")
Beautiful Soup doesn't return an error if it can't find the tag you want. Instead, it returns None:
print footer_tag
None
If you try to call a method on the object that Beautiful Soup returned anyway, you might end up with an error like this:
footer_tag.find("p")
--------------------------------------------------------------------------- AttributeError Traceback (most recent call last) <ipython-input-49-68ae6cd15b29> in <module>() ----> 1 footer_tag.find("p") AttributeError: 'NoneType' object has no attribute 'find'
You might also inadvertently try to get an attribute of a tag that wasn't actually found. You'll get a similar error in that case:
footer_tag['title']
--------------------------------------------------------------------------- TypeError Traceback (most recent call last) <ipython-input-50-914072fc1329> in <module>() ----> 1 footer_tag['title'] TypeError: 'NoneType' object has no attribute '__getitem__'
Whenever you see something like AttributeError: 'NoneType' object has no attribute 'find' or TypeError: 'NoneType' object has no attribute '__getitem__', it's a good idea to check to see whether your method calls are indeed finding the thing you were looking for.
However, the .find_all() method will return an empty list if it doesn't find any of the tags you wanted:
footer_tags = document.find_all("footer")
print footer_tags
[]
If you attempt to access one of the elements of this regardless...
print footer_tags[0].string
--------------------------------------------------------------------------- IndexError Traceback (most recent call last) <ipython-input-44-26f61605c5b0> in <module>() ----> 1 print footer_tags[0].string IndexError: list index out of range
...you'll get an IndexError.
A real-world example, sort of¶
The rocky blue golf ball we live on is simply filthy with HTML pages ripe for scraping. As an example today, we're going to take a look at this one. That's right, the faculty list page for the Columbia Graduate School of Journalism. Whoa.
Our task is to create a list of every faculty member, along with their title, and a link to their photo (if any). Let's say that, in the end, we want to end up with a list of dictionaries that looks like this:
[
{'name': 'Adkison, Abbey', 'title': 'Digital Media Coordinator', 'img_src': None,
{'name': 'Barclay, Dolores', 'title': 'Adjunct Faculty', 'img_src': 'http://www.journalism.columbia.edu/system/photos/1943/default/Dolores-Barclay.gif?1365711292',
{'name': 'Baum, Geraldine', 'title': 'Adjunct Faculty', 'img_src': None}
...
]
(We could then do fun things with this data, like turn it into a PANDAS table or whatever.)
We're going to make some mistakes along the way, so you know what it looks like when mistakes happen and so you'll learn a little bit about how to recover from them.
The first step in this task? Use Developer Tools to find the elements we're looking for. In this screenshot, I'm mousing over the unit on the page that seems to contain the information I'm looking for. I've "expanded" some of the collapsed code sections to make it easier to see the hierarchy of tags.
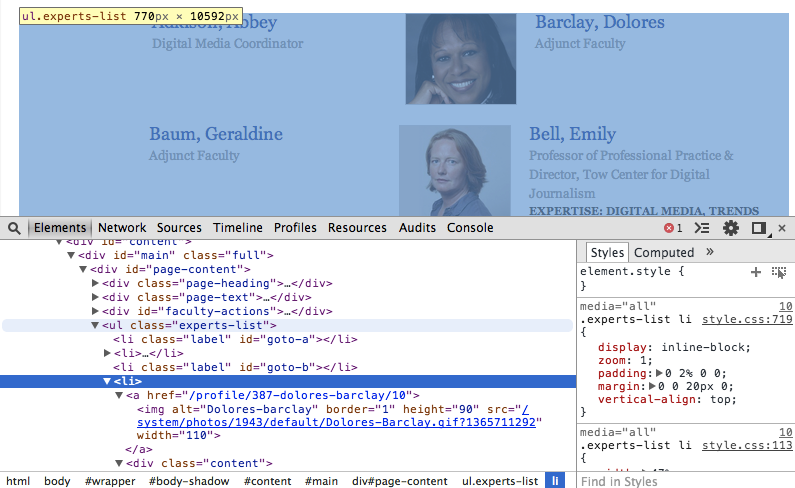
Based on what I'm seeing here, I can start to formulate a plan to scrape the document. Here's what I came up with:
- It looks like each faculty member has an
<li>tag, so I'll find all of those. - For each
<li>tag, I need to find an<img>tag---specifically, I need to grab thesrcattribute from that tag. - The faculty member's name is inside an
<a>tag---specifically, an<a>tag inside of an<h4>tag. - The faculty member's title seems to be located inside a
<p>tag withclassattributedescription.
Let's write some code to do that!
html_str = urllib.urlopen("http://www.journalism.columbia.edu/page/10/10?category_ids%5B%5D=2&category_ids%5B%5D=3&category_ids%5B%5D=37").read()
document = BeautifulSoup(html_str)
faculty_list = []
for faculty_tag in document.find_all('li'):
# create empty dictionary to store this faculty member
faculty_dict = {}
# faculty name
h4_tag = faculty_tag.find('h4')
a_tag = h4_tag.find('a')
faculty_dict['name'] = a_tag.string
# image URL
img_tag = faculty_tag.find('img')
faculty_dict['img_src'] = img_tag['src']
# title
p_tag = faculty_tag.find('p', attrs={'class': 'description'})
faculty_dict['title'] = p_tag.string
# append to list
faculty_list.append(faculty_dict)
faculty_list
--------------------------------------------------------------------------- AttributeError Traceback (most recent call last) <ipython-input-69-80e2b0320d95> in <module>() 7 # faculty name 8 h4_tag = faculty_tag.find('h4') ----> 9 a_tag = h4_tag.find('a') 10 faculty_dict['name'] = a_tag.string 11 # image URL AttributeError: 'NoneType' object has no attribute 'find'
Looks good, but wait! When we run it, we get an error: AttributeError: 'NoneType' object has no attribute 'find'. Specifically, the h4_tag, whose .find() method we're trying to use, seems to be None... which means that there wasn't an h4 tag where we expected there to be one. To diagnose the problem, let's simplify our code a little bit to see where the problem is. (I used the range syntax [:5] in the for loop here, so that we'll grab just the first five results---that should be enough to diagnose our problem.)
html_str = urllib.urlopen("http://www.journalism.columbia.edu/page/10/10?category_ids%5B%5D=2&category_ids%5B%5D=3&category_ids%5B%5D=37").read()
document = BeautifulSoup(html_str)
for faculty_tag in document.find_all('li')[:5]:
print faculty_tag
<li><a href="/page/1-about-the-school/1">About the School</a> </li> <li><a href="/page/7-our-programs/7">Academic Programs</a> </li> <li><a href="/page/13-career-services/13">Career Services</a> </li> <li><a href="/page/14-events-calendar/14">Events</a> </li> <li><a class="active" href="/page/10-full-time-adjunct-visiting-faculty/10">Faculty</a></li>
When you print a Tag object, BeautifulSoup displays the source code for those tags. Here we can see that the <li> tags we've found aren't quite the <li> tags we were looking for---these seem to be <li> tags from another part of the page! Whoops. I guess we need to be more specific about which <li> tags we want. How do we do that, though? Let's go back to Developer Tools.
Now it looks like all of the relevant <li> tags have a single parent tag---<ul class="experts-list">. So what we need to do is find not all <li> tags on the page, but only those <li> tags that are children of this particular <ul> tag. Here's some revised code to do just that:
experts_ul_tag = document.find('ul', attrs={'class': 'experts-list'})
for faculty_tag in experts_ul_tag.find_all('li')[:5]:
print faculty_tag
<li class="label" id="goto-a"></li> <li> <div class="content"> <h4><a href="/profile/228-abbey-adkison/10">Adkison, Abbey </a></h4> <p class="description">Digital Media Coordinator</p> </div> </li> <li class="label" id="goto-b"></li> <li> <a href="/profile/387-dolores-barclay/10"><img alt="Dolores-barclay" border="1" height="90" src="/system/photos/1943/default/Dolores-Barclay.gif?1365711292" width="110"/></a> <div class="content"> <h4><a href="/profile/387-dolores-barclay/10">Barclay, Dolores </a></h4> <p class="description">Adjunct Faculty</p> </div> </li> <li> <div class="content"> <h4><a href="/profile/341-geraldine-baum/10">Baum, Geraldine</a></h4> <p class="description">Adjunct Faculty</p> </div> </li>
This looks a little bit better, but we've still got a few weird things: namely, there are some <li> tags, (those with a class attribute of label) which don't seem to contain h4 tags---or any other content we're interested in at all. We need to put in a check so our code will disregard any <li> tags like this. Here's another attempt:
experts_ul_tag = document.find('ul', attrs={'class': 'experts-list'})
for faculty_tag in experts_ul_tag.find_all('li')[:5]:
h4_tag = faculty_tag.find('h4')
if h4_tag is None:
continue
print h4_tag
<h4><a href="/profile/228-abbey-adkison/10">Adkison, Abbey </a></h4> <h4><a href="/profile/387-dolores-barclay/10">Barclay, Dolores </a></h4> <h4><a href="/profile/341-geraldine-baum/10">Baum, Geraldine</a></h4>
Okay, now we're in business. At last. Let's put this code together with the previous example.
html_str = urllib.urlopen("http://www.journalism.columbia.edu/page/10/10?category_ids%5B%5D=2&category_ids%5B%5D=3&category_ids%5B%5D=37").read()
document = BeautifulSoup(html_str)
faculty_list = []
experts_ul_tag = document.find('ul', attrs={'class': 'experts-list'})
for faculty_tag in experts_ul_tag.find_all('li'):
# create empty dictionary to store this faculty member
faculty_dict = {}
# faculty name
h4_tag = faculty_tag.find('h4')
if h4_tag is None:
continue
a_tag = h4_tag.find('a')
faculty_dict['name'] = a_tag.string
# image URL
img_tag = faculty_tag.find('img')
faculty_dict['img_src'] = img_tag['src']
# title
p_tag = faculty_tag.find('p', attrs={'class': 'description'})
faculty_dict['title'] = p_tag.string
# append to list
faculty_list.append(faculty_dict)
faculty_list
--------------------------------------------------------------------------- TypeError Traceback (most recent call last) <ipython-input-85-5d4df53d970e> in <module>() 14 # image URL 15 img_tag = faculty_tag.find('img') ---> 16 faculty_dict['img_src'] = img_tag['src'] 17 # title 18 p_tag = faculty_tag.find('p', attrs={'class': 'description'}) TypeError: 'NoneType' object has no attribute '__getitem__'
ARGH! Another 'NoneType' object has no attribute '__getitem__'! It looks like the problem this time is with the img_tag variable. In particular, if we examine the source code, we find that faculty members without head shots don't even have an <img> tag in their <div>s. So let's add one more thing to fix that---we'll check to see if the <img> tag is present, and only then will we attemt to get its src attribute:
html_str = urllib.urlopen("http://www.journalism.columbia.edu/page/10/10?category_ids%5B%5D=2&category_ids%5B%5D=3&category_ids%5B%5D=37").read()
document = BeautifulSoup(html_str)
faculty_list = []
experts_ul_tag = document.find('ul', attrs={'class': 'experts-list'})
for faculty_tag in experts_ul_tag.find_all('li'):
# create empty dictionary to store this faculty member
faculty_dict = {}
# faculty name
h4_tag = faculty_tag.find('h4')
if h4_tag is None:
continue
a_tag = h4_tag.find('a')
faculty_dict['name'] = a_tag.string
# image URL: if <img> tag found, grab its src. if not, use None
img_tag = faculty_tag.find('img')
if img_tag is None:
faculty_dict['img_src'] = None
else:
faculty_dict['img_src'] = img_tag['src']
# title
p_tag = faculty_tag.find('p', attrs={'class': 'description'})
faculty_dict['title'] = p_tag.string
# append to list
faculty_list.append(faculty_dict)
faculty_list
[{'img_src': None,
'name': u'Adkison, Abbey ',
'title': u'Digital Media Coordinator'},
{'img_src': u'/system/photos/1943/default/Dolores-Barclay.gif?1365711292',
'name': u'Barclay, Dolores ',
'title': u'Adjunct Faculty'},
{'img_src': None, 'name': u'Baum, Geraldine', 'title': u'Adjunct Faculty'},
{'img_src': u'/system/photos/2056/default/EBell_112811.jpg?1322508884',
'name': u'Bell, Emily',
'title': u'Professor of Professional Practice & Director, Tow Center for Digital Journalism'},
{'img_src': u'/system/photos/2057/default/HBenedict_112811.jpg?1322509591',
'name': u'Benedict, Helen ',
'title': u'Professor'},
{'img_src': u'/system/photos/2982/default/Bennet_John.gif?1365697019',
'name': u'Bennet, John ',
'title': u'Adjunct Faculty'},
{'img_src': u'/system/photos/2984/default/Bennett_Rob.gif?1365706134',
'name': u'Bennett, Rob',
'title': u'Adjunct Faculty'},
{'img_src': u'/system/photos/2725/default/Nina-Berman.gif?1365711635',
'name': u'Berman, Nina',
'title': u'Associate Professor'},
{'img_src': None, 'name': u'Blair, Gwenda ', 'title': u'Adjunct Faculty'},
{'img_src': u'/system/photos/2985/default/Blum_David.gif?1365706164',
'name': u'Blum, David ',
'title': u'Adjunct Faculty'},
{'img_src': u'/system/photos/2692/default/GeorgeBodarky.gif?1365714064',
'name': u'Bodarky, George',
'title': u'Adjunct Assistant Professor '},
{'img_src': u'/system/photos/150/default/Walt-Bogdanich.gif?1365714085',
'name': u'Bogdanich, Walt ',
'title': u'Adjunct Faculty'},
{'img_src': u'/system/photos/3055/default/Lennart-Bourin.jpg?1368456160',
'name': u'Bourin, Lennart',
'title': u'Adjunct Faculty'},
{'img_src': u'/system/photos/1912/default/CurtisBrainard.gif?1365714245',
'name': u'Brainard, Curtis ',
'title': u'Staff Writer'},
{'img_src': u'/system/photos/842/default/bruder.jpg?1392672045',
'name': u'Bruder, Jessica',
'title': u'Adjunct Faculty'},
{'img_src': u'/system/photos/864/default/burford.jpg?1392672030',
'name': u'Burford, Melanie ',
'title': u'Adjunct Faculty'},
{'img_src': u'/system/photos/2986/default/Burleigh_Nina.gif?1365706179',
'name': u'Burleigh, Nina ',
'title': u'Adjunct Faculty'},
{'img_src': u'/system/photos/2713/default/HeatherCabot.gif?1365714437',
'name': u'Cabot, Heather',
'title': u'Adjunct Professor'},
{'img_src': u'/system/photos/3203/default/Elena.gif?1375217143',
'name': u'Cabral, Elena ',
'title': u'Adjunct Faculty & Assistant Director, Student Services'},
{'img_src': u'/system/photos/2987/default/Canipe_Chris.gif?1365706198',
'name': u'Canipe, Chris',
'title': None},
{'img_src': u'/system/photos/2988/default/Charnas_Dan.gif?1365706213',
'name': u'Charnas, Dan ',
'title': u'Adjunct Faculty'},
{'img_src': u'/system/photos/3412/default/Cohen_Julie.jpg?1384536342',
'name': u'Cohen, Julie',
'title': u'Adjunct Faculty'},
{'img_src': u'/system/photos/3262/default/Lisa-Cohen.gif?1376423474',
'name': u'Cohen, Lisa R.',
'title': u'Adjunct Faculty'},
{'img_src': u'/system/photos/2989/default/Cohen_Sarah.gif?1365706228',
'name': u'Cohen, Sarah',
'title': u'Adjunct Faculty'},
{'img_src': u'/system/photos/3278/default/Coll-web.gif?1377281425',
'name': u'Coll, Steve',
'title': u'Dean & Henry R. Luce Professor of Journalism'},
{'img_src': u'/system/photos/147/default/AnnCooper2.jpg?1276009818',
'name': u'Cooper, Ann',
'title': u'CBS Professor of Professional Practice in International Journalism'},
{'img_src': u'/system/photos/2990/default/Coronel_Sheila.gif?1365706241',
'name': u'Coronel, Sheila ',
'title': u'Dean of Academic Affairs'},
{'img_src': u'/system/photos/160/default/Unknown-1.jpeg?1378227266',
'name': u'Coyne , Kevin ',
'title': u'Adjunct Faculty'},
{'img_src': u'/system/photos/2993/default/Hockenberry_-Alison-Craiglow.gif?1365706287',
'name': u'Craiglow Hockenberry, Alison',
'title': None},
{'img_src': u'/system/photos/2059/default/JCross_112811.jpg?1322510850',
'name': u'Cross, June ',
'title': u'Professor '},
{'img_src': u'/system/photos/861/default/Brent-Cunningham.gif?1365714937',
'name': u'Cunningham, Brent ',
'title': u'Deputy Editor'},
{'img_src': u'/system/photos/1265/default/ADepalma.jpg?1291223442',
'name': u'DePalma, Anthony',
'title': u'Adjunct Faculty'},
{'img_src': u'/system/photos/1973/default/BruceDeSilva.gif?1365715036',
'name': u'DeSilva, Bruce ',
'title': u'Adjunct Faculty'},
{'img_src': u'/system/photos/3256/default/deitsch_.jpg?1376325514',
'name': u'Deitsch, Richard',
'title': u'Adjunct Faculty'},
{'img_src': u'/system/photos/2060/default/JDinges_112811.jpg?1322511090',
'name': u'Dinges, John',
'title': u'Godfrey Lowell Cabot Professor of Journalism'},
{'img_src': u'/system/photos/3075/default/SDodd_horiz.gif?1369166642',
'name': u'Dodd, Scott',
'title': u'Adjunct Faculty'},
{'img_src': u'/system/photos/1811/default/donahue.jpg?1392672057',
'name': u'Donahue, Kerry ',
'title': u'Adjunct Faculty'},
{'img_src': None, 'name': u'Drew, Christopher ', 'title': u'Adjunct Faculty'},
{'img_src': u'/system/photos/936/default/edsall.jpg?1304373008',
'name': u'Edsall, Thomas B. ',
'title': None},
{'img_src': u'/system/photos/882/default/Epstein.jpg?1280954937',
'name': u'Epstein, Randi Hutter ',
'title': u'Adjunct Faculty '},
{'img_src': None, 'name': u'Evans, Farrell ', 'title': u'Adjunct Faculty'},
{'img_src': u'/system/photos/1977/default/TysonEvans.gif?1365715311',
'name': u'Evans , Tyson ',
'title': u'Adjunct Faculty'},
{'img_src': u'/system/photos/3013/default/Fishman.gif?1365724719',
'name': u'Fishman, Elizabeth Weinreb',
'title': u'Associate Dean for Communications'},
{'img_src': u'/system/photos/3488/default/ford.jpg?1392672068',
'name': u'Ford, Constance Mitchell ',
'title': u'Adjunct Faculty'},
{'img_src': u'/system/photos/839/default/frederick.jpg?1392672079',
'name': u'Frederick, Pamela Platt',
'title': u'Adjunct Faculty'},
{'img_src': u'/system/photos/2061/default/SFreedman_112811.jpg?1322511767',
'name': u'Freedman, Samuel ',
'title': u'Professor'},
{'img_src': None, 'name': u'Freeman, George ', 'title': u'Adjunct Faculty'},
{'img_src': u'/system/photos/2991/default/Freeman_John.gif?1365706256',
'name': u'Freeman, John',
'title': u'Adjunct Faculty'},
{'img_src': u'/system/photos/93/default/HFrench.jpg?1291237303',
'name': u'French, Howard ',
'title': u'Associate Professor'},
{'img_src': u'/system/photos/162/default/Stephen_Fried.gif?1365716551',
'name': u'Fried, Stephen ',
'title': u'Adjunct Faculty'},
{'img_src': u'/system/photos/3119/default/Vanessa.gif?1371498827',
'name': u'Gezari, Vanessa',
'title': None},
{'img_src': None, 'name': u'Gilderman, Greg', 'title': u'Adjunct Faculty'},
{'img_src': u'/system/photos/837/default/SigGissler.gif?1365716632',
'name': u'Gissler, Sig',
'title': u'Administrator'},
{'img_src': u'/system/photos/113/default/TGitlin.jpg?1291237356',
'name': u'Gitlin, Todd',
'title': u'Professor & Chair, Ph.D. Program'},
{'img_src': None, 'name': u'Giudice, Barbara ', 'title': u'Adjunct Faculty'},
{'img_src': u'/system/photos/836/default/MartyGoldensohn.gif?1365716789',
'name': u'Goldensohn, Marty',
'title': u'Adjunct Faculty'},
{'img_src': u'/system/photos/86/default/AGoldman.jpg?1291237401',
'name': u'Goldman, Ari ',
'title': u'Professor'},
{'img_src': None, 'name': u'Goldstein, Jacob', 'title': u'Adjunct Professor'},
{'img_src': u'/system/photos/88/default/WGrueskin.jpg?1291236298',
'name': u'Grueskin, Bill',
'title': u'Professor of Professional Practice '},
{'img_src': u'/system/photos/1512/default/AHaburchak.gif?1365716878',
'name': u'Haburchak, Alan',
'title': u'Adjunct Faculty'},
{'img_src': u'/system/photos/2992/default/Hajdu_David.gif?1365706270',
'name': u'Hajdu, David ',
'title': u'Associate Professor '},
{'img_src': None, 'name': u'Hall, Stephen', 'title': u'Adjunct Faculty'},
{'img_src': u'/system/photos/97/default/LynNell-faculty.jpg?1368455738',
'name': u'Hancock, LynNell',
'title': u'H. Gordon Garbedian Professor of Journalism & Director, Spencer Fellowship Program'},
{'img_src': u'/system/photos/3545/default/hansen.jpg?1392670367',
'name': u'Hansen, Mark',
'title': u'Director, David and Helen Gurley Brown Institute for Media Innovation & Professor of Journalism '},
{'img_src': None, 'name': u'Harris, Mark', 'title': u'Adjunct Faculty'},
{'img_src': u'/system/photos/3210/default/Julie.gif?1375217224',
'name': u'Hartenstein, Julie',
'title': u'Associate Dean'},
{'img_src': u'/system/photos/1530/default/LarryHeinzerling.gif?1365717071',
'name': u'Heinzerling, Larry',
'title': u'Adjunct Faculty'},
{'img_src': u'/system/photos/154/default/TomHerman.gif?1365718880',
'name': u'Herman, Tom ',
'title': u'Adjunct Faculty'},
{'img_src': None, 'name': u'Hickey, Neil ', 'title': u'Adjunct Faculty'},
{'img_src': u'/system/photos/3059/default/Lars-head-shot-v2.jpg?1368463497',
'name': u'Hoel, Lars ',
'title': None},
{'img_src': u'/system/photos/3529/default/hogan.jpg?1392672092',
'name': u'Hogan, Pamela',
'title': u'Adjunct Faculty'},
{'img_src': u'/system/photos/155/default/Marguerite_Holloway2.jpg?1276019659',
'name': u'Holloway, Marguerite ',
'title': u'Associate Professor & Director, Science and Environmental Journalism'},
{'img_src': u'/system/photos/2994/default/Hoyt_-Mike.gif?1365706301',
'name': u'Hoyt, Michael ',
'title': u'Adjunct Faculty'},
{'img_src': u'/system/photos/2064/default/SIsaacs_112811.jpg?1322512995',
'name': u'Isaacs, Stephen',
'title': u'Professor Emeritus of Journalism'},
{'img_src': u'/system/photos/101/default/RJohn.jpg?1291236478',
'name': u'John, Richard R. ',
'title': u'Professor '},
{'img_src': None,
'name': u'Jones, Matthew L. ',
'title': u'Instructor, The Lede Program'},
{'img_src': None, 'name': u'Kalita, S. Mitra ', 'title': u'Adjunct Faculty '},
{'img_src': None, 'name': u'Kann, Peter R. ', 'title': u'Adjunct Faculty'},
{'img_src': u'/system/photos/833/default/kantrowitz.jpg?1392672104',
'name': u'Kantrowitz, Barbara',
'title': u'Adjunct Faculty & Associate Director, Continuing Education'},
{'img_src': u'/system/photos/2995/default/Karle_-Stuart.gif?1365706445',
'name': u'Karle, Stuart',
'title': u'Adjunct Faculty; William J. Brennan Jr. Visiting Professor of First Amendment Issues'},
{'img_src': u'/system/photos/858/default/RickKArr.gif?1365717241',
'name': u'Karr, Rick',
'title': u'Adjunct Faculty'},
{'img_src': u'/system/photos/158/default/ThomasKent.gif?1365717319',
'name': u'Kent, Thomas ',
'title': u'Adjunct Faculty'},
{'img_src': u'/system/photos/1259/default/DKlatell.jpg?1291217138',
'name': u'Klatell, David',
'title': u'Professor of Professional Practice & Chair, International Studies'},
{'img_src': None, 'name': u'Klein, Adam', 'title': u'Adjunct Professor'},
{'img_src': u'/system/photos/3056/default/Kim-Kleman-1.jpg?1368463019',
'name': u'Kleman, Kim ',
'title': u'Adjunct Faculty'},
{'img_src': u'/system/photos/832/default/knee.jpg?1392672119',
'name': u'Knee, Jonathan',
'title': u'Adjunct Professor'},
{'img_src': None, 'name': u'Konner, Joan', 'title': u'Dean Emerita'},
{'img_src': u'/system/photos/2507/default/MKottler.jpg?1336577232',
'name': u'Kottler, Mark',
'title': u'Adjunct Faculty'},
{'img_src': u'/system/photos/857/default/landis.jpg?1392672129',
'name': u'Landis, Peter',
'title': u'Adjunct Faculty'},
{'img_src': u'/system/photos/2650/default/DLee_New.jpg?1345145608',
'name': u'Lee, Deborah ',
'title': u'Adjunct Faculty'},
{'img_src': u'/system/photos/156/default/haupt.jpg?1392672140',
'name': u'Lehmann-Haupt, Christopher ',
'title': u'Adjunct Faculty'},
{'img_src': u'/system/photos/2065/default/NLemann_112811.jpg?1322513292',
'name': u'Lemann, Nicholas',
'title': u'Joseph Pulitzer II and Edith Pulitzer Moore Professor of Journalism; Dean Emeritus'},
{'img_src': None, 'name': u'Levenson, Jacob ', 'title': u'Adjunct Faculty'},
{'img_src': u'/system/photos/157/default/SethLipsky.gif?1365717822',
'name': u'Lipsky, Seth ',
'title': u'Adjunct Faculty'},
{'img_src': u'/system/photos/2066/default/RLipton_112811.jpg?1322513465',
'name': u'Lipton, Rhoda ',
'title': u'Senior Lecturer in Discipline'},
{'img_src': None, 'name': u'Lombardi, Kristen', 'title': u'Adjunct Faculty'},
{'img_src': u'/system/photos/1391/default/TamiLuhby.gif?1365717895',
'name': u'Luhby, Tami',
'title': u'Adjunct Faculty'},
{'img_src': u'/system/photos/3263/default/Tony-Maciulius.gif?1376424088',
'name': u'Maciulis, Tony',
'title': u'Adjunct Faculty'},
{'img_src': u'/system/photos/2996/default/Maharidge_-Dale.gif?1365706460',
'name': u'Maharidge, Dale ',
'title': u'Professor '},
{'img_src': u'/system/photos/2690/default/TomMason.gif?1365718118',
'name': u'Mason, Tom',
'title': None},
{'img_src': u'/system/photos/2997/default/Matloff_-Judith.gif?1365706478',
'name': u'Matloff, Judith ',
'title': u'Adjunct faculty'},
{'img_src': None, 'name': u'Maytal, Itai', 'title': u'Adjunct Faculty'},
{'img_src': None, 'name': u'McCormick, David ', 'title': u'Adjunct Faculty'},
{'img_src': None, 'name': u'McCray, Melvin', 'title': u'Adjunct Faculty'},
{'img_src': u'/system/photos/2998/default/McDonald_-Erica.gif?1365706494',
'name': u'McDonald, Erica',
'title': None},
{'img_src': u'/system/photos/2068/default/SMcGregor_112811.jpg?1322514173',
'name': u'McGregor, Susan E.',
'title': u'Assistant Professor & Assistant Director, Tow Center for Digital Journalism'},
{'img_src': None, 'name': u'McMasters, Kelly', 'title': u'Adjunct Faculty'},
{'img_src': None, 'name': u'Mencher, Melvin', 'title': u'Professor Emeritus'},
{'img_src': u'/system/photos/2999/default/Merchant_-Preston.gif?1365706509',
'name': u'Merchant, Preston',
'title': None},
{'img_src': None,
'name': u'Miller , Stephen C.',
'title': u'Adjunct Faculty'},
{'img_src': u'/system/photos/3000/default/Mintz_-Jim.gif?1365706529',
'name': u'Mintz, James',
'title': u'Adjunct Faculty'},
{'img_src': u'/system/photos/2069/default/SNasar_112811.jpg?1322514324',
'name': u'Nasar, Sylvia ',
'title': u'John S. and James L. Knight Professor of Business Journalism'},
{'img_src': u'/system/photos/2070/default/VNavasky_112811.jpg?1322514777',
'name': u'Navasky, Victor ',
'title': u'George T. Delacorte Professor in Magazine Journalism; Director, Delacorte Center for Magazine Journalism; Chair, Columbia Journalism Review '},
{'img_src': None, 'name': u'Newman, Maria', 'title': u'Adjunct Faculty'},
{'img_src': u'/system/photos/2714/default/nisenholtz.jpg?1392672182',
'name': u'Nisenholtz, Martin',
'title': u'Adjunct Professor '},
{'img_src': u'/system/photos/854/default/nocera.jpg?1392672191',
'name': u'Nocera, Joseph',
'title': u'Adjunct Faculty'},
{'img_src': u'/system/photos/2659/default/RNorton.jpg?1345495471',
'name': u'Norton, Rob',
'title': u'Adjunct Faculty'},
{'img_src': u'/system/photos/3288/default/habibanosheen2.jpg?1378324386',
'name': u'Nosheen, Habiba',
'title': u'Adjunct Professor'},
{'img_src': u'/system/photos/827/default/AmyNutt.gif?1365718410',
'name': u'Nutt, Amy',
'title': u'Adjunct Faculty'},
{'img_src': u'/system/photos/3074/default/Bridget-O_Brian-headshot.gif?1369166593',
'name': u"O'Brian, Bridget ",
'title': None},
{'img_src': u'/system/photos/1993/default/CharlesOrnstein.gif?1365718296',
'name': u'Ornstein, Charles',
'title': u'Adjunct Faculty'},
{'img_src': u'/system/photos/826/default/padawer.jpg?1392672201',
'name': u'Padawer , Ruth',
'title': u'Adjunct Professor'},
{'img_src': u'/system/photos/2073/default/SPadwe_112811.jpg?1322516163',
'name': u'Padwe, Sandy ',
'title': u'Special Lecturer'},
{'img_src': None, 'name': u'Parker, Diantha', 'title': u'Adjunct Faculty'},
{'img_src': None,
'name': u'Parrish, Adam ',
'title': u'Instructor, The Lede Program'},
{'img_src': u'/system/photos/1914/default/Patel_Headshot2.jpg?1319040513',
'name': u'Patel, Samir S.',
'title': u'Adjunct Faculty'},
{'img_src': u'/system/photos/3001/default/Perlman_-Merrill.gif?1365706552',
'name': u'Perlman, Merrill',
'title': u'Adjunct Faculty'},
{'img_src': u'/system/photos/852/default/pool-eckert.jpg?1392672210',
'name': u'Pool-Eckert, Marquita',
'title': u'Adjunct Faculty'},
{'img_src': None, 'name': u'Quinn, T.J. ', 'title': u'Adjunct Faculty'},
{'img_src': None, 'name': u'Rate, Betsy', 'title': u'Adjunct Faculty'},
{'img_src': None, 'name': u'Richardson, Lynda ', 'title': u'Adjunct Faculty'},
{'img_src': u'/system/photos/824/default/richmn.jpg?1392672219',
'name': u'Richman, Joe',
'title': u'Adjunct Faculty'},
{'img_src': u'/system/photos/3377/default/robbins.jpg?1392672228',
'name': u'Robbins, Ed',
'title': u'Adjunct Faculty'},
{'img_src': None, 'name': u'Roberts, Fletcher', 'title': u'Adjunct Faculty'},
{'img_src': u'/system/photos/3002/default/Rubinstein_-Julian.gif?1365706572',
'name': u'Rubinstein, Julian',
'title': u'Web Editor'},
{'img_src': u'/system/photos/851/default/Sacha.jpg?1280952529',
'name': u'Sacha, Bob ',
'title': u'Adjunct Faculty'},
{'img_src': u'/system/photos/823/default/RichSchapiro.gif?1365718608',
'name': u'Schapiro, Rich',
'title': u'Adjunct Faculty'},
{'img_src': None, 'name': u'Schatz, Robin', 'title': u'Adjunct Faculty'},
{'img_src': u'/system/photos/1913/default/BJSchechter.gif?1365718488',
'name': u'Schecter, B.J.',
'title': u'Adjunct Faculty'},
{'img_src': u'/system/photos/3584/default/HilkeSchellmann_final.jpg?1395348920',
'name': u'Schellmann, Hilke',
'title': u'Adjunct Faculty'},
{'img_src': u'/system/photos/3432/default/schoen.jpg?1392672237',
'name': u'Schoen, John',
'title': u'Adjunct Faculty'},
{'img_src': None,
'name': u'Schoonmaker, Mary Ellen',
'title': u'Adjunct Faculty'},
{'img_src': u'/system/photos/2075/default/MSchudson_112811.jpg?1322517107',
'name': u'Schudson, Michael ',
'title': u'Professor '},
{'img_src': u'/system/photos/2076/default/ESchumacher_112811.jpg?1322517858',
'name': u'Schumacher-Matos, Ed ',
'title': u'Adjunct Faculty'},
{'img_src': None, 'name': u'Schwartz, Jack ', 'title': None},
{'img_src': u'/system/photos/872/default/Seave.jpg?1280954557',
'name': u'Seave, Ava ',
'title': u'Adjunct Faculty'},
{'img_src': u'/system/photos/849/default/Seidman.gif?1365718701',
'name': u'Seideman, David',
'title': u'Adjunct Faculty'},
{'img_src': None,
'name': u'Shanor, Donald',
'title': u'G. L. Cabot Professor Emeritus '},
{'img_src': u'/system/photos/3003/default/Shapiro_-Bruce.gif?1365706590',
'name': u'Shapiro, Bruce',
'title': u'Executive Director'},
{'img_src': u'/system/photos/2077/default/MShapiro_112811.jpg?1322518042',
'name': u'Shapiro, Michael ',
'title': u'Professor '},
{'img_src': u'/system/photos/2682/default/ahmed-shihab-eldin.gif?1365717716',
'name': u'Shihab-Eldin, Ahmed ',
'title': u'Adjunct Assistant Professor '},
{'img_src': u'/system/photos/3235/default/Siegel_-Lloyd-2012.jpg?1375710566',
'name': u'Siegel, Lloyd',
'title': u'Adjunct Faculty'},
{'img_src': u'/system/photos/871/default/singer.jpg?1392672245',
'name': u'Singer, Amy ',
'title': u'Adjunct Faculty'},
{'img_src': u'/system/photos/1953/default/MariaSliwa.gif?1365717479',
'name': u'Sliwa, Maria',
'title': u'Adjunct Faculty'},
{'img_src': u'/system/photos/3004/default/Solomon_-Alisa.gif?1365706611',
'name': u'Solomon, Alisa',
'title': u'Professor & Director, Arts Concentration, M.A. Program'},
{'img_src': u'/system/photos/3664/default/jonathan-soma.jpg?1399473825',
'name': u'Soma, Jonathan',
'title': u'Instructor, The Lede Program'},
{'img_src': u'/system/photos/3204/default/Ernie.gif?1375217153',
'name': u'Sotomayor, Ernest',
'title': u'Dean of Student Affairs'},
{'img_src': u'/system/photos/848/default/PaulaSpan.gif?1365717399',
'name': u'Span, Paula ',
'title': u'Adjunct Professor'},
{'img_src': u'/system/photos/2079/default/SSreenavisan_112811.jpg?1322518253',
'name': u'Sreenivasan , Sree ',
'title': u'Adjunct Faculty'},
{'img_src': u'/system/photos/3236/default/Karen-Stabiner.jpg?1375717512',
'name': u'Stabiner, Karen',
'title': u'Adjunct Faculty'},
{'img_src': u'/system/photos/2080/default/JStewart_112811.jpg?1322518368',
'name': u'Stewart, James',
'title': u'Bloomberg Professor of Business Journalism'},
{'img_src': u'/system/photos/82/default/Stille.gif?1365718788',
'name': u'Stille, Alexander',
'title': u'San Paolo Professor of International Journalism'},
{'img_src': u'/system/photos/3523/default/stivers.jpg?1392672253',
'name': u'Stivers, Cyndi',
'title': u'Adjunct Faculty'},
{'img_src': u'/system/photos/3005/default/Subramanian_-Sushma.gif?1365706634',
'name': u'Subramanian, Sushma',
'title': u'Adjunct Faculty'},
{'img_src': u'/system/photos/3434/default/Mike_Sullivan.jpg?1386103502',
'name': u'Sullivan, Michael',
'title': u'Adjunct Faculty'},
{'img_src': u'/system/photos/847/default/Surowicz.jpg?1280952446',
'name': u'Surowicz, Simon',
'title': None},
{'img_src': u'/system/photos/3006/default/Tamman_-Maurice.gif?1365706648',
'name': u'Tamman, Maurice',
'title': u'Adjunct Faculty'},
{'img_src': None,
'name': u'Tenen, Dennis',
'title': u'Instructor, The Lede Program'},
{'img_src': u'/system/photos/105/default/topping.jpg?1392672489',
'name': u'Topping, Seymour ',
'title': u'San Paolo Professor of International Journalism Emeritus'},
{'img_src': u'/system/photos/3057/default/Dody.jpg?1368463129',
'name': u'Tsiantar, Dody ',
'title': u'Adjunct Faculty'},
{'img_src': u'/system/photos/2082/default/DLinhTu_112811.jpg?1322583281',
'name': u'Tu, Duy Linh',
'title': u'Assistant Professor of Professional Practice & Director, Digital Media Program '},
{'img_src': u'/system/photos/125/default/Andie_Tucher2.jpg?1275665800',
'name': u'Tucher, Andie ',
'title': u'Associate Professor; Director, Ph.D. Program'},
{'img_src': u'/system/photos/3188/default/Mike-Ventura.gif?1374078031',
'name': u'Ventura, Michael',
'title': u'Adjunct Faculty'},
{'img_src': u'/system/photos/3007/default/Wald_-Jonathan.gif?1365706666',
'name': u'Wald, Jonathan',
'title': u'Adjunt Faculty'},
{'img_src': u'/system/photos/126/default/Richard_Wald2.jpg?1275665983',
'name': u'Wald, Richard',
'title': u'Fred W. Friendly Professor of Professional Practice in Media and Society'},
{'img_src': u'/system/photos/1261/default/wayne.jpg?1392672262',
'name': u'Wayne, Leslie',
'title': u'Adjunct Faculty'},
{'img_src': u'/system/photos/127/default/JWeiner.jpg?1291237982',
'name': u'Weiner, Jonathan ',
'title': u'Maxwell M. Geffen Professor of Medical and Scientific Journalism '},
{'img_src': u'/system/photos/2269/default/weiss.jpg?1392672270',
'name': u'Weiss, Gary',
'title': u'Adjunct Faculty'},
{'img_src': u'/system/photos/819/default/welby.jpg?1392672278',
'name': u'Welby, Julianne ',
'title': u'Adjunct Faculty'},
{'img_src': u'/system/photos/128/default/Betsy_West2.jpg?1275668385',
'name': u'West, Betsy ',
'title': u'Associate Professor of Professional Practice'},
{'img_src': u'/system/photos/3008/default/Wheatley_-Bill.gif?1365706683',
'name': u'Wheatley, Jr., William',
'title': u'Adjunct Faculty'},
{'img_src': u'/system/photos/3665/default/chris-wiggins.jpg?1399473834',
'name': u'Wiggins, Chris',
'title': u'Instructor, The Lede Program'},
{'img_src': u'/system/photos/3009/default/Williams_-Josh---high-res.gif?1365706700',
'name': u'Williams, Josh',
'title': u'Adjunct Faculty'},
{'img_src': None, 'name': u'Wilson, Duff', 'title': u'Adjunct Faculty'},
{'img_src': None, 'name': u'Wolk, Joshua', 'title': u'Adjunct Faculty'},
{'img_src': u'/system/photos/3010/default/woodward.jpg?1392672287',
'name': u'Woodward, Tali ',
'title': u'Adjunct Faculty & Director, M.A. Program'},
{'img_src': None,
'name': u'Yu, Frederick T C.',
'title': u'CBS Professor Emeritus International Journalism'},
{'img_src': None, 'name': u'Zucker, John', 'title': u'Adjunct Faculty'},
{'img_src': u'/system/photos/3058/default/zuckerman.jpg?1392672295',
'name': u'Zuckerman, Jocelyn Craugh ',
'title': u'Adjunct Faculty'}]
It worked! So good. Now we can do fun stuff with the data, like making a pandas data frame and seeing how many are listed as "Adjunct Faculty":
import pandas as pd
faculty_frame = pd.DataFrame(faculty_list)
faculty_frame[faculty_frame["title"]=="Adjunct Faculty"]
| img_src | name | title | |
|---|---|---|---|
| 1 | /system/photos/1943/default/Dolores-Barclay.gi... | Barclay, Dolores | Adjunct Faculty |
| 2 | None | Baum, Geraldine | Adjunct Faculty |
| 5 | /system/photos/2982/default/Bennet_John.gif?13... | Bennet, John | Adjunct Faculty |
| 6 | /system/photos/2984/default/Bennett_Rob.gif?13... | Bennett, Rob | Adjunct Faculty |
| 8 | None | Blair, Gwenda | Adjunct Faculty |
| 9 | /system/photos/2985/default/Blum_David.gif?136... | Blum, David | Adjunct Faculty |
| 11 | /system/photos/150/default/Walt-Bogdanich.gif?... | Bogdanich, Walt | Adjunct Faculty |
| 12 | /system/photos/3055/default/Lennart-Bourin.jpg... | Bourin, Lennart | Adjunct Faculty |
| 14 | /system/photos/842/default/bruder.jpg?1392672045 | Bruder, Jessica | Adjunct Faculty |
| 15 | /system/photos/864/default/burford.jpg?1392672030 | Burford, Melanie | Adjunct Faculty |
| 16 | /system/photos/2986/default/Burleigh_Nina.gif?... | Burleigh, Nina | Adjunct Faculty |
| 20 | /system/photos/2988/default/Charnas_Dan.gif?13... | Charnas, Dan | Adjunct Faculty |
| 21 | /system/photos/3412/default/Cohen_Julie.jpg?13... | Cohen, Julie | Adjunct Faculty |
| 22 | /system/photos/3262/default/Lisa-Cohen.gif?137... | Cohen, Lisa R. | Adjunct Faculty |
| 23 | /system/photos/2989/default/Cohen_Sarah.gif?13... | Cohen, Sarah | Adjunct Faculty |
| 27 | /system/photos/160/default/Unknown-1.jpeg?1378... | Coyne , Kevin | Adjunct Faculty |
| 31 | /system/photos/1265/default/ADepalma.jpg?12912... | DePalma, Anthony | Adjunct Faculty |
| 32 | /system/photos/1973/default/BruceDeSilva.gif?1... | DeSilva, Bruce | Adjunct Faculty |
| 33 | /system/photos/3256/default/deitsch_.jpg?13763... | Deitsch, Richard | Adjunct Faculty |
| 35 | /system/photos/3075/default/SDodd_horiz.gif?13... | Dodd, Scott | Adjunct Faculty |
| 36 | /system/photos/1811/default/donahue.jpg?139267... | Donahue, Kerry | Adjunct Faculty |
| 37 | None | Drew, Christopher | Adjunct Faculty |
| 40 | None | Evans, Farrell | Adjunct Faculty |
| 41 | /system/photos/1977/default/TysonEvans.gif?136... | Evans , Tyson | Adjunct Faculty |
| 43 | /system/photos/3488/default/ford.jpg?1392672068 | Ford, Constance Mitchell | Adjunct Faculty |
| 44 | /system/photos/839/default/frederick.jpg?13926... | Frederick, Pamela Platt | Adjunct Faculty |
| 46 | None | Freeman, George | Adjunct Faculty |
| 47 | /system/photos/2991/default/Freeman_John.gif?1... | Freeman, John | Adjunct Faculty |
| 49 | /system/photos/162/default/Stephen_Fried.gif?1... | Fried, Stephen | Adjunct Faculty |
| 51 | None | Gilderman, Greg | Adjunct Faculty |
| ... | ... | ... | ... |
| 135 | /system/photos/851/default/Sacha.jpg?1280952529 | Sacha, Bob | Adjunct Faculty |
| 136 | /system/photos/823/default/RichSchapiro.gif?13... | Schapiro, Rich | Adjunct Faculty |
| 137 | None | Schatz, Robin | Adjunct Faculty |
| 138 | /system/photos/1913/default/BJSchechter.gif?13... | Schecter, B.J. | Adjunct Faculty |
| 139 | /system/photos/3584/default/HilkeSchellmann_fi... | Schellmann, Hilke | Adjunct Faculty |
| 140 | /system/photos/3432/default/schoen.jpg?1392672237 | Schoen, John | Adjunct Faculty |
| 141 | None | Schoonmaker, Mary Ellen | Adjunct Faculty |
| 143 | /system/photos/2076/default/ESchumacher_112811... | Schumacher-Matos, Ed | Adjunct Faculty |
| 145 | /system/photos/872/default/Seave.jpg?1280954557 | Seave, Ava | Adjunct Faculty |
| 146 | /system/photos/849/default/Seidman.gif?1365718701 | Seideman, David | Adjunct Faculty |
| 151 | /system/photos/3235/default/Siegel_-Lloyd-2012... | Siegel, Lloyd | Adjunct Faculty |
| 152 | /system/photos/871/default/singer.jpg?1392672245 | Singer, Amy | Adjunct Faculty |
| 153 | /system/photos/1953/default/MariaSliwa.gif?136... | Sliwa, Maria | Adjunct Faculty |
| 158 | /system/photos/2079/default/SSreenavisan_11281... | Sreenivasan , Sree | Adjunct Faculty |
| 159 | /system/photos/3236/default/Karen-Stabiner.jpg... | Stabiner, Karen | Adjunct Faculty |
| 162 | /system/photos/3523/default/stivers.jpg?139267... | Stivers, Cyndi | Adjunct Faculty |
| 163 | /system/photos/3005/default/Subramanian_-Sushm... | Subramanian, Sushma | Adjunct Faculty |
| 164 | /system/photos/3434/default/Mike_Sullivan.jpg?... | Sullivan, Michael | Adjunct Faculty |
| 166 | /system/photos/3006/default/Tamman_-Maurice.gi... | Tamman, Maurice | Adjunct Faculty |
| 169 | /system/photos/3057/default/Dody.jpg?1368463129 | Tsiantar, Dody | Adjunct Faculty |
| 172 | /system/photos/3188/default/Mike-Ventura.gif?1... | Ventura, Michael | Adjunct Faculty |
| 175 | /system/photos/1261/default/wayne.jpg?1392672262 | Wayne, Leslie | Adjunct Faculty |
| 177 | /system/photos/2269/default/weiss.jpg?1392672270 | Weiss, Gary | Adjunct Faculty |
| 178 | /system/photos/819/default/welby.jpg | Welby, Julianne | Adjunct Faculty |
| 180 | /system/photos/3008/default/Wheatley_-Bill.gif... | Wheatley, Jr., William | Adjunct Faculty |
| 182 | /system/photos/3009/default/Williams_-Josh---h... | Williams, Josh | Adjunct Faculty |
| 183 | None | Wilson, Duff | Adjunct Faculty |
| 184 | None | Wolk, Joshua | Adjunct Faculty |
| 187 | None | Zucker, John | Adjunct Faculty |
| 188 | /system/photos/3058/default/zuckerman.jpg?1392... | Zuckerman, Jocelyn Craugh | Adjunct Faculty |
104 rows × 3 columns
XML¶
XML (eXtensible Markup Language) is a markup language very much like HTML. Here's what XML looks like :
<?xml version="1.0" encoding="utf-8"?>
<feed xmlns="http://www.w3.org/2005/Atom">
<title>Example Feed</title>
<subtitle>A subtitle.</subtitle>
<link href="http://example.org/feed/" rel="self" />
<link href="http://example.org/" />
<id>urn:uuid:60a76c80-d399-11d9-b91C-0003939e0af6</id>
<updated>2003-12-13T18:30:02Z</updated>
<entry>
<title>Atom-Powered Robots Run Amok</title>
<link href="http://example.org/2003/12/13/atom03" />
<link rel="alternate" type="text/html" href="http://example.org/2003/12/13/atom03.html"/>
<link rel="edit" href="http://example.org/2003/12/13/atom03/edit"/>
<id>urn:uuid:1225c695-cfb8-4ebb-aaaa-80da344efa6a</id>
<updated>2003-12-13T18:30:02Z</updated>
<summary>Some text.</summary>
<content type="xhtml">
<div xmlns="http://www.w3.org/1999/xhtml">
<p>This is the entry content.</p>
</div>
</content>
<author>
<name>John Doe</name>
<email>johndoe@example.com</email>
</author>
</entry>
</feed>
As you can see, XML looks a lot like HTML: tags, with attributes and contents, exist in a hierarchical relationship with other tags. The main difference is that in XML, there isn't a pre-defined list of "valid" tag names---when you create a document, you can use whatever tag and attribute names you want. As you can see in the example above, there are tags called feed and entry that aren't a part of the HTML standard, but are valid XML.
The second important difference between XML and HTML is that in XML, all tags must consist of both an opening tag AND a closing tag. HTML doesn't have this restriction (as we saw with <img> tags in the HTML examples above). Also, in general, tools that work with XML are much more strict about syntax than tools that work with HTML. Browsers tend to be very forgiving of errors in HTML, but will immediately reject XML that isn't well-formed.
XML documents generally conform to a "standard" or "format,"---that is, a pre-defined list of tag names and attribute names and rules for which tags can have which attributes and which tags can contain which other tags. For example, the document in the above is in the Atom XML format, which you can find out more about here. XML standards also give you some idea of what the document means---a consistent mapping between the document's structure and its semantics.
In sum: XML documents conform to standards, they must be syntactically valid, and they have agreed-upon semantics. For these reasons, XML documents are considered to be much more friendly for computers to read than HTML documents.
CLEVER PEOPLE NOTE: XML and HTML work similarly enough, and XML documents can have standards, so why not just make an XML standard that defines all of the tags and attributes in HTML, and have the best of both worlds? It's been tried before, and there are several drawbacks, enumerated here, but mostly having to do with backwards compatibility.
Dealing with XML data¶
Now, you can parse XML data with Beautiful Soup (with one important caveat). But one of the benefits of data in XML is that there are many pre-existing libraries for Python that are purpose-built for working with data in whichever XML standard. These libraries will save you the effort of having to figure out how documents in that particular standard are put together.
There are a truly bewildering number of XML standards, each devised for more or less domain-specific tasks. (There is even a truly bewildering number of XML standards for writing documents that define XML standards). Listed below are a few standards of interest to journalists, along with links to Python libraries for dealing with documents using those standards:
- Keyhole Markup Language (KML), used for geographic data: fastkml
- Scalable Vector Graphics (SVG), used for images and drawings: pySVG
- SOAP, used for some web services: pysimplesoap
- Atom, a set of standards used for web publishing and services: feedparser. (The
feedparserlibrary also helps to parse all manner of other web syndication formats.)
An example: RSS feeds¶
One of the first tasks many students set themselves to after learning about web scraping is to scrape the front page of the New York Times. DON'T DO THIS if you can avoid it. You're inviting disaster, as the NYTimes is free at any moment to change the way their HTML is structured, and your scraper will break. Instead, try using the New York Times RSS feed!
RSS is a format that many websites use to publish their articles in computer-readable formats. (RSS support used to be all the rage back in the Internet days, and fewer sites now support it than used to, and some web sites---like the New York Times---support it but don't advertise that fact.) It's an XML format. Here's a link to the New York Times RSS feed for their front-page articles:
http://rss.nytimes.com/services/xml/rss/nyt/HomePage.xml
Click on that link, and you'll see a big mess of XML that doesn't make any sense. We're going to use the feedparser library mentioned above to parse this RSS and get back a list of all of the article titles. The feedparser library essentially takes a big ball of RSS XML and turns it into a Python data structure (to be specific, a list of dictionaries, where each dictionary represents an article in the feed).
First, check to see if you have feedparser installed.
import feedparser
If you get ImportError: No module named feedparser, try running this line (this will work ONLY on your AWS instances):
!sudo pip install feedparser
Password:
Otherwise, you can use your pip skills to install feedparser however you'd like.
Once you have feedparser installed, we can use it to read in a remote RSS file:
import feedparser
feed = feedparser.parse("http://rss.nytimes.com/services/xml/rss/nyt/HomePage.xml")
print type(feed.entries)
<type 'list'>
The feedparser.parse function returns a feedparser object, which has an attribute entries that is a list of articles in the feed. Let's take a look at one of them:
feed.entries[0]
{'author': u'By JACK HEALY',
'author_detail': {'name': u'By JACK HEALY'},
'authors': [{}],
'guidislink': False,
'id': u'http://www.nytimes.com/2014/06/24/us/Tom-Tancredos-Colorado-Governor-Puts-His-Party-on-Alert-.html',
'link': u'http://rss.nytimes.com/c/34625/f/640350/s/3bcb5250/sc/7/l/0L0Snytimes0N0C20A140C0A60C240Cus0CTom0ETancredos0EColorado0EGovernor0EPuts0EHis0EParty0Eon0EAlert0E0Bhtml0Dpartner0Frss0Gemc0Frss/story01.htm',
'links': [{'href': u'http://www.nytimes.com/2014/06/24/us/Tom-Tancredos-Colorado-Governor-Puts-His-Party-on-Alert-.html?partner=rss&emc=rss',
'rel': u'standout',
'type': u'text/html'},
{'href': u'http://rss.nytimes.com/c/34625/f/640350/s/3bcb5250/sc/7/l/0L0Snytimes0N0C20A140C0A60C240Cus0CTom0ETancredos0EColorado0EGovernor0EPuts0EHis0EParty0Eon0EAlert0E0Bhtml0Dpartner0Frss0Gemc0Frss/story01.htm',
'rel': u'alternate',
'type': u'text/html'}],
'media_content': [{'height': u'151',
'lang': u'',
'url': u'http://graphics8.nytimes.com/images/2014/06/24/us/TANCREDO1/TANCREDO1-moth.jpg',
'width': u'151'}],
'media_credit': {'scheme': u'urn:ebu'},
'media_description': u'A volunteer campaigned on a bridge in\xa0Littleton, Colo.',
'published': u'Mon, 23 Jun 2014 17:09:14 GMT',
'published_parsed': time.struct_time(tm_year=2014, tm_mon=6, tm_mday=23, tm_hour=17, tm_min=9, tm_sec=14, tm_wday=0, tm_yday=174, tm_isdst=0),
'summary': u'Some Republicans in Colorado say the views of Mr. Tancredo, a former congressman, could energize the state\u2019s Democrats while alienating moderate Republicans and unaffiliated voters.<img border="0" height="1" src="http://rss.nytimes.com/c/34625/f/640350/s/3bcb5250/sc/7/mf.gif" width="1" /><br clear="all" /><br /><br /><a href="http://da.feedsportal.com/r/199108753875/u/57/f/640350/c/34625/s/3bcb5250/sc/7/rc/1/rc.htm" rel="nofollow"><img border="0" src="http://da.feedsportal.com/r/199108753875/u/57/f/640350/c/34625/s/3bcb5250/sc/7/rc/1/rc.img" /></a><br /><a href="http://da.feedsportal.com/r/199108753875/u/57/f/640350/c/34625/s/3bcb5250/sc/7/rc/2/rc.htm" rel="nofollow"><img border="0" src="http://da.feedsportal.com/r/199108753875/u/57/f/640350/c/34625/s/3bcb5250/sc/7/rc/2/rc.img" /></a><br /><a href="http://da.feedsportal.com/r/199108753875/u/57/f/640350/c/34625/s/3bcb5250/sc/7/rc/3/rc.htm" rel="nofollow"><img border="0" src="http://da.feedsportal.com/r/199108753875/u/57/f/640350/c/34625/s/3bcb5250/sc/7/rc/3/rc.img" /></a><br /><br /><a href="http://da.feedsportal.com/r/199108753875/u/57/f/640350/c/34625/s/3bcb5250/sc/7/a2.htm"><img border="0" src="http://da.feedsportal.com/r/199108753875/u/57/f/640350/c/34625/s/3bcb5250/sc/7/a2.img" /></a><img border="0" height="1" src="http://pi.feedsportal.com/r/199108753875/u/57/f/640350/c/34625/s/3bcb5250/sc/7/a2t.img" width="1" />',
'summary_detail': {'base': u'http://rss.nytimes.com/services/xml/rss/nyt/HomePage.xml',
'language': None,
'type': u'text/html',
'value': u'Some Republicans in Colorado say the views of Mr. Tancredo, a former congressman, could energize the state\u2019s Democrats while alienating moderate Republicans and unaffiliated voters.<img border="0" height="1" src="http://rss.nytimes.com/c/34625/f/640350/s/3bcb5250/sc/7/mf.gif" width="1" /><br clear="all" /><br /><br /><a href="http://da.feedsportal.com/r/199108753875/u/57/f/640350/c/34625/s/3bcb5250/sc/7/rc/1/rc.htm" rel="nofollow"><img border="0" src="http://da.feedsportal.com/r/199108753875/u/57/f/640350/c/34625/s/3bcb5250/sc/7/rc/1/rc.img" /></a><br /><a href="http://da.feedsportal.com/r/199108753875/u/57/f/640350/c/34625/s/3bcb5250/sc/7/rc/2/rc.htm" rel="nofollow"><img border="0" src="http://da.feedsportal.com/r/199108753875/u/57/f/640350/c/34625/s/3bcb5250/sc/7/rc/2/rc.img" /></a><br /><a href="http://da.feedsportal.com/r/199108753875/u/57/f/640350/c/34625/s/3bcb5250/sc/7/rc/3/rc.htm" rel="nofollow"><img border="0" src="http://da.feedsportal.com/r/199108753875/u/57/f/640350/c/34625/s/3bcb5250/sc/7/rc/3/rc.img" /></a><br /><br /><a href="http://da.feedsportal.com/r/199108753875/u/57/f/640350/c/34625/s/3bcb5250/sc/7/a2.htm"><img border="0" src="http://da.feedsportal.com/r/199108753875/u/57/f/640350/c/34625/s/3bcb5250/sc/7/a2.img" /></a><img border="0" height="1" src="http://pi.feedsportal.com/r/199108753875/u/57/f/640350/c/34625/s/3bcb5250/sc/7/a2t.img" width="1" />'},
'tags': [{'label': None,
'scheme': u'http://www.nytimes.com/namespaces/keywords/nyt_geo',
'term': u'Colorado'},
{'label': None,
'scheme': u'http://www.nytimes.com/namespaces/nyt_org_all',
'term': u'Facebook Inc|FB|NASDAQ'},
{'label': None,
'scheme': u'http://www.nytimes.com/namespaces/keywords/nyt_per',
'term': u'Tancredo, Tom'},
{'label': None,
'scheme': u'http://www.nytimes.com/namespaces/nyt_org_all',
'term': u'Harley-Davidson Inc|HOG|NYSE'},
{'label': None,
'scheme': u'http://www.nytimes.com/namespaces/keywords/des',
'term': u'Midterm Elections (2014)'},
{'label': None,
'scheme': u'http://www.nytimes.com/namespaces/keywords/nyt_org_all',
'term': u'Republican Party'}],
'title': u'Tom Tancredo\u2019s Bid for Colorado Governor Puts His Party on Alert',
'title_detail': {'base': u'http://rss.nytimes.com/services/xml/rss/nyt/HomePage.xml',
'language': None,
'type': u'text/plain',
'value': u'Tom Tancredo\u2019s Bid for Colorado Governor Puts His Party on Alert'}}
Okay, cool. Looking over this data structure, it looks like we have a dictionary, and the thing we want---the title of the article---is the value for the title key. Let's make a list comprehension to pull them out:
[article['title'] for article in feed.entries]
[u'Tom Tancredo\u2019s Bid for Colorado Governor Puts His Party on Alert', u'Justices, With Limits, Let E.P.A. Curb Power-Plant Gases', u'Kerry Says ISIS Threat Could Hasten Military Action', u'Top Afghan Election Official Resigns Amid Candidate\u2019s Claims of Vote Fraud', u'Here Lies Progress: Asian Actors Fill the Playbill', u'Justice Department Found It Lawful to Target Anwar al-Awlaki', u'The Global Game: Drawing Lots at World Cup? There Must Be a Better Way', u'Top Investigator Has Blistering Criticism for V.A. Response to Whistle-Blowers', u'ArtsBeat: Annie Missing? No Worries, Dick Tracy Is on the Case', u'Last of Syria\u2019s Declared Chemical Arms Shipped Abroad', u'City Room: New York Today: Fire in the Dark', u'Afghan Official Quits in Bid to End Crisis', u'Report: Pennsylvania Governor Did Not Deliberately Delay Sandusky Case', u'Steve Rossi, Singer Who Found Fame in Comedy Duo, Dies at 82', u'Sunni Militants Seize Crossing on Iraq-Jordan Border', u'ArtsBeat: \u2018True Blood\u2019 Recap: Back to the Beginning', u'New Search Plan for Flight 370 Is Based on Farther, Controlled Flying', u'Vice Has Many Media Giants Salivating, but Its Terms Will Be Rich', u'Egyptian Court Convicts 3 Al Jazeera Journalists', u'Egyptian Court Convicts 3 Al Jazeera Journalists', u'Baptism by Fire: A New York Firefighter Confronts His First Test', u'Soldier Accused of Killing 5 Is Captured in South Korea', u'DealBook: An Employee Dies, and the Company Collects the Insurance', u'A Survey Says: Poll Shows No Consensus in U.S. for Helping in Iraq', u'Netherlands and Chile Will Fight to Win Group B']
Conclusion¶
By the end of this tutorial, you should feel confident in your ability to extract information from HTML and XML documents. There are a lot of subtleties we didn't go over, but you're well on your way! Here are some further links to aid in your exploration.