Preamble¶
Most of this workshop is taken from Hadley's R for Data Science book. You can find more examples, explanations and exercises there if you want.
What this workshop covers and does not cover¶
In this workshop you'll learn principles behind exploratory data analysis and visualization, including tidying and transforming data to answer questions you might want to ask. What you will not learn is how to make specific plots.
Exercises¶
There are exercises spread throughout this workshop. We're not going to cover them, but feel free to work on them if you feel like the lecture is going too slow for you. Solutions to a few are at the very end of this notebook.
Some useful but not necessary notes¶
- With Jupyter Notebook you can get a nice popup of function definitions just like you can in RStudio. Simply navigate to a cell or start a new one, and enter in
?functionlike you would normally. A popup will appear. - You should see an
Insertdropdown menu andRunbutton at the top which lets you add cells as well as run code or render Markdown in the cells, but these are very useful keyboard shortcuts for the same functions:Shift+Enter: Run code or render Markdown in the current cell you're onEsc+a: Add a cell aboveEsc+b: Add a cell belowEsc+dd: Delete a cell
Package prerequisites¶
Packages that required in this workshop are tidyverse, which includes the packages ggplot2, dplyr, purrr, and others, gridExtra which helps with arranging plots next to each other, ggrepel which helps with plot labels and maps which is for map data.
library(tidyverse)
library(gridExtra)
library(ggrepel)
library(maps)
If you get an error message “there is no package called ‘xyz’” then you need to install the packages first. (They should have been preloaded on your notebooks but if not it's ok, it won't take long.)
#install.packages('tidyverse')
#install.packages('gridExtra')
#install.packages('ggrepel')
#install.packages('map')
Visualizing Data¶
Core feature of exploratory data analysis is asking questions about data and searching for answers by visualizing and modeling data. Most questions around what type of variation or covariation occurs between variables.
options(repr.plot.width=6, repr.plot.height=4)
# regular plot functions in R
plot(x=mpg$displ,y=mpg$hwy)

# ggplot!
ggplot(data=mpg) + geom_point(mapping=aes(x=displ,y=hwy))

Basic syntax of ggplot:
ggplot(data=<DATA>) +
<GEOM_FUNCTION>(mapping=aes(<MAPPINGS>)
ggplot(mpg, aes(displ, hwy)) +
geom_point(aes(color = class)) +
geom_smooth(se = FALSE) +
labs(x="Engine displacement (L)",y="Heighway fuel economy (mpg)",
title = "Fuel efficiency generally decreases with engine size",
caption = "Data from fueleconomy.gov",
subtitle = "Two seaters (sports cars) are an exception because of their light weight",
colour = "Car type"
) + theme_classic()
`geom_smooth()` using method = 'loess' and formula 'y ~ x'

But first...¶
ggplot(data=<DATA>) +
<GEOM_FUNCTION>(mapping=aes(<MAPPINGS>)
How do we get data into a form appropriate for ggplot2?
Tidying Data¶
Most datasets are data frames made up of rows and columns. However, talking about data frames just in terms of what rows and columns it has is not enough.
- Variable: quantity, quality, property that can be measured.
- Value: State of variable when measured.
- Observation: Set of measurements made under similar conditions
- Tabular data: Set of values, each associated with a variable and an observation.

Tidy data:
- Each variable is its own column
- Each observation is its own row
- Each value is in a single cell
Benefits:
- Easy to manipulate
- Easy to model
- Easy to visualize
- Has a specific and consistent structure
- Stucture makes it easy to tidy other data
Cons:
- Data frame is not as easy to look at
Consider the following tables:
table1 <- data.frame(makemodel=c("audi a4","audi a4","chevrolet corvette","chevrolet corvette","honda civic","honda civic"),
year=rep(c(1999,2008),3),
cty=c(18,21,15,15,24,25),
hwy=c(29,30,23,25,32,36))
table1
| makemodel | year | cty | hwy |
|---|---|---|---|
| <fct> | <dbl> | <dbl> | <dbl> |
| audi a4 | 1999 | 18 | 29 |
| audi a4 | 2008 | 21 | 30 |
| chevrolet corvette | 1999 | 15 | 23 |
| chevrolet corvette | 2008 | 15 | 25 |
| honda civic | 1999 | 24 | 32 |
| honda civic | 2008 | 25 | 36 |
This is tidy data, because each column is a variable, each observation is a row, and each value is in a single cell
Next we will look at some non-tidy data and operations from the tidyr package (part of tidyverse) to make the data tidy. Many of you might be more used to using operations from reshape2 like melting and casting. It's a very useful package with more functionality including aggregating data, but syntax with tidyr commands is more simpler and intuitive for the purposes of tidying data.
Gathering¶
table2a <- data.frame(makemodel=c("audi a4","chevrolet corvette","honda civic"),`1999`=c(18,15,24),'2008'=c(21,15,25),check.names=FALSE)
table2b <- data.frame(makemodel=c("audi a4","chevrolet corvette","honda civic"),`1999`=c(29,23,32),'2008'=c(30,25,36),check.names=FALSE)
table2a
table2b
| makemodel | 1999 | 2008 |
|---|---|---|
| <fct> | <dbl> | <dbl> |
| audi a4 | 18 | 21 |
| chevrolet corvette | 15 | 15 |
| honda civic | 24 | 25 |
| makemodel | 1999 | 2008 |
|---|---|---|
| <fct> | <dbl> | <dbl> |
| audi a4 | 29 | 30 |
| chevrolet corvette | 23 | 25 |
| honda civic | 32 | 36 |
table2a column names 1999 and 2008 represent values of year variable. table2b is the same. Each row represents 2 observations, not 1. Need to gather columns into new pair of variables.
Parameters:
- Set of columns that represent values, not variables.
key: name of variable whose values are currently column names.value: name of variable whose values are currently spread out across multiple columns.
Experiments often report data in the format of table4a and table4b. One reason is for presentation purposes it's very easy to look at. Another is storage is efficient for completely crossed designs and can allow matrix operations.
tidy2a <- gather(table2a,`1999`,`2008`,key="year",value="cty")
tidy2a
| makemodel | year | cty |
|---|---|---|
| <fct> | <chr> | <dbl> |
| audi a4 | 1999 | 18 |
| chevrolet corvette | 1999 | 15 |
| honda civic | 1999 | 24 |
| audi a4 | 2008 | 21 |
| chevrolet corvette | 2008 | 15 |
| honda civic | 2008 | 25 |
tidy2b <- gather(table2b, `1999`, `2008`, key = "year", value = "hwy")
tidy2b
| makemodel | year | hwy |
|---|---|---|
| <fct> | <chr> | <dbl> |
| audi a4 | 1999 | 29 |
| chevrolet corvette | 1999 | 23 |
| honda civic | 1999 | 32 |
| audi a4 | 2008 | 30 |
| chevrolet corvette | 2008 | 25 |
| honda civic | 2008 | 36 |
Merge tables using left_join() (many other types of table joins as well)
right_join(tidy2a,tidy2b)
Joining, by = c("makemodel", "year")
| makemodel | year | cty | hwy |
|---|---|---|---|
| <fct> | <chr> | <dbl> | <dbl> |
| audi a4 | 1999 | 18 | 29 |
| chevrolet corvette | 1999 | 15 | 23 |
| honda civic | 1999 | 24 | 32 |
| audi a4 | 2008 | 21 | 30 |
| chevrolet corvette | 2008 | 15 | 25 |
| honda civic | 2008 | 25 | 36 |
Spreading¶
table3 <- data.frame(makemodel=c(rep("audi a4",4),rep("chevrolet corvette",4),rep("honda civic",4)),
year=rep(c(1999,1999,2008,2008),3),
type=rep(c("cty","hwy"),6),
mileage=c(18,29,21,30,15,23,15,25,24,32,25,36))
table3
| makemodel | year | type | mileage |
|---|---|---|---|
| <fct> | <dbl> | <fct> | <dbl> |
| audi a4 | 1999 | cty | 18 |
| audi a4 | 1999 | hwy | 29 |
| audi a4 | 2008 | cty | 21 |
| audi a4 | 2008 | hwy | 30 |
| chevrolet corvette | 1999 | cty | 15 |
| chevrolet corvette | 1999 | hwy | 23 |
| chevrolet corvette | 2008 | cty | 15 |
| chevrolet corvette | 2008 | hwy | 25 |
| honda civic | 1999 | cty | 24 |
| honda civic | 1999 | hwy | 32 |
| honda civic | 2008 | cty | 25 |
| honda civic | 2008 | hwy | 36 |
table3 has each observation in two rows. Need to spread observations across columns with appropriate variable names instead.
Parameters:
key: Column that contains variable names.value: Column that contains values for each variable.
spread(table3, key=type,value=mileage)
| makemodel | year | cty | hwy |
|---|---|---|---|
| <fct> | <dbl> | <dbl> | <dbl> |
| audi a4 | 1999 | 18 | 29 |
| audi a4 | 2008 | 21 | 30 |
| chevrolet corvette | 1999 | 15 | 23 |
| chevrolet corvette | 2008 | 15 | 25 |
| honda civic | 1999 | 24 | 32 |
| honda civic | 2008 | 25 | 36 |
Exercises¶
- Consider the example below, where we spread and then gather observations from the same columns in
stocks. Why aregather()andspread()not perfectly symmetrical? (Hint: look at the variable types and column names)
stocks <- tibble(
year = c(2015, 2015, 2016, 2016),
half = c( 1, 2, 1, 2),
return = c(1.88, 0.59, 0.92, 0.17)
)
stocks
stocks %>%
spread(year, return) %>%
gather("year", "return", `2015`:`2016`)
| year | half | return |
|---|---|---|
| <dbl> | <dbl> | <dbl> |
| 2015 | 1 | 1.88 |
| 2015 | 2 | 0.59 |
| 2016 | 1 | 0.92 |
| 2016 | 2 | 0.17 |
| half | year | return |
|---|---|---|
| <dbl> | <chr> | <dbl> |
| 1 | 2015 | 1.88 |
| 2 | 2015 | 0.59 |
| 1 | 2016 | 0.92 |
| 2 | 2016 | 0.17 |
- Why does the code below fail?
table4a %>%
gather(1999, 2000, key = "year", value = "cases")
Error in inds_combine(.vars, ind_list): Position must be between 0 and n Traceback: 1. table4a %>% gather(1999, 2000, key = "year", value = "cases") 2. withVisible(eval(quote(`_fseq`(`_lhs`)), env, env)) 3. eval(quote(`_fseq`(`_lhs`)), env, env) 4. eval(quote(`_fseq`(`_lhs`)), env, env) 5. `_fseq`(`_lhs`) 6. freduce(value, `_function_list`) 7. withVisible(function_list[[k]](value)) 8. function_list[[k]](value) 9. gather(., 1999, 2000, key = "year", value = "cases") 10. gather.data.frame(., 1999, 2000, key = "year", value = "cases") 11. unname(tidyselect::vars_select(tbl_vars(data), !!!quos)) 12. tidyselect::vars_select(tbl_vars(data), !!!quos) 13. inds_combine(.vars, ind_list)
- Why does spreading this tibble fail? How could you fix it?
people <- tribble(
~name, ~key, ~value,
#-----------------|--------|------
"Phillip Woods", "age", 45,
"Phillip Woods", "height", 186,
"Phillip Woods", "age", 50,
"Jessica Cordero", "age", 37,
"Jessica Cordero", "height", 156
)
Separating¶
table4 <- data.frame(makemodel=c("audi a4","audi a4","chevrolet corvette","chevrolet corvette","honda civic","honda civic"),
year=rep(c(1999,2008),3),
mileages=c('18/29','21/30','15/23','15/25','24/32','25/36'))
table4
| makemodel | year | mileages |
|---|---|---|
| <fct> | <dbl> | <fct> |
| audi a4 | 1999 | 18/29 |
| audi a4 | 2008 | 21/30 |
| chevrolet corvette | 1999 | 15/23 |
| chevrolet corvette | 2008 | 15/25 |
| honda civic | 1999 | 24/32 |
| honda civic | 2008 | 25/36 |
table4 has mileages column that actually contains two variables (cty and hwy). Need to separate into two columns.
Parameters:
- column/variable that needs to be separated.
into: columns to split intosep: separator value. Can be regexp or positions to split at. If not provided then splits at non-alphanumeric characters.
separate(table4, mileages, into = c("cty", "hwy"), sep="/")
| makemodel | year | cty | hwy |
|---|---|---|---|
| <fct> | <dbl> | <chr> | <chr> |
| audi a4 | 1999 | 18 | 29 |
| audi a4 | 2008 | 21 | 30 |
| chevrolet corvette | 1999 | 15 | 23 |
| chevrolet corvette | 2008 | 15 | 25 |
| honda civic | 1999 | 24 | 32 |
| honda civic | 2008 | 25 | 36 |
sep <- separate(table4, makemodel, into = c("make", "model"), sep = ' ')
sep
| make | model | year | mileages |
|---|---|---|---|
| <chr> | <chr> | <dbl> | <fct> |
| audi | a4 | 1999 | 18/29 |
| audi | a4 | 2008 | 21/30 |
| chevrolet | corvette | 1999 | 15/23 |
| chevrolet | corvette | 2008 | 15/25 |
| honda | civic | 1999 | 24/32 |
| honda | civic | 2008 | 25/36 |
Uniting¶
Now sep has make and model columns that can be combined into a single column. In other words, we want to unite them.
Parameters:
- Name of united column/variable
- Names of columns/variables to be united
sep: Separator value. Default is '_'
unite(sep, new, make, model)
| new | year | mileages |
|---|---|---|
| <chr> | <dbl> | <fct> |
| audi_a4 | 1999 | 18/29 |
| audi_a4 | 2008 | 21/30 |
| chevrolet_corvette | 1999 | 15/23 |
| chevrolet_corvette | 2008 | 15/25 |
| honda_civic | 1999 | 24/32 |
| honda_civic | 2008 | 25/36 |
unite(sep, makemodel, make, model, sep=' ')
| makemodel | year | mileages |
|---|---|---|
| <chr> | <dbl> | <fct> |
| audi a4 | 1999 | 18/29 |
| audi a4 | 2008 | 21/30 |
| chevrolet corvette | 1999 | 15/23 |
| chevrolet corvette | 2008 | 15/25 |
| honda civic | 1999 | 24/32 |
| honda civic | 2008 | 25/36 |
Piping¶
dplyr from tidyverse contains the 'pipe' (%>%) which allows you to combine multiple operations, directly taking output from a funtion as input to the next. Can save time and memory as well as make code easier to read. Can think of it this way: x %>% f(y) becomes f(x,y), and x %>% f(y) %>% g(z) becomes g(f(x,y),z), etc.
unite(sep, makemodel, make, model, sep=' ') %>%
separate(mileages, into=c("cty","hwy"))
| makemodel | year | cty | hwy |
|---|---|---|---|
| <chr> | <dbl> | <chr> | <chr> |
| audi a4 | 1999 | 18 | 29 |
| audi a4 | 2008 | 21 | 30 |
| chevrolet corvette | 1999 | 15 | 23 |
| chevrolet corvette | 2008 | 15 | 25 |
| honda civic | 1999 | 24 | 32 |
| honda civic | 2008 | 25 | 36 |
Exercises¶
- What do the
extraandfillarguments do inseparate()? Experiment with the various options for the following two toy datasets.
tibble(x = c("a,b,c", "d,e,f,g", "h,i,j")) %>%
separate(x, c("one", "two", "three"))
tibble(x = c("a,b,c", "d,e", "f,g,i")) %>%
separate(x, c("one", "two", "three"))
Warning message: “Expected 3 pieces. Additional pieces discarded in 1 rows [2].”
| one | two | three |
|---|---|---|
| <chr> | <chr> | <chr> |
| a | b | c |
| d | e | f |
| h | i | j |
Warning message: “Expected 3 pieces. Missing pieces filled with `NA` in 1 rows [2].”
| one | two | three |
|---|---|---|
| <chr> | <chr> | <chr> |
| a | b | c |
| d | e | NA |
| f | g | i |
Not all data should be tidy¶
Matrices, phylogenetic trees (although ggtree and treeio have tidy representations that help with annotating trees), etc.
Transforming (Tidy) Data¶
Now we know how to get tidy data. At this point we can already start visualizing our data. However in many cases we will need to further transform our data to narrow down variables and observations we are really interested in or to create new variables that are functions of our existing variables and data. This is known as transforming data.
filter()to pick observations (rows) by their valuesarrange()to reorder rows, default is by ascending valueselect()to pick variables (columns) by their namesmutate()to create new variables with functions of existing variablessummarise()to collapes many values down to a single summarygroup_by()to set up functions to operate on groups rather than the whole data set%>%propagates the output from a function as input to another. eg: x %>% f(y) becomes f(x,y), and x %>% f(y) %>% g(z) becomes g(f(x,y),z).
All functions have similar structure:
- First argument is data frame
- Next arguments describe what to do with data frame using variable names
- Result is new data frame
Will be working with data frame mpg for rest of workshop which comes with the tidyverse library.
head(mpg)
| manufacturer | model | displ | year | cyl | trans | drv | cty | hwy | fl | class |
|---|---|---|---|---|---|---|---|---|---|---|
| <chr> | <chr> | <dbl> | <int> | <int> | <chr> | <chr> | <int> | <int> | <chr> | <chr> |
| audi | a4 | 1.8 | 1999 | 4 | auto(l5) | f | 18 | 29 | p | compact |
| audi | a4 | 1.8 | 1999 | 4 | manual(m5) | f | 21 | 29 | p | compact |
| audi | a4 | 2.0 | 2008 | 4 | manual(m6) | f | 20 | 31 | p | compact |
| audi | a4 | 2.0 | 2008 | 4 | auto(av) | f | 21 | 30 | p | compact |
| audi | a4 | 2.8 | 1999 | 6 | auto(l5) | f | 16 | 26 | p | compact |
| audi | a4 | 2.8 | 1999 | 6 | manual(m5) | f | 18 | 26 | p | compact |
filter() rows/observations¶
As name suggests filters out rows. First argument is name of data frame, next arguments are expressions that filter the data frame.
# filter out 2seater cars
no_2seaters <- filter(mpg, class != "2seater")
head(no_2seaters)
| manufacturer | model | displ | year | cyl | trans | drv | cty | hwy | fl | class |
|---|---|---|---|---|---|---|---|---|---|---|
| <chr> | <chr> | <dbl> | <int> | <int> | <chr> | <chr> | <int> | <int> | <chr> | <chr> |
| audi | a4 | 1.8 | 1999 | 4 | auto(l5) | f | 18 | 29 | p | compact |
| audi | a4 | 1.8 | 1999 | 4 | manual(m5) | f | 21 | 29 | p | compact |
| audi | a4 | 2.0 | 2008 | 4 | manual(m6) | f | 20 | 31 | p | compact |
| audi | a4 | 2.0 | 2008 | 4 | auto(av) | f | 21 | 30 | p | compact |
| audi | a4 | 2.8 | 1999 | 6 | auto(l5) | f | 16 | 26 | p | compact |
| audi | a4 | 2.8 | 1999 | 6 | manual(m5) | f | 18 | 26 | p | compact |
# filter out audis, chevys, and hondas
mpg %>% filter(!manufacturer %in% c("audi","chevrolet","honda")) %>% head
| manufacturer | model | displ | year | cyl | trans | drv | cty | hwy | fl | class |
|---|---|---|---|---|---|---|---|---|---|---|
| <chr> | <chr> | <dbl> | <int> | <int> | <chr> | <chr> | <int> | <int> | <chr> | <chr> |
| dodge | caravan 2wd | 2.4 | 1999 | 4 | auto(l3) | f | 18 | 24 | r | minivan |
| dodge | caravan 2wd | 3.0 | 1999 | 6 | auto(l4) | f | 17 | 24 | r | minivan |
| dodge | caravan 2wd | 3.3 | 1999 | 6 | auto(l4) | f | 16 | 22 | r | minivan |
| dodge | caravan 2wd | 3.3 | 1999 | 6 | auto(l4) | f | 16 | 22 | r | minivan |
| dodge | caravan 2wd | 3.3 | 2008 | 6 | auto(l4) | f | 17 | 24 | r | minivan |
| dodge | caravan 2wd | 3.3 | 2008 | 6 | auto(l4) | f | 17 | 24 | r | minivan |
arrange() rows/observations¶
Changes order of rows. First argument is name of data frame, next arguments are column names (or more complicated expressions) to order by. Default column ordering is by ascending order, can use desc() to do descending order. Missing values get sorted at the end regardless of what column ordering is chosen.
# arrange/reorder mpg by class
arrange(mpg, class) %>% head
| manufacturer | model | displ | year | cyl | trans | drv | cty | hwy | fl | class |
|---|---|---|---|---|---|---|---|---|---|---|
| <chr> | <chr> | <dbl> | <int> | <int> | <chr> | <chr> | <int> | <int> | <chr> | <chr> |
| chevrolet | corvette | 5.7 | 1999 | 8 | manual(m6) | r | 16 | 26 | p | 2seater |
| chevrolet | corvette | 5.7 | 1999 | 8 | auto(l4) | r | 15 | 23 | p | 2seater |
| chevrolet | corvette | 6.2 | 2008 | 8 | manual(m6) | r | 16 | 26 | p | 2seater |
| chevrolet | corvette | 6.2 | 2008 | 8 | auto(s6) | r | 15 | 25 | p | 2seater |
| chevrolet | corvette | 7.0 | 2008 | 8 | manual(m6) | r | 15 | 24 | p | 2seater |
| audi | a4 | 1.8 | 1999 | 4 | auto(l5) | f | 18 | 29 | p | compact |
# arrange/reorder data frame with 2seaters filtered out by class
# 2seaters does not appear which is as it should be
arrange(no_2seaters, class) %>% head
| manufacturer | model | displ | year | cyl | trans | drv | cty | hwy | fl | class |
|---|---|---|---|---|---|---|---|---|---|---|
| <chr> | <chr> | <dbl> | <int> | <int> | <chr> | <chr> | <int> | <int> | <chr> | <chr> |
| audi | a4 | 1.8 | 1999 | 4 | auto(l5) | f | 18 | 29 | p | compact |
| audi | a4 | 1.8 | 1999 | 4 | manual(m5) | f | 21 | 29 | p | compact |
| audi | a4 | 2.0 | 2008 | 4 | manual(m6) | f | 20 | 31 | p | compact |
| audi | a4 | 2.0 | 2008 | 4 | auto(av) | f | 21 | 30 | p | compact |
| audi | a4 | 2.8 | 1999 | 6 | auto(l5) | f | 16 | 26 | p | compact |
| audi | a4 | 2.8 | 1999 | 6 | manual(m5) | f | 18 | 26 | p | compact |
What kinds of cars have the best highway and city gas mileage?
# arrange mpg so that first hwy mileage is by descending order, then cty mileage is by descending order
arrange(mpg, desc(hwy), desc(cty)) %>% head
| manufacturer | model | displ | year | cyl | trans | drv | cty | hwy | fl | class |
|---|---|---|---|---|---|---|---|---|---|---|
| <chr> | <chr> | <dbl> | <int> | <int> | <chr> | <chr> | <int> | <int> | <chr> | <chr> |
| volkswagen | new beetle | 1.9 | 1999 | 4 | manual(m5) | f | 35 | 44 | d | subcompact |
| volkswagen | jetta | 1.9 | 1999 | 4 | manual(m5) | f | 33 | 44 | d | compact |
| volkswagen | new beetle | 1.9 | 1999 | 4 | auto(l4) | f | 29 | 41 | d | subcompact |
| toyota | corolla | 1.8 | 2008 | 4 | manual(m5) | f | 28 | 37 | r | compact |
| honda | civic | 1.8 | 2008 | 4 | auto(l5) | f | 25 | 36 | r | subcompact |
| honda | civic | 1.8 | 2008 | 4 | auto(l5) | f | 24 | 36 | c | subcompact |
Example of missing data getting placed at bottom.
df <- data.frame(x=c(5,2,NA,6))
df
| x |
|---|
| <dbl> |
| 5 |
| 2 |
| NA |
| 6 |
# arrange df by ascending order, NA will be at bottom
arrange(df, x)
| x |
|---|
| <dbl> |
| 2 |
| 5 |
| 6 |
| NA |
# arrange df by descending order, NA will be at bottom
arrange(df, desc(x))
| x |
|---|
| <dbl> |
| 6 |
| 5 |
| 2 |
| NA |
If you want to bring NA to the top, you can instead use !is.na(x) which evaluates as a boolean, so FALSE/TRUE. The df gets arranged by FALSE first, so NA goes to the top. However the rest of the values are unsorted since they will all return TRUE, although you can add more arguments to sort by the same column. This can be done for any other variable you want to use to rearrange with boolean expressions instead.
# rest of the values are unsorted because they are all T for !is.na(x)
arrange(df,!is.na(x))
| x |
|---|
| <dbl> |
| NA |
| 5 |
| 2 |
| 6 |
# can arrange by x again to get ascending order
arrange(df,!is.na(x),desc(x))
| x |
|---|
| <dbl> |
| NA |
| 6 |
| 5 |
| 2 |
select() columns/variables¶
Selects columns, which can be useful when you have hundreds or thousands of variables in order to narrow down to what variables you're actually interested in. First argument is name of data frame, subsequent arguments are columns to select. Can use a:b to select all columns between a and b, or use -a to select all columns except a.
# select manufacturer, model, year, cty, hwy
select(mpg, manufacturer, model, year, cty, hwy) %>% head
| manufacturer | model | year | cty | hwy |
|---|---|---|---|---|
| <chr> | <chr> | <int> | <int> | <int> |
| audi | a4 | 1999 | 18 | 29 |
| audi | a4 | 1999 | 21 | 29 |
| audi | a4 | 2008 | 20 | 31 |
| audi | a4 | 2008 | 21 | 30 |
| audi | a4 | 1999 | 16 | 26 |
| audi | a4 | 1999 | 18 | 26 |
# select all columns model thru hwy
select(mpg, model:hwy) %>% head
head(mpg)
| model | displ | year | cyl | trans | drv | cty | hwy |
|---|---|---|---|---|---|---|---|
| <chr> | <dbl> | <int> | <int> | <chr> | <chr> | <int> | <int> |
| a4 | 1.8 | 1999 | 4 | auto(l5) | f | 18 | 29 |
| a4 | 1.8 | 1999 | 4 | manual(m5) | f | 21 | 29 |
| a4 | 2.0 | 2008 | 4 | manual(m6) | f | 20 | 31 |
| a4 | 2.0 | 2008 | 4 | auto(av) | f | 21 | 30 |
| a4 | 2.8 | 1999 | 6 | auto(l5) | f | 16 | 26 |
| a4 | 2.8 | 1999 | 6 | manual(m5) | f | 18 | 26 |
| manufacturer | model | displ | year | cyl | trans | drv | cty | hwy | fl | class |
|---|---|---|---|---|---|---|---|---|---|---|
| <chr> | <chr> | <dbl> | <int> | <int> | <chr> | <chr> | <int> | <int> | <chr> | <chr> |
| audi | a4 | 1.8 | 1999 | 4 | auto(l5) | f | 18 | 29 | p | compact |
| audi | a4 | 1.8 | 1999 | 4 | manual(m5) | f | 21 | 29 | p | compact |
| audi | a4 | 2.0 | 2008 | 4 | manual(m6) | f | 20 | 31 | p | compact |
| audi | a4 | 2.0 | 2008 | 4 | auto(av) | f | 21 | 30 | p | compact |
| audi | a4 | 2.8 | 1999 | 6 | auto(l5) | f | 16 | 26 | p | compact |
| audi | a4 | 2.8 | 1999 | 6 | manual(m5) | f | 18 | 26 | p | compact |
# select all columns except cyl thru drv and class
select(mpg, -(cyl:drv), -class) %>% head
| manufacturer | model | displ | year | cty | hwy | fl |
|---|---|---|---|---|---|---|
| <chr> | <chr> | <dbl> | <int> | <int> | <int> | <chr> |
| audi | a4 | 1.8 | 1999 | 18 | 29 | p |
| audi | a4 | 1.8 | 1999 | 21 | 29 | p |
| audi | a4 | 2.0 | 2008 | 20 | 31 | p |
| audi | a4 | 2.0 | 2008 | 21 | 30 | p |
| audi | a4 | 2.8 | 1999 | 16 | 26 | p |
| audi | a4 | 2.8 | 1999 | 18 | 26 | p |
mutate() to add new variables or transmute() to keep only new variables¶
Adds new columns that are functions of existing columns. First argument is name of data frame, next arguments are of the form new_column_name = f(existing columns).
# add a new column that takes average mileage between city and highway
mutate(mpg, avg_mileage = (cty+hwy)/2) %>% head
| manufacturer | model | displ | year | cyl | trans | drv | cty | hwy | fl | class | avg_mileage |
|---|---|---|---|---|---|---|---|---|---|---|---|
| <chr> | <chr> | <dbl> | <int> | <int> | <chr> | <chr> | <int> | <int> | <chr> | <chr> | <dbl> |
| audi | a4 | 1.8 | 1999 | 4 | auto(l5) | f | 18 | 29 | p | compact | 23.5 |
| audi | a4 | 1.8 | 1999 | 4 | manual(m5) | f | 21 | 29 | p | compact | 25.0 |
| audi | a4 | 2.0 | 2008 | 4 | manual(m6) | f | 20 | 31 | p | compact | 25.5 |
| audi | a4 | 2.0 | 2008 | 4 | auto(av) | f | 21 | 30 | p | compact | 25.5 |
| audi | a4 | 2.8 | 1999 | 6 | auto(l5) | f | 16 | 26 | p | compact | 21.0 |
| audi | a4 | 2.8 | 1999 | 6 | manual(m5) | f | 18 | 26 | p | compact | 22.0 |
# keep only average mileage between city and highway
transmute(mpg,cty,avg_mileage=(cty+hwy)/2) %>% head
| cty | avg_mileage |
|---|---|
| <int> | <dbl> |
| 18 | 23.5 |
| 21 | 25.0 |
| 20 | 25.5 |
| 21 | 25.5 |
| 16 | 21.0 |
| 18 | 22.0 |
summarise() and group_by() for grouped summaries¶
summarise() collapses a data frame into a single row, and group_by() changes analysis from entire data frame into individual groups.
# get average mileage grouped by engine cylinder
m <- mutate(mpg, avg_mileage=(cty+hwy)/2)
# behavior is actually different in R/RStudio compared to notebooks
m %>% group_by(cyl) %>%
summarise(avg=mean(avg_mileage)) %>%
head
| cyl | avg |
|---|---|
| <int> | <dbl> |
| 4 | 24.90741 |
| 5 | 24.62500 |
| 6 | 19.51899 |
| 8 | 15.10000 |
Note: If you look at the output of group_by in R/RStudio you will actually be able to see what your groupings are as well as how many of them you have. For example if we did group_by(mpg, cyl) the output would include cyl [4] which shows that our grouping is by cyl and there are 4 groups. Jupyter notebook doesn't display this for reasons having to do with how data frames are outputted. Some other differences exist between how certain objects from tidyverse are displayed as well.
group_by(m, drv) %>%
summarise(avg=mean(avg_mileage))
| drv | avg |
|---|---|
| <chr> | <dbl> |
| 4 | 16.75243 |
| f | 24.06604 |
| r | 17.54000 |
# df after group_by would show that we have 9 groups
drv_cyl <- group_by(m, drv, cyl) %>%
summarise(avg=mean(avg_mileage)) %>%
arrange(desc(avg))
drv_cyl
| drv | cyl | avg |
|---|---|---|
| <chr> | <int> | <dbl> |
| f | 4 | 26.26724 |
| f | 5 | 24.62500 |
| 4 | 4 | 21.47826 |
| r | 6 | 21.25000 |
| f | 6 | 21.12791 |
| f | 8 | 20.50000 |
| 4 | 6 | 17.14062 |
| r | 8 | 16.83333 |
| 4 | 8 | 14.22917 |
Can also run ungroup to ungroup your observations.
drv_cyl %>% summarise(max=max(avg))
| drv | max |
|---|---|
| <chr> | <dbl> |
| 4 | 21.47826 |
| f | 26.26724 |
| r | 21.25000 |
ungroup(drv_cyl) %>% summarise(max=max(avg))
| max |
|---|
| <dbl> |
| 26.26724 |
Exercises¶
Find all cars that:
- Have an average gas mileage greater than 20mpg
- Have an automatic transmission
- Are 4-wheel drive
Earlier we computed the average mileage with an explicit formula by taking city mileage + highway mileage and dividing the sum by two. How can you do this without typing out the exact formula? What happens if there are
NAs? Feel free to experiment on the dataframeex2_dfto arrive at an answer.Find all cars grouped by manufacturer, model, cylinder, and auto/manual transmission that improved on gas mileage (either city, highway, or both, you choose) by at least 1mpg between 1999 and 2008. (This one might take some time, if you just look at city mileage you should end up with 26 rows in your data frame.)
ex2_df <- data.frame(x=c(5,2,NA,6),y=c(NA,5,10,3))
Back to Visualizing Data¶
Basic syntax of ggplot:
ggplot(data=<DATA>) +
<GEOM_FUNCTION>(mapping=aes(<MAPPINGS>)
head(mpg) # automatically loaded when you load tidyverse
| manufacturer | model | displ | year | cyl | trans | drv | cty | hwy | fl | class |
|---|---|---|---|---|---|---|---|---|---|---|
| <chr> | <chr> | <dbl> | <int> | <int> | <chr> | <chr> | <int> | <int> | <chr> | <chr> |
| audi | a4 | 1.8 | 1999 | 4 | auto(l5) | f | 18 | 29 | p | compact |
| audi | a4 | 1.8 | 1999 | 4 | manual(m5) | f | 21 | 29 | p | compact |
| audi | a4 | 2.0 | 2008 | 4 | manual(m6) | f | 20 | 31 | p | compact |
| audi | a4 | 2.0 | 2008 | 4 | auto(av) | f | 21 | 30 | p | compact |
| audi | a4 | 2.8 | 1999 | 6 | auto(l5) | f | 16 | 26 | p | compact |
| audi | a4 | 2.8 | 1999 | 6 | manual(m5) | f | 18 | 26 | p | compact |
Let's break down the components of ggplot. First, note that ggplot(data=<DATA>) on its own will not actually plot anything.
ggplot(mpg)

This is because we need the <GEOM_FUNCTION>(mapping=aes(<MAPPINGS>) to tell us what exactly to plot using our data. However, just ggplot(data=<DATA>) + <GEOM_FUNCTION>() on its own doesn't do anything either.
ggplot(mpg) + geom_point()
ERROR while rich displaying an object: Error: geom_point requires the following missing aesthetics: x, y
Traceback:
1. FUN(X[[i]], ...)
2. tryCatch(withCallingHandlers({
. if (!mime %in% names(repr::mime2repr))
. stop("No repr_* for mimetype ", mime, " in repr::mime2repr")
. rpr <- repr::mime2repr[[mime]](obj)
. if (is.null(rpr))
. return(NULL)
. prepare_content(is.raw(rpr), rpr)
. }, error = error_handler), error = outer_handler)
3. tryCatchList(expr, classes, parentenv, handlers)
4. tryCatchOne(expr, names, parentenv, handlers[[1L]])
5. doTryCatch(return(expr), name, parentenv, handler)
6. withCallingHandlers({
. if (!mime %in% names(repr::mime2repr))
. stop("No repr_* for mimetype ", mime, " in repr::mime2repr")
. rpr <- repr::mime2repr[[mime]](obj)
. if (is.null(rpr))
. return(NULL)
. prepare_content(is.raw(rpr), rpr)
. }, error = error_handler)
7. repr::mime2repr[[mime]](obj)
8. repr_text.default(obj)
9. paste(capture.output(print(obj)), collapse = "\n")
10. capture.output(print(obj))
11. evalVis(expr)
12. withVisible(eval(expr, pf))
13. eval(expr, pf)
14. eval(expr, pf)
15. print(obj)
16. print.ggplot(obj)
17. ggplot_build(x)
18. ggplot_build.ggplot(x)
19. by_layer(function(l, d) l$compute_geom_1(d))
20. f(l = layers[[i]], d = data[[i]])
21. l$compute_geom_1(d)
22. f(..., self = self)
23. check_required_aesthetics(self$geom$required_aes, c(names(data),
. names(self$aes_params)), snake_class(self$geom))
24. stop(name, " requires the following missing aesthetics: ", paste(missing_aes,
. collapse = ", "), call. = FALSE)

So in fact we need all of the components described in the ggplot syntax.
ggplot(mpg) + geom_point(mapping=aes(x=displ,y=hwy))
<MAPPINGS>¶
ggplot(data=<DATA>) +
<GEOM_FUNCTION>(mapping=aes(<MAPPINGS>)
Visual property of objects in plot, i.e. size, shape, color. Can display points from other variables (in this case class) in different ways by changing value of aesthetic properties. These are known as levels, which is done in order to distinguish aesthetic values from data values.
head(mpg)
| manufacturer | model | displ | year | cyl | trans | drv | cty | hwy | fl | class |
|---|---|---|---|---|---|---|---|---|---|---|
| <chr> | <chr> | <dbl> | <int> | <int> | <chr> | <chr> | <int> | <int> | <chr> | <chr> |
| audi | a4 | 1.8 | 1999 | 4 | auto(l5) | f | 18 | 29 | p | compact |
| audi | a4 | 1.8 | 1999 | 4 | manual(m5) | f | 21 | 29 | p | compact |
| audi | a4 | 2.0 | 2008 | 4 | manual(m6) | f | 20 | 31 | p | compact |
| audi | a4 | 2.0 | 2008 | 4 | auto(av) | f | 21 | 30 | p | compact |
| audi | a4 | 2.8 | 1999 | 6 | auto(l5) | f | 16 | 26 | p | compact |
| audi | a4 | 2.8 | 1999 | 6 | manual(m5) | f | 18 | 26 | p | compact |
p1 <- ggplot(data=mpg) + geom_point(mapping=aes(x=displ,y=hwy,color=class))
p2 <- ggplot(data=mpg) + geom_point(mapping=aes(x=displ,y=hwy,shape=class))
p3 <- ggplot(data=mpg) + geom_point(mapping=aes(x=displ,y=hwy,size=class))
p4 <- ggplot(data=mpg) + geom_point(mapping=aes(x=displ,y=hwy,alpha=class))
grid.arrange(p1,p2,p3,p4,nrow=2)
Warning message: “The shape palette can deal with a maximum of 6 discrete values because more than 6 becomes difficult to discriminate; you have 7. Consider specifying shapes manually if you must have them.”Warning message: “Removed 62 rows containing missing values (geom_point).”Warning message: “Using size for a discrete variable is not advised.”Warning message: “Using alpha for a discrete variable is not advised.”

Exercises¶
Make a scatterplot of hwy vs cyl.
What does the
strokeaesthetic do? What shapes does it work with? Use one of the pieces of code above to make the same plot but withstroke=3and a different fill. (Hint: use ?geom_point)What happens if you map an aesthetic to something other than a variable name, like
aes(colour = displ < 5)? Note, you’ll also need to specify x and y.
Levels¶
ggplot2 automatically assigns a unique level of an aesthetic to a unique value of the variable. This process is known as scaling. It will also automatically select a scale to use with the aesthetic (i.e. continuous or discrete) as well as add a legend explaining the mapping between levels and values. That's why in the size mapping there's no shape for suv, and why the following two pieces of code do different things:
# for color property, all data points were assigned to 'blue', therefore ggplot2 assigns a single level to all of the
# points, which is red
ggplot(data=mpg) + geom_point(mapping=aes(x=displ,y=hwy,color='blue'))

# here color is placed outside aesthetic mapping, so ggplot2 understands that we want color of points to be blue
ggplot(data=mpg) + geom_point(mapping=aes(x=displ,y=hwy),color='blue')

# cty is a continuous variable, so when mapped to color we get a gradient with bins instead
ggplot(data=mpg) + geom_point(mapping=aes(x=displ,y=hwy,color=cty))

Continuous vs discrete scales¶
Generally continuous scales get chosen for numerical data and discrete scales are chosen for categorical data. If your data is numeric but in discrete categories you may have to use as.factor() in order to get proper levels.
# if we try to map cyl to shape we get an error because shape is only for discrete variables
# even though we only have cyl=4,5,6 or 8
ggplot(data=mpg) + geom_point(mapping=aes(x=displ,y=hwy,shape=cyl))
ERROR while rich displaying an object: Error: A continuous variable can not be mapped to shape
Traceback:
1. FUN(X[[i]], ...)
2. tryCatch(withCallingHandlers({
. if (!mime %in% names(repr::mime2repr))
. stop("No repr_* for mimetype ", mime, " in repr::mime2repr")
. rpr <- repr::mime2repr[[mime]](obj)
. if (is.null(rpr))
. return(NULL)
. prepare_content(is.raw(rpr), rpr)
. }, error = error_handler), error = outer_handler)
3. tryCatchList(expr, classes, parentenv, handlers)
4. tryCatchOne(expr, names, parentenv, handlers[[1L]])
5. doTryCatch(return(expr), name, parentenv, handler)
6. withCallingHandlers({
. if (!mime %in% names(repr::mime2repr))
. stop("No repr_* for mimetype ", mime, " in repr::mime2repr")
. rpr <- repr::mime2repr[[mime]](obj)
. if (is.null(rpr))
. return(NULL)
. prepare_content(is.raw(rpr), rpr)
. }, error = error_handler)
7. repr::mime2repr[[mime]](obj)
8. repr_text.default(obj)
9. paste(capture.output(print(obj)), collapse = "\n")
10. capture.output(print(obj))
11. evalVis(expr)
12. withVisible(eval(expr, pf))
13. eval(expr, pf)
14. eval(expr, pf)
15. print(obj)
16. print.ggplot(obj)
17. ggplot_build(x)
18. ggplot_build.ggplot(x)
19. by_layer(function(l, d) l$compute_aesthetics(d, plot))
20. f(l = layers[[i]], d = data[[i]])
21. l$compute_aesthetics(d, plot)
22. f(..., self = self)
23. scales_add_defaults(plot$scales, data, aesthetics, plot$plot_env)
24. scales$add(find_scale(aes, datacols[[aes]], env))
25. f(..., self = self)
26. find_scale(aes, datacols[[aes]], env)
27. scale_f()
28. stop("A continuous variable can not be mapped to shape", call. = FALSE)
# will transform into categorical variable with levels
as.factor(mpg$cyl)
- 4
- 4
- 4
- 4
- 6
- 6
- 6
- 4
- 4
- 4
- 4
- 6
- 6
- 6
- 6
- 6
- 6
- 8
- 8
- 8
- 8
- 8
- 8
- 8
- 8
- 8
- 8
- 8
- 8
- 8
- 8
- 8
- 4
- 4
- 6
- 6
- 6
- 4
- 6
- 6
- 6
- 6
- 6
- 6
- 6
- 6
- 6
- 6
- 6
- 6
- 6
- 6
- 8
- 8
- 8
- 8
- 8
- 6
- 8
- 8
- 8
- 8
- 8
- 8
- 8
- 8
- 8
- 8
- 8
- 8
- 8
- 8
- 8
- 8
- 8
- 8
- 8
- 6
- 6
- 6
- 6
- 8
- 8
- 6
- 6
- 8
- 8
- 8
- 8
- 8
- 6
- 6
- 6
- 6
- 8
- 8
- 8
- 8
- 8
- 4
- 4
- 4
- 4
- 4
- 4
- 4
- 4
- 4
- 4
- 4
- 4
- 4
- 6
- 6
- 6
- 4
- 4
- 4
- 4
- 6
- 6
- 6
- 6
- 6
- 6
- 8
- 8
- 8
- 8
- 8
- 8
- 8
- 8
- 8
- 8
- 8
- 8
- 6
- 6
- 8
- 8
- 4
- 4
- 4
- 4
- 6
- 6
- 6
- 6
- 6
- 6
- 6
- 6
- 8
- 6
- 6
- 6
- 6
- 8
- 4
- 4
- 4
- 4
- 4
- 4
- 4
- 4
- 4
- 4
- 4
- 4
- 4
- 4
- 4
- 4
- 6
- 6
- 6
- 8
- 4
- 4
- 4
- 4
- 6
- 6
- 6
- 4
- 4
- 4
- 4
- 6
- 6
- 6
- 4
- 4
- 4
- 4
- 4
- 8
- 8
- 4
- 4
- 4
- 6
- 6
- 6
- 6
- 4
- 4
- 4
- 4
- 6
- 4
- 4
- 4
- 4
- 4
- 5
- 5
- 6
- 6
- 4
- 4
- 4
- 4
- 5
- 5
- 4
- 4
- 4
- 4
- 6
- 6
- 6
Levels:
- '4'
- '5'
- '6'
- '8'
# all is well when we use as.factor()
ggplot(data=mpg) + geom_point(mapping=aes(x=displ,y=hwy,shape=as.factor(cyl)))

Note that this means x and y are aesthetic mappings as well. In fact without them you will get an error.
ggplot(data=mpg) + geom_point()
ERROR while rich displaying an object: Error: geom_point requires the following missing aesthetics: x, y
Traceback:
1. FUN(X[[i]], ...)
2. tryCatch(withCallingHandlers({
. if (!mime %in% names(repr::mime2repr))
. stop("No repr_* for mimetype ", mime, " in repr::mime2repr")
. rpr <- repr::mime2repr[[mime]](obj)
. if (is.null(rpr))
. return(NULL)
. prepare_content(is.raw(rpr), rpr)
. }, error = error_handler), error = outer_handler)
3. tryCatchList(expr, classes, parentenv, handlers)
4. tryCatchOne(expr, names, parentenv, handlers[[1L]])
5. doTryCatch(return(expr), name, parentenv, handler)
6. withCallingHandlers({
. if (!mime %in% names(repr::mime2repr))
. stop("No repr_* for mimetype ", mime, " in repr::mime2repr")
. rpr <- repr::mime2repr[[mime]](obj)
. if (is.null(rpr))
. return(NULL)
. prepare_content(is.raw(rpr), rpr)
. }, error = error_handler)
7. repr::mime2repr[[mime]](obj)
8. repr_text.default(obj)
9. paste(capture.output(print(obj)), collapse = "\n")
10. capture.output(print(obj))
11. evalVis(expr)
12. withVisible(eval(expr, pf))
13. eval(expr, pf)
14. eval(expr, pf)
15. print(obj)
16. print.ggplot(obj)
17. ggplot_build(x)
18. ggplot_build.ggplot(x)
19. by_layer(function(l, d) l$compute_geom_1(d))
20. f(l = layers[[i]], d = data[[i]])
21. l$compute_geom_1(d)
22. f(..., self = self)
23. check_required_aesthetics(self$geom$required_aes, c(names(data),
. names(self$aes_params)), snake_class(self$geom))
24. stop(name, " requires the following missing aesthetics: ", paste(missing_aes,
. collapse = ", "), call. = FALSE)
<GEOM_FUNCTION>¶
ggplot(data=<DATA>) +
<GEOM_FUNCTION>(mapping=aes(<MAPPINGS>)
geom geometrical object plot uses to represent data. Bar charts use bar geoms, line charts use line geoms, boxplots, etc. Scatterplots use point geoms. Full list of geoms provided with ggplot2 can be seen in ggplot2 reference. Also exist other geoms created by other packages.
Every geom function in ggplot2 takes a mapping argument with specific aesthetic mappings that are possible. Not every aesthetic will work with every geom. For example, can set shape of a point, but not shape of a line. However, can set linetype of a line.
ggplot(data = mpg) +
geom_smooth(mapping = aes(x = displ, y = hwy))
`geom_smooth()` using method = 'loess' and formula 'y ~ x'

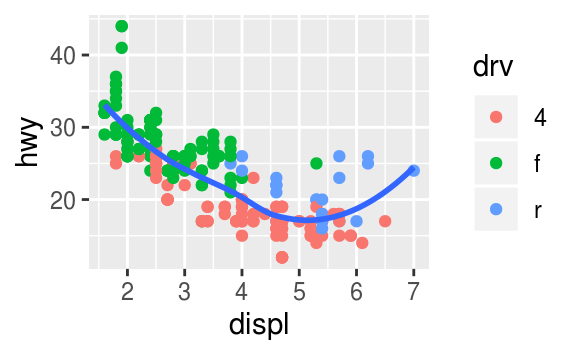
# data has been separated into three lines based on their drivetrain: 4 (4wd), f (front), r (rear)
ggplot(data = mpg) +
geom_smooth(mapping = aes(x = displ, y = hwy, linetype = as.factor(cyl)))
`geom_smooth()` using method = 'loess' and formula 'y ~ x'

Can display multiple geoms on same plot just by adding them
ggplot(data = mpg) +
geom_point(mapping = aes(x = displ, y = hwy, color=drv)) +
geom_smooth(mapping = aes(x = displ, y = hwy, color=drv, linetype=drv))
`geom_smooth()` using method = 'loess' and formula 'y ~ x'

Geoms like geom_smooth() use single geometric object to display multiple rows of data. If you don't necessarily want to add other distinguishing features to the geom like color, can use group aesthetic (for a categorical variable) to draw multiple objects.
ggplot(data=mpg) +
geom_smooth(mapping=aes(x=displ,y=hwy,group=drv))
`geom_smooth()` using method = 'loess' and formula 'y ~ x'

Global mappings vs local mappings¶
ggplot() function contains global mapping, while each geom has a local mapping
lmfrom stats for linear models (you can also fit other models)
# global mapping of displ and hwy creates x and yaxis
ggplot(data=mpg, mapping=aes(x=displ,y=hwy))

# mapping color to class for point geom while using global x and y mappings
ggplot(data=mpg, mapping=aes(x=displ,y=hwy)) + geom_point(mapping=aes(color=class))

# geom_smooth doesn't need any mapping arguments if using global
ggplot(data=mpg, mapping=aes(x=displ,y=hwy)) +
geom_point(mapping=aes(color=class))+
geom_smooth()
`geom_smooth()` using method = 'loess' and formula 'y ~ x'

# second geom_smooth uses same x and y mapping
# but mapping comes from no_2seaters data (from Transform section) instead
ggplot(data = mpg, mapping = aes(x = displ, y = hwy)) +
geom_point(mapping = aes(color = class)) +
geom_smooth() +
geom_smooth(data = no_2seaters)
`geom_smooth()` using method = 'loess' and formula 'y ~ x' `geom_smooth()` using method = 'loess' and formula 'y ~ x'

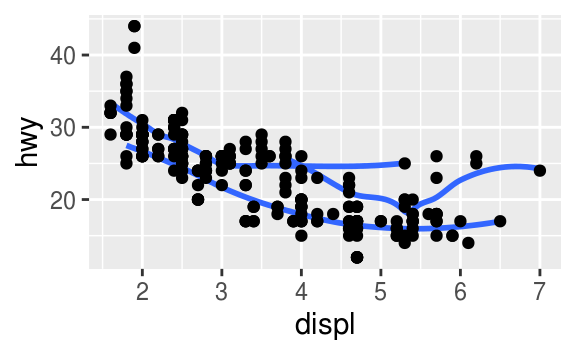




More syntax¶
{r}
ggplot(data = <DATA>) +
<GEOM_FUNCTION>(
mapping = aes(<MAPPINGS>),
stat = <STAT>,
position = <POSITION>
) +
<COORDINATE_FUNCTION> +
<FACET_FUNCTION>
Facets¶
Subplots displaying one subset of data.
facet_wrap()for a single variable.facet_grid()for along 2 variables.
ggplot(data=mpg) +
geom_point(mapping=aes(x=displ,y=hwy)) +
facet_wrap(~ class, nrow=2)

ggplot(data=mpg) +
geom_point(mapping=aes(x=displ,y=hwy)) +
facet_wrap(~ class, nrow=3)

ggplot(data=mpg) +
geom_point(mapping=aes(x=displ,y=hwy)) +
facet_wrap(~ class, ncol=4)
# some facets are empty because no observations have those combos
ggplot(data = mpg) +
geom_point(mapping = aes(x = displ, y = hwy)) +
facet_grid(drv ~ cyl)

Stats¶
{r}
ggplot(data = <DATA>) +
<GEOM_FUNCTION>(
mapping = aes(<MAPPINGS>),
stat = <STAT>,
position = <POSITION>
) +
<COORDINATE_FUNCTION> +
<FACET_FUNCTION>
Algorithm used to calculate new values for a graph. Each geom object has a default stat, and each stat has a default geom. Geoms like geom_point() will leave data as is, known as stat_identity(). Graphs like bar charts and histograms will bin your data and compute bin counts, known as stat_count(). Can see full list of stats at ggplot2 reference under both Layer: geoms and Layer: stats.
ggplot(data=mpg) +
geom_bar(mapping=aes(x=class))

Since each stat comes with a default geom, can use stat to create geoms on plots as well.
ggplot(data=mpg) +
stat_count(mapping=aes(x=class))
?geom_bar
# because stat_count() computes count and prop, can use those as variables for mapping as well
ggplot(data=mpg) + geom_bar(mapping=aes(x=class, y=..prop..,group=1))

# stat_summary is associated with geom_pointrange
# default is to compute mean and standard error
ggplot(data = mpg) +
stat_summary(mapping = aes(x=class,y=hwy))
No summary function supplied, defaulting to `mean_se()

# can change stat_summary to compute median and min/max instead
ggplot(data = mpg) +
stat_summary(
mapping = aes(x = class, y = hwy),
fun.ymin = min,
fun.ymax = max,
fun.y = median
)

Position adjustments¶
{r}
ggplot(data = <DATA>) +
<GEOM_FUNCTION>(
mapping = aes(<MAPPINGS>),
stat = <STAT>,
position = <POSITION>
) +
<COORDINATE_FUNCTION> +
<FACET_FUNCTION>
Each geom also comes with a default position adjustment specified by position argument. For geoms like geom_point() it is "identity" which is position as is.
Specifically for bar charts, have fill aesthetic. If fill aesthetic gets mapped to another variable, bars are automatically stacked under the "stack" position. Can see list of positions at ggplot2 reference.
p1 <- ggplot(data = mpg, mapping=aes(x=class,fill=as.factor(cyl)))
p1 + geom_bar()

# position = identity will place each object exactly where it falls in context of graph.
# Not useful for bar charts, better for scatterplots.
p1 + geom_bar(position="identity", alpha=0.2)

# position = fill will make bars same height
p1 + geom_bar(position="fill")

# position = "dodge" places objects directly beside one another. Easier to compare individual values.
p1 + geom_bar(position="dodge")

For geom_point one possible position is "jitter", which will add a small amount of random noise to each point. This spreads points out so that it's unlikely for points to overlap and therefore get plotted over each other. For example it's possible that majority of points are actually one combination of hwy and displ but they all get plotted at the exact same point so you can't tell. For very large datasets can help prevent overplotting to better see where mass of plot is or trends.
# seems quite uniform which suggests multiple observations with same value of cty/hwy
# creating overlapping points
ggplot(data = mpg, mapping = aes(x = cty, y = hwy)) +
geom_point()

# definitely the case
ggplot(data = mpg, mapping = aes(x = cty, y = hwy)) +
geom_point(position="jitter")

Coordinate systems¶
{r}
ggplot(data = <DATA>) +
<GEOM_FUNCTION>(
mapping = aes(<MAPPINGS>),
stat = <STAT>,
position = <POSITION>
) +
<COORDINATE_FUNCTION> +
<FACET_FUNCTION>
Default coordinate system is Cartesian.
coord_flip()switches x and y axes.coord_quickmap()sets aspect ratio for maps.coord_polar()sets polar coordinates.
p <- ggplot(data = mpg, mapping = aes(x = class, y = hwy))
p + geom_boxplot()

# flipping coordinates
p + geom_boxplot() + coord_flip()

# can reorder x axis by lowest to highest median hwy mileage
# allows easier comparisons
ggplot(data = mpg, mapping = aes(x = reorder(class,hwy,FUN=median), y = hwy)) +
geom_boxplot() +
coord_flip()

# Setting aspect ratio correctly
nz <- map_data("nz")
ggplot(nz, aes(long, lat, group = group)) +
geom_polygon(fill = "white", colour = "black")
ggplot(nz, aes(long, lat, group = group)) +
geom_polygon(fill = "white", colour = "black") +
coord_quickmap()


# polar coordinates
bar <- ggplot(data = mpg) +
geom_bar(
mapping = aes(x = class, fill = as.factor(cyl)),
show.legend = FALSE,
width = 1
) +
theme(aspect.ratio = 1) +
labs(x = NULL, y = NULL)
p1 <- bar + coord_flip()
p2 <- bar + coord_polar()
grid.arrange(p1,p2, nrow=1)

Summary¶
Now that we've gone through tidying, transforming, and visualizing data let's review all of the different functions we've used and in some cases learned the inner workings of:
Tidying¶
gather()spread()separate()unite()%>%propagates the output from a function as input to another. eg: x %>% f(y) becomes f(x,y), and x %>% f(y) %>% g(z) becomes g(f(x,y),z).
Transforming¶
filter()to pick observations (rows) by their valuesarrange()to reorder rows, default is by ascending valueselect()to pick variables (columns) by their namesmutate()to create new variables with functions of existing variablessummarise()to collapes many values down to a single summarygroup_by()to set up functions to operate on groups rather than the whole data set
Visualizing¶
ggplot- global data and mappingsgeom_point- geom for scatterplotsgeom_smooth- geom for regressionsgeom_pointrange- geom for vertical intervals defined byx,y,ymin, andymaxgeom_bar- geom for barchartsgeom_boxplot- geom for boxplotsgeom_polygon- geom for polygonsaes(color)- color mappingaes(shape)- shape mappingaes(size)- size mappingaes(alpha)- transparency mappingas.factor()- transforming numerical values to categorical values with levelsfacet_gridfacet_wrapstat_count- default stat for barcharts, bins by x and countsstat_identity- default stat for scatterplots, leaves data as isstat_summary- default stat for pointrange, by default computes mean and se of y by xposition="identity"position="stacked"position="fill"position="dodge"position="jitter"coord_flipcoord_mapcoord_polar
ggplot(mpg, aes(displ, hwy)) +
geom_point(aes(color = class)) +
geom_smooth(se = FALSE) +
labs(
title = "Fuel efficiency generally\n decreases with engine size",
subtitle = "Two seaters (sports cars) are an exception because of their light weight",
caption = "Data from fueleconomy.gov",
x = "Engine displacement (L)",
y = "Highway fuel economy (mpg)",
color = "Car type"
)
`geom_smooth()` using method = 'loess' and formula 'y ~ x'

Annotations¶
Can use geom_text() to add text labesls on the plot.
best_in_class <- mpg %>%
group_by(class) %>%
filter(row_number(desc(hwy)) == 1)
ggplot(mpg, aes(displ, hwy)) +
geom_point(aes(colour = class)) +
geom_text(aes(label = model), data = best_in_class)

ggplot(mpg, aes(displ, hwy)) +
geom_point(aes(colour = class)) +
ggrepel::geom_label_repel(aes(label = model), data = best_in_class) +
labs(
caption = "Data from fueleconomy.gov",
x = "Engine displacement (L)",
y = "Highway fuel economy (mpg)",
colour = "Car type"
) +
geom_point(size = 3, shape = 1, data = best_in_class)

Scales¶
breaks: For the position of tickslabels: For the text label associated with each tick.- Default scale is x continuous, y continuous but can also do x logarithmic, y logarithmic, change color scales.
ggplot(mpg, aes(displ, hwy)) +
geom_point() +
scale_y_continuous(breaks = seq(15, 40, by = 5))

ggplot(mpg, aes(displ, hwy)) +
geom_point() +
scale_x_continuous(labels = NULL) +
scale_y_continuous(labels = NULL)

p1 <- ggplot(diamonds, aes(carat, price)) +
geom_bin2d()
ggplot(diamonds, aes(carat, price)) +
geom_bin2d() +
scale_x_log10() +
scale_y_log10()
ggplot(diamonds, aes(log10(carat), log10(price))) +
geom_bin2d()


ggplot(mpg, aes(displ, hwy)) +
geom_point(aes(color = drv))
ggplot(mpg, aes(displ, hwy)) +
geom_point(aes(color = drv)) +
scale_colour_brewer(palette = "Set1")


ggplot(mpg, aes(displ, hwy)) +
geom_point(aes(color = drv)) +
scale_colour_manual(values=c(`4`="red",f="blue",r="blue"))

Legend positioning¶
theme(legend.position) to control legend position. guides() with guide_legened() or guide_colourbar() for legend display.
base <- ggplot(mpg, aes(displ, hwy)) +
geom_point(aes(colour = class))
#p1 <- base + theme(legend.position = "left")
#p2 <- base + theme(legend.position = "top")
#p3 <- base + theme(legend.position = "bottom")
#p4 <- base + theme(legend.position = "right")
#?theme
base + theme(text=element_text(color="blue",size=4))
#grid.arrange(p1,p2,p3,p4, nrow=2)

ggplot(mpg, aes(displ, hwy)) +
geom_point(aes(colour = class)) +
geom_smooth(se = FALSE) +
theme(legend.position = "bottom") +
guides(colour = guide_legend(nrow = 1, override.aes = list(size = 4)))
`geom_smooth()` using method = 'loess' and formula 'y ~ x'

Zooming¶
Three ways to control plot limits:
- Adjusting what data are plotted
- Setting limits in each scale
- Setting
xlimandylimincoord_cartesian()
# asetting xlim and ylim in coord_cartesian
ggplot(mpg, mapping = aes(displ, hwy)) +
geom_point(aes(color = class)) +
geom_smooth() +
coord_cartesian(xlim = c(5, 7), ylim = c(10, 30))
`geom_smooth()` using method = 'loess' and formula 'y ~ x'

# adjusting what data are plotted
# however geom_smooth will plot regression over subsetted data
filter(mpg, displ >= 5, displ <= 7, hwy >= 10, hwy <= 30) %>%
ggplot(aes(displ, hwy)) +
geom_point(aes(color = class)) +
geom_smooth()
`geom_smooth()` using method = 'loess' and formula 'y ~ x'

# 2 plots use subsetted data therefore have different scales along hwy and displ
suv <- mpg %>% filter(class == "suv")
compact <- mpg %>% filter(class == "compact")
ggplot(suv, aes(displ, hwy, colour = drv)) +
geom_point()
ggplot(compact, aes(displ, hwy, colour = drv)) +
geom_point()


# can set limits in each scale
x_scale <- scale_x_continuous(limits = range(mpg$displ))
y_scale <- scale_y_continuous(limits = range(mpg$hwy))
col_scale <- scale_colour_discrete(limits = unique(mpg$drv))
ggplot(suv, aes(displ, hwy, colour = drv)) +
geom_point() +
x_scale +
y_scale +
col_scale
ggplot(compact, aes(displ, hwy, colour = drv)) +
geom_point() +
x_scale +
y_scale +
col_scale


Themes¶
ggplot2 has 8 themes by default, can get more in other packages like ggthemes. Generally prefer theme_classic().
base <- ggplot(mpg, aes(displ, hwy)) +
geom_point(aes(color = class)) +
geom_smooth(se = FALSE)
p1 <- base + theme_bw()
p2 <- base + theme_light()
p3 <- base + theme_classic()
p4 <- base + theme_linedraw()
p5 <- base + theme_dark()
p6 <- base + theme_minimal()
p7 <- base + theme_void()
grid.arrange(base,p1,p2,p3,p4,p5,p6,p7,nrow=4)
`geom_smooth()` using method = 'loess' and formula 'y ~ x' `geom_smooth()` using method = 'loess' and formula 'y ~ x' `geom_smooth()` using method = 'loess' and formula 'y ~ x' `geom_smooth()` using method = 'loess' and formula 'y ~ x' `geom_smooth()` using method = 'loess' and formula 'y ~ x' `geom_smooth()` using method = 'loess' and formula 'y ~ x' `geom_smooth()` using method = 'loess' and formula 'y ~ x' `geom_smooth()` using method = 'loess' and formula 'y ~ x'

Saving your plots¶
ggsave()will save most recent plot to disktiff()will save next plot to disk- Other functions like
postscript()for eps files, etc. - All can take
width,height,fonts,pointsize,res(resolution) arguments
p1 <- ggplot(mpg, aes(displ, hwy)) +
geom_point(aes(color = class)) +
geom_smooth(se = FALSE) +
labs(x="Engine displacement (L)",y="Heighway fuel economy (mpg)",
title = "Fuel efficiency generally decreases with engine size",
caption = "Data from fueleconomy.gov",
subtitle = "Two seaters (sports cars) are an exception because of their light weight",
colour = "Car type"
) + x_scale + y_scale + theme_classic()
p1
ggsave("my_plot.pdf")
tiff("my_plot.tiff",width=7,height=5,units="in",pointsize=8,res=350)
p1
dev.off()
`geom_smooth()` using method = 'loess' and formula 'y ~ x' Saving 7 x 7 in image `geom_smooth()` using method = 'loess' and formula 'y ~ x' `geom_smooth()` using method = 'loess' and formula 'y ~ x'
Some other useful visualization packages¶
We don't have time in this workshop to get in depth to other workshops, but here are some more useful visualization packages that may be helpful for your research.
ggtree for phylogenetics¶
Resources and associated packages:
cowplot¶
Meant to provide publication-ready theme for gplot2 that requires minimum amount of fiddling with sizes of axis labels, plot backgrounds, etc. Auto-sets theme_classic() for all plots.
Gviz for plotting data along genomic coordinates¶
Can be installed from Bioconductor.
phyloseq for metagenomics¶
Website is very comprehensive.
Some exercise solutions¶
Transforming Data¶
- Earlier we computed the average mileage with an explicit formula by taking city mileage + highway mileage and dividing the sum by two. How can you do this without typing out the exact formula? What happens if there are
NAs? Feel free to experiment on the dataframeex2_dfto arrive at an answer.
rowMeans(ex2_df)
rowMeans(ex2_df,na.rm=TRUE)
mutate(mpg, avg_mileage = rowMeans(select(mpg,cty,hwy),na.rm=TRUE)) %>%
head
- <NA>
- 3.5
- <NA>
- 4.5
- 5
- 3.5
- 10
- 4.5
| manufacturer | model | displ | year | cyl | trans | drv | cty | hwy | fl | class | avg_mileage |
|---|---|---|---|---|---|---|---|---|---|---|---|
| <chr> | <chr> | <dbl> | <int> | <int> | <chr> | <chr> | <int> | <int> | <chr> | <chr> | <dbl> |
| audi | a4 | 1.8 | 1999 | 4 | auto(l5) | f | 18 | 29 | p | compact | 23.5 |
| audi | a4 | 1.8 | 1999 | 4 | manual(m5) | f | 21 | 29 | p | compact | 25.0 |
| audi | a4 | 2.0 | 2008 | 4 | manual(m6) | f | 20 | 31 | p | compact | 25.5 |
| audi | a4 | 2.0 | 2008 | 4 | auto(av) | f | 21 | 30 | p | compact | 25.5 |
| audi | a4 | 2.8 | 1999 | 6 | auto(l5) | f | 16 | 26 | p | compact | 21.0 |
| audi | a4 | 2.8 | 1999 | 6 | manual(m5) | f | 18 | 26 | p | compact | 22.0 |
- Find all cars grouped by manufacturer, model, cylinder, and auto/manual transmission that improved on gas mileage (either city, highway, or both, you choose) by at least 1mpg between 1999 and 2008. (This one might take some time, if you just look at city mileage you should end up with 26 rows in your data frame.)
separate(mpg,trans,into=c('trans',NA),sep='\\(') %>%
group_by(manufacturer, model, cyl,trans) %>%
mutate(imp=cty-mean(cty)) %>%
filter(year==2008,imp>1)
| manufacturer | model | displ | year | cyl | trans | drv | cty | hwy | fl | class | imp |
|---|---|---|---|---|---|---|---|---|---|---|---|
| <chr> | <chr> | <dbl> | <int> | <int> | <chr> | <chr> | <int> | <int> | <chr> | <chr> | <dbl> |
| audi | a4 | 2.0 | 2008 | 4 | auto | f | 21 | 30 | p | compact | 1.500000 |
| audi | a4 quattro | 2.0 | 2008 | 4 | auto | 4 | 19 | 27 | p | compact | 1.500000 |
| chevrolet | c1500 suburban 2wd | 5.3 | 2008 | 8 | auto | r | 14 | 20 | r | suv | 1.200000 |
| chevrolet | c1500 suburban 2wd | 5.3 | 2008 | 8 | auto | r | 14 | 20 | r | suv | 1.200000 |
| chevrolet | k1500 tahoe 4wd | 5.3 | 2008 | 8 | auto | 4 | 14 | 19 | r | suv | 1.500000 |
| chevrolet | malibu | 2.4 | 2008 | 4 | auto | f | 22 | 30 | r | midsize | 1.500000 |
| dodge | caravan 2wd | 3.3 | 2008 | 6 | auto | f | 17 | 24 | r | minivan | 1.400000 |
| dodge | caravan 2wd | 3.3 | 2008 | 6 | auto | f | 17 | 24 | r | minivan | 1.400000 |
| dodge | dakota pickup 4wd | 4.7 | 2008 | 8 | auto | 4 | 14 | 19 | r | pickup | 2.000000 |
| dodge | dakota pickup 4wd | 4.7 | 2008 | 8 | auto | 4 | 14 | 19 | r | pickup | 2.000000 |
| dodge | durango 4wd | 4.7 | 2008 | 8 | auto | 4 | 13 | 17 | r | suv | 1.333333 |
| dodge | durango 4wd | 4.7 | 2008 | 8 | auto | 4 | 13 | 17 | r | suv | 1.333333 |
| dodge | durango 4wd | 5.7 | 2008 | 8 | auto | 4 | 13 | 18 | r | suv | 1.333333 |
| dodge | ram 1500 pickup 4wd | 4.7 | 2008 | 8 | auto | 4 | 13 | 17 | r | pickup | 1.333333 |
| dodge | ram 1500 pickup 4wd | 4.7 | 2008 | 8 | auto | 4 | 13 | 17 | r | pickup | 1.333333 |
| dodge | ram 1500 pickup 4wd | 5.7 | 2008 | 8 | auto | 4 | 13 | 17 | r | pickup | 1.333333 |
| honda | civic | 1.8 | 2008 | 4 | manual | f | 26 | 34 | r | subcompact | 1.400000 |
| hyundai | sonata | 2.4 | 2008 | 4 | auto | f | 21 | 30 | r | midsize | 1.500000 |
| hyundai | sonata | 2.4 | 2008 | 4 | manual | f | 21 | 31 | r | midsize | 1.500000 |
| jeep | grand cherokee 4wd | 3.0 | 2008 | 6 | auto | 4 | 17 | 22 | d | suv | 1.333333 |
| jeep | grand cherokee 4wd | 4.7 | 2008 | 8 | auto | 4 | 14 | 19 | r | suv | 1.800000 |
| nissan | altima | 2.5 | 2008 | 4 | auto | f | 23 | 31 | r | midsize | 2.000000 |
| subaru | forester awd | 2.5 | 2008 | 4 | auto | 4 | 20 | 26 | r | suv | 1.333333 |
| toyota | corolla | 1.8 | 2008 | 4 | auto | f | 26 | 35 | r | compact | 1.333333 |
| volkswagen | gti | 2.0 | 2008 | 4 | auto | f | 22 | 29 | p | compact | 1.500000 |
| volkswagen | jetta | 2.0 | 2008 | 4 | auto | f | 22 | 29 | p | compact | 1.500000 |
Visualizing Data¶
- Make a scatterplot of hwy vs cyl
ggplot(mpg) + geom_point(aes(x=cyl,y=hwy))

sessionInfo()
R version 3.5.1 (2018-07-02) Platform: x86_64-apple-darwin15.6.0 (64-bit) Running under: macOS 10.14.5 Matrix products: default BLAS: /Library/Frameworks/R.framework/Versions/3.5/Resources/lib/libRblas.0.dylib LAPACK: /Library/Frameworks/R.framework/Versions/3.5/Resources/lib/libRlapack.dylib locale: [1] C/UTF-8/C/C/C/C attached base packages: [1] stats graphics grDevices utils datasets methods base other attached packages: [1] maps_3.3.0 ggrepel_0.8.1 gridExtra_2.3 forcats_0.4.0 [5] stringr_1.4.0 dplyr_0.8.3 purrr_0.3.2 readr_1.3.1 [9] tidyr_1.0.0 tibble_2.1.3 ggplot2_3.2.1 tidyverse_1.2.1 loaded via a namespace (and not attached): [1] pbdZMQ_0.3-3 tidyselect_0.2.5 repr_1.0.1 reshape2_1.4.3 [5] haven_2.1.1 lattice_0.20-38 colorspace_1.4-1 vctrs_0.2.0 [9] generics_0.0.2 htmltools_0.3.6 base64enc_0.1-3 rlang_0.4.0 [13] pillar_1.4.2 glue_1.3.1 withr_2.1.2 RColorBrewer_1.1-2 [17] modelr_0.1.5 readxl_1.3.1 uuid_0.1-2 plyr_1.8.4 [21] lifecycle_0.1.0 munsell_0.5.0 gtable_0.3.0 cellranger_1.1.0 [25] rvest_0.3.4 evaluate_0.14 labeling_0.3 broom_0.5.2 [29] IRdisplay_0.7.0 Rcpp_1.0.2 backports_1.1.4 scales_1.0.0 [33] IRkernel_1.0.2 jsonlite_1.6 hms_0.5.1 digest_0.6.21 [37] stringi_1.4.3 grid_3.5.1 cli_1.1.0 tools_3.5.1 [41] magrittr_1.5 lazyeval_0.2.2 crayon_1.3.4 pkgconfig_2.0.3 [45] zeallot_0.1.0 ellipsis_0.3.0 xml2_1.2.2 lubridate_1.7.4 [49] assertthat_0.2.1 httr_1.4.1 rstudioapi_0.10 R6_2.4.0 [53] nlme_3.1-141 compiler_3.5.1