Word2vec 詞嵌入 (word embeddings) 的基本概念¶
什麼是Word2vec?¶
一般進行NLP(自然語言處理)時,資料最小的細粒度是語詞(word),語詞組成句子,句子再組成句子,篇章,文檔。所以很多處理NLP的問題的前處理程序,首先就要思考語詞(word)的處理。
舉個簡單的例子,判斷一個詞的詞性,是動詞還是名詞。用機器學習的思路,我們有一系列樣本(x,y),這裡x是語詞,y是它們的詞性,我們要構建f(x) -> y的映射,但這裡的數學模型f(比如神經網絡,SVM)只接受數值型輸入,而NLP裡的語詞,是人類的語言抽象表示,是以符號形式來表現的(比如中文,英文,拉丁文等等),所以需要把他們轉換成數值形式,或者說"嵌入"到一個數學空間裡,這種嵌入方式,就叫"詞嵌入(word embedding)",而Word2vec,就是詞嵌入(word embedding)的一種作法。
在NLP中,把x看做一個句子裡的一個語詞,y是這個語詞的上下文(context)語詞,那麼這裡的f,便是NLP中經常出現的「語言模型」(language model),這個模型的目的,就是判斷(x,y)這個樣本,是否符合自然語言的法則,更通俗點說是:語詞x和語詞y放在一起時,像不像是人寫的話或寫的句子。
Word2vec正是來自於這個想法,但它的最終目的,不是要把f訓練得多麼完美,而是關心模型訓練完後的副產物-"模型參數"(這里指的是神經網絡的權重),並將這些參數,作為輸入x的某種向量化的表示,這個向量便叫做"詞向量(word vector)"。
我們來看個例子,如何用Word2vec尋找相似詞:
對於一句話:「她們誇二哥帥到沒朋友」,如果輸入x是「二哥」,那麼y可以是「她們」,「誇」,「帥」,「沒朋友」這些詞。
現有另一句話:「她們誇我帥到沒朋友」,如果輸入x是「我」,那麼不難發現,這裡的上下文y跟上面一句話一樣 從而f(二哥) = f(我) = y,所以大數據告訴我們:我 = 二哥(完美的結論)。
Skip-gram 和 CBOW (Continuous Bag of Words) 模型¶
上面我們提到了語言模型(Languate model):
- 如果是用一個語詞作為輸入,來預測它周圍的上下文,那這個模型叫做「Skip-gram模型」, 比如: 二哥 [?][?]

- 如果是拿一個語詞的上下文作為輸入,來預測這個詞語本身,則是「CBOW模型」, 比如: 誇 [?] 帥


我們先來看個最簡單的例子。上面說到,y是x的上下文,所以y只取上下文裡一個語詞(word)的時候,語言模型就變成:
用當前語詞 x 預測它的下一個語詞 y
但如上面所說,一般的數學模型只接受數值型輸入,這裡的x該怎麼表示呢?顯然不能用Word2vec,因為這是我們訓練完模型的產物,現在我們想要的是x的一個原始輸入形式。
答案是:one-hot encoder
OK,那我們接下來就可以看看Skip-gram的網絡結構了,x就是上面提到的one-hot encoder形式的輸入,y是在這V個詞上輸出的概率,我們希望跟真實的y的one-hot編碼結果一樣。
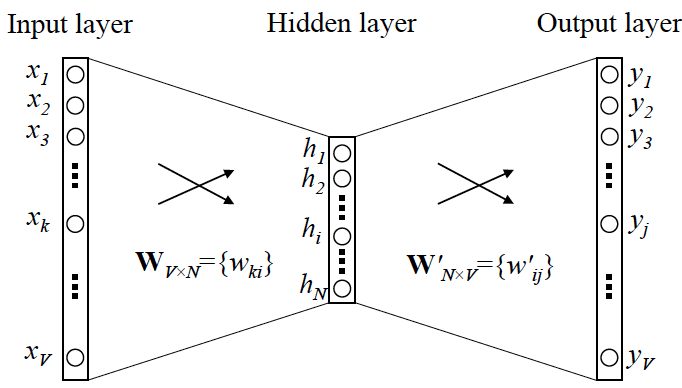
首先說明一點:隱藏層的激活函數(activation function)其實是"線性"的,相當於沒做任何處理(這也是Word2vec簡化之前其它語言模型的獨到之處),我們要訓練這個神經網絡,用反向傳播算法。
當模型訓練完後,最後得到的其實是神經網絡的權重,比如現在輸入一個x的one-hot encoder:[1,0,0,...,0],對剛剛說的那個詞語「二哥」,則在輸入層到隱藏層的權重裡,只有對應1這個位置的權重被激活,這些權重的個數,跟隱藏層節點數是一致的,從而這些權重組成一個向量vx來表示x,而因為每個語詞的one-hot encoder裡面1的位置是不同的,所以,這個向量vx就可以用來唯一表示x。
輸出y也是用V個節點表示的,對應V個語詞,所以其實,我們把輸出節點置成[1,0,0,…,0],它也能表示『二哥』這個單詞,但是激活的是隱含層到輸出層的權重,這些權重的個數,跟隱含層一樣,也可以組成一個向量vy,跟上面提到的vx 維度一樣,並且可以看做是語詞『二哥』的另一種詞向量。而這兩種詞向量 vx 和 vy,正是 Mikolov 在論文裡所提到的,『輸入向量』和『輸出向量』,一般我們用『輸入向量』。
需要提到一點的是,這個詞向量的維度(與隱藏層節點數一致)一般情況下要遠遠小於語詞總數V的大小,所以Word2vec本質上是一種降維操作(把語詞從one-hot encoder形式的表示降維到Word2vec形式的表示)。
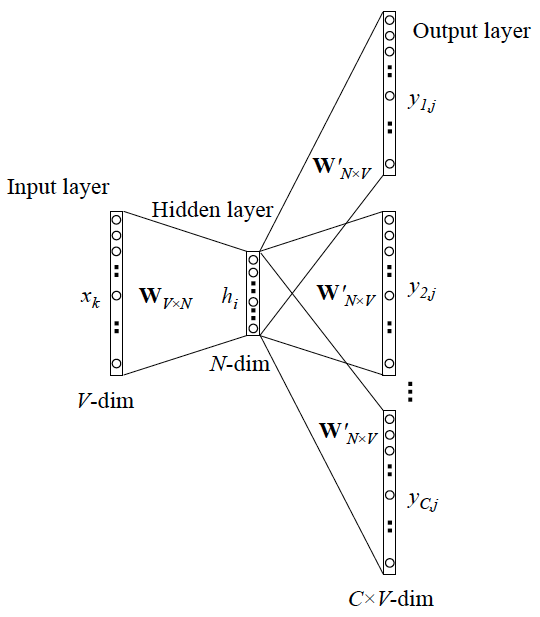
可以看成是 單個x -> 單個y 模型的並聯,cost function 是單個 cost function 的累加(取log之後)
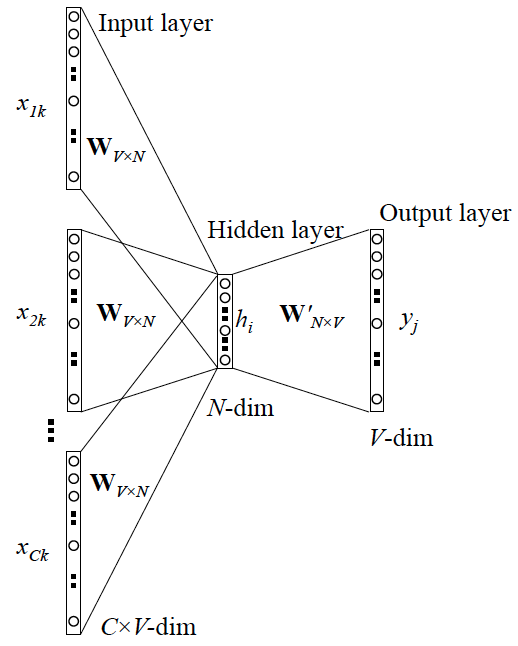
與 Skip-gram 模型的並聯不同,這裡是輸入變成了多個單詞,所以要對輸入進行前處理(一般是求和然後平均)
很多時候,當我們面對林林總總的模型與方法時,我們總希望總結出一些本質且共通性的東西,以構建我們的知識體系,比如在詞嵌入(word embeddings)的領域,除了Word2vec之外,還有基於共現矩陣分解的GloVe等等詞嵌入方法。
深入進去我們會發現,神經網絡形式表示的模型(如Word2vec),跟共現矩陣分解模型(如GloVe),有理論上的相通性,所以在實際應用當中,這兩者的差別並不算很大,尤其是在其中高級別的NLP任務(如句子表示,命名體識別,文檔表示)當中,經常把"詞向量"作為原始輸入。
鑑於語詞是NLP裡最細粒度的表達,所以"詞向量"的應用很廣泛,既可以執行詞語層面的任務,也可以作為很多模型的輸入,執行高級如句子,文檔層面的任務,包括但不限於:
計算相似度
- 尋找相似詞
- 信息檢索
作為SVM / LSTM等模型的輸入
- 中文分詞
- 命名體識別
句子表示
- 情感分析
文檔表示
- 文檔主題判別