Lecture 1: What is data science?¶
CSCI 1360E: Foundations for Informatics and Analytics
Overview and Objectives¶
In this lecture, we'll go over the basic principles of the field of data science and analytics. By the end of the lecture, you should be able to
- Broadly define "data science" and understand its role as an interdisciplinary field of study
- Answer what sets data science apart from "statisticians with computers"
- Identify the six major skill divisions of a data scientist
- Provide some justification for why there is a sudden interest and national need for trained data scientists
No programming just yet; this is mainly a history and background lesson.
Part 1: Data Science¶
At some point in the last few years, you've most likely stumbled across at least one of the many memes surrounding "big data" and "data science."

The level of ubiquity with which these terms have thoroughly saturated the tech sector's vernacular has rendered these terms almost meaningless. Indeed, many have argued that data science may very well not be anything new, but rather a rehashing and rebranding of ideas that did not gain traction previously, for whatever reason.
Before differentiating data science as a field unto itself and justifying its existence, I'll first offer a working definition. In my opinion, the most cogent and concise definition of data science is encapsulated in the following Venn diagram:
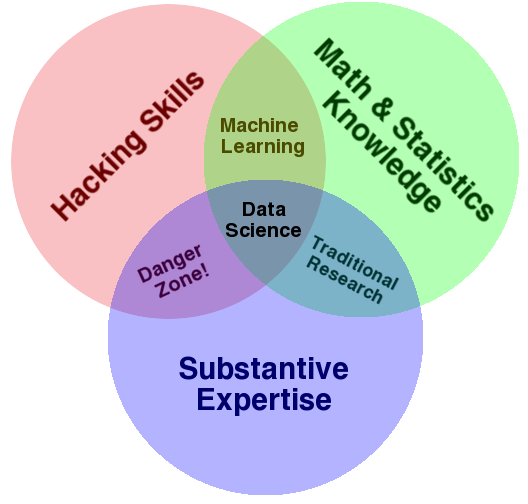
Data Science as a proper field of study is the confluence of three major aspects:
- Hacking skills: the ability to code, and knowledge of available tools.
- Math and statistics: strong quantitative skills that can be implemented in code.
- Substantive expertise: some specialized area of emphasis.
The third point is crucial to the overall definition of data science, and is also the reason that defining data science as a distinct field is so controversial. After all, isn't a data scientist whose substantive experience is biology just a quantitative biologist with strong programming skills?
I'll instantiate the answer to this question with a somewhat snarky data science definition I've stumbled across before:
Data Scientist (n.): Person who is better at statistics than any software engineer, and better at software engineering than any statistician.
Snarky, yes. But there is more than just a kernel of truth here.
Part 2: How is data science different?¶
The best answer here is "it depends." This being a college course, however, we'll need to be more rigorous than that if we expect to get any credit.
A big part of the ascendence of data science is, essentially, Moore's Law; more colloquially, the continued march of technological progression in our society. Where once upon a time, digital storage was a luxury and available processing power required hours to perform the most basic computations, we're now right smack in the middle of an exponential expansion of digitized data creation and enough processing power to crunch a significant portion of it.
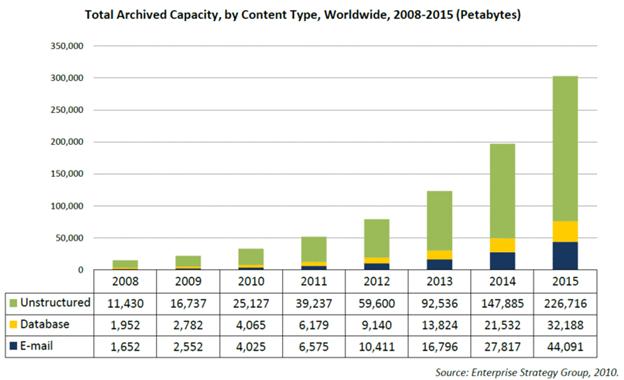
In effect, data science is not "new", but rather the result of technologies that have made such theoretical advancements plausible in practice.
- Digital storage is cheap enough to store everything.
- Modern CPUs / GPUs can perform trillions of calculations per second.
- Rather than pre-selecting features of data to save, we can now put sensors on everything and store the information for downstream analysis at a later time.
There is, nevertheless, a lot of overlap between this new field of "data science" and those that many regard as the progenitors: statistics and machine learning. Indeed, many data scientists hail from academia, with Ph.D.s in highly theoretical machine learning and data mining fields specialties and numerous publications to their records. On the other hand, many data scientists have more software engineering in their backgrounds than machine learning. To quote Joel Grus in his book, Data Science from Scratch [1]:
In short, pretty much no matter how you define data science, you'll find practitioners for whom the definition is totally, absolutely wrong.
In this light, we tend to fall back to the most general accepted definition of data science: "a professional who uses scientific methods to liberate and create meaning from raw data" [2]. Unfortunately, this is too overly broad to be useful; applied statisticians would claim this definition is, almost word-for-word, what they've been doing for centuries.
Donoho makes a compelling argument [2] that while the popular media tropes of "big data," "skills," and "jobs" don't inherently justify the spawn of a new field, there is nonetheless still a solid case to be made for a data science entity.
Part 3: "Greater" Data Science¶
It's important to note (and Donoho makes this point as well): data science did not develop overnight. Despite the seemingly rapid rise of Data Science as a field, "big data" as a meme, and the data scientist as an industry gold standard, this was something envisioned over 50 years ago by John Turkey in his book, The Future of Data Analytics. Published in 1962 in The Annals of Mathematical Statistics, it sent something of a shockwave through the statistics community by presenting the broad concepts of data analytics, interpretation, and visualization not as a branch or extension of math and statistics, but as their own field.
As Donoho outlines, there is legitimate value to training people in the practice of extracting information from data: from "getting acquainted with the data all the way to delivering results based upon it." Donoho refers to this field as "Greater Data Science", or GDS, and highlights six major divisions of the field that span all aspects of the data analytics and information extraction pipeline.
1: Data Exploration and Preparation¶
A quote that makes its way around the internets quite frequently: "A data scientist spends 80% of their time cleaning and rearranging their data." It's somewhat rhetorical--everyone knows data scientists spend 80% of their time watching cat videos, like the rest of us--but there is some truth here. Data are messy, often missing certain values or corrupted in other ways that would break naive attempts at analysis.
Furthermore, there's something to be said for exploring data beforehand; getting a feel for it; "becoming one" with the data you're working with. Ultimately there is no assumption-free algorithm that will "just work" for any arbitrary dataset; some algorithms work better with certain types of data, and understanding the data we're dealing with can dramatically improve our downstream modeling efforts.
2: Data Representation and Transformation¶
When I hear someone say "data," I often think one of: text, image, or video. But that's a dramatic oversimplification. There are countless data formats and standards, and more appearing all the time. Data scientists should be adaptable to these formats.
Text in a CSV file? Images in a TIFF stack? Compressed video in Ogg format? Or, moving beyond flat files: user activity stored in a MySQL database? Event logs stored in NoSQL key-value format? Or, moving beyond even concrete formats: are we reading 8-bit pixel data, or floating-point cepstral transformations? Are we receiving the raw image data, or the wavelet filter bank?
3: Computing with Data¶
Computing tools change; computer science fundamentals don't. Nevertheless, you'll need to be well-versed in a broad range of tools for reading, analyzing, and interpreting data at each stage of the data science pipeline. Arguably as important as the pieces of the project you'll assemble is how you plan to document your efforts. Inevitably, your code will fall to someone else to maintain and improve upon in the future, but sans your knowledge acquired in assembling the code in the first place. And just as inevitably, you will inherit code initially created by somebody long since gone. Thorough documentation strategies will be your lifeline.
What programming language will you use? What constructs will you employ within that language to maximize the efficiency of the algorithms you implement? What kind of platforms will you deploy your programs on? Can you containerize your applications for fine-grained resource scheduling?
4: Data Visualization and Presentation¶
I had a high school history teacher who once said, "If you can't write about it, you can't prove you know or understand it." While I certainly echo that sentiment in the literal sense, there will (sadly) be little to no opportunities for longform writing in this course. On the other hand, data visualization is a very close analogy, and is arguably one of the most important aspects of data science, as it is one of (if not the) primary ways in which analysis results are conveyed.
Visualization techniques can be used to explore the data you're working with (#1 above), or to create dashboards for monitoring live data processing pipelines (think Amazon EC2, or Microsoft Azure), or to present data-driven conclusions.
5: Data Modeling¶
Broadly speaking, this encompasses two primary modeling cultures:
- Generative modeling. In this case, you start with some dataset $\mathcal{X}$ and, using your knowledge of the data, construct a model $\mathcal{M}$ that could have feasibly generated your dataset $\mathcal{X}$. This roughly parallels most academic research endeavors: searching for and modeling the underlying mechanism which generated your data.
- Predictive modeling. In this case, you start with some dataset $\mathcal{X}$ and attempt to directly map it to some output space. This roughly parallels most machine learning pursuits and is the most common form of data modeling in industry (e.g. given a user, predict what products they would want to purchase).
Data scientists should be familiar with and competent in both modeling paradigms.
6: Science about Data Science¶
No field of science would be complete without a self-referential method by which to evaluate itself. In this case: packaging commonly-used analysis techniques or workflows into easily-accessible extensions; analyzing an algorithm's runtime and memory efficiency; measuring the effectiveness of human workflows from data extraction and exploration to final inferences; and for verifying existing results.
Part 4: The Perfect [Data] Storm¶
Ok, yes: there is a lot of money in data science. A lot.
As our society relies ever more heavily on digitized data collection and automated decision making, those with the right skill sets to help shape these new infrastructures will continue to be in demand for awhile. But don't take my word for it: go ahead and run your own Google search.
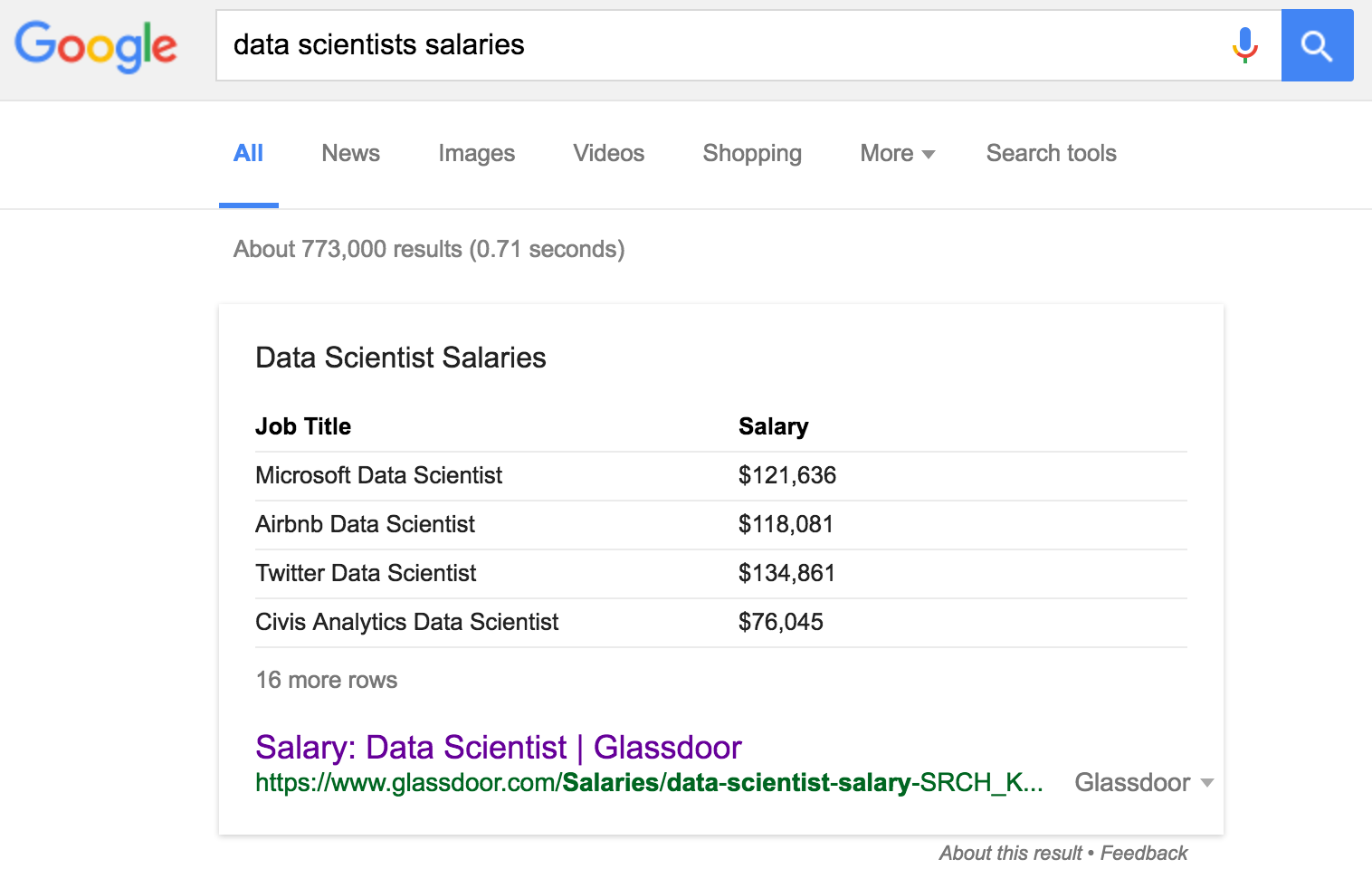
Internet article upon internet article upon internet article can attest to the borderline-ludicrous starting salaries of industry data scientists. Universities across the country (and the world) are building out data science and informatics programs (including UGA!). And as the above screenshot attests, data scientists are in high demand at just about any company. Not just any tech company; any company that deals with any kind of data will likely have a need for highly trained data scientists.
This is really all to say: we live in an era where cheap digital storage mechanisms, powerful computing hardware, and unprecedented digital connectivity have combined to create a perfect storm for those with the skills to ingest, structure, and analyze all the data that is being generated. This is the backdrop against which this course will be taught.
Review Questions¶
Some things to consider.
1: Why is the combination of hacking skills and substantive expertise, devoid of math and statistics knowledge, considered the "danger zone"?
2: What is the difference between machine learning and artificial intelligence?
3: Of the six divisions of "GDS," which one do you think is most prevalent in mainstream media? Why?
4: What's wrong with saying that data science is just statistics, but with computers?
5: Think of a company you wouldn't normally consider a "tech company," and contemplate how they might use a data science division to improve their bottom line.
Course Administrivia¶
A couple housekeeping items:
Future lectures¶
Each lecture will be released at midnight Mondays, Wednesdays, and Fridays. Each homework assignment will likewise be released at midnight every Tuesday and Thursday. In both cases, these announcements will be made both in the Course Administrivia section of any prior lectures (such as this one is right now!), and in the Slack chat (join if you have not already!).
Assignment 0 (A0)¶
Assignment 0 (A0) will be out tomorrow at midnight. This assignment will not count for a grade and is intended to help you set up your Python environment, as well as to familiarize you with the online tools we'll be using this semester (JupyterHub, nbgrader). It is highly recommended that you complete this assignment, as all future assignments will be in the same format and require that you have a working Python environment.
Slack channels¶
If you run into any technical problems setting up your environment (cryptic error messages, missing $PATH variable, etc), please post in the #techprobs channel. As for the other channels:
#csci1360e-discussions: your primary contact point for discussions around content in the course. Lecture clarifications, homework questions, and concept discussions all go here.#general: This is mostly for course announcements.#random: Read a good article about data science recently? Working on a data science project? Post about it and discuss it here!
Appendix: Additional Resources¶
- Grus, Joel. Data Science from Scratch: First Principles with Python. 2015.
- Donoho, David. 50 Years of Data Science. 2010.