從零開始構建VGG網絡來學習Keras¶
Keras使得創建深度學習模型變得快速而簡單, 雖然如此很多時候我們只要複製許多官網的範例就 可做出很多令人覺得驚奇的結果。但是當要解決的問題需要進行一些模型的調整與優化或是需要構 建出一個新論文的網絡結構的時候, 我們就可能會左支右拙的難以招架。
在本教程中,您將通過閱讀VGG的原始論文從零開始使用Keras來構建在ILSVRC-2014 (ImageNet competition)競賽中獲的第一名的VGG (Visual Geometry Group, University of Oxford)網絡結構。
那麼,重新構建別人已經構建的東西有什麼意義呢?重點是學習。通過完成這次的練習,您將:
- 了解更多關於VGG的架構
- 了解有關卷積神經網絡的更多信息
- 了解如何在Keras中實施某種網絡結構
- 通過閱讀論文並實施其中的某些部分可以了解更多底層的原理與原始構想
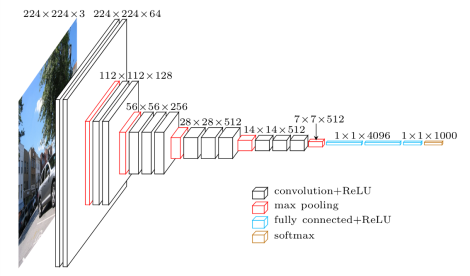
為什麼從VGG開始?¶
- 它很容易實現
- 它在ILSVRC-2014(ImageNet競賽)上取得了優異的成績
- 它今天被廣泛使用
- 它的論文簡單易懂
- Keras己經實現VGG在散佈的版本中,所以你可以用來參考與比較
讓我們從論文中挖寶¶
在VGG的論文-VERY DEEP CONVOLUTIONAL NETWORKS FOR LARGE-SCALE IMAGE RECOGNITION的2.3章節中提到了以下幾種VGG的網絡結構:
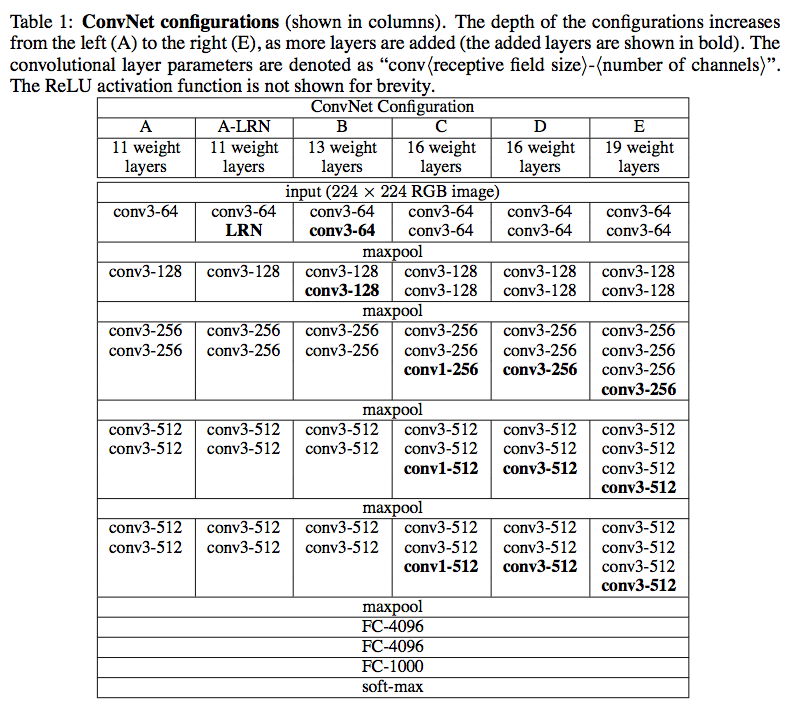
根據論文的測試給果 D (VGG16)與 E (VGG19) 是效果最好的, 由於這兩種網絡構建的方法與技巧幾乎相同, 因此我們選手構建D (VGG16)這個網絡結構類型。
在2.1章節中論述了詳細的卷積層的相關訊息:

歸納一下論文網絡構建訊息:
- 輸入圖像尺寸(
input size):224 x 224 - 感受過瀘器(
receptive field)的大小是3 x 3 - 卷積步長(
stride)是1個像素 - 填充(
padding)是1(對於3 x 3的感受過瀘器) - 池化層的大小是2×2且步長(
stride)為2像素 - 有兩個完全連接層,每層4096個神經元
- 最後一層是具有1000個神經元的
softmax分類層(代表1000個ImageNet類別) - 激勵函數是
ReLU
# 這個Jupyter Notebook的環境
import platform
import tensorflow
import keras
print("Platform: {}".format(platform.platform()))
print("Tensorflow version: {}".format(tensorflow.__version__))
print("Keras version: {}".format(keras.__version__))
%matplotlib inline
import matplotlib.pyplot as plt
import matplotlib.image as mpimg
import numpy as np
from IPython.display import Image
Using TensorFlow backend.
Platform: Windows-7-6.1.7601-SP1 Tensorflow version: 1.4.0 Keras version: 2.1.1
創建模型 (Sequential)¶
import keras
from keras.models import Sequential
from keras.layers import Dense, Activation, Dropout, Flatten
from keras.layers import Conv2D, MaxPool2D
from keras.utils import plot_model
# 定義輸入
input_shape = (224, 224, 3) # RGB影像224x224 (height, width, channel)
# 使用'序貫模型(Sequential)來定義
model = Sequential(name='vgg16-sequential')
# 第1個卷積區塊 (block1)
model.add(Conv2D(64, (3, 3), padding='same', activation='relu', input_shape=input_shape, name='block1_conv1'))
model.add(Conv2D(64, (3, 3), padding='same', activation='relu', name='block1_conv2'))
model.add(MaxPool2D((2, 2), strides=(2, 2), name='block1_pool'))
# 第2個卷積區塊 (block2)
model.add(Conv2D(128, (3, 3), padding='same', activation='relu', name='block2_conv1'))
model.add(Conv2D(128, (3, 3), padding='same', activation='relu', name='block2_conv2'))
model.add(MaxPool2D((2, 2), strides=(2, 2), name='block2_pool'))
# 第3個卷積區塊 (block3)
model.add(Conv2D(256, (3, 3), padding='same', activation='relu', name='block3_conv1'))
model.add(Conv2D(256, (3, 3), padding='same', activation='relu', name='block3_conv2'))
model.add(Conv2D(256, (3, 3), padding='same', activation='relu', name='block3_conv3'))
model.add(MaxPool2D((2, 2), strides=(2, 2), name='block3_pool'))
# 第4個卷積區塊 (block4)
model.add(Conv2D(512, (3, 3), padding='same', activation='relu', name='block4_conv1'))
model.add(Conv2D(512, (3, 3), padding='same', activation='relu', name='block4_conv2'))
model.add(Conv2D(512, (3, 3), padding='same', activation='relu', name='block4_conv3'))
model.add(MaxPool2D((2, 2), strides=(2, 2), name='block4_pool'))
# 第5個卷積區塊 (block5)
model.add(Conv2D(512, (3, 3), padding='same', activation='relu', name='block5_conv1'))
model.add(Conv2D(512, (3, 3), padding='same', activation='relu', name='block5_conv2'))
model.add(Conv2D(512, (3, 3), padding='same', activation='relu', name='block5_conv3'))
model.add(MaxPool2D((2, 2), strides=(2, 2), name='block5_pool'))
# 前饋全連接區塊
model.add(Flatten(name='flatten'))
model.add(Dense(4096, activation='relu', name='fc1'))
model.add(Dense(4096, activation='relu', name='fc2'))
model.add(Dense(1000, activation='softmax', name='predictions'))
# 打印網絡結構
model.summary()
_________________________________________________________________ Layer (type) Output Shape Param # ================================================================= block1_conv1 (Conv2D) (None, 224, 224, 64) 1792 _________________________________________________________________ block1_conv2 (Conv2D) (None, 224, 224, 64) 36928 _________________________________________________________________ block1_pool (MaxPooling2D) (None, 112, 112, 64) 0 _________________________________________________________________ block2_conv1 (Conv2D) (None, 112, 112, 128) 73856 _________________________________________________________________ block2_conv2 (Conv2D) (None, 112, 112, 128) 147584 _________________________________________________________________ block2_pool (MaxPooling2D) (None, 56, 56, 128) 0 _________________________________________________________________ block3_conv1 (Conv2D) (None, 56, 56, 256) 295168 _________________________________________________________________ block3_conv2 (Conv2D) (None, 56, 56, 256) 590080 _________________________________________________________________ block3_conv3 (Conv2D) (None, 56, 56, 256) 590080 _________________________________________________________________ block3_pool (MaxPooling2D) (None, 28, 28, 256) 0 _________________________________________________________________ block4_conv1 (Conv2D) (None, 28, 28, 512) 1180160 _________________________________________________________________ block4_conv2 (Conv2D) (None, 28, 28, 512) 2359808 _________________________________________________________________ block4_conv3 (Conv2D) (None, 28, 28, 512) 2359808 _________________________________________________________________ block4_pool (MaxPooling2D) (None, 14, 14, 512) 0 _________________________________________________________________ block5_conv1 (Conv2D) (None, 14, 14, 512) 2359808 _________________________________________________________________ block5_conv2 (Conv2D) (None, 14, 14, 512) 2359808 _________________________________________________________________ block5_conv3 (Conv2D) (None, 14, 14, 512) 2359808 _________________________________________________________________ block5_pool (MaxPooling2D) (None, 7, 7, 512) 0 _________________________________________________________________ flatten (Flatten) (None, 25088) 0 _________________________________________________________________ fc1 (Dense) (None, 4096) 102764544 _________________________________________________________________ fc2 (Dense) (None, 4096) 16781312 _________________________________________________________________ predictions (Dense) (None, 1000) 4097000 ================================================================= Total params: 138,357,544 Trainable params: 138,357,544 Non-trainable params: 0 _________________________________________________________________

import keras
from keras.models import Model
from keras.layers import Input, Dense, Activation, Dropout, Flatten
from keras.layers import Conv2D, MaxPool2D
# 定義輸入
input_shape = (224, 224, 3) # RGB影像224x224 (height, width, channel)
# 輸入層
img_input = Input(shape=input_shape, name='img_input')
# 第1個卷積區塊 (block1)
x = Conv2D(64, (3, 3), padding='same', activation='relu', name='block1_conv1')(img_input)
x = Conv2D(64, (3, 3), padding='same', activation='relu', name='block1_conv2')(x)
x = MaxPool2D((2, 2), strides=(2, 2), name='block1_pool')(x)
# 第2個卷積區塊 (block2)
x = Conv2D(128, (3, 3), padding='same', activation='relu', name='block2_conv1')(x)
x = Conv2D(128, (3, 3), padding='same', activation='relu', name='block2_conv2')(x)
x = MaxPool2D((2, 2), strides=(2, 2), name='block2_pool')(x)
# 第3個卷積區塊 (block3)
x = Conv2D(256, (3, 3), padding='same', activation='relu', name='block3_conv1')(x)
x = Conv2D(256, (3, 3), padding='same', activation='relu', name='block3_conv2')(x)
x = Conv2D(256, (3, 3), padding='same', activation='relu', name='block3_conv3')(x)
x = MaxPool2D((2, 2), strides=(2, 2), name='block3_pool')(x)
# 第4個卷積區塊 (block4)
x = Conv2D(512, (3, 3), padding='same', activation='relu', name='block4_conv1')(x)
x = Conv2D(512, (3, 3), padding='same', activation='relu', name='block4_conv2')(x)
x = Conv2D(512, (3, 3), padding='same', activation='relu', name='block4_conv3')(x)
x = MaxPool2D((2, 2), strides=(2, 2), name='block4_pool')(x)
# 第5個卷積區塊 (block5)
x = Conv2D(512, (3, 3), padding='same', activation='relu', name='block5_conv1')(x)
x = Conv2D(512, (3, 3), padding='same', activation='relu', name='block5_conv2')(x)
x = Conv2D(512, (3, 3), padding='same', activation='relu', name='block5_conv3')(x)
x = MaxPool2D((2, 2), strides=(2, 2), name='block5_pool')(x)
# 前饋全連接區塊
x = Flatten(name='flatten')(x)
x = Dense(4096, activation='relu', name='fc1')(x)
x = Dense(4096, activation='relu', name='fc2')(x)
x = Dense(1000, activation='softmax', name='predictions')(x)
# 產生模型
model2 = Model(inputs=img_input, outputs=x, name='vgg16-funcapi')
# 打印網絡結構
model2.summary()
_________________________________________________________________ Layer (type) Output Shape Param # ================================================================= img_input (InputLayer) (None, 224, 224, 3) 0 _________________________________________________________________ block1_conv1 (Conv2D) (None, 224, 224, 64) 1792 _________________________________________________________________ block1_conv2 (Conv2D) (None, 224, 224, 64) 36928 _________________________________________________________________ block1_pool (MaxPooling2D) (None, 112, 112, 64) 0 _________________________________________________________________ block2_conv1 (Conv2D) (None, 112, 112, 128) 73856 _________________________________________________________________ block2_conv2 (Conv2D) (None, 112, 112, 128) 147584 _________________________________________________________________ block2_pool (MaxPooling2D) (None, 56, 56, 128) 0 _________________________________________________________________ block3_conv1 (Conv2D) (None, 56, 56, 256) 295168 _________________________________________________________________ block3_conv2 (Conv2D) (None, 56, 56, 256) 590080 _________________________________________________________________ block3_conv3 (Conv2D) (None, 56, 56, 256) 590080 _________________________________________________________________ block3_pool (MaxPooling2D) (None, 28, 28, 256) 0 _________________________________________________________________ block4_conv1 (Conv2D) (None, 28, 28, 512) 1180160 _________________________________________________________________ block4_conv2 (Conv2D) (None, 28, 28, 512) 2359808 _________________________________________________________________ block4_conv3 (Conv2D) (None, 28, 28, 512) 2359808 _________________________________________________________________ block4_pool (MaxPooling2D) (None, 14, 14, 512) 0 _________________________________________________________________ block5_conv1 (Conv2D) (None, 14, 14, 512) 2359808 _________________________________________________________________ block5_conv2 (Conv2D) (None, 14, 14, 512) 2359808 _________________________________________________________________ block5_conv3 (Conv2D) (None, 14, 14, 512) 2359808 _________________________________________________________________ block5_pool (MaxPooling2D) (None, 7, 7, 512) 0 _________________________________________________________________ flatten (Flatten) (None, 25088) 0 _________________________________________________________________ fc1 (Dense) (None, 4096) 102764544 _________________________________________________________________ fc2 (Dense) (None, 4096) 16781312 _________________________________________________________________ predictions (Dense) (None, 1000) 4097000 ================================================================= Total params: 138,357,544 Trainable params: 138,357,544 Non-trainable params: 0 _________________________________________________________________
模型訓練¶
要用ImageNet的資料來訓練VGG16的模型則不是一件容易的事喔。
VGG論文指出:
On a system equipped with four NVIDIA Titan Black GPUs, training a single net took 2–3 weeks depending on the architecture.
也就是說就算你有四張NVIDIA的Titan網卡用Imagenet的影像集來訓練VGG16模型, 可能也得花個2-3星期。即使買的起這樣的硬體,你也得花蠻多的時間來訓練這個模型。
幸運的是Keras不僅己經在它的模組中包括了VGG16與VGG19的模型定義以外, 同時也幫大家預訓練好了VGG16與VGG19的模型權重。
詳請請見: keras.io
總結 (Conclusion)¶
在這篇文章中有一些個人學習到的一些有趣的重點:
- 在Keras中要建構一個網絡不難, 但了解這個網絡架構的原理則需要多一點耐心
- VGG16構建簡單效能高,真是神奇!
- VGG16在卷積層的設計是愈後面feature map的size愈小, 而過瀘器(receptive field/fiter/kernel)則愈多