使用 gensim 訓練中文詞向量 (word2vec)¶
word2vec演算法通過將語詞(word)映射到N維的向量空間,然後基於這個詞向量可以進行聚類,找到近似詞以及詞性分析等相關的應用。
關於word2vec原理和核心算法CBOW(Continuous Bag-Of- Words),Skip-Gram在Word2vec 詞嵌入 (word embeddings) 的基本概念已經進行了解釋,不過對如何訓練word2vec的模型並沒有太多著墨。
這篇文章裡將使用維基百科的中文語料,並使用python的gensim套件來訓練word2vec的模型。
需求¶
- Python 3.5
- Anaconda
- gensim : word2vec模型訓練
- jieba : 中文斷詞
- hanziconv : 簡體轉繁體
安裝¶
建議使用Windows的朋友使用Anandoa來設定相關的Python環境。
- 安裝Anaconda
- 產生一個Anaconda環境
- 安裝函式庫:
pip install gensim
pip install jieba
pip install hanziconv
下載相關訓練用的命令稿¶
- 下載Alex-CHUN-YU/Word2vec的Github專案
git clone https://github.com/Alex-CHUN-YU/Word2vec.git
下載中文維基數據¶
- 到 中文維基數據dump 的目錄下找到最新的dump資料檔zhwiki-yyyymmdd-pages-articles.xml.bz2, 比如zhwiki-20180220-pages-articles.xml.bz2 (1.4 GB)到'Word2vec/data'的子目錄下
下載jieba字典檔¶
- 以"Download ZIP"的方式下載 fxsjy/jieba, 解壓縮後將"extra_dict"整個目錄複製到"Word2vec/model"子目錄下
專案的檔案路徑佈局¶
你的目錄結構看起來像這樣: (這裡只列出來在這個範例會用到的相關檔案與目錄)
Word2vec/
├──xxxx.ipynb (代表這個範例的notebook)
├── main.py
├── segmentation.py
├── train.py
├── wiki_to_txt.py
├── stopwords.txt
├── model/
│ └── extra_dict
│ ├── dict.txt.big
│ ├── dict.txt.small
│ ├── idf.txt.big
│ └── stop_words.txt
└── data/
└── zhwiki-20180220-pages-articles.xml.bz2
訓練流程¶
- 取得中文維基數據,本次實驗是採用 2018/02/20 的資料。
- 將下載後的維基數據置於與"data/"子目錄,再使用gensim.corpora的WikiCorpus函數來從wiki的xml檔案中提取出維基文章的語詞
- 簡體轉繁體,再進行斷詞並同步過濾停用詞
- 訓練並產生 word2vec 模型
- 驗證word2vec近似詞以及詞性分析等相關功能
載入相關函式庫¶
# 把一些警告的訊息暫時関掉
import warnings
warnings.filterwarnings('ignore')
# Utilities相關函式庫
import os
import numpy as np
import mmap
from tqdm import tqdm
# 圖像處理/展現的相關函式庫
import jieba
from gensim.corpora import WikiCorpus
from gensim.models import word2vec
from hanziconv import HanziConv
import matplotlib.pyplot as plt
設定相關設定與參數¶
# 專案的根目錄路徑
ROOT_DIR = os.getcwd()
# 訓練/驗證用的資料目錄
DATA_PATH = os.path.join(ROOT_DIR, "data")
# 模型資料目錄
MODEL_PATH = os.path.join(ROOT_DIR, "model")
# 設定jieba繁體中文字典檔
JIEBA_DICTFILE_PATH = os.path.join(MODEL_PATH,"extra_dict", "dict.txt.big")
# 設定繁體中文字典
jieba.set_dictionary(JIEBA_DICTFILE_PATH)
歩驟 1. 取得語料 (Corpus)¶
由於 word2vec 是基於非監督式學習,語料涵蓋的越全面,訓練出來的結果也會越漂亮。在本文中所採用的是維基百科於2018/02/20的dump檔,文章篇數共有 309602 篇。因為維基百科會定期更新備份資料,如果 8 月 20 號的備份不幸地被刪除了,也可以前往維基百科:資料庫下載挑選更近期的資料,不過請特別注意一點,我們要挑選的是以 pages-articles.xml.bz2 結尾的備份,而不是以 pages-articles-multistream.xml.bz2 結尾的備份,否則會在清理上出現一些異常,無法正常解析文章。
初始化WikiCorpus後,能藉由get_texts()可迭代每一篇wikipedia的文章,它所回傳的是一個tokens list,我們以空白符將這些 tokens 串接起來,統一輸出到同一份文字檔裡。這邊要注意一件事,get_texts()受wikicorpus.py中的變數ARTICLE_MIN_WORDS限制,只會回傳內容長度大於 50 的文章。
# 將wiki資料集下載後進行擷取 xml 轉成 plain txt
wiki_articles_xml_file = os.path.join(DATA_PATH, "zhwiki-20180220-pages-articles.xml.bz2")
wiki_articles_txt_file = os.path.join(DATA_PATH, "zhwiki_plaintext.txt")
# 使用gensim.WikiCorpus來讀取wiki XML的corpus
wiki_corpus = WikiCorpus(wiki_articles_xml_file, dictionary = {})
# 迭代擷取出來的語詞
with open(wiki_articles_txt_file, 'w', encoding='utf-8') as output:
text_count = 0
for text in wiki_corpus.get_texts():
# 把語詞寫到檔案備用
output.write(' '.join(text) + '\n')
text_count += 1
if text_count % 10000 == 0:
print("目前已處理 %d 篇文章" % text_count)
print("轉檔完畢, 總共處理了 %d 篇文章!"% text_count)
目前已處理 10000 篇文章 目前已處理 20000 篇文章 目前已處理 30000 篇文章 目前已處理 40000 篇文章 目前已處理 50000 篇文章 目前已處理 60000 篇文章 目前已處理 70000 篇文章 目前已處理 80000 篇文章 目前已處理 90000 篇文章 目前已處理 100000 篇文章 目前已處理 110000 篇文章 目前已處理 120000 篇文章 目前已處理 130000 篇文章 目前已處理 140000 篇文章 目前已處理 150000 篇文章 目前已處理 160000 篇文章 目前已處理 170000 篇文章 目前已處理 180000 篇文章 目前已處理 190000 篇文章 目前已處理 200000 篇文章 目前已處理 210000 篇文章 目前已處理 220000 篇文章 目前已處理 230000 篇文章 目前已處理 240000 篇文章 目前已處理 250000 篇文章 目前已處理 260000 篇文章 目前已處理 270000 篇文章 目前已處理 280000 篇文章 目前已處理 290000 篇文章 目前已處理 300000 篇文章 轉檔完畢, 總共處理了 309602 篇文章!
在4 cores(AMD) 8 GB記憶體的電腦上, 以上歩驟花了將近20分鐘。
歩驟 2. 進行中文斷詞與stop-word移除¶
我們有清完XML標籤的語料了,再來就是要把語料中每個句子,進一步拆解成語詞,這個步驟稱為「斷詞」。中文斷詞的工具有很多,這裏採用的是jieba。在wiki的中文文檔中有簡體跟繁體混在一起的情形,所以我們在斷詞前,還需加上一道繁簡轉換的手續。
# 一個取得一個文字檔案的行數的函式
def get_num_lines(file_path):
fp = open(file_path, "r+")
buf = mmap.mmap(fp.fileno(), 0)
lines = 0
while buf.readline():
lines += 1
return lines
# 進行簡體轉繁體
wiki_articles_zh_tw_file = os.path.join(DATA_PATH, "zhwiki_zh_tw.txt")
wiki_articles_zh_tw = open(wiki_articles_zh_tw_file, "w", encoding = "utf-8")
# 迭代轉成plain text的wiki文檔, 並透過HanziConv來進行簡體轉繁體
with open(wiki_articles_txt_file, "r", encoding = "utf-8") as wiki_articles_txt:
for line in tqdm(wiki_articles_txt, total=get_num_lines(wiki_articles_txt_file)):
wiki_articles_zh_tw.write(HanziConv.toTraditional(line))
print("成功簡體轉繁體!")
wiki_articles_zh_tw.close()
100%|██████████████████████████████████| 309602/309602 [52:34<00:00, 98.15it/s]
成功簡體轉繁體!
# 進行中文斷詞同步過濾停用詞
stops_word_file = os.path.join(ROOT_DIR, "stopwords.txt")
# stopword字詞集
stopwordset = set()
# 讀取 stopword 辭典,並存到 stopwordset
with open("stopwords.txt", "r", encoding = "utf-8") as stopwords:
for stopword in stopwords:
stopwordset.add(stopword.strip('\n'))
# 保留斷詞後的結果
wiki_articles_segmented_file = os.path.join(DATA_PATH, "zhwiki_segmented.txt")
wiki_articles_segmented = open(wiki_articles_segmented_file, "w", encoding = "utf-8")
# 迭代轉成繁體的wiki文檔, 並透過jieba來進行斷詞
with open(wiki_articles_zh_tw_file, "r", encoding = "utf-8") as Corpus:
for sentence in tqdm(Corpus, total=get_num_lines(wiki_articles_zh_tw_file)):
#for sentence in Corpus:
sentence = sentence.strip("\n")
pos = jieba.cut(sentence, cut_all = False)
for term in pos:
if term not in stopwordset:
wiki_articles_segmented.write(term + " ")
print("jieba 斷詞完畢,並已完成過濾停用詞!")
wiki_articles_zh_tw_file.close()
0%| | 0/309602 [00:00<?, ?it/s]Building prefix dict from D:\ml\Word2vec\model\extra_dict\dict.txt.big ... Dumping model to file cache C:\Users\pc\AppData\Local\Temp\jieba.u9cd8b7843c9982f802b1cb4951f40771.cache Loading model cost 4.442 seconds. Prefix dict has been built succesfully. 100%|████████████████████████████████| 309602/309602 [1:40:40<00:00, 51.26it/s]
jieba 斷詞完畢,並已完成過濾停用詞!
停用詞與Word2Vec¶
停用詞(stop word)就是像英文中的 the,a,this,中文的你我他,與其他詞相比顯得不怎麼重要,對文章主題也無關緊要的,就可以將它視為停用詞。而要排除停用詞的理由,其實與word2vec的實作有著相當大的關係。
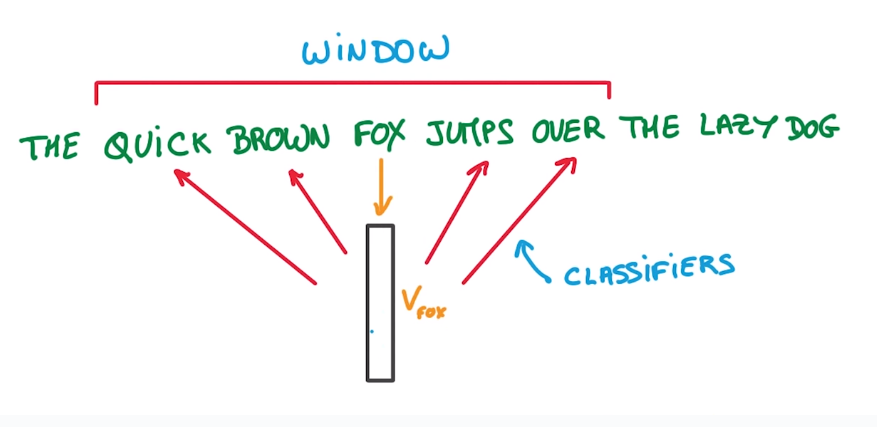
在word2vec有一個概念叫"窗口( windows )"。
很顯然,一個詞的意涵跟他的左右鄰居很有關係,比如「雨越下越大,茶越充越淡」,什麼會「下」?「雨」會下,什麼會「淡」?茶會「淡」,這樣的類比舉不勝舉,那麼,若把思維逆轉過來呢?
顯然,我們或多或少能從左右鄰居是誰,猜出中間的是什麼,這很像我們國高中時天天在練的英文克漏字。那麼問題來了,左右鄰居有誰?能更精確地說,你要往左往右看幾個?假設我們以「孔乙己 一到 店 所有 喝酒 的 人 便都 看著 他 笑」為例,如果往左往右各看一個:
1 [孔乙己 一到] 店 所有 喝酒 的 人 便 都 看著 他 笑
2 [孔乙己 一到 店] 所有 喝酒 的 人 便 都 看著 他 笑
3 孔乙己 [一到 店 所有] 喝酒 的 人 便 都 看著 他 笑
4 孔乙己 一到 [店 所有 喝酒] 的 人 便 都 看著 他 笑
5 ......
這樣就構成了一個 size=1 的 windows,這個 1 是極端的例子,為了讓我們看看有停用詞跟沒停用詞差在哪,這句話去除了停用詞應該會變成:
1 孔乙己 一到 店 所有 喝酒 人 看著 笑
我們看看「人」的窗口變化,原本是「的 人 便」,後來是「喝酒 人 看著」,相比原本的情形,去除停用詞後,我們對「人」這個詞有更多認識,比如人會喝酒,人會看東西,當然啦,這是我以口語的表達,機器並不會這麼想,機器知道的是人跟喝酒會有某種關聯,跟看會有某種關聯,但儘管如此,也遠比本來的「的 人 便」好太多太多了。
歩驟 3. 訓練詞向量¶
這是最簡單的部分,同時也是最困難的部分,簡單的是程式碼,困難的是詞向量效能上的微調與後訓練。
相關參數:
- sentences:這是要訓練的句子集
- size:這表示的是訓練出的詞向量會有幾維
- alpha:機器學習中的學習率,這東西會逐漸收斂到 min_alpha
- sg:sg=1表示採用skip-gram,sg=0 表示採用cbow
- window:還記得孔乙己的例子嗎?能往左往右看幾個字的意思
- workers:執行緒數目,建議別超過 4
- min_count:若這個詞出現的次數小於min_count,那他就不會被視為訓練對象
from gensim.models import word2vec
# 可參考 https://radimrehurek.com/gensim/models/word2vec.html 更多運用
print("word2vec模型訓練中...")
# Load file
sentence = word2vec.Text8Corpus(wiki_articles_segmented_file)
# Setting degree and Produce Model(Train)
model = word2vec.Word2Vec(sentence, size = 300, window = 10, min_count = 5, workers = 4, sg = 1)
# Save model
word2vec_model_file = os.path.join(MODEL_PATH, "zhwiki_word2vec.model")
model.wv.save_word2vec_format(word2vec_model_file, binary = True)
#model.wv.save_word2vec_format(u"wiki300.model.bin", binary = True)
print("word2vec模型已儲存完畢")
word2vec模型訓練中... word2vec模型已儲存完畢
詞向量實驗¶
訓練完成後,讓我們來測試一下模型的效果。由於 gensim 會將整個模型讀了進來,所以記憶體會消耗相當多。
from gensim.models.keyedvectors import KeyedVectors
word_vectors = KeyedVectors.load_word2vec_format(word2vec_model_file, binary = True)
print("詞彙相似詞前 5 排序")
query_list=['老師']
res = word_vectors.most_similar(query_list[0], topn = 5)
for item in res:
print(item[0] + "," + str(item[1]))
詞彙相似詞前 5 排序 同學,0.7062450647354126 數學老師,0.6757407188415527 體育老師,0.6715770363807678 級任老師,0.6657723188400269 班主任,0.6652411818504333
print("計算兩個詞彙間 Cosine 相似度")
query_list=['爸爸','媽媽']
res = word_vectors.similarity(query_list[0], query_list[1])
print(res)
計算兩個詞彙間 Cosine 相似度 0.853673762029
query_list=['爸爸','老公','媽媽']
print("%s之於%s,如%s之於" % (query_list[0], query_list[1], query_list[2]))
res = word_vectors.most_similar(positive = [query_list[0], query_list[1]], negative = [query_list[2]], topn = 5)
for item in res:
print(item[0] + "," + str(item[1]))
爸爸之於老公,如媽媽之於 老婆,0.6520007252693176 方鎮東,0.578291654586792 雲標,0.5759664177894592 良叔,0.5727513432502747 男友,0.5700175166130066