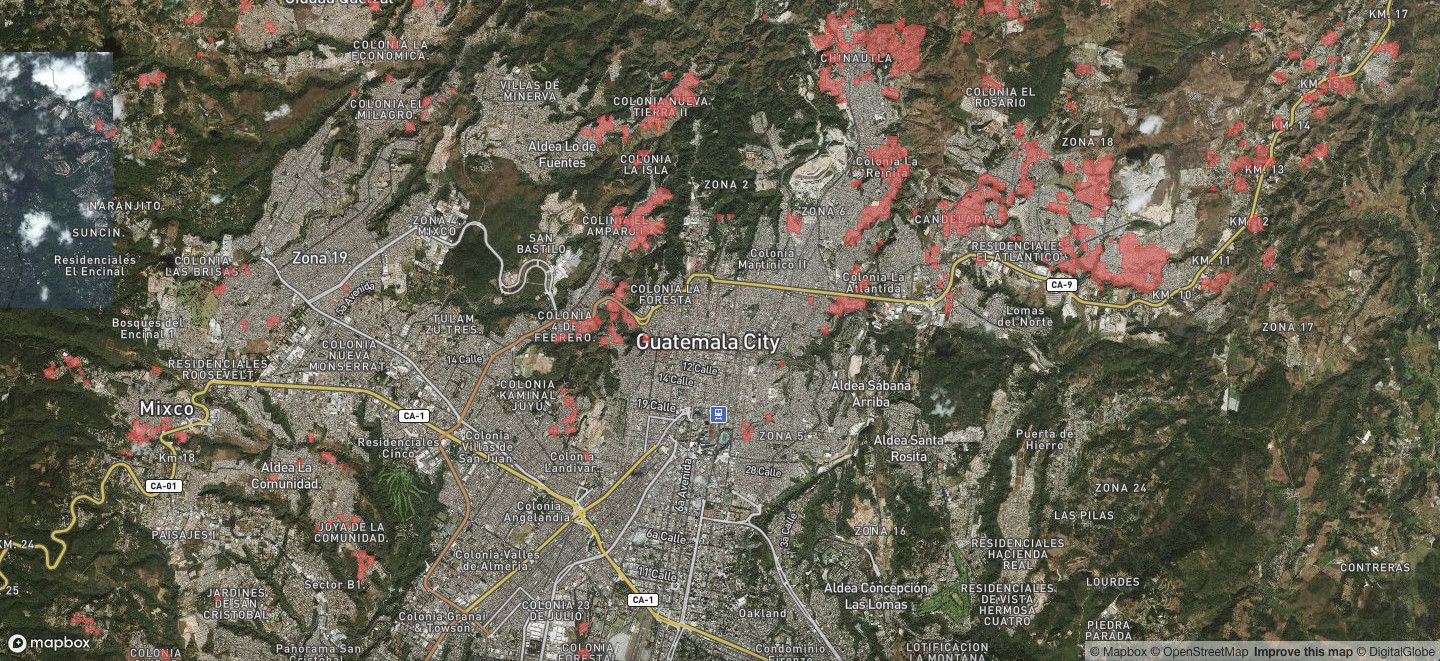
Nowcasting con imágenes satelitales¶
Vamos a presentar una posible aplicación de nowcasting usando imágenes satelitales. En este caso, buscaremos detectar asentamientos precarios usando solamente esa fuente de datos. De esta manera, podemos actualizar periódicamente la cantindad de km2 de asentamientos y así tener un indicador que pueda anticiparse a las estadísticas de hábitat.
El objetivo será mostrar como elaborar el mapa para que luego pueda ser replicable.
Tipos de imágenes satelitales¶
Existen distintos tipos de imágenes satelitales (ópticas), una clasificación que se puede hacer es de acuerdo a su resolución.
Podemos distinguir entre (no exhaustivo):
Resolución media: MODIS, 250-1000m por pixel.
- Utilizadas para investigación en cambio climático, recursos naturales y análisis de grandes superficies.
- 1 imagen nueva por día.
- Gratuitas, disponibles en varias fuentes. Por ejemplo Google Earth Engine
- Ejemplos de nowcasting: predicción de cosecha para el agro para grandes supericies. Indices de calidad del aire.
Resolución alta: Landsat (30m), Sentinel-2 (10m), RapidEye (5m).
- Utilizadas para análisis urbano y agro.
- 1 imagen cada 15 días (Landsat) y 5 días (Sentinel-2).
- Landsat y Sentinel-2 son gratuitas, disponibles en varias fuentes.
- Ejemplos de nowcasting: predicción de cosecha e indicadores relacionados con agricultura de precisión.
Resolución muy alta: WorldView-4 (0.3m de resolución)
- utilizadas para detección de objetos y monitoreo de gran precisión.
- Revisita variable según la zona.
- No son gratuitas (~ 24 USD/km2).
- Ejemplos de nowcasting: conteo de autos en parking lots de supermercados y contenedores en puertos.
Ejemplo Museo Louvre (Paris, Francia)¶
Sentinel-2¶

WorldView-4¶

Enfoques para resolución de problemas¶
Teledetección tradicional¶
Combinaciones de bandas en las imágenes para resaltar aspectos relevantes: por ejemplo banda roja e infrarroja para resaltar vegetación.


Machine Learning a nivel pixel¶
Se clasifican las imágenes de acuerdo a los valores de los píxeles. Esto puede traer problemas por la variabilidad que puede haber (ruido en la captura de la imagen y sombra entre otros).
Se resuelven problemas de clasificación de usos del suelo, detección de cambios, detección de cursos de agua y detección de vegetación, entre otros.
Ejemplo de detección de cambios para el municipio de Pilar.



OBIA (Object Based Image Analysis)¶
Se segmenta (agrupamiento de pixeles) previamente la imagen. De esta manera, cada fila es un segmento y a partir de estos calculamos atributos. Por ejemplo, para cada segmento se puede calcular distancia a cursos de agua, distancia a avenidas, intensidad de brillo promedio, etc.
Se clasifican las imágenes de acuerdo a los valores de los segmentos.


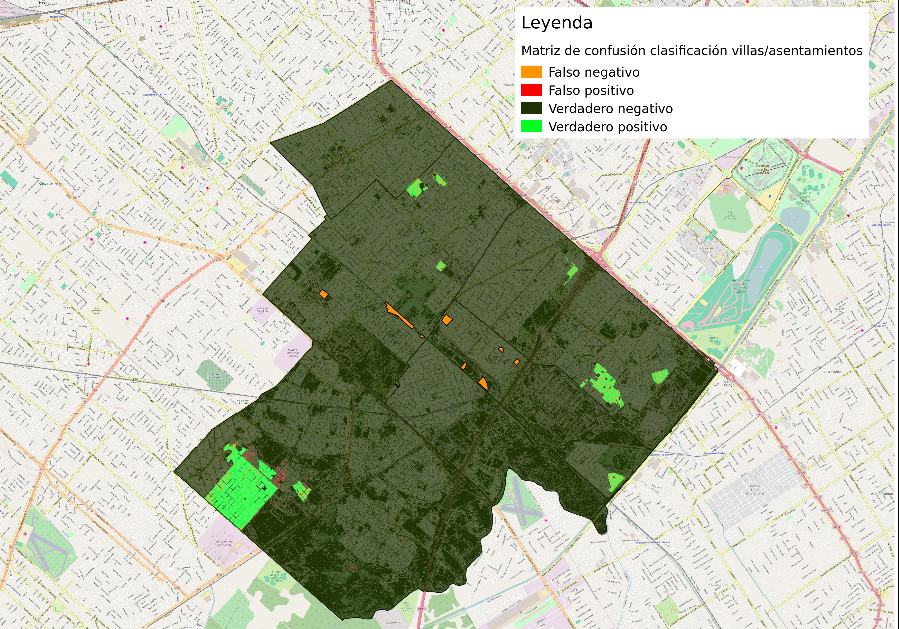
Redes Neuronales y Deep Learning¶
Un enfoque posible es usando redes neuronales convolucionales para hacer la clasificación. Se combina con técnicas de computer vision para filtrar y segmentar las imágenes de acuerdo a la clase que se busca detectar.
A continuación va un ejemplo de cómo procesar imáges de un territorio para clasificar asentamientos precarios usando redes neuronales convolucionales. Vamos a hacer transfer learning, aprovechando de redes ya entrenadas.
Se particiona la imagen entera en tiles de 256x256 pixeles y se cruza con las localizaciones de asentamientos precarios para establecer cuales son True y cuales False.
Ejemplos de True¶


Ejemplos de False¶


Dada la estructura de los directorios,
dir/
train/
true/
false/
validation/
true/
false/
levantamos los datos con una estructura que permita trabajar con Keras.
train_files = glob.glob(os.path.join('data/','train/**/', '*.jpg'))
validation_files = glob.glob(os.path.join('data/', 'validation/**/', '*.jpg'))
img_width, img_height = 256, 256
train_data_dir = "data/train/"
validation_data_dir = "data/validation/"
nb_train_samples = len(train_files)
nb_validation_samples = len(validation_files)
batch_size = 64
epochs = 200
Inicializamos una red ResNet50¶
model = applications.resnet50.ResNet50(
weights = "imagenet",
include_top = False,
input_shape = (img_width, img_height, 3))
Freezamos las primeras 50 capas, vamos a reentrenar las restantes¶
for layer in model.layers[:50]:
layer.trainable = False
Agregamos una última capa al final para obtener las predicciones¶
x = model.output
x = Flatten()(x)
x = Dense(1024, activation = "relu")(x)
x = Dropout(0.5)(x)
predictions = Dense(1, activation = "sigmoid")(x)
Cerramos el modelo y lo compilamos¶
model_final = Model(inputs = model.input, outputs = predictions)
# compile the model
model_final.compile(
loss = 'binary_crossentropy',
optimizer = optimizers.SGD(lr = 0.0001, momentum = 0.9),
metrics = ['accuracy'])
Generamos los conjuntos de datos de entrenamiento y validación¶
Usamos data agumentation para contemplar rotaciones y otras variaciones. El concepto aquí es que no nos importa en qué parte de la imagen está la clase que queremos detectar.
train_datagen = ImageDataGenerator(
rescale = 1./255,
horizontal_flip = True,
fill_mode = "nearest",
zoom_range = 0.3,
width_shift_range = 0.3,
height_shift_range = 0.3,
rotation_range = 30)
test_datagen = ImageDataGenerator(
rescale = 1./255,
horizontal_flip = True,
fill_mode = "nearest",
zoom_range = 0.3,
width_shift_range = 0.3,
height_shift_range = 0.3,
rotation_range = 30)
train_generator = train_datagen.flow_from_directory(
train_data_dir,
target_size = (img_height, img_width),
batch_size = batch_size,
class_mode = "binary")
validation_generator = test_datagen.flow_from_directory(
validation_data_dir,
target_size = (img_height, img_width),
class_mode = "binary")
Finalmente, usamos early stopping y usamos checkpoints para ir guardando cada corrida. Al final guardamos los pesos de la red.
checkpoint = ModelCheckpoint("./models/demo_weights.hdf5".format(trainable_layers),
monitor = 'val_acc',
verbose = 1,
save_best_only = True,
save_weights_only = False,
mode = 'auto',
period = 1)
early = EarlyStopping(
monitor = 'val_acc',
min_delta = 0,
patience = 10,
verbose = 1,
mode = 'auto')
model_final.fit_generator(
train_generator,
steps_per_epoch = nb_train_samples // batch_size,
epochs = epochs,
validation_data = validation_generator,
validation_steps = nb_validation_samples // batch_size,
callbacks = [checkpoint, early])
model_final.save('./models/demo.h5'.format(trainable_layers))
print('Done with {} layers'.format(trainable_layers))
Luego de esto hay que proceder a filtrar los resultados y segmentar las imágenes para terminar de detectar los objetos relevantes. Cabe destacar que hay arquitecturas de redes que permiten hacer esto último, como el caso de U-Net.
Para segmentar las imágenes se puede usar la librería scikit-image u OpenCV.
Resultado (link al mapa)¶