關於Keras序列到序列學習的十分鐘介紹¶
我經常看到有人問這個問題 - 如何在Keras中實現RNN序列到序列(sequence-to-sequence)的學習?
這篇文章是對"sequence-to-sequence"一個簡短的介紹。
請注意,這篇文章假設你已經有一些遞歸網絡(recurrent networks)和Keras的經驗。

什麼是從序列到序列 (seq2seq) 的學習?¶
序列到序列(Seq2Seq)學習是關於訓練模型以將來自一個領域(例如,英語的句子)的序列轉換成另一個領域(例如翻譯成中文的相同句子)的序列的模型。
"the cat sat on the mat" -> [Seq2Seq model] -> "那隻貓坐在地毯上"
這可以用於機器翻譯或任何Q&A(根據自然語言問題生成自然語言答案) - 通常,只要您需要生成文本,就可以使用它。
有多種方式來處理這樣的任務,或者使用RNN或者使用一維的卷積網絡(convnets)。這裡我們將重點放在RNN的使用。
簡單的案例:當輸入和輸出序列具有相同的長度時¶
當輸入序列和輸出序列長度相同時,您可以簡單地用Keras LSTM或GRU層(或其堆疊)來實現這些模型。以下的示範就是這種情況,它顯示瞭如何教導RNN學習如何對數字進行相加(加法):
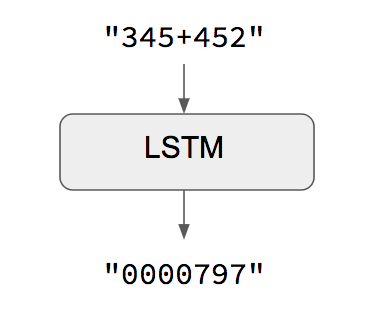
STEP 1. 引入相關的函數庫¶
from keras.models import Sequential
from keras import layers
from keras.utils import plot_model
import numpy as np
from six.moves import range
from IPython.display import Image
Using TensorFlow backend.
class CharacterTable(object):
"""
給予一組的字符:
+ 將這些字符使用one-hot編碼成數字表示
+ 解碼one-hot編碼數字表示成為原本的字符
+ 解碼字符機率的向量以回覆最有可能的字符
"""
def __init__(self, chars):
"""初始化字符表
# 參數:
chars: 會出現在輸入的可能字符集
"""
self.chars = sorted(set(chars))
self.char_indices = dict((c, i) for i, c in enumerate(self.chars))
self.indices_char = dict((i, c) for i, c in enumerate(self.chars))
def encode(self, C, num_rows):
"""對輸入的字串進行one-hot編碼
# 參數:
C: 要被編碼的字符
num_rows: one-hot編碼後要回傳的最大行數。這是用來確保每一個輸入都會得到
相同行數的輸出
"""
x = np.zeros((num_rows, len(self.chars)))
for i, c in enumerate(C):
x[i, self.char_indices[c]] = 1
return x
def decode(self, x, calc_argmax=True):
"""對輸入的編碼(向量)進行解碼
# 參數:
x: 要被解碼的字符向量或字符編碼
calc_argmax: 是否要用argmax算符找出機率最大的字符編碼
"""
if calc_argmax:
x = x.argmax(axis=-1)
return ''.join(self.indices_char[x] for x in x)
class colors:
ok = '\033[92m'
fail = '\033[91m'
close = '\033[0m'
STEP 2. 相關的參數與產生訓練用的資料集¶
# 模型與資料集的參數
TRAINING_SIZE = 50000 # 訓練資料集的samples數
DIGITS = 3 # 加數或被加數的字符數
INVERT = True
# 輸入的最大長度 'int + int' (比如, '345+678')
MAXLEN = DIGITS + 1 + DIGITS
# 所有要用到的字符(包括數字、加號及空格)
chars = '0123456789+ '
ctable = CharacterTable(chars) # 創建CharacterTable的instance
questions = [] # 訓練用的句子 "xxx+yyy"
expected = [] # 訓練用的標籤
seen = set()
print('Generating data...') # 產生訓練資料
while len(questions) < TRAINING_SIZE:
# 數字產生器 (3個字符)
f = lambda: int(''.join(np.random.choice(list('0123456789'))
for i in range(np.random.randint(1, DIGITS+1))))
a, b = f(), f()
# 跳過己經看過的題目以及x+Y = Y+x這樣的題目
key = tuple(sorted((a, b)))
if key in seen:
continue
seen.add(key)
# 當數字不足MAXLEN則填補空白
q = '{}+{}'.format(a, b)
query = q + ' ' * (MAXLEN - len(q))
ans = str(a + b)
# 答案的最大的字符長度為DIGITS + 1
ans += ' ' * (DIGITS + 1 - len(ans))
if INVERT:
# 調轉問題字符的方向, 比如. '12+345'變成'543+21'
query = query[::-1]
questions.append(query)
expected.append(ans)
print('Total addition questions:', len(questions))
Generating data... Total addition questions: 50000
STEP 3.資料的前處理¶
# 把資料做適當的轉換, LSTM預期的資料結構 -> [samples, timesteps, features]
print('Vectorization...')
x = np.zeros((len(questions), MAXLEN, len(chars)), dtype=np.bool) # 初始一個3維的numpy ndarray (特徵資料)
y = np.zeros((len(questions), DIGITS + 1, len(chars)), dtype=np.bool) # 初始一個3維的numpy ndarray (標籤資料)
# 將"特徵資料"轉換成LSTM預期的資料結構 -> [samples, timesteps, features]
for i, sentence in enumerate(questions):
x[i] = ctable.encode(sentence, MAXLEN) # <--- 要了解為什麼要這樣整理資料
print("Feature data: ", x.shape)
# 將"標籤資料"轉換成LSTM預期的資料結構 -> [samples, timesteps, features]
for i, sentence in enumerate(expected):
y[i] = ctable.encode(sentence, DIGITS + 1) # <--- 要了解為什麼要這樣整理資料
print("Label data: ", y.shape)
# 打散 Shuffle(x, y)
indices = np.arange(len(y))
np.random.shuffle(indices)
x = x[indices]
y = y[indices]
# 保留10%的資料來做為驗證
split_at = len(x) - len(x) // 10
(x_train, x_val) = x[:split_at], x[split_at:]
(y_train, y_val) = y[:split_at], y[split_at:]
print('Training Data:')
print(x_train.shape)
print(y_train.shape)
print('Validation Data:')
print(x_val.shape)
print(y_val.shape)
Vectorization... Feature data: (50000, 7, 12) Label data: (50000, 4, 12) Training Data: (45000, 7, 12) (45000, 4, 12) Validation Data: (5000, 7, 12) (5000, 4, 12)
STEP 4.構建網絡架構¶
# 可以試著替代其它種的rnn units, 比如,GRU或SimpleRNN
RNN = layers.LSTM
HIDDEN_SIZE = 128
BATCH_SIZE = 128
LAYERS = 1
print('Build model...')
model = Sequential()
# ===== 編碼 (encoder) ====
# 使用RNN“編碼”輸入序列,產生HIDDEN_SIZE的輸出。
# 注意:在輸入序列長度可變的情況下,使用input_shape =(None,num_features)
model.add(RNN(HIDDEN_SIZE, input_shape=(MAXLEN, len(chars)))) # MAXLEN代表是timesteps, 而len(chars)是one-hot編碼的features
# 作為解碼器RNN的輸入,重複提供每個時間步的RNN的最後一個隱藏狀態。
# 重複“DIGITS + 1”次,因為這是最大輸出長度,例如當DIGITS = 3時,最大輸出是999 + 999 = 1998(長度為4)。
model.add(layers.RepeatVector(DIGITS+1))
# ==== 解碼 (decoder) ====
# 解碼器RNN可以是多層堆疊或單層。
for _ in range(LAYERS):
# 通過將return_sequences設置為True,不僅返回最後一個輸出,而且還以(num_samples,timesteps,output_dim)
# 的形式返回所有輸出。這是必要的,因為下面的TimeDistributed需要第一個維度是時間步長。
model.add(RNN(HIDDEN_SIZE, return_sequences=True))
# 對輸入的每個時間片推送到密集層來對於輸出序列的每一時間步,決定選擇哪個字符。
model.add(layers.TimeDistributed(layers.Dense(len(chars))))
model.add(layers.Activation('softmax'))
model.compile(loss='categorical_crossentropy',
optimizer='adam',
metrics=['accuracy'])
model.summary()
Build model... _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= lstm_1 (LSTM) (None, 128) 72192 _________________________________________________________________ repeat_vector_1 (RepeatVecto (None, 4, 128) 0 _________________________________________________________________ lstm_2 (LSTM) (None, 4, 128) 131584 _________________________________________________________________ time_distributed_1 (TimeDist (None, 4, 12) 1548 _________________________________________________________________ activation_1 (Activation) (None, 4, 12) 0 ================================================================= Total params: 205,324 Trainable params: 205,324 Non-trainable params: 0 _________________________________________________________________
STEP 5.訓練模型/驗證評估¶
我們將進行50次的訓練,並且在每次訓練之後就進行檢查。
for iteration in range(1, 30):
print()
print('-' * 50)
print('Iteration', iteration)
model.fit(x_train, y_train,
batch_size=BATCH_SIZE,
epochs=1,
validation_data=(x_val, y_val))
for i in range(10):
ind = np.random.randint(0, len(x_val))
rowx, rowy = x_val[np.array([ind])], y_val[np.array([ind])]
preds = model.predict_classes(rowx, verbose=0)
q = ctable.decode(rowx[0])
correct = ctable.decode(rowy[0])
guess = ctable.decode(preds[0], calc_argmax=False)
print('Q', q[::-1] if INVERT else q, end=' ')
print('T', correct, end=' ')
if correct == guess:
print(colors.ok + '☑' + colors.close, end=' ')
else:
print(colors.fail + '☒' + colors.close, end=' ')
print(guess)
-------------------------------------------------- Iteration 1 Train on 45000 samples, validate on 5000 samples Epoch 1/1 45000/45000 [==============================] - 10s 221us/step - loss: 1.8837 - acc: 0.3226 - val_loss: 1.7765 - val_acc: 0.3463 Q 249+82 T 331 ☒ 109 Q 800+51 T 851 ☒ 109 Q 6+346 T 352 ☒ 70 Q 95+816 T 911 ☒ 109 Q 2+116 T 118 ☒ 22 Q 3+874 T 877 ☒ 10 Q 34+868 T 902 ☒ 109 Q 1+118 T 119 ☒ 22 Q 68+909 T 977 ☒ 100 Q 926+78 T 1004 ☒ 100 -------------------------------------------------- Iteration 2 Train on 45000 samples, validate on 5000 samples Epoch 1/1 45000/45000 [==============================] - 7s 166us/step - loss: 1.7156 - acc: 0.3660 - val_loss: 1.6534 - val_acc: 0.3875 Q 76+64 T 140 ☒ 167 Q 49+497 T 546 ☒ 409 Q 235+0 T 235 ☒ 110 Q 317+97 T 414 ☒ 709 Q 588+7 T 595 ☒ 889 Q 745+9 T 754 ☒ 154 Q 37+37 T 74 ☒ 33 Q 54+87 T 141 ☒ 154 Q 660+775 T 1435 ☒ 1477 Q 472+903 T 1375 ☒ 1329 -------------------------------------------------- Iteration 3 Train on 45000 samples, validate on 5000 samples Epoch 1/1 45000/45000 [==============================] - 8s 174us/step - loss: 1.5789 - acc: 0.4064 - val_loss: 1.5200 - val_acc: 0.4273 Q 85+6 T 91 ☒ 10 Q 49+517 T 566 ☒ 540 Q 55+474 T 529 ☒ 540 Q 984+369 T 1353 ☒ 1331 Q 52+490 T 542 ☒ 490 Q 540+96 T 636 ☒ 504 Q 175+861 T 1036 ☒ 1104 Q 8+285 T 293 ☒ 882 Q 467+47 T 514 ☒ 444 Q 467+47 T 514 ☒ 444 -------------------------------------------------- Iteration 4 Train on 45000 samples, validate on 5000 samples Epoch 1/1 45000/45000 [==============================] - 7s 162us/step - loss: 1.4369 - acc: 0.4614 - val_loss: 1.3570 - val_acc: 0.4923 Q 539+109 T 648 ☒ 682 Q 58+828 T 886 ☒ 883 Q 408+15 T 423 ☒ 444 Q 16+588 T 604 ☒ 623 Q 716+93 T 809 ☒ 777 Q 3+694 T 697 ☒ 664 Q 870+40 T 910 ☒ 884 Q 788+87 T 875 ☒ 884 Q 0+205 T 205 ☒ 222 Q 946+68 T 1014 ☒ 1004 -------------------------------------------------- Iteration 5 Train on 45000 samples, validate on 5000 samples Epoch 1/1 45000/45000 [==============================] - 7s 156us/step - loss: 1.2804 - acc: 0.5239 - val_loss: 1.2137 - val_acc: 0.5504 Q 492+88 T 580 ☒ 552 Q 6+685 T 691 ☒ 675 Q 228+651 T 879 ☒ 991 Q 75+688 T 763 ☒ 743 Q 14+640 T 654 ☒ 679 Q 21+291 T 312 ☒ 203 Q 57+858 T 915 ☒ 842 Q 202+37 T 239 ☒ 243 Q 391+810 T 1201 ☒ 1111 Q 90+987 T 1077 ☒ 1051 -------------------------------------------------- Iteration 6 Train on 45000 samples, validate on 5000 samples Epoch 1/1 45000/45000 [==============================] - 7s 159us/step - loss: 1.1528 - acc: 0.5759 - val_loss: 1.0907 - val_acc: 0.6036 Q 788+704 T 1492 ☒ 1485 Q 396+6 T 402 ☒ 490 Q 449+97 T 546 ☒ 548 Q 87+92 T 179 ☒ 188 Q 82+266 T 348 ☒ 355 Q 596+405 T 1001 ☒ 100 Q 50+24 T 74 ☒ 80 Q 354+17 T 371 ☒ 370 Q 42+381 T 423 ☒ 425 Q 450+76 T 526 ☒ 525 -------------------------------------------------- Iteration 7 Train on 45000 samples, validate on 5000 samples Epoch 1/1 45000/45000 [==============================] - 8s 176us/step - loss: 1.0391 - acc: 0.6230 - val_loss: 1.0094 - val_acc: 0.6263 Q 66+585 T 651 ☒ 641 Q 968+25 T 993 ☒ 990 Q 24+831 T 855 ☒ 864 Q 364+68 T 432 ☒ 434 Q 40+62 T 102 ☒ 110 Q 151+118 T 269 ☒ 299 Q 907+9 T 916 ☒ 913 Q 20+726 T 746 ☒ 745 Q 895+36 T 931 ☒ 939 Q 71+709 T 780 ☒ 789 -------------------------------------------------- Iteration 8 Train on 45000 samples, validate on 5000 samples Epoch 1/1 45000/45000 [==============================] - 8s 173us/step - loss: 0.9626 - acc: 0.6523 - val_loss: 0.9241 - val_acc: 0.6655 Q 504+15 T 519 ☒ 528 Q 903+334 T 1237 ☒ 1253 Q 896+809 T 1705 ☒ 1777 Q 330+338 T 668 ☒ 675 Q 43+63 T 106 ☒ 102 Q 12+682 T 694 ☒ 698 Q 135+43 T 178 ☒ 174 Q 121+64 T 185 ☒ 184 Q 459+148 T 607 ☒ 610 Q 7+34 T 41 ☒ 33 -------------------------------------------------- Iteration 9 Train on 45000 samples, validate on 5000 samples Epoch 1/1 45000/45000 [==============================] - 8s 177us/step - loss: 0.8857 - acc: 0.6836 - val_loss: 0.8589 - val_acc: 0.6865 Q 31+486 T 517 ☒ 518 Q 843+187 T 1030 ☒ 1008 Q 901+694 T 1595 ☒ 1690 Q 155+836 T 991 ☒ 900 Q 8+253 T 261 ☒ 264 Q 8+428 T 436 ☒ 441 Q 254+59 T 313 ☒ 316 Q 57+718 T 775 ☒ 776 Q 406+13 T 419 ☒ 418 Q 836+28 T 864 ☒ 867 -------------------------------------------------- Iteration 10 Train on 45000 samples, validate on 5000 samples Epoch 1/1 45000/45000 [==============================] - 7s 162us/step - loss: 0.8077 - acc: 0.7143 - val_loss: 0.7743 - val_acc: 0.7218 Q 68+41 T 109 ☒ 102 Q 866+607 T 1473 ☒ 1470 Q 552+35 T 587 ☒ 589 Q 339+68 T 407 ☒ 406 Q 78+672 T 750 ☒ 759 Q 773+45 T 818 ☒ 810 Q 953+28 T 981 ☒ 976 Q 474+927 T 1401 ☒ 1399 Q 86+53 T 139 ☒ 136 Q 66+973 T 1039 ☒ 1036 -------------------------------------------------- Iteration 11 Train on 45000 samples, validate on 5000 samples Epoch 1/1 45000/45000 [==============================] - 7s 165us/step - loss: 0.7308 - acc: 0.7399 - val_loss: 0.6885 - val_acc: 0.7488 Q 950+1 T 951 ☑ 951 Q 739+230 T 969 ☒ 975 Q 406+3 T 409 ☒ 408 Q 11+228 T 239 ☒ 249 Q 59+512 T 571 ☒ 579 Q 155+836 T 991 ☒ 997 Q 300+3 T 303 ☑ 303 Q 96+639 T 735 ☒ 731 Q 469+19 T 488 ☒ 484 Q 5+184 T 189 ☑ 189 -------------------------------------------------- Iteration 12 Train on 45000 samples, validate on 5000 samples Epoch 1/1 45000/45000 [==============================] - 7s 165us/step - loss: 0.6097 - acc: 0.7817 - val_loss: 0.5211 - val_acc: 0.8122 Q 776+284 T 1060 ☒ 1050 Q 433+633 T 1066 ☑ 1066 Q 1+176 T 177 ☒ 178 Q 465+125 T 590 ☑ 590 Q 55+69 T 124 ☑ 124 Q 447+303 T 750 ☒ 759 Q 478+555 T 1033 ☒ 1043 Q 390+29 T 419 ☒ 418 Q 871+465 T 1336 ☒ 1347 Q 787+36 T 823 ☒ 822 -------------------------------------------------- Iteration 13 Train on 45000 samples, validate on 5000 samples Epoch 1/1 45000/45000 [==============================] - 8s 172us/step - loss: 0.4288 - acc: 0.8542 - val_loss: 0.3511 - val_acc: 0.8901 Q 31+749 T 780 ☑ 780 Q 293+59 T 352 ☑ 352 Q 56+197 T 253 ☒ 255 Q 528+209 T 737 ☒ 738 Q 887+79 T 966 ☑ 966 Q 476+563 T 1039 ☑ 1039 Q 302+115 T 417 ☒ 438 Q 1+25 T 26 ☒ 36 Q 737+17 T 754 ☒ 755 Q 781+309 T 1090 ☒ 1099 -------------------------------------------------- Iteration 14 Train on 45000 samples, validate on 5000 samples Epoch 1/1 45000/45000 [==============================] - 8s 176us/step - loss: 0.2916 - acc: 0.9216 - val_loss: 0.2544 - val_acc: 0.9331 Q 643+33 T 676 ☑ 676 Q 21+623 T 644 ☑ 644 Q 35+84 T 119 ☑ 119 Q 57+989 T 1046 ☑ 1046 Q 199+941 T 1140 ☒ 1130 Q 259+0 T 259 ☒ 250 Q 99+448 T 547 ☑ 547 Q 5+459 T 464 ☒ 463 Q 10+0 T 10 ☒ 11 Q 315+51 T 366 ☑ 366 -------------------------------------------------- Iteration 15 Train on 45000 samples, validate on 5000 samples Epoch 1/1 45000/45000 [==============================] - 8s 169us/step - loss: 0.2108 - acc: 0.9509 - val_loss: 0.1777 - val_acc: 0.9599 Q 308+9 T 317 ☑ 317 Q 327+674 T 1001 ☑ 1001 Q 106+579 T 685 ☑ 685 Q 14+957 T 971 ☑ 971 Q 860+158 T 1018 ☒ 1008 Q 1+166 T 167 ☑ 167 Q 931+806 T 1737 ☒ 1747 Q 754+5 T 759 ☑ 759 Q 636+976 T 1612 ☑ 1612 Q 750+83 T 833 ☑ 833 -------------------------------------------------- Iteration 16 Train on 45000 samples, validate on 5000 samples Epoch 1/1 45000/45000 [==============================] - 8s 173us/step - loss: 0.1572 - acc: 0.9669 - val_loss: 0.1312 - val_acc: 0.9752 Q 40+379 T 419 ☑ 419 Q 592+845 T 1437 ☑ 1437 Q 81+756 T 837 ☑ 837 Q 513+25 T 538 ☑ 538 Q 62+339 T 401 ☑ 401 Q 462+70 T 532 ☑ 532 Q 563+658 T 1221 ☑ 1221 Q 366+29 T 395 ☑ 395 Q 98+474 T 572 ☑ 572 Q 495+91 T 586 ☑ 586 -------------------------------------------------- Iteration 17 Train on 45000 samples, validate on 5000 samples Epoch 1/1 45000/45000 [==============================] - 7s 159us/step - loss: 0.1106 - acc: 0.9813 - val_loss: 0.1020 - val_acc: 0.9818 Q 13+861 T 874 ☑ 874 Q 103+89 T 192 ☑ 192 Q 99+88 T 187 ☑ 187 Q 870+91 T 961 ☑ 961 Q 447+303 T 750 ☑ 750 Q 88+21 T 109 ☑ 109 Q 711+282 T 993 ☑ 993 Q 7+154 T 161 ☑ 161 Q 536+17 T 553 ☑ 553 Q 698+25 T 723 ☑ 723 -------------------------------------------------- Iteration 18 Train on 45000 samples, validate on 5000 samples Epoch 1/1 45000/45000 [==============================] - 8s 182us/step - loss: 0.0855 - acc: 0.9867 - val_loss: 0.0846 - val_acc: 0.9838 Q 91+761 T 852 ☑ 852 Q 526+3 T 529 ☑ 529 Q 492+41 T 533 ☑ 533 Q 571+35 T 606 ☑ 606 Q 46+426 T 472 ☑ 472 Q 857+1 T 858 ☑ 858 Q 449+67 T 516 ☑ 516 Q 675+78 T 753 ☑ 753 Q 18+79 T 97 ☑ 97 Q 908+134 T 1042 ☒ 1041 -------------------------------------------------- Iteration 19 Train on 45000 samples, validate on 5000 samples Epoch 1/1 45000/45000 [==============================] - 8s 174us/step - loss: 0.0688 - acc: 0.9897 - val_loss: 0.0710 - val_acc: 0.9865 Q 886+310 T 1196 ☑ 1196 Q 914+108 T 1022 ☑ 1022 Q 913+533 T 1446 ☑ 1446 Q 454+207 T 661 ☑ 661 Q 614+43 T 657 ☑ 657 Q 824+134 T 958 ☑ 958 Q 70+826 T 896 ☑ 896 Q 88+70 T 158 ☑ 158 Q 96+843 T 939 ☒ 949 Q 78+920 T 998 ☑ 998 -------------------------------------------------- Iteration 20 Train on 45000 samples, validate on 5000 samples Epoch 1/1 45000/45000 [==============================] - 8s 169us/step - loss: 0.0612 - acc: 0.9901 - val_loss: 0.0815 - val_acc: 0.9795 Q 945+1 T 946 ☑ 946 Q 454+930 T 1384 ☑ 1384 Q 667+100 T 767 ☒ 768 Q 938+13 T 951 ☑ 951 Q 836+28 T 864 ☑ 864 Q 38+4 T 42 ☑ 42 Q 348+865 T 1213 ☑ 1213 Q 891+365 T 1256 ☑ 1256 Q 328+93 T 421 ☑ 421 Q 181+336 T 517 ☑ 517 -------------------------------------------------- Iteration 21 Train on 45000 samples, validate on 5000 samples Epoch 1/1 45000/45000 [==============================] - 7s 158us/step - loss: 0.0587 - acc: 0.9886 - val_loss: 0.0454 - val_acc: 0.9929 Q 843+38 T 881 ☑ 881 Q 98+827 T 925 ☑ 925 Q 25+726 T 751 ☑ 751 Q 322+21 T 343 ☑ 343 Q 148+13 T 161 ☑ 161 Q 418+587 T 1005 ☑ 1005 Q 43+472 T 515 ☑ 515 Q 1+808 T 809 ☑ 809 Q 112+16 T 128 ☑ 128 Q 218+763 T 981 ☑ 981 -------------------------------------------------- Iteration 22 Train on 45000 samples, validate on 5000 samples Epoch 1/1 45000/45000 [==============================] - 7s 164us/step - loss: 0.0360 - acc: 0.9963 - val_loss: 0.0838 - val_acc: 0.9748 Q 965+110 T 1075 ☑ 1075 Q 246+323 T 569 ☑ 569 Q 939+6 T 945 ☑ 945 Q 78+743 T 821 ☑ 821 Q 0+978 T 978 ☑ 978 Q 54+205 T 259 ☑ 259 Q 29+26 T 55 ☑ 55 Q 474+5 T 479 ☑ 479 Q 93+366 T 459 ☑ 459 Q 80+429 T 509 ☑ 509 -------------------------------------------------- Iteration 23 Train on 45000 samples, validate on 5000 samples Epoch 1/1 45000/45000 [==============================] - 8s 168us/step - loss: 0.0381 - acc: 0.9938 - val_loss: 0.0551 - val_acc: 0.9863 Q 89+974 T 1063 ☑ 1063 Q 89+35 T 124 ☑ 124 Q 289+532 T 821 ☑ 821 Q 46+21 T 67 ☑ 67 Q 883+565 T 1448 ☑ 1448 Q 53+454 T 507 ☑ 507 Q 60+97 T 157 ☑ 157 Q 580+4 T 584 ☑ 584 Q 18+58 T 76 ☑ 76 Q 57+579 T 636 ☑ 636 -------------------------------------------------- Iteration 24 Train on 45000 samples, validate on 5000 samples Epoch 1/1 45000/45000 [==============================] - 7s 160us/step - loss: 0.0595 - acc: 0.9844 - val_loss: 0.0280 - val_acc: 0.9964 Q 6+323 T 329 ☒ 339 Q 515+237 T 752 ☑ 752 Q 90+8 T 98 ☑ 98 Q 256+88 T 344 ☑ 344 Q 566+500 T 1066 ☑ 1066 Q 9+739 T 748 ☑ 748 Q 3+500 T 503 ☑ 503 Q 782+527 T 1309 ☑ 1309 Q 97+422 T 519 ☑ 519 Q 87+65 T 152 ☑ 152 -------------------------------------------------- Iteration 25 Train on 45000 samples, validate on 5000 samples Epoch 1/1 45000/45000 [==============================] - 8s 169us/step - loss: 0.0210 - acc: 0.9986 - val_loss: 0.0251 - val_acc: 0.9962 Q 25+726 T 751 ☑ 751 Q 740+81 T 821 ☑ 821 Q 135+70 T 205 ☑ 205 Q 865+452 T 1317 ☑ 1317 Q 13+51 T 64 ☑ 64 Q 13+908 T 921 ☑ 921 Q 90+637 T 727 ☑ 727 Q 224+25 T 249 ☑ 249 Q 769+98 T 867 ☑ 867 Q 951+412 T 1363 ☑ 1363 -------------------------------------------------- Iteration 26 Train on 45000 samples, validate on 5000 samples Epoch 1/1 45000/45000 [==============================] - 8s 171us/step - loss: 0.0182 - acc: 0.9987 - val_loss: 0.0244 - val_acc: 0.9960 Q 56+728 T 784 ☑ 784 Q 65+26 T 91 ☑ 91 Q 252+556 T 808 ☑ 808 Q 843+187 T 1030 ☑ 1030 Q 93+468 T 561 ☑ 561 Q 56+242 T 298 ☑ 298 Q 206+8 T 214 ☑ 214 Q 659+119 T 778 ☑ 778 Q 377+113 T 490 ☑ 490 Q 497+67 T 564 ☑ 564 -------------------------------------------------- Iteration 27 Train on 45000 samples, validate on 5000 samples Epoch 1/1 45000/45000 [==============================] - 7s 149us/step - loss: 0.0437 - acc: 0.9883 - val_loss: 0.0259 - val_acc: 0.9952 Q 321+268 T 589 ☑ 589 Q 202+37 T 239 ☑ 239 Q 860+410 T 1270 ☑ 1270 Q 33+371 T 404 ☑ 404 Q 581+85 T 666 ☑ 666 Q 66+841 T 907 ☑ 907 Q 653+28 T 681 ☑ 681 Q 284+357 T 641 ☑ 641 Q 969+128 T 1097 ☑ 1097 Q 308+9 T 317 ☑ 317 -------------------------------------------------- Iteration 28 Train on 45000 samples, validate on 5000 samples Epoch 1/1 45000/45000 [==============================] - 7s 164us/step - loss: 0.0145 - acc: 0.9991 - val_loss: 0.0176 - val_acc: 0.9976 Q 390+693 T 1083 ☑ 1083 Q 67+53 T 120 ☑ 120 Q 8+839 T 847 ☑ 847 Q 614+9 T 623 ☑ 623 Q 792+841 T 1633 ☑ 1633 Q 291+688 T 979 ☑ 979 Q 9+311 T 320 ☑ 320 Q 801+14 T 815 ☑ 815 Q 937+1 T 938 ☑ 938 Q 978+821 T 1799 ☑ 1799 -------------------------------------------------- Iteration 29 Train on 45000 samples, validate on 5000 samples Epoch 1/1 45000/45000 [==============================] - 7s 161us/step - loss: 0.0118 - acc: 0.9993 - val_loss: 0.0133 - val_acc: 0.9986 Q 67+717 T 784 ☑ 784 Q 3+26 T 29 ☑ 29 Q 149+952 T 1101 ☑ 1101 Q 897+453 T 1350 ☑ 1350 Q 93+308 T 401 ☑ 401 Q 3+197 T 200 ☑ 200 Q 7+421 T 428 ☑ 428 Q 354+220 T 574 ☑ 574 Q 595+938 T 1533 ☑ 1533 Q 97+782 T 879 ☑ 879
我們可以看到在30次的訓練循環之後,我們己經可以在驗證準確性上達到99.8%的程度。
以上方法的一個先行條件是它假設:給定固定長度的序列當輸入[... t]有可能生成固定長度的目標[...t]序列。
這在某些情況下可行,但不適用於大多數使用情境。
一般情境:序列到序列(seq-to-seq)的典型範例¶
在一般情況下,輸入序列和輸出序列具有不同的長度(例如機器翻譯),並且為了開始預測目標,需要整個輸入序列。這需要更高級的設置,這是人們在沒有更多的上下文的情況下提到“序列到序列模型”時經常提到的。這是如何工作的:
- RNN層(或多個RNN層的堆疊)作為“編碼器(encoder)”:它處理輸入序列並返回其自身的內部狀態。請注意,我們丟棄編碼器RNN的輸出,只保留它的內部狀態。這個狀態將作為下一步解碼器的“上下文”或“條件”。
- 另一個RNN層(或多個RNN層的堆疊)充當“解碼器(decoder)”:對給定的目標序列的先前字符進行訓練,以預測目標序列的下一個字符。具體而言,訓練是將目標序列轉換成相同的序列偏移(offset)一個步驟的過程,這種情況稱為“教師強制(teacher forcing)”的訓練過程。重要的是,解碼器(decoder)使用來自編碼器(encoder)的狀態向量作為初始狀態,這是解碼器如何獲得關於它應該產生何種產出的關鍵資訊。實際上,解碼器學習以輸入序列為條件生成給定目標[... t]的目標[t + 1 ...]。
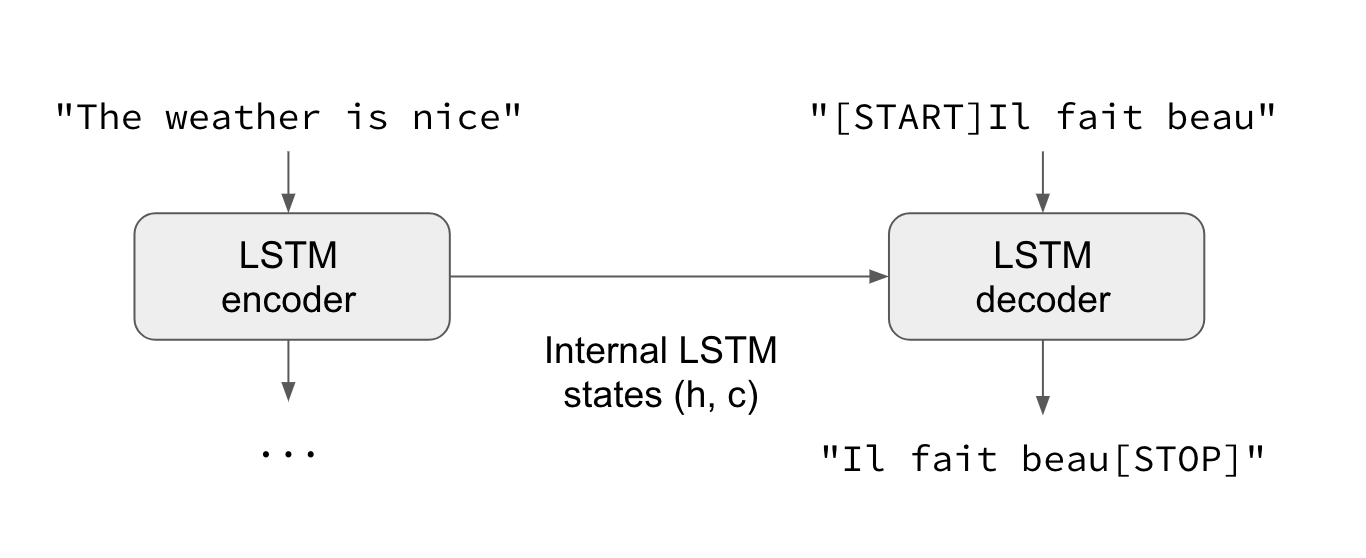
在預測模式下,當我們想要解碼(decode)未知的輸入序列時,我們經歷一個稍微不同的過程:
- 將輸入序列編碼成狀態向量(hidden state vector)。
- 從大小為1的目標序列開始(只是開始序列字符)。
- 將狀態向量和1-char目標序列饋送給解碼器以產生下一個字符的預測。
- 使用這些預測對下一個字符進行採樣(我們簡單地使用argmax)。
- 將採樣的字符附加到目標序列。
- 重複,直到我們拿到生成序列結束字符或我們達到字符限制。
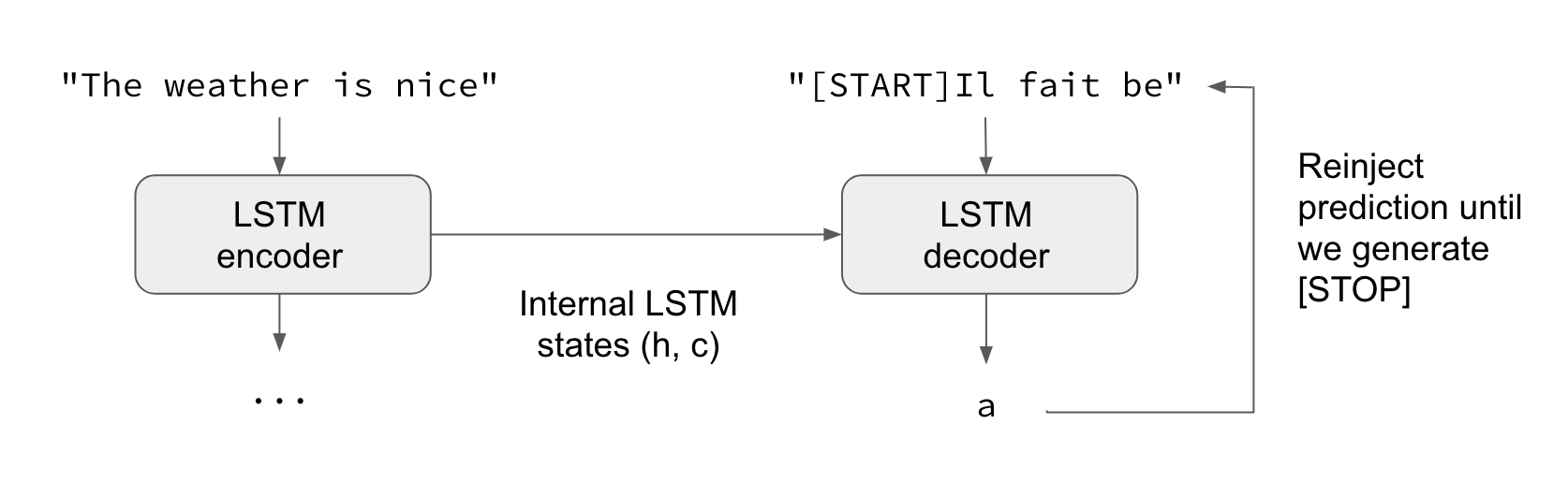
也可以使用相同的過程來訓練Seq2Seq網絡,而不需要“教師強制”,即通過將解碼器的預測重新輸入到解碼器中。
讓我們用實際的程式碼來說明這些想法。
為了實現我們的範例,我們將使用英語句子對應的中文語句翻譯的數據集,您可以從[manythings.org/anki]下載這些數據集。 要下載的文件被稱為cmn-eng.zip(簡中對應到英文)。為了更貼近學習的效果, 我己經把簡中轉成了繁中的版本(cmn-tw.txt),可以從Github上取得這個資料檔。我們將實現一個字符級(character-level)的序列到序列模型,逐個字符地處理輸入,並逐個字符地產生輸出。另一個選擇是一個字級(word-level)模型,這個模型往往是機器翻譯更常見的。在這篇文章的最後,你會發現一些關於使用嵌入圖層(embedding layers)將我們的模型轉換為字級模型的參考連結。
以下是我們的流程總結:
- 將句子(sentence)轉換為3個Numpy數組,
encoder_input_data,decoder_input_data,decoder_target_data:
encoder_input_data是包含英文句子的one-hot向量化的三維形狀數組(num_pairs, max_english_sentence_length, num_english_characters)。decoder_input_data是包含中文句子的one-hot向量化的三維形狀數組(num_pairs, max_chinese_sentence_length, num_chinese_characters)。decoder_target_data與decoder_input_data相同,但是偏移了一個時間步長。decoder_target_data[:,t,:]將與decoder_input_data[:,t+1,:]相同。
- 訓練一個基本的基於LSTM的Seq2Seq模型來預測給出
encoder_input_data和decoder_input_data的decoder_target_data。我們的模型使用教師強制(teacher forcing)的手法。 - 解碼一些句子以檢查模型是否正常工作(將來自
encoder_input_data的樣本轉換為來自decoder_target_data的對應樣本)。
整個網絡的架構構建可以參考以下的圖示:

STEP 1. 引入相關的函數庫¶
from keras.models import Model
from keras.layers import Input, LSTM, Dense
import numpy as np
import os
# 專案的根目錄路徑
ROOT_DIR = os.getcwd()
# 置放訓練資料的目錄
DATA_PATH = os.path.join(ROOT_DIR, "data")
# 訓練資料檔
DATA_FILE = os.path.join(DATA_PATH, "cmn-tw.txt")
STEP 2. 相關的參數¶
batch_size = 64 # 訓練時的批次數量
epochs = 100 # 訓練循環數
latent_dim = 256 # 編碼後的潛在空間的維度(dimensions of latent space)
num_samples = 10000 # 用來訓練的樣本數
STEP 3.資料的前處理¶
# 資料向量化
input_texts = []
target_texts = []
input_characters = set() # 英文字符集
target_characters = set() # 中文字符集
lines = open(DATA_FILE, mode="r", encoding="utf-8").read().split('\n')
# 逐行的讀取與處理
for line in lines[: min(num_samples, len(lines)-1)]:
input_text, target_text = line.split('\t')
# 我們使用“tab”作為“開始序列[SOS]”字符或目標,“\n”作為“結束序列[EOS]”字符。 <-- **重要
target_text = '\t' + target_text + '\n'
input_texts.append(input_text)
target_texts.append(target_text)
for char in input_text:
if char not in input_characters:
input_characters.add(char)
for char in target_text:
if char not in target_characters:
target_characters.add(char)
input_characters = sorted(list(input_characters)) # 全部輸入的字符集
target_characters = sorted(list(target_characters)) # 全部目標字符集
num_encoder_tokens = len(input_characters) # 所有輸入字符的數量
num_decoder_tokens = len(target_characters) # 所有輸目標字符的數量
max_encoder_seq_length = max([len(txt) for txt in input_texts]) # 最長的輸入句子長度
max_decoder_seq_length = max([len(txt) for txt in target_texts]) # 最長的目標句子長度
print('Number of samples:', len(input_texts))
print('Number of unique input tokens:', num_encoder_tokens)
print('Number of unique output tokens:', num_decoder_tokens)
print('Max sequence length for inputs:', max_encoder_seq_length)
print('Max sequence length for outputs:', max_decoder_seq_length)
# 輸入字符的索引字典
input_token_index = dict(
[(char, i) for i, char in enumerate(input_characters)])
# 輸目標字符的索引字典
target_token_index = dict(
[(char, i) for i, char in enumerate(target_characters)])
# 包含英文句子的one-hot向量化的三維形狀數組(num_pairs,max_english_sentence_length,num_english_characters)
encoder_input_data = np.zeros(
(len(input_texts), max_encoder_seq_length, num_encoder_tokens),
dtype='float32')
# 包含中文句子的one-hot向量化的三維形狀數組(num_pairs,max_chinese_sentence_length,num_chinese_characters)
decoder_input_data = np.zeros(
(len(input_texts), max_decoder_seq_length, num_decoder_tokens),
dtype='float32')
# decoder_target_data與decoder_input_data相同,但是偏移了一個時間步長。
# decoder_target_data [:, t,:]將與decoder_input_data [:,t + 1,:]相同
decoder_target_data = np.zeros(
(len(input_texts), max_decoder_seq_length, num_decoder_tokens),
dtype='float32')
# 把資料轉換成要用來訓練用的張量資料結構 <-- 重要
for i, (input_text, target_text) in enumerate(zip(input_texts, target_texts)):
for t, char in enumerate(input_text):
encoder_input_data[i, t, input_token_index[char]] = 1.
for t, char in enumerate(target_text):
# decoder_target_data is ahead of decoder_input_data by one timestep
decoder_input_data[i, t, target_token_index[char]] = 1.
if t > 0:
# decoder_target_data will be ahead by one timestep
# and will not include the start character.
decoder_target_data[i, t - 1, target_token_index[char]] = 1.
Number of samples: 10000 Number of unique input tokens: 73 Number of unique output tokens: 2165 Max sequence length for inputs: 33 Max sequence length for outputs: 22
STEP 4.構建網絡架構¶
# ===== 編碼 (encoder) ====
# 定義輸入的序列
# 注意:因為輸入序列長度(timesteps)可變的情況,使用input_shape =(None,num_features)
encoder_inputs = Input(shape=(None, num_encoder_tokens), name='encoder_input')
encoder = LSTM(latent_dim, return_state=True, name='encoder_lstm') # 需要取得LSTM的內部state, 因此設定"return_state=True"
encoder_outputs, state_h, state_c = encoder(encoder_inputs)
# 我們拋棄掉`encoder_outputs`因為我們只需要LSTM cell的內部state參數
encoder_states = [state_h, state_c]
# ==== 解碼 (decoder) ====
# 設定解碼器(decoder)
# 注意:因為輸出序列的長度(timesteps)是變動的,使用input_shape =(None,num_features)
decoder_inputs = Input(shape=(None, num_decoder_tokens), name='decoder_input')
# 我們設定我們的解碼器回傳整個輸出的序列同時也回傳內部的states參數
decoder_lstm = LSTM(latent_dim, return_sequences=True, return_state=True, name='decoder_lstm')
# 在訓練時我們不會使用這些回傳的states, 但是在預測時我們會用到這些states參數
# **解碼器的初始狀態是使用編碼器的最後的狀態(states)**
decoder_outputs, _, _ = decoder_lstm(decoder_inputs,
initial_state=encoder_states) #我們使用`encoder_states`來做為初始值(initial state) <-- 重要
# 接密集層(dense)來進行softmax運算每一個字符可能的機率
decoder_dense = Dense(num_decoder_tokens, activation='softmax', name='decoder_output')
decoder_outputs = decoder_dense(decoder_outputs)
# 定義一個模型接收encoder_input_data` & `decoder_input_data`做為輸入而輸出`decoder_target_data`
model = Model([encoder_inputs, decoder_inputs], decoder_outputs)
# 打印出模型結構
model.summary()
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
encoder_input (InputLayer) (None, None, 73) 0
__________________________________________________________________________________________________
decoder_input (InputLayer) (None, None, 2165) 0
__________________________________________________________________________________________________
encoder_lstm (LSTM) [(None, 256), (None, 337920 encoder_input[0][0]
__________________________________________________________________________________________________
decoder_lstm (LSTM) [(None, None, 256), 2480128 decoder_input[0][0]
encoder_lstm[0][1]
encoder_lstm[0][2]
__________________________________________________________________________________________________
decoder_output (Dense) (None, None, 2165) 556405 decoder_lstm[0][0]
==================================================================================================
Total params: 3,374,453
Trainable params: 3,374,453
Non-trainable params: 0
__________________________________________________________________________________________________
from keras.utils import plot_model
from IPython.display import Image
# 產生網絡拓撲圖
plot_model(model, to_file='seq2seq_graph.png')
Image('seq2seq_graph.png')

STEP 5.訓練模型¶
# 設定模型超參數
model.compile(optimizer='rmsprop', loss='categorical_crossentropy')
# 開始訓練
model.fit([encoder_input_data, decoder_input_data], decoder_target_data,
batch_size=batch_size,
epochs=epochs,
validation_split=0.2)
# 儲存模型
model.save('s2s.h5')
Train on 8000 samples, validate on 2000 samples Epoch 1/100 8000/8000 [==============================] - 10s 1ms/step - loss: 1.9829 - val_loss: 2.4389 Epoch 2/100 8000/8000 [==============================] - 8s 975us/step - loss: 1.8537 - val_loss: 2.3435 Epoch 3/100 8000/8000 [==============================] - 8s 979us/step - loss: 1.7435 - val_loss: 2.2536 Epoch 4/100 8000/8000 [==============================] - 8s 1ms/step - loss: 1.6472 - val_loss: 2.1720 Epoch 5/100 8000/8000 [==============================] - 8s 998us/step - loss: 1.5625 - val_loss: 2.0774 Epoch 6/100 8000/8000 [==============================] - 8s 1ms/step - loss: 1.4880 - val_loss: 2.0484 Epoch 7/100 8000/8000 [==============================] - 8s 992us/step - loss: 1.4232 - val_loss: 1.9879 Epoch 8/100 8000/8000 [==============================] - 8s 988us/step - loss: 1.3615 - val_loss: 1.9317 Epoch 9/100 8000/8000 [==============================] - 8s 976us/step - loss: 1.3076 - val_loss: 1.8757 Epoch 10/100 8000/8000 [==============================] - 8s 973us/step - loss: 1.2638 - val_loss: 1.8554 Epoch 11/100 8000/8000 [==============================] - 8s 995us/step - loss: 1.2198 - val_loss: 1.8237 Epoch 12/100 8000/8000 [==============================] - 8s 988us/step - loss: 1.1824 - val_loss: 1.8005 Epoch 13/100 8000/8000 [==============================] - 8s 992us/step - loss: 1.1469 - val_loss: 1.7941 Epoch 14/100 8000/8000 [==============================] - 8s 996us/step - loss: 1.1114 - val_loss: 1.7713 Epoch 15/100 8000/8000 [==============================] - 8s 976us/step - loss: 1.0787 - val_loss: 1.7613 Epoch 16/100 8000/8000 [==============================] - 8s 984us/step - loss: 1.0488 - val_loss: 1.7438 Epoch 17/100 8000/8000 [==============================] - 8s 974us/step - loss: 1.0203 - val_loss: 1.7418 Epoch 18/100 8000/8000 [==============================] - 8s 987us/step - loss: 0.9918 - val_loss: 1.7386 Epoch 19/100 8000/8000 [==============================] - 8s 991us/step - loss: 0.9660 - val_loss: 1.7267 Epoch 20/100 8000/8000 [==============================] - 8s 1ms/step - loss: 0.9398 - val_loss: 1.7283 Epoch 21/100 8000/8000 [==============================] - 8s 992us/step - loss: 0.9131 - val_loss: 1.7163 Epoch 22/100 8000/8000 [==============================] - 8s 988us/step - loss: 0.8890 - val_loss: 1.7248 Epoch 23/100 8000/8000 [==============================] - 8s 1ms/step - loss: 0.8657 - val_loss: 1.7248 Epoch 24/100 8000/8000 [==============================] - 8s 996us/step - loss: 0.8416 - val_loss: 1.7170 Epoch 25/100 8000/8000 [==============================] - 8s 988us/step - loss: 0.8197 - val_loss: 1.7226 Epoch 26/100 8000/8000 [==============================] - 8s 998us/step - loss: 0.7981 - val_loss: 1.7321 Epoch 27/100 8000/8000 [==============================] - 8s 1ms/step - loss: 0.7783 - val_loss: 1.7290 Epoch 28/100 8000/8000 [==============================] - 8s 988us/step - loss: 0.7576 - val_loss: 1.7283 Epoch 29/100 8000/8000 [==============================] - 8s 1ms/step - loss: 0.7374 - val_loss: 1.7356 Epoch 30/100 8000/8000 [==============================] - 8s 978us/step - loss: 0.7193 - val_loss: 1.7331 Epoch 31/100 8000/8000 [==============================] - 8s 1ms/step - loss: 0.7000 - val_loss: 1.7490 Epoch 32/100 8000/8000 [==============================] - 8s 998us/step - loss: 0.6823 - val_loss: 1.7447 Epoch 33/100 8000/8000 [==============================] - 8s 988us/step - loss: 0.6643 - val_loss: 1.7392 Epoch 34/100 8000/8000 [==============================] - 8s 992us/step - loss: 0.6465 - val_loss: 1.7528 Epoch 35/100 8000/8000 [==============================] - 8s 996us/step - loss: 0.6305 - val_loss: 1.7575 Epoch 36/100 8000/8000 [==============================] - 8s 1ms/step - loss: 0.6143 - val_loss: 1.7546 Epoch 37/100 8000/8000 [==============================] - 8s 1ms/step - loss: 0.5979 - val_loss: 1.7673 Epoch 38/100 8000/8000 [==============================] - 8s 1ms/step - loss: 0.5822 - val_loss: 1.7846 Epoch 39/100 8000/8000 [==============================] - 8s 990us/step - loss: 0.5678 - val_loss: 1.7974 Epoch 40/100 8000/8000 [==============================] - 8s 996us/step - loss: 0.5528 - val_loss: 1.7874 Epoch 41/100 8000/8000 [==============================] - 8s 988us/step - loss: 0.5390 - val_loss: 1.7983 Epoch 42/100 8000/8000 [==============================] - 8s 980us/step - loss: 0.5263 - val_loss: 1.8070 Epoch 43/100 8000/8000 [==============================] - 8s 992us/step - loss: 0.5123 - val_loss: 1.8127 Epoch 44/100 8000/8000 [==============================] - 8s 994us/step - loss: 0.4993 - val_loss: 1.8130 Epoch 45/100 8000/8000 [==============================] - 8s 1ms/step - loss: 0.4870 - val_loss: 1.8185 Epoch 46/100 8000/8000 [==============================] - 8s 996us/step - loss: 0.4748 - val_loss: 1.8358 Epoch 47/100 8000/8000 [==============================] - 8s 990us/step - loss: 0.4635 - val_loss: 1.8333 Epoch 48/100 8000/8000 [==============================] - 8s 1ms/step - loss: 0.4512 - val_loss: 1.8440 Epoch 49/100 8000/8000 [==============================] - 8s 1ms/step - loss: 0.4402 - val_loss: 1.8451 Epoch 50/100 8000/8000 [==============================] - 8s 999us/step - loss: 0.4290 - val_loss: 1.8525 Epoch 51/100 8000/8000 [==============================] - 8s 990us/step - loss: 0.4182 - val_loss: 1.8656 Epoch 52/100 8000/8000 [==============================] - 8s 998us/step - loss: 0.4083 - val_loss: 1.8839 Epoch 53/100 8000/8000 [==============================] - 8s 993us/step - loss: 0.3982 - val_loss: 1.8905 Epoch 54/100 8000/8000 [==============================] - 8s 1ms/step - loss: 0.3881 - val_loss: 1.8920 Epoch 55/100 8000/8000 [==============================] - 8s 1ms/step - loss: 0.3787 - val_loss: 1.8985 Epoch 56/100 8000/8000 [==============================] - 8s 991us/step - loss: 0.3697 - val_loss: 1.9039 Epoch 57/100 8000/8000 [==============================] - 8s 988us/step - loss: 0.3608 - val_loss: 1.9082 Epoch 58/100 8000/8000 [==============================] - 8s 987us/step - loss: 0.3525 - val_loss: 1.9121 Epoch 59/100 8000/8000 [==============================] - 8s 992us/step - loss: 0.3441 - val_loss: 1.9194 Epoch 60/100 8000/8000 [==============================] - 8s 983us/step - loss: 0.3347 - val_loss: 1.9338 Epoch 61/100 8000/8000 [==============================] - 8s 1ms/step - loss: 0.3270 - val_loss: 1.9478 Epoch 62/100 8000/8000 [==============================] - 8s 983us/step - loss: 0.3192 - val_loss: 1.9383 Epoch 63/100 8000/8000 [==============================] - 8s 998us/step - loss: 0.3114 - val_loss: 1.9512 Epoch 64/100 8000/8000 [==============================] - 8s 996us/step - loss: 0.3046 - val_loss: 1.9562 Epoch 65/100 8000/8000 [==============================] - 8s 986us/step - loss: 0.2970 - val_loss: 1.9666 Epoch 66/100 8000/8000 [==============================] - 8s 989us/step - loss: 0.2905 - val_loss: 1.9733 Epoch 67/100 8000/8000 [==============================] - 8s 1ms/step - loss: 0.2846 - val_loss: 1.9765 Epoch 68/100 8000/8000 [==============================] - 8s 1ms/step - loss: 0.2743 - val_loss: 1.9953 Epoch 69/100 8000/8000 [==============================] - 8s 1ms/step - loss: 0.2688 - val_loss: 2.0060 Epoch 70/100 8000/8000 [==============================] - 8s 981us/step - loss: 0.2632 - val_loss: 2.0008 Epoch 71/100 8000/8000 [==============================] - 8s 984us/step - loss: 0.2570 - val_loss: 2.0049 Epoch 72/100 8000/8000 [==============================] - 8s 984us/step - loss: 0.2501 - val_loss: 2.0082 Epoch 73/100 8000/8000 [==============================] - 8s 992us/step - loss: 0.2447 - val_loss: 2.0196 Epoch 74/100 8000/8000 [==============================] - 8s 987us/step - loss: 0.2384 - val_loss: 2.0287 Epoch 75/100 8000/8000 [==============================] - 8s 998us/step - loss: 0.2325 - val_loss: 2.0356 Epoch 76/100 8000/8000 [==============================] - 8s 1ms/step - loss: 0.2270 - val_loss: 2.0414 Epoch 77/100 8000/8000 [==============================] - 8s 988us/step - loss: 0.2209 - val_loss: 2.0477 Epoch 78/100 8000/8000 [==============================] - 8s 997us/step - loss: 0.2157 - val_loss: 2.0530 Epoch 79/100 8000/8000 [==============================] - 8s 985us/step - loss: 0.2108 - val_loss: 2.0583 Epoch 80/100 8000/8000 [==============================] - 8s 1ms/step - loss: 0.2053 - val_loss: 2.0610 Epoch 81/100 8000/8000 [==============================] - 8s 1ms/step - loss: 0.2047 - val_loss: 2.0742 Epoch 82/100 8000/8000 [==============================] - 8s 995us/step - loss: 0.1951 - val_loss: 2.0844 Epoch 83/100 8000/8000 [==============================] - 8s 988us/step - loss: 0.1905 - val_loss: 2.0889 Epoch 84/100 8000/8000 [==============================] - 8s 984us/step - loss: 0.1858 - val_loss: 2.1018 Epoch 85/100 8000/8000 [==============================] - 8s 984us/step - loss: 0.1809 - val_loss: 2.1055 Epoch 86/100 8000/8000 [==============================] - 8s 979us/step - loss: 0.1763 - val_loss: 2.1158 Epoch 87/100 8000/8000 [==============================] - 8s 987us/step - loss: 0.1710 - val_loss: 2.1169 Epoch 88/100 8000/8000 [==============================] - 8s 998us/step - loss: 0.1687 - val_loss: 2.1181 Epoch 89/100 8000/8000 [==============================] - 8s 985us/step - loss: 0.1627 - val_loss: 2.1390 Epoch 90/100 8000/8000 [==============================] - 8s 1ms/step - loss: 0.1588 - val_loss: 2.1428 Epoch 91/100 8000/8000 [==============================] - 8s 999us/step - loss: 0.1538 - val_loss: 2.1437 Epoch 92/100 8000/8000 [==============================] - 8s 1ms/step - loss: 0.1509 - val_loss: 2.1550 Epoch 93/100 8000/8000 [==============================] - 8s 996us/step - loss: 0.1464 - val_loss: 2.1528 Epoch 94/100 8000/8000 [==============================] - 8s 1ms/step - loss: 0.1424 - val_loss: 2.1584 Epoch 95/100 8000/8000 [==============================] - 8s 991us/step - loss: 0.1383 - val_loss: 2.1770 Epoch 96/100 8000/8000 [==============================] - 8s 1ms/step - loss: 0.1348 - val_loss: 2.1693 Epoch 97/100 8000/8000 [==============================] - 8s 989us/step - loss: 0.1310 - val_loss: 2.1808 Epoch 98/100 8000/8000 [==============================] - 8s 977us/step - loss: 0.1272 - val_loss: 2.1906 Epoch 99/100 8000/8000 [==============================] - 8s 990us/step - loss: 0.1233 - val_loss: 2.1884 Epoch 100/100 8000/8000 [==============================] - 8s 995us/step - loss: 0.1200 - val_loss: 2.1978
C:\Users\8703147\AppData\Local\Continuum\anaconda3\envs\ml\lib\site-packages\keras\engine\topology.py:2344: UserWarning: Layer decoder_lstm was passed non-serializable keyword arguments: {'initial_state': [<tf.Tensor 'encoder_lstm/while/Exit_2:0' shape=(?, 256) dtype=float32>, <tf.Tensor 'encoder_lstm/while/Exit_3:0' shape=(?, 256) dtype=float32>]}. They will not be included in the serialized model (and thus will be missing at deserialization time).
str(node.arguments) + '. They will not be included '
STEP 6.模型預測¶
以下是預測階段的步驟:
- 對輸入進行編碼(encode)並取得解碼器所需要的初始狀態(initial decoder state)
- 以此初始狀態運行一步解碼器,並以“開始序列”標記作為目標。輸出將是下一個目標標記
- 重複當前目標標記和當前狀態
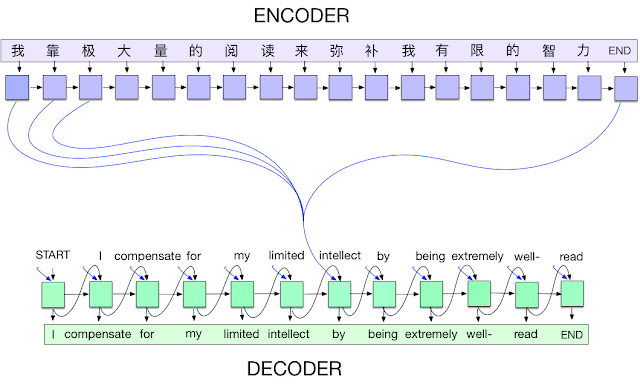
# 定義要進行取樣的模型
# 定義編碼器(encoder)的模型
encoder_model = Model(encoder_inputs, encoder_states)
# 定義解碼器LSTM cell的初始權重輸入
decoder_state_input_h = Input(shape=(latent_dim,))
decoder_state_input_c = Input(shape=(latent_dim,))
decoder_states_inputs = [decoder_state_input_h, decoder_state_input_c]
# # 解碼器(decoder)定義初始狀態(initial decoder state)
decoder_outputs, state_h, state_c = decoder_lstm(
decoder_inputs, initial_state=decoder_states_inputs) #我們使用`decoder_states_inputs`來做為初始值(initial state)
decoder_states = [state_h, state_c]
decoder_outputs = decoder_dense(decoder_outputs)
# 定義解碼器(decoder)的模型
decoder_model = Model(
[decoder_inputs] + decoder_states_inputs,
[decoder_outputs] + decoder_states)
# 反向查找字符索引來將序列解碼為可讀的內容。
reverse_input_char_index = dict(
(i, char) for char, i in input_token_index.items())
reverse_target_char_index = dict(
(i, char) for char, i in target_token_index.items())
# 對序列進行解碼
def decode_sequence(input_seq):
# 將輸入編碼成為state向量
states_value = encoder_model.predict(input_seq)
# 產生長度為1的空白目標序列
target_seq = np.zeros((1, 1, num_decoder_tokens))
# 發佈特定的目標序列起始字符"[SOS]",在這個範例中是使用 "\t"字符
target_seq[0, 0, target_token_index['\t']] = 1.
# 對批次的序列進行抽樣迴圈
stop_condition = False
decoded_sentence = ''
while not stop_condition:
output_tokens, h, c = decoder_model.predict(
[target_seq] + states_value)
# 對符標抽樣
sampled_token_index = np.argmax(output_tokens[0, -1, :])
sampled_char = reverse_target_char_index[sampled_token_index]
decoded_sentence += sampled_char
# 停止迴圈的條件: 到達最大的長度或是找到"停止[EOS]"字符,在這個範例中是使用 "\n"字符
if (sampled_char == '\n' or
len(decoded_sentence) > max_decoder_seq_length):
stop_condition = True
# 更新目標序列(of length 1).
target_seq = np.zeros((1, 1, num_decoder_tokens))
target_seq[0, 0, sampled_token_index] = 1.
# 更新 states
states_value = [h, c]
return decoded_sentence
for seq_index in range(100):
# 從訓練集中取出一個序列並試著解碼
input_seq = encoder_input_data[seq_index: seq_index + 1]
decoded_sentence = decode_sequence(input_seq)
print('-')
print('Input sentence:', input_texts[seq_index])
print('Decoded sentence:', decoded_sentence)
- Input sentence: Hi. Decoded sentence: 你好。 - Input sentence: Hi. Decoded sentence: 你好。 - Input sentence: Run. Decoded sentence: 你用跑的。 - Input sentence: Wait! Decoded sentence: 等等! - Input sentence: Hello! Decoded sentence: 你好。 - Input sentence: I try. Decoded sentence: 讓我來。 - Input sentence: I won! Decoded sentence: 我贏了。 - Input sentence: Oh no! Decoded sentence: 不會吧。 - Input sentence: Cheers! Decoded sentence: 乾杯! - Input sentence: He ran. Decoded sentence: 他跑了。 - Input sentence: Hop in. Decoded sentence: 等一下! - Input sentence: I lost. Decoded sentence: 我吃了這個蘋果。 - Input sentence: I quit. Decoded sentence: 我退出。 - Input sentence: I'm OK. Decoded sentence: 我沒事。 - Input sentence: Listen. Decoded sentence: 聽著。 - Input sentence: No way! Decoded sentence: 沒門! - Input sentence: No way! Decoded sentence: 沒門! - Input sentence: Really? Decoded sentence: 你確定? - Input sentence: Try it. Decoded sentence: 一個您方的。 - Input sentence: We try. Decoded sentence: 我們來試試。 - Input sentence: Why me? Decoded sentence: 為什麼是我? - Input sentence: Ask Tom. Decoded sentence: 去問湯姆。 - Input sentence: Be calm. Decoded sentence: 冷靜點。 - Input sentence: Be fair. Decoded sentence: 公平點。 - Input sentence: Be kind. Decoded sentence: 放鬆點吧。 - Input sentence: Be nice. Decoded sentence: 和氣點。 - Input sentence: Call me. Decoded sentence: 聯繫我。 - Input sentence: Call us. Decoded sentence: 聯繫我們。 - Input sentence: Come in. Decoded sentence: 快點。 - Input sentence: Get Tom. Decoded sentence: 滾! - Input sentence: Get out! Decoded sentence: 滾出去! - Input sentence: Go away! Decoded sentence: 走開! - Input sentence: Go away! Decoded sentence: 走開! - Input sentence: Go away. Decoded sentence: 走開! - Input sentence: Goodbye! Decoded sentence: 你用跑的。 - Input sentence: Goodbye! Decoded sentence: 你用跑的。 - Input sentence: Hang on! Decoded sentence: 等一下! - Input sentence: He came. Decoded sentence: 他來了。 - Input sentence: He runs. Decoded sentence: 他跑。 - Input sentence: Help me. Decoded sentence: 幫我一下。 - Input sentence: Hold on. Decoded sentence: 堅持。 - Input sentence: Hug Tom. Decoded sentence: 抱抱湯姆! - Input sentence: I agree. Decoded sentence: 我同意。 - Input sentence: I'm ill. Decoded sentence: 我生病了。 - Input sentence: I'm old. Decoded sentence: 我生病了。 - Input sentence: It's OK. Decoded sentence: 沒關係。 - Input sentence: It's me. Decoded sentence: 是該上個的子。 - Input sentence: Join us. Decoded sentence: 來加入我們吧。 - Input sentence: Keep it. Decoded sentence: 留著吧。 - Input sentence: Kiss me. Decoded sentence: 吻我。 - Input sentence: Perfect! Decoded sentence: 完美! - Input sentence: See you. Decoded sentence: 再見! - Input sentence: Shut up! Decoded sentence: 閉嘴! - Input sentence: Skip it. Decoded sentence: 不管它。 - Input sentence: Take it. Decoded sentence: 拿走吧。 - Input sentence: Wake up! Decoded sentence: 醒醒! - Input sentence: Wash up. Decoded sentence: 去清洗一下。 - Input sentence: We know. Decoded sentence: 我們什麼都沒? - Input sentence: Welcome. Decoded sentence: 歡迎。 - Input sentence: Who won? Decoded sentence: 誰贏了? - Input sentence: Why not? Decoded sentence: 為什麼不? - Input sentence: You run. Decoded sentence: 你跑。 - Input sentence: Back off. Decoded sentence: 你用跑的。 - Input sentence: Be still. Decoded sentence: 靜靜的,別動。 - Input sentence: Cuff him. Decoded sentence: 把他銬上。 - Input sentence: Drive on. Decoded sentence: 往前開。 - Input sentence: Get away! Decoded sentence: 滾! - Input sentence: Get away! Decoded sentence: 滾! - Input sentence: Get down! Decoded sentence: 趴下! - Input sentence: Get lost! Decoded sentence: 滾! - Input sentence: Get real. Decoded sentence: 醒醒吧。 - Input sentence: Grab Tom. Decoded sentence: 抓住湯姆。 - Input sentence: Grab him. Decoded sentence: 抓住他。 - Input sentence: Have fun. Decoded sentence: 玩得開心。 - Input sentence: He tries. Decoded sentence: 他很容易。 - Input sentence: Humor me. Decoded sentence: 你就是湯姆的主意。 - Input sentence: Hurry up. Decoded sentence: 趕快! - Input sentence: Hurry up. Decoded sentence: 趕快! - Input sentence: I forgot. Decoded sentence: 我忘了。 - Input sentence: I resign. Decoded sentence: 我放棄。 - Input sentence: I'll pay. Decoded sentence: 我來付錢。 - Input sentence: I'm busy. Decoded sentence: 我很忙。 - Input sentence: I'm cold. Decoded sentence: 我生病了。 - Input sentence: I'm fine. Decoded sentence: 我很好。 - Input sentence: I'm full. Decoded sentence: 我吃飽了。 - Input sentence: I'm sick. Decoded sentence: 我生病了。 - Input sentence: I'm sick. Decoded sentence: 我生病了。 - Input sentence: Leave me. Decoded sentence: 讓我一個人呆會兒。 - Input sentence: Let's go! Decoded sentence: 我們開始吧! - Input sentence: Let's go! Decoded sentence: 我們開始吧! - Input sentence: Let's go! Decoded sentence: 我們開始吧! - Input sentence: Look out! Decoded sentence: 當心! - Input sentence: She runs. Decoded sentence: 她試過了。 - Input sentence: Stand up. Decoded sentence: 起立。 - Input sentence: They won. Decoded sentence: 他們不錯。 - Input sentence: Tom died. Decoded sentence: 湯姆去世了。 - Input sentence: Tom quit. Decoded sentence: 湯姆不干了。 - Input sentence: Tom swam. Decoded sentence: 湯姆游泳了。 - Input sentence: Trust me. Decoded sentence: 相信我。 - Input sentence: Try hard. Decoded sentence: 努力。
MIT License
Copyright (c) 2018 Erhwen Kuo
Copyright (c) 2017 François Chollet
Permission is hereby granted, free of charge, to any person obtaining a copy of this software and associated documentation files (the "Software"), to deal in the Software without restriction, including without limitation the rights to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the Software, and to permit persons to whom the Software is furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.