YOLO 物體偵測 (Object Recognition) 演算法概念與介紹¶
近幾年的物體偵測 (Object Recognition)由於卷積神經網絡(CNN)的關係,準確度與運算速度也大幅度的提升,有一些論文很值得去讀一讀: R-CNN, Fast R-CNN, Faster R-CNN, YOLO, SSD。
這篇文章主要是說說明YOLO演算法一些重要概念的筆記。
一些物體檢測歷史(2001-2017)¶
第一個高效的人臉檢測器 (Viola-Jones Algorithm, 2001)¶
- Paul Viola&Michael Jones發明了一種高效的人臉檢測算法
- 他們的演示使用網絡攝像頭上實時檢測到人臉。
- 是當時最令人驚嘆的計算機視覺演示及顯露這項技術的潛力。
- 很快,它被實現在OpenCV
- 人臉檢測成為Viola和Jones算法的代名詞。


更有效的檢測技術 (Histograms of Oriented Gradients, 2005)¶
- Navneet Dalal和Bill Triggs為行人檢測發明了“HOG”
- 它們的特徵描述符,方向梯度的直方圖(Histograms of Oriented Gradients - HOG),在這項任務中明顯優於當時所有的算法
- 圖像特徵就像以前一樣仍然是由具有專業圖像知識的資料科學家透過特徵工程擷取出來(Handcoded features)
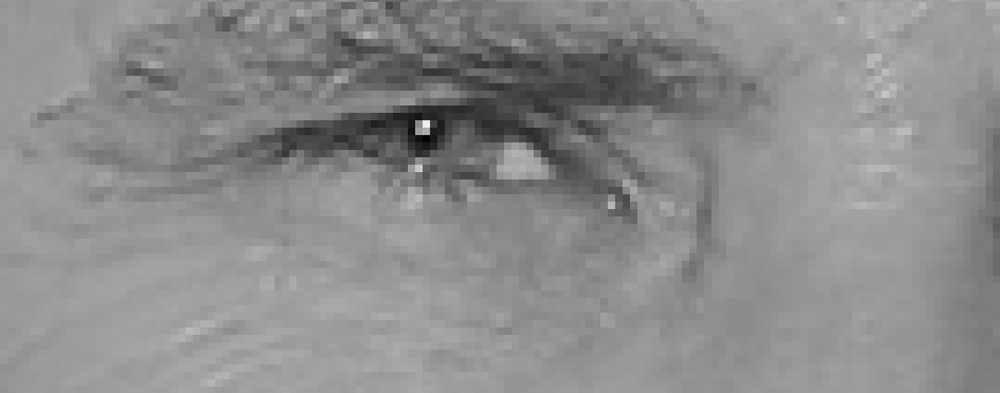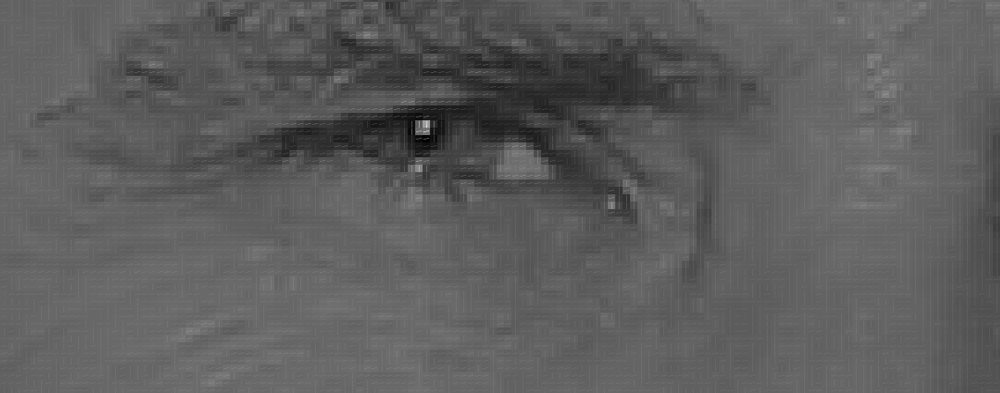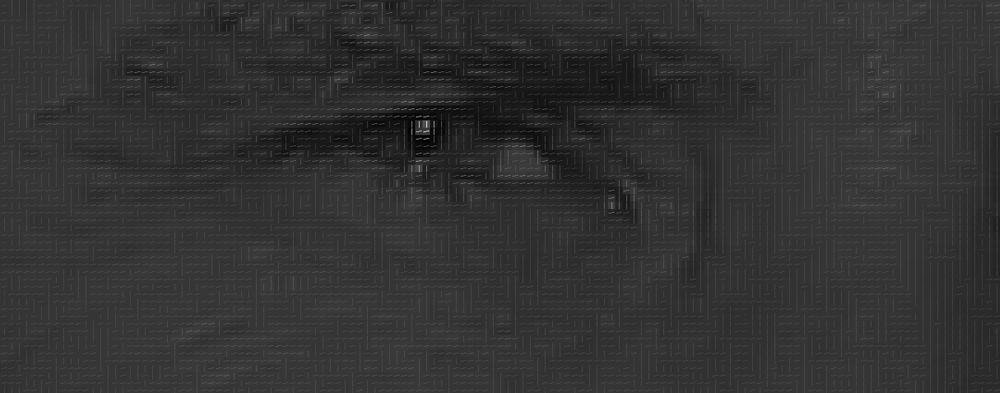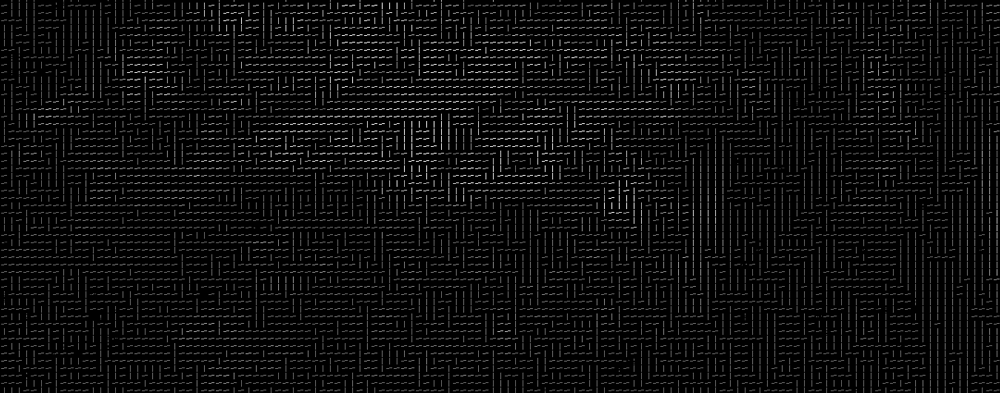
- 對於每一個圖像像素,我們都想看看直接圍繞它週圍的像素:

- 目標是了解與周圍像素相比,當前像素有多暗?
- 然後繪製一個箭頭,顯示圖像越來越暗的方向:

- 對圖像中的每個像素重複這個過程
- 每個像素都被一個箭頭取代。這些箭頭被稱為"梯度(gradients)"
- "梯度"顯示整個圖像中從光線由淺到深的流動:
- 把圖像分解成16x16像素的小方塊
- 在每個正方形中,我們將計算每個主要方向上有多少個"梯度"點
- 然後,我們將用最強的箭頭方向替換圖像中的方塊。
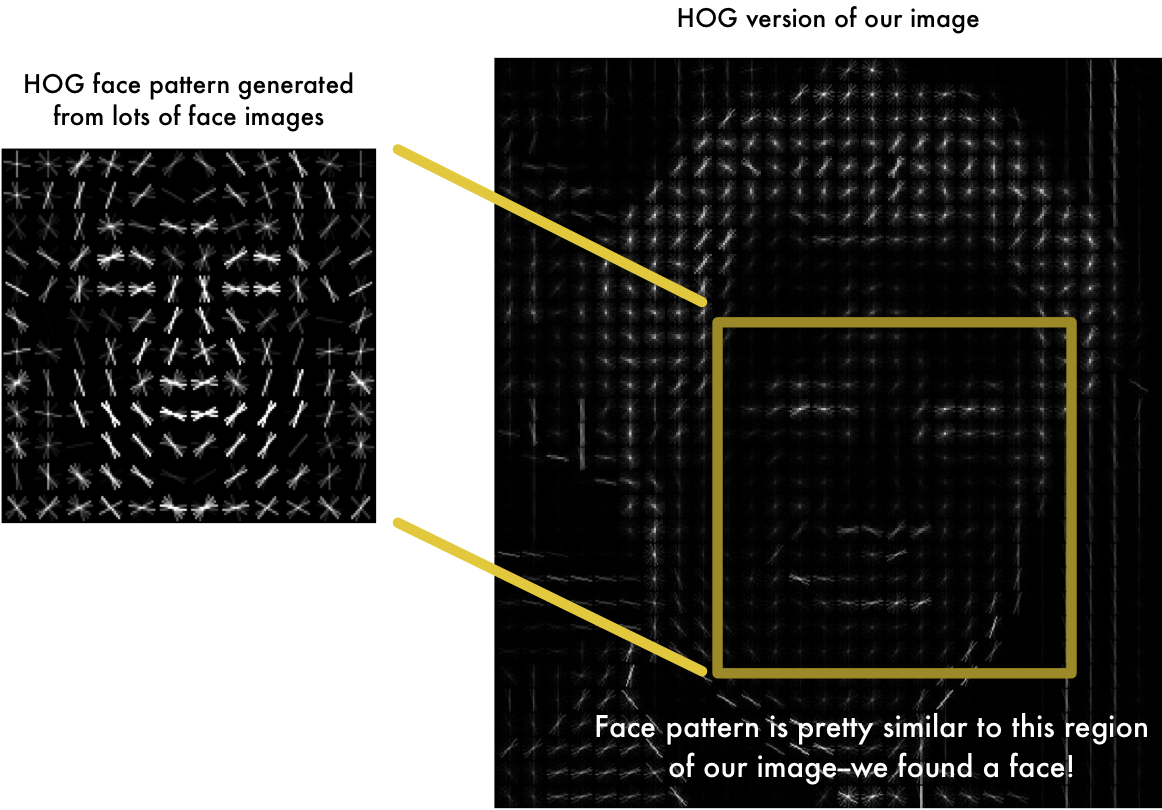
- 最終結果?原始圖像轉化為簡單的表示(representation)形式,以簡單的方式捕捉人臉的基本結構
- 檢測面部意味著找到我們圖像中看起來與從一堆其他訓練面提取的已知HOG模式最相似的部分:
雖然這些結果令人印象深刻,但圖像分類比真實的人類視覺理解的複雜性和多樣性要簡單得多。
在分類(image clarification)中,通常是以單個物體作為焦點的圖像,任務是說出該圖像是什麼

但是當我們看到周圍的世界時,我們執行的任務要複雜得多

我們看到多個重疊的物體,不同的背景,複雜的景象,我們不僅需要分類這些不同的對象,而且還要確定了彼此的邊界,差異和關係!
CNN可以幫助我們完成這麼複雜的任務嗎?是的!
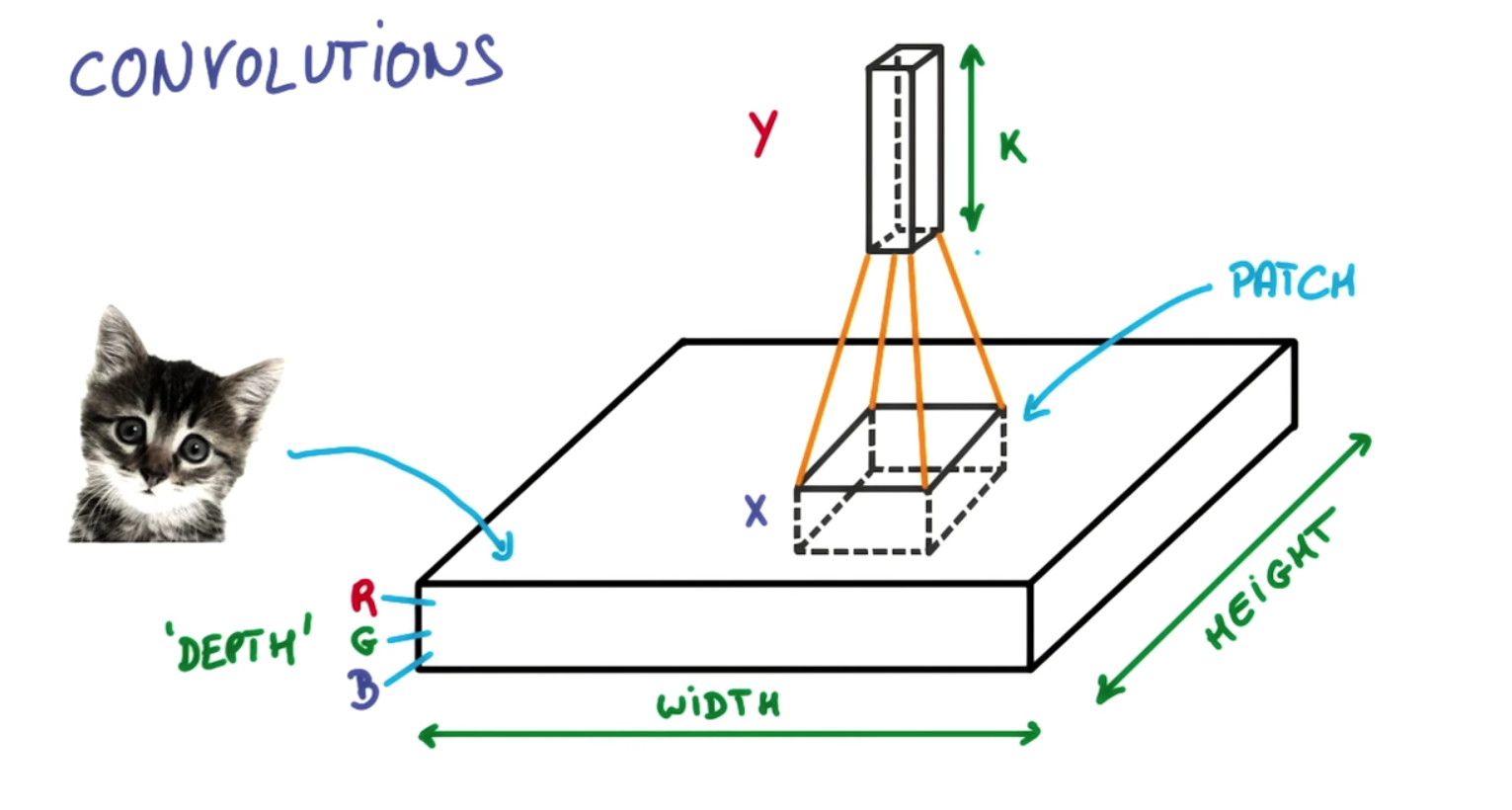
- 我們可以採用像VGGNet或Inception這樣的分類器,並通過在圖像上滑動一個小窗口將其變成一個物體檢測器
- 在滑動的每一步你運行分類器來預測當前窗口內的物體是什麼類型的。
- 使用滑動窗口可以對圖像進行數百或者數千個預測,但是只保留分類器最為確定的那些。
- 這種方法可行,但顯然會很慢,因為您需要多次運行分類器。
一個更好的方法 R-CNN¶

R-CNN使用稱為選擇性搜索(Selective Search)的過程創建邊界框(bounding boxes)或區域提議(regin proposals)
選擇性搜索(Selective Search)通過不同大小的窗口來查看圖像,並且對於每個大小嘗試通過紋理,顏色或強度將相鄰像素組合在一起以識別對象。
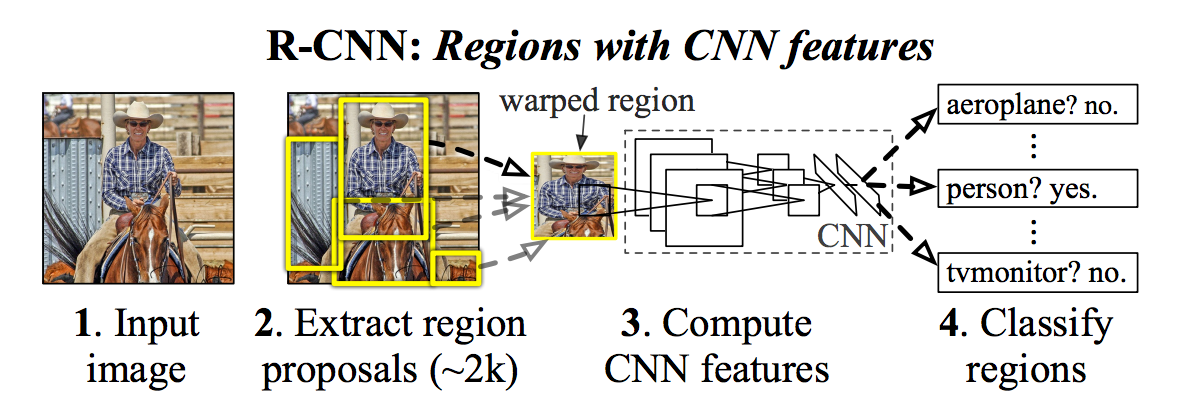
它進行的程序如下:
- 為圖像產生成一組邊界框的提議。
- 通過預先訓練的AlexNet運行邊界框中的圖像,最後通過SVM來查看框中的圖像是什麼對象。
- 一旦圖像物體被分類出來,再通過線性回歸模型運行預測更正確的圖像框的坐標。
R-CNN的一些改進演算法¶
- R-CNN: https://arxiv.org/abs/1311.2524
- Fast R-CNN: https://arxiv.org/abs/1504.08083
- Faster R-CNN: https://arxiv.org/abs/1506.01497
- Mask R-CNN: https://arxiv.org/abs/1703.06870
什麼是YOLO (你只看一次? You only look once)?¶
- YOLO採取了完全不同的方法。
- 它不是一個傳統的圖像分類器被重新用作對象檢測器。
- YOLO實際上只是以一種聰明的方式看圖像(因此它的名字:你只看一次)。
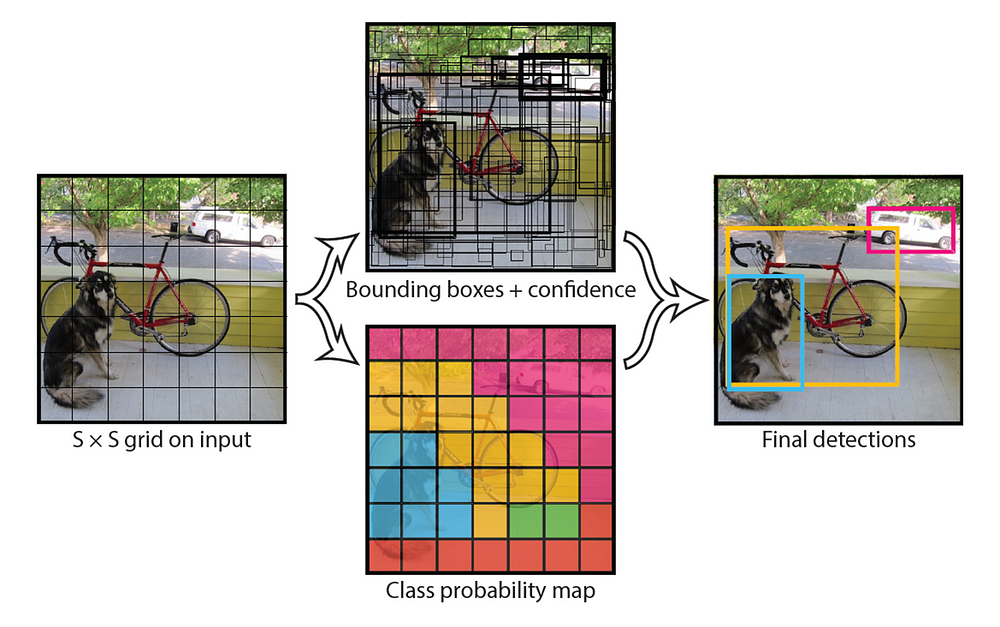
YOLO將圖像分成13×13的網格:

- 這些單元格負責預測5個邊界框。
- 每個邊界框(bounding box)描述了它包圍某種對象的矩形。
- YOLO還會輸出一個信心分數(confidence score),告訴我們它所預測的邊界框實際上是否包含某個物體的確定度。
- This score doesn’t say anything about what kind of object is in the box, just if the shape of the box is any good.
- 這個信心分數(confidence score)並沒有說明什麼樣的物體在邊界框裡。
預測的邊界框可能看起來像下面這樣(信心得分越高,框被繪製得越胖):

- 對於每個邊界框,YOLO還會預測裡頭的物體的類別。
- 它就像一個分類器:給出了所有可能的類的機率分佈。
- YOLO(v2) 分別使用了PASCAL VOC/MS COCO數據集來進行訓練,因此可以檢測PASCAL的20個不同的類別或MS COCO的80個類別。
- 邊界框的信心分數和類別預測被組合成一個最終分數,告訴我們這個邊界框包含特定類型的物體。例如,左邊那個大胖子黃色的盒子裡有85%確定它包含了物體“狗”:

- 由於有13×13 = 169個網格單元,每個單元格預測5個邊界框,因此總共有845個邊界框。
- 事實證明,這些邊界框絕大部分都具有非常低的信心分數,所以我們只保留最終得分為30%或更高的箱子(根據檢測器的準確度,可以改變這個閾值)。
最後的預測結果是:¶

- 從總共845個邊界框中,我們只保留了這三個,因為它們給出了最好的結果。
- 但請注意,即使有845個單獨的預測,他們都在同一時間同一個程序裡處理(神經網絡只運行一次)。這就是為什麼YOLO如此強大和快速(也是它為什麼叫You only look once)。
YOLO的架構很簡單,只是一個卷積神經網絡:(以PASCAL資料集為例)¶

該神經網絡僅使用標準圖層類型:3×3內核卷積和2×2內核最大共享。沒有花俏的東西。 YOLOv2中沒有使用全連接層(fully-connected layer)。
最後一個卷積層有一個1×1內核,用於將數據減少到13×13×125的形狀。這13×13應該看起來很熟悉:那就是圖像分成的網格的大小。
所以我們最終為每個網格單元提供了125個通道。這125個數字包含邊界框和類別預測的數據。為什麼125? 那麼,每個網格單元預測5個邊界框,邊界框由25個數據元素描述:
- 邊界框矩形的(x,y,width,height) -> 4個數字
- 信心評分 -> 1個數字
- 圖像類別的機率分佈 -> 20個數字 (PASCAL資料集有20個類別, 如果是用MS COCO的話那就會有80個類別)
使用YOLO很簡單:給它一個輸入圖像(調整大小為416×416像素),一次通過卷積網絡,另一端作為一個13×13×125的張量來描述邊界框網格單元格。所有你需要做的是計算邊界框的最終分數,並丟棄那些得分低於30%的分數的圖框。
from IPython.display import HTML
# Youtube
HTML('<iframe width="560" height="315" src="https://www.youtube.com/embed/QCdmmWh8I8o?rel=0&controls=0&showinfo=0" frameborder="0" allowfullscreen></iframe>')
總結 (Conclusion)¶
在這篇文章中有一些個人學習到的一些有趣的重點:
- 了解不同神經網絡的結構與構建這個結構的原始構想是非常重要的
- Kaggle的中心思想"No free lunch!"在物體偵測的這個任務上被表露無遺
- 很多看起來複雜的演算法, 當了解它的核心設計思想之後, 就會覺得簡單很多